BIG DATA ET IA: UNE ÉTRANGE RESSEMBLANCE... REVUE DE CONCEPTS - AI Paris
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

BIG DATA
ET IA:
UNE ÉTRANGE
RESSEMBLANCE...
REVUE DE
CONCEPTS
DU BIG DATA
À L’IA
BIG DATA, IA…
REVUE DE CONCEPTS
QU’EST-CE QUE L’INTELLIGENCE ARTIFICIELLE ?
Selon l’un de ses créateurs, Marvin Lee Minsky en 1956, l’Intelligence Artificielle serait une forme dégénérée d’intelligence humaine,
ou – à tout le moins – une pâle copie encore inaboutie du cerveau humain. Voici ce qu’il déclarait :
« L’IA correspond à la construction de programmes informatiques qui s’adonnent à des
tâches qui sont, pour l’instant, accomplies de façon plus satisfaisante par des êtres hu-
mains car elles demandent des processus mentaux de haut niveau tels que : l’appren-
tissage perceptuel, l’organisation de la mémoire et le raisonnement critique ».
Par la suite, les outils algorithmiques et informatiques ayant évolué vers davantage de perfor-
mance, la définition de l’IA supprime la notion de suprématie du cerveau humain sur ces tâches :
« L’IA se définit traditionnellement comme la capacité des ordinateurs à effectuer des
tâches cognitives habituellement associées au cerveau humain, telles que la percep-
tion, le raisonnement, l’apprentissage, l’interaction avec l’environnement, la résolution
de problèmes et même la pratique créative. » (Mc Kinsey 2018, An Executive’s Guide to AI)
3 NIVEAUX D’INTELLIGENCE ARTIFICIELLE
• Artificial Narrow Intelligence (ANI) ou « IA faible » = Capacité de l’IA à traiter des pro-
blèmes ciblés sur certains domaines. Les fonctions du système sont limitées à l’exécution d’un
segment de tâches complexes mais prédéfinies. C’est aujourd’hui l’état de l’art en matière d’IA :
moteur de recherche, assistants vocaux, véhicules autonomes, etc.
• Artificial General Intelligence (AGI) ou « IA forte » = Capacité de l’IA à exécuter toutes les
tâches intellectuelles effectuées par le cerveau humain. Dans son récent livre « Superintelligence :
Paths, Dangers, Strategies », le philosophe Nick Bostrom affirme qu’il y aurait 50% de chances
pour que cette étape de l’AGI soit franchie avant 2050.
• Artificial Super Intelligence (ASI) ou « Superintelligence » = Capacité de l’IA à exécuter
des tâches qui sont inatteignables pour le cerveau humain. Les chercheurs estiment que l’ASI
devrait advenir dans la foulée de l’AGI.
Un test simple si vous voulez vérifier que votre robot AGI
test
fonctionne bien :
LE TEST DU CAFE (PAR STEVE WOZNIAK)
« Dites à votre machine d’entrer dans n’importe quelle mai-
son et de comprendre comment y faire du café : trouver la
machine à café, trouver le café, ajouter de l’eau, trouver une
tasse et faire couler le café en pressant les bons boutons ».
Facile pour une AGI !
2
DU BIG DATA
À L’IA
INTERVIEW DE Le Big Data a sorti de
ger les data lake et d’en tirer la valeur. C’est
ce pavé qui manque encore bien souvent dans
CYRILLE CHAUSSON l’ombre toutes ces données
la stratégie des entreprises ; avec pour consé-
quence le phénomène des dark data, ces don-
nées qu’on a stockées mais qu’on n’utilise
qui étaient jusque-là pas. Seules 20% des données sont utilisées en
« LE BIG DATA A inutilisées ou invisibles
entreprise actuellement.
ÉTÉ LA RAMPE DE Le Big Data a sorti de l’ombre toutes ces don-
4/ LE BIG DATA, L’IA… CE SONT DES
CONCEPTS CONCURRENTS OU C’EST LA
LANCEMENT DE L’IA » nées qui étaient jusque-là inutilisées ou invi-
sibles car non structurées, et il a su en tirer
MÊME CHOSE ?
Je dirais que le premier a été la rampe de lan-
une mine d’informations. Donc, oui, il y a eu un cement du second. Pendant des années, j’ai
1/ ÇA INTÉRESSE TOUJOURS AUTANT DE effet de buzz marketing avec le Big Data mais vu des entreprises s’équiper au pas de course
LECTEURS LE BIG DATA ? son impact a été réel sur le décryptage et la avec des technologies complexes… sans for-
Plus que jamais ! Avant on parlait surtout
création de valeur. cément y voir d’autre objectif que de ne pas
des technologies, maintenant on a suffisam-
perdre du terrain sur leurs concurrents.
ment de cas concrets avancés (pas seulement
3/ AUJOURD’HUI, OÙ EN EST-ON DU DATA Désormais, avec la vague d’algorithmes et
des PoC) pour parler d’usages… c’est tout de
DELUGE ? d’automatisations issus de l’IA, elles y trouvent
même plus captivant ! C’est intéressant d’ail-
leurs de noter que le terme Hadoop a quasi- Ce qui est intéressant, c’est le mouvement in- enfin un sens : on va pouvoir enfin faire parler
ment disparu des articles ou événements liés verse que l’on observe actuellement : après toutes ces données accumulées ! Ce qui est sûr,
au Big Data (ex : le Hadoop Summit a laissé avoir réuni ces marécages de données non c’est que l’IA n’aurait eu aucune chance d’être
place au DataWorks Summit) : désormais les structurées, on veut désormais structurer le adoptée sans le Big Data : il a permis de déve-
technologies sont devenues assez abstraites, traitement, c’est-à-dire repasser au langage lopper la culture data au sein de l’entreprise et
on se concentre sur les cas d’usage et sur la SQL et à la classification de données en cata- d’insuffler la conduite du changement.
façon d’aborder concrètement les probléma- logues pour permettre aux métiers d’interro-
tiques data.
Repasser le Big Data au langage SQL, un des défis à venir pour garantir l’appropriation par les métiers
Interview
2/ AVEC UN PEU DE RECUL, EST-CE QU’ON
N’A PAS FORCÉ LE TRAIT SUR L’IMPACT DU
BIG DATA ? L’ANALYSE DE DONNÉES, CE
N’ÉTAIT PAS SI NOUVEAU…
L’analyse de données a toujours existé mais
pas l’interconnexion entre autant de sources
différentes d’informations. Avant, on privilé-
giait une approche structurée, en classifiant
les données pour pouvoir les traiter.
3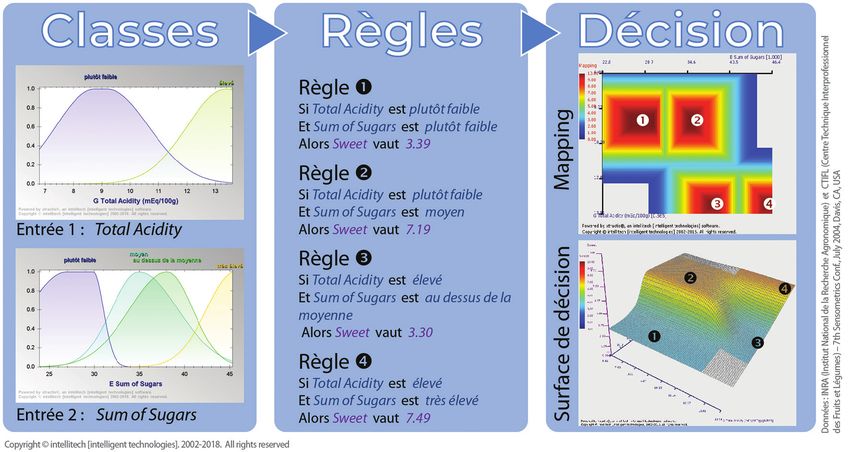
DU BIG DATA
À L’IA
5/ JUSTEMENT, L’IA, VOUS LA VOYEZ OÙ 6/ ET CÔTÉ USAGES… ?
Le Big Data a permis DANS DIX ANS ? Coté usages BtoB, je pense que les deux prin-
Difficile à dire car on est encore aux prémices : cipales utilisations de l’IA seront celles liées à
on voit beaucoup d’idées mais peu de projets l’automatisation des tâches et à la reconnais-
de développer la culture de grande ampleur. Ce qui est sûr, c’est qu’à sance vocale. Dans l’industrie mais aussi dans
l’image du Big Data, les fournisseurs vont pro- la banque, le retail, on aura besoin de proces-
gressivement adapter leur offre technologique sus automatisés et intelligents capables de
data au sein de l’entreprise pour qu’elle colle aux usages. Et puis, en répondre dynamiquement à une panne ou une
France, l’écosystème est en train de se struc- situation exceptionnelle. Cela changera l’ex-
turer : pour l’instant il est difficile de mesu- périence opérationnelle en interne mais aussi
et d’insuffler la conduite rer vraiment l’impact de chaque acteur car les l’expérience client.
start-ups sont beaucoup mises en avant, mais Et puis il y a la reconnaissance vocale… Pour
on ne sait pas concrètement le poids écono- l’instant, elle se limite à des chatbots mais elle
du changement mique que cela représente - au-delà des en- porte en elle un enjeu primordial, celui de l’in-
couragements des pouvoirs publics. Et puis, il terface entre l’homme et la machine. Toutes
y a toujours les GAFA qui portent l’innovation les fonctions du langage pourraient bientôt
sur ces sujets depuis dix ans et qui ne vont être analysées. Sur ce terrain, les progrès
pas s’arrêter là… c’est clairement de ce côté technologiques sont immenses, il y a beau-
là que se jouera l’avenir de l’IA dans les cinq coup à faire dans les dix prochaines années.
ans à venir.
WWW.BIGDATAPARIS.COM/2019 4
DU BIG DATA
À L’IA
LE LIEN ENTRE BIG DATA ET IA
3 INGRÉDIENTS FONDAMENTAUX CONSTITUENT LE CŒUR DE L’INTELLIGENCE ARTIFICIELLE :
L’ingrédient Algorithmique
L’ingrédient Algorithmique (« le cerveau »), soit les modèles de suites mathématiques incluant
calculs et règles opératoires itératives qui permettront de répondre à un problème donné de
manière stable - c’est-à-dire sans erreur possible dans le résultat final quelles que soient les
caractéristiques du problème à chaque étape de calcul.
L’ingrédient Data
L’ingrédient Data (« la matière »), soit l’ensemble des données qui entrent en ligne de compte dans
le problème donné et qui irrigueront les algorithmes pour aboutir à la résolution du problème et
valider la stabilité du modèle. A défaut, elles permettront d’affiner les modes opératoires de ces
algorithmes pour les amener vers le « zéro erreur ». Plus les données sont volumineuses et di-
versifiées, plus elles rendent compte d’une réalité complexe et tendent à rendre le modèle stable.
L’ingrédient Informatique
L’ingrédient Informatique (« le moteur »), soit l’ensemble des outils de stockage et de traitement
qui s’exécutent automatiquement sur une machine (ordinateur, capteurs, etc). Ils permettront à
l’algorithme d’extraire les données cibles et d’effectuer tous les calculs de manière lisse, rapide
et reproductible. La performance de ces outils (temps d’exécution, énergie disponible, volume
induit) est dès lors un critère essentiel.
Si le développement algorithmique s’est imposé dès les années 50 (ingrédient 1), c’est grâce à l’explosion des données (ingrédient 2) et le renfor-
cement des outils informatiques (ingrédient 3) induits par la révolution Big Data que l’intelligence artificielle a pu se généraliser. En ce sens, le Big
Data constitue non seulement le contributeur numéro 1 de l’Intelligence Artificielle (puisqu’il recouvre deux ingrédients sur trois) mais aussi son
catalyseur principal.
Mc Kinsey établit à 2009 la première date historique de réunion de ces trois ingré-
dients avec l’expérimentation d’Andrew Ng, chercheur en informatique à l’université de
Stanford : celui-ci démontre qu’en appliquant 100 millions de paramètres (data) à des
modèles de deep learning (algorithmes) et en les exécutant sur des processeurs gra-
phiques GPU (informatique), il gagne de façon exponentielle en vélocité (jusqu’à 70
fois le temps de traitement nécessaire auparavant avec des processeurs CPU).
5
LES CONCEPTS LIÉS À L’IA ET AU BIG DATA DONT
ON ENTEND TOUJOURS PARLER
LE MACHINE LEARNING (ou Apprentissage Automatique)
Techniques de traitement de larges segments de données qui permettent d’identifier des com-
portements et des règles généralisables à une population exogène aux données initiales (« patterns »),
à des fins de prédictions et de recommandations. Ces patterns s’affinent et s’enrichissent au fur
et à mesure qu’on les alimente de nouvelles données.
Le Deep Learning (ou Apprentissage Profond)
Type de Machine Learning faisant intervenir de plus grands volumes de données et des techniques
de traitement faisant appel à des architectures complexes de données (données interconnectées
de type « réseau de neurones » et traitées par couches successives). Le Deep Learning est parti-
culièrement efficace dans les applications de reconnaissance vocale, faciale ou sémantique.
Machine Learning et Deep Learning sont donc des implémentations spécifiques de traitements Big Data destinées à servir la création d’applications
d’Intelligence Artificielle.
INTERVIEW DE D’OBSERVATIONS QU’IL REÇOIT POUR DÉCOUVRIR LES MODÈLES PRÉDICTIFS
EXPLIQUANT DE MANIÈRE ROBUSTE LE PHÉNOMÈNE ÉTUDIÉ.
ZYED ZALILA 1/ LE BIG DATA EST-IL UN INGRÉDIENT FONDAMENTAL DE L’INTELLIGENCE
PDG-FONDATEUR ARTIFICIELLE ?
Je n’aime pas le terme de Big Data car il a tendance à survaloriser la question des
INTELLITECH / volumes de données, une question qui a plutôt trait à l’informatique (stockage, accès).
PROFESSEUR À L’UTC Or, en mathématiques, je peux vous garantir qu’on peut créer des modèles robustes
« LA VARIÉTÉ EST
d’IA sans forcément passer par des volumes importants de données : ce qui compte,
Interview
AU CŒUR DE LA
PROBLÉMATIQUE
DATA »
ZYED ZALILA EST PROFESSEUR À L’UTC
OÙ IL ENSEIGNE UN TYPE SPÉCIFIQUE
D’INTELLIGENCE ARTIFICIELLE : L’IA
FLOUE AUGMENTÉE.
AVEC SON ÉQUIPE D’UNE QUINZAINE
D’INGÉNIEURS DE RECHERCHE AU SEIN
DE SA SOCIÉTÉ INTELLITECH, IL A MIS
AU POINT XTRACTIS, UN AUTOMATE
INTELLIGENT UNIVERSEL CAPABLE
DE RAISONNER SUR UN ENSEMBLE
6
DU BIG DATA
À L’IA
c’est la largeur de la base de données, soit le
nombre de variables disponibles pour créer le
modèle. Vous n’aurez pas les mêmes besoins
en algorithmie IA si votre base de données
contient 26 000 colonnes (ce qui est le cas
pour la médecine prédictive épigénétique) au
lieu de 10… Encore plus si ces variables sont
liées entre elles. Mathématiquement, les al-
gorithmes d’IA doivent pouvoir résoudre de
tels problèmes complexes non-linéaires. Pour
moi, c’est donc la variété qui est au cœur de la
problématique data.
2/ POURTANT, AVEC XTRACTIS, VOUS
N’UTILISEZ QUE DES DONNÉES
STRUCTURÉES…
Disons que les données que j’injecte dans
le système vont toutes être présentées sous
un format lignes/colonnes, d’où la notion de
données structurées. C’est un prérequis : le
problème doit toujours être posé de la même
façon si l’on veut que l’automate puisse ré-
soudre n’importe quel problème prédictif
quel que soit le secteur d’application. Mais Le Robot xtractis détermine des zones de décisions plus ou moins satisfaisantes pour un problème donné. Ici,
les solutions les plus satisfaisantes sont en marron, les moins satisfaisantes en bleu
la nature des données est, elle, très variable
: qualitative/quantitative, objective/subjective,
certaine/incertaine, précise/imprécise, mesu- Le RGPD rend ce point d’autant plus crucial qu’il impose un « droit à l’explication » pour toute
rée/manquante… c’est l’un des avantages que décision issue d’un traitement automatisé. Pour être audité et certifié, un système IA se doit donc
nous apportent les mathématiques du flou. d’être intelligible et explicable.
D’ailleurs, nous intégrons de plus en plus des
images et des signaux - qui sont des données 4/ VOUS CONCENTREZ VOS TRAVAUX SUR UN GENRE PARTICULIER D’IA, L’IA FLOUE AUGMENTÉE…
non structurées - après une phase de prétrai- POUVEZ-VOUS NOUS EXPLIQUER CE QUE CETTE DISCIPLINE RECOUVRE ?
tement. L’IA floue ou IA nuancée / graduelle, c’est une logique quantique qui s’oppose à la modélisation
traditionnelle binaire du monde sous l’angle Vrai/Faux, comme nous l’appliquons depuis Aristote.
3/ A L’ISSUE DU TRAITEMENT PAR
XTRACTIS, VOUS PRÉTENDEZ OBTENIR
DES MODÈLES EXPLICABLES…
QUE VOULEZ-VOUS DIRE ?
Lorsque xtractis découvre des connaissances
à partir d’une base de données, il va pouvoir
formuler le modèle prédictif sous forme de
règles ou d’équations accessibles à l’enten-
dement humain (de type « si… alors… »). Cela
signifie que les personnes qui utiliseront en-
suite les résultats de ces travaux pour prendre
des décisions pourront toujours justifier de
leur démarche : elles pourront toujours ex-
pliquer, au régulateur ou au juge, les règles
du modèle et prouver qu’il est à la fois neutre
(sans biais) et robuste (prédictions fiables en
situations inconnues). Ce n’est pas le cas avec
la plupart des modèles « boîte noire », de type
Deep Learning/réseaux de neurones ou fo-
rêts aléatoires, car ceux-ci ne sont pas acces-
sibles à l’entendement humain. On doit donc
se fier à une décision automatisée, dont on
ne peut expliquer le schéma décisionnel, qui
pose la question de la responsabilité juridique.
7
7
On peut considérer qu’il y a une infinité de de-
grés de vérités différentes dans une assertion
et qu’il faudrait pouvoir toutes les modéliser.
Prenons un exemple : nous considérons que
la majorité juridique d’une personne s’établit
à 18 ans. Cela signifie que la règle de droit
ne va pas être la même entre un individu qui
commet un délit à 17 ans et 364 jours et un
autre qui commet ce même délit à 18 ans et
1 jour. Or, vous conviendrez que ces deux ré-
alités sont extrêmement proches… Avec l’IA
floue, nous essayons de modéliser ces réali-
tés proches au sein des data, avec pour ob-
jectif de proposer à nos clients des systèmes
continus d’aide à la décision insensibles aux
effets de seuil.
LES 10 « BIG DATA » DE L’INTELLIGENCE ARTIFICIELLE
DATA 1 DATA 2 DATA 3 DATA 4 DATA 5
LE MARCHÉ LA CROISSANCE LA CONTRIBUTION LA CONTRIBUTION AUX LES START-UP
A LA CROISSANCE ENTREPRISES
IDC prévoit un chiffre BPI France table sur MONDIALE Selon BPI France, on
d’affaires de une croissance de 53% Accenture évalue à recense 950 start-up
46 milliards de du marché entre 2015 PwC estime que l’IA 38 % en moyenne consacrées à l’IA dans
dollars pour les et 2020 devrait permettre l’accroissement de la le monde dont 499 aux
systèmes d’IA et de une croissance du PIB rentabilité des USA
Machine Learning d’ici mondial de 14% d’ici entreprises d’ici 2035.
2020 2030.
DATA 6 DATA 7 DATA 8 DATA 9 DATA 10
LES LEVÉES DE FONDS LES INVESTISSEMENTS CHINA FIRST L’APPORT MARKETING L’IA, EMPLOYÉ
DE L’ANNÉE
Le Hub Institute Selon CB Insights, en Toujours selon CB Selon BPI France, avec
estime que les 2017, 15,2 milliards Insights, 48% des l’IA, 85% des Toujours selon BPI
montants des levées de dollars ont été investissements interactions avec le France, avec l’IA, 20%
de fonds en France investis à l’échelle mentionnés étaient client ne nécessiteront du contenu des
ont été multipliés mondiale dans des destinés à la Chine plus de main d’œuvre entreprises sera
par 3 entre 2010 et start-up IA. contre 38% pour les humaine. bientôt généré par des
2016 passant de 0,6 à Etats-Unis. machines.
1,8 milliards de dollars.
PAR COMPARAISON… QUE DISAIT-ON DU BIG DATA EN 2013 ? (Extrait du Guide du Big Data 2013/14)
Selon IDC, le marché du Big Data s’établirait à 24 milliards de dollars en 2016
Avec un taux de croissance annuel de 31,7%
En juillet 2013, McKinsey estimait que le PIB des Etats-Unis pourrait croître de 1,7% d’ici 2020 en s’appuyant sur le Big Data
8
BIG DATA
ET IA:
UNE ÉTRANGE
RESSEMBLANCE...
REVUE DE
CONCEPTS
A la fois source d’inspiration, boîte à
outils technique et place de marché
incontournable de l’IA en France,
AI PARIS donne la parole aux hommes
et aux femmes qui façonnent jour
après jour les codes et usages de l’in-
telligence artificielle au sein de leurs
organisations.
Offrez-vous plus de 48h
d’immersion au cœur de
l’incroyable scène tech
française de l’IA, en réservant
votre badge sur www.aiparis.fr
Vous pouvez aussi lire

















































