ALGORITHMES GENETIQUES FITNESS FUNCTION
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
ÉC O L E P O L Y T E C H N IQ U E
FÉ DÉ R A L E D E L A U S A N N E
PROJET
MACHINES ADAPTATIVES BIO - INSPIREES
ALGORITHMES GENETIQUES
-
FITNESS FUNCTION
Professeur: Dario Floreano
Assistant: Claudio Mattiussi
Pascal JERMINI,
Tania MAGNENAT
Section Informatique, 6ème semestre
6 avril 2004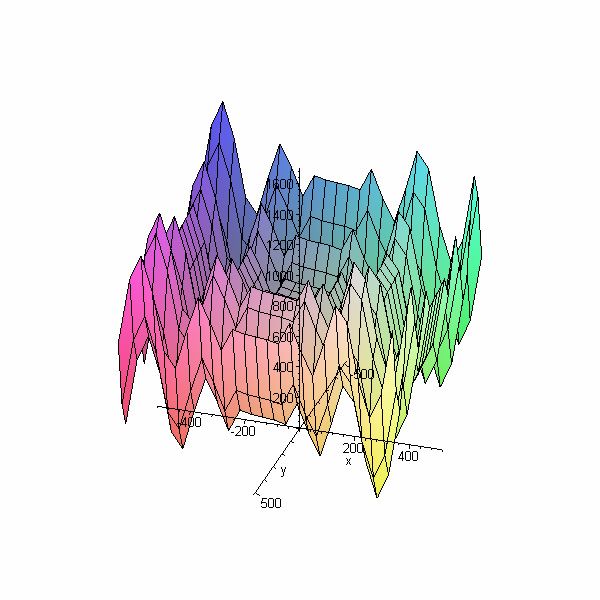
Machines adaptatives bio – inspirées avril 04
1. INTRODUCTION
1.1 But
Le but de ce projet est d'explorer de manière plus approfondie le thème des algorithmes
génétiques, en particulier comment varient les résultats en fonction de la valeur donnée
aux différents paramètres de l'algorithme et de la fonction d’adaptation.
On verra que certains paramètres ont une très grande influence sur la qualité du résultat,
tandis que d'autres ne semblent pas l'affecter de manière excessive. Comme toute
méthode bio - inspirée il sera facile de tracer un parallèle avec les sciences du vivant, et
découvrir que effectivement même dans la vie réelle ces paramètres ne jouent un rôle que
très secondaire dans l'évolution d'une espèce.
De plus on pourra observer que certaines fonctions d’adaptations parfois présentent des
particularités qui peuvent mettre en difficulté l’algorithme génétique.
1.2 Matériel à notre disposition
- Notebook Mathematica intitulé « Optimization of 2D functions »
- Applets GA Playground
-2-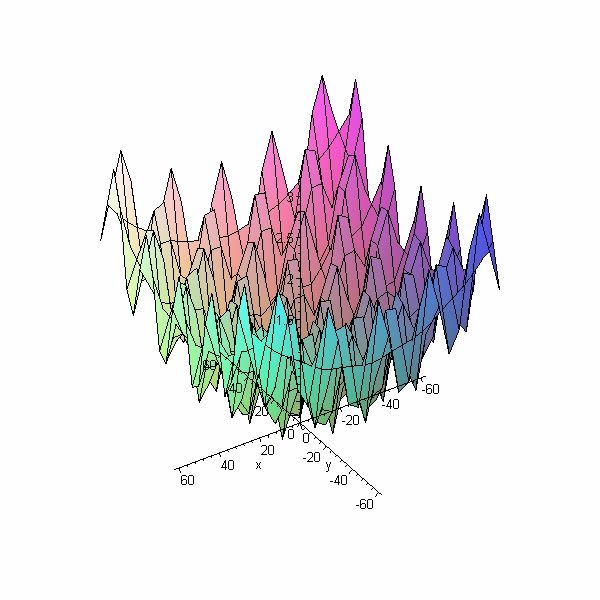
Machines adaptatives bio – inspirées avril 04
2. MARCHE A SUIVRE
La première étape de notre projet a été notre familiarisation avec les algorithmes
génétiques, grâce au notebook Mathematica intitulé « Optimization of 2D functions ». De
cette manière nous avons pu comprendre les mécanismes de base de ces algorithmes sur
des exemples simples et de manière visuelle.
Ensuite nous sommes passés à des cas plus complexes, l’étude des fonctions multi –
modales1 de dimension n et l’étude des fonctions d’optimisation.
Pour cette étape nous avons utilisé la démarche suivante pour les fonctions considérées :
¾ Simulation avec les paramètres par défaut fournis par le programme
GA Playground.
¾ Modification de la taille de la population
¾ Modification du nombre de gènes (c’est à dire de la dimension du problème)
¾ Modification du pourcentage des survivants à chaque génération (élitisme)
¾ Modification du taux de mutation.
Afin d’isoler l’effet de chaque paramètre, les essais ont été faits en n’en faisant varier
qu’un seul à la fois.
Pour chaque modification, au moins trois simulations ont été exécutées à cause de la
nature aléatoire de ces algorithmes. Dans certains cas un peu douteux (mesures avec une
très grande variance), des exécutions supplémentaires ont été faites, afin de lever le
doute.
Les algorithmes génétiques sont des méthodes non - déterministes, et cette composante
de hasard peut être configurée en modifiant plusieurs paramètres, comme par exemple le
taux de mutation. Ce non - déterminisme pose un certain problème lors des mesures des
résultats: on ne peut pas se baser uniquement sur une seule mesure pour pouvoir établir
une conclusion: il est indispensable d'en faire plusieurs pour pouvoir confirmer un résultat.
Pour cette exploration nous avons soumis à un programme qui utilise des algorithmes
génétiques plusieurs problèmes d'optimisation, avec comme objectif de trouver le
minimum (ou le maximum) global. Toutes ces fonctions ont des caractéristiques
particulière, qui les rendent intéressantes à soumettre à un algorithme génétique, car si on
les visualise graphiquement elles présentent un profile qui contient des pièges pour
l'algorithme (par exemple un minimum global perdu au milieu d'une multitude de minima
locaux).
Ces caractéristiques sont utilisées tous spécialement pour étudier les performances des
algorithmes en fonction des paramètres typiques des algorithmes génétiques (taux de
mutation, taille de la population, etc.).
1
Fonction qui présente plusieurs pics.
-3-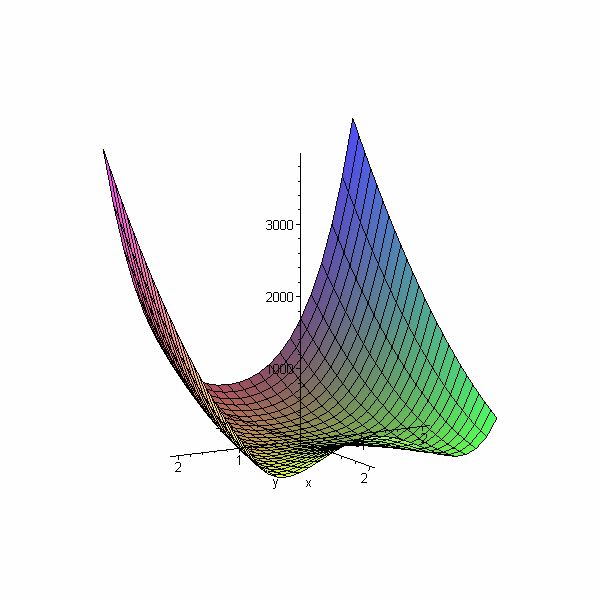
Machines adaptatives bio – inspirées avril 04
3. PREMIERS CONTACTS AVEC LES ALGORITHMES GENETIQUES
Grâce à ces simulations très visuelles, nous avons pu observer que les algorithmes
génétiques, pour une fonction d’adaptation donnée, ont tendance à trouver le maximum
global de la fonction, même si ce dernier est entouré de maxima locaux.
Ceci est visible sur les graphiques qui vont suivre.
3.1 Fonction d’adaptation 1
Paramètres
stringGeneLength=10;
mutationRate=0.03;
crossoverRate = 0.6;
populationSize=100;
numberOfGenerations=25;
elitism=True;
fitnessFunction=sin(π.x).sin(π.y).abs(sin(3.π.x).sin(3.π.y))
Intervalle : x ∈ [0, 1], y ∈ [0, 1]
Initial population Final population
1 1
0.75 0.75
0.5 0.5
0.25
0 0.25
0
10 10
0.75 0.75
0 0
0.25 0.5 0.25 0.5
0.5 0.5
0.25 0.25
0.75 0.75
1 0 1 0
Initial population Final population
1 1
0.8 0.8
0.6 0.6
0.4 0.4
0.2 0.2
0.2 0.4 0.6 0.8 1 0.2 0.4 0.6 0.8 1
Figure 1 : Résultat d’une simulation avec la fonction d’adaptation 1
Cette fonction présente un maximum global, ainsi que huit maxima locaux. La présence de
ces maxima rend la tâche particulièrement difficile à l’algorithme génétique, car selon la
distribution initiale de la population, il est possible qu’un maximum local soit confondu avec
le maximum global. Ceci peut arriver lorsque la population initiale se retrouve toute
-4-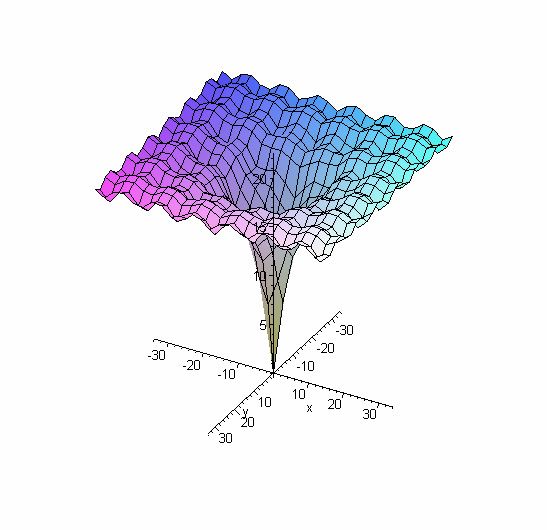
Machines adaptatives bio – inspirées avril 04
concentrée autour d’un maximum local.
Dans l’exemple de la Figure 1 on a une population initiale distribuée de manière assez
uniforme sur tout l’intervalle. Après 25 générations on voit très bien que une bonne partie
de la population est concentrée autour du maximum global. Il y a tout de même quelques
individus qui se retrouvent sur des maxima locaux.
3.2 Fonction d’adaptation 2
Paramètres
stringGeneLength=10;
mutationRate=0.03;
crossoverRate = 0.6;
populationSize=100;
numberOfGenerations=25;
elitism=True;
fitnessFunction= abs(sin(3.π.x).sin(3.π.y))
Intervalle : x ∈ [0, 1], y ∈ [0, 1]
Initial population Final population
1 1
0.75 0.75
0.5 0.5
0.25
0 0.25
0
10 10
0.75 0.75
0 0
0.25 0.5 0.25 0.5
0.5 0.5
0.25 0.25
0.75 0.75
1 0 1 0
Initial population Final population
1 1
0.8 0.8
0.6 0.6
0.4 0.4
0.2 0.2
0.2 0.4 0.6 0.8 1 0.2 0.4 0.6 0.8 1
Figure 2 : Résultat d’une première simulation avec la fonction d’adaptation 2
-5-Machines adaptatives bio – inspirées avril 04
Initial population Final population
1 1
0.75 0.75
0.5 0.5
0.25
0 0.25
0
10 10
0.75 0.75
0 0
0.25 0.5 0.25 0.5
0.5 0.5
0.25 0.25
0.75 0.75
1 0 1 0
Initial population Final population
1 1
0.8 0.8
0.6 0.6
0.4 0.4
0.2 0.2
0.2 0.4 0.6 0.8 1 0.2 0.4 0.6 0.8 1
Figure 3 : Résultat d’une deuxième simulation avec la fonction d’adaptation 2
Cet exemple est très similaire à celui précédant, avec l’exception qu’il n’y a pas de
maximum global. Il y a uniquement 9 maxima locaux, tous identiques.
La population initiale est à nouveau uniformément distribuée sur l’espace de recherche
considéré, mais après 25 générations on peut remarquer que dans les deux simulations
les maxima choisis par l’algorithme ne sont pas les mêmes. Le choix des pics est
essentiellement aléatoire et varie d’une exécution à l’autre.
Ce comportement est dû au fait qu’il n’y a pas de maximum global vers lequel la
population peut se concentrer, et que les différents maxima locaux ont tous la même
valeur, donc ils ont tous la même chance d’être sélectionnés.
-6-Machines adaptatives bio – inspirées avril 04
4. ETUDE DE FONCTIONS MULTI – MODALES
4.1 Fonction de Ackley
La fonction de Ackley en 3 dimensions présente un seul minimum global comme montré
sur la figure suivante :
> plot3d(20+exp(1)-20*exp(-0.2*sqrt(0.5*(x^2+y^2)))-
exp(0.5*(cos(2*Pi*x)+cos(2*Pi*y))), x=-32.768..32.768, y=-
32.768..32.768);
Figure 4 : Fonction de Ackley
La fonction de Ackley (qui représente un problème de minimisation) ne présente pas de
difficultés particulières pour les algorithmes génétiques, car elle possède qu’un seul
minimum, qui est très prononcé.
-7-Machines adaptatives bio – inspirées avril 04
4.2 Fonction de Rosenbrock
La fonction de Rosenbrock en 3 dimensions a comme résultat une espèce de vallée
parabolique, très étroite, avec un fond presque plat, comme montré sur la figure suivante:
> plot3d((1-x)^2+100*(y-x^2)^2, x=-2.048..2.048, y=-2.048..2.048);
Figure 5 : Fonction de Rosenbrock
Il est assez aisé de se retrouver sur le fond de la vallée, mais la recherche de l'optimum
global est difficile à cause du fond plat, qui a tendance à créer des individus très similaires.
Ceci a comme effet que les croisements entre individus peuvent ne pas être suffisant pour
s'approcher de l'optimum: les mutations sont les seuls opérateurs génétiques qui peuvent
encore aider à s'approcher du minimum optimal.
Le fond de la vallée étant très régulier, et qui ne présente pas de problèmes de minima
locaux, cette fonction est utile pour tester la précision du résultat obtenu et les
performances de l’algorithme.
-8-Machines adaptatives bio – inspirées avril 04
4.3 Fonction de Schwefel
> plot3d(2*418.9829+(-x*sin(sqrt(abs(x))))+(-y*sin(sqrt(abs(y)))),
x=-500..500, y=-500..500);
Figure 6 : fonction de Schwefel
Cette fonction est particulière, car le minimum global est plutôt éloigné (du point de vue
géométrique) du meilleur minimum local. Il est donc clair que les algorithmes génétiques
auront une forte tendance à se tromper de minimum et donc de converger dans la
mauvaise direction. Pour ce genre de fonction, une recherche en contemporaine dans
plusieurs zones de l’espace du domaine est la méthode à privilégier, pour éviter de se
retrouver bloqués dans l’optimum local. La meilleure méthode pour élargir le champ de
recherche est d’augmenter le nombre d’individus de la population initiale.
-9-Machines adaptatives bio – inspirées avril 04
4.4 Fonction de Griewank
La fonction de Griewank présente plusieurs minima locaux étalés sur tout le domaine, qui
sont uniformément distribués.
> plot3d(1/4000*(x^2+y^2) - (cos(x)/sqrt(1))*(cos(y)/sqrt(2)) + 1,
x=-60..60, y=-60..60);
Figure 7 : Fonction de Griewank
-10-Machines adaptatives bio – inspirées avril 04
5. ETUDE DE FONCTIONS D’OPTIMISATION
Les deux fonctions d’optimisation que nous avons considéré (le modèle de la sphère et un
problème simple de minimisation d’une variable) ne présentent aucun piège particulier
pour un algorithme génétique : se sont deux fonctions (une en trois dimensions et l’autre
en deux) régulières, sans plusieurs maxima (ou minima) locaux : en effet il n’y a que une
seule solution locale, qui est aussi la solution globale.
Nous les représentons ci-dessous, pour constater qu’elles sont effectivement régulières.
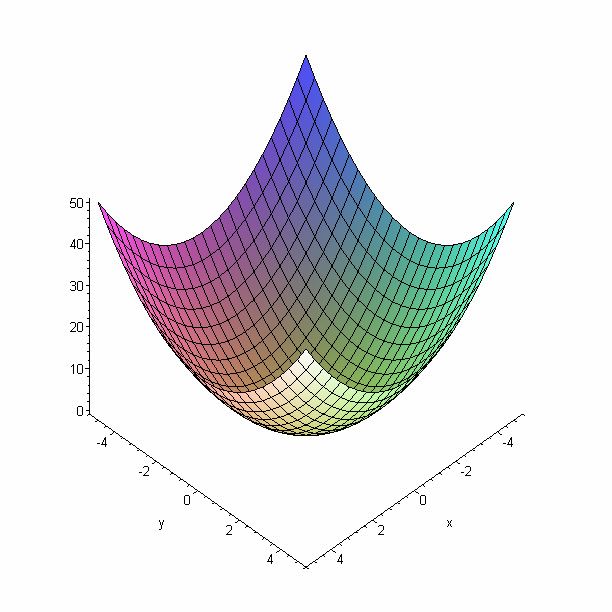
5.1 Le modèle de la sphère
> plot3d(x^2+y^2, x=-5..5, y=-5..5);
Figure 8 : le modèle de la sphère
-11-Machines adaptatives bio – inspirées avril 04
5.2 Minimisation d’une seule variable
> plot(x^4-12*x+15*x^2+56*x-60, x=-10..10);
Figure 9 : Minimisation d’une seule variable
-12-Machines adaptatives bio – inspirées avril 04
6. DISCUSSION DES RESULTATS OBSERVES
Effets sur l’évolution si on change la taille de la population
La modification de la taille de la population a une très grande influence sur le résultat final:
en effet d'après les observation faites, plus la population est grande, plus le résultat est
proche de l'optimum et plus la vitesse de convergence est élevée (en terme de nombre de
générations). Cette observation a été faite en fixant un plafond maximum de générations
permises pour ce jeu de paramètres, et une fois ce plafond atteint, les résultats (en
particulier la valeur de f(x)) ont étés notés afin de les comparer.
Afin d'expliquer ce phénomène, il faut se rendre compte que la population initiale est
constituée d'individus pris au hasard, donc distribués de manière aléatoire dans l'espace
des solutions du problème. Plus il y a d'individus, plus il y a de chances qu'un nombre
élevé se trouve près de la solution optimale (les individu les meilleurs se trouvent toujours
près de l'optimum). Les porteurs de gènes optimaux ont plus de chance de se retrouver à
la prochaine génération, donc de contribuer encore à la recherche de l'optimum.
Dans les cas de fonctions présentant un maximum (ou un minimum) global et un ou
plusieurs maximum (ou minimum) local, ceci peut être important, car avec une population
trop petite il est possible qu'elle se retrouve toute centrée autour d'un optimum local, et
qu'il soit donc difficile qu'elle se déplace autour de l'optimum global. Avec une population
plus grande, grâce à son étalement sur toute la surface des solutions, on a plus de
chances que certains individus se trouvent près de l'optimum global, et que donc on
obtienne effectivement le résultat cherché grâce à l’évolution de ces individus.
Si on utilise une population trop petite, seulement une petite partie de l'espace de
recherche sera explorée, ce qui ne garantie pas qu'on trouvera la solution optimale
(surtout dans le cas des fonctions multi - modales: un optimum local pourrait être pris pour
l'optimum global!). Mais utiliser une très grande population n'aide pas à trouver la solution
plus rapidement en terme de temps de calcul, bien au contraire! Plus la population est
grande, plus l'algorithme sera lent, car il devra effectuer toutes les étapes (sélections,
croisements, mutations) sur beaucoup d'individus! Il faut donc trouver le juste milieu! Les
valeurs souvent prises se situent entre 20 et 100 individus.
Exemple : fonction de Schwefel
Paramètres
Exit tolerance : 0.5
Population Size : 10
Number of genes : 10
Survivor percent : 20
Mutation rate : 0.05
f(x) Current generation Function calls
90.5897048 1123 11762
53.9080658 1042 10852
64.7441463 1083 11232
-13-Machines adaptatives bio – inspirées avril 04
Paramètres
Population Size : 30
f(x) Current generation Function calls
4.6134764 1082 34440
2.2436864 1081 34500
6.4987575 1055 33692
2.0313211 1070 33932
Paramètres
Population Size : 100
f(x) Current generation Function calls
0.4878036 742 78302
0.2137699 903 95302
0.1567759 852 90202
Paramètres
Population Size : 500
f(x) Current generation Function calls
0.4048841 167 85002
0.4423003 133 67002
0.4693474 221 112502
0.4764155 198 100502
Paramètres
Population Size : 1000
f(x) Current generation Function calls
0.2867090 98 99002
0.4969229 139 140002
0.4884985 97 98002
0.4984392 97 98002
0.4980498 140 141002
Avec ces données on peut voir que effectivement avec une taille de population réduite (10
individus), f(x) est éloignée de l’optimum, mais dès que l’on a une population plus
importante on s’approche du résultat optimal.
Considérons par exemple le cas de la population de 100 individus et celle de 1000
individus : le résultat de f(x) est assez similaire dans les deux cas, mais si on observe le
nombre d’appels aux fonctions génétiques (colonne « Function calls ») on s’aperçoit que
avec la très grande population il y a une tendance a faire plus d’appels, ce qui ralenti
l’algorithme, pour obtenir le même résultat !
Effets sur l’évolution si on change la dimension du problème
La dimension du problème (donc le nombre de gènes par individu) a aussi une grande
influence sur la rapidité avec laquelle on converge vers l'optimum de la fonction. En effet
plus la dimension du problème est élevée, plus l’algorithme a de la peine pour trouver un
-14-Machines adaptatives bio – inspirées avril 04
résultat optimal, car il doit trouver le meilleur gène dans toutes les dimensions
simultanément.
Comme exemple pour clarifier l’impact de la dimension, considérons le cas en une
dimension (1 seul gène) : l’algorithme doit trouver la valeur optimale f(x) pour un seul x, ce
qu’il arrive a faire en un certain temps. Considérons ensuite la même fonction d’adaptation
mais en cinq dimensions : l’algorithme doit maintenant trouver la valeur optimale pour cinq
gènes en même temps, ce qui naturellement prend plus de temps par rapport aux cas de
dimensions plus petites.
Exemple : fonction de Griewank
Paramètres
Exit tolerance : 0.5
Population Size : 30
Number of genes :1
Survivor percent : 20
Mutation rate : 0.05
f(x) Current generation Function calls
0.1264520 1 62
0.110852 1 62
0.0196584 47 1562
Paramètres
Number of genes :2
f(x) Current generation Function calls
0.3848217 14 482
0.4319212 31 1022
0.2711461 56 1802
Paramètres
Number of genes :5
f(x) Current generation Function calls
0.4714119 202 6482
0.4297878 111 3512
0.4949321 59 1862
Paramètres
Number of genes : 15
f(x) Current generation Function calls
1.1124772 1082 33272
1.1032210 1076 33332
1.0583229 1042 32222
Une tendance observée est que plus la dimension est réduite, plus rapidement on arrive à
l'optimum, tandis qu’avec un nombre élevé de gènes (15 dans nos simulations) la vitesse
de convergence vers l’optimum est assez lente.
-15-Machines adaptatives bio – inspirées avril 04
Effets sur l’évolution si on change le pourcentage de survivants
Le pourcentage de survivants correspond au phénomène d’élitisme, qui est un facteur très
important pour l’optimisation de la rapidité des algorithmes génétiques. En effet ce
pourcentage correspond au nombre d’individus de la génération précédente que l’on
retrouvera dans la prochaine : les individus choisis seront les meilleurs, donc ceux avec le
fitness plus élevé.
Exemple : fonction de Ackley
Paramètres
Exit tolerance : 0.5
Population Size : 30
Number of genes : 10
Survivor percent :0
Mutation rate : 0.05
f(x) Current generation Function calls
5.5446486 1082 32610
3.7368975 1076 32432
4.3572295 1077 32492
Paramètres
Survivor percent : 20
f(x) Current generation Function calls
1.2600556 1084 34500
1.1653655 1064 33572
1.0128672 1046 33002
1.2311506 1094 34262
Paramètres
Survivor percent : 50
f(x) Current generation Function calls
0.5140941 1071 34052
0.4391679 710 22532
0.4890741 1025 32312
Paramètres
Survivor percent : 80
f(x) Current generation Function calls
1.5129791 1076 34262
0.5910729 1085 34772
1.3433241 1077 34052
-16-Machines adaptatives bio – inspirées avril 04
Paramètres
Survivor percent : 100
f(x) Current generation Function calls
17.4312822 1046 34260
17.9354659 1068 34980
17.5463736 1086 35552
Après ces simulations, on voit clairement que si on désactive le mécanisme d’élitisme
(donc Survivor percent = 0) le résultat est loin de l’optimum et la vitesse de convergence
est lente, car à chaque nouvelle génération il faut recréer une nouvelle population
aléatoirement.
En incrémentant cette valeur à 20% ou à 50%, on peut observer que l’on obtient des
résultats plus proches de la valeur optimale, et ceci assez rapidement. Par contre dès que
l’on augmente trop le facteur d’élitisme (80% ou 100%), on obtient l’effet contraire : ça a
tendance à dégrader la population (et donc le résultat), car on garde tous les individus,
même ceux avec un fitness bas. Ceci naturellement influence les générations suivantes,
qui n’arriveront pas à s’améliorer, car elles partent d’une population de base trop
mauvaise.
Effets sur l’évolution si on change le taux de mutation
La désactivation de l’opérateur de mutation n’a pas de grande influence sur les résultats,
car il a une probabilité très basse de modifier les gènes. L’impact de cet opérateur est plus
marqué sur une grande population, étant donné que la probabilité qu’une mutation soit
faite est plus grande que sur une population réduite.
Exemple : Modèle de la sphère
Paramètres
Exit tolerance : 0.001
Population Size : 30
Number of genes :5
Survivor percent : 20
Mutation rate :0
f(x) Current generation Function calls
0.0013500 1099 35762
0.0013100 1058 34502
0.0006750 677 21962
0.0006890 1050 34232
Paramètres
Mutation rate : 0.03
f(x) Current generation Function calls
0.0007150 370 11882
0.0005800 474 15242
0.0003600 510 16382
-17-Machines adaptatives bio – inspirées avril 04
Paramètres
Mutation rate : 0.1
f(x) Current generation Function calls
0.0008550 526 16962
0.0009200 1052 33092
0.0008120 547 17162
Paramètres
Mutation rate : 0.5
f(x) Current generation Function calls
0.0230830 1069 33542
0.0634400 1066 33422
0.1001740 1082 33932
0.0473710 1050 32792
Paramètres
Mutation rate :1
f(x) Current generation Function calls
0.7007990 1060 33662
0.8684170 1075 34112
1.1158610 1060 33662
D’après les résultats de l’expérience il est évident que l’opérateur mutation est un
paramètre secondaire dans un algorithme génétique : en effet si on considère le cas avec
un taux de 0.03 et celui avec 0.1 on ne remarque pas de très grande différence tant dans
les résultats que dans la vitesse de convergence, et ce malgré une multiplication par un
facteur 3 de ce paramètre!
Pour ce paramètre aussi il est inutile de l’augmenter de manière démesurée : en effet la
dernière simulation, avec le taux de mutation de 1, montre clairement que les résultats se
sont dégradés par rapport aux valeurs considérées optimales que sont celles comprises
dans la fourchette 0.01 – 0.1.
En effet cela reflète de manière réaliste le fonctionnement de la nature, où les mutations
sont des évènements très rares (donc avec une probabilité basse) : il est effectivement
rare que tous les gènes mutent en même temps, tel qu’il serait le cas avec un taux de
mutation de 1.
-18-Machines adaptatives bio – inspirées avril 04
7. CONCLUSION
On a pu observer que malgré le caractère non - déterministe des algorithmes génétiques
ils étaient tout de même efficaces pour trouver les solutions optimales! Mais pour que leur
efficacité soit maximale il faut choisir de manière intelligente les paramètres en
considérant les caractéristiques de la fonction d’adaptation, car sinon on risque d'avoir un
résultat complètement faux. Mais en se basant sur des observations de la nature on peut
déjà trouver des valeurs raisonnables, qui permettent d’obtenir de bon résultats.
Dans le cas du piège des fonctions multi - modale, la méthode marche là aussi
étonnamment bien: souvent l'optimum global est trouvé!
L'immense avantage de ces algorithmes est qu'ils sont applicables à beaucoup de
situations et qu'ils sont assez rapides aussi! Souvent la méthode bio - inspirée produit des
résultats plus rapidement que les méthodes analytiques, ce qui est tout à fait remarquable
si on considère la relative simplicité de l'algorithme et son utilisation du hasard pour
converger vers la solution!
-19-Vous pouvez aussi lire

















































