ÉLECTION PRÉSIDENTIELLE FRANÇAISE DE 2022. REPRÉSENTER L'INCERTITUDE DANS LES INTENTIONS DE VOTE POUR LE 1ER TOUR : UNE GAGEURE ?
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Note de recherche Mars 2022 ÉLECTION PRÉSIDENTIELLE FRANÇAISE DE 2022. REPRÉSENTER L’INCERTITUDE DANS LES INTENTIONS DE VOTE POUR LE 1 ER TOUR : UNE GAGEURE ? Diégo Antolinos-Basso Pierre-Henri Bono Développeur Data Mining / Modélisation Économètre diego.antolinosbasso@sciencespo.fr ph.bono@sciencespo.fr Frédérik Cassor Flora Chanvril Assistant Ingénieur CNRS / Statisticien Chargée d’études statistiques frederik.cassor@sciencespo.fr flora.chanvril@sciencespo.fr Nicolas Sormani Ingénieur d’études CNRS nicolas.sormani@sciencespo.fr La présente note illustre la problématique du calcul et de la représentation des marges d’erreur dans la mesure des opinions faite par sondage, grâce à l’Enquête électorale française disponible au CEVIPOF et menée actuellement pour l’élection présidentielle française de 2022. Comment mesure-t-on les intentions de vote dans l’Enquête électorale française ? Depuis 2015, le CEVIPOF mène, en partenariat avec Ipsos, la Fondation Jean- Jaurès et le journal Le Monde, des enquêtes électorales longitudinales sur grands échantillons. Ce dispositif d’enquêtes, appelé Enquête électorale française (EnEF), a pour but de mieux comprendre les processus de décision du vote et répond à diverses questions complémentaires en fonction du contexte de chaque élection.
Pour les élections présidentielle et législatives françaises de 2022, l’EnEF repose sur 12 vagues d’enquête, comportant chacune entre 12 000 et 16 000 individus, dont certains peuvent être interrogés plusieurs fois durant 15 mois. La 1ère vague a eu lieu un an avant les élections, soit en avril 2021, et la vague la plus récente disponible à ce jour remonte au mois de mars 2022 (vague 7). La sélection des individus pour obtenir un échantillon représentatif de la population se fait à partir de l’Access Panel Online d’Ipsos pour les personnes âgées de 18 ans et plus inscrites sur les listes électorales et repose sur la méthode des quotas : sexe/âge, profession, catégorie d’agglomération et région de résidence de la personne interrogée. Dit autrement, pour chacune des catégories sociodémographiques précédentes, l'échantillon tente de mimer les caractéristiques de la population française âgée de 18 ans et plus inscrite sur les listes électorales. Les interrogations se font par Internet, sans intervention d’un enquêteur. Une pondération est appliquée aux résultats que l’on obtient et prend en compte non seulement les caractéristiques sociodémographiques précédentes, mais aussi les résultats du premier tour de l’élection présidentielle française de 2017 et ceux des élections européennes de 2019. Cela signifie que chaque individu interrogé possède un poids particulier pour que l’échantillon puisse correspondre parfaitement à la fois aux distributions sociodémographiques de la population française indiquée ci-dessus, et aux résultats obtenus lors des deux élections mentionnées plus haut. Par exemple, pour l’échantillon de la dernière vague en date, la vague 5, nous observons dans la base brute 18,9% de répondants qui se déclarent employés ; nous devons alors appliquer une pondération pour obtenir la cible de 17,1% qui correspond à la population de référence. De la même manière, nous redressons notre échantillon pour retrouver exactement les résultats des dernières élections présidentielle et européennes. Parmi les nombreuses questions posées de l’EnEF, figure celle des intentions de vote au 1er tour de l’élection présidentielle de 2022, ainsi formulée aux interviewés : « Si le 1er tour de l’élection présidentielle avait lieu dimanche prochain, quel est le candidat pour lequel il y aurait le plus de chances que vous votiez au 1er tour, je dis bien au 1er tour ? ». Dans le détail, les pourcentages d’intention de vote sont calculés à partir des réponses des interviewés qui se déclarent être certains d’aller voter. Cette certitude d’aller voter est mesurée par une autre question posée juste avant celle de l’intention de vote déclarée pour tel ou tel candidat et est posée de la manière suivante : « Si le 1er tour de l’élection présidentielle avait lieu dimanche prochain, pouvez-vous donner une note de 0 à 10 sur votre intention d’aller voter dimanche prochain ? 0 signifiant que vous êtes vraiment tout à fait certain de ne pas aller voter et 10 que vous êtes vraiment tout à fait certain d’aller voter ». À partir de ces deux questions, les intentions de vote des répondants sont construites pour chaque vague uniquement sur les personnes certaines d’aller voter pour un candidat. En d’autres termes, ce sont les pourcentages sur les exprimés sûrs d’aller voter.
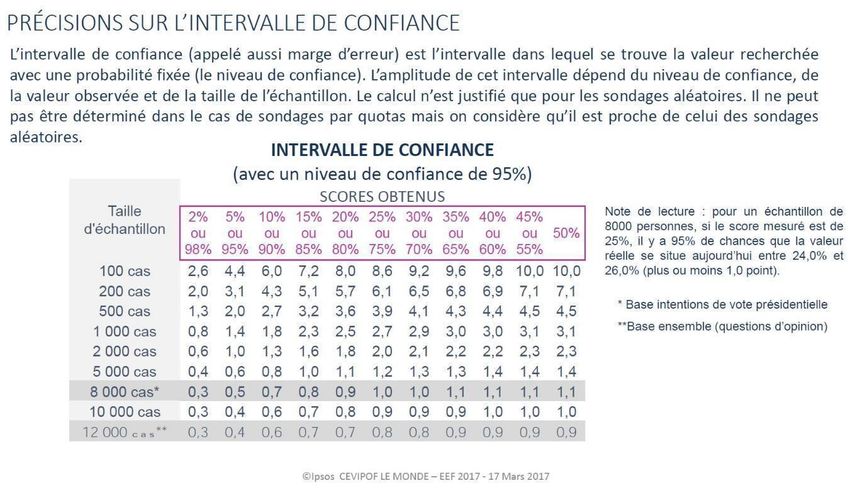
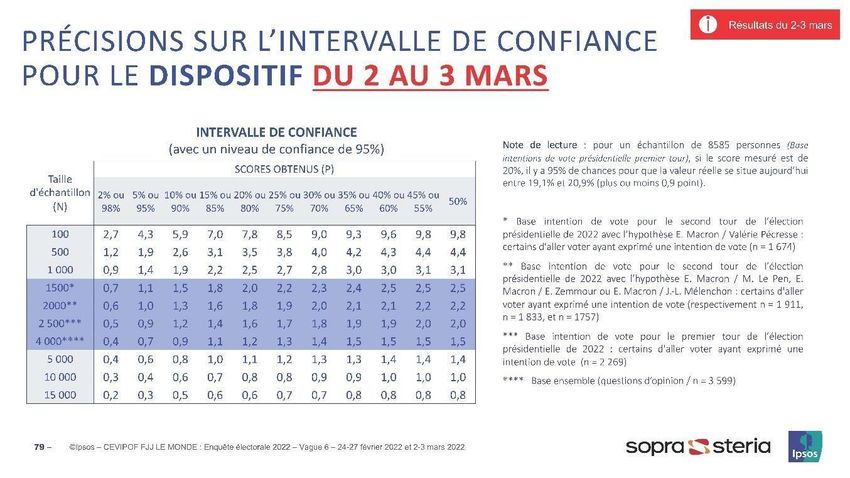
Partie 1 : Incertitude et cadrage juridique autour de la mesure des intentions de vote Cependant, l’aléa de la mesure statistique des intentions de vote aux élections, pourtant essentiel pour saisir la portée des sondages et les nuances à donner à 1. l’interprétation de leurs résultats, est relativement peu commenté et ses https://www.sciencespo.fr/cev répercussions sur les intentions de vote encore relativement peu expliquées ipof/fr/content/lenquete- electorale-francase-2022-enef- dans la plupart des media à destination du grand public. Concernant l’EnEF1, les 2022.html marges d’erreur apparaissent progressivement dans les rapports publics donnant à voir les résultats, et ces informations sont enrichies au fil des vagues 2. successives. Voir le site Internet de la Commission des sondages à Depuis 1977, il existe en France une Commission des sondages2 chargée de l’adresse suivante : www.commission-des- faire respecter la loi qui encadre la publication ou la diffusion des sondages sondages.fr électoraux, notamment les métadonnées documentant le sondage ou la vérification du respect de l’interdiction de publication de sondages électoraux 3. juste avant le scrutin. Une loi de 20163 oblige à publier les marges d’erreur des Loi n°2016-508 du 25 avril sondages d’opinion et son article 2 dispose ainsi : 2016 de modernisation de diverses règles applicables aux « La première publication ou la première diffusion de tout sondage […] est élections, qui modifie la loi accompagnée des indications suivantes, établies sous la responsabilité de n°77-808 du 19 juillet 1977 l'organisme qui l'a réalisé : [...] (6) une mention précisant que tout sondage est affecté de marges d'erreur ; (7) les marges d'erreur des résultats publiés ou diffusés, le cas échéant par référence à la méthode aléatoire ; [...] » La Commission des sondages demande que ces informations concernant les marges d’erreur soient rendues publiques lors de la première publication du sondage, et qu’elles fassent partie de la notice publique disponible en ligne. Se pose alors la question de savoir comment transmettre cette information supplémentaire des marges d’erreurs en conjonction avec les intentions de vote. Différentes solutions ont été présentées par les instituts de sondage et les organes de presse. Si tous les instituts présentent un tableau de correspondance entre la taille de l’échantillon et la valeur de l’intention pour avoir une idée de la marge d’erreur, le report de cette information dans leur infographie ou leurs tableaux de résultats reste très marginal. Dans un cadre statique (une seule vague d’enquête), les instituts de sondage optent principalement pour un tableau de valeurs dans leur document de référence technique (Cf encadré 1 en annexe). Si cela a le mérite de mieux tenir compte de la réglementation dont l’application est surveillée par la Commission des sondages, cela n’exempte malheureusement pas, en revanche, le lecteur de nombreux calculs mentaux, voire d’erreurs potentielles, si ce dernier souhaite par exemple évaluer la proximité entre plusieurs candidats dont les intentions de vote sont généralement représentées dans un autre schéma, sous la forme d’un diagramme en barres horizontales (Cf encadré 3 en annexe). En conséquence, il nous semble intéressant de rechercher une représentation graphique qui ferait apparaître à la fois de manière comparative et de manière dynamique, la marge d’erreur dans les intentions de vote. L’objectif visé serait de pouvoir lire clairement les intentions de vote elles-mêmes, tout en gardant une lecture plus prudente et plus rigoureuse, afin de se prémunir contre les incompréhensions, les raccourcis malheureux dans les interprétations ou les comparaisons des résultats eux-mêmes. 3
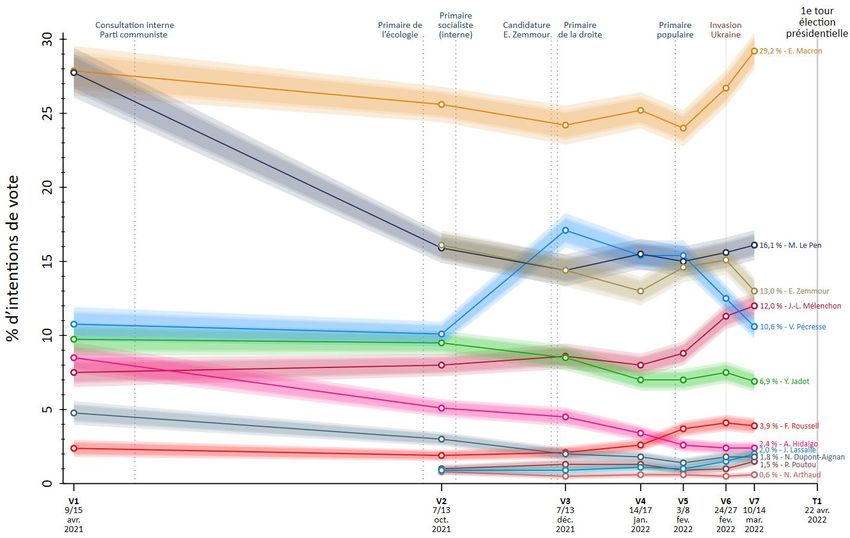
Partie 2 : Une représentation graphique plus juste des intentions de vote mesurées et de l’incertitude autour de cette mesure Graphique 1. Évolution des intentions de vote avec marges d’erreur Note de lecture : les points représentent, pour chaque candidat retenu, les intentions de vote des répondants sûrs d’aller voter ; ces intentions sont redressées par les caractéristiques sociodémographiques des répondants, les résultats du premier tour de l’élection présidentielle française de 2017 et ceux du premier tour des Européennes de 2019. Le gradient de couleur observable autour des points et des courbes représente les intervalles de confiance des intentions de vote, à 90% de probabilité pour le plus intense, à 95% pour celui d’intensité moyenne, et enfin à 99% pour celui le moins intense. Source : Ipsos - CEVIPOF - Fondation Jean-Jaurès - Le Monde : Enquête électorale 2022 - Vagues 1 à 7 Dans cette partie, nous nous demandons comment l’ajout des marges d’erreur à la représentation des résultats des intentions de vote peut influencer la lecture de ces résultats. Pour illustrer notre propos, nous proposons un graphique qui compare les résultats des sondages pour le 1er tour de l’élection présidentielle française de 2022 à la fois entre les candidats et au fil du temps, tout en tenant compte des marges d’erreur associées à ces intentions de vote. (1) Comparaison entre candidats : pour une vague donnée d’enquête, et pour chaque candidat déclaré ou potentiel au 1er tour de cette élection, le graphique affiche le pourcentage d’intention de vote ainsi que trois marges d’erreur (à 90%, 95% et 99% de probabilité ou seuil de confiance) - représentées par des bandes colorées plus ou moins intenses en fonction du niveau de la probabilité (ou du risque) - associées à cette mesure de l’enquête (Cf encadré 3 en annexe pour les formules de calcul de ces marges d’erreur).
Comment interpréter les marges d’erreur ? Une marge d’erreur s’exprime en points de pourcentage autour de la mesure et permet d’établir un intervalle de 4. Nous reviendrons plus loin sur confiance autour de cette mesure. Théoriquement, pour un échantillon l’utilisation des calculs de aléatoire4 d’individus d’une population plus générale, la marge d’erreur à X% marge d’erreur sur des correspond à la probabilité d’être sûr à X% que la vraie valeur de l’intention de échantillons par quotas vote dans la population dont est issu l’échantillon se trouve dans l’intervalle [valeur estimée dans l’échantillon - marge d’erreur ; valeur estimée dans l’échantillon + marge d’erreur]. Il est d’usage courant de retenir comme risque ou seuil d’erreur de première espèce la valeur 5%, ce qui équivaut à une marge d’erreur à 95% de seuil de confiance : sous cette hypothèse, nous admettons alors que la vraie valeur de l’intention de vote parmi les électeurs se trouve dans l’intervalle, valeur estimée plus ou moins la marge d’erreur, et que nous avons 5% de chance de nous tromper en acceptant cet intervalle de valeurs autour de la valeur estimée dans l’échantillon comme comprenant la vraie valeur dans la population globale. Considérons par exemple le candidat Emmanuel Macron à la vague 3 de l’EnEF 2022. L’intention de vote qu’il récolte auprès de l’échantillon de Français interrogés et certains de leur choix vaut 24,2%. Ce résultat est entouré d’une incertitude que l’on évalue à l’aide de trois probabilités à l’instant de la 5. mesure5 : Les niveaux de confiance et quantiles « classiques » sont - premièrement, en décembre 2021, la vraie valeur de l’intention de vote pour les suivants : Emmanuel Macron a 90% de probabilité de se trouver dans l’intervalle [23,3% ; (1) niveau de confiance de 25,1%] ; dit autrement, il y aurait 10% de risque qu’elle ne se trouve pas dans 90%, soit un quantile / = cet intervalle de valeurs à la date de l’enquête ; , ; (2) niveau de confiance de - deuxièmement, en décembre 2021, la vraie valeur de l’intention de vote pour 95%, soit un quantile / = Emmanuel Macron a 95% de probabilité de se trouver dans l’intervalle [23,1% ; , ; 25,3%] ; dit autrement, il y aurait 5% de risque qu’elle ne se trouve pas dans cet (3) niveau de confiance de intervalle de valeurs à la date de l’enquête ; 99%, soit un quantile / = - troisièmement, en décembre 2021, la vraie valeur de l’intention de vote pour , ; (4) niveau de confiance de Emmanuel Macron a 99% de probabilité de se trouver dans l’intervalle [22,8% ; 99,9%, soit un quantile / = 25,6%] ; dit autrement, il y aurait 1% de risque seulement qu’elle ne se trouve , . pas dans cet intervalle de valeurs à la date de l’enquête ; Ainsi, vague après vague, il est possible de voir avec clarté sur ce schéma : la valeur de l’intention de vote telle que mesurée par l’enquête ; l’étendue de ses valeurs possibles pour un risque compris entre 1% et 10% en raison des aléas de mesure associés à l’outil de l’EnEF 2022 ; la position de chaque candidat par rapport aux autres nuancée par cette étendue du risque de mesure. (2) Comparaison dynamique dans le temps : entre deux vagues successives, il est également possible de relier les valeurs d’intentions de vote mesurées par chaque enquête du dispositif EnEF 2022 par une courbe continue, autour de 6. Un graphique de l’Insee laquelle sont représentées par dégradés de couleurs les intervalles de confiance présentant les prévisions de à 90%, 95% et 99% de probabilité contenant les valeurs que peut prendre cette croissance économique de intention de vote6. Cela donne à voir l’évolution dans le temps des valeurs des l’institut pour l’économie intentions de vote pour les candidats retenus par le dispositif, ainsi que les française a servi d’inspiration pour notre représentation (cf. changements de leurs positions respectives. Insee (2019)) Une lecture simple, brève et non partisane des résultats de la vague 7 de l’EnEF 2022, enrichie par la représentation des marges d’erreur appliquées aux intentions de vote, donne : (i) à la date de cette enquête : trois groupes de candidats se distinguent les uns des autres. 5
Le candidat qui a l’intention de vote la plus élevée est Emmanuel Macron (29,2%), et les intervalles de confiance de ce candidat sont distincts de ceux des candidats qui le suivent. Viennent ensuite, autour de 10-15% d’intentions de vote, trois « candidats de droite » et un candidat de gauche dont les pourcentages et intervalles de confiance sont proches et plus ou moins enchevêtrés, à savoir Marine Le Pen, Éric Zemmour, Jean-Luc Mélenchon et Valérie Pécresse. Les cinq principaux autres candidats, qui les suivent, ont des valeurs d’intentions de vote au-dessous de 10% et les marges d’erreur associées aux intentions de vote pour ces candidats sont disjointes des précédents ; (ii) entre la vague 5 et la vague 7 de cette enquête : les intentions de vote augmentent pour les candidats Emmanuel Macron, Marine Le Pen et Jean-Luc Mélenchon ; elles diminuent pour les candidats, Éric Zemmour et Valérie Pécresse. Quels changements d’interprétation induit l’ajout des marges d’erreur à la représentation graphique des intentions de vote par candidat ? Au-delà de la vision des rapports de force entre candidats et des évolutions dans le temps, le graphique ci-dessus apporte deux informations complémentaires notables : (1) le choix du seuil d’erreur a peu d’impact sur la représentation des intervalles de confiance avec un échantillon de taille conséquente comme EnEF ; (2) selon la vague d’enquête, il est impossible de discriminer statistiquement entre certains candidats, par exemple les « candidats de droite » lors de la vague 5. Prendre comme seuil de confiance pour la marge d’erreur le seuil de 99% (le plus contraignant et donc l’aire la plus large sur la représentation graphique), le seuil de 95% ou encore le seuil de 90%, ne change pas les interprétations issues des résultats obtenus avec l’une ou l’autre des marges correspondantes. En effet, le calcul des marges d’erreur tient compte de la taille de l’échantillon, et le dispositif EnEF dispose d’échantillons pour chaque vague de tailles relativement importantes. Or, pour que deux valeurs d’intention de vote soit statistiquement différentes au seuil choisi pour la marge d’erreur, cela signifie graphiquement que le point d’un candidat ne se retrouve pas dans l’aire de la marge d’un autre. Il convient maintenant de s’interroger sur les fondements théoriques de la démarche qui a conduit à cette représentation. Partie 3 : Comment sont calculées les marges d’erreur dans les sondages d’opinion et quelle est leur crédibilité scientifique ? Un sondage est un exercice plutôt simple : comment connaître l’opinion d’une population à partir d’un nombre restreint d’individus ? Ce passage de la population à un échantillon nécessite de suivre un certain nombre de règles dictées par la statistique. En effet, se sont développés au fil du temps tout un ensemble d’outils permettant de faire de l’inférence, c’est-à- dire d’obtenir de l’information sur une population globale à partir d’un groupe d'individus « bien » choisis. Ce socle théorique statistique permet de sélectionner un échantillon représentatif de la population qui nous intéresse puis d’en inférer des
conclusions sur cette population initiale. Un concept important est à la base de cette théorie : le caractère aléatoire. Si l’on tire de manière aléatoire, c’est-à- dire au hasard, un nombre suffisant d’individus d’une population, les caractéristiques de ce groupe, en particulier ses opinions politiques pour un sondage politique, seront proches de celles de l’ensemble de la population. Par exemple, si l’on choisit de manière purement aléatoire 100 étudiants d’une université qui en compte 15 000, et que l’on mesure le poids moyen de chaque étudiant dans cet échantillon, cette moyenne de poids pour 100 étudiants sera très proche de la moyenne des poids de l’ensemble des 15 000 étudiants. Et plus la taille de l’échantillon augmente, plus l’erreur, autrement dit l’écart entre le poids moyen mesuré dans l’échantillon et le poids moyen réel de la population, aura de chance d’être faible, pour devenir quasiment nulle quand on se rapproche de la taille de la population initiale. Ce résultat n’est autre que la loi des grands nombres en mathématiques : lorsque la taille de l’échantillon converge vers la taille de la population, la moyenne des valeurs d’une variable de l’échantillon converge vers la vraie valeur prise par la variable dans l’ensemble de la population. La loi des grands nombres assure ainsi qu’un échantillon aléatoire est une bonne approximation de la population. Une autre loi fondamentale de la statistique appelée le théorème central limite permet également de calculer des marges d’erreurs. En effet, quel que soit le phénomène statistique que nous étudions, nous savons par avance comment va se comporter la distribution des moyennes d’échantillon. Donc pour un échantillon particulier, il suffit de comparer sa moyenne à la distribution d’échantillonnage théorique et si elle est proche de la moyenne théorique : « Supposons que l’on cherche à mesurer une moyenne ou une proportion à l’aide d’un échantillon constitué de façon aléatoire. Supposons encore que l’on a tiré tous les échantillons possibles à partir d’une même population de référence […] et que l’on a calculé pour chacun de ces échantillons la valeur correspondante pour la moyenne ou la proportion recherchée. Alors, la distribution de l’ensemble de ces mesures, que l’on appelle communément la distribution d’échantillonnage, suit une loi normale […] centrée sur le paramètre (moyenne ou proportion) que l’on cherche à mesurer. Cette propriété est centrale dans 7. l’optique de pouvoir ensuite inférer les résultats obtenus à la population de Chanvril, Flora et Le Hay, référence7 ». Viviane (2014) En se fondant sur les deux théorèmes ci-dessus, il est alors possible de calculer rigoureusement des marges d’erreur et des intervalles de confiance dans le cas de sondages aléatoires, selon des formules précises comme celles présentées dans l’encadré 3 (Cf annexe). Toutefois, en ce qui concerne les sondages d’opinion, la question se pose de savoir s’il est juste et fondé théoriquement de chercher à calculer et représenter graphiquement les marges d’erreur dans la mesure des intentions de vote, et plusieurs arguments s’opposent sur les réponses académiques à y apporter. D’un côté, certains arguments plaident pour ne pas prendre en compte l’aléa de mesure, ni chercher à en tirer du sens, parce qu’il est impossible d’appliquer parfaitement la théorie des sondages aléatoires à la pratique des enquêtes d’opinion. 7
En effet, la théorie des sondages probabilistes suppose l’absence de tout biais, ou au moins la parfaite connaissance quantitative de ceux-ci pour pouvoir calculer à partir de la loi normale les bornes des intervalles de confiance 8. contenant les valeurs possibles de la variable mesurée, pour une probabilité Ardilly, P. (2010) : « ces calculs connue ou un risque donné8. En résumé, « sans échantillons aléatoires, les [de mesure de l’erreur marges d’erreurs classiquement calculées par la statistique sont peu d’échantillonnage] […] négligent le biais (sans ce parti utilisables9» ou encore « seul un échantillonnage aléatoire « contrôlé », en un pris, il n'y a pas d'intervalle de sens que l’on précisera, offre une justification théorique rigoureuse aux confiance possible), d'autre enquêtes par sondage10 » et au calcul des marges d’erreur qui en découlent. part, ils résultent bien d'une assimilation à un Or, cela n’est pas vérifié dans le cas des enquêtes répétées du dispositif de échantillonnage probabiliste » l’EnEF 2017 ou de 2022 : compte-tenu des informations reçues de l’institut de 9. sondage chargé de mener l’enquête sur le terrain, il semble illusoire de penser Bar-Hen, A. et Chiche, J. (2009) que la répartition des réponses des membres du panel concernant leurs intentions de vote au 1er tour des élections suive une loi normale. Car la 10. Deville, J.-C. (2006) sélection des membres du panel de répondants est biaisée et n’obéit pas à un échantillonnage probabiliste pur11. 11. Parmi les biais possibles dans D’un autre côté, certains chercheurs, parfois les mêmes, soutiennent le principe une enquête, l’on peut citer de calculer et de diffuser les marges d’erreur dans les enquêtes, comme P. Weisberg, H.F. (2005), qui en identifie de nombreux, comme Ardilly, selon lequel « L'intention de mesurer et de diffuser l'erreur l’erreur d’échantillonnage, d'échantillonnage est très louable et doit être encouragée12». P. Ardilly, en 2013 l’erreur de couverture, la non- cette fois dans Statistique et Société, explique plus en détail : réponse totale ou partielle, « En pratique, on trouve des intervalles de confiance publiés à l’occasion de l’erreur de mesure due aux répondants ou aux sondages empiriques, électoraux ou portant sur d’autres thèmes. Il faut être enquêteurs, l’erreur de clair sur le sens de ces calculs : d’une part ils négligent le biais, d’autre part ils traitement, l’erreur liée au résultent nécessairement d’une assimilation de l’échantillonnage pratiqué à un mode de recueil, ou encore échantillonnage probabiliste. L’auteur de ces lignes peut accepter cette façon l’erreur de comparaison de procéder dans certaines circonstances, mais considère qu’elle reste 12. largement conditionnée à la maîtrise technique et opérationnelle du processus Ardilly, P. (2010) d’enquête, laquelle est par nature très dépendante du degré de professionnalisme de la structure qui en a la responsabilité13». Autrement dit, 13. utiliser les marges d’erreur dans un cadre non aléatoire : oui, à condition de Ardilly, P. (2013) travailler « proprement ! ». Le calcul de la marge d’erreur n’est, en théorie mathématique, possible que dans un cadre strictement aléatoire. Or, cela est impossible à réaliser dans la pratique, parce qu’il n’existe aucune base de sondage nationale accessible pour tirer aléatoirement les électeurs à qui l’on demande de répondre aux sondages d’opinion. C’est pourquoi, présenter ces marges d’erreur hors de leur cadre conceptuel d’origine, au-delà d’une note de bas de page ou d’une annexe de présentation de résultats d’enquête comme le fait notre graphique, permet de montrer que dans tout sondage subsiste un degré d’incertitude autour des résultats publiés et donc de faire preuve de transparence. Si cet usage ne fait pas totalement consensus dans la communauté scientifique, il reste néanmoins requis selon la Commission des sondages et permet aux utilisateurs et lecteurs des résultats d’enquêtes de garder à l’esprit un élément très important nécessaire à une interprétation plus juste des intentions de 14. vote : un sondage n’est pas et ne sera jamais une prédiction du résultat du Chanvril, F. (2022) scrutin14 !
Cette marge d’erreur permet aussi d’expliquer pourquoi il arrive parfois que deux sondages d’opinion publiés le même jour semblent donner des résultats différents pour un même candidat : « Il arrive aussi que deux enquêtes donnent 15. le même jour des résultats qui semblent contradictoires, quand on ne les Chiche, J. (2013) encadre pas des marges d’erreurs classiques15 ». Quels enseignements méthodologiques tirer à un mois du premier tour de l’élection présidentielle ? Il semble qu’une approche pragmatique et proche de la théorie des sondages soit possible. Représenter les intervalles de confiance ou marges d’erreur des intentions de vote vague après vague, pour chaque candidat à l’élection présidentielle française de 2022, repose sur un calcul rigoureux permettant de s’approcher des estimations issues de la théorie des sondages aléatoires, même si le dispositif d’enquêtes d’opinion de l’EnEF 2022 utilisé n’est pas probabiliste. Même si l’on ne peut être totalement certain du fondement théorique du calcul de ces marges d’erreurs dans le cas de tels sondages non probabilistes, il semble intéressant de les développer dans un but pédagogique, afin de vulgariser avec la plus grande rigueur possible les résultats de ces mesures « de terrain » et sensibiliser ainsi le lecteur sur l’incertitude intrinsèque qui les touche. Il semble enfin que cela soit, à ce jour et en attente de développements théoriques éventuels, l’unique approximation empirique disponible pour apprécier l’aléa des mesures faites par des enquêtes non probabilistes. En cela, nous rejoignons Bozonnet J.-P. et Bréchon P. qui s’expriment ainsi sur l’utilisation simultanée de la méthode des quotas et des marges d’erreur dans les sondages empiriques : « Malgré l’absence de fondement scientifique, cette technique fonctionne aussi bien que la méthode aléatoire. Sa fiabilité est démontrée par la constance des résultats obtenus lors de sondages successifs sur des questions qui ne sont pas soumises aux aléas de l’opinion. […] Il est vrai qu’en toute rigueur la méthode aléatoire est la seule à autoriser le calcul d’une marge d’erreur. Mais, si on considère que la procédure des quotas est en fait une reconstitution de l’aléa à 16. moindre coût, on peut en déduire que les marges d’erreur valables pour la Bozonnet, J.-P. et Bréchon, P. méthodologie aléatoire le sont aussi pour les quotas16 ». (2011) 9
Bibliographie ARDILLY (Pascal), « Nature et déterminants de l’erreur d’échantillonnage dans les enquêtes par sondage », Statistique et Société, Vol. 1 No. 2, pp. 43-49, 2013. ARDILLY (Pascal) en annexe de PORTELLI (Hugues), SUEUR (Jean-Pierre) (2010), Rapport d’information du Sénat n°54 sur les sondages, Enregistré à la Présidence du Sénat le 20 octobre 2010 https://www.senat.fr/rap/r10-054/r10-05421.html (consulté le 15 février 2022). ARDILLY (Pascal), Les techniques de sondage, Éditions TECHNIP, 2006. BAR-HEN (Avner) et CHICHE (Jean), « Les sondages sont-ils devenus fous ? », Images des Mathématiques, CNRS, 2009 https://hal.archives-ouvertes.fr/hal-00585951/file/Les_sondages_sont- ils_devenus_fous_.pdf (consulté le 15 février 2022). BOZONNET (Jean-Pierre) et BRÉCHON (Pierre) (2011), « Établir un échantillon représentatif », dans BRÉCHON (Pierre) (dir.), Enquêtes qualitatives, enquêtes quantitatives, Grenoble, Presses universitaires de Grenoble, pp. 123-143. CEVIPOF, Fondation Jean-Jaurès, Ipsos (2017), Enquête électorale française https://www.sciencespo.fr/cevipof/fr/content/lenquete-electorale-francaise- 2017.html (consulté le 1er février 2022). CEVIPOF, Fondation Jean-Jaurès, Ipsos (2022), Enquête électorale française https://www.sciencespo.fr/cevipof/fr/content/lenquete-electorale-francase- 2022-enef-2022.html (consulté le 1er février 2022). CHANVRIL (Flora), Sondages politiques : l’envers du décor (de leur méthodologie à leur utilisation par le grand public), Fabrique des données quantitatives, CMH- EHESS, 17 janvier 2022. CHANVRIL (Flora) et LE HAY (Viviane), Méthodes statistiques pour les sciences sociales, Ellipses, 2014. CHICHE (Jean), « Sondages d’intentions de vote : de la transparence à la confiance », Statistique et Société, Vol. 1 No. 2, pp. 29-32, 2013. Commission des sondages www.commission-des-sondages.fr (consulté le 1er février 2022). DEVILLE (Jean-Claude), « Peut-on croire aux sondages ? », Pour la science, n°344, pp. 58-65, 2006. WEISBERG (Herbert F.), The total survey error approach, The University of Chicago, Chicago, 2005.
Annexes Encadré 1 : Tableau générique contenant les marges d’erreur pour des exemples de pourcentages à une probabilité ou un risque donnés, dans les dispositifs EnEF 2017 et EnEF 2022 EnEF 2017 Source : Ipsos, CEVIPOF, Fondation Jean-Jaurès, Enquête électorale française 2017 (vague 12) EnEF 2022 Source : Ipsos, CEVIPOF, Fondation Jean-Jaurès, Enquête électorale française 2022 (vague 6b) 11
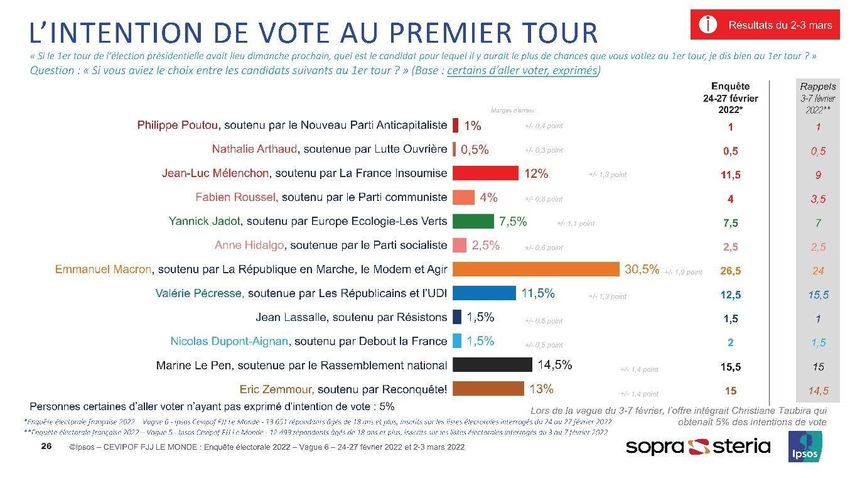
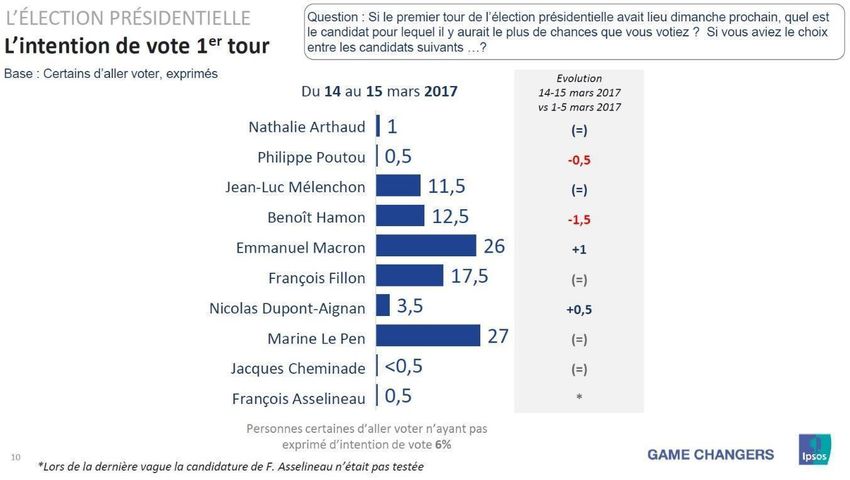
Encadré 2 : Intentions de vote pour le 1er tour des élections présidentielles françaises de 2017 et de 2022 mesurées par les dispositifs EnEF 2017 et EnEF 2022 EnEF 2017 Source : Ipsos, CEVIPOF, Fondation Jean-Jaurès, Enquête électorale française 2017 (vague 12) EnEF 2022 Source : Ipsos, CEVIPOF, Fondation Jean-Jaurès, Enquête électorale française 2022 (vague 6b)
Encadré 3 : Formules de calcul d’un intervalle de confiance pour les valeurs d’une variable statistique calculée à partir d’une question posée dans une enquête d’opinion 1/ Formule de l’intervalle de confiance : ̂ 1− ( ) = [ ̂ − × ( ̂ ̂) ; ̂ + × ( ̂ )] 2 2 Où : 1 − correspond au niveau de confiance → la probabilité que la vraie valeur appartienne à cet IC est égale à 1 − correspond au quantile d’ordre pour la loi normale centrée réduite → ce quantile correspond 2 2 à la valeur sur l’axe des abscisses telle que la probabilité d’observer une valeur supérieure à 2 vaut 2 ̂ ( ̂ ) correspond à l’écart-type autour de la mesure, tel que calculé à partir des données de l’échantillon 2/ Formule de la marge d’erreur : ̂ ̂ ) correspond à la marge d’erreur autour de la mesure × ( 2 Cette marge d’erreur dépend du seuil de confiance 1 − , de la mesure ̂ et de la taille de l’échantillon qui permet de calculer l’écart-type observé. 3/ Formule de l’intervalle de confiance en fonction de l’écart-type : IC pour une proportion : ̂(1 − ̂) ̂(1 − ̂) 1− ( ) = [ ̂ − × √ ; ̂ + × √ ] 2 2 IC pour une moyenne : 1− ( ) = [ ̂ − × ; ̂ + × ] 2 √ 2 √ Où : correspond à la taille de l’échantillon correspond à l’écart-type corrigé, soit à l’écart-type classique multiplié par un facteur √ −1 L’ensemble de ces éléments se calculent à partir des données, excepté le quantile qui se 2 retrouve facilement à partir d’une table de distribution de loi normale centrée réduite. Source : Chanvril F., Le Hay V. (2014) Édition : Florent Parmentier Mise en forme : Marilyn Augé Pour citer cette note : ANTOLINOS-BASSO (Diégo), BONO (Pierre-Henri), CASSOR (Frédérik), CHANVRIL (Flora) et SORMANI (Nicolas), « Élection présidentielle française de 2022. Représenter l’incertitude dans les intentions de vote pour le 1 er tour : une gageure ? », Sciences Po CEVIPOF, note de recherche, mars 2022, 13 p. 13 © CEVIPOF, 2022 Diégo ANTOLINOS-BASSO, Pierre-Henri BONO, Frédérik CASSOR, Flora CHANVRIL & Nicolas SORMANI
Vous pouvez aussi lire

















































