Visualisation Interactive de Données - Data Room
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Visualisation Interactive de Données
MOS 5.5 — dataviz
Romain Vuillemot
Version 0.1– 2021/12/13 – 14:02:06
TODOs
— Reprendre les éléments du cours déjà fait
— Reprednre Observables https://observablehq.com/d/c171cce964114932
— Exercice sur l’évaluation de visualisations
— Mettre des liens vers références externes
— Trouver livres liés à ce cours et indiquer dedans
— Inciter à générer ses propres données et aléatoires
— Voir ce cours https://curran.github.io/dataviz-course-2018/
— S’inspirer de Tufte pour la partie excellence graphiqeiue
— Mettre cote à cote les exemples code/figure
— Document à la Tufte avec soin graphique et utilisation de la marge voir Overleaf
— Reprendre les PE/PAr qui peuvent être liés
— Reprendre les cours MOS
— Template/consignes de projet
— Gitlab/Github pour être transparent et permettre corrections/additions et liens avec le code ?
— Quid de la traduction ? -> versions futures une fois stabilité
— Voir books mises en page https://jokergoo.github.io/ComplexHeatmap-reference/book/
upset-plot.html
— Experimentation à la cleveland et macgill ?
— Voir autres cours type MOOC
— Environnement de développement ? Observable ? Local ? Blocks. VizHubb ?
— Comment live coder et rapidement partager les solutions ? Montrer aussi ses solutions ?
— Regarder FIL notebooks https://observablehq.com/d/45fac7997d3a119e et SL
— Charger et parser ses données
— Scale à zero
— reprendre les notes du Github
— Mettre sur gitlab ECL et éventuellement permettre aux étudiants et autres personnes de contribuer
à l’écriture du document, en y mettant toutes les sources
— Charger les jeu de données directement depuis le gitlab
— Biggest challenges
— petits charts embededs inline -> svg idealement
—
— Parler quelque part des inputs classiques
1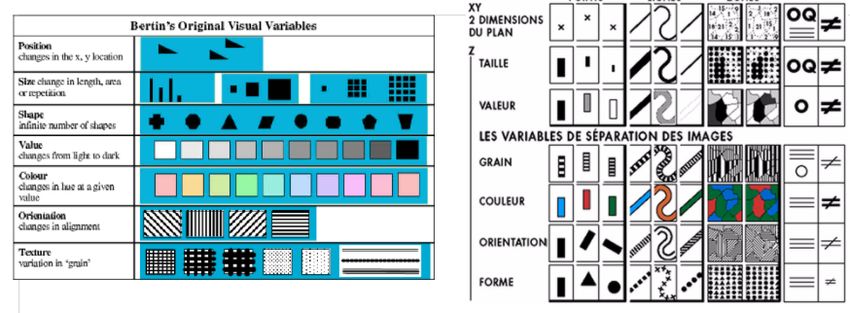
1 Préambule
Le domaine de la Visualisation Interactive de Données vise à améliorer la compréhension des données par
l’humain afin de prendre des décisions efficacement. Le objectif de ce domaine n’est pas de réaliser de belles
images, mais de donner des points de vues sur les données pertinents. Nous aurons une approche orientée
informatique sur toute la chaîne de vie d’une donnée, depuis sa captation, stockage, pré-traitement. Car
ces étapes sont nécessaires afin d’effectuer une visualiser qui ne sera efficace que si elles ont bien été
réalisées. C’est un domaine qui a une histoire assez riche sous forme physiques (cartes en papier) mais
aussi très récemment par exemple dans le cadre de l’explicabilité du machine learning ou la pandémie ou
de la covid-19.
(a) Historique XIXeme (b) Machine learning (c) Pandémie
Figure 1 – Exemples de domaines d’application de la visualisation (a) exemple historique de visualisation,
(b) élections et données complexes, (c) la pandémie avec données
L’objectif de ce cours sera de passer en revu les fondements du domaine avec une approche informatique,
à savoir la mise au point de méthodes automatiques de traitement de données. En particulier concernant
la chaîne de vie des données d’analyse de données et de visualisation, cela peut être décomposé selon
les quatres parties suivantes à suivre de manière séquentielle afin de réaliser une visualisation. Nous
verrons aussi des bases en interaction homme machine car les visualisations devront être re-formulables
par l’utilisateur. Enfin en design pour la partie prototypage, étape indispensable pour la réalisation d’une
visualisation qui prend en compte les besoins utilisateurs ou explore un espace visuel nouveau.
A noter que ce cours se noir et blanc, le plus concis, appel à ressources externes pour se spécialiser, mais
ne pas faire trop long/verbeux
1.1 Organisation du cours et rendus
Le cours comporte au total 28 heures de face à face divisé en séances comme suit. Les séances ont pour
objectif d’introduire progressivement les compéténces aussi bien techniques que de design relatives à la
visualisation. Toutes les séances sont indispensables et il est important de bien respecter l’ordre.
Vendredi 1/8/2021 13:30 Introduction à l’exploration visuelle de données
Vendredi 1/8/2021 15:45 Tableau et Observable
Vendredi 1/15/2021 13:30 Graphiques de base en Observable
Vendredi 1/15/2021 15:45 Vues coordonnées, tableau de bord
Vendredi 1/22/2021 13:30 Visualiser le temps
Vendredi 1/22/2021 15:45 Aggréger les données et prototypage
Vendredi 1/29/2021 13:30 Visualiser l’espace
Vendredi 1/29/2021 15:45 Layouts avancés en D3
Vendredi 2/5/2021 13:30 Visualisation de machine learning
Vendredi 2/5/2021 15:45 Visualiser les graphes
Vendredi 2/12/2021 13:30 Visualisation de trafic routier
2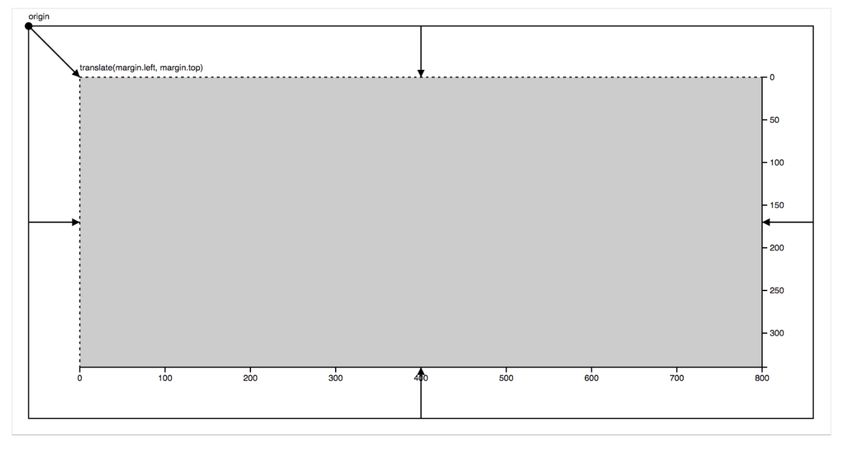
Vendredi 2/12/2021 15:45 Projet
Vendredi 2/26/2021 13:30 Soutenance projets
Vendredi 2/26/2021 15:45 Soutenance projets
Vendredi 3/5/2021 13:30 AUTONOMIE
Vendredi 3/5/2021 15:45 AUTONOMIE
Le rendu principal du cours est un projet sous forme de web application interactive à réaliser en binôme.
Une évaluation écrite sera aussi à réaliser individuellement sous format papier couran mars 2022.
Enfin une note de participation et suivi aux cours sera attribuée en fonction de l’activité pendant et entre
les séances de cours.
https://gitlab.ec-lyon.fr/rvuillem/mos5.5-dataviz
1.2 Pré-requis et préparation aux séances
Chaque séance de travail doit être lue au préalable, le cours ne servant qu’à en rappeler le contenu et à
répondre aux questions. Egalement à réaliser les exercices qui sont proposés et auxquels chacun d’entre
vous doit répondre individuellement afin d’avoir un processus actif de travail.
Les réponses devront être enregistrées dans un fichier texte, le nom du fichier doit être le nom de la séance
suivie de l’identifiant de l’étudiant. La compilation de ces fichiers servira ensuite à réaliser un rapport
de travail qui sera envoyé et constituera une note de participation au cours évaluée. Votre document de
travail pourra ensuite être consulté par les enseignants pour vous aider à réaliser vos exercices et corrigé
tout au fil du cours. L’objectif étant que ce document vous suive dans le futur.
Pre-requis. Ici sont indiqués la phase de préparation à la séance de travail. Il peut s’agir de plusieurs
types de préparation aussi bien technique, que d’exercice ou bien de lecture.
Définition " " –
Important.
En savoir plus.
Exercice.
Solution.
2 Processus d’analyse visuel de données
Pre-requis. Vous devez installer un outil d’édition de tables de type Microsoft Excel, WPS ou bien avoir
un compte Google Sheets. Ensuite installer Tableau Software qui est diposnibles pour Mac et Windows
(pas pour Linux hélas).
Le processus d’analyse visuel a pour but de répondre à des questions, qui sont souvent ouvertes et non-
connues à l’avance.
32.1 D’ou viennent les données ?
La toute première étape à se faire est de déterminer la source des données. C’est à dire quel est le moyen
de collecter les données. Cela peut être une base de données, un fichier texte ou pdf, un site web, etc.
1. Captation des données dans un monde réel où se déroule un phénomène
2. Stockage des space de données et traitement
3. Rendu graphique de dessin et animation de la visualisation sur un écran d’ordinateur
4. Perception et interaction par l’humain, mémorise, raisonne et prend une décision
Le point de départ de conception n’est cependant que rarement linée de gauche à droite (du phénomème
en passant par la données, visualisation et perception/analyse).
Figure 2 – Cycle de vie de la donnée depuis la captation juq’au rendu et interprétation par l’humain.
A ce stade ces questions doivent principalement être documentées dans votre processus d’analyse et
ensuite présentées lors de la communication des données (section 2.4).
2.2 Analyser un jeu de données simple
Avant de voir en détail la conception de visualisations, il est important de comprendre le processus
d’analyse visuelle de données, à savoir ce qui sera réalisé par l’humain à partir de la visualisation une fois
créée. Ce processus peut déjà être initié sans visualisation avec des données brutes comme sur la Figure 5.
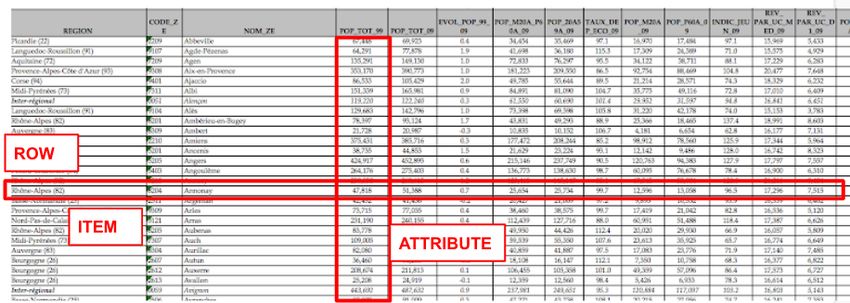
Figure 3 – Table de données.
Il s’agit d’un monde abstrait, c’est à dire qui ne dispose pas d’une représentation immédiate et efficace. Il
s’agit principekement d’une table qui contient des lignes et des colonnes, et les cellules sont remplies par
des valeurs. Ces valeurs auront un type, et nous considérons chaque ligne comme un item. Les colonnes
sont des attributs de ces items. Les données sont donc les croisements entre les lignes et les colonnes.
La première étape consiste à explorer un tel jeu de données. Ce n’est pas efficace pour l’humain car il
n’est pas apte à identifier visuellement des propriétés des données sous forme symbolique, alors qu’il est
efficace sous forme graphique
4Figure 4 – Table de données avec identification des item, colonnes et types.
Définition " Items " – Ce dont les objets d’études, le plus souvent représentés sous forme de ligne
dans un tableau.
Définition " Attributs " – Ce sont les propriétés des items. Is sont représentés sous forme de colonne
dans un tableau.
- Données quantitatives - Données ordinales - Données nominales - Données temporelles (dates) - Données
de type arbres et graphes - Données de type géographiques - Données de type binaires (booléens) - Données
de type textuelles
Data Types
Les données sont très souvent uniquement des types suivants :
1D/2D/3D spatial temporels categoriques numériques ordinal graphes / relationnelles hierachies binaire
Noous ne verron pas les données multimédias (images, vidéos, sons, etc.) du fait de leur pré-traitement
nécessaire et les soucis particuliers de captation et de stockage qu’elles peuvent engendrer.
Etant donné la table ci-dessus, les premières questions à ce poser sont généralement les suivantes (dans
l’ordre) :
1. Des objets d’intérêt ou items
2. Des événements qui n’ont pas de durées
3. Des événements qui ont une durée (intervales)
4. Qualité et distribution générale des données
5. Types de données et formattage (unité, etc)
Le design de cette table peut ensuite aider la lecture. Par exemple son ordonnancement ou bien sa
capacité à pouvoir être ré-ordonnée (souvent en cliquant sur l’en-tête de chaque colonne), le zebra pattern
permettant la mise en forme des lignes, etc.
En fois ces premières question posées des tests statistiques sont généralement à réaliser afin d’avoir un
résumé du comportement global
Exercice. Choississez un phénomène à comprendre et identifier : quelles sont les données ? Les tâches à
réaliser ? Les utilisateurs ?
5Réponse.
Comment aujourd’hui arrivez-vous à interpréter un jeu de données comme celui-ci dessous ? Ci-dessous
un exemple de table de données qui contient des exemples afin de démontrer le fonctionnement de l’ex-
pressivité des données.
Voici le jeu de données Iris
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5.0,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
Exercice. Pouvez-vous identifier un motif intéressant dans les données ?
Exercice. Quel outil utiliseriez-vous afin de répondre à la question récédente ?
Exercice. Calculer des indicateurs statistiques simples à l’aide de cet éditeur ou langage de programma-
tion : moyenne, écart-type, etc.
Ensuite est-ce que cet outil vous permet d’identifier des motifs intéressants ? En particulier exist-il des
méthodes de visualisation ?
Réponse.
2.3 Un jeu de données et analyses plus complexes
Désormais nous souhaitons travailler avec un jeu de données existant beaucou plus large et varié. Pour
cela il est nécessaire de charger les données et visualiser un échantillon.
Les zones d’emploi sont les zones qui regroupent à la fois les zones où les salariés exercent leur activités,
mais aussi où ils habitent et se rendent à leur travail. Ces zones sont souvent situées autour d’une zone
urbaine majeure. Ci dessous un échantillon du jeu de données
Figure 5 – Table de données.
Vous pouvez vous-même télécharger le jeu de données disponible http://romain.vuillemot.net/data/
tableau-annexe-atlas-ze.xls
Exercice. Posez vous les questions vues comme précédemment, mais pour cette fois avec les données de
zones d’emplois. Quelles les réponses aux questions ? Quelles sont le snouveautés ?
Utiliser l’outil Tableau afin de réaliser un tableau de bord permettant d’explorer les données. Afin de
réaliser cela il est nécessaire de suivre une formation Tableau disponible ici.
6Opérations de transformation des données
- Filtrage - Aggregation - Transformation / Dérivation
Illustrations
Des opérations de transformation des données sont souvent utilisées pour obtenir des données plus com-
plexes. Il existe également des opérations d’enrichissement des données afin de générer de nouvelles
données et aussi de les rendre plus compréhensibles (par exemple les coordonnées géographiques afin
d’identifier le pays correspondant).
Parmis la dérivation des données, des points dans un espace cartésien 2D
Exercice. Charger le jeu de données ci-dessous, calculer les statistiques de moyenne, variance, correlation.
Proposer une analyse et représentation de données. Faites une conclusion
b.count = values.length;
b.sum = d3.sum(values, d => d.value);
b.mean = d3.mean(values, d => d.value);
b.median = d3.median(values, d => d.value);
b.min = d3.min(values, d => d.value);
b.max = d3.max(values, d => d.value);
Concernant les autres indicateurs statistiques descriptifs, tels que les box plots, ils sont beaucoup plus com-
plexes à réaliser de manière automatique car ils combinent plusieurs indicateurs statistiques et marques
graphiques.
Exercice. Lister tous les étudiants de la classe sous forme de noms et ensuite de groupes. Prévoir les
rendus et validations
2.4 Communiquer et mettre en scène ses résultats
Une fois votre analyse il est nécessaire de capturer le processus, de A à Z à la fois depuis la collecte des
données et les hypohtèses de transfomations et de pré/post-traitements.
Microsoft Excel/Power Point
Tableau Software
PowerBI
Autres outils de recherche
Dans ce cours nous allons utiliser Tableau afin de charger et communiquer les données. Tableau permet
également d’explorer les données mais il est nécessaire de suivre une formation Tableau afin de pouvoir
utiliser les outils de Tableau de manière avancées et faire une exploration efficace. Dans notre cas
Tutorial Tableau
73 Dessiner une visualisation interactive
Pre-requis. Cette partie aborde désormais la partie programmation du cours. Des connaissances inter-
médiaires à avancées sont nécessaire en développement web JavaScript, HTML/CSS et SVG. Ces connais-
sances peuvent être acquises rapidement en suivant quelques tutoriels de développement web fournis en
Annexe qu’il faut suivre soit pour découvrir ces technologies, soit vour rafraichir (elles évoluent vite).
Désormais nous souhaitons dessiner une visualisation interactive. Pour cela il est nécessaire de charger les
données et visualiser un échantillon. La visualisation devant bien évidemment encoder les données, nous
allons voir comment progressivement passer d’une visualisation statique à une interactive. Ce processus
sera quasiment similaire pour les autres visualisations. A ce stade nous ne nous préocuppons pas encore
de la partie technique mais plutôt sur le lien entre monde des données et monde graphique.
Le dessin peut être réalisé de plusieurs façons :
— En SVG en utilisant les marques graphiques de base
— En Canvas en re-dessiner chaque marque
— En WebGL en utilisant la carte graphique
Chaque format a ses avantages et inconvénients. Le SVG permet de rapidement prototyper et inspecter
le graphe de scène qui est le DOM de la page web. Le Canvas est plus rapide à dessiner, mais il est moins
pratique pour la manipulation de données. Le WebGL est encore plus rapide à dessiner, mais demande
plus de connaissances en informatique graphique. Dans le cas du SVG et Canvas la biblithèque D3 permet
de faciliter le rendu. Dans le cas du WebGL, la bibliothèque ThreeJS facilite le rendu (et il faut utiliser
un navigateur qui supporte WebGL et posséder une carte graphique pour le rendu GPU).
3.1 Marques et propriétés graphiques
Définition " Marques graphiques " – Les briques de base de la visualisation sont les marques
graphiques, à savoir des groupes de pixels qui correspondent à une forme géométrique déjà établie (rec-
tangle, cercle, ligne). Ces marques serviront dans la plupart du temps à encoder les Items d’un tableau.
Ces marques ont des propriétés graphiques qui permettent de définir leur position, leur taille, leur couleur,
leur forme, etc. Ces propriétés encoderont les attributs de tout type (quantitatif, ordinal, nominal, etc.).
Figure 6 – Graphiques de base.
83.2 Marques en
Le est un langage standardisé pour le dessin vectoriel. La création de fichiers permet ainsi le dessin
et le rendu dans un outil d’édition et de rendu. Le format ressemble à du XML et a une organisation
hierarchique.
L’objectif dans le cadre de ce cours est de maîtriser le de manière assez imple afin d’être en mesure
de dessiner des visualisations. Nous commencerons par définir une marque graphique simple de type
rectangle, qui vient avec des propriétés graphiques.
a line is represented by :
while a general (closed) polygon is described by pairs of coordinates for each vertex :
Les marques peuvvent être groupées ... paire de brackets mais qui ne sont pas visibles. Il
permettront de mieux organiser le code afin de reflêter les groupes de sommets.
La mise en forme du SVG peut se faire de manière externe dans un fichier CSS qui est inclu au début
d’une page web.
3.3 D’une visualisation statique à dynamique
L’objectif de ce cours est de dynamiquement générer une visualisation à partir de données, afin d’utiliser
au mieux le système visuel et cognitif de l’humain. Ces visualisations seront inclues dans une page web
afin d’intercepter les interactions utilisateur.
3.3.1 Une visualisation statique
Nous souhaitons désormais réaliser nos propres visualisations en . Ci-dessous un code SVG per-
mettant d’afficher un bar chart comme dans l’exemple précédent. Cet exemple contient les informations
nécessaires à l’interprétation de la donnée. Le code ci-dessous affiche un premier bar chart assez simple
qui peut être édité en ligne.
Exercice. A partir du code ci-dessus, créez votre propre bar chart à partir d’un autre jeu de
données. Essayez de faire ne sorte que les informations encodées soient fidèles aux données.
Solution. Le travail réalisé est long et fastidieux, d’autant plus qu’il ne se passe que dans l’espace
graphique au moment où les données ont été rendues.
93.3.2 Repère et échelles
Le repère cartésien est le principal et sera in-fine l’espace de rendu car les pixels sont une matrice 2D
à remplir. Cependant il est possible de définir un repère cartésien qui est différent du repère cartésien
de l’écran, dans lequel les formes géométriques sont positionnées. Ce sera le cas pour d’autres repères :
radial, auto-organisateur et 3D.
Figure 7 – Graphiques de base.
var margin = {top: 20, right: 10, bottom: 20, left: 10};
var width = 960 - margin.left - margin.right,
height = 500 - margin.top - margin.bottom;
Cartésien
Radial. Il s’agit de représenter les données de manière polaire, avec un angle θ et une distance ρ. Un tour
complet de l’espace est le suivant : 2π soit 360°.
d3.scaleLinear().domain([0, 100]).range([0, 100])
Cette échelle
Echelles ordinales :
Exercice. Dessinez votre visualisation dans ce repère.
3.3.3 Data binding
3.4 Fonctionnement complet et mise en page
Votre visualisation est une fonction qui possède plusieurs méthodes permettant
104 Graphiques de base en visualisation
Pre-requis. Pour cette partie il est nécessaire d’avoir réalisé le code la section précédente et d’avoir un
premier jeu de données. Ces graphiques pourront être développés soit en local avec un serveur web, soit
en Observable en utilisant D3. Ces graphiques seront par la suite ré-utilisés.
Avant de commencer à travailler sur le dessin bas niveau de visualisations, nous allons voir quelques
graphiques standards. Ces graphiques sont des graphiques qui sont déjà pré-définis dans le domaine de
la visualisation interactive de données, mais aussi dans les outils et langages de programmation. Ces
graphiques ne sont cepdendant pas nouveaux : il resultent de l’assemblage de marques graphiques et
leur propriétés avec les données, mais en suivant une convention sous forme de graphiques pré-définis ou
templates. Ces
4.1 Bar chart
(a) Historique XIXeme (b) Machine learning (c) Pandémie (d) Pandémie
Définition " Bar chart " – C’est un graphique en baton où la marque est le rectangle.
La marque Ligne est le principal élément du graphique sur un axe continue et un axe catégorique
https ://observablehq.com/@observablehq/plot-scales ?collection=@observablehq/plot
Les variations sont nombreuses et les principales ne dépdent que de la variation de données. Par exemple
l’histogramme utilise une catégorisation de l’espace en divisions, mais ces catégories résulent d’un décou-
page ou binning des données en sous-groupes selon une méthode de discrétisation.
Histogramme n’est qu’une variation du bar chart où la catégorisation est le processus de binning à
savoir de groupement des valeurs de la distribution dans un certain nombre de groupes. Par exemple le
code ci-dessous génère des données en D3 afin d’avoir une distribution normale avec certains paramètres :
data_normal = Array.from({length: 200}, d3.randomNormal(1, 1))
Bar chart groupé (grouped bar chart)
d3.groups()
Bar chart empilé (stacked bar chart)
d3.layout()
4.2 Line chart
Définition " Line chart " – La marque Ligne est le principal élément du graphique sur deux axes
continus.
11(a) Historique XIXeme (b) Machine learning (c) Pandémie (d) Pandémie
Figure 9 – Exemples de domaines d’application de la visualisation (a) exemple historique de visualisation,
(b) élections et données complexes, (c) la pandémie avec données
La principale difficulté est le parsing des données temporelles selon un axe horizontal. Cet axe temporel
définira le dessin d’une ligne en D3 défini en fonction des échelles X et Y :
Line chart
Line chart cumulatif
Stacked line chart
Sparkline
4.3 Scatterplot
(a) Historique XIXeme (b) Machine learning (c) Pandémie (d) Pandémie
Figure 10 – Exemples de domaines d’application de la visualisation (a) exemple historique de visualisa-
tion, (b) élections et données complexes, (c) la pandémie avec données
Définition " Scatterplot " – C’est un graphique en baton où la marque est le point.
Scatterplot
Couleur + taille
Matrice de scatterplot
Connected scatterplot
Iris comme scatterplot le plus simple Interaction : hover pour title, changer les axes, etc
Player orientation using radial visualizaiton
Space occupation
125 Visualisations multi-vues et interactives
Nous allons maintenant nous intéresser à la conception de plusieurs visualisations et aussi à les rendre
ré-utilisables dans de nouveaux contextes.
Il est important de partitionner
5.1 Encapsuler les visualisations
L’objectif de l’encapsulation consiste à avoir une approche de modularisation que l’on rencontre en déve-
loppement logiciel. A savoir créer une fonction pour chaque élément du programme, ici une visualisation,
afin que l’on puisse découper un grand projet en plusieurs petits projets. Mais aussi que l’on puisse utiliser
les mêmes fonctions pour plusieurs vues soit aussi d’une même page, soi plusieurs pages.
Les principes de l’encapsulation sont les suivants :
— les données
— mapping avec les variables
— ..
5.2 Interactions
Il est souvent nécessaire de re-formuler une visualisation, autrement dit changer ses paramètres, car
ceux-ci ne
Les principales interactions étant :
— hover : affichage d’un tooltip
— click :
— drag :
— zoom :
— brush :
Ces interactions permettent très souvent
5.3 Assembler en vues coordonnées et tableau de bord
Matrices. c’est le cas où les visualisations sont générées et assemblées en fonction de données. Par
exemple via la permutation des attributs d’un jeu de données
Cette matrice peut même être interactive 1 afin d’explorer de grands jeux de données multi-dimensionnels.
Dans le cas où les données sont quantitatives alors le scatterplot est adapté. Mais dans le cas où il y a une
faible dispertion des données et/ou les données sont de type catégoriques alors cela ne s’applique plus.
Enfin à noter que les matrices sont symétriques et peuven n’être représentées qu’à moitié. La diagonale
peut aussi être utilisée pour représenter une distribution uni-variable telle qu’un histograme.
Vues coordonnées.
Tableaux de bord.
1. https://labs.data-publica.com/emploi/
135.4 Décoration et layouts
Layouts et division de l’espace.
Décoration visuelle.
6 Graphiques avancés
Nous avons jusque là vu les graphiques de base, mais il y a aussi des graphiques avancés qui résulent
d’autres assemblages de marques et propriété,s mais aussi de traitement de données.
6.1 Dessin de trajectoires
Trajsectoires Nouvelle marque : une flèche
players_positions = Array(9800) [
0: Object {x: 16, y: 15, id: "0", frame: 36}
1: Object {x: 19, y: 48, id: "1", frame: 36}
2: Object {x: 19, y: 105, id: "2", frame: 36}
3: Object {x: 19, y: 155, id: "3", frame: 36}
4: Object {x: 23, y: 214, id: "4", frame: 36}
5: Object {x: 21, y: 256, id: "5", frame: 36}
6: Object {x: 21, y: 314, id: "6", frame: 36}
- Les éléments avec un id - Les unités de temps avec frame - Les positions
Dans ce cas nous considérerons les positions
6.2 Visualiser le temps
https://xeno.graphics/
7 Visualiser le temps
7.1 Structure de données
1D avec index temporel Parsing de dates
7.2 Alogrithme de visualisation
7.3 Visualisations typiques
7.4 Variations de design
148 Visualiser l’espace
Geo map
C’est un repère 3D + temps à partir duquel peuvent être captées certains types de données. Les données
sont ensuite traitées et analysées pour obtenir des visualisations dans un espace de rendu graphique perçu
par l’humain, avec lequel il raisonne et intéragit. Le monde 3D est un ensemble de coordonnées (x, y, z)
et de temps (t). Ensuite sont dérivées des attributs de ces coordonnées et de temps pour obtenir des
données plus complexes.
8.1 Structure de données
Fond de carte Shapefiles Parsing des coordonnées + enrichissement
8.2 Alogrithme de visualisation
8.3 Visualisations typiques
8.4 Variations de design
Heatmaps Grids
9 Visualiser les graphes et les arbres
G = (V, E)
9.1 Structure de données
Liste d’adjacence Sous forme de matrice d’adjacence
9.2 Algorithmes
Comment est calculé un force-link layout ?
// Init graph data structure
var graph = {nodes:[], links:[]};
// Generate random nodes
var nb_nodes = 100, nb_cat = 10;
graph.nodes = d3.range(nb_nodes).map(function() {
return {cat: Math.floor(nb_cat * Math.random())};
})
graph.nodes.map(function(d, i) {
graph.nodes.map(function(e, j) {
if(Math.random()>.99 && i!=j)
graph.links.push({"source": i, "target": j})
});
});
15Parcours de graphe
Le parcours d’un graphe est un algorithme prennant en entrée une structure de données de graphe, et
en sortie renvoie un chemin dans ce graphe en fonction du type de parcours demande : plus court, moins
couteux, etc.
Cependant ce parcours résulte de plusieurs étapes consécutives, qui s’exécutent de manière séquentielle
et les étapes proposées sont définitives (alogirhtmes glouton) ou parfois un ré-ajustement est nécessaire
(programmation dynamique, relaxation).
Un al
Dijkstra
Voir les notes de cours de TC1
9.3 Alogrithme de visualisation
9.4 Visualisations typiques
9.5 Variations de design
10 Visualisation et Texte
Avec visualisations embeded
Fréquence de lettres -> algo de
11 Visualisation en 3D
12 Visualisation et Image/Vidéo
13 Visualisation ses propres données
Personal data visualizations
Gérer sa collection de jeux de données
14 Couleur
La couleur est un domaine
15 Visualisation dans le sport
Densité d’actions sur un terrain sportif
Profil de joueur
Métrique comme expected goals
Autres métriques
16Les données proviennent de méthodes d’annotations d’images ou de vidéos (qui sont une succession
d’images). Des exemples d’outils sont Trakcer https://physlets.org/tracker/help/frameset.html
ou Physmo http://physmo.sourceforge.net/download.html
Sure, the Golden State Warriors remain commanding favorites
over the league, but this season our Basketball Power Index (BPI)
preseason projections paint a different picture of the NBA --
and many of the changes can be attributed to James’ departure
from Cleveland.
— Which part is relevent to a fact ? Which one is relevant to an opinion ?
— Which data source would you rely upon to support the opinion ? How would you extract information
and present it ?
Sport data allow to either earn money as an income source (e. g.,bets), but also can be a way to develop
expertise to become a consultant or a sport journalist. Also can allow to better sepnd modeny on players
such as on early carreer if they show potential, or during carreer move to assess their strenght and
weaknesses, and find market value
On-field vs Off-field analytics
Typology of sports. Sports are human activities that can be seen with different lenses
spatial, non-spatial, individual, team, accessories
Each sport will have a set of descriptors throught this book
Types of data Sports have so many facets that there is no one single data type needed to master to
discover analytics. Sports can indeed be observed as spatially continuous trajectories chaning over time ;
discrete events ; a network of passes ; calendars of games ; single aggregated performance score ; and so
on.
This apparent compelxity can be approached with a hierarchical structure of available sports data. as the
top are high-level physical performances or games outcomes that usually aggregate large datasets into
a few measures. Those measures usually are derived from rules or interpretations of the game. At the
bottom the hierarchy are what we call raw data or observations, which usually are captured by sensors or
simple observations like position and basic events. Those raw data under their simplest form are a series
of data points, with space and time attribute. They still need some treatment to be meaninful, such as
trajectories reconstruction.
TODO : find a generic data taxonomy to derive information from ?
La difficulté de cette approche est la dualité entre la capture des données et la visualisation. L’objectif
est de capter les données et de les visualiser, mais ces deux processus ne doivent pas pour autant être
dissociés. La visualisation est un processus qui doit être réalisé en permance, et peut être même vu comme
un moyen de capture des données, comme par exemple si l’on dessine dans un plan 2D une trajectoire de
mouvement. Cette trajectoire est une série de positions.
Contexte. L’objectif de cette formation est de former étudiants et sportifs aux méthodes informatiques
permettant de capter leurs propres données dans un cadre expérimental, au moyen de motion capture,
video trackiing et capteurs (sonor, gestuel). Une fois ces données captées elles seront ensuite stockées,
17annotées et visualisées de manière exploratoire. Ensuite différentes modélisations seront introduites afin
de permettre l’analyse et visualisation :
Objectifs. Une fois la formation rélisée, il sera possible pour les participants de :
— capter ses propres données sportives (mouvements, événements)
— stocker les données et effectuer des vérifications sur la qualité
— réaliser des modèles simples statistiques d’analyse : trajectoires, séquences
— modélisations avancées, apprentissage
— ...
Sports are competitive activities, performed by humans. Sports are very diverse, as they can involve one
or many individuals, that may be grouped by teams, using accessories and balls, on small to very large
areas.
The Visualisation Interactive de Données handbook is aimed at anybody with basic programming skills
and interest in sport, to benefit from latest data sources, programming libraries and visual tools to explore
and communicate sports data.
Related to data science books as it is very hands on and question-data-driven approach. What you will
learn :
— understand a sport caracteristics ;
— basics of data science and visualization ;
— find data sources or create your own ;
— structure the data and assess quality and its potential ;
— build your own visualization tool to communication and add predictions.
Classification des sports
Spatial attribute, time attribute, network/graph
Backetball events : pass, picks, postups, .. Offense and defense
Looking at players, but also looking at games
Players profiles
Teams profiles
E.g. spider charts
On/Off statistics about how well a player performs when on the court vs on the bench
Desktop
Screenshot 2021-11-19 at 10.47.17.png
/Users/rvuillemot/Desktop/Screenshot 2021-11-19 at 10.47.17.png
Unknown
182006
1504
3
0
AAA
Unspecified
0
0
185
600
695
978
Similarities between sports For instance batting average are similar for batsmen in cricket and
batters in baseball and
TODO : make a difference between sports similarities in generale, and similarities based on data structures
History of sports, spin-off, variations, ..
As the right question
Know your audience Actors, players, coaches
16 Get the data
In this chapter we provide an end-to-end presentation of the data processing pipeline. We start with
data collection which translate real world events, in a digital format. We’ll see it can be done manually
by hand, automatically with sensors, and eventually via simulations to facilite controle over scale and
details.
Source websites to scrap data from
Basketball references
Manchester city open data
Soccer passes
Soccer -Recovery -Deflection -Minutes played -Goals -Assist -Accurate pass -Key passes -Crosses
Read the game (like ngolo kante)
A dataset usually is a file or a collection of files.
CSV file as archive. It is usefull as can be used offline, and sometimes pre-processed, cleaned and used in
other or similar context/application so you can compare your results against.
19CSV
Data model ‘.apply‘ applies a function to the rows
The home team is likely to win at a higher rate than the away one
Hitting metrics the problem with battling averages -> see how it correlates with walk score Developped
in early 70s
Baseball datasource
Basketball stats - Player Efficiency Rating (PER)
3D reconstruction
Radar data
16.1 Scrapping
Websites often contain the most up-to-date source of information, presented in a way for humans to read
and understand it. Since most of them are automatically generated, there exists a way to re-create the
underlying database format and content, using scrapping. The code below shows how a webpage is open,
read and number of game days are extracted, only using html markups such as .
from bs4 import BeautifulSoup
from urllib . request import urlopen
import urllib . request
import pandas as pd
import json
import lxml
req = urllib . request . Request ( ’ http ://www. maxifoot . f r / c a l e n d r i e r−ligue1 −2015−2016.htm ’ )
r = urllib . request . urlopen ( req )
soup = BeautifulSoup (r , ’ lxml ’ )
days = soup . select ("td > table")
days = soup . find_all ("table", class_ ="cd1")
nb_days = len ( days )
The nb_days variable contains all the necessary code to then visualize or analyse ranlings
Resulting data
{ ’ Angers ’ : [{ ’ day ’ : 0 , ’ pts ’ : 0 , ’ rank ’ : 0} ,
{ ’ day ’ : 1 , ’ pts ’ : 3 , ’ rank ’ : 0} ,
{ ’ day ’ : 2 , ’ pts ’ : 4 , ’ rank ’ : 0} ,
{ ’ day ’ : 3 , ’ pts ’ : 7 , ’ rank ’ : 0} ,
{ ’ day ’ : 4 , ’ pts ’ : 8 , ’ rank ’ : 0} ,
{ ’ day ’ : 5 , ’ pts ’ : 8 , ’ rank ’ : 0} ,
{ ’ day ’ : 6 , ’ pts ’ : 11 , ’ rank ’ : 0} ,
16.2 API
http://api.football-data.org/v1/soccerseasons returns
16.3 Data fusion Augmenting / enriching with metadata
https://squared2020.com/2017/05/07/identifying-player-possession-in-spatio-temporal-data/
Entities extracted during the previous step can be further detailed using so called metadata, which are
data about data. The range of such data is very broad, from getting details on teams or tames locations,
players characateristics,
20Choose the right pivot/index By id By time By position
To augment the data one needs a way to connect different datasets. One way to do so is to use entities
unique id. For instance an acronyme or a normalized form. Wikipedia is good at providing such form in
their URL. Using this unique id, it is then possible to fetch metdata, e. g.,from DBpedia
Another type of pivot is the time. Whatever is the information, if synced by time it can be put together,
e. g.,on an interface.
Finally position is also a very powerful pivot. However as time might not be sinced, spatio-temporal
events require a specific treatment.
16.4 Video analysis
Extract soccer players from video
Video datasets
16.5 Scouting apps
16.6 Activity tracker
Apple Watch, ..
Strava / Run tracking -Rate limit for apps
Export -GPSX file -CSV ? -See Strava export formats
Synchronize activities between apps
17 Explore the data
This chapter provides you with starting points to explore an already collected dataset. Basic statistics
are useful to get a first glimpse of the dataset, either to confirm early intuitions or get to know a sport
you’ve never investigated before. Those statiscs however are not an end and should be taken with caution
as they don’t fully capture the complexity of a game.
Similar statistics can describe radically different behavior or outcomes. Deriving statistics is the next
step to extract more meaningful information.
parse and store, timestamps assess quality, completeness preview plot use standard tools like Tableau, ..
Interesting patterns
Streak / streakiness
17.1 Advanced metrics
Likelihood of a shot Quality of a shot Quality of a shooter
Shoot ability vs Shooting probability
2117.1.1 Expected goals
Blog on stats
17.1.2 FIFA ranking
FIFA ranking metrics is defined as follows :
P = Pbef ore + I ∗ (W ˘We )
What you need to caculate it :
— teams score/ranking history
— games calendars
— list of teams
— calculate the metric !
18 Visualize the data
18.1 Tables
Tables are presentation of data as rows and columns, using symboles (mostly numbers)
18.2 Ranking charts
Definitions
Ranking have different names : Standing, ladder, ..
A rank is an ordering technique taking as input a set of items S (e. g.,teams) and provides a permutation
of these items according to one dimension (e. g.,points, goals scored). A rank is a function rank : S →
0, ..., S − 1, that generates up to S! permutations, i. e.the number of ways the items in the set can be
uniquely ordered [?]. Ranks apply to dimensions (columns) D, D > 0.
Assuming a continuous and tie-free ranking, we can express a rank as : di < dj ⇔ rank(i) < rank(j),
i, j ∈ S, di , dj being the values of two rows i, j ranked according to d.
Finally, a rank can be applied to temporal values, where t ∈ T , with T a set of discrete events (e. g.,games
in a championship). Sdi ,tj is the ranking table, which is a snapshot of a championship, ranked according
to a dimension di at a time tj .
-Ranking function
-Ranking attribute
{’Angers’: [{’day’: 0, ’pts’: 0, ’rank’: 0},
{’day’: 1, ’pts’: 3, ’rank’: 0},
{’day’: 2, ’pts’: 4, ’rank’: 0},
{’day’: 3, ’pts’: 7, ’rank’: 0},
{’day’: 4, ’pts’: 8, ’rank’: 0},
{’day’: 5, ’pts’: 8, ’rank’: 0},
{’day’: 6, ’pts’: 11, ’rank’: 0},
...
22Predictions
Predictions are about guessing future values v̂ beyond a **current time** tc ∈ T + , with T + being all the
future time and tc being the time-stamp after which the last values have been observed.
Predicting a ranking means determining the set of values v̂ = [v̂tc+1 , ..v̂tn ] where each v̂ti depends on the
ranking of v̂ti−1 and will influence the ranking of v̂ti+ .
Rankings prediction
In the case of a ranking, v̂ti has the form [game : gi , teama : r1 , teamb : r2 , ..] where teams values are
ranking values r ∈ N , 0 < r < Teams. TODO : find a better formalism.
A soccer ranking tables usually has the following properties : S = 20 teams ; D = 10 dimensions ; T =
(S−1)×2, i. e.T = 38 games ; 0 ≤ t ≤ 38. An important property of permutations in soccer championships
is that the higher t is, the less the teams’ permutation amplitude is important because teams tend to
have high points difference.
In the case of a soccer league, the schedule is known in advance.
18.3 Brackets
18.4 Trajectory
The OpenField sensors present the data in a different way.
# OpenField Export : 03.07.2018 14:33:04;;;;;;;;
# Reference time : 05.05.2018 19:00:36 UTC;;;;;;;;
# CentisecTime : 152554683600;;;;;;;;
# DeviceId : 43896;;;;;;;;
# Speed Units : Kilometers Per Hour;;;;;;;;
# Distance Units : Meters;;;;;;;;
"# Period: ""LOU MHR""";;;;;;;;
"# Athlete: ""Menini""";;;;;;;;
Timestamp;Seconds;Velocity;Acceleration;Odometer;Latitude;Longitude;Heart Rate;Player Load
05.05.2018 21:00;0;0;0;0;0;0;0;0
05.05.2018 21:00;0,1;0;0;0;0;0;0;0
05.05.2018 21:00;0,2;0;0;0;0;0;0;0
05.05.2018 21:00;0,3;0;0;0;0;0;0;0
05.05.2018 21:00;0,4;0;0;0;0;0;0;0
05.05.2018 21:00;0,5;0;0;0;0;0;0;0
05.05.2018 21:00;0,6;0;0;0;0;0;0;0
Heat map Kirk Goldsberry
ESPN articles
Angles de passes :
18.5 Graph
Pass network https://www.lukebornn.com/papers/cervone_ssac_2014.pdf
Network science
2318.5.1 Build and deploy your own Web app
18.5.2 ...
19 Model and prediction
We want to build some basic models first. It requires some exploratory method to learn about the data
and the features.Then we eventually add more complexity such as using deep learning that learns its
features by itself.
Hidden Markov Model
19.1 Event prediction
Notebook predictions
A Poisson random variable is a count of the number of occurences of an event in a given unit of time,
distance, area or volume.
Goals distribution follow a Poisson distribution :
e−λ λx
P (x) = x! , λ >0
Similarities between trajectories Finding longest sub-strajectories
Euclidian distance
19.2 Performance of players
19.3 Playres injury
Injury prevention
List of all possible injuries
Physical factors that are not specific to sport players
Factors that are specific to sports
Current ways to prevent injuries
Détection de dribbles
19.4 Performance of teams
Fifa world cup analysis
19.5 Predict games outcomes (win, loss)
Predicting Win Shares
Home teams score more than away teams (show some stats ?)
2419.6 World Cup Predictions
FIFA World Cup
19.7 Case studies
19.7.1 NCAAA predictions
19.7.2 FIFA worldcup predictions
Allocation system
Prediction
19.8 Metadata
colors, logos, ..
federations
big datasets, high resolution datasets, .. missing data completion 3D animation https ://twitter.com/kashthefuturist/status/10
Fantasy basketball
Prediction
Athtles analytics, posters,
Pen plotter
20 Resources
20.1 Tools
Hudl
20.2 Online blogs
FiveThrithyEight
FanGraphs
Hudle 2
Olympic Channel
StatsBom
TODO Kirk Goldsberry
Daryl Morey (basketball)
2. https://www.hudl.com/blog/sports-analytics-101-an-intro-to-advanced-stats
2520.3 Classes
Stats by Lopez Labs and lecture notes
Python data mining notebooks
Simply Soccer Academy
20.4 Academic journals
Journal of Quantitative Analysis in Sports (JQAS)
26A Statistiques de base
Totals.
Average. Number of average goals Basic statistics averages -Nb of goals - -
Median.
Percentages.
A.1 Derive data
Le calcul de la moyenne
Mean
Variance
Correlation
Pn
X = n1 i=1 Xi
La MSE
2
σ2
h 2 i σ
MSE X = E X −µ = √ =
n n
27B Couleur
??
C Projets
??
Qu’est ce qu’un bon projet et pourquoi ?
monter une vraie web app qui sera pérenne et qui sera accessible à tous de manière publique, simple et
efficace en termes de visualisation.
28D Visualisation de trajectoires
Une trajectoire est un ensemble de points qui se déplacent dans un espace. Par exemple, une trajectoire
d’un joueur dans pendant un match de football, ou bien le déplacement d’une personne dans une ville. Les
points sont issus d’observations continues d’objets complexes en mouvement dans un espace Cartésien
principalement en 2D (x, y) souvent initialement issus d’un espace 3D (x, y, z).
Le plan de déplacement, qui souvent est statique, comporte aussi des caractéristiques. Il est en effet
rarement continue et infinie. Par exemple un terrain de foot est continue mais avec un périmètre et
des landmarks auxquelles sont associées. Le plan d’une ville comporte beaucoup de murs limitant le
déplacement des indivisus. Parfois on ne considère le déplacement que d’une intersection à une autre.
Même dans un plan continu nous allons chercher à discrétiser soit sous forme d’ensemble de points soit
par régions afin de limiter les calculs.
La position la plus facile et idéale est une view from above qui permet de
Random walk. Dans le plan on peut déjà tracer une trajectoire aléatoire en utilisan un Random Walk
2D, qui est une série de coordinées générées successivement avec une orientation aléatoire. Ainsi θ est
uniformément distribué sur un interval d’angle [0, 2π].
Ces pas sont cependant décorélés les un des autres. Le mouvement brownien est un mouvement typique,
qui se déplace dans un espace aléatoire. Ce mouvement peut être utilisé pour parcourir un espace de
manière aléatoire sous forme d’heuristique. C’est par exemple la manière dont les algorithmes de recherche
d’un chemin dans un graphe sont décrits par des algorithmes de recherche d’un chemin dans un graphe
(ex. Google). Cela relève de la théorie des probabilités et de la théorie des statistiques.
TODO : il est cependant intéressant de calculer des statistiques tels que l’éespériance, la variance, etc.
Trajectoire est formée une trajectoire en concaténatn dans l’ordre tous ces points telle que T =
{s1 , ..si .., sn } avec s ∈ S. Cette trajectoire même aléatoire peut être représentée par une succession
de segments sur un plan 2D. Ces segments sont définis par leurs extrémités si et si+1 et leur longueur li .
D’autres propriétés de ces segments sont la longueur totale lT et la longueur moyenne lT /n.
Valeur angulaire de la trajectoire en fonction de la position si en utilisant la formule suivante : si =
(x, y) et si+1 = (x0 , y 0 ) alors thetai = arctan(y 0 − y/x0 − x).
Vitesse enputilisant la formule suivante : vi = (x0 − x)2 + (y 0 − y)2 . L’acceleration est définie comme
p
suit : ai = (vi − vi−1 )2 .
Distance parcourue D’autres métriques sont la distance parcourue depuis le début de la trajectoire dT
et la distance moyenne dT /n.
Vitesses d’animation Time-lapse visualizations (s < 1), Real-time visualization (s = 1), and Slow
motion visualizations (s > 1).
Division du terrain Un terrain de jeu est divisé en zones P = m × n. Chaque zone est définie par
une position si et une taille li . La zone i est définie par si et li . Chaque segment part de la zone i et se
termine dans la zone i + 1 si la définition est temporelle au niveau de la séquence de zones.
Calcul de la complexité d’une trajectoire Une trajectoire étant composée de n la complexité spatiale
est le nombre de zones parcourues
Calcul d’une heatmap cela correspond à identifier pour chaque zone le nombre d’observation qui passe
29par celle-ci, ensuite de calculer un scale global permettant
Prédiction simple d’une trajectoire
Re-construction d’une trajectoire à partir de points
Similarité de trajectoires par exemple en utilisant DTW
Time series modélisation
Le sens des pairs de strokes qui sont les (si , sj ) qui sont des positions dans l’espace pour un moment
t ∈ T (souvent associé à l’arrivée). Ces moments existent de manière indépendante mais son reliés afin
de former une trajectoire et ainsi donner un sens de continuité du mouvement.
Chaque positio si possède un ensemble de propriétés au delà du temps. A savoir des dimensions D qui
permettent de caractériser ce point. Ces dimensions ne sont pas forcément spatiale et sont ainsi dites
abstraites car elles n’ont pas une représentation immédiate.
Au delà des dimensions abstraites, il existe des dimensions dérivées directement des trajectoires qui sont
reconstituées. C’est le but du projet trajmetrics d’avoir un ensemble le plus exhaustif de ces métriques
et ainsi pouvoir caractériser les trajectoires
Ces données de trajectoires forment aussi des intervalles temporels qu’il est intéressant de rendre explicite.
Chaque interval étant défini comme I = [ti , tj ]. Tout comme les trajectoires les intervales sont associés
à des positions si ce sont les éléments d’analyse associés à ces points. Et également il existe différentes
métriques qu’il est possible de dériver depuis les intervalles notamment au moyen d’algèbres d’ensembles.
Points uniques dans le temps associé à des events
Intevales avec t min et t max, et propriétés sur ces intervales
Spatial events are characterized by their spatio-temporal positions, that is, by pairs (t, s), where t ∈ T ,
s ∈ S. Movers
A trajectory is a sequence of pairs ordered by time that provide a sens of continuity
L’objectif du tracking est de faire émerger ces types de données à partir de pixels de vidéo. Il est pour
RNN
E Perception humaine
F Evaluation d’un outil de visualisation
30Vous pouvez aussi lire

















































