Critères pour avoir la meilleure équipe ! - PROJET DATAMINING - CEREMADE
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
PROJET DATAMINING
Basket-ball professionnel "NBA" :
Critères pour avoir la meilleure équipe !
Réalisé par : Anasse LAHLOU KASSI DESS TIO
Houssam Eddine HOUBAINE DESS ID
Année Scolaire : 2004 - 2005SOMMAIRE
INTRODUCTION.................................................................................................................................................... 1
I. ETAT DE L’ART : ........................................................................................................................................... 2
1. QU’EST CE QUE LE DATAMINING ? ................................................................................................................... 2
2. POURQUOI LE DATAMINING ? .......................................................................................................................... 2
3. COMMENT ? ..................................................................................................................................................... 3
4. CLASSIFICATION DES OUTILS ET LOGICIELS DE DATAMINING ........................................................................... 3
4.1. Les outils Open Source....................................................................................................................... 3
4.2. Les autres outils et logiciels Datamining ........................................................................................... 5
4.3. SODAS (Symbolic Official Data Analysis System)............................................................................. 6
II. PROBLEMATIQUE....................................................................................................................................... 12
1. CONTEXTE ..................................................................................................................................................... 12
2. DESCRIPTION DE LA BASE DE DONNEES .......................................................................................................... 13
2.1. Le schéma relationnel ...................................................................................................................... 13
2.2. Description des variables................................................................................................................. 13
3. CHOIX DES INDIVIDUS ET CONCEPTS .............................................................................................................. 16
4. LES REQUETES DEFINISSANTS LES CONCEPTS ................................................................................................. 16
4.1. La requête Principale....................................................................................................................... 16
4.2. La requête addsingle ........................................................................................................................ 16
4.3. La requête Taxonomie...................................................................................................................... 17
III. UTILISATION DU MODULE DB2SO SOUS SODAS............................................................................... 18
1. CREATION DE LA CONNEXION ........................................................................................................................ 18
2. EXECUTION DES REQUETES ............................................................................................................................ 19
3. ENREGISTREMENT DU FICHIER SODAS ......................................................................................................... 23
IV. UTILISATION DES METHODES DE SODAS POUR L’ANALYSE DES DONNEES ......................... 24
1. LA METHODE VIEW (SOE DANS L’ANCIENNE VERSION) : ............................................................................. 24
1.1. Présentation de la méthode VIEW : ................................................................................................. 24
1.2. Application de la méthode VIEW ..................................................................................................... 25
1.3. Interprétation des résultats .............................................................................................................. 30
2. LA METHODE DSTAT : .................................................................................................................................. 31
2.1. Présentation de la méthode DSTAT ................................................................................................. 31
2.2. Application de la méthode DSTAT ................................................................................................... 31
2.3. Interprétation des résultats .............................................................................................................. 32
3. LA METHODE TREE ....................................................................................................................................... 32
3.1. Présentation de la méthode TREE.................................................................................................... 32
3.2. Application de la méthode TREE ..................................................................................................... 33
3.3. Interprétation des résultats .............................................................................................................. 34
4. LA METHODE PYR ......................................................................................................................................... 34
4.1. Présentation de la méthode PYR ...................................................................................................... 34
4.2. Application de la méthode PYR........................................................................................................ 35
4.3. Interprétation des résultats .............................................................................................................. 36
5. LA METHODE DIV.......................................................................................................................................... 36
5.1. Présentation de la méthode DIV ...................................................................................................... 36
5.2. Application de la méthode DIV ........................................................................................................ 37
5.3. Interprétation des résultats .............................................................................................................. 37
6. LA METHODE PCM ........................................................................................................................................ 38
6.1. Présentation de la méthode PCM..................................................................................................... 38
6.2. Application de la méthode PCM ...................................................................................................... 38
V. LES "PEPITES" DE L’ANALYSE .............................................................................................................. 40
CONCLUSION....................................................................................................................................................... 41DATAMINING
Introduction
Ce document est le rapport de notre projet Datamining. Ce projet est réalisé par le logiciel
SODAS.
Le but principal est d’utiliser une base de données dont il faut extraire les informations
importantes pour l’analyse. Cela est fait à travers l’ensemble des méthodes et techniques vues
dans le cours.
Pour notre analyse, nous allons utiliser une base de données de Basket-ball professionnel :
"NBA".
Le rapport élaborera en premier lieu une présentation de l’état de l’art (datamining), le
positionnement de SODAS sur le marché des logiciels du datamining.
Ensuite il posera la problématique et présentera la base de données utilisée avec une
justification des différents choix (individus, concepts, etc.).
Et enfin, il affichera les rapports, graphiques, et résultats avec leurs explications.
Enseignant : M. DIDAY 1 2004 - 2005DATAMINING
I. Etat de l’art :
1. Qu’est ce que le Datamining ?
En informatique, le développement des moyens de stockage (bases de données) et de calcul
permet le traitement et l’analyse d’un ensemble de données très volumineux.
Et récemment, le perfectionnement des interfaces Hommes-Machines offre aux utilisateurs,
des possibilités d’utilisation et de mise en oeuvre très simples des outils logiciels. Cette
évolution, ainsi que la popularisation de nouvelles méthodes algorithmiques (réseaux de
neurones) et outils graphiques, ont conduit au développement et à la commercialisation d’un
ensemble d’outils et logiciels intégrant un sous-ensemble de méthodes statistiques et
algorithmiques sous la terminologie de Data Mining, dont l’objectif est la prospection ou
fouille de données.
Le datamining est une étape du “Knowledge Discovery in Database” (KDD) ou extraction de
données qui consiste en la fouille de la base de données en se basant sur certaines règles et
techniques. Ces extractions permettent de dégager des informations potentiellement utiles.
Le but principal du datamining est d’extraire des "pépites" (données pour l’analyse) dans
une "mine" (base de données) sans se salir les mains.
2. Pourquoi le Datamining ?
Les différents secteurs et domaines sur le marché sont en pleine expansion. Les entreprises
sont en effet très motivées pour tirer parti et amortir, par une aide à la décision quantifiée, les
coûts de stockage significatifs (souvent des teras octets) que leur service informatique
s’emploie à administrer.
C’est là ou l’approche du Datamining prend notamment place. Différents exemples peuvent
être cités à ce niveau :
- La Gestion de la Relation Client (GRC) ou plus connu, en anglais, sous
Customer Relationship Management (CRM), où il faut fidéliser et choyer les
clients, et ce dans un but lucratif. Cependant, la base de données client contient
souvent un nombre important de clients. La question qui se pose est comment
choisir le bon client pour la bonne campagne, segmentation, produit, etc. ?
- Le développement et contrôle de qualité des applications industrielles. En effet,
le contrôle de qualité est une phase très importantes lors de la réalisation
d’applications. Par contre, si le nombre de processus et d’applications est très
important, souvent dans le milieu industriel, il faut savoir les gérer parfaitement
sans erreurs ou ambiguïté.
- Etc.
On peut constater que le Datamining n’est pas limité à un secteur ou milieu précis. En
effet, cette technique devient utile dès que l’entreprise est confrontée à un volume de données
important.
Enseignant : M. DIDAY 2 2004 - 2005DATAMINING
3. Comment ?
Le Datamining est une technique nécessitant, au préalable, une préparation des données pour
que leur exploration soit cohérente et intéressante. C’est à ce niveau qu’intervient la notion de
l’entrepôt de données (Data WareHouse).
Un entrepôt de données, dont la mise en place est assuré par un gestionnaire de données (data
manager) est un ensemble de bases relationnelles extraites des données brutes de l’entreprise.
Ces bases sont nettoyées et homogénéisées, à travers des outils d’Extraction, de
Transformation et de Chargement (ETL), dans le but d’être stockées dans l’entrepôt.
Une fois ces données sont préparées et nettoyées, elles deviennent à ce stade prêtes à être
exploitées. Leur exploitation se fait via les techniques de Datamining. Plusieurs outils et
logiciels de Datamining, sont disponibles actuellement sur le marché. Ces outils permettent
de s’interfacer avec la base de données (entrepôt de données) et d’y accéder dans le but
d’extraire les informations potentiellement utiles comme cité auparavant.
L’entrepôt de données est utilisé notamment quand le nombre de données est très
significatif, ou plusieurs bases de données existent mais sont hétérogènes et non consolidées.
Les outils Datamining peuvent aussi explorer des bases de données relationnelles sans avoir
besoin d’un entrepôt de données. Il suffit que l’information soit bien stockée et cohérente pour
en tirer profit. Par exemple, pour notre projet, nous allons travailler sur une base de données
Access.
Pour notre projet, nous allons utiliser le logiciel SODAS. Il serait donc intéressant de faire le
tour du marché des outils et logiciels Datamining pour connaître le positionnement de SODAS.
4. Classification des outils et logiciels de Datamining
Dans cette partie, nous allons faire une présentation rapide d’une liste, non exhaustive, de
logiciels les plus connus et utilisé sur le marché du Datamining.
4.1. Les outils Open Source
Certains peuvent être intéressé par des outils libres. Voici une liste, non exhaustive, d’outils
Open Source pour le Datamining.
Cette liste se restreint aux logiciels qui nous ont parus efficaces.
4.1.1. R-projet
R est un langage et une infrastructure spécialisés pour les traitements statistiques. Il est l'un des
nombreux projets GNU distribué sous licence GPL (logiciel libre).
R est écrit en langage compilé (principalement en C), ce qui autorise de bonnes performances.
La qualité de cet environnement et son ouverture ont permis à une myriade de théoriciens,
statisticiens et informaticiens de compléter cette plate-forme d'un nombre impressionnant de
fonctionnalités. Des dizaines de packages offrant des milliers de fonctions en font
probablement la plate-forme la plus complète. Cependant l'outil n’est pas considéré comme
étant très simple à utiliser.
Enseignant : M. DIDAY 3 2004 - 2005DATAMINING
Comme on peut le constater sur l’image, R utilise plusieurs techniques intéressantes
(classification hiérarchique, ..) :
Pour plus d’informations ou téléchargement du logiciel :
http://www.r-project.org/
4.1.2. Scilab et Mixmod :
Scilab est un langage et une infrastructure spécialisés pour les traitements mathématiques
numériques et la modélisation. Scilab est un projet de l'INRIA et de l'Ecole Nationale des
Ponts et Chaussées. Sa licence autorise une utilisation gratuite ainsi que la modification des
sources.
Scilab supporte un spectre très large d'applications, et de nombreuses contributions sont
opérationnelles sur cette plate-forme.
Mixmod est une contribution de l'INRIA, du Laboratoire de Mathématique de Besançon et du
Laboratoire Heudiasys de Compiègne qui fonctionne sur Scilab. Mixmod propose des
fonctionnalités de clustering (analyse discriminante et maximum de vraisemblance).
Mixmod est relativement simple d'utilisation et s'avère adapté pour un volume raisonnable de
données.
Pour plus d’informations ou téléchargement du Scilab :
http://www-rocq.inria.fr/scilab/
Pour plus d’informations ou téléchargement Mixmod :
http://www-math.univ-fcomte.fr/mixmod/index.php
Enseignant : M. DIDAY 4 2004 - 2005DATAMINING
4.1.3. Autoclass-c :
C’est un logiciel spécialisé notamment dans le Clustering (analyse discriminante et maximum
de vraisemblance).
Développé par un laboratoire de la NASA et disponible dans le domaine publique. Outil
performant écrit en C qui n'a plus évolué depuis le milieu 2002.
4.2. Les autres outils et logiciels Datamining
4.2.1. SAS :
La solution logicielle intégrée SAS est un outil très puissant. Il permet des analyses rapides
sur de très grosses bases de données.
Il est très convivial : il dispose d'une interface composée d'icônes et de flèches permettant une
visualisation générale de la totalité du projet.
Il est aussi très complet : Il dispose d'une grande richesse analytique et permet aussi
l'intégration de toutes les méthodes statistiques.
4.2.2. SPAD :
Créé en 1985 dans sa version Dos, SPAD est le logiciel français pionnier dans les analyses
exploratoires et le Datamining.
Connu et reconnu pour sa convivialité et son efficacité, il possède les principales techniques
statistiques liées au Datamining :
- Description automatique des variables ;
- Analyse exploratoire multidimensionnelle (ACP, AFC, ACM et Classifications) ;
- Réseaux de neurones ;
- Analyse discriminante ;
- Segmentation ;
- Etc.
4.2.3. XLSTAT :
Addinsoft est l'éditeur d'XLSTAT.
XLSTAT est un logiciel implémentant dans Microsoft Excel des fonctionnalités d'analyse de
données et de statistiques.
Le module central, XLSTAT-Pro, comprend plus de 40 outils d'analyse de données et de
statistiques. Des modules avancés sont également disponibles ou en cours de développement
(tableaux croisés dynamiques, séries chronologiques).
4.2.4. Clementine :
Clementine, l'atelier de Datamining, est un outil SPSS. Il accompagne l'entreprise dans la
gestion de sa relation client.
Enseignant : M. DIDAY 5 2004 - 2005DATAMINING
Clementine intègre l'ensemble des techniques statistiques pour la valorisation et la
modélisation des données :
- Arbres de décision ;
- Statistiques ;
- Règles d’associations ;
- Etc.
Son interface visuelle et intelligente facilite le processus de Datamining et permet à
l'utilisateur d'exploiter pleinement ses connaissances métier.
Solution globale d'entreprise, Clementine permet le déploiement des modèles créés à chaque
acteur de l'entreprise.
4.2.5. Set Analyser :
Business Objects propose un outil d'analyse des données issues de l'e-business et du CRM : Le
logiciel Set Analyser.
Set Analyzer s'appuie sur les fonctionnalités d'interrogation, de reporting et d'analyse
multidimensionnelle OLAP de Business Objects et de Web Intelligence.
Cette liste n’est pas exhaustive, d’autres logiciels et outils existent et qui sont aussi performants
et très utilisés, tels que :
- Oracle ;
- IBM ;
- CART ;
- Etc.
4.3. SODAS (Symbolic Official Data Analysis System)
SODAS est un logiciel issu d’un projet, appelé aussi SODAS, de EUROSTAT. Ce logiciel
répond aux principales qualités d'un outil de Datamining.
C’est un projet à vocation européenne. Le projet regroupait donc plusieurs laboratoires et
centres de différents pays européens.
On peut citer :
- CISIA : Paris ;
- DIB-UNIBA : Bari ;
- DMS : Naples ;
- INRIA : Paris ;
- LEAD : Lisbonne ;
- LISE-DAUPHINE : Paris ;
- Etc.
Deux versions sont actuellement disponibles sur le site :
http://www.ceremade.dauphine.fr/~touati/sodas-pagegarde.htm
Enseignant : M. DIDAY 6 2004 - 2005DATAMINING
- La version 1.2
- La version 2.5
Ce logiciel est destiné à des utilisateurs "métier" sans compétences statistiques ou
informatiques particulières. En effet son ergonomie, sa convivialité, et la facilité pour sa mise
en oeuvre et d'interprétation le rendent accessible à des utilisateurs non statisticiens.
Malgré la simplicité du logiciel, il n’est néanmoins pas un outil se résumant à de simples
"clicks ", il permet à l’utilisateur les possibilités de saisir ses propres paramètres.
Les résultats fournis par l'outil sont clairs et compréhensibles : ils ne contiennent pas trop de
termes techniques et statistiques par exemple.
SODAS est un logiciel permettant l’analyse des données symboliques.
L’objectif principal de SODAS est d’expliquer un ensemble de concepts définis dans la base
de données. En effet, à partir de l’ensemble des variables expliquant les individus de la base de
données, on construit des concepts.
Les concepts peuvent être définis comme étant des substances secondes (second ordre),
contrairement au variables qui sont définis comme des substances premier (principal).
Parmi les exemples qu’on peut citer pour les concepts :
- Catégorie socioprofessionnelle ;
- Buts marqués ;
- Etc.
Ce sont donc des variables qualitatives, qui peuvent être définis dans des intervalles…
Un concept est défini par :
Son intension : Ensembles de propriétés du concept ;
Son extension : Ensembles des individus qui satisfaisant ses propriétés.
Pour l’analyse des données dans SODAS, il faut suivre un ensemble d’étapes :
o Construire une base de données relationnelle (ORACLE, ACCESS, etc.)
o Définir un contexte :
des unités statistiques de premier niveau (habitants, familles, entreprises, etc.) ;
des variables qui les décrivent ;
des concepts (villes, groupes socio-économiques, scénario d'accident,...).
Chaque unité statistique de premier niveau est associée à un concept (par exemple, chaque
habitant est associé à sa ville).
Ce contexte est défini par une requête de la base.
On construit alors un tableau de données symboliques dont les nouvelles unités statistiques
sont les concepts décrits par généralisation des propriétés des unités statistiques de premier
niveau qui leur sont associés.
Ainsi, chaque concept est décrit par des variables dont les valeurs peuvent être des
histogrammes, des intervalles, des valeurs uniques (éventuellement munies de règles et de
taxonomies) etc., selon le type de variables et le choix de l'utilisateur.
Enseignant : M. DIDAY 7 2004 - 2005DATAMINING
Parmi les fonctionnalités du logiciel SODAS :
analyser les données symboliques sous forme d’histogrammes, d’étoiles…
les comparer par des calculs de dissimilarité…
les classifier…
donner une représentation graphique et une description symbolique des classes
obtenues
Elaborer une hiérarchie divisive, une hiérarchie ou pyramide ascendante de
concepts…
donner une représentation graphique plane des classes (ACP…)…
discriminer les classes (analyse factorielle discriminante, arbres de décision)...
Ainsi, le logiciel SODAS peut se résumer par le schéma figure ci-dessous :
Avantages de l’analyse de données symboliques :
L’analyse des données symboliques offre certains avantages par rapport aux approches
classiques.
Enseignant : M. DIDAY 8 2004 - 2005DATAMINING
D’abord, elle peut s’appliquer à des données complexes. En effet, elle part de donnés
symboliques (histogrammes, intervalle…) munies de règles et de taxonomies et fournit en
sortie des connaissances nouvelles sous formes d’objets symboliques.
De plus, elle utilise des outils adaptés à la manipulation d’objets symboliques de
généralisation et spécialisation, d’ordre et de treillis, de calculs d’extension, d’intension et
de mesures de ressemblances ou d’adéquation tenant compte des connaissances sous-
jacentes basées sur les règles et taxonomies.
Ce type d’analyse fournit des représentations graphiques exprimant entre autres la variation
interne des descriptions symboliques. Rappelons qu’en analyse factorielle, un objet symbolique
sera représenté par une zone et pas seulement par un point.
L’interface utilisateur :
Une nouvelle version de SODAS est actuellement disponible. En effet, avant il existait la
version 1.2 de SODAS. Maintenant une nouvelle version 2.5 est disponible.
Pour les deux versions de SODAS, la fenêtre principale se compose de 3 éléments principaux.
Version 1.2 :
1. La barre d’outils de la fenêtre principale comporte 5 menus.
2. La fenêtre Methods de la fenêtre principale propose, par groupe, les différentes
méthodes disponibles.
3. La fenêtre Chaining de la fenêtre principale gère l’enchaînement des méthodes
appliquées à la base choisie.
Enseignant : M. DIDAY 9 2004 - 2005DATAMINING
Version 2.5 :
1. La barre d’outils de la fenêtre principale comporte 5 menus.
2. La fenêtre Methods de la fenêtre principale propose, par groupe, les différentes
méthodes disponibles.
3. La fenêtre Chaining de la fenêtre principale gère l’enchaînement des méthodes
appliquées à la base choisie.
On peut constater qu’il y a un changement au niveau des icônes et de la présentation. Par
exemple, dans la fenêtre Methods, les différentes techniques statistiques sont maintenant
regroupées par méthode. Et on peut choisir la méthode dans le menu déroulant…
Enseignant : M. DIDAY 10 2004 - 2005DATAMINING
Afin d’analyser les données de la base, nous devons enrichir la filière définie précédemment
grâce à des méthodes (Methods).
Nous pouvons, soit utiliser les filières prédéfinies, (Model/Predefined chaining) soit composer
nous même une filière en enchaînant des méthodes issues de la fenêtre Methods.
Pour insérer de nouvelles méthodes, il suffit de cliquer sur Insert Method dans le menu Method
du Chaining. Un carré vide apparaît alors sous l’icône BASE ; il faut alors sélectionner la
méthode à appliquer, dans la fenêtre Methods et la faire glisser jusqu’à l’emplacement vide.
Les méthodes constituant maintenant la filière sont affichées à la suite de l’icône BASE, selon
l’ordre défini par l’utilisateur, dans lequel elles vont s’enchaîner. Chaque méthode est
représentée par une icône à gauche de laquelle se trouve son nom ainsi qu’une description
sommaire.
La couleur de l’icône de la méthode renseigne sur son état :
- Gris : la méthode n’est pas encore paramétrée ;
- Rouge : la méthode est paramétrée.
Il va de soit que les méthodes qui viennent d’être insérées sont grisées.
Chaque méthode est numérotée dans la filière : ce numéro apparaît dans une petite boîte située
à gauche de la méthode.
Une fois encore la couleur nous renseigne, elle indique le statut de la méthode :
1. Gris : la méthode ne peut être exécutée car elle n’est pas paramétrée ;
2. Vert : la méthode est exécutable car elle est paramétrée ;
3. Rouge : la méthode est désactivée. Elle est exécutable mais l’utilisateur en interdit
l’exécution (menu Methods puis Desactive method).
Par la suite, nous devons paramétrer la méthode. Pour cela, il suffit de double-cliquer sur
l’icône de la méthode. Une fenêtre structurée en fiches à onglets s’ouvre : elle regroupe
l’ensemble des différents paramètres de la méthode.
Une fois les méthodes paramétrées, l’affichage de la filière change : toutes les méthodes sont
maintenant exécutables (les icônes sont rouges).
Toute exécution d’une filière doit être obligatoirement précédée de sa sauvegarde (menu
Chaining puis Save chaining as et saisie d’un nom dont l’extension est .fil).
Une fois cette opération effectuée, la filière est exécutée en cliquant sur le sous-menu Run
chaining du menu chaining.
Enseignant : M. DIDAY 11 2004 - 2005DATAMINING
II. Problématique
1. Contexte
Notre analyse est orientée sport professionnel. En effet, nous allons faire une analyse sur des
données concernant le basket-ball professionnel : NBA.
Durant cette analyse, nous allons essayer de définir les critères pertinents permettant d’avoir
les meilleures équipes (les mieux classées) NBA.
Nous allons donc explorer selon certaines techniques et méthodes (les plus pertinentes)
d’analyses existantes dans SODAS pour arriver à cette fin.
Nos données sont organisées, comme il sera expliqué plus en détail dans le point qui suit, selon
une structure permettant cette analyse :
- Joueur ;
- Equipe ;
- Pays ;
- Etc.
Chacune d’entre elles est composée d’un ensemble de variables permettant une exploration
intéressante et optimale des données.
Sources : Les sources de nos enregistrements sont, majoritairement, deux sites :
www.sports.fr (rubriques Basket-ball)
www.nba.com
A noter que pour certaines données (âge, taille,…) qu’on n’a pas trouvé sur ces sites pour
certains joueurs, nous avons donc fais une recherche à travers les moteurs de recherche
(Yahoo, google,…).
Enseignant : M. DIDAY 12 2004 - 2005DATAMINING
2. Description de la base de données
2.1. Le schéma relationnel
Le schéma relationnel de notre base de données est le
suivant :
Remarque : comme notre analyse concerne les équipes NBA, qui sont des équipes
américaines, nous avons jugé raisonnable de garder les termes en anglais. Les noms des tables
et des attributs (variables) sont en anglais. Ces données seront traduites pendant leur
explication dans le point qui suit (2.2) de ce chapitre.
2.2. Description des variables
Voici une description de l’ensemble des variables (attributs) de chacune des tables de notre
base de données :
La table Player :
C’est la table Joueur.
Champs Description
PlayerID Identifiant du joueur (clé primaire)
CountryNo Identifiant Pays (clé étrangère)
PlayerName Nom du joueur
TeamName Nom de l’équipe
Age Age du joueur
Jersey Numéro du maillot
Enseignant : M. DIDAY 13 2004 - 2005DATAMINING
Wage(M€) Salaire (revenu) en millions d’euros
Points Le nombre de points marqués par le joueur
Position La position du joueur dans le terrain (attaque, rebond , centre)
Height Taille du joueur en centimètre
Weight Poids du joueur en kilogrammes
La table Team :
C’est la table Equipe.
Champs Description
TeamNo Identifiant équipe (clé primaire)
TeamName Nom équipe
Foundation Année de fondation de l’équipe
President Le président de l’équipe (club)
CoachNo Identifiant entraîneur (clé étrangère)
ArenaNo Identifiant stade de l’équipe (clé étrangère)
MascotNo Identifiant drapeau de l’équipe (clé étrangère)
Nb_games Nombre de matchs joués
Nb_games_won Nombre de matchs gagnés
Nb_games_lost Nombre de matchs perdus
Standing Classement
Standing_type Type classement (bon, moyen, mauvais)
PointsM Points marqués par l’équipe
PointsC Points encaissés par l’équipe
La table Country :
C’est la table Pays.
Champs Description
CountryNo Identifiant pays (clé primaire)
Country Nom pays
Continent Nom continent
Enseignant : M. DIDAY 14 2004 - 2005DATAMINING
La table Coach :
C’est la table Entraîneur.
Champs Description
CoachNo Identifiant entraîneur (clé primaire)
CoachName Nom de l’entraîneur
CoachAge Age de l’entraîneur
CoachNationality Nationalité de l’entraîneur
La table Arena :
C’est la table Stade.
Champs
Description
ArenaNo Identifiant du stade (clé primaire)
ArenaName Nom du stade
Capacity Capacité du stade
LocationNo Identifiant location (clé étrangère)
Foundation Année de fondation du stade
La table Location :
C’est la table Location.
Champs Description
LocationNo Identifiant location (clé étrangère)
LocationName Nom location (Etat/ville)
LocationPopulation Nombre habitants dans la ville
La table Mascot :
C’est la table Drapeau.
Champs
Description
MascotNo Identifiant Drapeau (clé primaire)
MascotName Nom du drapeau
MascotSpecies Description du drapeau
MascotColor Couleur du drapeau
Enseignant : M. DIDAY 15 2004 - 2005DATAMINING
3. Choix des individus et concepts
L’objectif de cette étude est d’analyser le profil des équipes participant au championnat NBA.
Elle permettra de mieux connaître les particularités des équipes les mieux classées, et les
dissimilarités par rapport à celles en fin du classement.
Les individus c’est à dire l’unité statistique de premier ordre de cette étude sont les joueurs,
qui sont au nombre de 145 à participer au championnat NBA.
Les concepts sont donc les équipes, et elles sont au nombre de 29 dans notre base de données
"NBA.mdb".
4. Les requêtes définissants les concepts
Dans ce point, nous allons présenter la liste des requêtes définies dans la base de données
Access, et qui vont être appelées dans le module DB2SO de SODAS pour l’analyse.
Trois requêtes sont nécessaires pour notre analyse :
1. La requête "Principale" ;
2. La requête "AddSingle" ;
3. La requête "AddTaxo".
Chacune de ces requêtes sera expliquée et présentée sous format SQL (comme dans Access) ;
ci-dessous.
4.1. La requête Principale
Cette première requête renvoie les individus du premier ordre et leur description.
Elle permet ainsi d’extraire de la base de données :
1. Les individus ;
2. Les concepts ;
3. Les caractéristiques des individus.
Voici, en SQL, cette requête :
SELECT
Player.Playername, Team.TeamName, Player.Age, Player.Height, Player.Weight, Player.[Wage
(M€)], Player.Points, Player.Position, Country.Country, Country.Continent
FROM
Team INNER JOIN
(Country INNER JOIN PlayerON Country.CountryNo = Player.CountryNo)
ON Team.TeamName = Player.Teamname;
4.2. La requête addsingle
Cette deuxième requête renvoie les concepts avec la liste des variables les expliquant. Elle
permet donc d’ajouter des variables pour les concepts.
Enseignant : M. DIDAY 16 2004 - 2005DATAMINING
Voici, en SQL, cette requête :
SELECT
Team.TeamName, Team.Foundation, Team.Nb_games, Team.Nb_games_won,
Team.Nb_games_lost, Team.Standing, Team.Standing_type, Team.PointsM, Team.PointsC
FROM
Team;
4.3. La requête Taxonomie
Cette requête permet de faire la taxonomie entre le pays d’origine du joueur et le continent
auquel appartient ce pays.
Voici, en SQL, cette requête :
SELECT
Country, Continent
FROM
Country;
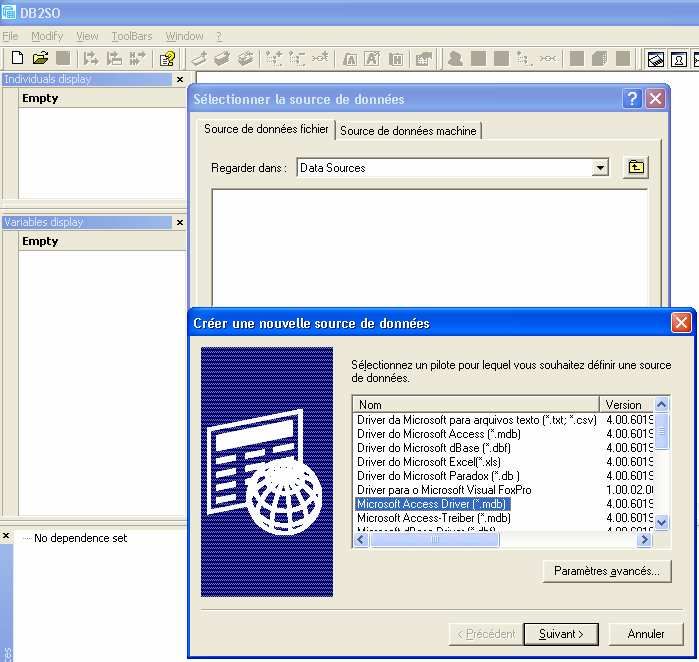
Enseignant : M. DIDAY 17 2004 - 2005DATAMINING III. Utilisation du module DB2SO sous SODAS DB2SO est le module de SODAS qui permet d’extraire les individus de la base de données vers SODAS en créant les concepts correspondants pour chaque groupe de ces individus. DB2SO se base essentiellement pour cela sur la requête « Principale » (précédemment présentée). 1. Création de la connexion Sous SOSAS, on choisit d’importer avec DB2SO sous le menu Import de Sodas File : Cela nous permettra d’importer la base de données Access sous Sodas. Ensuite, sous DB2SO il faut choisir comme source de données le Driver Ms Access : Enseignant : M. DIDAY 18 2004 - 2005
DATAMINING Après, on choisit la base de données "nba.mdb" : 2. Exécution des requêtes Maintenant que la base de données est sélectionnée sous le module DB2SO, il faut exécuter les requêtes pré-établies sous MS Access : Principale, AddSingle, et AssTaxo. Tout d’abord, on commence par l’exécution de la première requête permettant d’extraire les individus. C’est la requête Principale : Enseignant : M. DIDAY 19 2004 - 2005
DATAMINING
Comme on peut le constater,et contrairement à l’ancienne version de SODAS, la nouvelle
version permet d’exécuter les requêtes en sélectionnant tout simplement la requête désirée et
en cliquant sur OK.
Rappel :
La requête exécutée suite à cette procédure est :
Select * From Principale
Le résultat de l’exécution de cette requête est le suivant :
On peut constater que SODAS a importé 8 variables, dont 3 qualitatives (Position, Country,
Continent), et 5 quantitatives (Age, Height, Weight, Wage (M€), Points).
Les 29 assertions (concepts), qui sont les équipes, ont bien été importées par SODAS.
La deuxième requête qui va être exécutée est la requête AddSingle. Cette requête permet
d’ajouter des colonnes de description du concept dans SODAS.
Voici l’exécution de cette requête :
On choisit "Add single-valued variables" dans le menu Modify de DB2SO:
Enseignant : M. DIDAY 20 2004 - 2005DATAMINING
Après, on définit la requête :
La requête exécutée, suite à cette procédure, est la suivante :
Select * From AddSingle
Le résultat de cette requête est le suivant :
On peut constater que les sept variables relatives aux concepts (Foundation, Nb_games,
Nb_games_won, Nb_games_lost, Standing, PointsM, PointsC) ont bien été ajoutées.
La dernière requête à exécuter est AddTaxo. Cette requête permettra d’établir le lien entre le
continent et le pays de chaque joueur. Elle sera utile à SODAS.
Enseignant : M. DIDAY 21 2004 - 2005DATAMINING
La procédure de l’exécution de la requête est la suivante :
Dans le menu Modify de DB2SO, choisir Create a Taxonomy :
Il faut choisir après la requête AddTaxo. Et dans la variable on choisit la variable Country :
La requête exécutée, suite à cette procédure, est la suivante :
Select * From AddTaxo
Enseignant : M. DIDAY 22 2004 - 2005DATAMINING Le résultat de cette requête est le suivant : On peut constater que les 13 nœuds (pays) ont été pris en compte par SODAS. En faisant un view de la taxonomie, on a la fenêtre, comme montré ci-dessus, présentant la structure de la taxonomie. Maintenant, le fichier est prêt pour être exploité sous SODAS. Il faut l’enregistrer et l’exporter. C’est ce qu’on va voir dans le point qui suit. 3. Enregistrement du fichier SODAS Après avoir enregistré le fichier, dans lequel les requêtes ont été exécutées, on doit l’exporter sous format SODAS pour qu’il soit exploité dans SODAS. Pour cela, on fait Export sous le menu File de SODAS : Le logiciel SODAS nous propose de nommer le fichier… Enseignant : M. DIDAY 23 2004 - 2005
DATAMINING
IV.Utilisation des méthodes de SODAS pour l’analyse des
données
Sous SODAS, dans la fenêtre Chaining on double click sur BASE pour choisir le fichier
SODAS exporté et enregistré au préalable :
Ensuite, pour chaque méthode, il suffit de cliquer avec le bouton droit sur la base dans la
partie Chaining et faire Insert Method pour insérer une méthode d’analyse.
Ensuite, il suffit de glisser la méthode depuis la fenêtre Methods dans le Chaining.
Par exemple, pour la méthode View, voici sa représentation :
Ensuite, il faut définir les paramètres de la méthode, et l’exécuter.
1. La méthode VIEW (SOE dans l’ancienne version) :
1.1. Présentation de la méthode VIEW :
La méthode VIEW permet à un utilisateur à partir d’un fichier SODAS, de sélectionner les
objets symboliques avec la liste des variables qualitatives et quantitatives correspondantes
qu’il veut analyser, il peut ensuite les visualiser sur un tableau croisé ou sous forme de
graphiques 2D ou 3D (étoile Zoom).
Enseignant : M. DIDAY 24 2004 - 2005DATAMINING
Ces visualisations graphiques existent en deux modes. En effet il est possible d’afficher un
graphe par concept ou d’afficher l’ensemble des concepts dans le même graphe afin de
faciliter leur comparaison.
Dans le cadre de notre étude, nous avons jugé intéressant pour notre analyse de retenir deux
équipes en haut du classement, une au milieu et deux en bas du classement. Cela nous
permettra de connaître et découvrir les critères permettant d’avoir les meilleures équipes en
NBA.
1.2. Application de la méthode VIEW
On choisit les paramètres de la méthode : Variable et objets symboliques. Ceci en cliquant avec
le bouton droit sur la méthode insérée dans la fenêtre Chaining ou en double cliquant sur la
méthode.
Ensuite, on exécute la méthode (bouton droit puis execute Method ou click sur F5) pour obtenir
le fichier exécuté.
Voici un écran après représentant la fenêtre Chaining après l’exécution :
Remarques : Comme vous pouvez le constater, ici pour la méthode DSTAT, par la suite il
suffit de refaire la même procédure comme pour VIEW pour insérer n’importe quelle
méthode et l’exécuter. C’est ce qui permet de construire un Chaining (un enchaînement de
méthode) qu’on peut exécuter en une seule fois ou bien méthode par méthode.
A droite de view, on peut voir deux icônes :
- La première sous forme de fichier : le fichier d’exécution ;
- La deuxième sous forme d’écran : les résultats de l’exécution.
Il suffit après de cliquer sur l’icône rouge pour avoir le résultat.
Au début, un tableau représentant les données obtenues est affiché. Il a la forme suivante :
Enseignant : M. DIDAY 25 2004 - 2005DATAMINING
Les variables (Height, Weight,…) et objets symboliques (Equipes) affichés sont ceux choisis
dans les paramètres de la méthode. Il peuvent être changés (réduits ou augmentés) en allant tout
simplement dans le menu Selection>Variables du VSTAR (Etoile Zoom).
Comme nous l’avons mentionné précédemment, nous allons nous limiter pour notre analyse
VIEW à deux équipes (objets symboliques) du haut du classement, une au milieu et deux en
bas du classement. Et ce dans le but de savoir Qu’est ce qui fait le bon classement des unes et
le mauvais des autres ?
Les équipes choisies, donc, sont :
1. Phoenix Suns : 1ère du classement ;
2. Miami Heat : 2ème du classement ;
3. Washington Wizards : 11ème du classement ;
4. New Orleans Hornets : 28ème du classement ;
5. Atlanta Hawks : 29ème du classement (dernière) ;
En appliquant les graphiques de l’étoile Zoom, nous obtenons les résultats suivants :
Voici le graphique, en 2D des deux premières équipes (Phoenix Suns 1ère du classement, et
Miami Heat, 2ème du classement) :
Enseignant : M. DIDAY 26 2004 - 2005DATAMINING Les mêmes équipes représentées en 3D : Maintenant, on va refaire les mêmes représentations pour les deux dernières équipes (New Orleans Hornets, 28ème du classement, et Atlanta Hawks, dernière du classement). D’abord, en 2D : Enseignant : M. DIDAY 27 2004 - 2005
DATAMINING Ensuite en 3D : Maintenant, on va superposer les données de certaines équipes 2 à 2 pour confirmer et mieux représenter notre analyse. D’abord, la première (Phoenix) avec la dernière (Atlanta) : Enseignant : M. DIDAY 28 2004 - 2005
DATAMINING Ensuite, la première (Phoenix) avec la onzième (Washington) : Enseignant : M. DIDAY 29 2004 - 2005
DATAMINING
Et enfin, la onzième (Washington) avec la dernière (Atlanta) :
1.3. Interprétation des résultats
Les différents graphes (ci-dessus) élaborés à partir de la méthode VIEW de SODAS nous ont
permis d’identifier des variables qui présentent des similitudes, et ce entre les équipes situées
au même niveau du classement, notamment la variable âge.
En effet, nous avons remarqué que pour les équipes ayant un bon classement, les joueurs ont un
intervalle d’âge plus large que celui des équipes en bas de classement.
D’autant plus que l’âge minimum dans les équipes bien classées est très inférieur à celui des
équipes mal classées. Par exemple, l’âge minimum de l’équipe Phoenix, première du
classement, est de 22 ans. Alors que pour celui d’Atlanta, dernière du classement, il est de 27
ans.
Nous avons aussi constaté que les équipes mal classées, à l’exception d’une seule équipe (New
Orleans), n’ont pas des joueurs dans la position Guard (Arrière). Contrairement aux équipes
bien classées, qui ont en plus des joueurs en attaque (Forward), ils ont des joueurs Guard.
Cependant, certaines variables comme le continent d’origine des joueurs, ne semble pas
influencer sur le classement des équipes.
Enseignant : M. DIDAY 30 2004 - 2005DATAMINING
2. La méthode DSTAT :
2.1. Présentation de la méthode DSTAT
Cette méthode permet d’appliquer aux objets symboliques contenus dans une base de type
SODAS plusieurs méthodes de statistique élémentaire.
Elle permet d’étudier la répartition des données variable par variable indépendamment des
concepts.
2.2. Application de la méthode DSTAT
Pour appliquer la méthode DSTAT. Il suffit comme indiqué auparavant de rajouter la méthode
dans le Chaining et de l’exécuter.
La première variable que nous avons choisit d’étudier avec cette méthode est la variable Age
Nous obtenons les répartitions suivantes :
Voici le résultat de l’application de la même méthode pour la variable Height (Taille) :
Enseignant : M. DIDAY 31 2004 - 2005DATAMINING
2.3. Interprétation des résultats
Le premier graphe (concernant Age) permet de confirmer le résultat constaté avec la
méthode précédente (view).
En effet, nous remarquons clairement que plus l’équipe est bien classée plus l’intervalle
d’âge de ses joueurs est plus grand. De plus, nous constatons que la majorité des joueurs de
la NBA ont moins de trente ans.
Cependant, le second graphe "Height" (concernant la Taille) ne nous a pas confirmé notre
hypothèse sur un éventuel rapport entre la taille des joueurs et le classement de l’équipe.
En effet, il semblerait que cette variable n’a pas trop d’influence sur le classement des
équipes alors que nous étions persuadé du contraire.
3. La méthode TREE
3.1. Présentation de la méthode TREE
Cette technique est très utilisée en datamining. Elle est employée en classification pour
détecter des critères permettant de répartir les individus d’une population en n classes
(souvent n=2).
Il faut donc choisir la variable qui sépare le mieux possible les individus d’une classe. Ceci
permet de construire des nœuds résultants de cette séparation. Ensuite, on réitère le même
processus sur ces nœuds en les considérant comme de nouvelles classes jusqu’à atteindre la
séparation maximale ou celle souhaitée. A la fin, on a au niveau des nœuds terminaux
(feuilles) des individus constitués majoritairement d’une seule classe. L’individu est
affecté à une feuille s’il vérifie fortement les critères permettant d’atteindre cette feuille.
On obtient une nouvelle liste d’objets symboliques qui permet d’assigner de nouveaux objets à
une classe.
Enseignant : M. DIDAY 32 2004 - 2005DATAMINING
3.2. Application de la méthode TREE
Comme cité auparavant, il faut séparer les individus. Le problème se pose au niveau du choix
de la meilleure séparation.
Pour cela, plusieurs critères, dont certains ont été vus dans le cours, sont utilisés. Le plus utilisé
est celui de Gini qui peut être appliqué à tous les types de variables explicatives.
Cet indice est le suivant : IG = 1 − ∑ fi ² avec fi : fréquences dans les nœuds à prédire.
i
Il faut essayer donc de minimiser cet indice.
Dans SODAS, nous avons choisi les critères suivants :
- Profondeur de 4 ;
- Pure et non flous ;
- Critères de séparation de GINI ;
- Séparation minimale en 2 noeuds ;
- Taille minimale de classes non pures de 2 ;
- Taille minimale de nœuds descendants (droite et gauche) de 1 ;
- Sans pourcentage de tests.
L’utilisation de la méthode Tree donne le résultat suivant :
+ --- IF ASSERTION IS TRUE (up)
!
--- x [ ASSERTION ]
!
+ --- IF ASSERTION IS FALSE (down)
Enseignant : M. DIDAY 33 2004 - 2005DATAMINING
+---- < 4 >Good_stand ( 1.00 4.00 1.00 )
!
!----2[ Age bad_stand ( 5.00 0.00 0.00 )
!
!----1[ Wage_(M€) Good_stand ( 0.00 4.00 3.00 )
! !
!----3[ Age Medium_stand ( 3.00 2.00 6.00 )
Vous pouvez vous référer à la version électronique pour voir le document (résultat Tree).
Document WordPad
3.3. Interprétation des résultats
Le tableau ci-dessous explique les classes obtenues de la méthode Tree :
Type classement Revenus Age
Good_stand (bon classement) [Wage_(M€) 28.000000]
Bad_stand (mauvais classement) [Wage_(M€) 27.000000]
On peut donc toujours confirmer que l’âge joue un rôle très important pour le classement des
équipes.
On peut aussi conclure que les équipes ayant des joueurs avec des revenus supérieurs à 4 M€
sont soit au bon classement ou au milieu du classement, et non au mauvais classement.
4. La méthode PYR
4.1. Présentation de la méthode PYR
La méthode PYR pour pyramide de SODAS permet de caractériser les classes en les organisant
sous forme de paliers.
Selon les critères définis, cette méthode représente les classes et situe les objets les uns par
rapport aux autres.
L’algorithme commence depuis la base pour atteindre le sommet. Dans un échantillonnage
pyramidal symbolique, chaque échantillon formé est défini non seulement par l’ensemble de
ses éléments (extension) mais aussi par l’objet symbolique, qui décrit ses propriétés (intention).
L’intention est déduite du prédécesseur au successeur, formant une structure d’héritage. La
structure permet d’identifier les concepts intermédiaires, en d’autres termes, les concepts qui
relient les classes bien identifiées.
Enseignant : M. DIDAY 34 2004 - 2005DATAMINING
4.2. Application de la méthode PYR
En appliquant la méthode PYR, nous avons les résultats suivants :
Enseignant : M. DIDAY 35 2004 - 2005DATAMINING
4.3. Interprétation des résultats
La pyramide permet de constater certains résultats qui peuvent être expliquées par l’existence
de certaines variables.
On peut déjà voir que nos variables représentent une homogénéité pour regrouper les individus
de petits paliers (au début).
Voici certains exemples :
- L’équipe Cleveland, 13ème de classement, est regroupée avec Minesota, qui est 15ème
de classement.
- L’équipe Orlondo, 18ème de classement, est regroupée avec Toronto, qui est 23ème de
classement
- L’équipe New Orleons, 28ème de classement, est regroupée avec Atlanta qui est
29ème de classement.
- L’équipe Denver, 12ème de classement, est regroupée avec Chicago qui est 14ème de
classement.
- Etc.
Donc, on remarque que les distances par rapport aux classements sont bien respectées. Les
variables (âge, taille, etc.) sont par conséquent des variables assurant une bonne comparaison
des équipes selon le classement.
Chaque groupe d’individus est regroupé avec l’individu le plus proche en distance, selon le
classement, dans la pyramide.
5. La méthode DIV
5.1. Présentation de la méthode DIV
La méthode DIV (Divisive Clustering) permet une classification hiérarchique. Au début, une
seule classe compose l’ensemble des objets symboliques. Et procède ensuite par division
successive de chaque classe.
A chaque étape, et suivant une question binaire, chaque classe est divisée en deux classes ;
Ceci permet d’obtenir le meilleur partitionnement en deux classes, conformément à
l’extension du critère d’inertie.
L’algorithme se termine après k-1 divisions, où k représente le nombre de classes données
en entrée par l’utilisateur. DIV maximise la distance inter-classe et minimise la distance intra-
classe.
Enseignant : M. DIDAY 36 2004 - 2005DATAMINING
5.2. Application de la méthode DIV
Le résultat de l’application de cette méthode est le suivant :
-------------------------------------------------------
BASE=C:\Program Files\DECISIA\SODAS version 2.0\Tmp\DGSX5P01.CMD nind=29
nvar=16 nvarsel=2 nvarcoup=2
METHOD=DIV ASSO VERSION=02 DATE=02/24/03
-------------------------------------------------------
THE SELECTED SPLIT-VARIABLES ARE:
--------------------------
(1): Age
(2): Height
VARIANCE OF THE CRITERTION-VARIABLES:
------------------------------------
Age : 15.601665
Height : 47.570749
- the number noted at each node indicates
the order of the division
- Ng yes and Nd no
+---- Classe 1 (Ng=7)
!
!----2- [HeightDATAMINING
6. La méthode PCM
6.1. Présentation de la méthode PCM
Le but de l’Analyse en Composantes Principales (ACP) est de réduire l’espace de dimension
en déformant le moins possible la réalité.
En effet, lorsque nous avons un nombre significatif de variables (individus) initiales (même 4),
le problème qui se pose est comment les représenter dans un espace ? Et comment en faire un
graphique ? C’est difficile dès que l’espace de dimensions dépasse 2. D’autant plus que le
cerveau humain est relativement limité à un espace 3.
Le but principal de l’ACP, est donc de réduire l’espace d’étude en déformant le moins
possible les données initiales. Cela en faisant un résumé pertinent des données initiales.
Ce résumé est réalisé grâce à la matrice de variance – covariance ou celles des corrélations,
parce qu’on analyse essentiellement la dispersion des données considérées. Si la métrique
euclidienne est celle qui a été utilisée dans l’espace des individus (calcul de distance), on
utilise la matrice de "variance – covariance". Si les unités de mesure ne sont pas les mêmes
pour toutes les variables, et que l’on a choisi la métrique "inverse des variances", c’est la
matrice de corrélations qui est utilisée.
Cela facilitera par la suite la compréhension et l’interprétation, par l’utilisateur, des données
analysées.
6.2. Application de la méthode PCM
Les résultats de l’application de cette méthode sont les suivantes :
D’abord avec VPLOT :
Enseignant : M. DIDAY 38 2004 - 2005DATAMINING Enseignant : M. DIDAY 39 2004 - 2005
DATAMINING
V. Les "pépites" de l’analyse
Cette étude nous a permis de tirer un certain nombre de constatations sur les le profil des
équipes du championnat NBA et d’identifier quelques paramètres qui expliquent en partie leur
classement, voici l’essentiel de ces conclusions :
- Contrairement à toutes nos attentes la taille des joueurs ne semblent pas être le
principal facteur dans le bon classement d’une équipe de la NBA, cependant nous
avons pu constater que la majorité des joueurs sont de taille supérieure à 1m98.
- Le pays d’origine des joueurs ne présente pas un facteur intéressant dans le
classement des joueurs, surtout que la majorité des joueurs professionnels de la
NBA sont de nationalités américaines.
- Les joueurs des équipes du haut du classement ont un intervalle d’âge assez
grand, ce qui peut vouloir dire qu’une équipe disposant de seulement de joueurs
assez âgés, donc plus expérimentés, ne lui garantit pas d’être une bonne équipe
et même chose pour celles qui n’ont que des joueurs jeunes et sans trop
d’expérience.
- Le salaire des joueurs semble avoir une grande influence aussi sur les résultats des
équipes essentiellement pour les jeunes joueurs (cf. résultats Tree).
- La position des joueurs sur le terrain semble avoir un intérêt (cf. méthode View).
En effet, nous avons constaté que la majorité des équipes n’ayant pas de joueurs
en Guard (arrière) ne sont pas bien classées. Contrairement aux autres ayant des
joueurs dans cette position.
Cette remarque ne peut être confirmée qu’en faisant des analyses sur d’autres
championnats ou saisons…Cela veut dire plus de données. En effet, certaines
équipes (très rares) qui ne sont pas bien classées ont des joueurs dans cette position
(moins que les biens classées ou égales).
Enseignant : M. DIDAY 40 2004 - 2005DATAMINING
Conclusion
Au cours de ce projet, nous avons pu développer et pratiquer les connaissances en
Datamining que nous avons pu acquérir durant le cours.
Aussi, nous avons utilisé un logiciel (SODAS) qu’on peut positionner parmi les logiciels qui
sont puissant sur ce marché, et ce pour :
Sa simplicité ;
Ses diverses méthodes d’analyse ;
Ses résultats qui sont clairs ;
Etc.
De plus, le sujet que nous avons choisi (Basket-ball professionnel) est très intéressant dans la
mesure où il peut être appliqué et utilisé dans la vie courante (pronostic), notamment pour les
analyses dans le cadre sportif.
Le projet nous a aussi permis d’apprendre qu’en Datamining il ne faut jamais faire des
jugements (analyses) préalables avant de faire une exploration des données.
Par exemple, et c’est le cas de la plupart des gens, nous étions persuadé que la taille des joueurs
avait un rôle très important pour le classement des équipes.
En effet, on supposait que pour être bien classé dans les championnats de basket-ball, il ne faut
avoir que des joueurs de grandes tailles.
Mais, nous étions étonnés de connaître que la dispersion de l’âge est un critère très important.
Enfin, comme nous avons eu une formation en décisionnel, on peut conclure que faire des
entrepôts de données, des modélisations,…sans du datamining derrière pour analyser et
explorer les données peut être fatal par la suite car certains bénéfices et avantages peuvent
être omis, et d’autres risques peuvent ne pas l’être…
Mieux vaut prévenir que guérir !
Enseignant : M. DIDAY 41 2004 - 2005Vous pouvez aussi lire

















































