DERNIÈRES INNOVATIONS ET TENDANCES DANS LE CALCUL HAUTES PERFORMANCES - COSINUS ROMAIN CASTA ANNAÏG PEDRONO - IMFT
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

CoSiNus
Dernières innovations et tendances
dans le
Calcul Hautes Performances
Romain CASTA – Pierre ELYAKIME
Annaïg PEDRONO – Hervé NEAU
https://www.entreprises.gouv.fr/num
erique/secteur-du-
numerique?language=en-gb
15 mars 2018 1
Introduction
Présentation suivie d'une discussion sur les dernières innovations et tendances dans le
Calcul Hautes Performances suite à nos participations :
• au congrès SuperComputing 17 (Annaïg, Pierre, Hervé)
• à la formation HPC SC Camp 2017 (Romain)
dégager les grandes tendances du HPC et du supercomputing et de voir dans quelle mesure
la CFD ou le traitement d'images peut en profiter
Thèmes abordés
- Big Data/Data science, Intelligence Artificielle et Machine / Deep Learning (Pierre)
- Les évolutions hardware : de plus en plus de cœurs mais … Top500, Exascale (Hervé)
- Les conséquences des évolutions Hardware sur les applications (Annaïg)
- Parallélisation hybride, MPI3 (Romain)
2
SuperComputing 2017
Plus grand congres mondial sur le SuperComputing (Denver)
• ~10 000 participants
• des conférences plénières filmées (7000 places assises)
• Un hall d’exposition avec tous les intervenants du HPC
• 40 présentions en parallèle, un hall posters
Photos SC17
3
SuperComputing 2017 Photos SC17
4
https://www.lemondeinformatique.fr/act
ualites/lire-q-network-ibm-concretise-l-
informatique-quantique-avec-ses-clients-
70427.html
Big Data – Data Science
Intelligence Artificielle
Machine Learning / Deep Learning https://www.startechnormandy.com/b
log/intelligence-artificielle-non-neutre
Machine Quantique
Pierre
5
Big Data – Data Science
http://startupradar. https://www.lebigdata.f
asia/tag/agriculture r/definition-big-data
Big Data = le pétrole de notre ère digitale : explosion quantitative des données numérique 2,5
quintillions (1030) d’octets de données par jour (mail, vidéos, photos, informations climatiques,
signaux GPS, enregistrement d’achats en ligne, etc )
Besoin de traiter et de valoriser le Big Data: naissance de la Data Science
https://www.esaip.org/metiers/numerique/big-data/
Les solutions logicielles et les architectures matérielles actuelles sont elles assez puissantes pour
relever les défis de plus en plus ambitieux de la Data Science ?
⇒ Mutation cognitive (IA, Machine Learning, Deep Learning)
⇒ Convergence HPC Big Data
⇒ Mutation Quantique
6
Intelligence artificielle - Machine Learning
I.A. : « ensemble de théories et de techniques pour réaliser des machines capables de simuler
l'intelligence » - Fait appel à la neurobiologie computationnelle : particulièrement aux réseaux de
neurones, à la logique mathématique et à l’informatique
Machine Learning (ML) : approche statistique de l’IA, concept mis en place par le mathématicien
Alan Turing vers 1950. Il imagine une machine capable d’apprendre, une « Learning Machine »
=> Algorithmes d’apprentissages automatiques Machine Learning qui ont la faculté de
s’auto-organiser pour améliorer leur pouvoir prédictif
Machine Learning :
- Réseaux de neurones profonds (deep learning)
- reconnaissance d’images
- vision par robotique
- adaptative boosting (AdaBoost: détection des
visages en temps réel)
- etc.
https://www.lebigdata.fr/machine-learning-et-big-data
7
Machine Learning - Deep Learning
Deep Learning : technique de Machine Learning qui se base sur la modélisation des circuits biologiques
des neurones pour construire une méthode par apprentissage automatique. Plus le nombre de neurones
est élevé, plus le réseau est profond
https://www.nextplatform.com/2017/03/21/can-fpgas-beat-
gpus-accelerating-next-generation-deep-learning/
Reconnaissance faciale de facebook, synthèse vocale (traduction orale en temps réel de Skype ou
Google), création de la machine intelligente AlphaGo par Google DeepMind
Mais aussi … en science : les algorithmes d’apprentissage construisent seuls le modèle optimal
pour décrire un phénomène sans aucune règle prédéfinie à partir d’une masse de données
traitement d’images, du son, de la vidéo robotique domaine de la santé …
8
Impact de l’IA
L’IA est en train de transformer les industries :
santé, finance, science, énergie, transport, …
SC17 : Nvidia
… et révolutionne le HPC : https://software.intel.com/en-us/articles/machine-learning-on-intel-fpgas
Simulation numérique -> Industries Automobile, aéronautique, chimie, cosmétique, …
Nouveau domaine d’application: le High Performance Data Analytics (convergence Big Data HPC) :
le Big Data Analytics et l’IA ont maintenant recours au HPC
=> Mise au point de framework (environnement de développement) libre et open source pour faciliter la
création d’applications distribuées (stockage de données, traitement parallèle) : Hadoop, MapReduce, …
=> La convergence HPC Big Data implique des solutions matérielles HPC plus performantes
9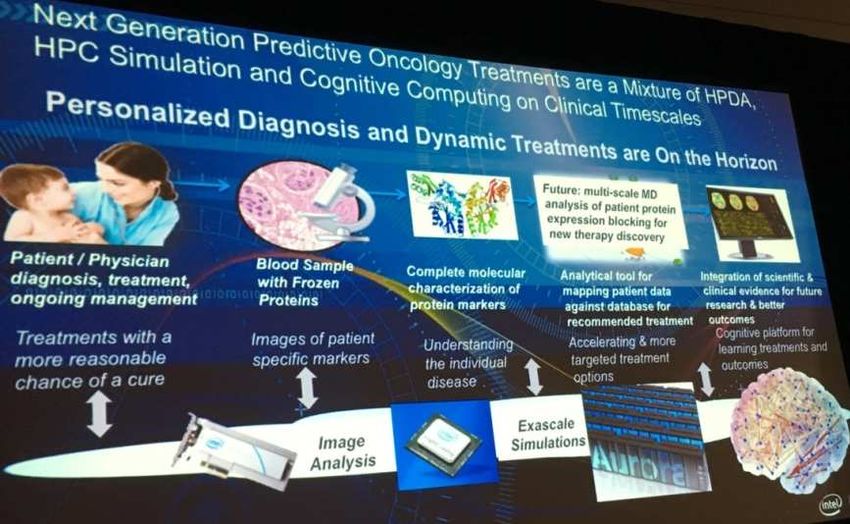
Convergence HPC Big Data https://software.intel.com/en-
us/xeon-phi/x200-
processor/remote-access
Architecture hybride sur laquelle sont installées :
Processeurs multi-cœurs : fréquence élevée de 1,5 à 3 GHz (1,5 à 3 millions d’opération/sec.) avec plusieurs
cœurs (24 pour Intel Xeon Skylake et pour Power 9 d’IBM, …)
Cartes Manycore : Volta avec NVLINK de Nvidia (processeurs graphiques), Xeon Phi génération Knight’s
Landing (KLN) d’Intel, FirePro S d’AMD
Processeur avec puce graphique intégrée : Kaby Lake d’Intel et AMD (pour fin 2018)
FPGA : circuits intégrés reprogrammables sur lesquels plusieurs
tâches peuvent être lancées en parallèles
https://www.wxwenku.com/d/337318
http://drsalbertspijkers.blogspot.fr/2017/03/ibm-power-9-cpu-game-changer.html
https://www-03.ibm.com/systems/fr/power/hardware/
⇒ Efficacité des machines HPC pour des problèmes Big Data démontrée au SC17
• deep learning sur clusters GPU,
• plugin Harp de Hadoop avec la librairie d’Intel DAAL sur un algorithme d’exploration de sous-graphes
utilisant les architectures d’Intel Xeon et Xeon phi,
• tests sur les algorithmes de ML Kmeans et Graph Layout sur 4096 cœurs du super calculateur IU Big Red II
10Machine Learning et la science
Utilisé par la science qui possède du Big Data : cosmologie (télescopes, satellites, …), météorologie
(intempéries, cyclone, …), médical (génome, problème avec la politique de confidentialité des
données Google DeepMind), …
- une analyse génomique à partir d’un traitement HPC de nombreux flux de données permet
d’établir un lien entre séquence d’ADN et maladie
- Aide au diagnostic de maladies
- Agriculture : développement de nouvelles variétés génétiques plus résistantes,
optimisation des conditions en termes de champs, de sol et de climat
- Projet Square Kilometer Array (SKA), cartographie du ciel plus en détail :
50 pétaflops de traitement dédié, 10 pétaoctets par jour, …
Apprentissage via le mooc de Google : udacity
Librairie de Deep Learning : Intel DAAL
Librairies de Machine Learning : TensorFlow (Google), NNabla (Sony),
Matlab, python avec Scikit Learn http://www.johncanessa.com/category/tensorflow/
!! Le Machine Learning n’est pas encore une science exacte : boîte noire dont
on ne contrôle rien (Google Deep Mind), donne parfois des résultats absurdes :
une IA de facebook crée son propre langage et est débranchée par les chercheurs, ...
11Machine Learning et la science
Algorithmes de ML en science: problème de classification et de régression
- Linear Regression (régression linéaire)
- Logistic Regression (régression logistique)
- Decision Tree (arbre de décision)
- Random forest (forêts d'arbres/arbres aléatoires)
- SVM (machines à vecteur de support)
- Naive Bayes (classification naïve bayésienne)
- KNN (Plus proches voisins): application directe à la segmentation
- Gradient Boost & Adaboost
- Dimensionality reduction
- Q-Learning
- Réseaux de neurones
Pour aller plus loin: makina-corpus
12Machine Learning au SC 17
Application médicale (oncologie, imagerie médicale, analyse d’images
volumétriques)
Cosmologie, Industrie automobile, …
Convergence HPC Big Data
SC17 - Nvidia - SKA
13Evolution Hardware: la machine quantique
Limites actuelles :
Microprocesseur binaire : l’information circule sous la forme de très faibles
courants électriques ne pouvant être que dans deux états possibles 0 ou 1 : le bit !
Architecture séquentielle : ces circuits ne gèrent qu’un calcul à la fois
« Goulot de Von Neumann » : lorsque la quantité d’informations est trop grande face à la fréquence
du microprocesseur : goulot d’étranglement !
L’avenir du « Hardware » pour le Data Science: la Machine Quantique SC17 -
http://hexus.net/tech/news/indus
try/86177-intel-puts-us50-million-
L’unité élémentaire est le Qubit qui peut prendre à la fois les états 0 et 1 quantum-computing-research/
Un circuit composé de 50 Qubits
peut être à la fois dans 2 états
différents : un calcul effectué
par ce circuit est réalisé sur chacun
de ce million de milliards d’états =
Architecture parallèle
14Machine Quantique
Encore à l’état de recherche : Projet IBM avec le Qubit électronique vs Projet Monroe
avec le Qubit ionique
Le projet D-Wave avec le Qubit à boucle a été commercialisé,
mais il n’a pas été démontré qu’il était quantique …
Architecture parallèle faite pour traiter le Big Data avec des algorithmes
de réseaux de neurones approfondis
Au SuperComputing 17 :
Simulation d’un circuit à 45 Qubits sur le super calculateur Cori II en utilisant 8192 nœuds et 0.5
pétaoctet de mémoire : permet un étalonnage crucial; la plus grande simulation de circuits
quantiques
Planification dynamique des tâches dans les plateformes HPC basée sur la simulation et
l’apprentissage automatique pour obtenir des politiques d’ordonnancement dynamique
https://www.hardwareluxx.de/inde
Nouveauté: Bristlecone (Google) 72 Qubits, x.php/galerie/komponenten/prozes
soren/google-bristlecone-
aucune simulation avec un super ordinateur possible quantenchip-.html
15http://www.zdnet.com/article/intel-takes-its-next-
Les évolutions hardware step-towards-exascale-computing/
De plus en plus de cœurs mais …
Top500, Exascale
Hervé
https://iotbusinessnews.com/tag/strategy-analytics/
16Evolutions Hardware
Loi de Moore : Le nombre de transistors que l’on peut mettre à un coût raisonnable sur un
circuit imprimé double tous les 18/24 mois
Consommation électrique : Puissance électrique dissipée ~ fréquencen
Limitations : refroidissement + coût de l’énergie => Efficacité énergétique cruciale
SC17
⇒ La fréquence des processeurs stagne : fmax ~ 3 GHz (1er Top 500 ~20MW/an ~20M€/an)
⇒ Besoin de refroidissement efficace et bon marché : ~30% de la dépense énergétique
Refroidissement par immersion des cartes dans un
liquide électriquement neutre, et refroidi
On amène de l’eau froide directement sur le point chaud,
mais l’eau reste isolée de l’électronique
On refroidit par eau une « porte/grille »
dans laquelle circule un flux d’air
https://www.zurich.ibm
.com/st/energy_efficien
cy/zeroemission.html https://news.filehippo.com/2013/11/liquid-
cooling-cuts-costs-heats-building-innovation-
centre/
https://submer.com/data-center-cooling-methods/
17Evolutions Hardware
https://en.wikipedia.org/wiki/Moore%27s_law
Part de marché des processeurs :
Intel : 94%, AMD : 1%, …
18Evolutions Hardware
http://www.idris.fr/media/formations/hybride/form_hybride.pdf
19Evolutions Hardware : Multicore et Manycore
⇒ Multicore : le nombre de cœurs par puce augmente
Intel Skylake : 24 cœurs (48 threads) – 1,5TFLOPS
AMD EPYC 32 cœurs
Intel KNL 72 cœurs https://people.eecs.berkeley.edu/~y
elick/talks/data/MoreData-VT14.pdf
IBM Blue Gene/P 450 cœurs/chips
⇒ Manycore :
accélérateur graphique/GPGPU, Intel Xeon Phi, MIC, ARM, …
=> Ratio Gflops/€ imbattable mais performances crête inatteignables
Nvidia Tesla V100 : CUDA Cores 5120 - Tensor Core 640 - 16 GB 900 GB/s - 12 nm - 7,5 TFLOPS FP64
⇒ Le memory wall : débit vers la mémoire , puissance-nb cœurs , latences mémoire
- De plus en plus de cycles de procs à attendre les données
- De plus en plus difficile d’exploiter la performance des processeurs
⇒ Performances dominées par la disponibilité et l’équilibre des ressources
⇒ Solutions partielles : ajout de mémoires caches, parallélisation des accès mémoire
20Evolutions Hardware
GFLOPS = nombre de milliards
d’opérations par seconde
http://www.info.univ-angers.fr/~richer/cuda_crs1.php
21Evolutions Hardware
CPU Accélérateurs GPU
2000 NetBurst (Pentium 4) 800–3466 MHz 180 nm
2003 Pentium M 400–2133 MHz 130 nm NV30
2006 Intel Core 3333 MHz 65 nm G70/G80
2008 Nehalem 3600 MHz 45 nm Tesla C2050 (CUDA)
2010 Westmere 3730 MHz 32 nm Fermi
2011 Sandy Bridge 4000 MHz 32 nm
2012 Ivy Bridge 4000 MHz 22 nm http://igm.univ-
mlv.fr/~dr/XPOSE2011/CUDA/
2013 Haswell 4400 MHz 22 nm caracteristiques.html
2014 Broadwell 3700 MHz 14 nm
2015 Skylake 4200 MHz 14 nm Xeon Phi
2016 Goldmont 2600 MHz 14 nm Pascal
2017 Goldmont Plus 2800 MHz 14 nm Volta, PEZY-SC2*
2018 Cannonlake ? MHz 10 nm
KNL (Xeon Phi2), Kaby Lake G : CPU+GPU (Intel + AMD)
FPGA (circuits logiques programmables)
https://www.extremetech.com/
- GPU = Manycore => SIMD (Single Instruction, Multiple Data), SIMT (Single Instruction, Multiple Thread) gaming/261297-intel-leaks-
details-new-desktop-core-i7-
- 1 cœur GPU “va moins vite” qu’un CPU et dispose de moins de mémoire 8809g-radeon-graphics
mais accélération grâce au traitement parallèle *PEZY-SC2 : 2048 cœurs par chipset à 0.7GHz
22Evolutions Hardware : coût énergétique
https://spcl.inf.ethz.ch/Publications
/.pdf/hoefler-energy-utah.pdf
23Evolutions Hardware : KNL vs Haswell (NERSC’s Cori Supercomputer)
T. Allen et al., Performance and Energy Usage of Workloads on KNL and Haswell Architectures, SC17
Haswell Xeon E5 2698 : 2.3Ghz, 32 cores (64 log), 2 socket, 128GB 2.1GHz DDR4, 2388 n
Xeon Phi 7250 KNL : 1.4GHz, 68 cores (272 log), 1 socket, 96GB 2.4GHz DDR4 16GB MCDRAM, 9688 n
⇒ Comparer Manycore/Multicore
⇒ Mesure temps CPU et énergie consommée
⇒ Variables : MPI/OpenMP, threads per core
Conclusion :
- Gain moyen performances KNL (6/9) : x1.27
- Gain moyen énergie KNL (9/9) : x1.84 SC17
- Utilisation KNL MCDRAM très performante
⇒ Beaucoup de travail pour obtenir des gains
importants (cache) avec KNL
⇒ Difficultés pour mesurer les temps CPU
variation de la fréquence des cœurs (turbo, Pmax/cœur)
24Evolutions Hardware : Intensité arithmétique / bande passante mémoire
L’architecture des processeurs et mémoire influence fortement les performances des codes
Suivant l’intensité arithmétique, code Memory Bound ou Compute Bound
https://www.codeproject.com/
Articles/1191905/Optimizing-
Application-Performance-with-
Roofline
⇒ Intensité arithmétique = nb d’opérations / quantité de mémoire échangée
⇒ Gros travail des développeurs pour profiter des évolutions hardware https://www.slideshare.net/i
des super-calculateurs : algorithme, parallélisation hybride nsideHPC/atpesc-2017-
track12731845amparkertheta
(MPI+ OpenMP/OpenACC/pthreads/Cuda/…), réutilisation mémoire
25Evolutions Hardware : Vectorisation
AVX-512 32 registres de 512bits / AVX2 16 registres 256 bits https://colfaxresearch.com/skl-avx512/
=> 2x largeur registres, 2x nombre de registres, 2x largeur des unités FMA (fused-multiply add)
26National Supercomputing Center in Wuxi : TaihuLight : 10 millions de cœurs
1st Top500 => 125PFlops, 1310TB memory, Linpack 93PFlops
6 GFlops/W, 17th Green500, 2nd Graph500, 3rd HPCG
Processeur chinois SunWay 260 / Compilateur chinois
40 racks x 1,024 chipsets x 4 groupes de cœurs x 65 cœurs = 10,649,600 cœurs
1er niveau : 163,840 process MPI
2ème niveau : 64 ou 65 threads concurrents 1 chipset
2018 : Sunway Exa-Pilot System
5-10 Tflops per node - 10-20 Gflops/W
2021 : Exa-scale System :
1000 Pflops - 30 GFlops/W SC17 : https://www.asc-
events.org/ASC18/doc/Sunway%20TaihuLight%20Extreme%20Co
Challenge : - How to scale over 10 million heterogeneous cores? mputing%20and%20Big%20Data%20HAOHUAN%20FU.pdf
- How to utilize the different memory hierarchy and resolve the even tougher memory barrier?
- How to migrate the existing science software?
27National Supercomputing Center in Wuxi : TaihuLight : 10 millions de cœurs
Problèmes
Gap entre les logiciels (100T) et le hardware (100P)
Des millions de lignes de codes traditionnels écrites
pour du Multicore mais pas pour du Manycore
Une scalabilité limitée
SC17 : https://www.asc-
Solutions events.org/ASC18/doc/Sunway%20T
aihuLight%20Extreme%20Computin
Réécrire des codes Fortran/OpenACC g%20and%20Big%20Data%20HAOH
UAN%20FU.pdf
en codes par thread en C
Réécrire les communications et les
accès mémoire
Utilisation actuelle :
Applications classiques HPC (Science ->Service)
Utilisation future :
Applications relatives au Deep Learning
28Top 500
SC17 :
https://fr.slideshare.net/top500/
top500-november-2017
Tendance : Plus de parallélisme (Manycore) et Architecture hybride (CPU/GPU)
29Top 500
J. Dongara, In the begining, SC17
Linpack : facile à faire tourner, à
comprendre et à analyser (pb denses Ax=b)
Linpack n’est plus fortement
corrélé aux applications réelles
Retourne des perfs crêtes
Argument marketing SC17 : https://fr.slideshare.net/top500/top500-november-2017
https://www.hpcwire.com/2017/11/13/flipping-flops-
reading-top500-tea-leaves/green500-nov-2017-top5/
Top 500 n’est qu’un aspect d’un
supercalculateur :
- Power consumption : Green 500
- Graph Applications : Graph 500
- Unstructured applications : HPCG
- I/O benchmarcks : IO-500
17 6 TaihuLight 1
30Top 500
845TFlop/s
6-8 years
548TFlop/s
My laptop : 166Gflop/s
https://www.top500.org/news/top500-
meanderings-sluggish-performance-
growth-may-portend-slowing-hpc-market/
PFlops (> 1015 Flop/s) : 181 systems - CPU classiques Intel - CPU classiques + accélérateurs GPU -
Cœurs légers : IBM BG, ARM, Knight Landing, TaihuLight, PEZY-SC2
31Exascale (>1018 Flops/s) : 0 system
https://www.slideshare.net/ultrafilter/algorith
mic-challenges-of-exascale-computing-20121
Exascale chips : thousands of tiny cores and a few large ones
Processors don’t run at the same speed (cache - power/T° mng)
New processors means new softwares : avoiding communication
in iterative solver, avoiding synchronisation, auto-tuning gets kernel
performance near optimal (framework), load balancing with locality
Not all computing problems are exascale but they should be
exascale-technology aware (DOE) https://www.hpcwire.com/2015/07/28/doe-
exascale-plan-gets-support-with-caveats/
32Exascale (>1018 Flops/s) : 0 system
Chine :
2020/21 : 3 supercalculateurs
Etats-Unis (SC17) :
2021-2023 : US DOE (30MW/year)
Europe :
202x https://fr.slideshare.net/schihei/high-performance-
computing-challenges-on-the-road-to-exascale-computing
Exascale computing will deliver science breakthroughs, in simulation
and data analytics but requires advances in models, algorithms andsoftware
Exascale will impact a broad set of applications : science, health, manufacturing,
environment, infrastructure
There are still many algorithmic challenges : deploying
the best numerical methods with the best parallelization
33Exascale
http://orap.irisa.fr/wp-
content/uploads/2017/10/Orap_40eForum
_Philippe_Lavocat.pdf
34https://software.intel.com/en-us/blogs/2016/02/17/what-
is-thread-parallelism-and-how-do-i-put-it-to-use
Les conséquences des
évolutions Hardware
sur les applications
Annaïg
http://le-blog-agpm.fr/a-lhonneur/lemdr-et-la-prazosine-
pour-guerir-de-letat-de-stress-post-traumatique-2/
35Les conséquences des évolutions Hardware sur les applications
L’efficacité énergétique est devenue cruciale
La fréquence des processeurs n’augmente plus voire diminue
Le nombre de cœurs par nœud augmente
Le nombre d’opérations par cycle augmente : vectorisation
(vector width SSE 128 -> AVX 512) et FMA (Fused Multiply Add)
Généralisation des accélérateurs (GPU, Many-core, …)
⇒ Effort important pour améliorer les performances parallèles des codes et/ou pour
franchir le cap du massivement parallèle.
36Comment faire évoluer les applications pour ces nouvelles architectures?
Quelques pistes :
⇒ Programmation hybride (MPI+X)
⇒ Utilisation hétérogène d’un nœud de calcul (Shared time versus space time)
⇒ Plus de souplesse dans l’exécution des jobs parallèles
⇒ Profiter de la vectorisation (intensité arithmétique)
⇒ Calculer en simple précision?
⇒ Espérer que d’autres fassent le travail à notre place en adaptant les langages et les
bibliothèques scientifiques aux architectures hétérogènes…
⇒ Utiliser des méthodes adaptées à l’exascale
⇒ Optimiser la chaîne de calcul dans son intégralité (solveur, pré- et post-traitement)
37Shared time versus space time
L’augmentation du nombre de cœurs permet de mélanger le parallélisme de données
avec le parallélisme de tâches.
Exemple : 16/18 cores d’un nœud sont utilisés pour le parallélisme de données (MPI,
MPI+OpenMP, …). Ce « dépeuplement » permet de moins saturer les accès mémoire.
⇒ des cœurs restants font de l’analyse in situ (statistiques, visu in situ)
⇒ un cœur peut traiter des communications inter-nœuds
⇒…
https://sc17.supercomputing.org/presentation
/?id=post149&sess=sess293
38Vers des jobs de plus en plus économes
L’efficacité énergétique est devenue cruciale et peut conduire à des codes
nécessitant plus de souplesse pour une meilleure utilisation des supercalculateurs
Exemple :
- soumission d’un job avec une fourchette de besoin plutôt qu’un nombre
de cœurs fixé (ex. entre 500 et 1000 cœurs). Dès que les ressources sont
disponibles, le job se lance. Meilleure utilisation du supercalculateur.
- Vers une dotation sur les centres de calcul en Watt.heure plutôt qu’en
heures.CPU pour favoriser l’efficacité énergétique? L’utilisateur attend son
résultat 5% de temps en plus pour un gain de 20% d’énergie grâce à une
baisse de la fréquence du CPU par exemple.
39Comment profiter de la vectorisation?
Code « memory bound » ou « CPU bound »? Le premier réflexe est de « profiler » son code pour en connaître
les caractéristiques. Intel propose un nouvel outil gratuit et très peu intrusif pour un premier diagnostic.
https://software.intel.com/en-us/performance-snapshot
https://software.intel.com/sites/products
/snapshots/application-snapshot/
40Intensité arithmétique (1)
Ia = nombre d’opérations / quantité de mémoire échangée
Gflops/sec atteignables = min(performance « peak », bande passante x Ia )
Si le programme est limité par la bande passante mémoire (memory bounded), il a une
faible intensité arithmétique => utilisation non optimale du CPU => la vectorisation
améliore peu ou pas le temps de restitution.
Essayer d’augmenter le nombre d’opérations effectuées pour chaque octet déplacé
depuis/vers la mémoire. L’augmentation de l’intensité arithmétique a deux effets
majeurs :
- une vitesse de traitement plus élevée
- une meilleure efficacité de la vectorisation
FMA code
vectorized code
Roofline model :
optimisation no AVX, no vectorisation
memory bounded CPU bounded
https://fr.slideshare.net/sjf_dhi/m-britton-fmafinal
41Intensité arithmétique (2)
integer, parameter :: n=655360000
real(kind=8), dimension(n) :: a_vec, b_vec, c_vec, d_vec, e_vec
do i=1,n
a_vec(i)=b_vec(i)*c_vec(i)+d_vec(i)*e_vec(i) boucle 1
enddo
_______________________________________________________
do i=1,n
a_vec(i)=b_vec(i)*c_vec(i) &
+b_vec(i)*d_vec(i) &
+b_vec(i)*e_vec(i) &
+c_vec(i)*d_vec(i) & boucle 2
+c_vec(i)*e_vec(i) &
+d_vec(i)*e_vec(i)
enddo
-no-vec -xAVX
Boucle 1 (0.075 Flop/Byte) 1,03 GFlop/s 1,48 GFlop/s
Boucle 2 (0.275 Flop/Byte) 2,58 GFlop/s 4,15 GFlop/s
Ref : https://www.calmip.univ-toulouse.fr/spip.php?article552
42Calculer en simple précision?
Pour réduire le temps de calcul, l’utilisation mémoire et donc la consommation énergétique, il est
possible d’utiliser la précision mixte. Les variables sont calculées en double précision uniquement
quand c’est nécessaire pour la validité des résultats. La « half precision » apporte des gains
conséquents pour le calcul sur carte graphique.
Influence de la précision flottante sur une carte graphique Volta :
SC17 : Nvidia
Tensor Core 4x4x4 matrix
multiply and accumulate
http://www.electronicdesign.com/automotive/nvidia-s-volta-architecture-gives-drive-px-pegasus-its-smarts
43Nouveaux « Middleware » pour simplifier HPC
=> Emergence frameworks (High-Level Frameworks HLFs) et de nouveaux langages (PGAS,
Domain-specific languages DSLs) utilisables par des scientifiques non spécialistes en HPC.
L’objectif est de réduire la complexité d’écriture de codes parallèles exécutables sur des
architectures hétérogènes. La multiplication du nombre de cœurs nécessite des applications
tolérantes aux erreurs.
- Partionned Global Address Space (PGAS) pour diminuer la complexité d’écriture
des codes distribués. Plusieurs essais plus ou moins concluants : Unified Parallel
C, High Performance Fortran, Chapel, coarray fortran (-> norme 2008)
- Projet JuML (Juelich Machine Learning Library) : permettre aux non-spécialistes
d’utiliser le HPC avec des APIs qui s’adaptent à la machine cible (CPU, GPU, …)
- Méta-programmation pour s’affranchir de la couche matérielle : exemple du
langage JULIA (MIT) construit à partir de LLVM Compiler Infrastructure et
compilé « Just in Time » pour être performant tout en gardant un typage
dynamique
44Performances de Julia comparée aux langages « historiques »
https://eklausmeier.wordpress.com/2016/04/05/performance-comparison-c-vs-lua-vs-luajit-vs-java/
45… mais le Fortran n’est pas mort!
Pourquoi du Fortran en 2018?
- Héritage, premier langage développé pour le calcul scientifique, c’est toujours le langage
de référence pour des gros codes Météo/Climat : NEMO, 4Dvar (NASA), Unified Model,
Meso-NH, …
- facile à utiliser pour des non-informaticiens
- performant
- nouvelles fonctionnalités
• pour le calcul parallèle (coarrays)
• orienté objets
• meilleure interopérabilité avec le C
Inconvénients
- peu attractif pour les informaticiens
- des compilateurs qui tardent à intégrer les nouvelles normes (le fortran 2003 n’est
pas encore entièrement pris en charge par les compilateurs)
46Des méthodes adaptées à l’exascale
Dans le domaine de la mécanique des fluides numériques, deux méthodes sont ciblées
pour des projets « exascale » :
- Lattice-Boltzmann Method (LBM)
- Discrete Element Method (DEM)
Exascale Computing Project (ECP - US Department Of Energy) :
=> MFIX-Exa 10-year target : simulate several minutes of the operation of a multiphase reactor,
containing around a hundred billion particles, in less than twenty-four hours of wall time.
47HPC pour le pré et le post-traitement
https://www.siam.org/news/news.php?id=1598
Ne pas oublier les phases de pré- et post-traitement qui sont souvent
coûteuses en temps et pas toujours parallèles.
48https://fr.slideshare.net/sjf_dhi/m-britton-fmafinal
Parallélisation hybride
MPI3
Romain
https://www.scienceabc.com/humans/the-human-brain-vs-supercomputers-which-one-wins.html
49Programmation hybride
Hier
Calcul scientifique massif à faire => Plusieurs directions/méthodes possibles
OpenMP : Mémoire partagée entre différents processus légers (threads) : parallélisation boucles
MPI : Mémoire distribuée par processus : découpage données
CUDA : Calcul sur carte graphique Exemple MPI/OpenMP
…
Demain et un peu aujourd’hui
Association de plusieurs méthodes
dans des programmes hybrides.
MPI + OpenMP
MPI + CUDA (GPU)
MPI + OpenMP + CUDA (GPU)
MPI mémoire distribuée/partagée
...
Formation IDRIS : Programmation hybride MPI-OpenMP
http://www.idris.fr/media/formations/hybride/hybride_v3-0_fr.pdf
50Programmation hybride
Exemple programmation MPI mémoire distribuée/partagée pour le partage de la
géométrie dans le code de calcul JADIM (IMFT)
Uniquement en MPI/MPI
Fenêtre mémoire d’accès distant : MPI 3.0
51Programmation hybride
Exemple programmation MPI mémoire distribuée/partagée pour le partage de la
géométrie dans le code de calcul JADIM
Création et allocation d’une fenêtre d’accès mémoire par le processus 0 et requête
des autres processus du nœud leur permettant via un pointeur d’accéder
directement à cet espace mémoire.
Mémoire en partie distribuée entre tous les processus et en partie partagée au sein
des processus d’un nœud de calcul => Programmation hybride
Ouverture de fenêtre d’Accès Mémoire
Distant (Remote Memory Access)
possible depuis la norme MPI 3.0.
52Programmation hybride
Exemple programmation MPI mémoire distribuée/partagée pour le
partage de la géométrie dans le code de calcul JADIM
Avantage
Très permissif
Permet en théorie énormément de configurations mémoire possibles.
Facilité de mise en place dans un premier temps. Permet rapidement de
paralléliser des données de calculs.
Inconvénient
Très permissif
Peut générer des erreurs de calculs
dues à des ordres dans l’écriture/lecture
très difficiles à détecter.
53Programmation hybride
Exemple programmation MPI mémoire distribuée/partagée pour le
partage de la géométrie dans le code de calcul JADIM
Similarités avec la programmation hybride MPI/OpenMP
MPI/OpenMP MPI Distribué/Partagé
http://www.idris.fr/media/formations/hybride/hybride_v3-0_fr.pdf
54http://on-demand.gputechconf.com/gtc/2014/presentations/S4672-ansys-fluent-amgx-linear-solver.pdf
http://on-demand.gputechconf.com/supercomputing/2013/presentation/SC3137-NVIDIA-AmgX-Performance-Acceleration-Large-Scale-Iterative-Methods.pdf
55Conclusion
http://bouquivore.fr/infos-presse/bouquinfos/les-billets/ouf/
56Synthèse / Notes en vrac
Part très importante de l’Intelligence Artificielle : gestion de flux (gaz, EDF, homme,
voiture, …), traitement d’images, reconnaissance vocale, détection séismes, météo, …
HPC proprement dit = petite partie du SuperComputing
De plus en plus de cœurs par puce/chipset/processeur : Multicore => Manycore
Un Gros Travail à faire par les développeurs pour tirer partie de ces évolutions hardware !!!
⇒ Méthodologie de développement (Scrum / Kanban, Continuous integrating for scientifics,
github, doxygen, Sphinx)
⇒ Cycle de vie logiciel
⇒ Algorithmique (intensité et extensibilité)
⇒ Parallélisation hybride, vectorisation, réutilisation mémoire, …
⇒ Tolérance aux pannes / erreurs
⇒ Fortran encore et toujours …
Journal of Computational Physics : vers une meilleure acceptation des papiers si le code
source est fourni …
57Synthèse / Notes en vrac
Solutions différentes de visu in situ :
pas de solution parfaite universelle…
M-VTK.org et VTK-m => bibliothèques visu in situ
pour CPU et GPU/CUDA
Houdini/Ytini en astrophysique
ParaView/Blender…
http://www.personal.psu.edu/dab143/OFW6/Training/cragun_slides.pdf
https://vimeo.com/230309447
58Journée Thématique calcul intensif, intelligence artificielle et données en
masse : état de l’art, enjeux et retours d’expérience du HPC
Lundi 26 mars - Amphithéâtre Nougaro - IMFT
Ces conférences sont ouvertes à tous, dans la
limite des places disponibles
Pour des raisons logistiques, merci de vous inscrire
- Panorama et perspectives sur le HPC
Denis Veynante, directeur de la mission
calcul-données du CNRS
- Centres de calcul et des constructeurs de
super-calculateurs
Jean-Philippe Proux (GENCI)
Damien Declat (Atos)
- Retour d’expérience scientifique et technique
Matthieu Chavent (CNRS – IPBS)
Vincent Moureau (CNRS - CORIA)
Gabriel Staffelbach (CERFACS)
59Vous pouvez aussi lire

















































