Introduction 'a l'apprentissage automatique S eance 2 - Loria
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Introduction à l’apprentissage automatique
Séance 2
Apprentissage non-supervisé: partitionnement
Dilemme biais-fluctuation et sélection de modèle
Frédéric Sur
Université de Lorraine / LORIA
https://members.loria.fr/FSur/
“machine learning mines”
1/32 app.wombo.art
Apprentissage non-supervisé
On dispose de N observations non-étiquetées : (xxi )16i6N
En général, les observations sont vectorielles : x ∈ Rd
Aujourd’hui, on s’intéresse aux problèmes d’apprentissage
non-supervisé :
partitionnement
→ identifier des groupes d’observations homogènes
(estimation de densités de probabilité)
→ modèle probabiliste génératif
Pour commencer, quelques exemples. . .
2/32
Exemple : arbre phylogénétique
Partitionnement
Cf TP Exercice 2
3/32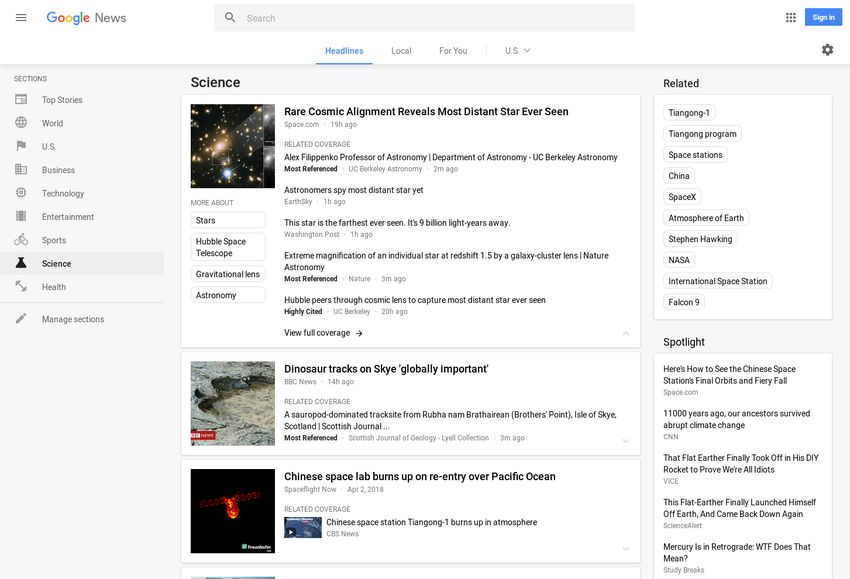
Exemple : Google news
Partitionnement
Cf TP Exercice 3
4/32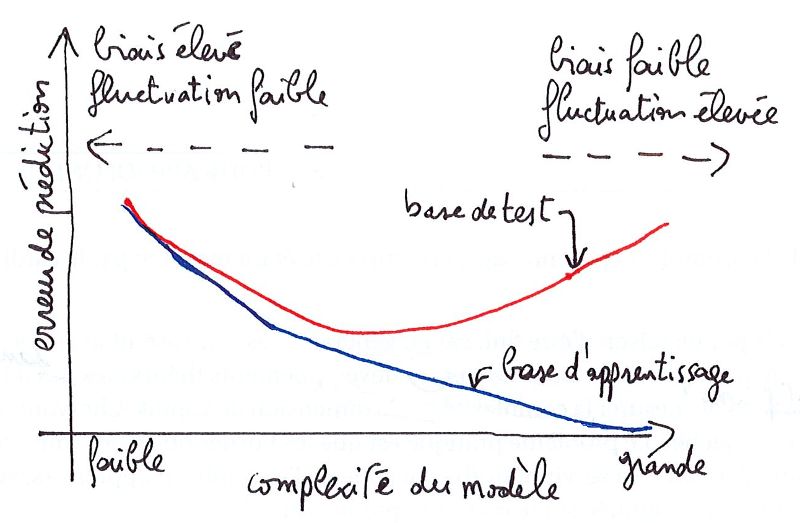
Exemple : génération automatique de texte (1)
Modèle probabiliste
Claude Shannon (1916-2001) MIT - Bell labs
Père de la théorie statistique de l’information
Article fondateur : A mathematical theory of communication, 1948
5/32
Exemple : génération automatique de texte (2) 6/32

Exemple : génération automatique de texte (3)
Approche deep-learning ∼ 2015
Breaking news : 9 novembre 2021
https://cedille.ai/
7/32
Exemple : Meow generator
Modèle probabiliste
Alexia Jolicoeur-Martineau (Univ. McGill)
https://ajolicoeur.wordpress.com/cats/
Google : generative models AI
8/32
Une difficulté intrinsèque
Malédiction de la dimension :
Comment comparer des observations x dans un espace de
grande dimension ?
Ex. : x = séquence de nucléotides, représentation d’un article de
journal. . .
Comment apprendre une distribution de probabilité p(xx ) sur
l’espace des observations ?
Ex. : génération de lettres selon p(x|x−1 , x−2 , . . . , x−d ) =
p(x, x−1 , x−2 , . . . , x−d )/p(x−1 , x−2 , . . . , x−d ),
ou génération d’images selon p(x)=
loi des images de chats
→ dans des cours spécialisés
9/32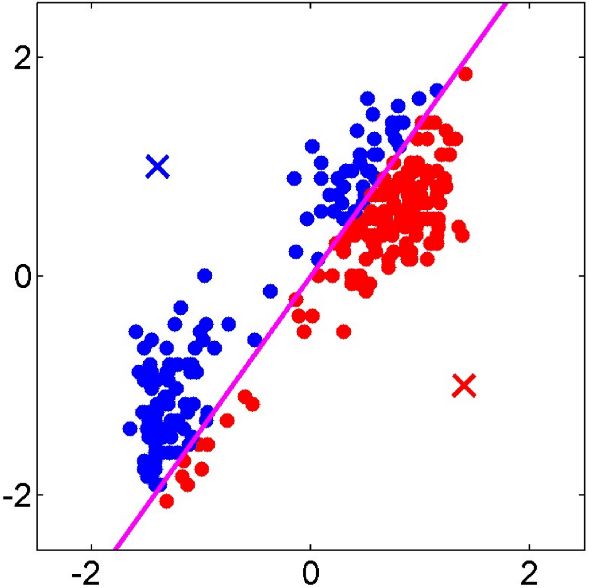
Plan
1 Partitionnement / classification non supervisée
Classifications hiérarchiques (rappels)
K -moyennes
2 Dilemme biais-fluctuation et sélection de modèle
3 Point méthodologique
4 Conclusion
10/32Partitionnement / classification non supervisée
Observations : généralement, points dans Rd
Distance / mesure de dissimilarité entre observations d(x, y ) :
– L1 , L2 , L∞ . . .
– distance d’édition entre mots
Mesure de dissimilarité entre classes (cluster) D(A, B) :
D(A, B) = min{d(x, y ), x ∈ A, y ∈ B} (single linkage)
D(A, B) = max{d(x, y ), x ∈ A, y ∈ B} (complete linkage)
nA nB
D(A, B) = ||mA − mB ||2 (Ward)
n A + n B
||x − mA∪B ||2 − ||x − mA ||2 − ||x − mB ||2
P P P
= x∈A∪B x∈A x∈B
11/32Classifications hiérarchiques (rappels TCS analyse données)
Algorithme :
1 initialisation : chaque observation dans une classe différente ;
2 jusqu’à ce qu’il ne reste qu’une classe, fusionner les deux plus
proches au sens de D.
Sortie : le dendrogramme
= arbre binaire de classification, où hauteur des classes proportionnelle à
dissimilarité des classes filles.
Classification : on fixe une hauteur-seuil dans le dendrogramme.
Voir exemples polycopié
12/32Discussion classification hiérarchique
Quelle métrique de dissimilarité d entre observations ?
Quelle métrique de dissimilarité D entre groupes ?
Quels choix de métriques selon la distribution des
observations ?
Quel nombre de groupes ?
Occupation mémoire O(N 2 ) (il faut généralement stocker les
distances entre toutes les paires d’observations)
Complexité algorithmique O(N 2 log(N)) (
lent
)
(il va falloir trier les distances)
→ ordres de grandeurs (très grossier) : N = 1, 000, 000
nécessite 1To en mémoire et 20 min de traitement. . .
Cf TP Exercice 1
13/32K -moyennes (K -means)
On cherche une partition (C1 , C2 , . . . , CK ) de (xx i )1≤i≤N minimisant
K X
X
E (C1 , C2 , . . . , CK ) = ||xx − m j ||2
j=1 x ∈Cj
où m j est la moyenne (barycentre) des x ∈ Cj .
(E : inertie dans sklearn)
14/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Illustration de l’algorithme de Lloyd
https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/clustering/slides.pdf
15/32Propriété de l’inertie
Recherche de K groupes :
K X
X
(C1 , C2 , . . . , CK ) minimise EK = ||xx − m j ||2
j=1 x ∈Cj
Si C10 t C100 = C1 :
X X X
||xx − m j ||2 = ||xx − m j ||2 + ||xx − m j ||2
x ∈C1 x ∈C10 x ∈C100
X X
> ||xx − m 0j ||2 + ||xx − m 00j ||2
x ∈C10 x ∈C100
où m 0j , m 00j sont les barycentres de C10 , C100
Conclusion : (EK ) décroı̂t avec K .
Remarque : en pratique, on n’est pas certain d’avoir trouvé le
minimum global de l’inertie. . .
16/32Heuristique pour le choix de K
Exemple : iris de Fisher
150 observations, 4 caractéristiques
(longueur et largeur des pétales et sépales)
trois variétés d’iris
https://scikit-learn.org/stable/auto_examples/datasets/plot_
iris_dataset.html
Méthode du coude (elbow method) : on choisit K où la
décroissance de Ek devient moins franche
Remarque : cela ne dit pas que la partition obtenue est satisfaisante
17/32Discussion K -moyennes
→ on peut démontrer que cet algorithme permet la convergence
en un nombre fini d’étapes vers un minimum local de E
Choix de K ?
→ méthode du coude
Convergence vers un minimum local de E
→ plusieurs exécutions avec initialisations aléatoires différentes
Est-ce une approche adaptée à toute distribution des
observations ?
Rapide en pratique
Cf TP exercice 1
18/32Plan
1 Partitionnement / classification non supervisée
Classifications hiérarchiques (rappels)
K -moyennes
2 Dilemme biais-fluctuation et sélection de modèle
3 Point méthodologique
4 Conclusion
19/32Dilemme biais-fluctuation
Cadre : apprentissage supervisé. On cherche à faire des prédictions
dataset 1 p.p.v. 5 p.p.v.
Question : a-t-on intérêt à avoir un modèle compliqué (précis sur
les observations d’apprentissage), qui va bien représenter les
observations d’apprentissage, ou un modèle simple (grossier) qui va
moins bien représenter ces observations mais moins en dépendre ?
20/32Risque empirique et risque de prédiction
Données :
0
base d’entraı̂nement : (xi , yi )1≤i≤N , xi ∈ Rd , yi ∈ N ou Rd
réalisation d’un N-échantillon i.i.d. (X, Y ) (loi inconnue)
Objectif : faire une prédiction y à partir d’une observation x.
Comment ? on cherche un prédicteur dans une famille H.
Exemple : H = {h : x 7→ a · x + b, a ∈ Rd , b ∈ R}
h(x) : prédiction à partir de l’observation x
On voudrait : choisir f ∈ H qui minimise l’espérance Rp du coût
d’erreur de prédiction (erreur face à une observation inconnue)
→ impossible car on ne connaı̂t pas la loi de X
Ce qu’on fait : on choisit fe ∈ H minimisant le risque
empirique Re (coût d’erreur moyen sur la base d’apprentissage)
Question : l’espérance du coût d’erreur de fe est-elle grande ?
21/32Dilemme biais-fluctuation
Rp (f ) ≤ Rp (fe) ≤ Rp (f ) + 2 max |Rp (h) − Re (h)|
| {z } | {z } h∈H
biais biais
| {z }
fluctuation
Conséquence : choisir un modèle d’apprentissage H, c’est faire un
compromis entre biais et fluctuation
22/32Illustration (source : scikit-learn)
Régression par polynomes de degré d : comment choisir d ?
→ minimisation de Re sur Hd = {x 7→ di=0 ai x i }
P
remarque : H1 ⊂ H4 ⊂ H15
H1 H4 H15
sous-apprentissage sur-apprentissage
(under-fitting) (over-fitting)
biais élevé biais faible
fluctuation faible fluctuation élevée
23/32Comment sélectionner un modèle ?
Les paramètres d’un modèle sont (souvent) estimés par
minimisation du risque empirique. Comment choisir un modèle ?
Exemples :
1 Dans chaque H , on détermine h minimisant le risque
d
empirique, mais comment choisir d ?
2 Classification K -ppv (ici, pas de risque) : comment choisir K ?
→ on calcule l’erreur de prédiction moyenne sur une base de test
représentative des observations, indépendante de la base
d’apprentissage
On observe
en pratique :
(ex. : choix de Hd )
24/32Sélection de modèle
Rappel : base de test et base d’apprentissage sont supposées
représentatives des données et indépendantes
→ l’erreur sur la base de test est une estimation du risque moyen
de prédiction
(contrairement à l’erreur d’apprentissage, cf apprentissage
par cœur
)
→ on choisit le modèle H minimisant l’erreur sur la base de test
On remarque :
erreur d’apprentissageEn pratique avec un jeu de données (xi , yi )1≤i≤N
Approche 1 : on met une partie du jeu de données de côté pour
servir de base de test, c’est la validation holdout
Limite : fluctuation d’échantillonnage vs. taille base d’apprentissage
Approche 2 : pour exploiter au mieux le jeu de données, on peut
faire de la validation croisée à K plis (K -fold cross validation)
on répète K fois : apprentissage sur K − 1 plis, test sur K -ème pli
A A A A T → erreur sur T : e1
A A A T A → erreur sur T : e2
K =5: A A T A A → erreur sur T : e3
A T A A A → erreur sur T : e4
T A A A A → erreur sur T : e5
Erreur de validation croisée : moyenne des ei
Cas particulier : K = N, leave-one-out cross validation (temps de calcul !)
Généralement, K = 5 ou K = 10.
26/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 0.2 0.4 0.6 0.8 1
Données
régression linéaire ou quadratique ?
→ validation croisée à 3 plis
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression linéaire
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. linéaire, 1er pli
RMSE sur base test : 0.1194
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression linéaire
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. linéaire, 2ème pli
RMSE sur base test : 0.1193
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression linéaire
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. linéaire, 3ème pli
RMSE sur base test : 0.0536
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression quadratique
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. quadratique, 1er pli (pas le même que pour rég. linéaire)
RMSE sur base test : 0.0901
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression quadratique
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. quadratique, 2ème pli
RMSE sur base test : 0.1749
27/32Exemple illustratif. . .
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
régression quadratique
0.1 apprentissage
test
0
0 0.2 0.4 0.6 0.8 1
rég. quadratique, 3ème pli
RMSE sur base test : 0.1431
27/32Exemple illustratif. . .
Scores de validation croisée :
Régression linéaire :
0.1194 0.1193 0.0536
moyenne : 0.0974
Régression quadratique :
0.0901 0.1749 0.1431
moyenne : 0.1360
Conclusion : on sélectionne le modèle de la régression linéaire
Remarque : on réestime les paramètres de la régression linéaire sur
toute la base d’apprentissage.
27/32Plan
1 Partitionnement / classification non supervisée
Classifications hiérarchiques (rappels)
K -moyennes
2 Dilemme biais-fluctuation et sélection de modèle
3 Point méthodologique
4 Conclusion
28/32Un mot sur les travaux dirigés. . .
Les contraintes : profils divers, 6 × 2 heures seulement
→ ce ne sont pas des TD
de maths
, ni de programmation
de manière générale, il faut (bien) utiliser les bibliothèques faites par des
gens bien plus forts que nous
→ le travail est en partie
prémâché
, notamment le traitement
des jeux de données
Objectifs dans ce cours :
comprendre le fonctionnement de différentes méthodes
d’apprentissage
savoir à quoi correspondent leurs nombreux paramètres
(donc avoir une idée assez précise des maths derrière)
mettre en place une méthodologie
et étudier différentes applications
réelles
29/32Pratique des data sciences
→ toute application pratique de méthodes de l’apprentissage
nécessite d’intéragir avec un spécialiste du domaine,
voire d’en être un. . .
(analyse d’images, traitement de la langue, matériaux, chaı̂ne logistique,
etc.)
→ la manipulation des données (recueil, mettre en forme, charger
dans la bonne structure de données. . .) est un travail ingrat
chronophage
→ il faut tester différentes méthodes, souvent les combiner
→ à pratiquer dans des projets ou défis, souvent interdisciplinaires
(Kaggle, OpenML.org, challenge Data @ ENS. . .)
30/32Plan
1 Partitionnement / classification non supervisée
Classifications hiérarchiques (rappels)
K -moyennes
2 Dilemme biais-fluctuation et sélection de modèle
3 Point méthodologique
4 Conclusion
31/32Conclusion
Partitionnement / classification non-supervisée
classifications hiérarchiques
k-means
et autres méthodes : DBSCAN, mean-shift. . .
The 5 Clustering Algorithms Data Scientists Need to Know :
https://towardsdatascience.com/
the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68
Sélection de modèle
compromis entre sous- et sur-apprentissage
sélection de modèle par validation croisée
32/32Vous pouvez aussi lire

















































