Solutions Open Source de Business Intelligence - ETAT DE L'ART
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Solutions Open Source de
Business Intelligence
ETAT DE L'ART
Copyright © 2008 - ADULLACT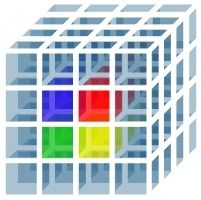
État de l'art : Solutions Open Source Business Intelligence
Préambule
ADULLACT
ADULLACT est une association régie par la loi du 1er juillet 1901 et le décret du 16 août 1901,
ayant pour nom : Association des Développeurs et des Utilisateurs de Logiciels Libres pour les
Administrations et les Collectivités Territoriales.
L'association a été créée en septembre 2002, par Claude LAMBEY et François ELIE.
L'objectif de l'ADULLACT est de soutenir et coordonner l’action des administrations et des
collectivités pour promouvoir, développer, mutualiser et maintenir un patrimoine commun de
logiciels libres utiles aux missions de service public (administration, éducation, monde
associatif, santé...).
Pour satisfaire les contraintes de transparence, de sécurité, d’interopérabilité et d’évolutivité,
indispensables pour gérer dans de bonnes conditions les informations propres aux administrés,
en favorisant les télé-procédures. Ce patrimoine logiciel respectera les standards et les
protocoles ouverts, et sera librement utilisable, copiable, modifiable et redistribuable par
quiconque sans aucune discrimination.
Les standards et protocoles sont dits ouverts s’ils sont publiquement documentés, librement
utilisables et implémentables.
L’ADULLACT apporte son soutien à l’usage de Logiciels Libres dans les administrations et dans
les collectivités territoriales, et se propose de participer au développement de Logiciels
applicatifs Libres.
ADULLACT Projet
ADULLACT Projet est une SCIC (Société Coopérative d'Intérêt Commun) régie par la loi du 10
septembre 1947 portant statut de la coopération, et la loi du 24 juillet 1867 sur les sociétés à
capital variable. Elle a été créée en octobre 2006.
En optant pour cette forme de société, les porteurs du projet poursuivent, en accord avec les
adhérents de l’ADULLACT à l’origine de cette SCIC, leur action, inscrite dans l’intérêt collectif,
en faveur de l’optimisation des systèmes d’information au sein des collectivités territoriales et
du monde de la santé et, d’une manière générale, en faveur du développement du Logiciel
Libre au sein des Services Publics.
La SCIC ADULLACT Projet s’est donnée pour but, dans un esprit de coopération entre les
acteurs publics (usagers) et privés (opérateurs techniques, salariés) :
De répondre aux besoins de refonte des systèmes d'information des administrations,
collectivités territoriales et organisations relevant des services Publics à base de
Logiciels Libres.
De mutualiser les coûts de développement des logiciels dit Libres ou Open Source dont
les avantages (coûts, pérennité, accès au code source) ne sont plus à démontrer.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 2 / 56
État de l'art : Solutions Open Source Business Intelligence
S’ajoutent :
Le souci de préserver totalement son indépendance et sa neutralité vis-à-vis des
organisations économiques ou industrielles privées, pour garantir la meilleure
objectivité de ses services, accompagnements ou aides.
La volonté de ménager, avec les organisations publiques, des partenariats de haute
proximité, organisés de manière à faire bénéficier ses partenaires des avancées
technologiques les plus récentes.
Cet ouvrage
La Business Intelligence, ou Informatique Décisionnelle, est un domaine bien spécifique des
systèmes d'information, qui n'échappe pas à l'Open Source.
Ainsi, cet ouvrage s'efforce :
De mettre en avant les enjeux et les défis de la Business Intelligence dans l'Open
Source.
De définir les différents outils décisionnels afin de décomplexifier ce domaine.
De présenter les solutions qui sont, ou ont été, les plus pertinentes dans chaque famille
d'outils.
D'établir une analyse de ces applications afin d'en retirer une synthèse mettant en
avant les intérêts, et inconvénients, de chacun.
Cette étude est fondée sur plusieurs mois de travail de recherche. Elle n'a pas pour objectif
d'établir un classement entre les différents outils mais de mettre en avant leurs potentiels
respectifs afin que chaque lecteur puisse s'orienter vers celui qui conviendra le mieux à ses
besoins et attentes.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 3 / 56État de l'art : Solutions Open Source Business Intelligence
Table des matières
Préambule...................................................................................................................................................2
ADULLACT................................................................................................................................................2
ADULLACT Projet.......................................................................................................................................2
Cet ouvrage..............................................................................................................................................3
Introduction................................................................................................................................................5
Business Intelligence..................................................................................................................................5
Deux systèmes d'information : transactionnel et décisionnel.......................................................................5
Historique de la Business Intelligence......................................................................................................5
Règles conceptuelles ............................................................................................................................6
Open Source.............................................................................................................................................6
Définition du Logiciel Libre.....................................................................................................................6
Évolution de ce modèle économique........................................................................................................6
Critères de choix..................................................................................................................................6
L'Open Source Business Intelligence (OSBI)..................................................................................................7
Apports et avantages............................................................................................................................8
Perspectives.........................................................................................................................................8
Les outils décisionnels.................................................................................................................................9
Extract Transform Load (ETL)......................................................................................................................9
Data Warehouse et Data Mart......................................................................................................................9
Cubes OLAP ............................................................................................................................................11
Analyse multidimensionnelle......................................................................................................................13
Data Mining.............................................................................................................................................14
Générateur d'état.....................................................................................................................................15
Synthèse.................................................................................................................................................17
Les solutions décisionnelles.......................................................................................................................18
ETL........................................................................................................................................................18
Clover.ETL.........................................................................................................................................18
Enhydra Octopus................................................................................................................................20
Pentaho Data Integration (ex. Kettle)....................................................................................................21
Talend Open Studio (TOS)....................................................................................................................23
Data Warehouse......................................................................................................................................25
Bizgres..............................................................................................................................................25
Ingres...............................................................................................................................................25
MySQL...............................................................................................................................................26
PostgreSQL........................................................................................................................................26
Serveur OLAP..........................................................................................................................................27
Pentaho Analysis Services (ex. Mondrian)...............................................................................................27
Palo..................................................................................................................................................29
Client OLAP.............................................................................................................................................31
FreeAnalysis.......................................................................................................................................31
Jpalo.................................................................................................................................................33
Jpivot................................................................................................................................................34
Jrubik................................................................................................................................................36
Data Mining.............................................................................................................................................38
Waikato Environment for Knowledge Analysis (WEKA).............................................................................38
Générateur d'état.....................................................................................................................................40
Business Intelligence and Reporting Tools (BIRT)....................................................................................40
JasperReport......................................................................................................................................42
Pentaho Reporting (ex. JfreeReports)....................................................................................................44
OpenReports......................................................................................................................................46
Suites décisionnelles.................................................................................................................................48
Jasper Intelligence..............................................................................................................................48
Marvel IT Dash...................................................................................................................................50
Pentaho.............................................................................................................................................51
Spago BI...........................................................................................................................................54
Synthèse....................................................................................................................................................56
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 4 / 56État de l'art : Solutions Open Source Business Intelligence Introduction Business Intelligence Selon la définition de Robert REIX, « un système d'information est un ensemble organisé de ressources (matérielles, logicielles, personnelles, données, procédures...) permettant d'acquérir, de traiter, de stocker des informations (sous forme de données, textes, images, sons...) dans et entre organisations ». Le choix de l'appellation système n'est pas anodin. Il reflète la logique sous-jacente considérant ce dernier comme un ensemble d'entités en interaction entre elles, que l'on pourrait considérer comme autant de maillons formant une chaîne. De ce fait, ce dernier peut être ainsi observé à différents degrés de précision, soit en le considérant comme un système d'information global, soit en accentuant le zoom afin de mettre en valeur deux sous systèmes. Deux systèmes d'information : transactionnel et décisionnel D'une part le système d'information transactionnel. Il gère les applications quotidiennes et se rapproche à ce titre de la couche opérationnelle. Il est typiquement utilisé par les acteurs métiers et se voit plus comme un outil utilisé par ces derniers afin de répondre à des besoins de simplification et d'automatisation. D'autre part le système d'information décisionnel, angle d'approche de cet ouvrage, qui est utilisé pour prendre les décisions de l'entreprise, et à ce titre doit permettre aux décideurs d'avoir un certain recul sur leur entreprise. Il fournit pour cela les informations nécessaires et pertinentes afin de faire les bons choix. Le Gartner Group définit, en 1993, la Business Intelligence comme l'« ensemble des moyens et méthodes permettant de rassembler, consolider, analyser et rendre accessible les données d'une entreprise dans une perspective d'aide à la décision ». Le décisionnel est donc à l'information de l'entreprise ce que les mathématiques sont à la pensée. Force est de constater que le concept de Business Intelligence n'est pas récent, et que, depuis sa création, des évolutions notables peuvent être distinguées. Il est nécessaire de connaître ces mutations afin de bien saisir les tenant et aboutissant de leur structure actuelle. Historique de la Business Intelligence Au début des années 90, l'informatique est au service de l'entreprise pyramidale. D'une manière très classique, elle remonte les informations de la base vers le haut. Cette époque est celle des Executive Information Systems (EIS). Milieu des années 90, les besoins d'informations composites révèlent des lacunes dans les systèmes d'informations. Les technologies Data Warehouse et Data Mart se banalisent et l'informatique décisionnelle se tourne vers les cubes OLAP, dans un soucis d'analyse plus poussée. De nos jours, le décisionnel n'est plus l'apanage des instances dirigeantes et toutes les couches de l'entreprise revendiquent un besoin d'information pertinente, propre à leur fonction. Que ce soit dans des soucis de pilotage par les acteurs du top management, pour des besoins particuliers formulés par des experts ou dans des logiques de reporting classique demandées par les acteurs métiers, cette mutation culturelle s'appuie sur la banalisation et l'accessibilité Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 5 / 56
État de l'art : Solutions Open Source Business Intelligence
des technologies Web, qui rendent cette divulgation d'information possible à moindre coûts.
Force est de constater également que certaines règles conceptuelles se sont inconsciemment
standardisées, et actuellement le système d'information décisionnel peut être schématisé sous
trois étapes.
Règles conceptuelles
Tout d'abord, l'extraction des données. L'entreprise étant composée d'informations aussi
variées en terme de structure, de format, de taille... le système se doit d'extraire les
informations afin de les amener vers la deuxième étape.
Ensuite, la consolidation. Ces données doivent être consolidées afin de pouvoir effectuer le
travail nécessaire dessus.
Enfin le traitement. Il doit fournir aux dirigeants les informations pertinentes sous forme
d'indicateurs, tout en répondant aux questions que toute mise en place doit se poser : Quelles
informations ? Sous quelle forme ? Tous les combien ?...
Open Source
Bien plus qu'un simple copyright, la terminologie Open Source (également connue sous
l'appellation Logiciel Libre) reflète une certaine philosophie. Richard STALLMAN, le père
fondateur de la Free Software Foundation a coutume de résumer ce qu'est le Logiciel Libre par
« Liberté, Egalité, Fraternité ».
Définition du Logiciel Libre
Le Logiciel Libre est ainsi défini par :
La liberté d’utiliser et/ou d’exécuter un logiciel pour tout objectif.
La liberté d’examiner et/ou d’étudier le fonctionnement d’un logiciel et de l’adapter à
ses propres besoins (pour ceci l’accès au code source est une condition requise).
La liberté de faire des copies pour des tiers.
La liberté d’améliorer le logiciel et de rendre ces améliorations largement disponibles
pour le bien public.
Évolution de ce modèle économique
Ce modèle de développement collaboratif, que certains considèrent encore comme utopique et
ne prenant pas en compte les logiques de marchés actuelles, s'avère en réalité être plus que
réaliste. En effet, dans son édition de Janvier 2007 du Baromètre des tendances 2006,
l'Observatoire du Logiciel Libre (O2L), composé de Anaska et du Groupe Cegos, met
notamment en évidence une progression sur un an de 30% des ventes de serveurs sous Linux,
de 30% également des formations bureautique (tel OpenOffice) et de 50% de celles
concernant la base de données MySQL. Ces observations reflètent un réel engouement pour les
solutions Open Source, de la part des entreprises qui les jugent assez fiables pour être
implantées au sein de leur organisme.
Critères de choix
Néanmoins, une implantation de solution Open Source doit se faire en prenant en compte
certains critères de choix, non pris en considération lors de l'intégration de logiciels
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 6 / 56État de l'art : Solutions Open Source Business Intelligence
propriétaires car spécifiques au modèle de développement collaboratif.
Popularité
La visibilité sur la toile est, en plus d'être un facteur de taille, un bon outil pour définir la
popularité de la solution, et donc plus de facilité à trouver sa communauté.
De la même façon le taux de fréquentation étant le nombre de téléchargement du produit, il
reflète, de la même façon que la visibilité sur la toile, la popularité de la solution.
L'âge du projet permet de se faire une idée de la maturité de la solution. Ce critère est
néanmoins très subjectif car il n'y a pas de réelle préférence à avoir entre un projet jeune ou
un vieux.
Documentation
Dans l'open source, la communauté est la hotline. La taille de la communauté doit être prise
en considération, et Il convient donc de choisir des projets avec de riches forum, une home
page, des FAQ dédiées et visibles sur le net.
Les aspect de documentation permettent également de délester une bonne partie de la charge
de l'équipe animatrice. De plus, elle peut être considérée comme un gage de qualité.
Développement
Le taux d'activité concerne le développement et désigne le temps passé entre deux versions (il
ne doit pas excéder 6 mois, doit être relativisé et comparé au taux de fréquentation).
Le nombre de contributeurs doit être distingué de la communauté car il est un garant de la
stabilité de la solution, de sa pérennité et de son évolutibilité.
Les compétences internes de l'entreprise doivent également être prises en compte et il
convient de privilégier les projets maintenables ou abordables en interne, et de prendre
également en compte les compétences des partenaires.
Déploiement
La portabilité et l'interopérabilité révèlent la compatibilité de l'application avec les fichiers
entrant-sortant, ainsi qu'avec les différents systèmes d'exploitation.
Le niveau de Packaging concerne l'installation. Elle comporte aussi bien une documentation
d'installation qu'une définition des pré-requis.
Droit
Différentes licences de logiciels libre existent, et il convient de privilégier GPL et CeCiLL. Éviter
les licences de type « BSD ».
L'Open Source Business Intelligence (OSBI)
De même que pour les autres classes d'outils (CRM, GED...), le rapprochement entre Open
Source et Business Intelligence s'avère de plus en plus performant, et ce depuis quelques
années. Bien qu'ayant pâti de leur manque de maturité et de stabilité, les solutions de
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 7 / 56État de l'art : Solutions Open Source Business Intelligence
Business Intelligence Open Source s'avèrent être actuellement assez solides pour être
employées par nombre d'entreprises et de collectivités, et pour posséder leur premier salon
professionnel qui s'est tenu à l'arche de la Défense à Paris, le 18 mars 2008.
Organisé par Micropole-Univers et l'Arche Numérique, ce salon a dressé un portrait de l'Open
Source dans le décisionnel par le biais de conférences, ateliers, tables rondes... Animés par de
nombreux partenaires d'importance dont notamment les sociétés MySQL, Talend et JasperSoft.
Apports et avantages
L'engouement des entreprises pour ces solutions peut s'expliquer sur plusieurs points.
Intérêts financiers
Tout d'abord dans une logique de coûts. Une solution Open Source n'entraîne pas, de par sa
définition même, de coûts de licence. Elle s'avèrent donc actuellement être une alternative plus
qu'intéressante pour les sociétés. De même, certaines entités telles que les TPE/PME profitent
de cet aspect de par un coût d'entrée moins onéreux.
Mutualisation des compétences
La possibilité de coopération entre entreprises, afin de mutualiser les compétences et
d'amoindrir les investissements, tant sur le plan financier qu'humain. Comme le souligne
Stefano SCAUZZO, Technical Manager chez Engineering, « Les entreprises sont aussi bien en
concurrence sur certains domaines et en collaboration sur d'autres, ce qui crée un éco système
de valeurs où chacun doit trouver sa place et jouer son rôle ».
Tester la solution
La possibilité de tester le logiciel avant d'investir dedans, et ce sans limite de temps ou de
fonctionnalité. L'entreprise peut ainsi s'apercevoir d'elle même, sans biais commercial ou
limitation, de la pertinence de la solution. Cette logique d'avant vente se fait de fait par les
utilisateurs qui ne se tournent ensuite vers les SSLL que pour des besoins de connaissances et
de formations.
Personnalisation et innovation
Personnalisation et innovation sont également des facteurs clefs de ce choix. En effet, outre
l'innovation entrainée par le développement collaboratif, Stéphane LAISNE, Responsable
d'étude de solutions chez Lectra souligne que « l'Open Source permet une réelle collaboration
car le client apporte vraiment sa touche en donnant sa vision de la solution, ce qui permet
d'une part de la personnaliser mais également de la faire évoluer en ce sens ».
Perspectives
Bien que des composants comme les ETL ou les bases de données s'avèrent être les plus
aboutis, les outils Open Source de Business Intelligence doivent encore s'enrichir sur des
aspects métiers et fonctionnels, et arriver à maturité sur certaines briques logicielles.
Néanmoins, l'arrivée de différents acteurs sur ce marché, ainsi que la marche de progression
possible de par sa faible part dans la BI, nous autorise à envisager une évolution grandissante.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 8 / 56État de l'art : Solutions Open Source Business Intelligence
Les outils décisionnels
Contrairement aux autres applications s'intégrant à d'autres fonctions de l'entreprise, comme
par exemple les SCM qui gèrent la chaîne logistique ou les CRM qui s'occupent de la relation
client, l'Informatique Décisionnelle est composée de plusieurs outils qui, imbriqués les uns aux
autres ou utilisés séparément, conduisent à créer un véritable système décisionnel. Nous
verrons donc ici les différents composants de ce domaine, en partant de la couche la plus
invisible de l'iceberg, jusqu'à sa partie la plus visible.
Extract Transform Load (ETL)
Un ETL, pour Extract Transform Load, est utilisé pour alimenter le Data Warehouse à partir des
bases de données de production.
Comme son nom l'indique, un ETL :
Extract : extrait les données à partir de différentes sources.
Transform : transforme ces dernières afin de les unifier sous un même format.
Load : charge les données dans le Data Warehouse.
Les intérêts d'un ETL sont multiples :
Il peut prendre en charge différentes natures de sources (SGBD relationnels, flux XML,
fichiers CSV...), que ce soit en entrée comme en sortie.
L'intégration d'un nouveau flux ne nécessite pas de développement spécifique, une
configuration interactive, par le biais d'interface graphique, des 3 étapes vues
précédemment suffit.
L'intégration d'outil de planification, au sein même des ETL, permet d'éviter le
développement de programmes batch spécifiques, ainsi que leur maintenance.
Il est cependant important de souligner qu'un ETL fonctionne sous un mode Point à Point. Bien
qu'il récupère les données de plusieurs sources, il n'a pas pour vocation de construire un flux
agrégé entre deux sources différentes.
Afin de ne pas retomber dans les erreurs du passé (échec de réalisation, dépassement de
budget...) relatives à la mise en place de projets décisionnels, il est impératif d'apprécier à sa
juste valeur cette phase de collecte et de préparation des données, et ainsi d'y consacrer les
ressources nécessaires. A titre informatif, cette phase doit représenter environ les ¾ temps du
projet.
Data Warehouse et Data Mart
Littéralement entrepot de données, Le Data Warehouse est une base de données recueillant et
gérant toutes les données collectées au sein de l'organisme, dans le cadre de la prise de
décision.
En ce sens, elle est :
Exclusivement réservée à cet usage.
Organisée, structurée et préparée à des fins de traitement décisionnel.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 9 / 56État de l'art : Solutions Open Source Business Intelligence
Alimentée en données depuis les bases de production a l'aide d'outils de type ETL.
Bill Immon, père du concept du Data Warehouse, le décrit comme tel :
'' Subject oriented, integrated, nonvolatile, time variant collection of data in support of
management decisions '' - Building the Data Warehouse, John Wiley and son, 1996
Il doit donc répondre à 4 caractéristiques essentielles :
1. Orienté sujet : les données sont organisées par thème.
2. Intégré : les données provenant de sources hétérogènes, elles utilisent chacune un
type de format. Elles doivent donc être intégrées avant d'être proposées à utilisation.
3. Non volatile : les données ne disparaissent pas et ne changent pas au fil des
traitements, au fil du temps.
4. Historisé : les données sont horodatées, afin de visualiser l'évolution dans le temps
d'une valeur donnée.
Le degré de détail de l'archivage est bien entendu relatif à la nature des données. Toutes les
données ne méritent pas d'être archivées.
Il existe plusieurs natures de Data Warehouse possibles (bases relationnelles, bases OLAP,
bases hybrides...). Nous ne les recenserons pas ici mais proposerons plutôt ce tableau mettant
en avant les caractéristiques différenciant les Data Warehouse et les bases de données
relationnelles classiques.
Comparatif entre Base de Données etData Warehouse
Caractéristique Base de Données Data Warehouse
Opération Gestion courante. Analyse.
Production. Support à la décision.
Modèle de données Entité / relation. 3NF.
Etoile.
Flocon de neige.
Normalisation Fréquente. Plus rare dans les Data
Marts.
Données Actuelles. Historisées.
Brutes. Parfois agrégées.
Mise à jour Immédiate. Souvent différée.
Temps réel.
Niveau de Faible. Elevé.
consolidation
Perception Bidimensionnelle. Multidimensionnelle.
Opérations Lecture. Lectures.
Mises à jour. Analyses croisées.
Suppressions. Rafraîchissements.
Taille En giga-octets. En téra-octets.
Source : Wikipédia
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 10 / 56État de l'art : Solutions Open Source Business Intelligence
Cubes OLAP
Le concept OLAP (On Line Analytical Processing) a été défini en 1993 par le Dr Ef Codd. Ce
dernier doit respecter 12 règles de conception :
Multidimensionalité : le modèle OLAP l'est par nature.
Transparence : l'emplacement physique du serveur OLAP est transparent pour
l'utilisateur.
Accessibilité : l'utilisateur OLAP dispose de l'accessibilité à toutes les données
nécessaires à ses analyses.
Stabilité : la performance des reportings reste stable indépendamment du nombre de
dimensions.
Client-Serveur : le serveur OLAP s'intègre dans une architecture de la sorte.
Dimensionnement : il est générique, afin de ne pas fausser les analyses.
Gestion complète : le serveur OLAP assure la gestion des données clairsemées.
Multi-utilisateurs : le serveur OLAP offre un support multi-utilisateurs (gestion des
mises à jour, intégrité, sécurité...).
Inter Dimension : Le serveur OLAP permet la réalisation d'opérations inter dimensions
sans restriction.
Intuitif : Le serveur OLAP permet une manipulation intuitive des données.
Flexibilité : La flexibilité (ou souplesse) de l'édition des rapports est intrinsèque au
modèle.
Analyse sans limites : Le nombre de dimensions et de niveaux d'agrégation possibles
est suffisant pour autoriser les analyses les plus poussées.
Cette notion a vu le jour du fait que les bases de données de type relationnel (SGBDR) sont
inadaptées aux besoins décisionnel. En effet, les requêtes décisionnelles, particulièrement
complexes par principe, mobilisent abusivement les ressources machines et perturbent les
traitements de production.
Les outils OLAP permettent de modéliser l'activité d'une entreprise suivant des axes ou
paramètres, répondant ainsi à ces contraintes. Pour ce faire, la structure de données construite
est parfois appelé schéma en étoile, du fait de sa forme :
POINT DE
VENTE
TEMPS ID_PV
VENTE
ID_TEMPS ADR_PV
ID_TEMPS
Date
ID_PRODUIT
ID_PV
ID_VENDEUR
Quantite
Prix
PRODUIT
VENDEUR
ID_PRODUIT
NOM_PRODUIT ID_VENDEUR
NOM_VENDEUR
PRENOM_VENDEUR
Exemple de modèle de données en étoile
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 11 / 56État de l'art : Solutions Open Source Business Intelligence
Nous pouvons ainsi distinguer deux types de tables :
Celles formant les branches des étoiles, utilisées comme critères d'analyse. Elles sont
appelées dimensions ou axes.
Celle qui forme le centre de l'étoile. Appelée table de fait, elle contient les indicateurs,
également appelés mesures.
Ces indicateurs sont donc fonctions des différentes dimensions, c'est pour cela que l'on
emploie le terme multidimensionnel.
Si l'on représente cette conceptualisation sous forme schématique, on obtient ce type de
graphique :
Points de Vente
Paris Lyon Nantes Montpellier
Janvier
Fêvrier
Temps
Mars
Avril
Prod. A Prod. B Prod. C Prod. D
Produits
Exemple de Cube OLAP
La représentation de cette base de données donne donc un Cube. On appelle Cube OLAP une
représentation des données selon des axes. Cette structure présente de nombreux avantages
pour des applications de Business Intelligence, en particulier grâce à sa capacité à faire
évoluer, recalculer et transformer les tableaux de bord. Le concept OLAP s’est spécialisé avec
différentes déclinaisons : multidimensionnelles, hybrides, desktop… Le Cube complet est
appelé population d'analyse. Dès qu'on dépasse trois dimensions, on parle d'hypercube.
Dans la mesure où toutes les cases du Cube ne seront pas forcément remplies (ex. : tel point
de vente ne vend pas tel produit), il est possible d'indiquer au moteur OLAP les
caractéristiques d'une variable, dimension dense ou éparse, afin d'optimiser la gestion de
l'espace disque et l'accès aux données.
Il peut être intéressant de définir des hiérarchies sur les dimensions. Ainsi, l'axe Temps pourra
se découper en jour, semaine, mois... Et de même pour Point de Vente qui pourra se découper
en ville, canton, département... On utilisera les termes parents, enfants... pour décrire les
différents niveaux entre eux.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 12 / 56État de l'art : Solutions Open Source Business Intelligence
Ainsi, le modèle conceptuel découlant de ces différentes hiérarchies donne :
JOUR
ID_JOUR POINT DE VENTE
DESC _JOUR TEMPS VENTE ID_PV
ID_TEMPS ID_TEMPS ID_VILLE
MOIS ID_JOUR ID_PRODUIT
ID_MOIS ID_MOIS ID_PV
DESC _MOIS ID_SEMAINE ID_VENDEUR
Quantite VILLE
Prix ID_VILLE
SEMAINE ID_C ANTON
DESC _VILLE
ID_SEMAINE
DESC _SEMAIN
E
CANTON
ID_C ANTON
DESC _C ANTON
Exemple de modèle de données en flocons
La structure de cette base de données, dans la même lignée que l'appellation schéma en
étoile, est appelée schéma en flocons.
Sous cette forme là, les seuls indicateurs possibles sont donc, comme vu précédemment, la
quantité et le prix. Néanmoins, il n'est pas nécessaire de définir, à l'origine, tous les indicateurs
possibles. Ainsi, d'autres indicateurs, non stockés à la base, seront calculés à partir de ceux
stockés, selon certains calculs. Ils sont souvent appelés formules.
Analyse multidimensionnelle
L'analyse multidimensionnelle s'effectue à partir des Cubes OLAP. Les Cubes OLAP, comme vu
précédemment, comportent de nombreux doublons du fait de leur structure. Il convient donc
d'agréger certaines données afin de faciliter la compréhension des résultats.
Les jeux d'informations sont caractérisés par :
Des attributs, qualifiant l'information (référence client, date, région ...).
Des grandeurs, portant l'information quantitative (quantités, prix...).
On distingue également :
Des grandeurs cumulables (montant, nombre d'items...).
Des grandeurs non cumulables (âge, date...).
Les attributs constituent les axes potentiels d'analyse. Néanmoins, la redondance de certaines
informations, bien que nécessaire dans un premier temps, est telle qu'il est nécessaire
d'agréger dans un second temps, certaines données en fonction d'axes potentiels d'analyse
définis, les plus pertinentes étant généralement les grandeurs cumulables.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 13 / 56État de l'art : Solutions Open Source Business Intelligence
L'analyse multidimensionnelle à proprement parler consistera à sélectionner les axes
d'analyses souhaités, ainsi que leur ordre. Chaque hiérarchisation d'axes d’analyse correspond
à une question que l’on se pose, et il n'est pas forcément nécessaire de les utiliser tous.
Les axes sont également scindés selon deux types :
A valeur discrète, (ou discontinues) : définis par un nombre fini de valeurs (code postal,
segment CSP...).
A valeurs continues (date, prix...).
Il est plus intéressant de disposer d'axes à valeur discrète, plus aisément manipulables. Ainsi,
on ramènera, autant que faire ce peut, les valeurs continues en valeurs discrètes (en
définissant des tranches par exemple).
Data Mining
Que l'on peut traduire par forage de données, le Data Mining consiste donc à forer dans un
grand volumes de données afin d'en extraire des informations pertinentes pour le décideur.
Le point important du Data Mining est que l'utilisateur ne sait pas ce qu'il cherche. En effet, les
outils de Data Mining recherchent, de manière semi-automatisés, des corrélations invisibles
entre des données n'ayant à priori aucun lien entre elles.
L'utilité même du Data Mining peut être comprise par l'exemple (plus ou moins légendaire)
Wall-Mart. Cette entreprise Américaine, spécialisée dans la grand distribution, utilisa les
premières techniques de Data Mining sur leurs données produits. Ainsi, les résultats de ces
recherches mirent en avant une corrélation entre les ventes de couches et celles de bières le
samedi après-midi. Après analyse, il s'avéra que le lien entre ces deux produits était induit par
le fait que le samedi après-midi, pour les couples ayant un ou plusieurs enfants en bas âge, les
femmes délèguaient les courses à leur mari. Ces derniers achetaient ainsi les couches pour
leur nourrissons, ainsi que des bières pour eux-mêmes. De ce fait, une réorganisation de
l'agencement des rayons, mettant côte à côte les rayons couches et bières, firent grimper les
ventes de ces dernières en flèche.
Cet exemple du Data Mining est tout particulièrement éloquent car il met en avant les points
essentiels de cet outil :
1. Ce n'est pas l'utilisateur qui cherche des réponses à des questions spécifiques mais
l'application qui met en valeur des axes de réflexion à suivre.
2. Cet outil est particulièrement adapté au traitement de grands volumes de données.
3. Une analyse des résultats obtenus doit être effectuée afin de définir, d'une part quel
type de relation se cache derrière ces résultats (cause à effets, résultante d'une cause
conjointe...), et d'autre part les causes de cette relation.
4. L'information pertinente, résultante de cette analyse, doit aboutir à des préconisations
utilisables par le décideur.
Il en découle ainsi plusieurs points :
1. Le Data Mining est plus considéré comme un art que comme une science, car sa
pertinence réside dans l'analyse effectuée, et les résultats qui en découlent, sur les
données retournées.
2. Il s'utilise sur un volume de données important, dont une chronologie peut être établie
(typiquement des Data Warehouse), à contrario de l'analyse statistique.
3. Cette technique peut tout aussi bien être utilisée à des fins explicatives que dans un
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 14 / 56État de l'art : Solutions Open Source Business Intelligence
objectif prédictif.
Il existe ainsi non pas une technique de Data Mining mais plusieurs, chacune reposant sur des
algorithmes mathématiques bien spécifiques, à choisir en fonction des résultats escomptés :
Les méthodes utilisant les techniques de classification et de segmentation.
Les méthodes utilisant des principes d'arbres de décision assez proches des techniques
de classification
Les méthodes fondées sur des principes et des règles d'associations ou d'analogies
Les méthodes exploitant les capacités d'apprentissage des réseaux de neurones
Les algorithmes génétiques, utilisés pour les études d'évolution des populations.
Une utilisation performante des outils de Data Mining nécessite 3 conditions obligatoires,
chacune possédant ses contraintes :
Une collecte des données complète, minutieuse et fiable (longue et coûteuse).
Une étude des résultats approfondie, à mettre en relation avec d'autres techniques
d'analyse (nécessite du temps et des compétences).
Une absence de réponse du système ne doit pas être systématiquement considérée
comme une négation. Il peut parfois indiquer la nécessité d'aborder le problème sous
un autre angle (nécessite du temps et le recul nécessaire).
Générateur d'état
Le générateur d'état permet de réaliser des états, appelés également reporting, qui sont des
rapports présentant de manière synthétique et lisible des données, sous forme de tableaux de
chiffres, tout en gérant la mise en page (en-tête, pied de pages...).
D'une manière générale, le fonctionnement d'un générateur d'état se décline sous 4 phases :
1. Obtention d'un fichier modèle XML.
2. Construction d'un rapport à partir du modèle.
3. Remplissage du modèle à l'aide des sources de données.
4. Exportation sous différents formats.
Nous pouvons ainsi le schématiser de la sorte :
Base de données Fichiers
Etape
3
Etape Etape Etape
1 2 4
Outil de designer Modèle XML Moteur de reporting Rapport rempli
Schéma de fonctionnement d'un générateur d'état
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 15 / 56État de l'art : Solutions Open Source Business Intelligence
La particularité d'un générateur d'état est qu'il peut se décliner sous deux aspects :
Interactif : l'utilisateur pourra tout aussi bien générer un état en le déclinant sous
plusieurs variantes (année, produit, région...).
Figé : les règles de gestion sont définies à la base et l'utilisateur ne se servira de
l'application que dans un mode Client-Serveur.
Cette particularité induit ainsi deux modes de conception diamétralement opposés :
Dans le mode interactif, la phase de paramétrage et de production ne requiert aucune
expertise particulière car elle est sous le contrôle de l'utilisateur final.
Dans le mode figé, a contrario, l'utilisateur ne peut modifier les paramètres des états.
La conception initiale nécessite donc une expertise spécifique et rigoureuse.
Il est cependant plus intéressant de mettre à disposition des générateurs d'état figés. Bien que
cette orientation nécessite un coût plus important, aussi bien en terme de temps que d'argent,
et qu'elle rigidifie les possibilités d'utilisation, l'expérience montre que les utilisateurs ont en
général d'autres priorités que celles de l'apprentissage de l'application et de la définition des
ses paramétrages.
Le principal inconvénient des générateurs d'états vient de leur utilisation. En effet, bien qu'ils
permettent au décideur de disposer d'une vue d'ensemble précise de son organisation, ils sont
plus utilisés afin de rendre des comptes. Cela s'inscrit dans une logique de management par le
contrôle, et non dans celle de la Business Intelligence.
Il existe également des générateurs de graphiques qui, comme leur nom l'indique, permettent
la visualisation des données sous forme de graphes. Néanmoins, bien que certains documents
distinguent ces outils des générateurs d'états, nous ne ferons pas la différence dans cet
ouvrage car la plupart de ces générateurs sont actuellement utilisés comme des moteurs
graphiques implémentés directement dans les générateurs d'états.
Point important : il ne faut pas confondre reporting et tableau de bord. Le premier est
généré par le générateur d'état alors que le second propose une vision plus globale.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 16 / 56État de l'art : Solutions Open Source Business Intelligence
Synthèse
Après avoir défini les différents outils, nous proposerons ici une vue d'ensemble de leurs
articulations et de leur liens, sous une représentation graphique théorique.
Data Mart
Générateur
d'état
BD Interne
Data Mart C ube OLAP Analyse
Multidimensionnelle
BD Externe
ETL
Data Warehouse
Data Mining
Fichiers TXT, Data Mart
C SV...
Tableaux de
bord
Source de Extraction Stockage Restitution
Données
Réprésentation d'un sytème d'information décisionnel
Cette représentation est schématique. En effet, elle illustre d'une manière globale les
différentes interactions entre chaque outil. Elle doit être considérer comme un socle d'analyse
et non comme une vérité absolue. Chaque cas d'implémentation d'une solution de Business
Intelligence est unique, et doit faire l'objet d'une étude des besoins. Ainsi, il n'est pas rare de
voir de nombreux systèmes d'information décisionnels dépourvus de solution de Data Mining,
ou bien encore d'en rencontrer où les données à analyser étant uniquement stockées dans une
base de données relationnelle, les générateurs d'états travaillent directement dessus sans
passer par un ETL, un Data Warehouse et un Data Mart. Ainsi, il est bon d'avoir une
représentation globale des différents éléments de Business Intelligence mais elle doit être
adapter aux différents cas et contextes rencontrés.
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 17 / 56État de l'art : Solutions Open Source Business Intelligence
Les solutions décisionnelles
Nous analyserons dans cette partie un panel des solutions existants dans le décisionnel, en
décrivant les aspects techniques, les fonctionnalités des outils et les caractéristiques globales
des communautés s'articulant autour.
ETL
Clover.ETL
● Clover.ETL est un ETL Open Source, basé sur un framework Java qui peut être
utilisé pour transformer des données structurées. Il peut être utilisé seul,
comme un serveur d'application, ou peut être embarqué dans d'autres
applications, comme une librairie de transformation.
Fiche d'identité
Caractéristiques générales de la solution
Projet âgé de 3 ans.
Bonne documentation.
Distribué sous Licence GPL.
Communauté
Sponsorisé par OpenSys, un administrateur et six
développeurs ont clairement étaient identifiés.
Taille de la communauté et visibilité Internet assez
faible.
Taux de fréquentation très bon.
Niveau d'accessibilité
Interface graphique.
Faible niveau de packaging.
Pas de traduction Française.
OS Indépendant.
Taux d'activité
Très bon.
02 avril 2008
Accès aux données
L'accès aux données est somme toute juste moyen. Bien que reconnaissant la plupart des
fichiers plats, fournissant un outil de création de requêtes, permettant leur exécution et ayant
une très bonne reconnaissance des bases de données, il ne gère pas les relations avec les
Aurélien CABROL - Mai 2008 Copyright © 2008 - ADULLACT Page 18 / 56Vous pouvez aussi lire

















































