Supervision et collecte de journaux 15-12-2021 - Pandora FMS
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Supervision et collecte de journaux 15-12-2021
Supervision et collecte de journaux
Pandora FMS| pg. 2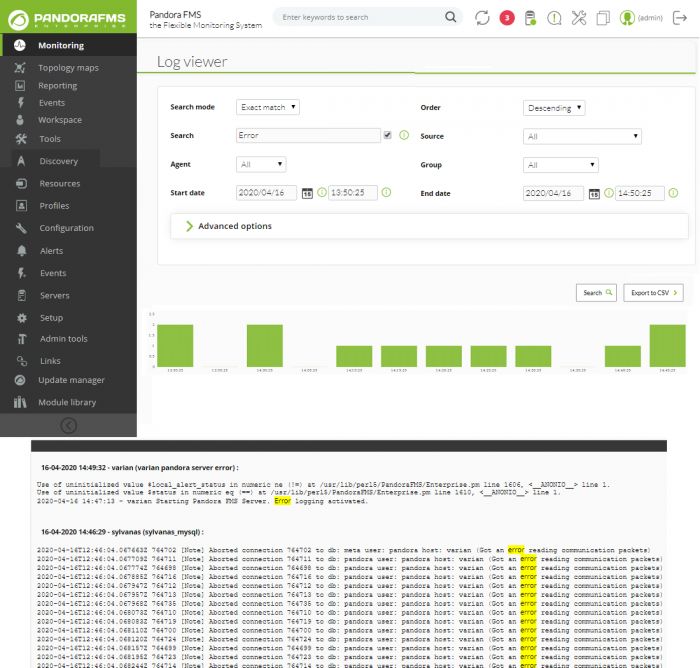
Supervision et collecte de journaux
Supervision et collecte de journaux
Retour à l'index de documentation du Pandora FMS
Collectes de logs
Introduction
Version 5.0 ou supérieure.
La supervision des logs dans Pandora FMS est abordée de deux façons différentes:
1. Basée sur des modules : Représente les logs dans Pandora FMS comme des
moniteurs asynchrones, pouvant associer des alertes aux entrées détectées qui
remplissent une série de conditions préconfigurées par l'utilisateur. La
représentation modulaire des logs nous permet de :
1. Créer des modules qui comptent les occurrences d'une expression régulière
dans un journal.
2. Obtenir les lignes et le contexte des messages du journal
2. Basé sur la visualisation combinée : Permet à l'utilisateur de visualiser dans une
seule console toutes les informations de logs d'origines multiples qu'il souhaite
capturer, en organisant les informations de manière séquentielle en utilisant la
marque du temps dans lequel les logs ont été traités.
A partir de la version 7.0NG 712, Pandora FMS intègre ElasticSearch pour stocker les
informations des logs, ce qui implique une amélioration substantielle des performances.
Comment ça fonctionne ?
Pandora FMS| pg. 3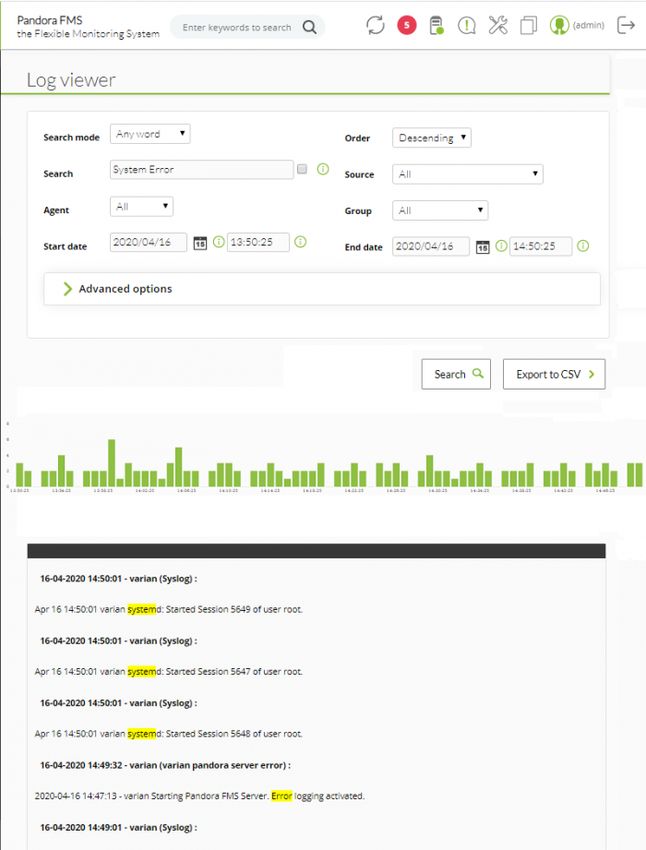
Supervision et collecte de journaux
Les logs analysés par les Agents Logiciels (eventlog ou fichiers texte), sont
transmis au serveur Pandora FMS, sous forme « littérale » (RAW) à l'intérieur du
rapport d'agent XML :
Le serveur Pandora FMS (DataServer) reçoit l'agent XML, qui contient à la fois les
informations de surveillance et de logs.
Lorsque le DataServer traite les données XML, il identifie les informations des logs,
en sauvegardant dans la base de données principale les références de l'agent qui a
rapporté et l'origine du log, et en envoyant automatiquement les informations à
ElasticSearch pour son stockage.
Pandora FMS stocke les données dans des index ElasticSearch générant
quotidiennement un index unique pour chaque instance de Pandora FMS.
Le serveur Pandora FMS dispose d'unce tâche de maintenance qui élimine les index
dans l'intervalle défini par l'administrateur du système (par défaut 90 jours.
Configuration
Configuration du serveur
Le nouveau système de stockage des logs, basé sur ElasticSearch nécessite la
configuration des différents composants.
Pré requis pour le serveur
Il est possible de distribuer chaque composant (Pandora FMS Server et ElasticSearch) dans
des serveurs indépendants.
Centos 7
Au moins 4 Go de RAM, mais nous recommandons 6 Go de RAM pour chaque intance
de ElasticSearch.
Au moins 2 CPU cores
Au moins 20 Go d'espace disque pour le système
Au moins 50 Go d'espace disque pour les données de ElasticSearch (le nombre peut
varier selon la quantité de données que vous souhaitez stocker).
Connectivité avec du Serveur et Console Pandora FMS vers l'API de ElasticSearch
(par défaut le port 9200/TCP).
Installation et configuration de ElasticSearch
Avant de commencer l'installation de ces composants, il est nécessaire d'installer Java sur
Pandora FMS| pg. 4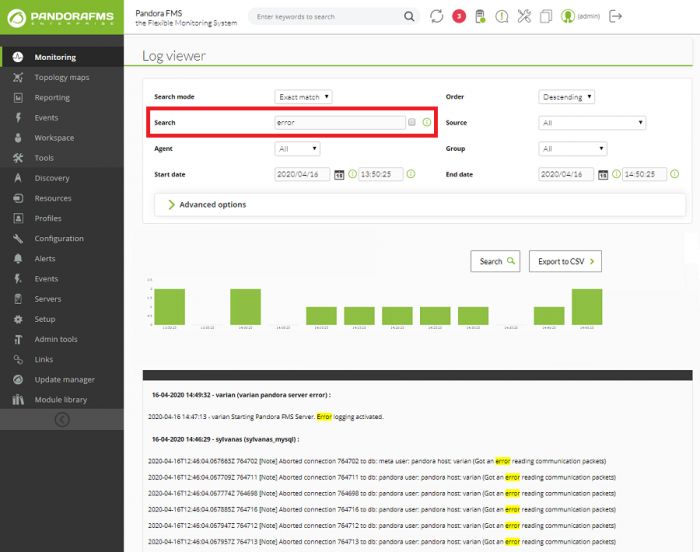
Supervision et collecte de journaux
la machine :
yum install java
Une fois Java installé, installez ElasticSearch suivant la documentation officielle ; les
environnements Debian ont leurs propres intructions.
Une fois le paquet téléchargé, nous l'installons en exécutant :
Configurez le service :
Configurez les options réseau et, éventuellement, les emplacements des données (et les
logs d'ElasticSearch lui-même) dans le fichier de configuration situé dans
/etc/elasticsearch/elasticsearch.yml.
# ---------------------------------- Network ----------------------
-------------
# Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 0.0.0.0
# Set a custom port for HTTP:
http.port: 9200
# ----------------------------------- Paths -----------------------
-------------
# Path to directory where to store the data (separate multiple
locations by comma):
path.data: /var/lib/elastic
# Path to log files:
path.logs: /var/log/elastic
Décommentez et définissez les lignes suivantes :
cluster.name: elkpandora
node.name: ${HOSTNAME}
bootstrap.memory_lock: true
network.host: ["127.0.0.1", “IP"]
cluster.name
Le nom du groupe ou grappe.
node.name
Pour nomer le noeud en utilisant la variable de système ${HOSTNAME}, celui-ci prendra le
nom de l'hôte.
bootstrap.memory_lock
Pandora FMS| pg. 5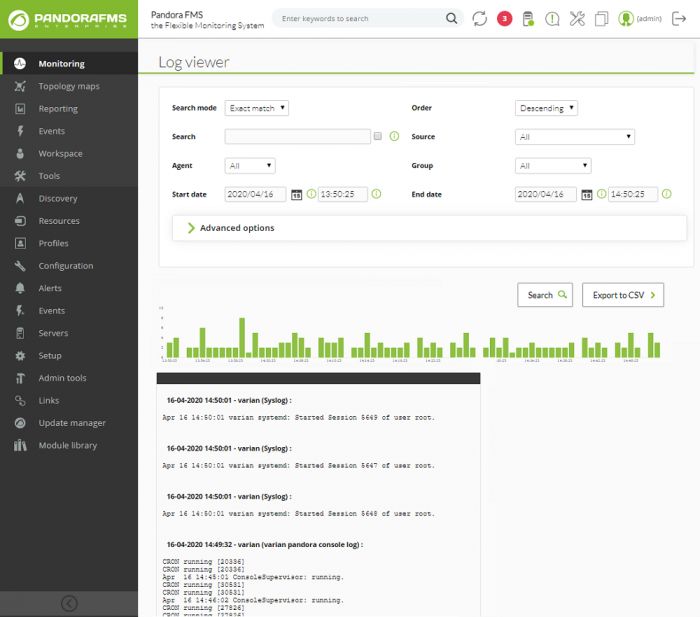
Supervision et collecte de journaux
Doit toujours être vrai « true ».
network.host
L'adresse IP du serveur.
Si vous travaillez avec un seul noeud, ajoutez aussi la ligne suivante :
discovery.type: single-node
Si vous travaillez avec une grappe, complétez le paramètre
discovery.seed_hosts.
discover.seed_hosts : [["ip:port",|"ip", "ip"]]
Ou bien :
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
Déterminez les options de resources alloués à ElasticSearch, en ajustant les paramètres
disponibles dans le fichier de configuration qui se trouve dans
/etc/elasticsearch/jvm.options. Nous vous recommandons d'utiliser au moins 2
Go d'espace dans XMS.
# Xms represDeents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms2g
-Xmx2g
Les ressources sont alloués selon l'utilisation de ElasticSearch, nous vous recommandons
de suivre la documentation officielle.
Il faut aussi changer dans le fichier de configuration de ElasticSearch le paramètre
memlock unlimited, placé dans le fichier
/usr/lib/systemd/system/elasticsearch.service pour ajouter le paramètre
suivant :
MAX_LOCKED_MEMORY = unlimited
Une fois fini, il faut éxécuter :
systemctl daemon-reload && systemctl restart elasticsearch
Pandora FMS| pg. 6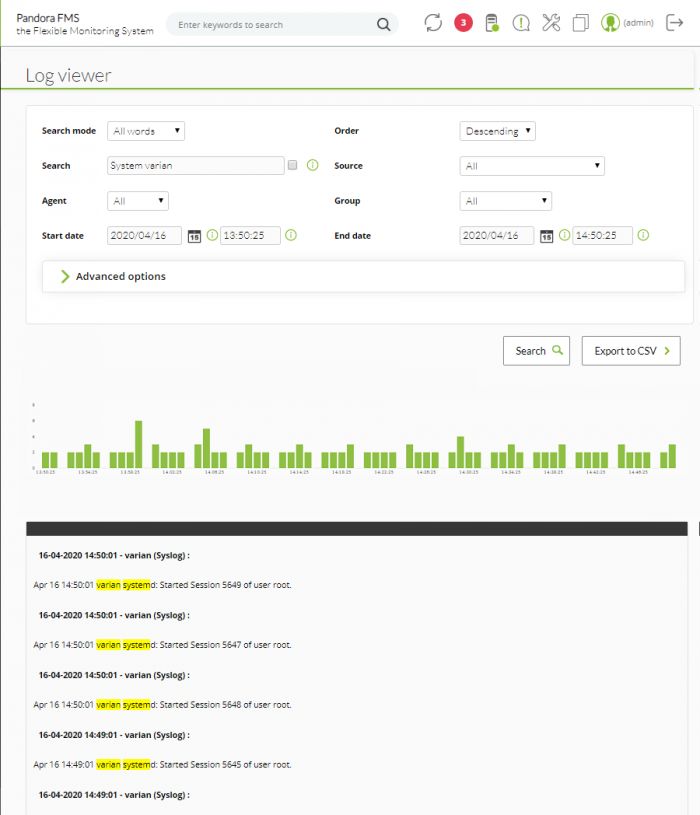
Supervision et collecte de journaux
La commande pour démarrer le service est :
systemctl start elasticsearch
Si le service n'est pas démarré, vérifiez les journaux
dans /var/log/elasticsearch/
Pour vérifier l'installation de ElasticSearch éxécutez la commande suivante dans un
fenêtre terminale :
curl -q http://{IP}:9200/
Vous recevrez une réponse similaire à la suivante :
{
"name" : "3743885b95f9",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "7oJV9hXqRwOIZVPBRbWIYw",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Visitez le lien de best practices de ElasticSearch pour des environnements de production :
https://www.elastic.co/guide/en/elasticsearch/reference/current/system-config.html#dev-v
s-prod
Pandora FMS SyslogServer
Pandora FMS| pg. 7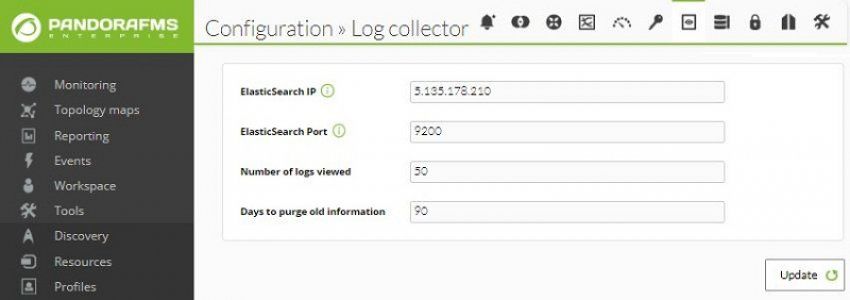
Supervision et collecte de journaux
Version NG 717 ou supérieure.
Ce composant permet à Pandora FMS d'analyser le syslog de la machine où elle se
trouve, d'analyser son contenu et de stocker les références dans notre serveur
ElasticSearch.
Le principal avantage de SyslogServer est de compléter l'unification des logs. Basé sur les
caractéristiques d'exportation de SYSLOG des environnements Linux® et Unix®,
SyslogServer permet la consultation des logs indépendamment de l'origine, en
recherchant dans un seul point commun (visualiseur des logs de la console Pandora FMS).
L'installation de Syslog Server doit se faire sur client et sur le serveur, et pour l'exécuter il
est nécessaire de lancer la commande suivante :
yum install rsyslog
Une fois syslog installé dans les ordinateurs à travailler, il faut accéder au fichier de
configuration /etc/rsyslog.conf pour habiliter l'input de TCP et UDP.
(...)
# Provides UDP syslog reception
$ModLoad imudp
$UDPServerRun 514
# Provides TCP syslog reception
$ModLoad imtcp
$InputTCPServerRun 514
(...)
Après avoir fait cet ajustement il sera nécessaire d'arrêter et relancer le service rsyslog.
Une fois le service disponible, vérifiez que le port 514 est accessible avec :
netstat -ltnp
Pour plus d'informations de la configuration de rsyslog, visitez leur site officiel.
Dans le client configurez-le pour que les journauz peuvent être envoyés au Syslog
Server. Pour ça accédez une autre fois au fichier de configuration de rsyslog
/etc/rsyslog.conf dans le client . Localisez et habilitez la ligne qui permet de
configurer l'hôte distant.
Pandora FMS| pg. 8Supervision et collecte de journaux
.* @@remote-host:514
L'envoi de logs génére un agent containeur avec le
nom du client, donc on vous récommande de créer les
agents avec « alias as name » en coïncidant avec le
hostname du client, ainsi vous éviterez de la duplicité
dans les agents.
Pour activer cette fonctionnalité, il suffit de l'activer dans la configuration, en ajoutant
àpandora_server.conf le contenu suivant :
# Enable (1) or disable (0) the Pandora FMS Syslog Server (PANDORA
FMS ENTERPRISE ONLY).
syslogserver 1
# Full path to syslog's output file (PANDORA FMS ENTERPRISE ONLY).
syslog_file /var/log/messages
# Number of threads for the Syslog Server (PANDORA FMS ENTERPRISE
ONLY).
syslog_threads 2
# Maximum number of lines queued by the Syslog Server's producer on
each run (PANDORA FMS ENTERPRISE ONLY).
syslog_max 65535
syslogserver
Booléen, activer (1) ou désactiver (0) le moteur d'analyse SYSLOG local.
syslog_file
Emplacement du fichier où les entrées SYSLOG sont livrées.
syslog_threads
Nombre maximum de fils à utiliser dans le système producteur/consommateur du
SyslogServer.
syslog_max
Il s'agit de la fenêtre de traitement maximale pour SyslogServer ; ce sera le nombre
maximum d'entrées SYSLOG à traiter dans chaque itération.
Vous aurez besoin d'un serveur ElasticSearch habilité
Pandora FMS| pg. 9Supervision et collecte de journaux
et configuré ; veuillez vérifier les points précedents
pour savoir comment.
Rappelez vous qu'il est nécessaire de modifier la
configuration de votre appareil pour que les journaux
soient envoyés au serveru Pandora FMS.
Recommandations
Rotation des journaux pour ElasticSearch
Important: Pour éviter que les journaux de ElasticSearch croissent sans mesure, créez
une nouvelle entrée pour le démon de rotation de journaux dans /etc/logrotate.d :
cat > /etc/logrotate.d/elasticSupervision et collecte de journaux
Où {index-name} est le fichier de sortie de la commande précédente. Cette opération
libère l'espace utilisé par l'index supprimé.
Configuration de la console
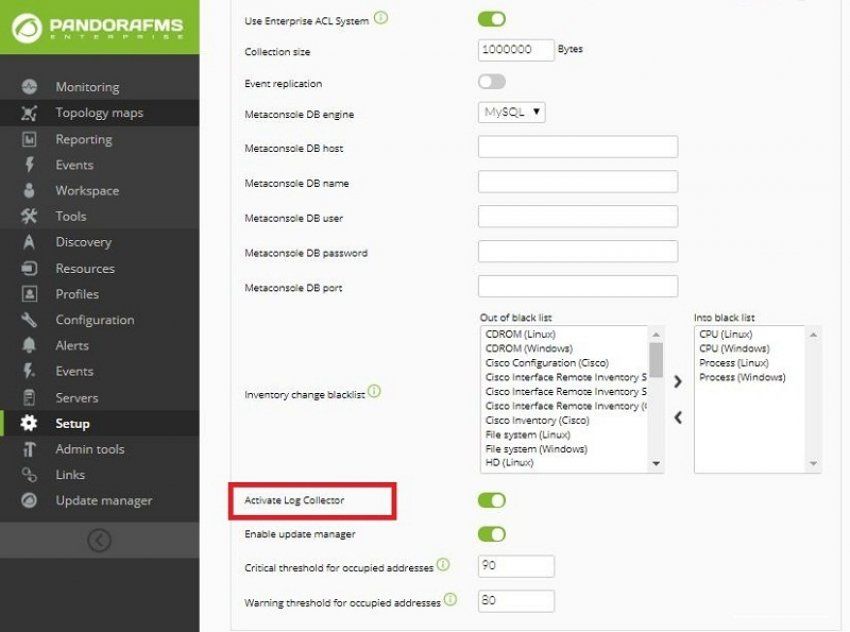
Pour activer le système de visualisation des logs, vous devrez activer la configuration
suivante :
Ensuite, vous pouvez configurer le comportement du visionneur de logs dans l’onglet
Configuration > Log Collector :
Pandora FMS| pg. 11Supervision et collecte de journaux
L'adresse IP ou FQDN du serveur qui héberge le service ElasticSearch.
Le nombre de logs affichés : Pour accélérer la réponse de la console, la charge
dynamique des enregistrements a été ajouté . Pour l'utiliser, l'utilisateur doit faire
défiler jusqu'à la fin de la page, ce qui oblige à charger le groupe suivant
d'enregistrements disponible, groupés selon le conmbre défini ici.
Jours à purger : Pour éviter que la taille du système ne soit surchargée, vous
pouvez définir un nombre maximum de jours pendant lesquels les informations des
journaux seront stockées. A partir de cette date, elles seront automatiquement
supprimées dans le processus de nettoyage de Pandora FMS.
ElasticSearch Interface
Version NG 747 ou supérieure.
Pandora FMS| pg. 12Supervision et collecte de journaux
Dans la configuration par défaut Pandora FMS génére un index par jour, fragmenté et
réparti pour des futures recherches.
Pour que ces recherches soient optimales, par défaut ElasticSearch génére un index pour
chacune, donc il faut configurer dans votre environnement aussi de recherches
(search) que le nombre de noeuds que vous avez installés.
Ces search et répliques sont configurés quand un index est créé, que Pandora FMS
génére automatiquement, donc pour modifier cette configuration il faut utiliser les
modèles.
Modèles de Elasticsearch
Les modèles avec des configurations qui sont
appliqués au moment de la création de l'index.
Changer un modèle n'aura aucun impacte sur les
index existantes.
Pour créer un modèle de base , seulement définnissez les champs suivants :
{
"index_patterns": ["pandorafms*"],
"settings": {
Pandora FMS| pg. 13Supervision et collecte de journaux
"number_of_shards": 1,
"auto_expand_replicas" : "0-1",
"number_of_replicas" : "0"
},
"mappings" : {
"properties" : {
"agent_id" : {
"type" : "long",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"group_id" : {
"type" : "long",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"group_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"logcontent" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"source_id" : {
"type" : "text",
"fields" : {
"keyword" : {
Pandora FMS| pg. 14Supervision et collecte de journaux
"type" : "keyword",
"ignore_above" : 256
}
}
},
"suid" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"utimestamp" : {
"type" : "long"
}
}
}
}
}
Si vous devez definir un modèle multinoeud vous devez avoir sur compte :
Lorsque vous configurez le template (format JSON), vous devez configurer aussi de
search que le nombre des noeuds que vous avez, cependant pour configurer
correctement les répliques vous devez soustraire 1 au nombre de noeuds
d'environnement.
Par exemple, dans un environnement de Pandora FMS avec ElasticSearch avec 3 noeuds
configurés, lorsque vous modifiez las champs number_of_search et
number_of_replicas ça devarit rester comme ça :
{
"index_patterns": ["pandorafms*"],
"settings": {
"number_of_shards": 3,
Pandora FMS| pg. 15Supervision et collecte de journaux
"auto_expand_replicas" : "0-1",
"number_of_replicas" : "2"
},
Vous pouvez faire ces opérations à travers de l'interface de ElasticSearch dans Pandora
FMS en utilisant les commandes natives d'ElasticSearch.
PUT _template/: Il permet d'introduire les données de
votre modèle.
GET _template/>: Il permet de voir le modèle.
Pandora FMS| pg. 16Supervision et collecte de journaux
Pandora FMS| pg. 17Supervision et collecte de journaux
Migration vers le système ElasticSearch
Une fois le nouveau système de stockage des logs configuré vous pouvez migrer toutes
les données précédemment stockées dans Pandora FMS, d'une manière distribuée dans
des répertoires vers le nouveau système.
Pour migrer vers le nouveau système, vous devrez exécuter le script suivant que vous
trouverez dans /usr/share/pandora_server/util/
# Migrate Log Data = 7.0NG 712
/usr/share/pandora_server/util/pandora_migrate_logs.pl
/etc/pandora/pandora_server.conf
Visualisation et recherche
Dans un outil de collecte de logs, nous nous intéressons principalement à deux choses :
rechercher des informations -filtrer par date, sources de données et/ou mots-clés- et voir
ces informations dessinées en occurrences par unité de temps. Dans cet exemple, nous
recherchons tous les messages de journaux de toutes origines au cours de la dernière
heure ; fixez-vous sur Search, Start date et End date :
Pandora FMS| pg. 18Supervision et collecte de journaux
Vista de ocurrencias a lo largo del tiempo
Le champ le plus important et utile sera la chaîne à chercher à introduire le cadre de texte
Search combiné avec les trois types de recherche disponibles ( Search mode ).
Exact match
Recherche de chaîne littéral, le journal contient une coîncidence exacte.
Pandora FMS| pg. 19Supervision et collecte de journaux
All words
Recherche qui contient tous les mots indiqués, n'importe l'ordre dans un même ligne
de journal (tenez sur compte désormais que chque mot soit séparée par des espaces).
Pandora FMS| pg. 20Supervision et collecte de journaux
Any word
Recherche qui contienne quelque des mots indiquñes. n'importe l'ordre.
Pandora FMS| pg. 21Supervision et collecte de journaux
Si vous marquez l'option de voir contexte du contenu filtré, vous obtiendrez une vue
générale de la situation avec de l'information d'autres lignes de journaux rélationnées
avec votre recherche :
Pandora FMS| pg. 22Supervision et collecte de journaux
Visualisation et recherches avancées
Version NG 727 ou supérieure.
Grâce à cette fonction, nous serons en mesure de représenter graphiquement les entrées
du journal, en classant l'information en fonction de modèles de saisie de données.
Ces modèles de capture de données sont essentiellement des expressions régulières et
des identificateurs, ce qui nous permettra d'analyser les origines des données et de les
représenter sous forme de graphique.
Pour accéder aux options avancées, cliquez sur Options avancées. Un formulaire
Pandora FMS| pg. 23Supervision et collecte de journaux
s'affiche dans lequel vous pouvez choisir le type d'affichage des résultats :
Afficher les entrées de journal (texte brut).
Afficher le graphique de journal.
Sous l'option Afficher le graphique de log, vous pouvez sélectionner le modèle de capture.
Le modèle par défaut, Apache log model, offre la possibilité d'analyser les journaux
Apache au format standard (access_log), en étant capable d'extraire des graphiques
comparatifs du temps de réponse, de grouper par page visitée et code de réponse :
Vous pouvez cliquer sur editer , ou créer pour faire un nouvel modèle de capture.
Pandora FMS| pg. 24Supervision et collecte de journaux
Capture regexp
Une expression regulière de capture de données, chaque champ à extraire est identifié
avec la sous-expression entre parenthèses (expression à capturer).
Fields
Champs selon l'ordre selon lequel ils ont été capturés avec l'expression regulière. Les
résultats seront groupés par la contaténation des champs clè qui sont ceux dont le nom
n'est pas entre des tirets bas :
clave, _valor_
clave1,clave2,_valor_
clave1,_valor_,clave2
Observation : Si vous ne spécifiez pas une valeur de champ, ce sera automatiquement le
nombre d'apparitions qui coïncident avec l'expression regulière.
Observation 2 : Si vous especifiez une colonne valeur, vous pourrez choisir entre
représenter la valeur accumulée (performance par défaut) ou maruqer la case de
vérification pour représenter la moyenne.
Example
Extraire des entrées d'un journal avec le format suivant :
Sep 19 12:05:01 nova systemd: Starting Session 6132 of user root.
Sep 19 12:05:01 nova systemd: Starting Session 6131 of user root.
Pandora FMS| pg. 25Supervision et collecte de journaux
Pour compter le nombre de fois que vous vous êtes connecté, en groupant par utilisateur,
utilisez :
Expression régulière
Starting Session \d+ of user (.*?)\.
Champs :
username
Ce modèle de capture retournera le nombre de connexions par utilisateur pour l'intervalle
de temps que vous avez sélectionné.
Pandora FMS| pg. 26Supervision et collecte de journaux
Configuration des agents
La collecte des logs se fait au moyen des agents, tant dans l'agent Windows que dans les
agents Unix® (Linux®, MacOsX®, Solaris®, HPUX®, AIX®, BSD®, etc). Dans le cas des
agents Windows, les informations peuvent également être obtenues à partir du visualiseur
d'événements Windows, en utilisant les mêmes filtres que dans le module de surveillance
Pandora FMS| pg. 27Supervision et collecte de journaux
du visualiseur d'événements.
Voyons deux exemples pour capturer les informations du log, sous Windows et Unix :
Sur Windows
À partir de la version 750 cette action peut être réalisée ay moyen des plugins d'agent en
activant l'option Advanced.
Des exécutions comme celles montrés ci-dessous pourront être effectuées :
Module logchannel
module_begin
module_name MyEvent
module_type log
module_logchannel
module_source
module_eventtype
module_eventcode
module_pattern
module_description
module_end
Module logevent
module_begin
module_name Eventlog_System
module_type log
module_logevent
module_source System
module_end
Module regexp
module_begin
module_name PandoraAgent_log
module_type log
module_regexp \pandora_agent\pandora_agent.log
module_description This module will return all lines from the
specified logfile
module_pattern .*
module_end
Pandora FMS| pg. 28Supervision et collecte de journaux
Pour plus d'informations sur la description des modules journal, consultez la section sur les
Directives spécífiques.
module_type log
Lorsque vous definissez ce type d'etiquétte, module_type log, il indique qu'il faut pas
stocker sur la base de données, mais les envoyer au collecteur de journaux. Tout module
avec ce type de donnée sera envoyé au collecteur, tandis qu'il est activé : sinon
l'information sera écartée.
Note : Cette nouvelle syntaxe n'est comprise que par l'agent de la version 5.0, vous devez
donc mettre à jour les agents si vous souhaitez utiliser cette nouvelle fonctionnalité
Enterprise.
Systèmes Unix
Unix utilise un nouveau plugin, fourni avec la version 5.0 de l'agent. Sa syntaxe est très
simple :
module_plugin grep_log_module /var/log/messages Syslog \.\.\*
Semblable au plugin d'analyse de logs (grep_log), le plugin grep_log_module envoie les
informations de logs traitées au collecteur de logs avec le nom “Syslog” comme source du
log. Utilisez l'expression régulière \.\* (dans ce cas “tout”) comme modèle pour choisir
les lignes à envoyer et celles à ne pas envoyer.
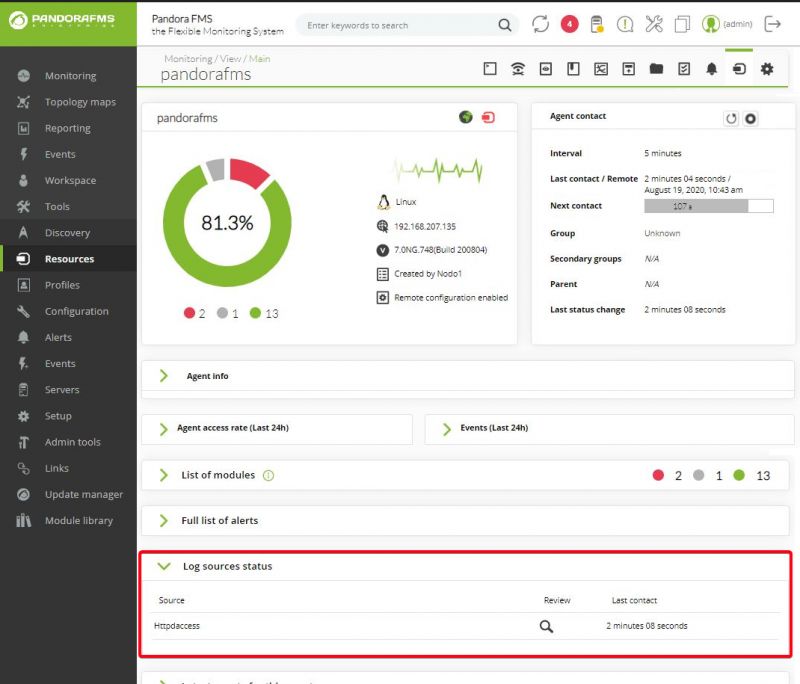
Log Source dans la vue d'agents
À partir de la versión 749 de Pandora FMS, un cadre a été ajouté à la vue d'agent appelé
Log sources status, dans lequel vous verrez la date de la dernière mise à jour des
journaux par l'agent. Si vous cliquez sur le zoom dans le Review, vous serez rédirigé à la
vue de Log Viewer filtrée par ce journal-là.
Pandora FMS| pg. 29Supervision et collecte de journaux
Retour à l'index de documentation du Pandora FMS
Pandora FMS| pg. 30Supervision et collecte de journaux
From:
https://pandorafms.com/manual/ - Pandora FMS Documentation
Permanent link:
https://pandorafms.com/manual/fr/documentation/03_monitoring/09_log_monitoring
Last update: 2021/11/11 23:44
Pandora FMS| pg. 31Vous pouvez aussi lire

















































