Comprendre les données visuelles à grande échelle - Inria
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Comprendre les données visuelles à grande échelle Karteek Alahari & Diane Larlus December 13th 2018 © 2018 NAVER LABS. All rights reserved.

Comprendre les données visuelles à grande échelle l Site Web: https://project.inria.fr/bigvisdata/ l Intervenants: ► Diane Larlus, Senior Scientist @ NAVER LABS ► Karteek Alahari, Chargé de Recherche @ INRIA Grenoble l 6 x 3h = 18h de cours l Évaluation : l Examen final écrit l Toutes les semaines l Quizz sur des articles de recherche l Présentation de ces articles (bonus!)

Organisation du cours l Séance du jeudi 13 décembre – 8h15 à 11h15 – D208 l Premier cours l Distribution des articles de recherche l Séance du jeudi 20 décembre – 8h15 à 11h15 – D208 l Deuxième cours l Présentation article 1 + quizz l Séance du jeudi 10 janvier – 8h15 à 11h15 – D208 l Troisième cours l Présentation article 2 + quizz l Séance du jeudi 17 janvier – 8h15 à 11h15 – D208 l Quatrième cours l Présentation article 3 + quizz l Séance du jeudi 24 janvier – 8h15 à 11h15 – D208 l Cinquième cours l Présentation article 4 + quizz l Séance du jeudi 31 janvier – 8h15 à 11h15 – D208 l Dernier cours l Présentation article 5 + quizz

Cours 1: Introduction, données, modèles et évaluation é à é é

Les données à grande échelle Comprendre les données visuelles à grande échelle Cours 1: Introduction, 13 décembre 2016

Les données à grande échelle Le big data • littéralement « grosses données » • méga données • données massives désigne un ensemble de données qui deviennent tellement volumineuses qu‘elles en deviennent difficiles à travailler avec des outils classiques de gestion de base de données. Wikipedia • Nécessite le développement d’outils spécifiques
Les données visuelles à grande échelle ou Big Visual Data sont devenues une façon majeure de transférer l’information
Quelques chiffres l Croissance très importante, en raison de l’accumulation des contenus numériques auto-produits par le grand public ► ImDb recense plus de 400 000 films ► Images (semi-)pro : Corbis, Getty, Fotolia ► centaines de milliers d’ images ► Facebook – chiffres de 2013 ► 350 millions de nouvelles photos / jour ► 250 milliards de photos stockées ► Flickr – novembre 2016 ► 13 milliards de photos ► Youtube ► 35h / min uloaded in 2011 ► 100h / min uploaded in 2014

Les données visuelles à grande échelle ou Big Visual Data sont devenues une façon majeure de transférer l’information Selon la British Security Industry Authority (BSIA), il y aurait autour de 5M de CCTV cameras en GB, soit une pour 14 habitants (source: telegraph-2013)

Les données visuelles à grande échelle ou Big Visual Data sont devenues une façon majeure de transférer l’information Seule une partie de ces données est exploitée, et une bonne partie du processus est fait à la main → opportunités de simplification de tâches fastidieuses → opportunités de nouvelles applications et de nouvelles solutions commerciales → développement de l’intelligence ambiante
Exemples d’applications du Big Visual Data l News/Films à la demande l Commerce électronique l Informations médicales l Systèmes d’informations géographiques l Architecture/Design l Protection du copyright / traçage de contenu l Géolocalisation, système de navigation l Enquêtes policières l Militaire l Expérimentations scientifiques l Enseignement l Archivage, gestion des bases de données de contenu (personnelles ou professionnelles) l Moteur de recherche (Internet, collections personnelles) l Voitures et autres véhicules autonomes l Robotique, plateformes d’intelligence ambiante l Autres applications industrielles
Exemples d’applications à NAVER LABS Autonomous Driving M1 Indoor 3D mapping robot
Chaîne du Big Visual Data 1. Génération : • outils de production et de création 2. Représentation • utilisation de formats de représentation différents 3. Stockage 4. Transmission • problème de réseaux, architecture 5. Recherche d’information • recherche basée sur le contenu 6. Distribution • conception de serveur de streaming, interfaces de l’application, etc.
Annotations d’images: variété et ambiguïté Comprendre les données visuelles à grande échelle Cours 1: Introduction, 13 décembre 2018
Contenu et métadonnées l Les données “brutes” (fichier image, fichier son) contiennent des informations sémantiques = directement compréhensibles pour l'utilisateur l Ces métadonnées proviennent ► Soit de propriétés de descripteurs des objets (ex: couleur moyenne d’une image, métadonnée surexposé) ► Soit de données d’autres médias (ex: GPS) ► Soit d’annotations manuelles (ex. Tags) .
Annotations / Métadonnées l Une annotation textuelle sera toujours trop restrictive, même si elle contient des informations syntaxiques et symboliques l Malgré cela, l’approche la plus utilisée reste l’annotation textuelle et manuelle l Avantage ► recherche indépendante du type de media ► techniques de base de données classiques l Inconvénients ► Le coût de ces annotations manuelles est très important ► Différentes personnes utilisent un vocabulaire différent pour signifier la même chose (ex: clair, lumineux). Ce problème est connu sous le nom du “problème du vocabulaire”. Différentes personnes peuvent décrire des aspects très différents du média (polysémie du contenu), la même personne décrira différents aspects en fonction de la situation.
Illustration de la polysémie du contenu Légendes possibles pour cette image: • « Charlotte promène son chien pendant les vacances de Noël » • footing, femme, chien, neige • « des vacances d’hiver sportives»
Exchangeable image file format (Exif) l Spécification pour les formats d’images des appareils numériques ► non uniformisé, mais largement utilisé l Pour JPEG, TIFF, RIFF. Ne supporte pas, PNG ou GIF l Le format supporte souvent ► Date et heure, enregistrés par l’appareil ► Les paramètres de l’appareil l Dépendent du modèle : inclus la marque et des informations diverses telles que le temps d’ouverture, l’orientation, la focale, l’ISO, etc. ► Une vignette de prévisualisation ► La description et les informations de copyright ► Les coordonnées GPS l Ce format est supporté par de nombreuses applications
Annotation d'images l Choix d’un type d’annotation l Ensemble de tags / étiquettes (une ou plusieurs étiquettes par image) l Position approximative de tous les objets (boites englobantes) l Position précise de tous les objets (masques de segmentation) l Phrases descriptives l Cohérence des annotations sur toute une base people motorbike people motorbike A motorcyclist turning right
Ambiguïté de l'annotation d'images l Difficile de se mettre d'accord sur les annotations l Exemple: Instructions pour la création d’une vérité terrain pour la compétition PASCAL 2009 All objects of the defined categories, unless: you are unsure what the object is. What to label the object is very small (at your discretion). less than 10-20% of the object is visible. If this is not possible because too many objects, mark image as bad. Viewpoint Record the viewpoint of the ‘bulk’ of the object e.g. the body rather than the head. Allow viewpoints within 10-20 degrees. If ambiguous, leave as ‘Unspecified’. Unusually rotated objects e.g. upside-down people should be left as 'Unspecified'. Bounding box Mark the bounding box of the visible area of the object (not the estimated total extent of the object). Bounding box should contain all visible pixels, except where the bounding box would have to be made Ø tout de même excessively large to include a few additional pixels (
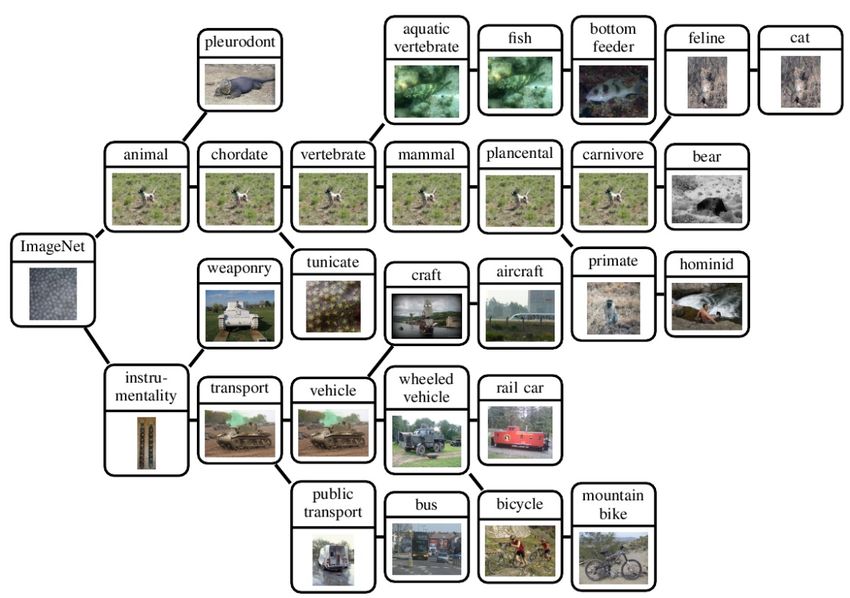
Ambiguïté de l'annotation d'images l Obtenir des annotations précises est une tâche fastidieuse l Une solution récente : plateformes de crowdsourcing, comme Amazon Mechanical Turk l Crowdsourcing : externalisation ouverte ou production participative en français l Amazon Mechanical Turk (AMT) l Origine du nom : le Turc mécanique ou l’automate joueur d'échecs est un célèbre canular construit à la fin du XVIIIe siècle : il s’agissait d'un prétendu automate doté de la faculté de jouer aux échecs l L’utilisation d’Amazon Mechanical Turk a permis la construction de bases d’images annotées qui ont grandement participé à l’avancée de la recherche en vision par ordinateur, par exemple: l ImageNet (http://image-net.org/) l MS Coco (http://mscoco.org/) l Visual Genome (https://visualgenome.org/) l Base VQA (http://www.visualqa.org/)
ImageNet
MS COCO • Common Objects in Contexts “What is COCO?” from its webpage COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features: • Object segmentation • Recognition in context • Superpixel stuff segmentation • 330K images (>200K labeled) • 1.5 million object instances • 80 object categories • 91 stuff categories • 5 captions per image • 250,000 people with keypoints
Visual Genome Article correspondant à lire pour la semaine prochaine (cf page du cours)
Quels sont les processus automatisables en analyse de données visuelles ? Comprendre les données visuelles à grande échelle Cours 1: Introduction, 13 décembre 2018
Recherche d’images par similarité Principe • Etant donné une image, retrouver les images similaires dans une grande base visuelle
Recherche d’images par similarité l Utilise la notion de proximité, de similarité, ou de distance entre images l Généralement, la requête est exprimée sous la forme d’un ou de plusieurs vecteurs dans un espace multidimensionnel. ► définition d’une distance (ou mesure de similarité) sur cet espace ► recherche des objets dont la distance est minimale l Les vecteurs sont extraits du contenu de l’image Recherche par le contenu ou CBIR: content based information retrieval l Possibilité d’utiliser un retour de pertinence l L’utilisateur spécifie quels résultats sont les plus pertinents pour sa requête l Le système raffine les résultats en fonction de ce retour
Recherche d’images: Indexation l Structurer la base pour ne pas avoir à la parcourir entièrement à chaque recherche, comme dans un dictionnaire l Utiliser une représentation adaptée au contenu des médias l Difficulté : les médias en question sont représentés par des vecteurs de grande dimension The curse of dimensionality La malédiction de la dimension l Définition: aussi appelée « fléau de la dimension », elle est liée à l’idée générale que lorsque le nombre de dimensions augmente, le volume de l’espace croit rapidement, et les données se trouvent isolées et deviennent éparses. Ce problème rend certaines méthodes développées en petites dimensions inefficaces, voire inopérantes.
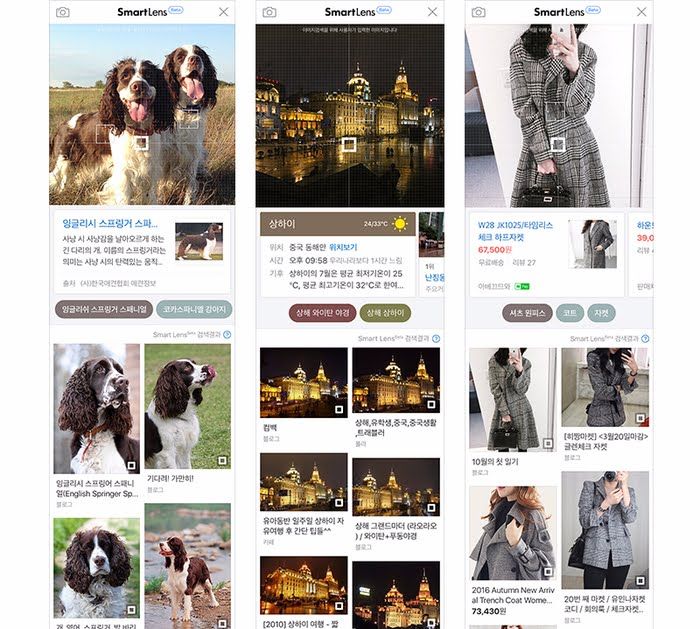
Moteurs de recherche basés sur le contenu La requête est une image • Google Goggles (2010) remplacé par • Google Lens (2017) • Smart Lens (2017) de Naver ► Google Lens ► Smart Lens (NAVER)
Moteurs de recherche basés sur le contenu l Google similar image search
Fonctionnalités d’un système idéal de recherche d’images l Ce qu’il doit permettre ► Ne pas reposer (uniquement) sur des annotations manuelles ► Le processus de requête est interactif ► Le processus de requête peut utiliser plusieurs modalités (ex: texte, image) l Il doit posséder deux modes ► Gestion du contenu (ajout, modification des objets présents, suppression) ► Interrogation de la base l Nécessité d’une interface utilisateur permettant la manipulation des objets existants, la présentation de résultats, le retour de pertinence
Variation d’apparence d’un objet donné scale reference image viewpoint occlusion illumination Diane Larlus PRAIRIE Artificial Intelligence Summer School July 2nd 2018
Autre processus automatisables: la reconnaissance d’objet Catégorisation d’image • Catégorie principale associée à l’image, ou réponse oui/non à une liste de catégories connues à l’avance Détection d’objet • Boite englobante pour toutes les instances d’une catégorie d’intérêt Segmentation d’objet, segmentation sémantique • Localisation précise des objets au niveau du pixel
Difficultés de la modélisation des catégories d’objet • Illumination, ombres • Orientation et pose • Fond texturé, distracteurs • Occultations • Variations intra-classe
Etiquetage d’image Image tagging • Catégorisation de l’objet principal contenu dans l’image (ou des différents objets) • lien avec la reconnaissance d’objet • Catégorisation de la scène • intérieur vs extérieur, paysage urbain ou campagnard, etc. • Tout autre type d’attributs possible • Couleur, forme, texture, etc. Tokyo tower Landscape Sunset Urban
Exemple d’outil d’étiquetage Démo proposée par Clarifiai (https://www.clarifai.com/demo) • lake • wood • water • fall • nature • no person • reflection • outdoors • landscape • scenic • mountain • wild • tree • river
Annotations avec des critères subjectifs • Qualités esthétiques • Prédire si le plus grand nombre va trouver une image agréable à regarder, visuellement esthétique • Iconicité d’une image • Prédire si une image est un bon représentant d’un concept, par exemple dans un but d’enseignement • Mémorabilité • Prédire si une image sera plus facilement remarquée, mémorisée (remembered) [AVA: Murray et al. CVPR12] [What makes an image iconic? Zhang et al. Arxiv 14] [Image memorability. Khosla et al. ICCV15]
Annotations plus complexes • Le sous-titrage automatique d’image (image captioning) Automatic Image Caption Generation Sample taken from the work of Andrej Karpathy and Li Fei-Fei More recent demo: https://www.captionbot.ai/
Annotations plus complexes • La réponse à des questions visuelles (Visual question answering) http://www.visualqa.org/ More recent demo: http://visualqa.csail.mit.edu/
Modèles et apprentissage Comprendre les données visuelles à grande échelle Cours 1: Introduction, 13 décembre 2018
Vocabulaire • Apprentissage automatique (Machine learning) champ d'étude de l'intelligence artificielle qui se base sur des approches statistiques pour donner aux ordinateurs la capacité d' « apprendre » à partir de données [..]. Il comporte généralement deux phases. - La première consiste à estimer un modèle à partir de données, appelées observations [..] Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. Wikipedia - La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. • Apprentissage profond (Deep Learning) est un ensemble de méthodes d'apprentissage automatique tentant de modéliser avec un haut niveau d’abstraction des données grâce à des architectures articulées de différentes transformations non linéaires • Intelligence artificielle (AI) est l'ensemble des théories et des techniques mises en œuvre en vue de réaliser des machines capables de simuler l'intelligence
AI in the news • 2016: computer beats a top-ranked professional player at the go game, known as one of the most difficult for computers • You can check the movie, e.g. on Netflix
AI in the news • September 2016: Google Translate moves to deep learning and cuts errors by 60% Credit: http://www.nature.com/news/deep-learning-boosts-google-translate-tool-1.20696
AI in the news 2016: the first proof of concept for neural network-based style transfer Figure adapted from L. Gatys et al. A Neural Algorithm of Artistic Style" (2015).
Pushing the state of the art • ImageNet challenge: • Task: Categorize images into 1000 classes
Pushing the state of the art • ImageNet challenge: • Task: Categorize images into 1000 classes • Until 2011: “standard” techniques (Fisher Vector) • Starting 2012: deep learning (CNNs) Deep Learning techniques have led to significant performance improvements in recent years (Source: Nervana)
The power of training Strictly static program instructions have huge applicative limitations Machine learning overcomes these limitations using data: • It explores algorithms that can learn from data to make predictions on data
The power of training Strictly static program instructions have huge applicative limitations Machine learning overcomes these limitations using data: • It explores algorithms that can learn from data to make predictions on data Machine learning is employed in computing tasks where designing and programming explicit algorithms is infeasible Early applications: • Spam filtering • Optical character recognition (OCR) • Search engines
Supervised learning Input: x Output: y Sheep Principle • Data collection • Training data for which we know the correct outcome, i.e. the label • Learning • within a class of methods, find the best hypothesis you can
Supervised learning • Traditional approaches for recognition Input data: pixels Output: label Feature Learning representation Algorithm Sheep Principle • Feature representation: hand crafted, not learnt • Learning algorithm: prediction is produced based on the training data
Deep Learning • Deep Learning is a type of machine learning algorithm • End-to-end learning (apprentissage de “bout-en-bout”) • Hierarchical modeling Layer 1 Layer 2 Layer 3 Sheep Principle • Learn a hierarchy • All the way from pixels to classifiers • One layer extracts features from the output of the previous layer
Deep Learning • Deep Learning is a type of machine learning algorithm • End-to-end learning (apprentissage de “bout-en-bout”) • Hierarchical modeling • Deep Learning is a deeper neural networks • Deeper = more layers • Neural networks • based on a large collection of neural units, or artificial neurons • loosely modeling the way a biological brain solves problems
Artificial Neurons • Biological neurons • Accept information from multiple inputs • Transmit information to other neurons • Artificial neurons • Multiply inputs by weights along edges • Apply some function to the set of inputs at each node
Multilayer Networks • Cascade neurons together • The output from one layer is the input to the next • Each layer has its own sets of weights • Weights are the parameters of the model that are learnt
Training a network • Training • Choose the right set of weights ( " ) along edges
Learning the network parameters [Credit: Karpathy - Standford – CS231 course]
Learning the network parameters • “Follow the slope” = direction of the derivative Numerical gradient: slow :(, approximate :(, easy to write :) Analytic gradient: fast :), exact :), error-prone :( Loss L Cow Layer 1 Layer 2 Layer 3 Sheep [Credit: Karpathy - Standford – CS231 course]
Backpropagation activations “local f gradient” gradients
Final recipe • Training a deep architecture Loop: 1. Sample a batch of data 2. Forward propagate it through the graph, get loss 3. Back propagate to calculate the gradients 4. Update the parameters using the gradient
Notions de similarité, de mesures, et d’évaluation Comprendre les données visuelles à grande échelle Cours 1: Introduction, 13 décembre 2018
Exemple d’un système de recherche d’images
Mesures et évaluation A) Distances et mesures de similarité B) Évaluation d’un système de recherche d’information
Distances et mesures de similarité : objectif l Avoir un outil quantitatif pour répondre à la question Est-ce que deux entités X et Y se ressemblent ? l Lorsqu’on désire comparer des entités, on cherche à obtenir un scalaire indiquant la proximité de ces entités l La mesure utilisée répond à un objectif particulier l Par exemple: ► compression d'image : comparer la qualité de reconstruction d’une image compressée avec l’image originale ► mise en correspondance d'images : indiquer la similarité du contenu de deux images (exemple du début de chapitre)
Distance l Une distance d sur un ensemble E est une application de E x E dans R+ vérifiant les axiomes suivants ► (P1) séparation d(x,y) = 0 ⇔ x = y ► (P2) symétrie d(x,y) = d(y,x) ► (P3) inégalité triangulaire d(x,z) ≤ d(x,y) + d(y,z)
Distances usuelles sur Rn x = (x1,…,xi,…,xn) dans Rn l Distance Euclidienne (ou distance L2) d ( x, y ) = å (x - y ) 2 i i i l Distance de Manhattan (ou distance L1) d ( x, y ) = å |xi - yi | i l Plus généralement, distance de Minkowski (ou p-distance) d ( x, y ) = p å ( xi - yi ) p i l Cas particulier : distance ∞ d ( x, y ) = miax |xi - yi |
Distance de Mahalanobis l Observation : les différentes composantes d’un vecteur ne sont pas forcément homogènes, et peuvent être corrélées l Comment comparer deux vecteurs ? ► Nécessité de pondérer les composantes ► Connaissance a priori sur la répartition des points : l Matrice de covariance S (apprise sur un jeu de données) Définition : la distance de Mahalanobis est d ( x, y ) = (x - y )T Σ -1 (x - y ) l Si S = Id, alors elle est équivalente à la distance Euclidienne l Si changement de repère x → Lx où L est la décomposition de Cholesky de S -1 =LTL alors la distance de Mahalanobis dans l'espace d'origine = distance L2 dans le repère transformé
Apprentissage de distance (supervisé) l Exemple dans le domaine linéaire l Supervisé: ► les points appartiennent à des classes (= ils ont des labels) ► Objectif ► maximiser la distance entre points de classes différentes ► minimiser la distance entre points de la même classe l Trouver W (méthode LMNN) ► échantillonner des triplets (q, p, n), minimiser ► descente de gradient en fonction de W l Plus pertinent que Mahalanobis ► proche de l'objectif: classification par plus proche voisin Metric Learning for Large Scale Image Classification: Generalizing to New Classes at Near-Zero Cost, Thomas Mensink ; Jakob Verbeek ; Florent Perronnin; Gabriela Csurka, ECCV 2012
Autres distances l Distance du c2 (khi-deux ou chi-square distance) pour comparer deux distributions (histogrammes) d ( x, y ) = (xi - yi ) 2 å i xi + yi l Valorise les variations dans les petites composantes d'un histogramme l Mahalanobis « du pauvre » quand on n'a pas de données pour calculer une matrice de covariance
Quasi-distance, similarité / dissimilarité l La notion de distance n’est pas toujours adaptée, car elle impose des axiomes très forts qui ne servent pas directement l’objectif recherché l Une quasi-distance q est une application de E x E dans R+ vérifiant les axiomes suivants ► (P1') x=y implique d(x,y) = 0 ► (P2) symétrie : d(x,y) = d(y,x) ► (P3) inégalité triangulaire: d(x,z) ≤ d(x,y) + d(y,z) l Une quasi-distance peut être nulle entre des objets différents l Plus général encore: mesure de dissimilarité ou de similarité l Lien évident entre similarité / dissimilarité ► Faible mesure de similarité = forte mesure de dissimilarité l Toute distance ou quasi-distance est une mesure de dissimilarité
Exemple l Le cosinus est une mesure de similarité ► pour des vecteurs normalisés, équivalent au produit scalaire ► Calcule la similarité entre deux vecteurs en déterminant le cosinus de l’angle entre eux http://dataaspirant.com
Mesures et évaluation A) Distances et mesures de similarité B) Évaluation d’un système de recherche d’information
Prérequis pour l’évaluation l Exemple : recherche et indexation d'images l Avoir à disposition ► un ensemble de test (base dans laquelle on recherche) ► un ensemble de requêtes (peuvent être incluses dans la base de test) ► une vérité terrain (ground truth) pour chaque couple (requête, élément de la base) qui répond à la question : est-ce que l’élément de la base est pertinent pour la requête considérée ? l Remarques ► pour comparer deux méthodes, les mêmes ensembles de test et de requêtes doivent être utilisés → bases de tests partagées par les chercheurs du domaine → compétition avec introduction de nouvelles bases de test ► la taille de ces ensembles doit être suffisamment grande pour diminuer la variance de l’évaluation ► attention bases trop faciles / trop difficiles → diminue la sensibilité ► question de la reproductibilité
Performances au cours du temps • Exemple de la classification d’action dans les vidéos • Amélioration de la performance sur différentes bases au fil des ans
Précision/rappel (début) l Soit E un ensemble d’objets (par exemple de textes, d’images, ou de vidéos) muni d’une mesure q telle que ► pour x, y ∈ E, q(x,y) = 0 si y est pertinent pour x q(x,y) = 1 sinon Remarque: on suppose ici la symétrie de la relation q l Cette mesure est la vérité terrain l Exemple : x et y sont deux images q(x,y) = 0 si x et y contiennent le même objet q(x,y) = 1 sinon l Soit un ensemble E’ ⊂ E, et x : x ∈ E et x ∉ E’ ► E’ : ensemble dans lequel on effectue la recherche ► x : la requête
Précision/rappel (suite) l Le système de recherche est paramétré pour retourner plus ou moins de résultats, entre 1 et #E’. l Compromis : ► plus on retourne de résultats, plus on a de chance de retourner tous les objets pertinents de la base ► en général, moins on en retourne, plus le taux d’objets retournés et qui sont pertinents est élevé l Ces deux notions sont couvertes par les mesures de précision et de rappel
Précision/rappel (suite)
l Soit R l’ensemble des résultats retournés, de cardinal #R
l Soit P l’ensemble des résultats pertinents dans E’ pour x, c-a-d
P = { y ∈ E’ / q(x,y) = 0 }
l Soit A l’ensemble des résultats retournés et qui sont pertinents
A = { y ∈ R / q(x,y) = 0 }
DEFINITION : la précision = #A / #R est le taux d’éléments qui sont pertinents parmi
ceux qui sont retournés par le système
DEFINITION : le rappel = #A / #P est le taux d’éléments pertinents qui sont retournés par
le système parmi les pertinents
l La performance du système peut être décrite par une courbe précision/rappel, en
faisant varier la taille de l’ensemble des résultats retournésPrécision/rappel (suite et presque fin) l Remarques : ► P est indépendant de la paramétrisation. ► R varie en fonction de la paramétrisation (qui retourne + ou – de résultats) E’ R P A
Précision/rappel (suite) • Equal Error Rate et Average Precision: réduire la courbe précision-rappel à une mesure de performance 1 Quelle est la meilleure précision méthode ? Equal Error Rate rappel 1 Average precision précision précision precision =recall rappel rappel
Exercice : système de recherche d’objets l Pour la requête et les résultats triés suivants : tracer la courbe précision/rappel, calculer la précision moyenne (Average Precision) Query 1 2 3 4 5 6 7 8 9 10
Exercice : système de recherche d’objets l Pour la requête et les résultats triés suivants : tracer la courbe précision/rappel, calculer la précision moyenne (Average Precision) 1 2 3 4 5 6 7 8 9 10
ROC (Receiver operating characteristic) l Soit une vérité terrain q(.,.) définissant la pertinence à une requête x l Réponse du système (imparfait) à une requête x ► r(x,y)=0 si y est retourné (objet considéré pertinent par le système), r(x,y)=1 sinon Vérité terrain Pertinent non pertinent Système Pertinent (=positif) True positive (TP) False positive (FP) q(x,y)=0 r(x,y)=0 q(x,y)=1 r(x,y)=0 False negative (FN) True negative (TN) Non pertinent (=négatif) q(x,y)=0 r(x,y)=1 q(x,y)=1 r(x,y)=1 REMARQUE : rappel = TP / (TP + FN) DEFINITION : taux de faux positifs = FP / (FP + TN) l Courbe ROC : rappel en fonction du taux de faux positifs
Et la pertinence ? DEFINITION: la pertinence d’un système (pour une paramétrisation donnée) est le taux d’objets qui sont correctement jugées, c’est-à-dire pertinence = (vrais positifs + vrais négatifs) / taille de la base l En recherche d’information (image, texte, etc.) c’est une mauvaise mesure de la qualité du système ► en général, la plupart des objets ne sont pas pertinents ► un système qui renverrait systématiquement “négatif” serait quasiment imbattable avec cette mesure l Intérêt d’avoir des courbes (PR et ROC) pour l’évaluation ► dépend de l’utilisation : certains utilisateurs cherchent la précision (ex: requête sur Google), d’autres un grand rappel possible (recherche de contenu piraté) ► operating point: choisir le bon point de fonctionnement du système
Mesures et protocoles d’évaluation : conclusion l Difficulté de trouver une bonne mesure ► elle doit être adaptée à ce que l’on compare (ex: loi de probabilité) ► elle doit répondre à l’objectif recherché l Évaluation d’un système de recherche dans des données visuelles ► méthodes identiques à celles utilisées en texte ► utilisation de courbes plutôt que de scalaires (peuvent être interprétées en fonction du besoin) ► n’intègrent pas les mesures de similarité, juste leur rang!
Biais dans les bases d'évaluation l Il est difficile (impossible ?) de construire une base de test parfaitement générique ► Photos pro / amateur ► Points de vue “typiques” : voiture de côté, anse de tasse à droite ► Environnements “typiques” : ville, campagne ► Choix des négatifs ► Base sélectionnée semi-automatiquement l Problème : les algorithmes apprennent le biais l Base de test n+1 créée pour supprimer le bias de la base n l Nouvelle direction de recherche active au vue des conséquences potentiellement impactantes dans le produit final Unbiased look at dataset bias, Torralba and Efros, CVPR 2011
Exemples de bias : reconnaissance de voitures
Exemples de biais dans un système IA • D’après une étude de 2015, les résultats de Google image search pour le mot “CEO” contenait seulement 11% de femme alors que 27% des CEO aux état unis sont des femmes. • Quelques mois plus tard, une autre étude a montré que le système de publicité en ligne de Google montrait des offres d’emploi fortement rémunérées plus souvent aux hommes qu’aux femmes.
Exemples de biais dans un système IA • Les outils de reconnaissance faciale sont de plus en plus utilisés par les forces de l’ordre, en particulier aux US • Février 2018, Joy Buolamwini (MIT) a montré que les derniers outils de reconnaissance de genre pouvait identifier correctement le genre d’une personne dans une photographie à 99% dans le cas des hommes blancs, mais que ce taux tombait à 35% pour les femmes de couleur. • Risque accru de mauvaise identification pour les minorités • Lié aux données utilisées pour l’apprentissage, l’algorithme est meilleur pour les données correspondant aux populations les plus largement rencontrées dans les bases d’apprentissage. • Les auteurs des algorithmes ont annoncé travailler à leur amélioration
Merci © 2018 NAVER LABS. All rights reserved.
Vous pouvez aussi lire

















































