Métrologie centralisée dun cluster Docker - Tuteur : Stéphane Casset Mercredi 27 mars 2019 - Loria
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Métrologie centralisée dun cluster Docker
Auteurs : Berard Benjamin, Egloff Maxime,
Lancetti Aymeric, Galichet Victor
Tuteur : Stéphane Casset
Mercredi 27 mars 2019
page 1 Métrologie Centralisée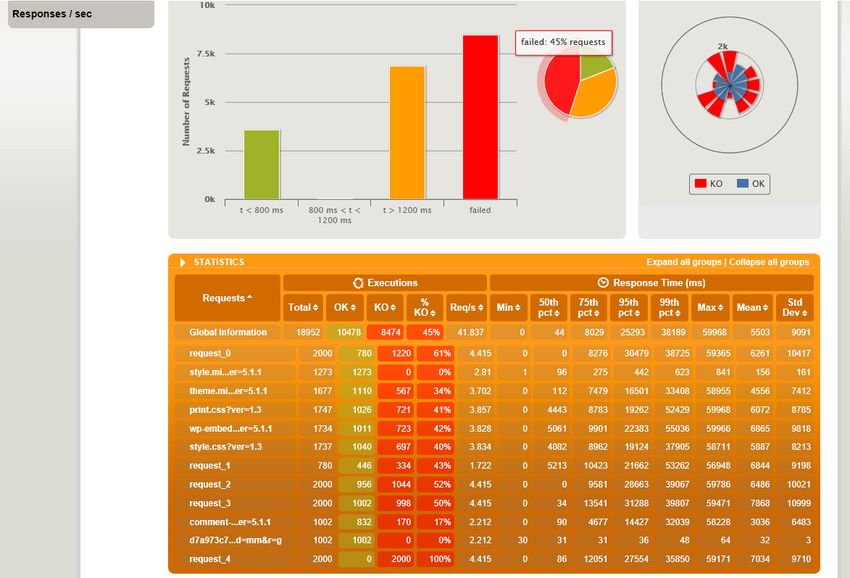
Table des matières
Contents 3
Remerciements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Contexte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Problématique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Le Principe de la métrologie centralisée . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Métrologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Métrologie centralisée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Présentation de notre support de travail . . . . . . . . . . . . . . . . . . . . . . . . . 8
Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Docker-machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Docker Swarm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Principe de la conteneurisation . . . . . . . . . . . . . . . . . . . . . . . 10
Description des types de solutions utilisées . . . . . . . . . . . . . . . . . . . . . . . . 11
Cadvisor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Node-Exporter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Apache Exporter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Netdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Telegraf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Synthèse des solutions de sondes . . . . . . . . . . . . . . . . . . . . . . . 15
Gestions des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Centralisation de toutes les sondes . . . . . . . . . . . . . . . . . . . . . 16
Prometheus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Graphite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Base de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
Différence avec une base de données classique . . . . . . . . . . . . . . . 17
InfluxDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Rétentions Policies . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Continuous Query . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Shard Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Thanos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Timescale DB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Synthèse des solution pour la bases de données Time Series . . . . . . . . 21
Outils de visualisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Grafana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Prometheus graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Chronograf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Alertes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2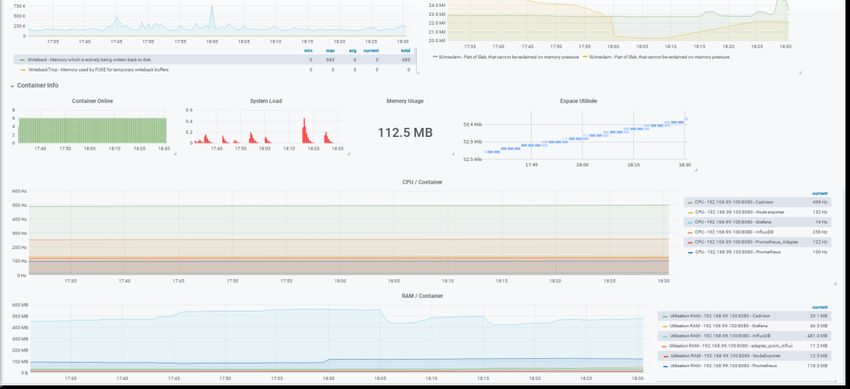
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Système webhook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Discord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Slack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Logiciels de Stress . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Gatling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Apache Jmeter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Synthèses des solutions de stress . . . . . . . . . . . . . . . . . . . . . . . 26
Description et mise en place de linfrastructure . . . . . . . . . . . . . . . . . . . . . . 28
Schéma d’interaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
Impact de performance de la métrologie Centralisée . . . . . . . . . . . . . . . . . . 33
Simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
Alertes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Problèmes rencontrés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Docker-Compose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Configuration obsolète . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
InfluxDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Espace mémoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Sondes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Compatibilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Organisation du projet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
Répartition des tâches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Bibliographie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Liens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Annexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
How to create cluster docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Installation Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Installation Docker-machine . . . . . . . . . . . . . . . . . . . . . . . . . 42
Installation Infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Installer Docker-compose (sur noeuds) . . . . . . . . . . . . . . . . . . . 43
Leader . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
docker-compose.yml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
prometheus.yml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Worker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
docker-compose.yml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
Fichier denregistrement gatling . . . . . . . . . . . . . . . . . . . . . . . 50
page 3 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Remerciements
Avant de débuter le rapport de notre projet, nous tenons à remercier lensemble des personnes
qui ont pu, de près ou de loin, nous suivre durant toute lélaboration de ce projet.
Nous remercions lensemble du corps enseignant de la licence professionnelle comportant tous
les enseignants-chercheurs, intervenants de luniversité de lorraine.
Nous remercions Monsieur Stéphane Casset, administrateur système et réseau ainsi quassocié-
gérant de la société logidee qui nous a donné lopportunité de réaliser ce projet. Lexpertise de
ces conseils nous ont permis davancer et de surmonter les problèmes.
Nous remercions également Monsieur Lucas Nussbaum, Debian Project Leader (DPL) da-
vril 2013 à avril 2015, maître de conférence à l’Université de Lorraine et chercheur auprès du
laboratoire LORIA, pour nous avoir donné lenvie daller plus loin dans lunivers du monde libre.
Merci encore à la licence Professionnelle ASRALL ( Administration de Systèmes, Ré-
seau et Application à base de Logiciels Libres) qui nous a dispensé les connaissances nécessaires
à nos expériences futures.
Merci Monsieur Philippe Dosch, responsable de la licence qui a su nous guider tout au long
de cette année.
page 4 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Introduction
Contexte
Les infrastructures des entreprises ont besoin d’être disponibles tout le temps, afin que les ad-
ministrateurs ne soient pas obligés de découvrir les problèmes qui surviennent lors de louverture
dun ticket Helpdesk. Pour cela, différents outils de supervision, métrologie ont été créés. Ils per-
mettent une vue densemble de toute linfrastructure mais permettent aussi aux administrateurs
de toujours garder un oeil attentif sur tout le système. En principe, la loi de Murphy nous dit
“Tout ce qui est susceptible de mal tourner, tournera mal” . Pour se prémunir de tout problème,
la métrologie est lune des solutions appropriées afin déviter de devoir réagir trop tardivement
face à un dysfonctionnement.
Les entreprises évoluent et ne cessent de faire croître leurs systèmes dinformations. Ceci les
incitent à utiliser des systèmes de conteneurisation 1 afin de réduire les coûts dexploitations tels
que de multiples serveurs, une réduction de l’électricité, une réduction des coûts de mainte-
nances. Pour cela, les infrastructureS ont décidé de se reposer sur un système de conteneur, où
chaque conteneur contient un seul service / besoin. Le projet Docker est ainsi né de ce besoin
de gérer les conteneurs.
De ce système de conteneurisation est né le besoin de connaître létat de tous les conte-
neurs. Le principe est davoir une centaine de serveurs sur lesquels nous souhaitons savoir si les
applications lancées sur le serveur fonctionnent. Il faut également pouvoir voir létat de santé
des serveurs afin de pouvoir réagir en cas de besoin.
1. La conteneurisation, à ne pas confondre avec la virtualisation est une méthode permettant dexécuter une
application dans un environnement virtuel dans une seule zone appelée Conteneur
page 5 Métrologie Centralisée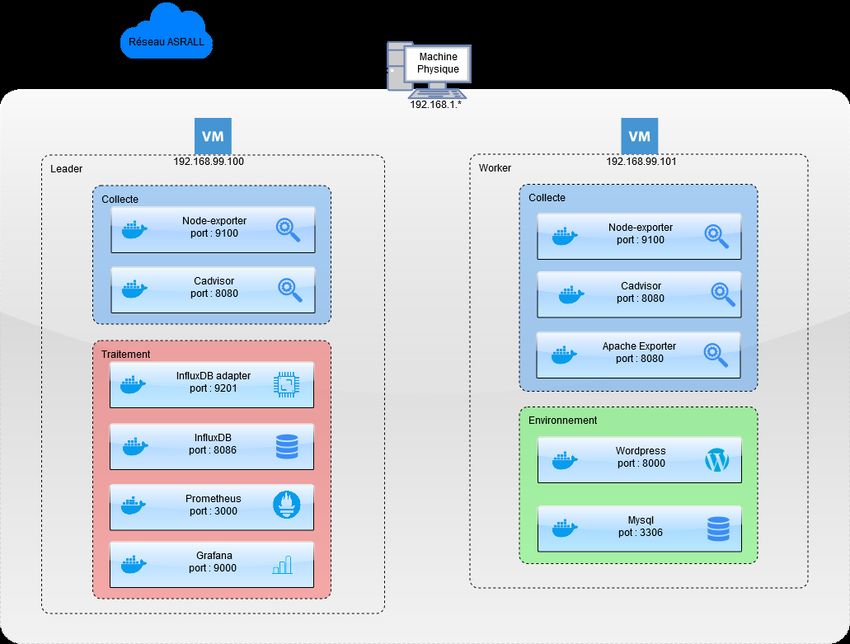
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Problématique Lobjectif de notre projet est de créer un système qui permettra davoir une vue densemble de tous les conteneurs. Celui-ci dressera un compte rendu dun coup doeil pour ladministrateur en charge du cluster Docker. La technologie de conteneurisation est une technologie qui évolue très vite. il faut donc avoir une élasticité 2 permettant lajout de serveurs, de conteneurs. Il est possible d’utiliser munin comme solution, cependant, il porte plusieurs soucis, en effet munin n’est pas précis, il affiche une data toutes les 5 minutes et la personnalisation des graphiques sont très limités. Il existe différentes solutions de surveillances. Nous avions besoin dune base de données en time series capable de faire de la rétention de donnée. On voulait donc également un accès direct sur les données perçues depuis une interface graphique. Il nous fallait aussi des sondes qui récupèrent les données de la machine virtuelle ainsi que celle des conteneurs. Enfin, un système dalerte ainsi quun affichage clair et personnalisable pour voir en direct les éventuelles incidents. La solution se compose de prometheus (avec les imports de métrique node exporter et cadvisor), influxDB pour notre base de données, grafana pour laffichage, ainsi que discord et slack pour lalerting. Comment pouvons-nous allier lutilisation dun cluster Docker et ses différentes métriques en ayant un filtrage pour avoir un rendu précis ? 2. L’élasticité dans le cloud computing est la capacité de ce cloud à s’adapter aux besoins applicatifs le plus rapidement possible page 6 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Le Principe de la métrologie centralisée Métrologie Malgré les différentes solutions de haute-disponibilité, un réseau dentreprise n’est jamais à labri dun dysfonctionnement au sein de linfrastructure. Le monitoring a pour but davoir une vue claire et détaillée de létat du système informatique et de létat du réseau informatique en temps réel. Métrologie centralisée La centralisation de la métrologie permet à un administrateur système de ne surveiller quun seul point disponible 24h/24 7j/7. Il est donc plus simple de créer des alertes ou alarmes sur toute linfrastructure en cas de dysfonctionnement et donc permet la recherche plus rapidement plutôt que de passer sur chaque serveur afin de savoir qui est le défaillant. La centralisation apporte que des avantages pour un agent ayant pour mission de monitorer un parc informatique mais aussi de prévenir des risques. Il peut agir sur des périodes et travailler sur la granularité pour avoir des données très précise. La métrologie apporte que des avantages pour un agent ayant pour mission de monitorer un parc informatique mais aussi de prévenir des risques. En effet la prévention des risques fait partie de la métrologie centralisée. Il est possible de la mettre en place à grande échelle une prévention qui permet à lapplication destimer à quel moment le taux critique peut être atteint et de prévenir à laide dune alerte avant que la défaillance ait lieu. page 7 Métrologie Centralisée

Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Présentation de notre support de travail
Docker
Figure 1 : Logo Docker
Docker 3 est un logiciel libre disolation dapplication de bas niveau.
Docker utilise des fonctionnalités provenant du Kernel Linux, tels que les conteneurs et les
Cgroups. Lutilisation des Cgroups lui permet dutiliser les fonctionnalités du noyau Linux pour
limiter, compter et isoler l’utilisation des ressources comme la RAM, les accès réseau, les CPUs.
Il est ainsi basé sur lAPI 4 de la solution de virtualisation LXC 5 . La solution docker a tout
dabord été développée par Solomon Hykes pour la société dotCloud. Puis le projet a été rendu
disponible en tant que projet open source depuis le 13 mars 2013 sur les systèmes Linux,
MacOS et plus tard sous Windows. Cest un outil utile pour déployer facilement et rapidement
des services sans se soucier des problèmes de compatibilité éventuels entre les systèmes.
Docker est un outil qui permet dempaqueter une application et toutes ses dépendances dans un
même conteneur. Il permet d’exécuter cette application sur tout type de de serveur (quimporte
sa version). Il permet ainsi des mises à jour bien plus simples et aisées pour les administrateurs
système.
3. source projet : https ://www.docker.com/
4. application programming interface : un ensemble normalisé de classes, de méthodes ou de fonctions qui
sert de façade par laquelle un logiciel offre des services à d’autres logiciels.
5. LXC : contraction de langlais Linux Containers est un système de virtualisation, utilisant l’isolation
comme méthode de cloisonnement au niveau du système d’exploitation
page 8 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Docker-machine
Docker ne fonctionne pas comme une machine virtuelle. Il nembarque pas dO.S. dédié et utilise
seulement son application avec ses dépendances spécifiques. Nous avons donc besoin dutiliser
plusieurs docker-machine. Nous avons besoin de faire la différentiation entre le leader et les
workers permettant ainsi davoir un cluster de plusieurs dizaines de données.
Lutilisation de la fonctionnalité Docker-machine permet de faire la liaison entre le logiciel
Docker et un hyperviseur permettant aux logiciels dockers de gérer les machines. Dans notre
cas, nous utiliserons le driver virtualbox afin de créer notre cluster.
Docker Swarm
Docker Swarm permet de gérer des cluster Docker en les associant autour dun ou plusieurs
leader. Les dockers swarm permettent de répartir automatiquement les charges de travail des
différents conteneurs qui sont exécutés.
Figure 2 : Fonctionnement Docker Swarm - source : docker.com
page 9 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Principe de la conteneurisation
Les conteneurs sont des espaces virtuels qui présentent un avantage important. Ils ne nécessitent
pas dOS permettant disoler les ressources.
La virtualisation consiste à exécuter de nombreux systèmes dexploitation sur un seul et même
système. Les conteneurs se partagent le noyau de système dexploitation hôte et isolent les
processus de lapplication du reste du système.
Figure 3 : Schéma conteneur VS vm
Lun des problèmes de la virtualisation est la suivante : si lon souhaite utiliser le même système
dexploitation, on devra le retélécharger et recommencer la configuration sur la machine virtuelle.
Lutilisation dun conteneur permet de navoir que les applications et les dépendances.
La virtualisation reproduit toutes les interactions du système physique. Ce nest pas le cas du
conteneur qui lui, se base sur notre machine, ce qui a pour résultat une utilisation réduite des
performances de notre machine.
Concrètement, il est possible dexécuter près de 4 à 6 fois plus dinstances dapplications avec
un conteneur quavec des machines virtuelles. Etant donné lespace et les ressources que les
conteneurs nécessitent, la densité applicative est bien plus vaste.
page 10 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Description des types de solutions utilisées
Au cours du projet, nous avons utilisé beaucoup dapplications qui nont pas lieu d’être dans
le schéma de linfrastructure finale. Cependant pour savoir comment trouver les étapes, nous
avons dressé un schéma regroupant les 6 étapes nécessaires au bon fonctionnement de tout le
système de métrologie centralisée.
Figure 4 : Etapes de notre projet
Notre projet se compose ainsi de 6 types de solutions :
• Les sondes
• La gestion des données
• La base de données
• Les outils de visualisation
• Les alertes
• Les logiciels de stress
Pour chaque type de solution, nous allons avoir plusieurs possibilités.
Nous les avons toutes détaillées pour voir leurs différentes caractéristiques et définir le support
de la communauté présente derrière le projet concerné.
Certains projets présentés étant trop jeunes, nous avons donc décidé de les écarter par manque
dinformation. dautres projets étant trop anciens, (documentations et utilisation potentiellement
obsolètes), nous avons également décidé de les écarter.
Notre écosystème comportent des applications web multiples. ne sachant pas à lavance leur
nature, nous avons donc besoin de toucher lensemble des composants.
page 11 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Cadvisor Cadvisor ou container advisor, fournit aux utilisateurs de conteneurs une compréhension de lutilisation des ressources et des caractéristiques du rendement des conteneurs en fonctionne- ment. Lapplication prend nativement en charge les conteneurs dockers, et supporte la majeure partie des fonctionnalités des autres orchestrateurs de conteneurs tels que Kubernetes, dû principale- ment aux propriétés en relation avec le kernel Linux. Le projet cadvisor a été créé et développé par la société Google pour leur propre projet dor- chestrateur de Conteneurs ( cf Kubernetes 6 ). Il est rendu publique le 9 juin 2014. Cadvisor est basé sur lancien projet LMCTFY 7 qui a pour objectif de faire l’implémentation des données de Docker / LXC. Notre version testée est la dernière, cest la version v0.32.0 Node-Exporter Node-Exporter se rapproche du principe de cadvisor, mais lui permet de récupérer les données de la machine hôte et non pas des conteneurs. Le projet Node-Exporter a la particularité d’être un projet dirigé par la communauté autour du logiciel Prometheus. Il est donc en adéquation avec celui-ci et comporte une très grande partie des metrics que peuvent avoir dautres solutions, il est très stable du point de vue de son développement. La version utilisée est la 0.17.0. 6. https ://en.wikipedia.org/wiki/Kubernetes 7. github.com/google/lmctfy page 12 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Figure 5 : Logo Apache Exporter
Apache Exporter
Apache Exporter est un exportateur Prometheus écrit en Go. il a été créé pour les métriques
qui concernent le serveur web Apache, il exporte les rapports d’état du serveur Apache générés
par mod_status comme lespace disponible et utilisé sur la racine dApache soit /var/www/pu-
blic_html ou encore le nombre de requête effectuées sur les serveurs Apache.
Version actuel dapache Exporter (0.5.0).
Netdata
Netdata est un outil de supervision en temps réel pour les systèmes Linux qui permet de
visualiser les éléments importants d’un système (processeur, mémoire, débit du disque dur,
traffic réseau, application, etc.).
• Projet très suivi par sa communauté.
• Très consommateur en performance à cause de ses métriques instantanées et son dash-
boards.
Version actuelle de netdata (1.13.0 ).
page 13 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Telegraf
Telegraf est un plug-in écrit en Go. Il a été conçu pour collecter et rapporter des métriques
systèmes comme le CPU, la RAM ou lespace disque.
Il permet également de rapporter des métriques applicatives comme apache, présent dans
notre label applicatif.
Pour cela, Telegraf collecte des métriques via des plugins ń input ż, les transforme si besoin,
et les envoie dans des plugins ń output ż.
Il existe beaucoup de plugins input et output, il suffit juste de les paramétrer dans la
configuration telegraf.
Nous avons utilisé le plugin input de docker. Celui-ci récupère les données d’un service
docker.
page 14 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Synthèse des solutions de sondes
Type de Compatibilité Métriques générées
sonde avec Prometheus
Cadvisor Conteneur oui conteneur
Telegraf Système non Conteneur et physique
Apache Exporter Applicatif oui serveur web
Node Exporter Système oui physique
Netdata Système oui physique
Nous avons choisi dinstaller Node Exporter, Cadvisor ainsi quApache Exporter, car ces sondes
nous permettaient davoir les métriques des conteneurs, de la machine physique, ainsi que le
serveur web.
Nous avons abandonné lutilisation de Netdata car il a généré beaucoup de problèmes de per-
formance et nétait pas compatible avec notre solution au moment du projet.
Telegraf, quant à lui, ne permettait pas lutilisation de Prometheus et se liait directement avec
influxDB.
page 15 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Gestions des données Dans le cadre de notre projet, toute les données qui vont transiter grâce aux sondes devront donc être gerer. Nous avons besoin dune solution qui nous permettra de tout centraliser sur un même logiciel. Pour cela, plusieurs solutions soffrent à nous pour récolter les données que les sondes vont transmettre. Centralisation de toutes les sondes Prometheus Prometheus est un projet open-source développé par des ex-ingénieurs de Google. Il utilise le langage de requête “PromQL” . La communauté est très active, contient de nombreux développeurs à son actif et de nom- breuses entreprises lutilisent. Son avantage principale est sa flexibilité. Il peut être utilisé dans la surveillance, centralisée sur une machine ou encore sur des architectures bien plus avancées et dynamiques. Prometheus est un système complet de surveillance et dalerting. Il contient des fonctions natives pour récolter ses propres données. Il peut également créer des graphiques à partir de ses données ainsi qu’à des mesures externes et les stocker temporairement. Dans le cadre du projet nous utilisons dautres modules pour compléter larchitecture, dont influxDB adapter, qui permet de faire la transition entre Prometheus et influxDB. Graphite Graphite stocke des échantillons numériques pour des séries chronologiques nommées, un peu comme Prometheus. Cependant, Graphite est surtout une base de données passive de séries chronologiques avec un langage de requête et des fonctions graphiques. Pour aller plus loin dans le traitement des données, Graphite est obligé d’utiliser des composantes externes. Prometheus, lui, est plus complet et ne nécessite pas forcément lintervention de module externe. page 16 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Base de données
Actuellement, la majorité des données qui transitent sur internet ( Big Data ) sont de nature
temporelle. Toute ces données sont appelées des transactions.
Dans notre cas dutilisation de la base de données, nous avons les besoins suivants :
• Stocker un très grand flux de données.
• Un flux de données sans aucunes relations réelles.
• Un flux de données qui est régie par son horodatage
• Faire des milliers de requêtes sans difficultés.
• Une latence très courte pour un affichage rapide
Différence avec une base de données classique
Relational Databases Time Series Databases
Comment sont stockés les Les données des tables Les données sont mises les
données ? et des index dans unes derrière les autres avec
des fichiers organisés leur horodatage incrémental
sous forme de pages
Accès vitesse Accès aux données rapides Accès aux données très ra-
pides
travailler sur les données Très difficile, données dépen- Très simple car elles sont in-
dans le temps dantes du reste dépendantes
En plus de ces quelques besoins cité au dessus, nous devons avoir la possibilité de retravailler
lensemble des métriques permettant de faire des moyennes, et de ne pas conserver toutes les
métriques qui seront stockés au fur et à mesure.
page 17 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 InfluxDB InfluxDB est une base de données temporelles ayant comme équivalents Timescale DB. In- fluxDB nous permet de faire de la rétention de données. Il permet dobtenir, de réduire la taille et dinterroger en temps réel un haut débit de données. Il permet également de faire de l’échantillonnage pour stocker des valeurs clés afin de ne pas avoir de problème de stockage. Influx DB fonctionne avec le principe “NoSQL désigne une famille de systèmes de gestion de base de données (SGBD) qui s’écarte du paradigme classique “ 8 Pour effectuer toutes les manipulations, nous avons utilisé trois fonctionnalitées du logiciel influxDB : • Retentions Policies • Continuous Queries • Shard Groups Rétentions Policies Commençons par les politiques de rétention. Les données chronologiques par nature com- mencent à s’accumuler assez rapidement et il peut être utile de supprimer les anciennes données une fois qu’elles ne sont plus utiles. Les stratégies de rétention offrent un moyen simple et ef- ficace d’y parvenir. Cela équivaut essentiellement à une date d’expiration de vos données. Une fois que les données sont ńexpiréesż, elles seront automatiquement supprimées de la base de données, une action couramment appelée application de la stratégie de rétention. Lorsque vient le temps de supprimer ces données, InfluxDB ne supprime pas simplement un point de données à la fois, il supprime un groupe de fragments entier 8. https ://fr.wikipedia.org/wiki/NoSQL page 18 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Continuous Query
Les requêtes continues (CQ) sont des requêtes InfluxQL (query language) qui s’exécutent au-
tomatiquement et périodiquement sur des données en temps réel et stockent les résultats de la
requête dans une mesure spécifiée.
De base sur influxDB, l’intervalle régulière d’exécution des Continuous Querys est de 30 min
sur nos trois bases de données.
Shard Groups
Un groupe de fragments est un conteneur pour les fragments, qui contiennent à leur tour les
données de série temporelle. Chaque groupe de fragments ont une stratégie de rétention corres-
pondante et tous les fragments d’un même groupe adhèrent à la même stratégie de rétention.
De plus, chaque groupe de fragments ont une durée, qui détermine la fenêtre temporelle de
chaque groupe de fragments (intervalle de temps). L’intervalle de temps peut être spécifié lors
de la configuration de la stratégie de rétention. Si rien n’est spécifié, la durée du groupe de
partitions par défaut est de 7 jours.
Figure 6 : Tableau des shard duration / RP
page 19 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Thanos
Thanos 9 est un ensemble de composant qui peut être composés dans un système métrique
hautement disponible avec une capacité de stockage illimitée. Les composants peuvent être
ajoutés aussi de manière transparente au-dessus des déploiements existants de Prometheus.
Cest un nouveau projet qui a été présenté au FOSDEM 10 2019.
Le projet Thanos est un projet visant à combler les lacunes que Prometheus peut avoir sur
la haute disponibilité ainsi que la possibilité de le faire fonctionner un peu partout dans le
monde sur des stockages avec des rétentions de donnée illimitée, permettre une vue globale des
requêtes pour les métriques.
Le projet datant de novembre 2017 et nétant pas adéquat, nous avons décidé de ne pas
lutiliser, le logiciel étant plus adapté pour une utilisation entre datacenter de différents lieux
dans le monde.
Timescale DB
TimescaleDB est un projet open-source fonctionnant en tant que plugin de Postgresql pour
rendre les requêtes SQL en time series données avec des métriques horodatés.
TimescaleDB est la base de données que nous avons essayé dinstaller, seulement, impossible de la
faire fonctionner au niveau des continuous Query, lun des problèmes est le projet TimescaleDB
qui nest pas aussi bien documenté que les autres solutions de base de données.
Lune des particularités de TimescaleDB 11 est sa rapidité, comparé à postgresql qui est considé-
rée 20 fois supérieures pour linsertion des données et une gestion jusquà 14 000 fois plus rapide
pour la plupart des requêtes directes.
La vision du projet TimescaleDB, dans le monde des base de données est très axé sur le full SQL,
ce qui est un contraste à ce quinfluxDB propose. InfluxDB vise à se passer des requêtes SQL.
Afin quune solution corresponde à nos besoins, elle doit permettre le stockage des métriques
avec les résultats dans un temps donné, permettre de créer des échantillons et une moyenne sur
un temps définis.
9. https ://github.com/improbable-eng/thanos
10. conférence annuelle organisée à l’Université libre de Bruxelles depuis 2001, la conférence accueille 5000
personnes de façon annuelle
11. https ://blog.timescale.com/timescaledb-vs-6a696248104e/
page 20 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Synthèse des solution pour la bases de données Time Series
Fonctionnalité Correspond Production Documentation
intéressante aux besoins
InfluxDB Retention Oui Oui Documentation complète,
Policies soutenu par InfluxDATA
/ Conti-
nuous Query
Thanos centralisation Non / Stade de Aucune documentation
Entre Exportation projet
chaque lieu
TimeScale Fonctionnalité Oui Oui très faible documen-
Database non im- tation en rapport
plémenté avec nos besoins
Nous avons donc choisi la solution InfluxDB qui est la plus couramment utilisée, car elle
propose des fonctionnalités intéressantes, compréhensibles et il ny a pas besoin de plugin pour
accéder à ses fonctionnalités.
page 21 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Outils de visualisation
Les outils de visualisation sont une des dernières étapes pour permettre à ladministrateur
système de visualiser les données des différents serveurs et conteneurs. Dans le cadre de notre
projet, plusieurs outils existent et doivent être en adéquations avec notre base de données.
Grafana
Grafana est un logiciel libre qui permet de visualiser, de réaliser des graphiques et mettre en
formes des métriques qui seront récupérées depuis la base de données influxDB. Il peut être
déployé sur de nombreux OS et il peut aussi être utilisé par Docker.
Prometheus graphique
Prometheus intègre une fonction qui permet de générer des graphiques, mais linterface
est très peu esthétique. Il faut donc avoir recours à une alternative (ici Grafana). Prometheus
peut également générer ses propres métriques, il peut donc indiquer ce quil consomme.
Figure 7 : Exemple graphique prometheus
page 22 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Chronograf
Chronograf est linterface graphique proposé par InfluxDATA permettant de visualiser le
contenu des bases de données InfluxDB. Il permet également la création dalerte et de calcul de
données.
Prometheus Grafana Chronograf
Calcul sur métriques Oui Oui ( dépend de la Oui
source )
Dashboard Person- Non Oui Oui
nalisable
Alerte Oui Oui Oui
Utilisation de va- Non Oui Non
riable
Nous avons porté notre choix final sur Grafana pour la visualisation, car la création de
dashboard personnalisable permet lutilisation de variable, pour les alertes nous avons utilisé
dans un premier temps grafana puis nous avons testé prometheus alert manager.
page 23 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Alertes Dans le cadre de la métrologie centralisée, nous avons besoin de toujours être informés des problèmes actuels de linfrastructure, pour que dun coup doeil, les personnes en charge voient les problèmes et puissent les régler. Système webhook Un webhook sert à notifier à une tierce application quun événement a eu lieu. Techniquement, un Webhook envoie une requête HTTP vers une URL. Les webhook peuvent avoir de nombreuses applications comme informer sur le suivi des colis ou prévenir votre équipe quand un ticket urgent est créé. Dans notre cas, les webhook servent à nous notifier, sur discord et stack, les alertes paramétrées dans Grafana. Discord Discord est un logiciel de communication instantané pensé pour les joueurs et lancé en 2015. Il est possible dintégrer des webhook et des bots. Cest un logiciel qui nous est très familier, nous avons commencé par lutiliser avec une intégration dun bot grafana. Cette intégration fonctionne avec la fonction dalerte de grafana. Selon les configurations de lalerting, grafana envoyait une alerte sil y avait une surcharge du CPU par exemple. Slack Slack est un logiciel de communication professionnelle lancé en 2013. Slack est similaire à un chat IRC organisé en canaux. Il est disponible sur différentes plateformes android, IOS, Windows, Linux. page 24 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Logiciels de Stress
Dans le cadre dun cluster docker, nous avons effectué quelques tests unitaires afin de nous
assurer que la solution en place sur l’infrastructure permet de faire remonter des alertes, détudier
les problèmes relatifs aux données qui transitent sur le système.
Gatling
Le logiciel Gatling, est un outil de stress dapplication web open-source, il permet deffectuer des
tests de montée en charge, très précise.
Le projet a été développé par Stéphane Landelle qui a fondé la société Gatling Corp après
la sortie des premières versions du logiciel. Stéphane Landelle travaille sur dautres projets
comme Asynchronous HTTP Client et sur le framework Netty également sous licence apache
2.0. Gatling est soutenu par la fondation Apache et est distribué sous licence Apache-2.0.
Gatling est une solution alternative au projet Jmeter qui est lui une solution développée directe-
ment par la fondation Apache, il est en concurrence direct, mais Gatling utilisent une méthode
de gestion du trafic permettant dêtre moins gourmands que la solution Apache JMeter.
Loutil est développé en langage scala. Lutilisation du langage scala a été poussé par lutilisation
dAkka qui est un système permettant léchange de message asynchrone, ceci permet de simuler
un nombre dutilisateur beaucoup plus important avec une seule et unique machine. Gatling
comporte de multiple fonctionnalités telles que :
• La possibilité d’enregistrer des sessions de requêtes afin de les rejouer plus tard.
• La génération dun ensemble de pages HTML afin de visualiser le rapport ainsi créer.
Le rapport est généré grâce à des librairies javascript Highstockes et highcharts afin de
produire des graphiques optimisés.
• Lun des aspects pratiques du logiciel gatling cest quil est paramétrables en utilisant des
scripts de simulations.
page 25 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Apache Jmeter
Apache Jmeter 12 a été créé par la fondation apache et est un logiciel écrit en java, conçu
pour tester le comportement et mesurer les performances. Au départ il était développé pour
tester des applications web, mais il a été amélioré pour quil réponde à plus de besoin. Il peut
être utilisé pour tester des performances à la fois sur des ressources statiques et dynamique. Il
permet de simuler de lourde charges sur un serveur ou de tester les performances dun protocole
comme le TCP/IP ou le HTTP.
Apache Jmeter contient les fonctions suivantes :
• Mode CLI (Mode ligne de commande) pour lancer le test depuis les OS compatibles Java
(comme linux, windows, Mac).
• Un rapport HTML dynamique est créé à la fin du test de charge pour avoir un aperçu
avec une mise en cache pour avoir accès au contenu en hors ligne
• Possibilité dextraire les données dans des formats courant (HTML, XML, JSON) ainsi
quen dautres formats textuels.
• Permet une portabilité complète.
• Permet lutilisation de plusieurs processus pour faire les requêtes.
• Environnement de développement qui permet lenregistrement rapide des plans de tests.
Synthèses des solutions de stress
Gatling Apache Jmeter
Impact sur le cluster Consomme moins de RAM Risque de crash
un conteneur
rapport user-friendly / complet austère
Fonctionnalité requêtes asynchrone Visualisation des requêtes
Documentation très accessible accessible
Notre choix cest porté sur Gatling, qui car il nous a permis denregistrer une simulation
ayant pour impact la base de donnée et le serveur apache.
12. https ://jmeter.apache.org/
page 26 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Figure 8 : Rapport de stress gatling
En effet nous avons ajouté des commentaires pour chaque simulation ce qui a permis à la
base de donnée dêtre sollicité.
page 27 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Description et mise en place de linfrastructure
Schéma d’interaction
Figure 9 : Schéma d’interaction
Lensemble des six étapes décrites plus tôt sont représentés dans cette ordre.
page 28 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
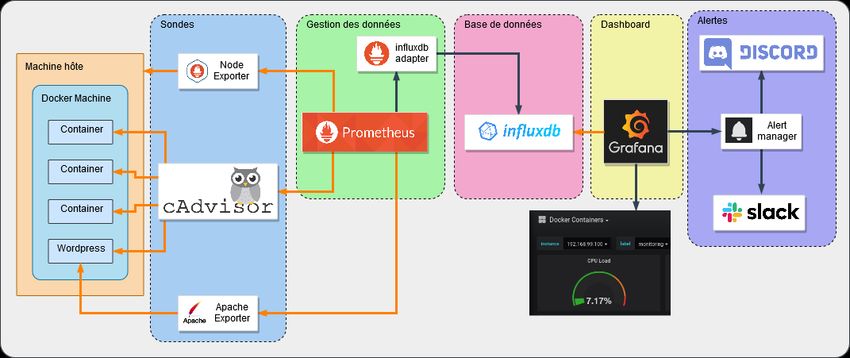
Schéma de linfrastructure
Figure 10 : Schéma infrastructure
Nous avons mis en place trois machines virtuels, “leader” et “worker” basé sur docker-machine.
Afin dalimenter nos machines, nous avons mis en place deux fichiers “docker-compose.yml” .
Pour chaque conteneur dans le fichier docker-compose nous lavons indexé dun label permettant
de faire des calculs sur l’utilisation des ressources et des groupes de statistiques.
Après le lancement des sondes et l’exposition des ports, nous avons configuré Prometheus afin
quil puisse aller lire les sondes.
Prometheus peut donc lire les métriques venant de node exporter, cadvisor et apache exporter
situés dans la plupart des cas sur “host :port/metrics” , les data sont notées “inline” ce qui
permet la gestion simplifiée des données pour la prochaine étape.
page 29 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Afin de créer des rétentions, nous envoyons toutes les requêtes sur InfluxDB. Nous avons utilisé
quatre bases de données, dans ces quatre bases de données, lune delle est utilisée pour récupérer
toutes les métriques et les trois autres sont les unes après les autres basées sur le système de
resampling 13 permettant ainsi de ne pas conserver trop de données.
Pour alimenter la base nous utilisons un adapter, nous y sommes obligés même si node
exporter et cadvisor peuvent être envoyés directement, ce nest pas le cas de lapache exporter.
Figure 11 : Représentation graphique InfluxDB
Afin de visualiser les datas présentes dans les différentes bases nous utilisons grafana.
Il a donc fallu rajouter InfluxDB en tant que data source sur Grafana.
Nous avons donc rajouté trois datasources influxDB (voir pour les différentes bases de
données “prom_short” , “prom_moy“ et “prom_long” .
13. A partir de plusieurs valeurs, nous ne conservons quune seule valeur : la moyenne
page 30 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Les dashboards utilisant les trois bases de données ci dessus, nous créons la variable qui sera
définie en tant que Datasource.
Sur Grafana, nous avons créé nos propre dashboard afin de visualiser les métriques. Nous
avons donc dû créer différentes variables pour créer un dashboard complet (contraintes deman-
dées).
Nous avons décidé de mettre en avant certaines métriques, comme lutilisation de la mémoire
par label “monitoring” et “vie” , la mémoire pour chacun de nos conteneurs, le CPU, le nombre
de conteneur lancés ou encore la charge sur chaque noeuds.
Le label “vie” inclut tout ce qui nest pas du monitoring tels que des applications Webs.
page 31 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Figure 12 : Dashboard Grafana
Figure 13 : Variables grafana
Nous avons mis en place les variables afin de trier les graphiques par datasource, instance,
label et noeud.
• $ datasource : Cette variable permet de trier en fonction des trois datasources précédem-
ment mentionnés.
• $ instance : Il permet de trier les instances liées à cadvisor (certaines métriques lui sont
dédiées).
• $ label : Il permet de trier par les labels mis en place “sondes” , “monitoring” et
“application” .
• $ instance_node : Il permet de trier les instances liées à Node Exporter (certaines mé-
triques lui sont dédiées).
page 32 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Impact de performance de la métrologie Centralisée Les Performances du système de métrologie centralisée dans une utilisation en production doit être le plus minime possible, pour cela nous avons dressé des graphiques provenant de Grafana directement depuis le dashboard. Sur le serveur Leader, on peut voir tout de suite limpact sur notre docker machine utilisant seulement les outils de monitoring et de stockage des métriques. Limpact est dors et déjà important, car les requêtes sont en permanence effectuées entre prometheus et influxDB. Il faut savoir que le serveur qui a lensemble des données à une consommation de 5% à 10% pour la base de données. En sachant que dans notre configuration en fonction des différentes rétentions, nous avons besoin que les données se répliquent dans les différentes bases. De ce fait, la consommation peut difficilement être réduite. page 33 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Limpact de la partie monitoring sur “worker” est légère et acceptable, en effet la charge CPU
est de 0.5% . En sachant quil y a seulement les sondes. Dans notre cas les sondes présentes
sont :
• Apache Exporter
• Node Exporter
• Cadvisor
Simulation
Nous avons simulé des montées en charges sur le serveur wordpress situé dans le conteneur avec
le logiciel gatling ce qui nous a permis de détecter les défaillances de notre infrastructure.
Figure 14 : Dashboard grafana pendant un test de charge
page 34 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Alertes
Figure 15 : Configuration alertes grafana
Afin de mettre en place des alertes il faut dans un premier temps définir la “query” qui signifie
donc les métriques, choisir un seuil critique et le temps minimum dalerte.
Dans le cadre de lorganisation de notre projet nous avons utilisé Discord afin déchanger au
sein du projet, donc nous avons créé un robot Grafana afin dêtre au courant de la moindre
défaillance au sein de notre infrastructure.
Figure 16 : Grafana alert - discord
page 35 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Afin dutiliser une messagerie instantanée plus professionnelle, nous avons installé un serveur
SLACK et avons créé les alertes pour montrer quil est également possible de créer des alertes
dans le monde professionnel sur une messagerie instantanée.
Figure 17 : Grafana alert - Slack
page 36 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Problèmes rencontrés Docker-Compose Configuration obsolète Lors de la première approche de ce sujet, nous avons survolé plusieurs docker-compose afin de créer linfrastructure. Cependant à chaque fois il existait des problèmes de compatibilité, de version très anciennes et plus compatible avec les derniers fichiers de configuration. Pour palier à ce problème, nous avons décidé de créer nos propres docker-compose et nos propre fichiers de configuration. Ceci nous a permis de mettre en place cette méthode étudiée en cours. InfluxDB Espace mémoire Le conteneur influxdb prend très vite beaucoup despace, nous avons donc dû réfléchir à une solution permanente afin de régler le soucis. Pour ce faire, nous avons augmenté la taille de la VM “leader” et demandé à InfluxDb de se servir dun répertoire que nous avons créé pour écrire les données. Sondes Compatibilité Nous avons été obligés décarter certaines sondes en raison de leurs versions (netdata et telegraf). En effet les métriques récoltées étaient illisibles pour prometheus. Suite à un comparatif de sonde, netdata et telegraf ont pu être remplacés par node_exporter. page 37 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019 Organisation du projet Pour le projet, nous avons décidé de nous répartir le travail mais également de communiquer le plus possible ensemble pour avancer à un rythme soutenu. Nous avons dès le début du projet mis en place un outil de gestion de développement de projet nommé framagit 14 qui utilise le logiciel Git Lab community Edition. Framagit est hébergé sur le réseau de lassociation déducation populaire, Framasoft. Dès le début nous avons renseigné notre avancement du projet sur un système de suivi disponible sur le site de luniversité de Lorraine. Ce qui permet à notre tuteur davoir un aperçu journalier de lavancement du projet tutoré tout au long de la période du 21 janvier 2019 jusquaux 27 mars 2019, jour de la soutenance finale. Durant les deux mois de projet tutoré, nous avons chaque fin de semaine en adéquation avec notre tuteur, fournit un rapport hebdomadaire dune page relatant tous les problèmes que nous avons eus durant cette période. Nous avons aussi présenté dans ce rapport, les points à travailler les semaines suivantes afin de connaître lavancée du projet. 14. https ://framagit.org/ page 38 Métrologie Centralisée
Sujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Répartition des tâches
Aymeric Maxime Victor Benjamin
Recherche Théorie X X X
Mise en place X X X X
Infrastructure
Travail sur X X X X
les sondes
Mise en place X X
du planning
Docker-swarm X X
Configuration X X
InfluxDB
Test solution X X
timescaleDB
Dashboards X X X
Grafana
Installation du X X X
système dalerte
Travail sur la X
génération de
trafic sur les
applications
Création de X X X X
graphiques
Rapport Heb- X X X X
domadaires
Rapport X X X X
page 39 Métrologie CentraliséeSujet : NPI NPI - Projet Tuteuré - ASRALL 2018 2019
Conclusion
Autour de ce projet nous avons su travailler en groupe sur un même sujet, se répartir les tâches
et gérer les rôles de chacun.
Linformatique ne cessent dévoluer et au fur et à mesure des années, un nouveau besoin est
apparu, la gestion des ressources. Le monitoring est devenu primordial lors de linstallation des
moyennes et grosses infrastructures. Dans le cas dune infrastructure conséquente, nous sommes
obligés de faire de la métrologie centralisée pour avoir toutes les données en un seul point.
Pour ce faire, on utilise divers logiciels et sondes qui permettent davoir un retour direct sur la
consommation de ressource physique comme la RAM ou le CPU. Tout ce système est installé
sur des machines virtuelles ou des conteneurs.
Le but de notre projet était de mettre en place une solution de métrologie centralisée pour
noeuds et conteneurs afin de pouvoir récupérer et échantillonner dans le temps les données
récoltés.
Nous avons mené à bien afin cette tâche en proposant une solution basée sur Docker comme
demandé.
Pour récolter les données, nous navons pas utilisé netdata/cadvisor comme conseillé car
suite à nos recherches et nos différents tests nous avons constaté que netdata renvoi les mêmes
types de métrique que node exporter et posséder une erreur au niveau des versions utilisées,
dont une mauvaise interprétation des données sur prometheus.
Il nous a été demandé de créer différents échantillonnages au sein de notre collecte. Pour ce
faire InfluxDB a remplit son rôle et a permis un échantillonnage court, moyen et long dans le
temps.
Afin de visualiser les résultats nous avons créé un dashboard sur grafana avec différentes
variables afin de voir en un seul clic les différents échantillonnages en fonction des différentes
bases.
Pour créer les alertes, nous avons utilisé grafana alert mais beaucoup derreurs ont été dé-
tectés lorsque nous voulions en créer une avec des variables.
Pour palier à ce problème nous avons utilisé prometheus alert manager afin de créer des
alertes en fonction des labels que nous avons utilisées.
Ce projet nous aura permis de découvrir des parties non abordées en cours de docker, mais
aussi davoir de nouvelles connaissances dans le domaine de la métrologie.
page 40 Métrologie CentraliséeVous pouvez aussi lire

















































