Mise en oeuvre d'un référentiel commun des individus à l'échelle d'une région
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Mise en oeuvre d’un référentiel commun des
individus à l’échelle d’une région
Boris Doucey
DSI Université de Bordeaux
351 cours de la Libération
33 400 Talence
Philippe Depouilly
Institut de Mathématiques de Bordeaux
351 cours de la Libération
33 400 Talence
Karen Raynal
DSI Université de Bordeaux
351 cours de la Libération
33 400 Talence
Résumé
Dans le cadre de la mise en oeuvre de l’Université Numérique d’Aquitaine (UNA), une des Université Nu-
mérique en région, a été élaboré un Schéma Directeur (SDNA) définissant un ensemble de 31 projets réunis
autour de 4 axes. Ces projets ont pour vocation de favoriser le développement de l’usage des technologies
de l’information et de la communication dans l’enseignement supérieur.
Nous parlerons ici plus précisément du projet 3.8 dont l’objectif est de doter les établissements d’ensei-
gnement supérieur en Aquitaine d’un référentiel commun des individus. Ce projet, démarré initialement en
2011, était basé sur des recommandations issues d’une étude externe, qui selon les établissements étaient
trop contraignantes pour être réalisables.
En 2012, un nouveau chef de projet a été nommé et les objectifs ont été rediscutés avec l’ensemble des
partenaires (DSI des établissements partenaires du PRES). Le référentiel a été mis en production en juin
2014. L’objectif principal atteint, il est utilisé par deux tiers des établissements et recense une population
d’environ 90.000 personnes sur les 120.000 attendues.
Pour sa réalisation, les choix techniques seront déclinés de la façon suivante :
— une modélisation des données suffisamment simple pour être déployé dans les temps
— une phase d’import initial depuis les divers établissements avec un dédoublonnage des individus
(dans le contexte de la fusion des universités de Bordeaux)
— un choix de technologies API REST/JSON et de Webservices au dessus de Java/Spring/Hibernate
Nous présenterons aussi la situation en 2015 à travers quelques statistiques d’utilisation ainsi que le bilan
de cette solution en s’appuyant sur le retour d’expérience de l’Université de Bordeaux.
Ce projet a déjà été brièvement présenté lors des premières Lightning Sessions des JRES 2013.
Mots clefs
Identité Numérique, SI établissement, Esup-Commons, Java, Spring, Hibernate, MVC, DAO, API REST
JRES 2015 - Montpellier 1/19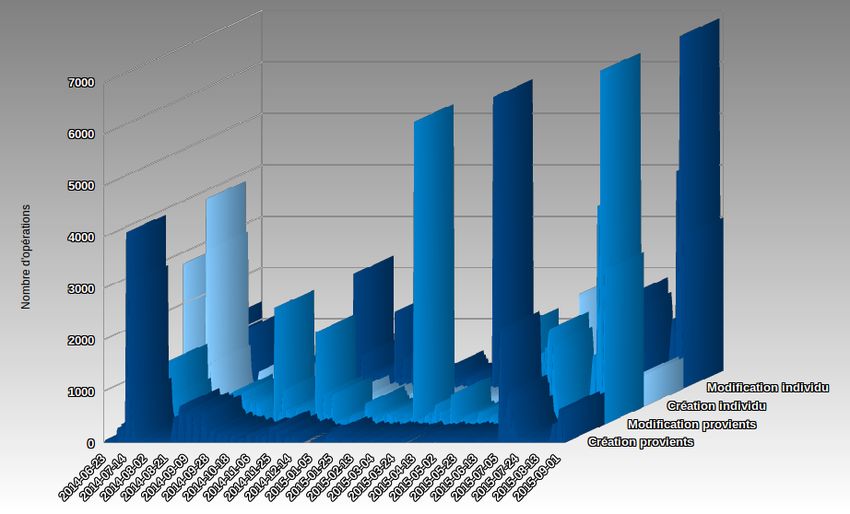
1 Présentation du projet
1.1 État initial du projet
En 2009, dans le cadre de la mise en place d’un schéma numérique à l’échelle de la Région, le PRES
(Pôle de Recherche et d’Enseignement Supérieur) a sollicité un cabinet d’étude pour définir des axes puis
a associé à ces axes des projets pour le développement du numérique dans les établissements de recherche
en Aquitaine dans le cadre d’un Schéma Directeur Numérique Aquitain (SDNA).
L’axe 3 dans lequel est positionné le projet décrit ici a pour objectif de renforcer le système de pilotage
des établissements et du PRES Université de Bordeaux. Pour répondre à cela, le projet 3.8 a pour objet de
déployer un référentiel commun des individus et un annuaire dans le périmètre de l’Université Numérique
Aquitaine (UNA). Pour ce faire, les objectifs retenus étaient les suivants :
1. Se doter d’un référentiel unique intégrant l’ensemble des usagers (étudiants et personnels) des éta-
blissements de l’UNA. Chaque individu devant posséder un identifiant unique et pérenne quelque soit
l’évolution statutaire des individus au sein de l’UNA.
2. Alimentation et évolutivité de la solution : ce référentiel doit pouvoir être alimenté autant que possible
à partir des bases sources des établissements (bases RH et bases étudiants). Le système d’alimentation
et l’architecture choisie devront pouvoir s’adapter sans difficulté aux évolutions des bases de données
sources, notamment dans la perspective de la nouvelle université de Bordeaux.
3. Favoriser son exploitation en positionnant ce référentiel comme base commune pour tous les besoins
d’identification des individus : progressivement, ce référentiel sera utilisé afin d’identifier les utilisa-
teurs sur l’ensemble des services numériques et applications de l’UNA (et des établissements) ayant
besoin de référencer un individu. Afin de pouvoir migrer les applications et services actuels, le réfé-
rentiel devra s’adapter aux contraintes des systèmes existants (par exemple : prendre en compte les
identifiants existants actuellement utilisés au sein de chaque établissement pour les applications et
services).
4. Faciliter ou prendre en charge les éléments permettant la gestion des habilitations aux services numé-
riques : certains services ou applications nécessiteront une gestion spécifique des droits mais pourront
s’appuyer sur des informations particulières profilant l’utilisateur. D’autres services s’appuieront di-
rectement sur des informations présentes dans le référentiel et liées aux individus. La solution devra
pouvoir répondre à ces 2 besoins.
5. Permettre la mise en place d’un service d’authentification centralisé : intégrer la gestion du cycle de
vie d’un compte associé à chaque individu référencé (gestion de l’activation du compte, gestion du
code secret sécurisé).
6. Fédération d’identité : le référentiel d’individu sera également utilisé comme base du futur fournis-
seur d’identité unique déclaré sur la fédération d’identité RENATER (Shibboleth). Les 3 objectifs
précédents permettront de fournir ce service sans difficulté.
7. Doter l’UNA d’un outil de communication et de fédération de la communauté par la production d’un
annuaire (en ligne + édition papier annuelle). Cet objectif pourrait être traité comme un projet "client"
s’appuyant sur le référentiel des individus, il est cependant préférable de livrer l’annuaire en avance
de phase. Cela permettra également d’amorcer la dynamique et l’implication des acteurs internes des
établissements.
8. Organiser l’administration et la gestion de ce référentiel et de l’annuaire commun. Une organisation
doit être mise en place afin d’identifier l’équipe garante du référentiel. Cette équipe, reconnue par
l’ensemble des établissements, aura en charge l’administration et l’exploitation du référentiel (traite-
ment des cas particuliers, fiabilisation des données). A l’issue du projet, cette organisation assurera
la maintenance et le développement du référentiel et de l’annuaire.
JRES 2015 - Montpellier 2/19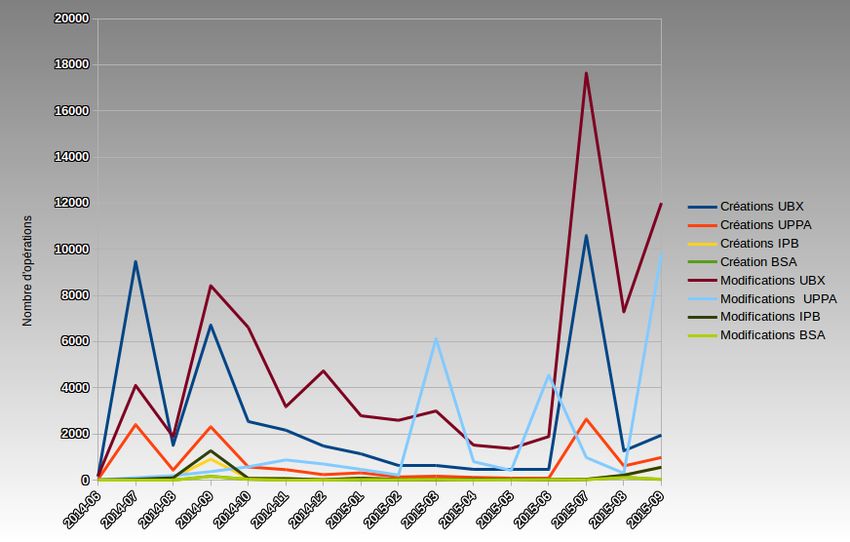
Le projet était porté initialement par le DSI de l’Université de Bordeaux1. Il a pu organiser deux réunions
plénières regroupant les DSI de tous les établissements représentés dans le PRES, chaque DSI étant accom-
pagné d’un référent technique. Suite à ces deux réunions, le porteur du projet a quitté son affectation et s’est
déssaisi du projet. Une période creuse d’un an a donc suivi, le temps d’identifier un nouveau porteur et de
convoquer une nouvelle réunion plénière.
1.2 Réorientations
Il aura fallu au nouveau porteur deux réunions plénières supplémentaires pour arbitrer les points suivants :
Au niveau de l’organisation, il est apparu inenvisageable de mener un tel projet avec un objectif de réali-
sations à court terme (sur les deux ans) uniquement à travers des réunions plénières de 25 à 30 personnes.
Il a donc été proposé d’arbitrer les points principaux et stratégiques en pleinière et de passer à la phase
opérationnelle en groupe restreint, soit un représentant par établissement (qui peut être accompagné ponc-
tuellement). Ce représentant ayant la capacité d’arbitrage technique.
Au niveau des objectifs initiaux, il s’est avéré que les établissements ne les partageaient pas. Il a donc fallu
lever les points de blocage, redéfinir les objectifs et préciser les engagements des établissements.
Par exemples les objectifs 1), 4) et 6) avaient des implications trop fortes de la part des établissements qui
exprimaient les impératifs suivants :
— Le référentiel ne doit pas être unique mais commun. Il se positionne donc en référentiel source dans
lequel les référentiels d’établissement peuvent puiser des informations ou alimenter des données indi-
viduelles partagées. Les référentiels établissement restant centraux dans les SI d’établissement. Ceci
permet de préserver le caractère souverain de l’établissement dans l’alimentation de son SI.
— L’adhésion au référentiel commun doit préserver un caractère de réversibilité. Un établissement doit
pouvoir y adhérer et se retirer sans remettre en cause le fonctionnement de son SI.
— Un établissement peut adhérer au référentiel commun à son lancement ou plus tard. Si c’est plus tard,
il acceptera de fait les impératifs techniques et les choix d’implantation.
— Le référentiel doit contenir le minimum d’informations sur un individu afin que celles-ci soient faci-
lement mises à jour par les SI d’établissement. De fait, une entrée dans le référentiel est un tuple nom,
prénom, date de naissance, identifiant d’établissement, type de référentiel, clé dans le référentiel, date
d’entrée, date de sortie, statut, identifiant UNA et identifiant établissement si différent.
— Ce n’est plus le référentiel commun qui génère un annuaire des individus, mais un moissonnage croisé
entre le référentiel et les informations disponibles dans les référentiels des établissements.
Toutes ces attentes ont été prises en compte et respectées lors de la rédaction du cahier des charges ainsi
que dans chaque phase de développement du projet.
2 Phases effectives de développement du projet
Après avoir arrêté un premier modèle de données correspondant aux attendus en termes de cycle de vie
d’un individu dans le référentiel, il a fallu réaliser plusieurs phases de développement avec des étapes
intermédiaires de construction des données. La première étape a été la mise en oeuvre d’une importation
initiale des individus provenant des SI des établissements dans une base avec un mécanisme de calcul
et d’arbitrage des identifiants afin de préserver les identifiants existants et connus. Ce développement et
importation a été réalisé sur deux ans, partiellement en développement interne et par le biais d’un prestataire.
Ensuite, le référentiel UNA à proprement parler a été developpé par le même prestataire selon le phasage
suivant :
JRES 2015 - Montpellier 3/19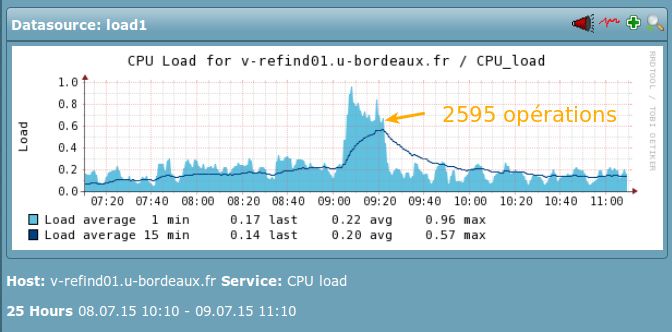
— évolution du modèle de données de l’import initial vers le modèle cible du référentiel ;
— développement du moteur d’API REST du référentiel à travers un structure classique d’application
MVC développée avec Java Spring/Hibernate : un servlet distribuant les requêtes HTTP vers un
contrôleur qui lui même réalisera les opérations métier en s’appuyant sur un modèle implanté sous la
forme de DAO (Objets d’accès aux données) ;
— une interface graphique permettant de gérer de façon graphique le contenu du référentiel afin de
permettre l’accès aux données contenues dans le référentiel aux référents des des établissements.
JRES 2015 - Montpellier 4/19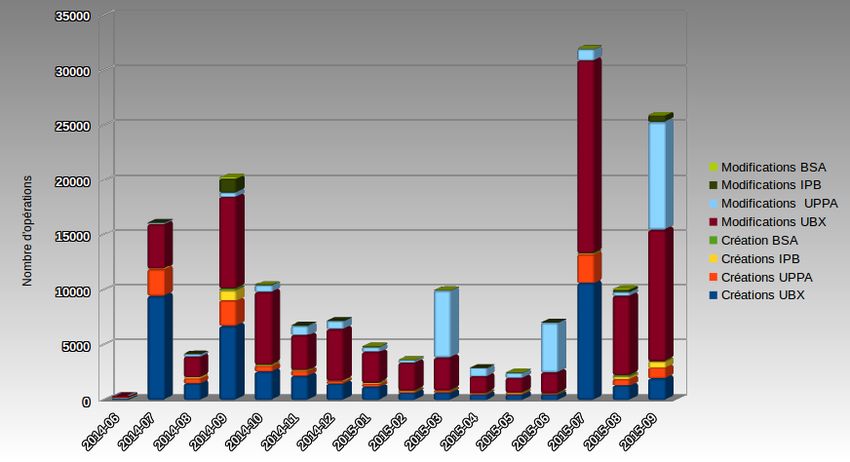
3 Partir d’un existant
3.1 État des lieux
Chaque établissement de l’UNA possède un ou plusieurs référentiels source (RH et scolarité) et un ou plu-
sieurs annuaires LDAP dont les entrées sont issues en général —mais pas exclusivement— des référentiels
sources (certains établissements permettant la saisie d’entrées locales à l’annuaire).
Pour un même établissement, dans ces annuaires, une même personne peut apparaître une ou plusieurs fois
selon qu’elle apparaît dans un ou plusieurs référentiels source (ceci n’est pas vrai pour les établissements
qui réalisent des opérations régulières de dédoublonnage).
3.2 Stratégie du traitement des collisions/doublons
La première opération a consisté à développer une application de détection des doublons et collisions
d’identifiant (technologies Spring/Hibernate/Quartz).
Chaque établissement procédait au dépôt quotidien d’un fichier CSV constitué des champs suivants :
— identifiant LDAP ;
— nom de famille ;
— nom usuel ;
— prénom ;
— prénom usuel ;
— date de naissance ;
— code INE 1 ;
— référentiel source ;
— date de validité ;
— état du compte dans l’annuaire ;
— statut de l’individu.
Les requêtes d’extraction permettant la création de ce CSV ont été laissées à la discrétion de chaque éta-
blissement.
Règles de détection de doublon :
— empreinte (nom + prénom) + date de naissance (doublon sûr) ;
— code INE + date de naissance (doublon sûr) ;
— empreinte (nom) + date de naissance (non sûr) ;
— empreinte (nom prénom) distance Levenshtein (1) + date de naissance (non sûr) ;
— empreinte (non sûr).
La collision concerne des individus qui ont un identifiant identique au sein de plusieurs annuaires d’établis-
sement.
Quelques chiffres :
1838 (2,1L’application a permis à chaque établissement de traiter les individus doublons de son propre SI
et de mettre en valeur les cas à résoudre avant de procéder à l’import initial (notamment les cas de collision
sur des personnes potentiellement identiques).
Dans le cadre de la fusion des universités bordelaises, il a été décidé de mener le travail de dédoublonnage
sur le périmètre des 3 établissements impliqués (un peu plus de 6000 cas à traiter en quelques semaines) :
de façon systématique, les comptes utilisateurs ont été modifiés pour être en phase avec le référentiel UNA.
1. Numéro unique d’Identifiant National d’Etudiant
JRES 2015 - Montpellier 5/193.3 Modélisation de l’import La mise en production du référentiel impliquait une phase d’import initial, à partir de la base de données alimentée par les fichiers CSV des établissements. L’algorithme d’import (script en Python) s’est appuyé sur les règles de priorisation suivantes pour la conser- vation de l’identifiant de l’établissement comme identifiant UNA : — personnel titulaire d’un établissement ; — individu présent dans deux établissements avec le même identifiant ; — personnel EPST titulaire ; — personnel contractuel (hors vacataire) d’un établissement (EPST compris) ; — étudiant ; — vacataire ; — invité. Ces règles étaient pondérées par l’état du compte dans l’annuaire de l’établissement (non activé ou obsolète faisant baisser la priorité). En cas d’égalité pour deux étudiants, on a choisi de privilégier le plus âgé (le plus âgé étant potentiellement depuis plus longtemps dans l’établissement donc disposant de davantage de ressources numériques). L’import a été joué plusieurs fois pour vérifier l’algorithme et les résultats produits avant une intégration des données dans le référentiel cible le 28 juin 2014 (par l’intermédiaire d’une migration de la base d’import vers la base du référentiel avec Talend). 3.4 Bascule de l’import intitial vers le référentiel UNA Le développement effectif du référentiel UNA a débuté en septembre 2013, a été mis en test au printemps 2014 et validé courant du mois de juin. Suite à la migration des données d’import intial, nous sommes passé en phase de production juste avant les inscriptions post-bac, première semaine de juillet 2014. Cinq établissements (UB 2 , UPPA 3 , INP 4 , BSA 5 et la COMUE) se sont appuyés sur le référentiel et se sont donc engagés à l’exploiter pour l’alimentation de leurs propres référentiels. Cela signifie qu’à partir de ce moment, chaque action d’ajout, modification ou suppression d’un invididu dans leur SI respectif fait appel à un connecteur respectant les spécifications des API du référentiel UNA ainsi que le choix de l’identifiant associé à l’individu. Pour les deux autres établissements de la COMUE (et intialement du PRES), l’Université Bordeaux Mon- taigne et Sciences Po Bordeaux, leur adhésion est remise à plus tard et sera possible avec une évolution de leur SI ou de leur capacité à intégrer les connecteurs au référentiel UNA dans les différents processus métiers de leur SI respectif. A ce jour, aucune date d’intégration n’est prévue et ces établissements devront respecter les prérequis et l’existant du référentiel pour y adhérer. 2. Université de Bordeaux, née de la fusion des universités Bordeaux 1, Bordeaux Segalen et Montesquieu Bordeaux IV 3. Université de Pau et des Pays de l’Adour 4. Bordeaux INP 5. Bordeaux Sciences Agro JRES 2015 - Montpellier 6/19
4 Réalisation
4.1 Technologies retenues
Parmi les nombreuses technologies qui peuvent répondre au besoin tel qu’il a été exprimé, certaines se
sont détachées du lot, principalement pour leur maturité / robustesse, et leur capacité d’intégration à des
systèmes hétérogènes.
Tableau 1 - Technologies retenues
Technologie Explication
Service WEB La volonté était de disposer d’un outil connecté, assez souple pour faire
toutes les opérations qu’un établissement pourrait demander et dont
l’intégration à l’existant serait relativement simple.
Pour le côté connecté, le choix s’est porté sur la mise en place d’un
service web (webservice : service en ligne permettant une interrogation
et un échange de donnée via http(s) et utilisant la grammaire WSDL)
REST Ce webservice prend la forme d’une API REST, qui remplit les
contraintes de souplesse : REST permet de rendre chaque opération in-
dépendante les unes des autres (le côté « stateless »).
L’API se compose ainsi d’un ensemble d’opérations unitaires permet-
tant d’interagir avec le référentiel : on dispose d’une boite à outil de
fonctionnalités permettant de manipuler les objets, sans jamais interve-
nir directement sur la base.
JSON Un format d’échange de données robuste et répandu. Là encore, de nom-
breuses bibliothèques permettent de manipuler ce format, dans divers
langage de programmation, facilitant l’intégration dans les établisse-
ments.
Esup-Commons V2 (Java Spring) Un standard dans le domaine de l’enseignement supérieur et la re-
cherche. Une volonté de faire un outil intégrable à l’existant (ex :
ENT esup-portal).
Shibboleth La dimension « inter-établissement » du projet impose un système d’au-
thentification fédéré.
4.2 Modèle de données
Les concepts :
— chaque établissement dispose d’un ou plusieurs référentiels ;
— à ces référentiels, on rattache des provients 6 ;
— chaque provient est lui même relié à un et un seul individu UNA.
L’API nous assure que :
— seul un utilisateur (table user) ayant les droits adéquats sur un référentiel (table privileges) peut ajou-
ter/modifier/supprimer un provient dans ce référentiel ;
— un individu UNA n’ayant plus de provient actif est automatiquement désactivé ;
— chaque individu UNA créé voit son identifiant (login) enregistré dans la table des « logins grillés ».
Ce login est alors exclus des logins utilisables (même en cas de désactivation de l’individu UNA qui
porte ce login).
6. Dans notre jargon, « provient » est le nom d’une entrée de la table provient de la base de données, nous acceptons donc de
l’accorder au pluriel
JRES 2015 - Montpellier 7/19Note : À chaque provient, on associe une date de fin de validité. Néanmoins, il n’y a pas de traitement
automatisé du cycle de vie des provients. Chaque établissement peut, s’il le souhaite, désactiver ses propres
provients.
Néanmoins, il a été convenu parmi les établissements partenaires que :
— les provients obsolètes depuis plus d’un an seront désactivés (par le biais d’un script)
— les provients désactivés depuis plus de 5 ans seront retirés de la base de donnée. (recommandation
CNIL)
Un schéma du modèle des données est présenté en Annexe.
4.3 Architecture
Tableau 2 - Caractéristiques matérielles des serveurs (Machines Virtuelles VMWARE)
CPU 2 Intel(R) Xeon(R) CPU E5-4650 0 @ 2.70GHz
RAM 6 Go
Disques 12 Go pour la partition /var/lib/postgresql (la base pèse moins de 200Mo
pour 150000 provients enregistrés )
Lien Réseau
Distribution Debian GNU/Linux 7.4 (wheezy)
SGBD PostgreSQL 9.1.13
Tomcat apache-tomcat-7.0.53
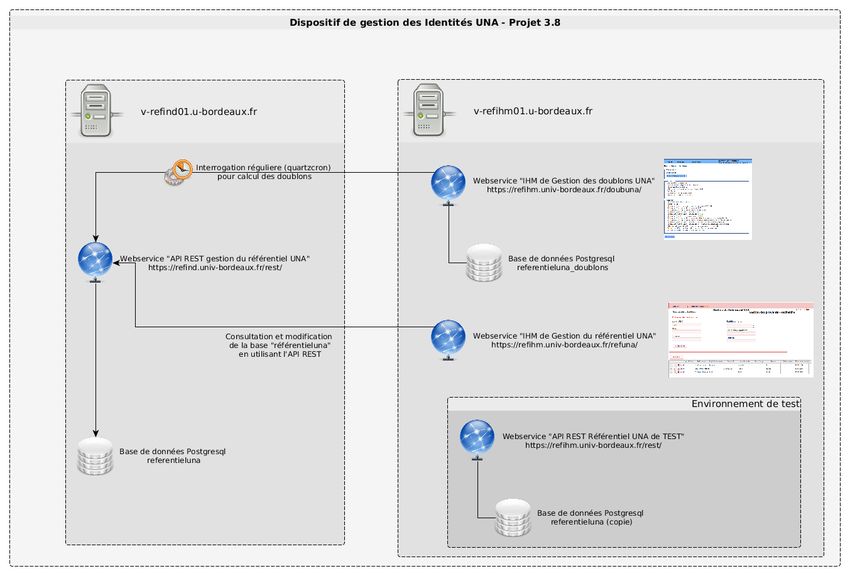
Le déploiement du référentiel dans sa forme actuelle est la suivante :
Figure 1 - Déploiement du dispositif « Référentiel UNA »
Chacun des deux serveurs a des fonctions bien définies, l’un est le moteur du référentiel UNA, l’autre est
l’IHM de gestion et accueille une instance de test du référentiel (validation et tests de régression avant
JRES 2015 - Montpellier 8/19mise en production). La résilience et la disponibilité n’est pas prise en charge dans les spécifications tech-
niques. L’hébergeur des services inter-établissements (dans notre cas, la DSI UB) garantit une sauvegarde
et une reprise sur incident. Ensuite, les établissements doivent intégrer une gestion des erreurs au niveau
des connecteurs afin de gérer les problèmes d’accès au référentiel (panne système, réseau, etc.) en gérant
par exemple la mise en attente des demandes de création de comptes ou un calcul d’identifiants temporaires
qui seront corrigés lors du retour du service.
4.4 Implantation
Chaque interaction suit le scénario suivant :
— un client appelle une URL avec une méthode définie (GET, POST, etc.) + JSON (éventuellement) ;
— l’API renvoie une réponse HTTP (voir tableau 3) + corps de la réponse (éventuellement au format
JSON).
Exemple :
— type de requête : Interrogation par login UNA ;
— méthode HTTP : [GET] ;
— chemin d’accès : /cxf/api/comptes/{login_una}.
Tableau 3 - Types de réponses sur une interrogation par login UNA
Code HTTP Signification (technique) Signification (détaillée) Corps/Message
200 OK Un individu correspond à OK
l’identifiant fourni
204 No Content Il n’existe aucune donnée ré- No Content
férencée pour le tuple donné
400 Bad Request La syntaxe de la requête Mandatory field is
est incorrecte (champ trop missing Too long
long, champ obligatoire ab- field content Invalid
sent,champ mal formatté, field format
etc...)
401 Unauthorized Si les identifiants ne sont pas Pris en charge par
fournis ou qu’ils sont incor- Spring Security
rects
403 Forbidden Si le connecteur ne dispose Pris en charge par
pas des droits suffisants sur Spring Security
le référentiel concerné
500 Internal Server Error En cas de problème tech- En fonction du pro-
nique que l’on ne sait pas blème
traiter (FS saturé, élément
du serveur inopérant, autres
problèmes techniques im-
prévus...)
4.4.1 Les requêtes de création et de modification
Les fonctionnalités les plus utilisées sont celle de création et modification de provient. Elle suivent le même
modèle que celui présenté ci-dessus :
JRES 2015 - Montpellier 9/19— une URL d’accès [GET] contenant des variables relatives au provient (ici code RNE 7 , référentiel,
clé) : /cxf/api/compte/etablissement/{codeRne}/referentiel/{referentiel}/cle/{cle} ;
— si l’individu existe, un JSON est retourné sous la forme suivante :
{
"login-una":"pmartin",
"nom-de-famille":"martin",
"nom-d-usage":"",
"prenom":"pierre",
"prenom-usuel":"",
"code-ine":"123456AD",
"date-de-naissance":"01/02/1980",
"login-etablissement":"pmartin",
"temoin-validite":"true",
"date-validite":"01/01/2020",
"statut":"ETUDIANT",
"civilite":"MONSIEUR"
}
— selon le résultat, une méthode http [PUT] est utilisée pour la modification ou une méthode [POST]
pour la création ;
— avec un contenu au format JSON fourni en paramètre, contenant les données d’information (dans un
format similaire à celui retourné par la méthode [GET]).
Dans le cas d’une modification, on n’intervient jamais directement sur un individu, on modifie un provient.
Ces modifications sont ensuite répercutées au niveau de l’individu via les règles mise en places au niveau
de l’API. Le scénario correspondant est le suivant :
— S’il n’existe pas déjà un individu dans la base de données avec la même clé {clé} pour le même
référentiel {referentiel} et le même établissement {codeRne}, la modification est arrêtée et un code
HTTP 204 est retourné.
— Sinon, on recherche s’il existe un doublon potentiel à partir des données que l’on souhaite modifier.
Par exemple, si l’on change la date de naissance d’un individu, on vérifie qu’il n’existe pas déjà un
individu avec les mêmes noms/prénoms (voir "empreintes") et date de naissance.
— Si aucun doublon n’est trouvé, l’individu est modifié.
— Si plus d’un doublon est trouvé, un code HTTP 501 est retourné. (501 Not Implemented).
— Si un seul et unique doublon est trouvé, on vérifie s’il s’agit du même individu (même login UNA),
c’est-à-dire que le doublon est trouvé sur les provients d’un même individu.
— Si oui, l’individu est modifié.
— Si non, l’entrée est fusionnée avec le doublon trouvé (voir ci-dessous Empreinte/Split/Fusion).
Résultat : le résultat est renvoyé sous forme d’une réponse HTTP, éventuellement accompagnée d’un JSON
(voir exemple plus bas)
— code HTTP 200 + JSON (contenant le login UNA) ;
— code HTTP 204 : Pas de résultat ;
— code HTTP 401 : Non autorisé ;
— code HTTP 400 : Une erreur s’est produite ;
7. Répertoire National des Etablissements
JRES 2015 - Montpellier 10/19— code HTTP 501 : Cas non géré par l’application.
Exemple de JSON renvoyé sur une modification réussie de provient :
{
"message":" Compte modifie avec succes",
"code":"SUCCES",
"\emph{login}-una":"pmartin"
}
De nombreuses autres opérations sont accessibles via l’API :
— recherche par login ; — recherche des logins grillés des provients in-
— recherche par clé / référentiel / code RNE ; actif ;
— recherche par code INE ; — recherche des logins grillés par établissement ;
— création d’un provient ; — recherche des logins grillés par référentiel ;
— modification d’un provient ; — recherche de tous les établissements ;
— suppression d’un provient ; — recherche de tous les référentiels ;
— suppression d’un individu en base de don- — recherche de toutes les civilités ;
nées ; — recherche de provient par login UNA ;
— recherche d’un individu par login UNA ; — recherche d’un provient par ID ;
— fusion d’individu ; — recherche d’un provient par clé/référentiel ;
— split d’individu ; — recherche de provients multi critère ;
— griller un login ; — recherche de tous les statuts d’individu ;
— supprimer un login grillé ; — recherche de tous les rôles ;
— recherche de login grillé par login UNA ; — recherche d’utilisateurs ;
— recherche de tous les logins grillés ; — recherche de privilèges d’un utilisateur.
4.4.2 Repérage et gestion des doublons : empreintes/split/fusion
Lors de la création d’un provient, l’API calcul des « empreintes ». Les empreintes, sont des chaînes de
caractères concaténant plusieurs champs relatifs aux informations nominatives de l’individu.
L’API en calcule 6 à chaque création :
— les empreintes étendues :
— nom de famille + prénom ;
— nom de famille + prénom usuel ;
— nom d’usage + prénom ;
— nom d’usage + prénom usuel.
— les empreintes restreintes :
— nom de famille ;
— nom d’usage.
Elles sont ensuite normalisées pour pouvoir être exploitées :
— les caractères accentués sont remplacés par les caractères non accentués correspondant ;
— les caractères spéciaux (dont les tirets) sont supprimés ;
JRES 2015 - Montpellier 11/19— les majuscules sont transformées en minuscules.
Ces empreintes sont utilisées ensuite pour déterminer si deux entrées du référentiel sont identiques en
appliquant la règle : empreinte + date de naissance identique = même individu.
Comme expliqué plus haut (voir Les requêtes de création et de modification) il peut arriver que la modi-
fication d’un provient fasse que le couple Empreinte + date de naissance corresponde à présent à un autre
individu du référentiel.
Ex : Jean Dupond, né le 01/01/1976 a un double statut : Étudiant et Vacataire.
Il est saisi une première fois dans le SI scolarité, puis crée dans le référentiel UNA et hérite du login
pdupond.
Il est saisi ensuite par les RH qui commet une erreur sur son nom en écrivant DuponT. Une nouvelle entrée
est crée dans le référentiel UNA (login pduponT)
Les RH reviennent ensuite sur leur saisie. La modification du provient RH lié à pduponT est effectuée. Il
s’avère alors que l’empreinte générée correspond à celle d’un autre individu : Pierre Dupond (pduponD).
Dans ce cas, il faut rattacher ce provient à l’individu dont l’empreinte correspond à la ’nouvelle’ empreinte.
— le provient est détaché de l’individu que l’on modifie (split) ;
— le provient est modifié en fonction des paramètres reçus ;
— le provient est ensuite attaché à l’individu détecté comme doublon (fusion) ;
— accessoirement, si l’individu dont le provient a été détaché (split) n’avait que ce provient, il est inva-
lidé (car il n’a plus de provient).
5 Mise en production
5.1 Phases
5.1.1 Intégration à l’existant
L’intégration du référentiel UNA dans le SI de l’Université de Bordeaux a nécessité de suivre un protocole
et un calendrier précis : une fois la bascule effectuée, il est très complexe de faire marche arrière.
L’ensemble des connecteurs d’alimentation du LDAP de l’Université de Bordeaux a été modifié pour utiliser
le référentiel. Une librairie de fonction a été développée (en Perl) pour dialoguer avec l’API REST et
effectuer les opérations de base : ajout / modification. La partie ’génération du login’ de chaque connecteur
a ainsi été mise à jour pour alimenter le référentiel et obtenir en retour un login à attribuer à chaque nouveau
compte.
Le fonctionnement de chaque connecteur peut donc se résumer ainsi :
— Récupération du compte à créer à partir d’un SI source (SI RH, SI scolarité. . .)
— Recherche de l’existence du provient dans le référentiel : y-a-t’il une entrée dans le référentiel avec
cette « clé » pour ce « référentiel source » ?
— Si le provient existe : on le modifie, sinon, on le crée.
— Le résultat de l’opération fournit un login que l’on peut attribuer à la personne.
Tout le travail de vérification de la présence d’un doublon et de génération d’un login adéquat est délégué
au référentiel.
Après la phase d’import initial qui a permis d’attribuer à chaque compte un identifiant UNA (le même que
le login déjà attribué à chaque fois que c’est possible), les nouveaux comptes crées à partir du 29 juin 2014
ont tous été référencés dans la base UNA.
JRES 2015 - Montpellier 12/195.1.2 Utilisation au quotidien Au delà des connecteurs qui utilisent le référentiel sur les opérations de créations et modifications, l’API est régulièrement sollicitée pour d’autres raisons. Gestion des doublons Bien que la cible soit que chaque compte dispose d’un login UNA identique à son login « établissement », il subsiste quelques cas où le login UNA sera différent de celui employé par l’individu. C’est le cas lorsqu’un provient UNA a été créé avec une erreur de saisie, et qu’un doublon a été créé pour un même individu. Lors de la correction de la saisie, alors, le login UNA de la personne change (voir 4.4.2), mais il n’est pas toujours possible de la changer au niveau LDAP, notamment si des ressources sont attachées à l’ancien login. Le Ldap Université de Bordeaux dispose donc d’un attribut spécifique (UbxLoginUna) pour stocker la valeur de l’uid générée par l’API du référentiel, la réconciliation login établissement / login UNA se faisant par la suite, généralement par une opération manuelle. Suppression d’individus Initialement prévue pour ne pas autoriser la suppression d’individus, l’API propose désormais cette fonctionnalité. En effet, il est rapidement apparu qu’une solution simple de gestion des erreurs de saisie était nécessaire, afin de ne pas inutilement griller des logins pour des individus mal saisis. Pour les cas de mauvaise saisie, il est souvent plus simple de supprimer l’individu UNA créé et de redemander une création avec les bonnes informations. 5.2 Retours sur l’utilisation Charge système : L’API du référentiel UNA est sollicitée quotidiennement par l’ensemble des dispositifs des établissements partenaires. Il permet de faire facilement le lien entre un individu UNA et son entrée dans un SI de l’établissement (son « provient »). La disponibilité de l’API est donc un élément crucial du dispositif. Jusqu’à présent, nous n’avons eu à déplorer aucun dysfonctionnement, ni indisponibilité de l’application. Après un an d’utilisation, on a pu constater que la solution réagissait très bien, y compris lors des solli- citations importantes comme dans l’exemple illustré ci-dessous (charge CPU observée le 09/07/2015, jour d’ouverture des inscriptions où l’API a du traiter 2595 opérations entre 9H et 9H20) 5.3 Statistiques d’usage L’adoption du référentiel UNA implique de la part des établissements partenaires que l’ensemble des indi- vidus inscrits dans les divers SI soient insérés dans le référentiel UNA. On a donc, tout au long de l’année, une utilisation constante du référentiel, avec des pics observés lors des mouvements importants (rentrée universitaire notamment). On peut constater sur le graphique « Opérations sur le référentiel UNA Juin 2014 à Septembre 2015 » l’étalement des opérations tout au long de l’année Universitaire, avec un pic de création / modification sur la période d’inscription. Cette information est confirmée par le diagramme « Création et Modification de provients par établisse- ment » qui nous indique que le mois de Juillet 2014 a totalisé plus de 30000 opérations, tous établissements confondus, principalement en provenance de l’Université de Bordeaux, puis de l’ UPPA. JRES 2015 - Montpellier 13/19
Figure 2 - charge CPU observée le 09/07/2015 JRES 2015 - Montpellier 14/19
Figure 3 - Opérations sur le référentiel UNA Juin 2014 à Septembre 2015 JRES 2015 - Montpellier 15/19
Figure 4 - Création et Modification de provients par établissement (diagramme empilé) JRES 2015 - Montpellier 16/19
Figure 5 - Création et Modification de provients par établissement JRES 2015 - Montpellier 17/19
6 Conclusion La mise en oeuvre d’un référentiel unique des individus partagé par différents établissements est un projet intéressant sur plusieurs points. Déjà, il permet de questionner profondément les situations de chacun, les modes de fonctionnements adoptés graduellement, qui retracent aussi l’histoire de l’évolution de ces éta- blissements. Dans notre cas, la majorité des établissement a adopté la suite logicielle Cocktail pour leur SI, partiellement ou globalement. Malgré cela, il est apparu que chacun l’utilisait de façon bien différente. L’adoption du référentiel nous a permis de partager les différents usages d’un même outil de gestion de SI. C’est un élément qui a orienté notre réflexion vers le développement d’un outil totalement agnostique et générique, piloté essentiellement via des API REST. Un autre point est l’indispensable engagement des DSI de chaque établissement dans le suivi du projet. Avant d’exploiter le référentiel, il a fallu près de deux ans de réunions quasi hebdomadaires. Certains ont mouillé leurs chemises et mené une réflexion très poussée sur ce que pouvait être ce référentiel, voire maquetté et testé de leur côté des prototypes afin de valider les processus. L’engagement a été réel et suivi, même si la visibilité reste très faible. L’impact direct du référentiel peut se résumer à celui de produire des identifiants uniques lors de la création de comptes. Cet engagement est vraiment remarquable et les auteurs de cet article ne pourront jamais les remercier à la hauteur de leur investissement. Ensuite, l’expérience acquise est que pour obtenir un résultat dans un délai raisonnable (en deux ans dans notre cas) et à cette échelle, il faut être capable de réduire les ambitions et de s’orienter impérativement vers des objectifs accessibles et raisonnables. Initialement, le projet était très ambitieux (un référentiel socle et unique à l’échelle de l’Aquitaine, un seul fournisseur d’identité RENATER, un impact direct et conséquent sur les SI des établissements et leurs pratiques métier). Rapidement, il nous est apparu que sans un engagement fort et coordonné des responsables des établissements dans ce sens cela ne serait pas possible, engagement qui n’était manifestement pas au rendez-vous. Nous avons donc opté pour une approche plus pragmatique et en accord avec les acteurs opérationnels des SI. Ce choix a été payant. Il a aussi fallu savoir profiter du contexte. Le projet a vraiment démarré au moment où devait se mettre en place la fusion de trois universités. Cela signifie que nous avons démarré avec neuf établissements, sachant que la mise en oeuvre ne se passerait qu’avec sept. La construction du SI de la nouvelle université a pleinement profité de la première phase du projet. L’import initial a permis ainsi de produire un travail conséquent de dédoublonnage d’identités des individus des trois universités. Ce phasage non prévu a été source de travail supplémentaire mais précieux au final. Cela a aussi permis de forcer le planning, il devait y avoir un avant et un après la fusion avec des livrables bien définis. Développer de A à Z un tel outil est un choix de pouvoir le proposer à la communauté, il a donc été développé sur la forge SourceSup dans un environnement connu des établissements (Esup-Common v2) et une licence libre. Nous invitons donc à le découvrir, l’utiliser et le faire évoluer. N’ayant pas à l’époque rencontré de projet équivalent, c’était aussi un choix de partager une expérience. Actuellement, le projet n’est pas totalement fini, il reste à terminer une réflexion sur l’harmonisation des mots de passe avec un mécanisme soit de opt-in ou de opt-out par les établissements. Une maquette a validé les choix techniques, mais l’impact est réellement important pour les établissements. C’est le projet pour 2016. Enfin, nous espérons voir se concrétiser la production d’un annuaire des individus à l’échelle de la COMUE, basé sur l’exploitation du référentiel UNA. Pour conclure nous tenons à remercier les collègues qui nous ont suivi ces deux années chaque jeudi matin en présentiel ou en visio-conférence, plus particulièrement Michel Beheregaray, Michel Pallard et Françoise Priam, bravo pour votre persévérence. Merci à Christophe Couronne pour la première modélisation et le développement de l’import intitial. Et merci à la société IMC, plus particulièrement Muriel Bazerque, Julien Bailay et Farid Bouhassoun pour la qualité de leur travail, leur professionalisme et leur accompagnement. JRES 2015 - Montpellier 18/19
Annexe
6.1 Modèle de données
Figure 6 - Modèle de données
JRES 2015 - Montpellier 19/19Vous pouvez aussi lire

















































