Orange HTTP formation web - octobre 2019 - Orange Campus Africa
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Orange octobre 2019 HTTP formation web
sommaire – les bases de HTTP – les concepts fondamentaux de HTTP – les entêtes – le cache – les requêtes conditionnelles – la sécurité 2 / 69 formation web - http
les bases de HTTP
historique
HTTP (HyperText Transfer Protocol) est un élément fondamental et fondateur du web.
Historique des versions de HTTP :
– HTTP 1.0 : publié en 1996
– HTTP 1.1 : publié 1997
– HTTP 2.0 :
- début des travaux en 2012 sur la base des travaux de Google sur SPDY
- publié en mai 2015
Conclusion : HTTP fonctionne bien et n'a pas eu vraiment besoin d'évoluer pendant 15 ans.
3 / 69 formation web - http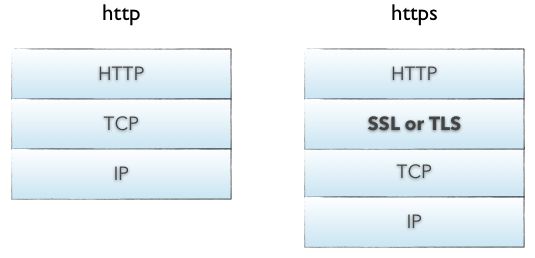
les bases de HTTP
le principe
La communication entre un client et un serveur est basée sur un échange requête/réponse :
– le client initie une requête à destination du serveur
– le serveur reçoit la requête, la traite et retourne une réponse au client.
En HTTP 1.0, pour chaque élément que le client demande au serveur (fichier html, fichiers css, javascript, images...), il y a en terme de délai
un coût fixe lié à l'établissement puis à la fermeture de la connexion (coût fixe plus élevé si on est en HTTPS).
source : net.tutsplus.com
4 / 69 formation web - httples bases de HTTP
le principe
HTTP un protocole :
– sans état (stateless) qui permet la communication entre systèmes répartis (exemple : le web)
– standard ouvert qui permet l'interopérabilité :
- abstraction des caractéristiques techniques des serveurs et des clients
- utilisable quelque soit le système d'exploitation, le serveur web ou le client web
- ne pré-supposant que très peu d'exigences sur les systèmes
La force de HTTP réside dans sa simplicité, en particulier le fait qu'il ne conserve pas d'état entre les différents messages échangés.
5 / 69 formation web - httples bases de HTTP HTTP et HTTPS La pile (stack) HTTP a très peu de dépendances. Elle s'appuie en général sur le protocole TCP/IP mais ça n'est pas une exigence. Cela peut par exemple être TLS pour passer en HTTPS : On peut donc faire passer une application web en HTTP vers HTTPS (développement / production) sans avoir à tout ré-écrire. Par défaut, les ports utilisés sont le port 80 pour HTTP et 443 pour HTTPS. L'administrateur du serveur web peut choisir un autre port (attention : certains ports sont réservés et normés). source : net.tutsplus.com 6 / 69 formation web - http
les bases de HTTP
HTTP 1.1
La version 1.1 de HTTP apporte les améliorations suivantes :
– les connexions persistantes (la connexion est maintenue entre 2 requêtes HTTP, ou plus !)
– les entêtes liées au cache
– le transfert des données par morceaux (chunked transfer encoding).
HTTP 1.1 représente la majorité du trafic HTTP sur internet. HTTP/1.0 est vraiment sur le déclin.
7 / 69 formation web - httples bases de HTTP HTTP 1.1 : la connexion persistante (keep-alive) Avec HTTP 1.1, la connexion n'est pas fermée après l'envoi du premier élément. Elle est réutilisée pour envoyer les éléments suivants, selon la configuration du serveur qui détermine la durée maximale de la connexion (et peut même la désactiver). Le coût fixe lié à l'établissement puis à la fermeture de la connexion n'est subit qu'une fois, et non pas pour chaque élément. 8 / 69 formation web - http
les bases de HTTP
HTTP 1.1 : la parallélisation des connexions (pipelining)
Cette connexion persistante ne fonctionne que pour les éléments provenant du même serveur (même nom DNS).
Or, une application est souvent architecturée autour de plusieurs serveurs spécialisés : un serveur d'application, un autre serveur pour les
ressources statiques (images, fichiers css...), un autre serveur pour le suivi de l'audience (tracking)...
Dans ces cas-là, la persistance des connexions n'est pas suffisante.
Les navigateurs intègrent un mécanisme de parallélisation des connexions :
– ils disposent d'un pool de connexions, en général limité à 6 connexions.
– ils l'utilisent pour paralléliser les connexions HTTP, ce qui permet de récupérer jusqu'à 6 éléments en parallèle
– la parallélisation fonctionne pour toutes les architectures (mono-serveur ou multi-serveurs)
9 / 69 formation web - httples bases de HTTP HTTP et la performance HTTP n'est pas naturellement un protocole performant : c'est un protocole à base de texte, sans état. Mais la combinaison des deux méthodes précédentes (connexion persistante et parallélisation des connexions) permet d'obtenir de très bonnes performances. Elles ont permis de supporter l'augmentation du trafic pendant presque 20 ans. En outre, le mécanisme de cache intrinsèquement lié à HTTP en fait une architecture distribuée permettant d'assurer une haute disponibilité et d'augmenter encore les performances. 10 / 69 formation web - http
les bases de HTTP
HTTP/2
Mais depuis quelques années, les usages (audio-vidéos...) font que le trafic augmente de façon exponentielle, atteignant les limites du HTTP
1.1.
La version 2.0 de HTTP apporte d'autres améliorations :
– protocole binaire : plus performant qu'à base de texte (mais le debug s'en trouve complexifié)
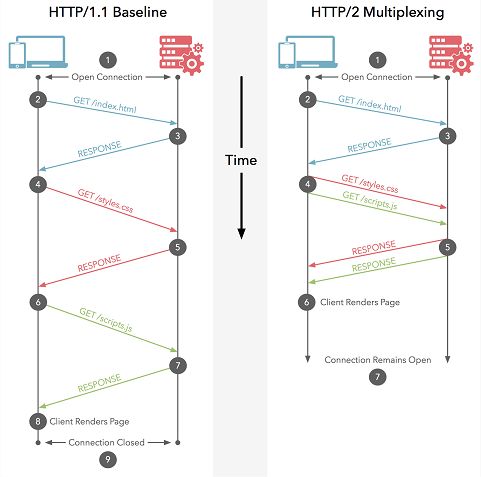
– multiplexage : une seule connexion nécessaire par hôte, ce qui encourage les sites à regrouper leurs contenus (images, CSS...) sur
un seul hôte :
- plusieurs ressources sont envoyées en même temps
- auparavant, la deuxième ressource était envoyée une fois la première reçue complètement.
– cache pushing : le serveur peut pousser des données dans la chaîne de réseau (caches) :
- une révolution dans la gestion du cache
- invalidation immédiate et/ou mise à jour proactive du cache par le serveur
– chiffrement par TLS : non obligatoire, mais les implémentations actuelles l'imposent toutes de facto.
L'usage de HTTP/2 progresse, il était 9 fois plus utilisé que HTTP 1.0 en février 2015. Le 29 janvier 2015, Google annoncait que 5 % de leur
trafic global était délivré en HTTP/2 (notamment YouTube).
11 / 69 formation web - httples bases de HTTP HTTP/2 : multiplexage 12 / 69 formation web - http source : blog.restcase.com
les bases de HTTP
HTTP/2 : multiplexage pour les développeurs
Le multiplexage des fichiers permet de supprimer des tâches habituellement gérées automatiquement par des task runner comme grunt, gulp
ou webpack.
– plus besoin de concaténer ses ressources (CSS, javascript...)
– plus besoin de faire de l'inlining (exemple : intégrer le CSS ou le javascript dans le HTML)
– plus besoin de répartir les données sur plusieurs serveurs (pour bénéficier de la parallélisation des connexions)
Pour aller plus loin sur HTTP/2 :
– Nine Things to Expect from HTTP/2
– HTTP/2 is Done
– HTTP/2 home page
– HTTP/2 For Web Developers
– http2 expliqué
13 / 69 formation web - httples bases de HTTP
HTTP/3 : UDP plutôt que TCP
Les nouveautés de HTTP/3 sont dans les détails et principalement là grâce à l'utilisation de QUIC par HTTP/3:
– HTTP/2 est conçu pour TCP et gère donc les flux dans la couche TCP, HTTP/3 est conçu pour QUIC qui est un protocole de transport
qui gère les flux par lui-même
– HTTP/2 peut être implémenté et utilisé sans HTTPS (même si c'est rare sur internet), HTTP/3 n'existe pas dans une version non
sécurisée ou non chiffrée
14 / 69 formation web - httples bases de HTTP HTTP/3 : handshake optimisé – HTTP/3 a des handshakes beaucoup plus rapides grâce à QUIC vs TCP + TLS – HTTP/3 a plus de chances de fonctionner plus tôt grâce aux handshakes 0-RTT de QUIC – HTTP/2 peut être négocié directement dans un handshake TLS avec l'extension ALPN, alors que HTTP/3 est sur QUIC donc nécessite une réponse d'en-tête Alt-Svc: pour informer le client de ce fait 15 / 69 formation web - http
les bases de HTTP
HTTP/3
Pour aller plus loin sur HTTP/3 :
– http3 expliqué
– QUIC: what hides behind HTTP/3
16 / 69 formation web - httples concepts fondamentaux de HTTP
les URLs
Les URLs sont la base du fonctionnement de HTTP car elles permettent d'identifier une ressource (page HTML, fichier CSS, image...).
– protocol : le protocole utilisé (HTTP, HTTPS, FTP, news, ssh...)
– host : nom de domaine identifiant le serveur (FQDN)
– port : le port utilisé (80 pour HTTP, 443 pour HTTPS, 21 pour FTP)
– ressource path : identifiant de la ressource sur le serveur
– query : paramètres de la requête (filtrage, tri, pagination...)
source : net.tutsplus.com
17 / 69 formation web - httples concepts fondamentaux de HTTP
les verbes
Les verbes sont invisibles pour l'utilisateur, mais ils sont systématiquement utilisés dans les échanges entre le client et le serveur.
Les verbes permettent de manipuler les ressources identifiées par les URLs :
– GET : le client demande à lire une ressource existante sur le serveur
– POST : le client demande la création d'une nouvelle ressource sur le serveur
– PUT : le client demande la mise à jour d'une ressource déjà existante sur le serveur
– DELETE : le client demande la suppression d'une ressource existante sur le serveur
En réalité, GET est utilisé la majeure partie du temps, POST est parfois utilisé pour les formulaires (ceux dont la méthode est POST).
En revanche, PUT et DELETE sont souvent remplacés (à tort) par un verbe GET ou POST surchargé d'un paramètre spécifiant s'il faut mettre à
jour ou supprimer la ressource.
GET http://example.com/script.php?action=update&id=1234
GET http://example.com/script.php?action=delete&id=5678
18 / 69 formation web - httples concepts fondamentaux de HTTP
les verbes
D'autres verbes sont spécifiés mais sont moins fréquemment utilisés :
– HEAD : le client demande l'entête d'une ressource existante sur le serveur (dérive de GET, principalement utilisé par les proxies cache)
– PATCH : le client demande la mise à jour partielle d'une ressource déjà existante sur le serveur (dérive de PUT)
– TRACE : usage à des fins de debug HTTP (similaire à TRACEROUTE, pour tracer les différents proxies)
– OPTIONS : le client demande à connaître les capacités optionnelles du serveur (exemple : connaître les verbes autorisés)
– CONNECT : le client souhaite utiliser un proxy à la connexion.
Il existe 38 verbes différents.
19 / 69 formation web - httples concepts fondamentaux de HTTP les verbes Idempotence : l'invocation n+1 renvoi le même résultat que l'invocation n. Une action idempotente est répétable sans effet de bord inattendu. verbe lecture seule idempotent commentaires GET oui oui récupérer une ressource POST non non créer une ressource, non cachable PUT non oui modifier une ressource DELETE non oui supprimer une ressource PUT est idempotent car la spécification indique que le serveur doit remplacer la ressource cible sur le serveur par celle envoyée dans la requête du client. A l'inverse, POST n'est pas idempotent car la spécification indique que le serveur doit ajouter la ressource envoyée dans la requête du client à la collection cible sur le serveur. Une solution à cette absence d'idempotence pour le verbe POST est d'ajouter une clé d'idempotence à la requête générée par le client HTTP est un protocole de niveau application, l'usage d'un verbe ou d'un autre est donc un choix applicatif qui doit être effectué avec attention ! 20 / 69 formation web - http
les concepts fondamentaux de HTTP
les codes de statut
Lors de l'échange requête/réponse, le serveur répond au client en spécifiant dans l'entête de sa réponse un code de statut (status code).
Le protocole HTTP spécifie des plages numériques pour ces codes de statut :
– 1xx : message d'information provisoire
– 2xx : requête reçue, interprétée, acceptée et traitée avec succès
– 3xx : message indiquant qu'une action complémentaire de la part du client est nécessaire (exemple : redirection vers une autre url)
– 4xx : erreur du serveur du fait des données en entrée envoyées par le client (exemple : authentification, autorisations, paramètres
d'entrée)
– 5xx : erreur du serveur du fait d'un motif interne au serveur (exemple : indisponibilité d'un composant du serveur, erreur inattendue)
Les listes qui suivent ne sont pas exhaustives ! Il existe 58 codes de statut, consultez httpstatus.es ou la RFC 7231 pour plus de détails.
21 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut 1xx : message d'information
Classe de statut introduite en HTTP 1.1 et encore peu utilisée. Les clients ne supportant que HTTP 1.0 doivent ignorer ces messages.
Cette classe de statut comprend des codes de statut provisoires. Ils doivent nécessairement être suivis d'une réponse de classe de statut
2xx, 3xx, 4xx ou 5xx.
– 100 Continue : le serveur indique au client qu'il attend la suite de la requête
– 101 Switching Protocols : le serveur accepte le changement de protocole demandé par le client (exemple : HTTP => HTTPS)
– 102 Processing : le serveur indique que le traitement est en cours. Cela évite que le client dépasse le temps d'attente limite
(timeout).
22 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut 2xx : requête traitée avec succès
Classe de statut la plus fréquente, quand le serveur a traité la requête avec succès :
– 200 OK : code de statut de succès générique
– 201 Created : la ressource a bien été créée (souvent lié à un verbe post)
– 202 Accepted : traitement OK mais la resssource n'est peut-être pas encore créée (souvent utilisé pour des traitements asynchrones)
– 204 No Content : traitement OK mais la ressource n'est pas dans la réponse
– 206 Partial Content : traitement OK mais seule une partie de la ressource se trouve dans la réponse (exemple : réponse
paginée).
200 est le code de statut le plus générique dans cette catégorie. Il est préférable d'en utiliser un plus spécifique si cela est approprié.
23 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut 3xx : redirection
Classe de statut qui permet au serveur d'informer le client qu'il attend une autre action de sa part. Généralement le serveur indique au client
que ce dernier doit demander une autre URL :
– 301 Moved Permanently : la ressource a été déplacée de manière permanente et indique la nouvelle URL de la ressource
– 302 Moved Temporarily : la ressource a été déplacée de manière temporaire et indique la nouvelle URL de la ressource
– 303 See Other : la réponse à cette requête se trouve à une autre URL
– 304 Not Modified : la ressource n'a pas été modifiée depuis la dernière fois (en fonction du ETag envoyé par le client, voir la section
cache)
– 307 Temporary Redirect : la requête doit être redirigée temporairement vers l'URL spécifiée
– 308 Permanent Redirect : la requête doit être redirigée définitivement vers l'URL spécifiée.
Toutes ces redirections sont effectuées automatiquement car elles sont gérées par le navigateur, mais on pourrait imaginer un navigateur qui
demande une confirmation à l'utilisateur avant d'effectuer une redirection.
24 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut 4xx : erreur du client
Classe de statut qui permet au serveur d'informer le client qu'il y a une erreur dans sa requête :
– 400 Bad Request : la requête est mal formée (souvent une erreur de syntaxe)
– 401 Unauthorized : la ressource nécessite une authentification et que la procédure d'authentification a échoué
– 403 Forbidden : le client n'a pas accès à cette ressource (même si la procédure d'authentification peut avoir réussi)
– 404 Not Found : la ressource demandée n'existe pas (la fameuse erreur 404 !)
– 409 Conflict : la requête ne peut être exécutée suite à un conflit (souvent la ressource est plus récente que le timestamp du client,
la ressource a été modifiée par un autre client).
25 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut 5xx : erreur du serveur
Classe de statut qui permet au serveur d'informer le client qu'il y a une erreur du serveur dans le traitement de la requête :
– 500 Internal Server Error : code statut d'erreur interne générique
– 502 Bad Gateway : la passerelle a retourné une erreur (souvent suite à une mauvaise configuration d'un reverse proxy)
– 503 Service Unavailable : le service n'est pas disponible (typiquement, le serveur Apache indique que le serveur d'application
n'est pas opérationnel, ou fonctionne en mode dégradé)
– 504 Gateway Timeout : une passerelle intermédiaire n'a pas répondu dans le délai imparti.
500 est le code de statut le plus générique dans cette catégorie. Il peut être utilisé si le serveur :
– ne peut déterminer l'origine de l'erreur
– ne veut pas la dévoiler au client (pour des raisons de sécurité).
26 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut
Il existe de nombreux autres codes de statut qui ne sont pas listés ici.
Les codes de statut font partie intégrante de l'application et ne doivent pas être laissés de côté :
– par conséquent, le serveur web fait partie intégrante de l'application et doit être configuré en adéquation avec chaque application
– il ne faut pas sous-estimer la richesse des informations fournies par un code de statut HTTP.
27 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut : gestion des erreurs
En cas d'erreur, l'application web côté client doit savoir correctement :
– différencier chaque type d'erreur
– gérer chaque cas d'erreur (ou chaque type d'erreur) :
- soit en gérant cette erreur de manière applicative
- soit en prévenant l'utilisateur de l'erreur rencontrée.
La bonne démarche côté serveur est :
– d'utiliser un code de statut d'erreur approprié (exemple : 400 Bad Request)
– et de préciser l'erreur applicative dans le corps du message.
HTTP/1.1 400 Bad Request
Content-Type: application/json
error: {
"code": 1023,
"label": "The format of userID input parameter is invalid
(must be: mandatory, alphanumeric [a-z][A-Z], max. length)."
}
28 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut : gestion des erreurs
Un contre-usage des codes statuts, à proscrire en cas d'erreur :
– renvoyer un code de statut 200 OK
– et indiquer une erreur dans le corps du message.
HTTP/1.1 200 OK
Content-Type: application/json
error: {
"code": 1023,
"label": "The format of userID input parameter is invalid
(must be: mandatory, alphanumeric [a-z][A-Z], max. length)."
}
Cela améliore en apparence les tableaux de bord de l'application, mais cela masque la qualité réelle du service rendu.
29 / 69 formation web - httples concepts fondamentaux de HTTP
les codes de statut : gestion des erreurs
source
30 / :69
CommitStrip
formation web - httpexercices exercice 1 Quels sont les quatre concepts fondamentaux de HTTP ? 31 / 69 formation web - http
exercices
exercice 1
Quels sont les quatre concepts fondamentaux de HTTP ?
– le binôme requête/réponse
31 / 69 formation web - httpexercices
exercice 1
Quels sont les quatre concepts fondamentaux de HTTP ?
– le binôme requête/réponse
– les URLs
31 / 69 formation web - httpexercices
exercice 1
Quels sont les quatre concepts fondamentaux de HTTP ?
– le binôme requête/réponse
– les URLs
– les verbes
31 / 69 formation web - httpexercices
exercice 1
Quels sont les quatre concepts fondamentaux de HTTP ?
– le binôme requête/réponse
– les URLs
– les verbes
– les codes de statut
31 / 69 formation web - httpexercices
exercice 1
Quels sont les quatre concepts fondamentaux de HTTP ?
– le binôme requête/réponse
– les URLs
– les verbes
– les codes de statut
source : net.tutsplus.com
31 / 69 formation web - httpexercices exercice 2 Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses possibles) 32 / 69 formation web - http
exercices exercice 2 Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses possibles) 201 Created : 32 / 69 formation web - http
exercices
exercice 2
Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses
possibles)
201 Created :
– car POST est utilisé lorsqu'on souhaite créer une ressource, 201 Created permet de répondre que la ressource a été créée.
32 / 69 formation web - httpexercices
exercice 2
Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses
possibles)
201 Created :
– car POST est utilisé lorsqu'on souhaite créer une ressource, 201 Created permet de répondre que la ressource a été créée.
– avec un entête Content-Location (voir la documentation) et la représentation de la ressource.
32 / 69 formation web - httpexercices
exercice 2
Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses
possibles)
201 Created :
– car POST est utilisé lorsqu'on souhaite créer une ressource, 201 Created permet de répondre que la ressource a été créée.
– avec un entête Content-Location (voir la documentation) et la représentation de la ressource.
303 See Other :
32 / 69 formation web - httpexercices
exercice 2
Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses
possibles)
201 Created :
– car POST est utilisé lorsqu'on souhaite créer une ressource, 201 Created permet de répondre que la ressource a été créée.
– avec un entête Content-Location (voir la documentation) et la représentation de la ressource.
303 See Other :
– le fait de retourner ce code de statut pour rediriger vers la ressource nouvellement créée génère une requête supplémentaire.
32 / 69 formation web - httpexercices
exercice 2
Quel devrait être le code de statut d'un formulaire soumis en POST et dont le traitement côté serveur se déroule sans erreur ? (2 réponses
possibles)
201 Created :
– car POST est utilisé lorsqu'on souhaite créer une ressource, 201 Created permet de répondre que la ressource a été créée.
– avec un entête Content-Location (voir la documentation) et la représentation de la ressource.
303 See Other :
– le fait de retourner ce code de statut pour rediriger vers la ressource nouvellement créée génère une requête supplémentaire.
Les deux solutions ont pour effet de revalider le cache invalidé par le POST, mais la première est plus performante.
32 / 69 formation web - httpexercices exercice 3 Et si le traitement côté serveur d'un formulaire soumis en POST est asynchrone, quel devrait être le code de statut retourné par le serveur si le traitement se déroule sans erreur ? 33 / 69 formation web - http
exercices exercice 3 Et si le traitement côté serveur d'un formulaire soumis en POST est asynchrone, quel devrait être le code de statut retourné par le serveur si le traitement se déroule sans erreur ? 202 Accepted : 33 / 69 formation web - http
exercices
exercice 3
Et si le traitement côté serveur d'un formulaire soumis en POST est asynchrone, quel devrait être le code de statut retourné par le serveur si le
traitement se déroule sans erreur ?
202 Accepted :
– avec une URL où le client peut effectuer du polling pour se tenir au courant de l'avancement du traitement.
33 / 69 formation web - httples entêtes
Tout message, que ce soit une requête du client ou une réponse du serveur, est composé :
– des entêtes
– du corps du message
Les entêtes peuvent être de 4 types :
– general header fields: entêtes appliquables aux requêtes et aux réponses
– request header fields : entêtes spécifiques aux requêtes
– response header fields : entêtes spécifiques aux réponses
– entity header fields : méta-entêtes appliquables au message transporté
Les pages suivantes ne présentent que quelques exemples des entêtes existantes.
34 / 69 formation web - httples entêtes
appliquables aux requêtes et aux réponses
Ces entêtes sont les plus génériques :
– Via : pour tracer les proxies intermédiaire pour une requête dont le verbe est trace
– Date : pour dater le message (même si c'est une information a priori non fiable)
– Upgrade : pour négocier un changement de protocole (de HTTP vers HTTPS, pour les weksocket)
– Transfert-Encoding : pour négocier un transfert des données par morceaux (Transfert-Encoding: chunked), fonctionnalité
ajoutée en HTTP 1.1
– Pragma : pour définir des entêtes propriétaires ou candidates à la normalisation
- par exemple, l'entête Pragma: no-cache en HTTP 1.0 a été normalisée en Cache-Control: no-cache en HTTP 1.1
– ...
35 / 69 formation web - httples entêtes
spécifiques aux requêtes
GET /blog/my-blog-post HTTP/1.1
Host: www.example.com
Connection: keep-alive
Cache-Control: no-cache
Pragma: no-cache
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Ces entêtes permettent au client de donner des informations à la chaîne réseau :
– Host : le client indique le nom du serveur à qui il s'adresse (utile lorsqu'il existe plusieurs virtual host sur le serveur)
– Connection : le client indique au serveur s'il souhaite maintenir la connexion (lié à HTTP 1.1)
– Cache-Control: le client donne à la chaîne de connexion des directives de mise en cache
- no-cache indique que le client souhaite que le contenu provienne réellement de l'hôte et non d'un cache intermédiaire
– Pragma : idem que précédemment mais pour HTTP 1.0
– Accept : le client indique au serveur les formats de données qu'il sait interpréter, avec une indication de priorité (q)
– ...
36 / 69 formation web - httples entêtes
spécifiques aux réponses
HTTP/1.1 200 OK
Content-Type: text/html
Age: 0
Server: Apache
Ces entêtes permettent au serveur de donner des informations sur la réponse renvoyée :
– Age : le serveur indique le temps écoulé (en secondes) depuis la génération du message par le serveur (utilisé pour la gestion du
cache)
– ETag : le serveur indique le tag de l'entité (entity tag) de la ressource, calculé via MD5 (utilisé pour la gestion du cache)
– Location: le serveur utilise cette entête pour indiquer l'URL de redirection lorsque le code de statut est de type 3xx (redirection)
– Server : le serveur indique son type
– ...
37 / 69 formation web - httples entêtes
les méta-entêtes appliquables au message transporté
Ces entêtes permettent de fournir des informations sur le formatage des données du message :
– Content-Language : la langue principale de la ressource (optionnel)
– Content-Type : le format de la ressource
– Expires : date d'expiration de la ressource, pour les caches
– Last-Modified : date de dernière modification de la ressource, pour les caches
– ...
38 / 69 formation web - httpexercice – tracer un binôme requête/réponse à l'aide de l'outil de tracage réseau de Firefox – explorer les entêtes 39 / 69 formation web - http
le cache
Tous les mécanismes de cache partent d'un principe simple : il est inutile d'effectuer deux fois le même traitement.
Ce principe a guidé la conception des mécanismes de cache HTTP :
– HTTP est un sytème réparti dont la performance provient de mécanismes de cache
– ces mécanismes de cache sont rendus possibles par l'aspect stateless (sans état) de HTTP
Les mécanismes de cache permettent d'économiser du temps, de réduire les coûts et la bande passante nécessaire.
En réduisant en apparence la latence réseau, ils permettent en outre d'améliorer l'expérience utilisateur sur le web.
40 / 69 formation web - httple cache source : net.tutsplus.com 41 / 69 formation web - http
le cache
fonctionnement général
cache server algorithm
cache service
client cache server cache database http server
[1] GET path/to/ressource
[2] analyzing client request
[3] lookup resource in cache database
opt [if resource is not in cache]
retreiving resource from the source
[4] GET path/to/ressource http server or another cache server
(in fact the cache server doesn't care)
200 OK
[5]
+ ressource
[6] storing new resource in cache database
at this point, resource is in cache but not necessarily fresh enough
[7] checking resource expire date
opt [if resource in cache is expired]
retreiving resource from the source
[8] GET path/to/ressource http server or another cache server
(in fact the cache server doesn't care)
200 OK
[9]
+ ressource
[10] storing refreshed resource in cache database
at this point, resource is in cache and fresh enough
[11] generate a response for the client
[12] sending the reponse to the client
opt [depending on cache service configuration]
[13] log the whole operation
42 / 69 formation web - httple cache
fonctionnement général
Le serveur HTTP doit gérer finement les entêtes du message, car ils permettent aux serveurs de cache de correctement gérer leur cache.
Voici les différents codes statut possibles :
– 304 Not Modified si la ressource n'a pas été modifiée
– 200 OK si la ressource a été modifiée ou que la copie du cache a expiré (niveau de fraicheur trop faible)
– 404 Not Found si la ressource n'est plus disponible.
Les serveurs de cache peuvent ainsi gérer leur cache et conserver suffisamment de données pour être performants, mais pas trop non plus
afin de ne pas servir des données invalides (modifiées ou supprimées).
Le but est de trouver le bon compromis entre la fraîcheur des ressources et la rapidité à les servir...
43 / 69 formation web - httple cache
la notion d'expiration
Lorsqu'un serveur web sert une ressource, il indique dans les entêtes de sa réponse la durée de validité de la ressource, c'est à dire le temps
pendant lequel la ressource pourra être conservée en cache :
– Expires (HTTP 1.0) : date d'expiration, mais cela suppose (à tort) que tous les serveurs aient leur horloge synchronisée
– Cache-Control (HTTP 1.1) : durée maximum (en secondes) de maintien en cache, fonctionne donc même si les serveurs ne sont
pas à la même heure.
Cache-Control: max-age=86400 // in seconds, equals to one day
Lorsque la ressource en cache expire, le serveur de cache doit arrêter de servir la ressource en provenance du cache et revalider la ressource
à partir du serveur HTTP.
44 / 69 formation web - httple cache
la notion d'expiration
cache expiration
client cache server http server
[1] GET path/to/ressource
resource not in cache
retreiving resource from the source
[2] GET path/to/ressource http server or another cache server
(in fact the cache server doesn't care)
200 OK
Cache-Control: "max-age=86400"
[3]
ETag: "1a2b3c4d"
+ ressource
200 OK
Cache-Control: "max-age=86400"
[4]
ETag: "1a2b3c4d"
+ ressource
1 hour later
GET path/to/ressource
[5]
If-None-Match: "1a2b3c4d"
resource in cache
304 Not Modified
[6] Cache-Control: "max-age=82800"
ETag: "1a2b3c4d"
1 hour later
GET path/to/ressource
[7] Cache-Control: "no-cache"
If-None-Match: "1a2b3c4d"
resource in cache but needs to be revalidated
GET path/to/ressource retreiving resource from the source
[8] Cache-Control: "no-cache" http server or another cache server
If-None-Match: "1a2b3c4d" (in fact the cache server doesn't care)
304 Not Modified
[9] Cache-Control: "max-age=86400"
ETag: "1a2b3c4d"
304 Not Modified
[10] Cache-Control: "max-age=86400"
ETag: "1a2b3c4d"
1 week later
GET path/to/ressource
[11]
If-None-Match: "1a2b3c4d"
resource in cache but expired
retreiving resource from the source
[12] GET path/to/ressource http server or another cache server
(in fact the cache server doesn't care)
200 OK
Cache-Control: "max-age=86400"
[13]
ETag: "1a2b3c4d"
+ ressource
45 / 69 formation web - http [14]
200 OK
Cache-Control: "max-age=86400"
ETag: "1a2b3c4d"
+ ressourcele cache
la notion de revalidation
Lorsqu'une ressource est expirée, le serveur de cache n'est pas obligé de rafraîchir son cache immédiatement, il ne le fait souvent que
lorsqu'un client lui redemande la ressource en question.
Pour cela, le serveur de cache ajoute dans sa requête des entêtes pour indiquer au serveur web l'état de son cache :
– If-Modified-Since (HTTP 1.0) : date de dernière validation, mais information non fiable
– If-None-Match (HTTP 1.1) : se base sur la notion de ETag, un hash MD5
GET /blog/my-blog-post HTTP/1.1
HTTP/1.1 200 OK
ETag: "686897696a7c876b7e"
+ ressource
GET /blog/my-blog-post HTTP/1.1
If-None-Match: "686897696a7c876b7e"
HTTP/1.1 304 Not Modified
46 / 69 formation web - httple cache
la notion de revalidation
Si la ressource n'a pas été modifiée depuis le dernier rafaîchissement, ou si le ETag est identique (et donc que la ressource n'a pas été
modifiée), alors le serveur HTTP peut répondre à la requête à l'aide d'un entête :
– Last-Modified : en réponse à If-Modified-Since (HTTP 1.0)
– ETag : en réponse à If-None-Match (HTTP 1.1)
Ces entêtes sont en général accompagnés du code statut 304 Not Modified. Il y a alors très peu de données (uniquement des entêtes) qui
transitent du serveur HTTP au serveur de cache, puis du serveur de cache au client.
Cette combinaison du mécanisme d'expiration des ressources et de revalidation par le serveur de cache permettent d'obtenir un système
réparti très efficace et performant.
47 / 69 formation web - httple cache
la notion de revalidation
conditional cache querying
client cache server
[1] GET path/to/ressource
resource in cache with ETag "1a2b3c4d"
200 OK
[2] ETag:"1a2b3c4d"
+ ressource
later
GET path/to/ressource
[3]
If-None-Match: "1a2b3c4d"
resource in cache with ETag "1a2b3c4d"
[4] 304 Not Modified
later
GET path/to/ressource
[5]
If-None-Match: "1a2b3c4d"
resource in cache with ETag "5e6f7g8h"
200 OK
[6] ETag:"5e6f7g8h"
+ ressource
48 / 69 formation web - httple cache
côté serveur
Le serveur HTTP connaît l'application et les ressources qu'il sert. Il est le plus à même de donner les directives de mise en cache. Il ne doit
pas être considéré comme une commodité mais bien comme une brique logicielle faisant partie de l'application.
Directives de mise en cache Cache-Control (s'appliquent à tous les équipements de la chaîne réseau) :
– Cache-Control: private : la ressource ne doit pas être mise en cache par un proxy public et partagé
– Cache-Control: no-cache : la ressource peut-être mise en cache mais doit être revalidée à chaque requête (économie de bande
passante)
– Cache-Control: no-store : la ressource ne doit pas être mise en cache
– Cache-Control: must-revalidate : la ressource doit être revalidée même si elle n'est que légèrement périmée (no stale)
– Cache-Control: max-age= : il faut revalider la ressource si la dernière mise à jour est plus ancienne que secondes
(réponse la plus courante)
49 / 69 formation web - httple cache
côté client
Si le serveur prend en charge la responsabilité de la gestion des directives de mise en cache, le client peut également communiquer ses
exigences de cache via le même entête Cache-Control qu'il insère dans sa requête.
Par exemple, en utilisant le raccourcis F5, ctrl-R ou encore shift-reload, le client peut forcer le rafraîchissement de la page sans faire
appel aux serveurs de cache, en forcant le rechargement des ressources depuis le serveur HTTP.
Directives de mise en cache Cache-Control :
– Cache-Control: max-age= : la réponse doit être âgée de moins de secondes
– Cache-Control: min-fresh= : la réponse doit être valide pour encore secondes
– Cache-Control: max-stale= : la réponse doit avoir expiré depuis moins de secondes (le client accepte les réponses
légèrement périmées)
– Cache-Control: no-cache : la réponse peut provenir d'un cache, mais la ressource doit avoir été revalidée
– Cache-Control: no-store : la ressource ne doit pas être mise en cache
50 / 69 formation web - httples requêtes conditionnelles
HTTP étant sans état (stateless), il part du principe qu'il n'y aura pas de conflit lors de l'accès à des modifications de ressources (optimistic
lock).
Techniquement cette stratégie optimiste se concrétise par l'utilisation de requêtes conditionnelles :
– le serveur fournit les entêtes permettant de dater la fraîcheur ou la version des ressources qu'il sert : Last-Modified and ETag
– le client utilise ces données pour rajouter des conditions dans les requêtes qu'il envoie au serveur :
- If-Modified-Since et If-None-Match pour valider les ressources en cache
- If-Unmodified-Since et If-Match pour la gestion de l'accès concurrent.
51 / 69 formation web - httples requêtes conditionnelles
GET
Le client demande une ressource en spécifiant les entêtes suivants : If-Modified-Since ou If-None-Match .
Pour une requête GET, le serveur en déduit s'il doit retourner :
– si la ressource a été modifiée, une réponse complète avec :
- les entêtes
- la représentation de la ressource
- un code de statut 200 OK
– si la ressource n'a pas été modifiée :
- uniquement les entêtes
- un code de statut 304 Not Modified.
Cela permet une importante économie de ressources informatiques (bande passante, CPU...) :
– même nombre de requêtes
– mais diminution leur taille.
52 / 69 formation web - httples requêtes conditionnelles
GET
GET conditional request
«client» «server» «client»
Alice Dave Bob
[1] GET path/to/ressource-A
200 OK
[2] ETag: "1a2b3c4d"
+ ressource-A
PUT path/to/ressource-A
[3] If-Match: "1a2b3c4d"
+ ressource-A*
204 No Content
[4] ressource modified
ETag: "5e6f7g8h"
ETag of resource-A is now 5e6f7g8h
GET path/to/ressource-A
[5]
If-None-Match: "1a2b3c4d"
200 OK ressource-A* means that the resource
[6] ETag: "5e6f7g8h" resource-A has been modified, but its
+ ressource-A* url stays the same
5 minutes later
GET path/to/ressource-A*
[7]
If-None-Match: "5e6f7g8h"
server does only return headers,
[8] 304 Not Modified
the response is then very light
53 / 69 formation web - httples requêtes conditionnelles
POST
Une requête POST conditionnelle permet d'éviter l'envoi en double d'un formulaire POST (en rafraichissant la page par exemple).
La détection d'un double envoi se base sur un jeton dont la valeur est unique, ce jeton se trouve dans l'URL du champ action d'un
formulaire.
Le verbe POST est un verbe non-idempotent, et pour lequel il est donc important d'assurer l'unicité de la requête.
Le serveur répond par un code de statut :
– 201 Created : en cas de succès
– 303 See Other : en cas de détection d'un double envoi (la ressource a déjà été créée, accessible à l'URL suivante...)
– 403 Forbidden : en cas de jeton invalide (le serveur doit alors expliquer le motif du refus).
54 / 69 formation web - httples requêtes conditionnelles
POST
POST conditional request
«client» «server»
Alice Dave
single submission
[1] GET path/to/form requesting token
200 OK
[2] receiving token
+ form with attribute action="1a2b3c4d"
POST path/to/ressource-A
[3] submission
action="1a2b3c4d"
[4] 201 CREATED submission accepted by the server
double submission
[1] GET path/to/form requesting token
200 OK
[2] receiving token
+ form with attribute action="5e6f7g8h"
POST path/to/ressource-A
[3] first submission
action="5e6f7g8h"
[4] 201 CREATED first submission accepted by the server
POST path/to/ressource-A
[5] second submission
action="5e6f7g8h"
submission is rejected by the server because
[6] 303 See Other someone (and it should normally be Alice) has
already used the token 5e6f7g8h
55 / 69 formation web - httples requêtes conditionnelles
PUT
Une requête PUT conditionnelle permet d'éviter l'écrasement des modifications par accès concurrent.
Scénario :
– un utilisateur A et un utilisateur B demandent une même ressource R par une requête GET
– puis l'utilisateur A modifie la ressource R via une requête PUT
– puis l'utilisateur B modifie la ressource R via une requête PUT
– sans gestion de l'accès concurrent, l'utilisateur B écrase les modifications de l'utilisateur A, sans savoir que :
- l'utilisateur A a modifé cette ressource avant lui
- ces modifications remettaient peut-être en cause la pertinence de ses propres (utilisateur B) modifications.
56 / 69 formation web - httples requêtes conditionnelles
PUT
Le client s'assure qu'il dispose de la dernière version de la ressource qu'il est en train de modifier, en ajoutant les entêtes suivants : If-
Unmodified-Since ou If-Match
Le serveur répond par un code de statut :
– 200 OK : en cas de succès
– 412 Precondition Failed : en cas de tentative de modification d'une ressource de version obsolète
– 403 Forbidden : en cas de jeton invalide (et le serveur doit alors expliquer le motif du refus).
57 / 69 formation web - httples requêtes conditionnelles
PUT
PUT conditional request
«client» «server» «client»
Alice Dave Bob
[1] GET path/to/ressource-A
200 OK
[2] ETag: "1a2b3c4d"
+ ressource-A
[3] GET path/to/ressource-A
200 OK
[4] ETag: "1a2b3c4d"
+ ressource-A
PUT path/to/ressource-A ressource-A* means that the resource
[5] If-Match: "1a2b3c4d" resource-A has been modified, but its
+ ressource-A* url stays the same
modification is allowed by the server
204 No Content
[6] because Bob is modifying the last
ETag: "5e6f7g8h"
version of resource-A
ETag of resource-A is now 5e6f7g8h
PUT path/to/ressource-A ressource-A% means that the resource
[7] If-Match: "1a2b3c4d" resource-A has been modified, but its
+ ressource-A% url stays the same
modification is rejected by the server
[8] 412 Precondition Failed because Bob is not having the last
version of resource-A
58 / 69 formation web - httples requêtes conditionnelles
DELETE
Une requête DELETE conditionnelle permet d'éviter la suppression d'une ressource modifiée par accès concurrent.
Scénario :
– un utilisateur A et un utilisateur B demandent une même ressource R par une requête GET
– puis l'utilisateur A modifie la ressource R via une requête PUT
– puis l'utilisateur B supprime la ressource R via une requête DELETE
– sans gestion de l'accès concurrent, l'utilisateur B supprime la ressource, sans savoir que :
- l'utilisateur A a modifé cette ressource avant lui
- ces modifications remettaient peut-être en cause la pertinence de la suppression.
Le fonctionnement est similaire aux requêtes conditionnelles PUT.
59 / 69 formation web - httples requêtes conditionnelles
DELETE
DELETE conditional request
«client» «server» «client»
Alice Dave Bob
[1] GET path/to/ressource-A
200 OK
[2] ETag: "1a2b3c4d"
+ ressource-A
[3] GET path/to/ressource-A
200 OK
[4] ETag: "1a2b3c4d"
+ ressource-A
PUT path/to/ressource-A ressource-A* means that the resource
[5] If-Match: "1a2b3c4d" resource-A has been modified, but its
+ ressource-A* url stays the same
modification is allowed by the server
204 No Content
[6] because Bob is modifying the last
ETag: "5e6f7g8h"
version of resource-A
ETag of resource-A is now 5e6f7g8h
DELETE path/to/ressource-A
[7] If-Match: "1a2b3c4d"
deletion is rejected by the server
[8] 412 Precondition Failed because Bob is not having the last
version of resource-A
60 / 69 formation web - httpla sécurité
l'identification
L'identification d'un client par un serveur est un élément central de la sécurité et des services à valeur ajoutée qui bien souvent nécessitent
l'identification du client pour lui proposer un contenu personnalisé.
L'identification d'un client par un serveur peut passer par 4 mécanismes :
– les entêtes spécifiques aux requêtes
- voir les entêtes From, Referer et User-Agent dans la documentation
– l'adresse IP du client
- peu fiable, par exemple en cas de NAT ou de proxy
– des URLs longues avec des identifiants codés dans les paramètres de l'URL
- peu fiable, par exemple en "volant" une URL sur un proxy ou dans l'historique du navigateur
– les cookies sont le plus souvent utilisés car non intrusif et plutôt fiables
61 / 69 formation web - httpla sécurité
l'identification par cookie
Un cookie est envoyé par le serveur et stocké par le navigateur du client. C'est une simple chaîne de caractère telle que :
Set-Cookie: session-id=12345ABC; username=orange-client-login
Le client renvoie le cookie au serveur à chaque requête. Le serveur est alors en mesure d'identifier le client.
Un serveur peut (et devrait) restreindre le périmètre d'un cookie en définissant :
– un domaine : Domain=id.orange.fr
– un chemin : Path=/accounts
– une date d'expiration : Expires=Wed, 13 Jan 2021 22:23:01 GMT
La navigateur peut lui aussi déterminer sa politique de gestion des cookies pour les supprimer selon des règles à déterminer dans les
préférences du navigateur.
Pour aller plus loin :
– retour aux sources des cookies http, par Hubert Sablonnière (vidéo de 47 minutes)
62 / 69 formation web - httpla sécurité
l'authentification
La notion d'authentification est différente de la notion d'identification :
– l'identification consiste à dire son identité
– l'authentification consiste à prouver son identité
L'authentification est donc un mécanisme indispensable pour tout service proposant des services personnalisés et sécurisés.
Les serveurs web proposent au moins :
– une authentification de base appelée : basic authentication
– une authentification un peu plus évoluée appelée : digest authentication
Ces authentifications entraînent l'apparition d'une popup du navigateur demandant un login et un mot de passe.
63 / 69 formation web - httpla sécurité
l'authentification basique
L'authentification basique fait un usage intensif des mécanismes de HTTP :
– le client demande au serveur une ressource
– le serveur refuse de servir au client la ressource demandée
- il répond par un code statut 401 Unauthorized
- et un entête WWW-Authenticate
– le navigateur du client affiche une boite de dialogue permettant de saisir un login et un mot de passe
- il encode ces informations au format base64
- le niveau de sécurité de cette solution est faible
– le client renvoie une requête avec un entête Authorization
– le serveur authentifie le client et valide la requête
Une authentification basique doit impérativement utiliser TLS pour augmenter le niveau de sécurité. Le login et le mot de passe encodés en
base64 sont très facilement décodable et base64 ne doit pas être considéré comme un mécanisme sécurisé.
64 / 69 formation web - httpla sécurité
l'authentification basique
basic authentication
«client» «server»
Alice Dave
[1] GET path/to/my-profile
401 Unauthorized
[2]
WWW-Authenticate: Basic realm="my-service"
the user Alice enters their username
and password in the pop-up window
of the web browser
GET path/to/my-profile
[3] where Basic = base64(user:password)
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
user Alice authenticated
[4] 200 OK
65 / 69 formation web - httpla sécurité
l'authentification par proxy
Le mécanisme ressemble en tout point à l'authentification basique, sauf que c'est le proxy et non le serveur qui effectue l'authentification.
– le client demande au serveur une ressource
– le proxy refuse de transmettre au serveur la requête
- il répond par un code statut 407 Proxy Authentication Required
– le navigateur du client affiche une boite de dialogue permettant de saisir un login et un mot de passe
- il encode ces informations au format base64
- le niveau de sécurité de cette solution est faible
– le client renvoie une requête avec un entête Proxy-Authorization
– le proxy authentifie le client et valide la requête qui est alors transmise au serveur
L'authentification par proxy était en vigueur chez France Télécom il y a quelques années pour accéder à internet (avec le PASE internet). Elle
a été remplacée par une authentification NTLM qui ne nécessite plus de saisir des identifiants mais est liée à la session Windows via des
mécanismes propriétaires de Microsoft.
66 / 69 formation web - httpla sécurité
l'authentification unique
Aujourd'hui sont déployées des solutions de SSO. Elles permettrent d'être identifié sur de multiples sites grâce à une authentification unique
(ou single sign-on, SSO) :
– au sein des SI d'entreprise, par exemple le gassi et le guardian chez Orange, voire entre entreprises partenaires
– mais également dans le monde universitaire, notamment avec les solutions Shibboleth) et CAS
– ainsi que plus largement sur le Web avec notamment Facebook Login et Google Sign-In
Des efforts de standardisation des protocoles ont été menés, aboutissant finalement à :
– SAML 2.0 publié en 2005 par l'OASIS
– OpenID Connect basé sur OAuth 2.0 et publié en 2014 par l'OpenID Foundation
Orange est en train de se diriger vers l'adoption du standard OpenID pour ses APIs, que ce soit en interne ou pour nos partenaires. API
Discovery vous permet de consulter les API disponibles pour vos projets, donc certaines liés à la gestion de l'identité, utilisant OpenID
Connect :
– Identity France
– User Details France
67 / 69 formation web - httpla sécurité les certificats Pour passer de HTTP à HTTPS, il faut déployer sur le serveur un certificat, de préférence valide (signé par une autorité de certification). Mais techniquement, un certificat signé et un certificat auto-signé n'ont pas de différence. Les certificats mettent en oeuvre un réseau de confiance car ils font eux-même référence aux certificats des autorités de certification. Votre navigateur intègre par défaut des centaines de certificats d'autorités de certification (plus ou moins dignes de confiance, comme l'armée turque...). En faisant confiance à votre navigateur (et à son éditeur) vous faites également confiance à l'ensemble de ces autorités de certification. Certains dénoncent un marché de dupes où les autorités de certification vendent du vent. En effet, toutes les autorités de certification peuvent délivrer des certificats pour tous les noms de domaines. En réponse, des organisations comme CAcert ou Let’s Encrypt se sont créées en vue d'être des autorités de certification plus fiables. 68 / 69 formation web - http
conclusion HTTP est la base technique du web, de REST, et devient souvent un protocole utilisé par défaut dans beaucoup d'applications du fait qu'il passe bien les proxies. Il est vraiment important de bien comprendre HTTP et de bien connaître ses mécanismes dès-lors qu'on est amené à travailler dans le domaine du web et plus généralement dans le domaine de l'internet. 69 / 69 formation web - http
Vous pouvez aussi lire