Rapport d'alternance - Apprenti Maître d'apprentissage Tuteur académique - Réseaux & Télécommunications
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Rapport d’alternance
Système de supervision pour des baies énergies de relais radio
Apprenti : Adrien CHABOD
Maître d’apprentissage : Hubert WINKLER
Tuteur académique : Eugen DEDU
1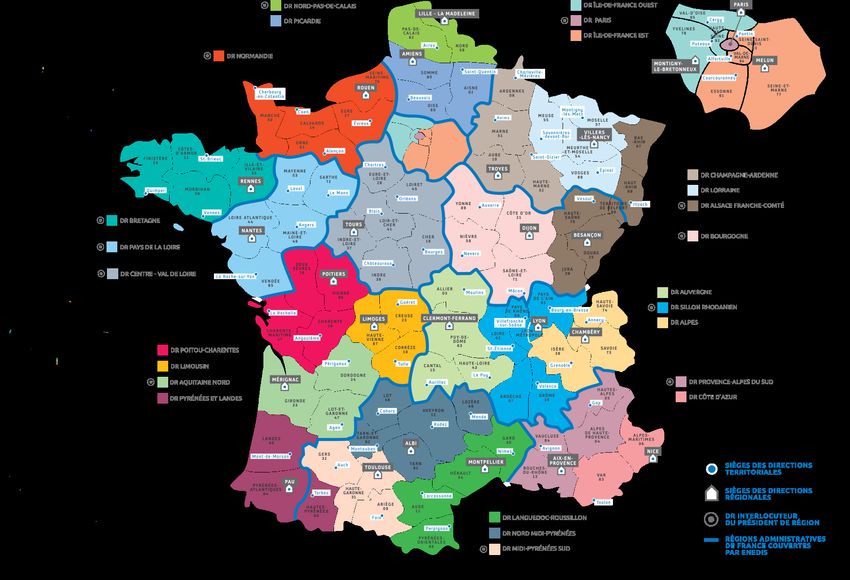
Sommaire
Enedis 4 - 11
1 – Présentation d’Enedis 4-9
2 – Présentation de l’AIS 10
3 – Présentation de l’équipe télécom AFC 10
4 – Présentation du poste de technicien télé-conduite 10 - 11
Projet 12 - 45
1 – Le but de mon projet 12
2 – Étude des besoins du projet 12
3 – Étude des solutions évoquées 13
4 – Choix du support matériel 14
5 – Choix du système d’exploitation 15
6 – Choix des différents composants logiciels 16 - 27
6.1 – Serveur Web 16
6.2 – Serveur de base de données 16 - 17
6.3 – Pare-feu 17 -19
6.4 – Fail2Ban 19
6.5 – Automatisation des tâches 19 - 20
6.6 – SNMP 20 - 23
6.6.1 – Utilisation du protocole SNMP 20
6.6.2 – Le protocole SNMP 20 - 23
6.7 – L’interpréteur de commandes Bash 24 - 25
6.8 – PHP 25 - 27
2
6.8.1 – Le langage PHP 25 - 26
6.8.2 – La communication PHP – MariaDB 27
7 – Configuration des outils 28 - 30
7.1 – Apache2 28
7.2 – NFTables/NetFilter 28 - 29
7.3 – Fail2Ban 30
8 – Les différentes versions du projet 31 - 45
8.1 – Version 0.1 32 - 35
8.2 – Version 0.2 36 - 37
8.3 – Version 0.3 38 - 39
8.4 – Version 0.4 39 - 41
8.5 – Version 0.5 42 - 43
8.6 – Version 0.6 44 - 45
Abstract 46
Conclusion 46
Evolutions envisagées 47
Remerciements 47
Bibliographie et Webographie 48
Lexique 49
Annexes 50 - 74
3
Enedis
1. Présentation d’Enedis
Enedis, anciennement ERDF (Électricité Réseau Distribution France) est une entreprise de
service public, gestionnaire du réseau de distribution d’électricité pour 95 % du territoire
métropolitain (hors Corse) et est une filiale détenue à 100 % par EDF Groupe.
Enedis développe, exploite et modernise 1,4 million de kilomètres de réseau électrique basse
et moyenne tension (220 et 20 000 volts) et gère les données associées.
Enedis réalise les raccordements des clients, le dépannage 24h/24, 7J/7, le relevé des
compteurs et toutes les interventions techniques. Elle est indépendante des fournisseurs
d’énergie qui sont chargés de la vente et de la gestion du contrat de fourniture d’électricité.
En tant que gestionnaire ayant un contrat de concession avec les communes et collectivités
locales propriétaires des lignes électriques, Enedis a l'obligation de garantir un accès au
réseau public d’électricité à tous les fournisseurs quels qu'ils soient, en toute indépendance,
en toute transparence et en assurant la non-discrimination. Elle est soumise à un code de
bonne conduite et une charte éthique.
Enedis, maillon essentiel du système électrique français
La Commission de régulation de l’énergie (CRE), autorité administrative indépendante
française, veille au bon fonctionnement du marché de l’électricité
4
Les missions du distributeur
Le réseau public de distribution d’électricité géré par Enedis
5
Enedis, 1er gestionnaire de réseau de distribution en Europe
Chiffres clés en 2019
• 36 millions de clients
• 38 000 salariés
• 14 Mds € de Chiffre d’Affaires (et + 4 Mds € d’investissements)
• 1,377 million de kilomètres de réseau électrique
• 386 419 nouveaux clients raccordés en 2019
• 12,6 millions d’interventions clients réalisées, 24h/24
• 374,8 TWh d’électricité acheminée avec moins de 6 % de pertes
• 31 000 nouvelles installations d’énergies renouvelables raccordées en 2019
Enedis, une entreprise proche des territoires avec 25 Directions Régionales et 800 sites en
France
6
Un modèle électrique à deux niveaux
Pour le bon exercice de ces missions, la distribution est organisée autour d’une double
dimension, nationale et territoriale, avec à la fois une activité régulée et une activité de
« concession » :
Les principes structurants du réseau électrique français
7
La transition énergétique et la distribution d’électricité
La distribution d’électricité est au cœur des enjeux de la transition énergétique et la loi de
2015 a conféré un rôle central aux gestionnaires de ces réseau pour :
Le distributeur est un facilitateur neutre au service de l’ensemble des acteurs de la transition
énergétique.
La loi transition énergétique pour la croissance verte prévoit de porter la part des énergies
renouvelables à 23 % de la consommation finale brute d’énergie en 2020 et 32 % de cette
consommation en 2030. Or 95 % des énergies renouvelables (ENR) sont directement
raccordées au réseau public de distribution d’électricité.
Avec l’annonce de la PPE (Programmation pluriannuelle de l’énergie) en novembre 2018, le
Gouvernement prévoit un doublement des capacités installées en termes d’ENR électriques
d’ici 2028.
En outre, La Loi de transition écologique pour la croissance verte (LTECV) met en avant les
nouveaux modes de consommation, dont l’autoconsommation et l’objectif que, d’ici à 2030,
7 millions de points de recharge seront déployés sur l’ensemble du territoire.
Le rôle d’Enedis est de raccorder ces points de recharge au réseau électrique naturellement
mais aussi conseiller les collectivités locales pour l’optimisation et la localisation des bornes
de recharge des véhicules électriques et assurer la qualité de fourniture, c’est-à-dire
l’adéquation entre la charge sur le réseau et l’évolution des usages électriques
Les smarts grids : un enjeu clef de la transition énergétique
Les smart grids répondent à plusieurs enjeux :
Gestion de la production intermittente
Nouveaux modes de consommation, tels que les véhicules électriques, et essor des
consomm’acteurs
Nouvelles technologies (numérique, stockage)
Attentes croissantes en faveur du « local »
8
Le compteur communicant, la première pierre des Smard Grids
Les pouvoirs publics ont confié à Enedis la mission de remplacer tous les compteurs existants
par des compteurs électriques communicants Linky. Lancé en 2016, le déploiement se
poursuivra jusqu’en 2021. Plus de vingt millions de compteurs sont déjà en fonctionnement.
Linky permet aux collectivités locales d’accéder à des données de consommation électrique
de masse, indispensables à l’évaluation des mesures d’économie et à l’élaboration de leurs
PLU (Plan Local d’Urbanisme) ou encore SRADDET (Schéma régional d'aménagement, de
développement durable et d'égalité des territoires) et PCAET (Plan climat-air-énergie
territorial)
Enedis est ainsi un exploitant de réseaux électriques avec les activités afférentes à cette
mission et devient un gestionnaire de données énergétiques. Le monde est en pleine
mutation, l’entreprise Enedis, ses salariés et ses métiers aussi.
9
2. Présentation de l’AIS
L’AIS (Agence d’Interventions Spécialisées) est un regroupement de l’AMEPS (Agence de
Maintenance et d’exploitation des postes sources) et l’ACM (Agence Comptage Mesures). Les
principales missions de cette unité sont : les maintenances préventives et curatives des
transformateurs et des équipements rattachés (comme les disjoncteurs HTA), la recherche
des défauts câbles, la mise en place de compteurs pour les gros consommateurs (entreprises,
industries, etc.) mais aussi pour les producteurs électriques (sites éoliens principalement
dans notre région), la mise en service et la maintenance des OMT aériens et souterrains.
Enfin, l’AIS est chargé d’assurer le bon fonctionnement du réseau de communication
permettant le pilotage à distance des postes sources, des OMT et la télé-relève des
compteurs.
3. Présentation de l’équipe télécom AFC
L’équipe dans laquelle je suis intégré est composée de 2 personnes. Hubert Winkler qui est
mon maître d’apprentissage et Alexandre Roland. Cette petite équipe couvre l’Alsace
Franche-Comté.
4. Présentation du poste de technicien télé-conduite chez Enedis :
La mission du technicien télé-conduite est d’assurer le bon fonctionnement du réseau de
communications utilisé pour « conduire » le réseau électrique. Ce réseau de communication
appelé réseau de conduite est un regroupement de plusieurs technologies qui sont
interconnectées pour permettre une totale interopérabilité des équipements.
Le réseau de conduite utilise principalement les technologies suivantes :
- RTC (en cours de remplacement)
- Radio
- ADSL/SDSL (en cours de migration d’opérateur)
- 3G/4G LTE
Les solutions reposant sur la fibre optique sont en cours d’étude.
10La totalité des sites et des équipements sont pilotés et supervisés à distance depuis un lieu
appelé l’ACR (Agence de Conduite Régionale). De plus, sur des sites sensibles comme les
postes sources les liaisons sont doublées. En effet, les postes sources disposent d’un lien
nominal ADSL ou SDSL et d’un lien RTC. Depuis peu, les équipements sont en cours de
remplacement (projet HAWAI de basculement entre SFR et Orange) ; à partir de maintenant,
les postes sources qui auront basculé chez Orange disposeront d’un lien nominal ADLS/SDSL
et d’un lien secondaire 3G/4G LTE double opérateur défini en fonction de la couverture
mobile sur site. Les relais radios seront eux aussi en liaison doublée à partir du basculement
sur HAWAI.
Comme dit précédemment, les équipements sont supervisés depuis l’ACR à l’exception des
baies énergies des relais radios qui eux disposent nativement de fonctions de supervisions
mais celles-ci n’ont jamais été mises en place.
11Projet
1. Le but de mon projet
Le but de ce projet est de réaliser un système pour superviser les baies énergies des relais
radios. Elles sont constituées d’un atelier énergie qui gère l’alimentation électrique des
autres équipements et permettent de proposer une continuité dans l’approvisionnement
électrique à l’aide de batteries en cas de défaillance secteur. Cependant, plusieurs
contraintes sont à prendre en compte, notamment celles de sécurité : les baies énergies
étant directement connectées sur le réseau de conduite, et celui-ci étant un réseau privé
sans aucune interconnexion avec un d’autres réseaux (intranet ou internet). Ceci permet un
cloisonnement total des flux qui permet d’assurer une sécurité sur le réseau. Il faut donc
rendre cette solution utilisable facilement au quotidien sans pour autant mettre en péril la
sécurité des infrastructures.
2. Etude des besoins du projet
Comme vu précédemment, le but de ce projet est de pouvoir superviser les baies énergies
des relais radios. Les objectifs de ce système sont les suivants :
- Permettre le suivi de l’état des différents composants de la baie énergie
notamment les disjoncteurs.
- Proposer une interface simple et intuitive.
- Permettre l’ajout ou la suppression de relais directement depuis l’interface.
- Assurer une mise à jour régulière des données.
- Proposer une portabilité, c’est-à-dire rendre le système compatible avec
plusieurs systèmes d’exploitation.
- Proposer des outils de débogage comme par exemple un accès simplifié aux
logs systèmes.
- Assurer une compatibilité avec les deux réseaux Enedis (SFR et Orange)
- Permettre un fonctionnement dans des conditions optimales de sécurité pour
éviter tout piratage du réseau de conduite.
Le cahier des charges de ce projet est important et les objectifs sont multiples.
123. Etude des différentes solutions évoquées
Les baies énergies des relais radio Enedis dans la Direction Régionale (DR) Alsace Franche-
Comté reposent sur des équipements de la marque Eltek. En fonction des spécifications des
relais les références varient. Cependant, peu importe le relais, chaque équipement Eltek
embarque un firmware proposant les même fonctionnalités :
Une interface Web qui propose les fonctionnalités ci-dessous
- Un système de remontée d’alarme par SMS et / ou Email.
- Une page d’administration pour configurer les accès
- Une gestion des paramètres SNMP
- Un accès aux logs d’utilisation de la machine
A première vue, le firmware natif semble proposer une grande partie des fonctionnalités
évoquées dans le cahier des charges ci-dessus, notamment un système de remontée
d’alarme. Cependant, après quelques recherches, il a été mis en évidence que toutes les
fonctionnalités intéressantes nécessitent un accès direct au réseau internet ce qui est
impossible dans notre cas car comme dit précédemment, le réseau est totalement
hermétique pour éviter toute intrusion.
Il est donc nécessaire de mettre un place un système de supervision « maison ». Il a été
envisagé dans un premier temps d’incruster directement la page Web d’administration des
ateliers énergies des relais radios. Cependant, les baies énergies des relais radios supportent
nativement le protocole SNMP qui a été imaginé pour rendre universelle la supervision peu
importe l’équipement. J’ai donc fait le choix de me baser sur SNMP pour la réalisation de
mon projet.
134. Choix du support matériel
Avant de commencer la réalisation de ce projet, il a fallu sélectionner une plateforme
matérielle pour accueillir celui-ci. Comme dit précédemment, la configuration en réseau
fermé interdit toute utilisation d’un service cloud comme l’utilisation d’un VPS. De plus, pour
des raisons de sécurité et de simplicité d’administration, nous avons aussi écarté la
possibilité d’utiliser un serveur déjà alloué pour d’autres usages. Trois solutions ont donc été
retenues afin de comparer les avantages et inconvénients de chacune :
- Un ordinateur fixe bureautique.
- Un Raspberry PI
- Une machine virtuelle
J’ai choisi d’utiliser une machine virtuelle car celle-ci propose une portabilité accrue. Pour
rappel, une machine virtuelle est un ordinateur fonctionnant virtuellement sur un autre
ordinateur. Plus précisément, l’ordinateur hôte (de préférence un ordinateur disposant de
ressources importantes) est appelé Hyperviseur, celui-ci peut être de deux types, un
hyperviseur de type 1 aussi appelé hyperviseur natif ou encore « bare métal » ayant la
particularité de s’installer directement sur la couche matériel. Au démarrage de la machine
virtuelle, l’hyperviseur prend directement le contrôle du matériel, et alloue l’intégralité des
ressources aux machines hébergées. Pour ce projet, j’ai fait le choix d’un hyperviseur de
type 2 car je ne dispose pas de machine ayant des capacités suffisantes pour permettre
l’installation et l’utilisation d’un hyperviseur de type 1. Un hyperviseur de type 2 est
considéré comme un logiciel, s’installant et s’exécutant sur un système d’exploitation déjà
présent sur la machine physique. Le système d’exploitation virtualisé par un hyperviseur de
type 2 s’exécutera dans un troisième niveau au-dessus du matériel, celui-ci étant émulé par
l’hyperviseur.
J’ai choisi d’utiliser la solution VirtualBox proposée par Oracle. Il s’agit d’un logiciel pouvant
être utilisé sous n’importe quel OS et permettant de virtualiser tous les systèmes
d’exploitation sur un même hôte.
145. Choix du système d’exploitation
Une fois la plateforme matérielle sélectionnée, il a fallu faire le choix d’un système
d’exploitation.
Le cahier des charges pour le système d’exploitation était le suivant :
- Système léger.
- Peu gourmand en ressources.
- Permet l’installation d’un grand nombre de logiciels sans complexité de
dépendances.
- Ne demande pas de mises à jour récurrentes.
Le choix d’une base Unix plutôt que d’un système Windows a rapidement fait l’unanimité ;
en effet, une distribution Linux a les avantages suivants :
- Choix de l’installation d’une interface graphique ou non.
- Très peu gourmand en ressources.
- Facilité d’installation les logiciels (paquets) nécessaires à l’accomplissement
du projet.
- Pas besoin d’activation.
- Mise à jour uniquement sur demande.
J’ai choisi d’utiliser une distribution Debian en version 10 car c’est un système que j’utilise
très souvent et que je connais.
156. Choix des différents composants logiciels
6.1. Serveur Web
Pour le serveur Web, j’ai fait le choix d’utiliser Apache2. En janvier 2020, le serveur Web
Apache2 maintenu et développé par Apache Software Foundation était utilisé par environ
46 % des sites web à travers le monde. La solution proposée par Apache Software
Foundation a l’avantage d’être très simple de configuration, de plus celui-ci est facilement
personnalisable car il est construit sur une structure modulaire. En clair, un administrateur
active ou désactive les modules qu’il souhaite sur son installation. De plus, Apache est le
serveur qui est installé par défaut sur les machines exécutant Debian 10 (la version choisie
pour la mise en place du projet) et c’est aussi celui-ci qui sera automatiquement configuré à
l’installation de PHP (dont nous parlerons plus tard). D’autres solutions existent comme
Nginx ou Lighttpd. Nginx est une alternative à Apache2, celui-ci a été créé pour résoudre un
problème appelé c10k, problème qui dégrade fortement les performances des serveurs Web
au-delà de 10 000 connexions simultanées. Nginx est donc plus adapté aux sites à fort trafic.
Quant à Lighttpd, il s’agit d’un projet visant à créer un serveur Web à très faible
consommation de ressources, cependant, celui-ci ne permet pas l’utilisation de très
nombreuses fonctionnalités…
Plusieurs composantes ont été ajoutées au serveur Web afin de lui permettre d’interagir
avec les autres éléments du projet ou dans le but d’en améliorer la sécurité.
En effet, une interface Web est nécessaire, la façon la plus simple de faire communiquer un
site avec une base de données est d’utiliser le langage PHP, pour utiliser PHP avec Apache2 il
faut installer le paquet : « php » via le gestionnaire APT intégré à Debian. De plus, j’ai installé
« php-mbstring » qui permet l’utilisation de chaines de caractères multi-octets.
6.2. Serveur de base de données
Les bases de données (BDD) sont utilisées pour stocker et exploiter l’intégralité des
informations relatives à un thème ou à une activité. Celles-ci peuvent être structurées
comme les bases de données relationnelles (que nous allons utiliser) ou bien hébergées sous
forme de données brutes déstructurées qui, dans ce cas, seront ensuite parcourues de
manière organisée au moment de la lecture via des moteurs spécifiques.
16J’ai fait le choix d’une base de données relationnelle au langage SQL car celles-ci ont été
étudiées durant le DUT, de plus, elles sont bien intégrées et facile d’utilisation avec PHP.
Par habitude, j’ai aussi fait le choix d’utiliser Maria DB qui est un fork communautaire de
MySQL. A la différence de MySQL qui est gratuit mais sous licence propriétaire, Maria DB est
libre (open source) et donc évidemment gratuit. Enfin, en 2012, MySQL a été abandonné au
profit de Maria DB par Debian ce qui facilite son installation par rapport à MySQL.
6.3. Pare-feu
Un pare-feu (firewall en anglais) est un logiciel et/ou matériel permettant de faire respecter
la politique de sécurité du réseau. Cette dernière définit les types de communications
autorisées sur ce réseau informatique. Il surveille et contrôle les applications et les flux de
données (paquets).
Même si ce réseau informatique est physiquement hermétique, j’ai fait le choix d’installer un
pare-feu sur la machine virtuelle qui sera amené à héberger mon projet. En effet,
l’installation d’un pare-feu permet de diminuer la « surface d’attaque » de la machine et
donc d’éviter au maximum que celle-ci soit utilisée à des fins malveillantes. Par exemple, on
peut très bien imaginer le scénario d’attaque suivant : ce réseau étant assez difficile d’accès,
les personnes disposant dudit accès sont toutes connues par l’entreprise car elles disposent
d’habilitations et des connaissances sur la topologie du réseau. Si une personne
malintentionnée souhaite réaliser une attaque contre un ou plusieurs équipements du
réseau, elle aurait tout intérêt à masquer l’origine de l’attaque. Le recours à une machine
vulnérable comme intermédiaire permettrait alors d’effectuer une attaque en diminuant
fortement le risque d’être mis en cause.
Le choix d’un pare-feu est à réfléchir en fonction de l’importance de la machine mais surtout
en fonction de la quantité de trafic à filtrer et du coût financier de celui-ci par rapport au
gain en termes de sécurité.
On distingue deux grandes plateformes de pare-feux :
- Les pare-feux physiques.
- Les pare-feux logiciels
Un pare-feu physique est un équipement séparé de notre ordinateur, celui-ci est situé entre
notre accès au réseau externe et notre machine. Ce genre de pare-feu ne fonctionne pas
directement sur le système comme un logiciel, il a l’avantage d’être beaucoup plus difficile à
déjouer mais il est aussi plus onéreux qu’un pare-feu logiciel.
17Un pare-feu logiciel est installé directement sur le système à protéger, celui-ci a l’avantage
d’être moins cher voire gratuit mais en échange il est un peu moins efficace que le pare-feu
physique. Dans mon cas, j’ai fait le choix d’un pare-feu logiciel car celui-ci sera suffisant pour
assurer la sécurité de notre installation.
Une fois la plateforme sélectionnée, il faut savoir que différentes catégories de pare-feux
existent. On compte notamment le pare-feu sans état (stateless firewall), le pare-feu à états
(stateful firewall), le pare-feu applicatif et le pare-feu identifiant.
Pour commencer, le pare-feu sans état (stateless firewall) est le plus vieux dispositif de
filtrage réseau. Il regarde chaque paquet indépendamment des autres et le compare à une
liste de règles préconfigurées. Le pare-feu sans état est bien souvent assez complexe à
configurer et l’absence de prise en compte de l’état des connexions ne permet pas d’obtenir
une finesse de filtrage très évoluée. Ces pare-feux ont donc tendance à tomber en
désuétude.
Ensuite, le pare-feu à états introduit une notion de connexion. Les pare-feux à états vérifient
la conformité des paquets à une connexion en cours. C’est-à-dire qu’il vérifie que chaque
paquet d’une connexion est bien la suite du précédent paquet et la réponse à un paquet
dans l’autre sens.
Le pare-feu applicatif quant à lui vérifie la conformité d’un paquet à un protocole. Par
exemple, le port 80 est utilisé par le protocole HTTP, le pare-feu applicatif vérifie que chaque
paquet transitant par le port 80 est bien un paquet utilisant le protocole HTTP. Cependant,
ce genre de filtrage est très gourmand en temps de traitement dès que le débit devient
important.
Enfin, le pare-feu identifiant permet un filtrage par utilisateur et non plus par adresse IP ou
adresse MAC. Ce genre de pare-feu utilise un système d’association entre l’utilisateur et une
adresse IP ou MAC.
Dans notre cas, nous allons utiliser un pare-feu avec états (et qui propose aussi les
fonctionnalités d’un pare-feu sans état). Il s’agit du cadriciel (framework) Netfilter associé à
l’utilitaire NFTables.
Comme dit précédemment, Netfilter est un cadriciel (framwork) implémentant un pare-feu
au sein du noyau Linux (à partir de la version 2.4). Il prévoit des accroches ((hooks) sans le
noyau pour l’interception et la manipulation des paquets réseau lors de l’appel des routines
de réception ou d’émission des paquets des interfaces réseau. L’une des caractéristiques
importantes construites sur la framework Netfilter est le Connection Tracking (CT) qui
permet au noyau de garder la trace de toutes connexions réseau et par conséquent tous les
paquets qui composent cette connexion.
NetFilter est donc le pare-feu de Linux, cependant, celui-ci est pratiquement inconfigurable
sans un utilitaire pour réaliser cette tâche. Il en existe deux : IPTables et NFTables. NFTables
est simplement une grosse évolution d’IPTables. Nous parlerons donc uniquement de celui-ci
qui sera utilisé dans le projet.
18NFTables est un sous-système du noyau Linux fournissant le filtrage et la classification des
paquets. Il s’agit d’une sorte d’interface permettant la mise en place d’un pare-feu (ou d’une
translation d’adresse) sur un système Linux en utilisant les crochets (hooks) proposés par
NetFilter. NFTables apporte de nombreuses évolutions par rapport à IPTables notamment
dans la syntaxe des règles de filtrage mais surtout, les performances de NFTables sont
supérieures à celles d’IPTables.
Ci-dessous deux schémas explicatifs du fonctionnement de différents crochets (hooks) :
6.4. Fail2Ban
Fail2ban bloque les adresses IP appartenant à des hôtes qui tentent de casser la sécurité du
système, pendant une période configurable (mise en quarantaine).
Il lit les logs de divers services (SSH, Apache, FTP…) à la recherche d'erreurs
d'authentification répétées et ajoute une règle IPTables ou NFTables pour bannir l'adresse IP
de la source.
Il permet de ralentir les attaques par force brute, ainsi que les attaques par déni de service.
Fail2ban est aussi capable de bloquer les attaques distribuées.
6.5. Automatisation des taches – Cron
L’automatisation des tâches est une nécessité car elle assure la mise à jour régulière des
informations. Sans cette automatisation, le système ne permettrait plus de supervision ni de
remontée d’alarme en cas de défaillance. Les systèmes Unix étant très complets et
permettant de nombreux cas d’usage, cette fonctionnalité est implémentée depuis très
longtemps sous la forme d’un programme appelé « cron ». Cron est la troncation de crontab,
lui-même troncation de chrono-table qui signifie « table de planification ». Il s’agit d’une
19fonctionnalité très utile pour des tâches routinières d’administration système mais elle peut
très bien être exploitée pour tout autre chose.
Cron prend la forme d’un daemon, ce qui désigne un programme qui s‘exécute en arrière-
plan. Le service cron (crond) attend ainsi jusqu’au moment spécifié dans le fichier de
configuration (que l’on appelle le crontab) puis effectue l’action correspondante et se
rendort jusqu’à l’événement suivant. Crontab est le programme permettant sous Unix la
modification des fichiers de configuration cron. Enfin, le service cron est lancé par le compte
root pour pouvoir s’adapter à l’identité de chacun des utilisateurs.
Le logiciel cron s’utilise avec une syntaxe particulière qui est la suivante :
6.6. SNMP
6.6.1. Utilisation du protocole SNMP
Comme dit en introduction, j’ai choisi de me baser sur le protocole SNMP pour effectuer la
supervision des baies énergies. Le fonctionnement de SNMP sera expliqué plus bas,
cependant, pour exploiter les fonctionnalités de SNMP, il faut avant tout installer le client
SNMP via le gestionnaire de paquets APT à l’aide de la commande : « apt install snmp ».
L’installation du service SNMP (snmpd) n’est pas utile car le service SNMP offre la possibilité
de supervision de la machine sur lequel il est installé, ce qui n’a aucun intérêt dans mon cas.
6.6.2. Le protocole SNMP
20Une fois l’étude de besoins et les différentes configurations réalisées, il a fallu commencer la
création à proprement parler du système.
Comme dit plus haut, le projet va utiliser le protocole de SNMP pour effectuer le relevé de
l’état des différents systèmes.
SNMP signifie « Simple Network Management Protocol », ce protocole réseau permet le
monitoring et la supervision d’éléments systèmes et réseaux. Généralement, un serveur de
supervision utilise SNMP pour connaître rapidement l’état du parc informatique (switch,
routeur, serveurs) comme l’occupation RAM, CPU, Disque etc.
Le système de gestion de réseau est basé sur deux éléments principaux : un superviseur et
des agents. Le superviseur est la console qui permet à l'administrateur réseau d'exécuter des
requêtes de management. Les agents sont des entités qui se trouvent au niveau de chaque
interface connectant l'équipement managé au réseau et permettant de récupérer des
informations sur différents objets.
Switchs, hubs, routeurs et serveurs sont des exemples d'équipements contenant des objets
manageables. Ces objets manageables peuvent être des informations matérielles, des
paramètres de configuration, des statistiques de performance et autres objets qui sont
directement liés au comportement en cours de l'équipement en question. Ces objets sont
classés dans une sorte de base de données appelée MIB ("Management Information Base").
SNMP permet le dialogue entre le superviseur et les agents afin de recueillir les objets
souhaités dans la MIB.
L'architecture de gestion du réseau proposée par le protocole SNMP est donc basée sur trois
principaux éléments :
Les équipements managés (managed devices) sont des éléments du réseau (ponts,
hubs, routeurs ou serveurs), contenant des "objets de gestion" (managed objects)
pouvant être des informations sur le matériel, des éléments de configuration ou des
informations statistiques ;
Les agents, c'est-à-dire une application de gestion de réseau résidant dans un
périphérique et chargée de transmettre les données locales de gestion du
périphérique au format SNMP ;
Les systèmes de management de réseau (network management systems notés NMS),
c'est-à-dire une console au travers de laquelle les administrateurs peuvent réaliser
des tâches d'administration.
Concrètement, dans le cadre d'un réseau, SNMP est utilisé :
pour administrer les équipements ;
pour surveiller le comportement des équipements.
21Une requête SNMP est un datagramme UDP habituellement envoyé par le manager à
destination du port 161 de l'agent. Les schémas de sécurité dépendent des versions de
SNMP (v1, v2 ou v3). Dans les versions 1 et 2, une requête SNMP contient un nom appelé
communauté, utilisé comme un mot de passe. Sur de nombreux équipements, la valeur par
défaut de communauté est « public » ou « private ». Pour des raisons de sécurité, il convient
de modifier cette valeur. Un nom de communauté différent peut être envisagé pour les droits
en lecture et ceux en écriture. Les versions 1 et 2 du protocole SNMP comportent de
nombreuses lacunes de sécurité. C'est pourquoi les bonnes pratiques recommandent de
n'utiliser que la version 3. Cette dernière se base sur le chiffrement DES avec deux mots de
passe ou clés sur 64 bits partagés entre l'agent et le manager :
un pour l'authentification
un pour le chiffrement
Si un mot de passe venait à être trouvé, ce procédé permet de ne pas compromettre à la fois
la sécurité du chiffrement et de l'authentification.
Pour les tâches d'administration de serveurs sensibles via SNMP (reboot, etc.), la version 3
montre tout de même certaines limites en matière de sécurité (chiffrement plutôt faible).
Pour pallier cela et ainsi renforcer la sécurité des échanges SNMP, la RFC 38262 traite de
l'implémentation d'AES dans ce dernier.
Un grand nombre de logiciels libres et propriétaires utilisent SNMP pour interroger
régulièrement les équipements et produire des graphes rendant compte de l'évolution des
réseaux ou des systèmes informatiques (Centreon, NetCrunch 5, MRTG, Cacti, Shinken,
Nagios, Zabbix, PRTG, Observium, LibreNMS).
Le protocole SNMP définit aussi un concept d'interruptions3 (traps en anglais). Une fois
défini, si un certain événement se produit, comme le dépassement d'un seuil, l'agent envoie
un paquet UDP sur le port 162 du serveur de supervision.
Vous trouverez-ci dessous un schéma très simplifié des interactions en utilisant le protocole
SNMP :
Comme dit plus haut, différentes versions du protocole SNMP existent. Cependant, au vu des
importants problèmes de sécurité présents dans les versions 1 et 2, seule la version 3 du
protocole est recommandée pour une utilisation sur des équipements en production.
22De plus, le protocole de chiffrement DES (Data Encryption Standard) n’est plus recommandé
du fait de sa lenteur à l’exécution et de son espace de clés trop petit permettant une attaque
par force brute en un temps raisonnable.
J’ai donc choisi d’implémenter dans mon système de supervision la version 3 du protocole
SNMP. A la différence des versions 1 et 2 de ce protocole, la version 3 n’utilise pas de nom de
communauté mais un nom d’utilisateur et deux mots de passe, ce qui a été expliqué plus
haut. J’ai fait le choix de l’algorithme SHA1 pour l’authentification et AES pour le chiffrement.
Le protocole SNMP est juste un protocole de communication, il est inutile si on ne connaît
pas en détail la branche MIB se rapportant à l’appareil à superviser ou plus largement à son
constructeur.
Une MIB (management information base, base d'information pour la gestion du réseau) est
un ensemble d'informations structuré sur une entité réseau, par exemple un routeur, un
commutateur ou un serveur.
La structure de la MIB est hiérarchique : les informations sont regroupées en arbre. Chaque
information a un « object identifier », une suite de chiffres séparés par des points, qui
l'identifie de façon unique et un nom, indiqué dans le document qui décrit la MIB.
Par exemple, 1.3.6.1.2.1.2.2.1.2 est l'object identifier ifDescr qui est la chaîne de caractères
décrivant une interface réseau (comme eth0 sur Linux ou Ethernet0 sur un routeur Cisco).
Chaque constructeur dispose donc de sa propre branche dans la MIB, il est libre de
l’organiser à sa façon, cependant, il est évident qu’il ne peut pas utiliser une autre branche
que la sienne et qu’il doit appliquer les règles d’écriture propres à cette base de données qui
sont définies dans la RFC 1155. Généralement, les constructeurs intègrent dans leurs
équipements la totalité de la MIB standard (qui est publique) et la branche correspondant à
leurs équipements sous la branche « Entreprise ». Le schéma suivant montre la position dans
l’arbre de la branche MIB du constructeur Cisco.
Dans mon cas, j’ai été forcé de contacter
à plusieurs reprises l’entreprise Eltek
pour obtenir de leur part la branche MIB
se rattachant aux équipements possédés
par Enedis. Eltek propose un système de
supervision plus évolué que celui intégré
nativement dans chaque équipement, je
suppose donc qu’ils souhaitent éviter de
communiquer ces informations pour des
raisons commerciales.
236.7. L’interpréteur de commandes Bash
Une fois la MIB connue, il est à présent temps de l’exploiter pour effectuer quelques tests de
vérification. Pour cela, j’ai au préalable installé sur la machine hébergeant mon projet le
client SNMP pour l’exploitation de ce protocole. Le paquet SNMP regroupe un grand nombre
d’outils permettant l’exploitation de ce protocole. Certains outils graphiques existent pour
naviguer et extraire des informations à l’aide du protocole SNMP mais par choix, j’ai décidé
d’utiliser uniquement des outils en lignes de commandes pour deux raisons : les outils en
lignes de commandes sont bien moins gourmands en ressources. De plus, étant utilisateur
très régulier de systèmes Linux, les outils en CLI sont plus simples à utiliser une fois qu’on en
a l’habitude.
Cependant, pour utiliser des outils en lignes de commandes il faut au préalable disposer d’un
interpréteur de commandes. Un interpréteur de commande est un logiciel système faisant
partie des composants de base d’un système d’exploitation. Sa fonction est d’interpréter les
commandes qu’un utilisateur tape au clavier dans l’interface en lignes de commandes pour
ensuite les traduire en code compréhensible par la machine. Sur Debian et plus largement
sur les systèmes Unix, l’interpréteur de commandes de base est Bash pour « Bourne-Again
shell », celui-ci est l’évolution du Bourne shell « sh ou bsh » qui était un des premiers
interpréteurs du projet Unix.
Comme tous les interpréteurs en lignes de commandes de type script, Bash exécute quatre
opérations fondamentales :
1. Il fournit une liste de commandes permettant d'opérer sur l'ordinateur (lancement de
programmes, copie de fichiers, etc.) ;
2. Il permet de regrouper ces commandes dans un fichier unique appelé script ;
3. Il vérifie la ligne de commandes lors de son exécution ou lors d'une éventuelle
procédure de vérification et renvoie un message d'erreur en cas d'erreur de syntaxe ;
4. En cas de validation, chaque ligne de commande est interprétée, c'est-à-dire traduite
dans un langage compréhensible par le système d'exploitation, qui l'exécute alors.
Les scripts sont de courts programmes généralement faciles à construire. Bash offre un
service de gestion de flux, c'est-à-dire qu'il permet que le résultat d'un script (la sortie) soit
transmis à un autre script (l'entrée). De cette façon, les scripts peuvent être « chaînés »,
chacun effectuant une seule tâche bien délimitée.
Bash est un shell qui peut être utilisé soit en mode interactif, soit en mode batch :
mode interactif : Bash attend les commandes saisies par un utilisateur puis renvoie le
résultat de ces commandes et se place à nouveau en situation d'attente.
mode batch : Bash interprète un fichier texte contenant les commandes à exécuter.
24Pour les besoins du projet, j’ai utilisé Bash dans les deux modes, le mode interactif pour
l’administration de la machine et réaliser des tests ou du débogage et le mode batch car les
requêtes SNMP seront réalisées par des scripts bash qui seront eux-mêmes générés par un
autre script Bash.
6.8. La partie PHP
6.8.1. Le langage PHP
PHP est un langage de script utilisé le plus souvent côté serveur : dans cette architecture, le
serveur interprète le code PHP des pages Web demandées et génère du code (HTML,
XHTML, CSS par exemple) et des données (JPEG, GIF, PNG par exemple) pouvant être
interprétés et rendus par un Navigateur Web. PHP peut également générer d'autres formats
comme le WML, le SVG et le PDF.
Il a été conçu pour permettre la création d'applications dynamiques, le plus souvent
développées pour le Web. PHP est le plus souvent couplé à un serveur Apache bien qu'il
puisse être installé sur la plupart des serveurs HTTP tels qu’IIS ou Nginx. Ce couplage permet
de récupérer des informations issues d'une base de données, d'un système de fichiers
(contenu de fichiers et de l'arborescence) ou plus simplement des données envoyées par le
navigateur afin d'être interprétées ou stockées pour une utilisation ultérieure.
C'est un langage peu typé et souple et donc facile à apprendre par un débutant mais, de ce
fait, des failles de sécurité peuvent rapidement apparaître dans les applications.
Pragmatique, PHP ne s'encombre pas de théorie et a tendance à choisir le chemin le plus
direct. Néanmoins, le nom des fonctions (ainsi que le passage des arguments) ne respecte
pas toujours une logique uniforme, ce qui peut être préjudiciable à l'apprentissage.
Son utilisation commence avec le traitement des formulaires puis par l'accès aux bases de
données. L'accès aux bases de données est aisé une fois l'installation des modules
correspondants effectuée sur le serveur. La force la plus évidente de ce langage est qu'il a
permis au fil du temps la résolution aisée de problèmes autrefois compliqués et est devenu
par conséquent un composant incontournable des offres d'hébergement.
Il est multiplateforme : autant sur Linux qu'avec Windows, il permet aisément de reconduire
le même code sur un environnement à peu près similaire (prendre en compte les règles
d'arborescences de répertoires qui peuvent changer).
Libre, gratuit, simple d'utilisation et d'installation, ce langage nécessite comme tout langage
de programmation une bonne compréhension des principales fonctions usuelles ainsi qu'une
connaissance aiguë des problèmes de sécurité liés à ce langage.
PHP appartient à la grande famille des descendants du C, dont la syntaxe est très proche. En
particulier, sa syntaxe et sa construction ressemblent à celles des langages Java et Perl, à ceci
25près que du code PHP peut facilement être mélangé avec du code HTML au sein d'un fichier
PHP.
Dans une utilisation destinée à l'internet, l'exécution du code PHP se déroule ainsi : lorsqu'un
visiteur demande à consulter une page de site Web, son navigateur envoie une requête au
serveur HTTP correspondant. Si la page est identifiée comme un script PHP (généralement
grâce à l'extension .php), le serveur appelle l'interprète PHP qui va traiter et générer le code
final de la page (constitué généralement d'HTML ou de XHTML, mais aussi souvent de feuilles
de style en cascade et de JS). Ce contenu est renvoyé au serveur HTTP, qui l'envoie
finalement au client.
Ce schéma explique ce fonctionnement :
Comme expliqué précédemment, le mode de fonctionnement de PHP se rapproche d’un
langage interprété même si pour être précis, celui-ci est précompilé en bytecode (code
intermédiaire) puis envoyé à la machine pour être interprété. C’est une notion importante
car dans une page Web utilisant du PHP, les instructions sont exécutées selon l’ordre dans
lequel elles ont été écrites. Je me suis servi de cette propriété pour permettre un affichage
dynamique de la page en utilisant une seule fois le même code pour toute la page et en
modifiant simplement les variables.
266.8.2. La communication entre PHP et MariaDB
Une fois le fonctionnement de base de PHP bien assimilé, il a été nécessaire de permettre la
communication entre mon serveur Web et mon serveur de base de données. Pour cela, il a
fallu installer l’extension php-mysql qui au travers du langage PHP permet l’exploitation
d’une base de données relationnelle qui se base sur le langage SQL. Le paquet php-mysql
permet de réaliser à partir d’une page Web écrite en PHP des requêtes sur un serveur SQL.
Il existe deux syntaxes différentes pour accéder à une base de données via PHP, la syntaxe
dite mysqli et la syntaxe PDO. L’extension MySQLi (abréviation pour MySQL Improved en
anglais, c’est-à-dire MySQL Amélioré) est un pilote qui permet d’interfacer des programmes
écrits en PHP avec les bases de données MySQL. MySQLi est donc la méthode la plus
ancienne des deux mais elle ne permet d’accéder qu’aux bases de données MySQL. Pour ma
part, j’ai choisis d’utiliser PDO qui est plus récent. PHP Data Objects (PDO) est une extension
définissant l'interface pour accéder à une base de données avec PHP.
Elle est orientée objet, la classe s’appelant PDO. PDO constitue une couche d'abstraction qui
intervient entre l'application PHP et un système de gestion de base de données (SGDB) tel
que MySQL, PostgreSQL ou MariaDB par exemple. La couche d'abstraction permet de
séparer le traitement de la base de données proprement dite. PDO facilite donc la migration
vers un autre SGBD puisqu'il n'est plus nécessaire de changer le code déjà développé. Il faut
seulement changer les arguments de la méthode envoyés au constructeur.
Pour récupérer les enregistrements d’une table de la base de données, la procédure
classique en PHP consiste à parcourir cette table ligne par ligne en procédant à des allers-
retours entre l'application PHP et le SGBD. Ceci risque d’alourdir le traitement surtout si les
deux serveurs sont installés chacun sur une machine différente. PDO corrige ce problème en
permettant de récupérer en une seule fois tous les enregistrements de la table sous forme
d’une variable PHP de type tableau à deux dimensions, ce qui réduit le temps de traitement.
277. Configuration des outils
La présentation et l’explication du rôle de chacun de ces outils, je vais à présent rapidement
détailler la configuration de chacun. Les configurations complètes seront disponibles en
annexe, ce chapitre présentera uniquement quelques lignes de configuration pour chaque
outil.
Généralement, les fichiers de configuration des différents logiciels sur une machine Linux se
situent dans le répertoire « /etc », dans la suite de cette partie, les répertoires seront donnés
depuis le répertoire « /etc »
7.1. Apache2
La configuration du serveur Web se situe dans le répertoire « apache2/sites-enabled» mais la
bonne pratique consiste à écrire la configuration dans « apache2/sites-available » puis de
réaliser un lien symbolique via la commande « ln -s » du répertoire « apache2/sites-
available » sur le répertoire « apache2/sites-enabled »
La configuration que j’ai utilisée est en réalité la configuration par défaut du logiciel Apache2,
celle-ci est disponible en annexe de ce document.
7.2. NFTables/NetFilter
Comme dit précédemment, le framework NFTables permet d’interagir avec NetFilter, il peut
être configuré de deux manières différentes : soit on entre les règles de filtrage l’une après
l’autre directement dans la console, celles-ci seront effacées au redémarrage du système, soit
on écrit un fichier de configuration qui sera pris en compte à chaque démarrage. J’ai fait le
choix de la seconde option (mélanger les deux façons n’est pas impossible) car je trouve cela
beaucoup plus simple à vérifier et à modifier.
Après installation de NFTables via le gestionnaire APT : « apt install nftables », il faut donc
modifier le fichier nftables.conf depuis le compte root à l’aide de nano ou vi.
Dans une idée de possible évolution, le firewall mis en place filtre les requêtes Ipv4 mais
aussi les requêtes Ipv6. Les parties Ipv4 et Ipv6 sont assez semblables, je vais donc expliquer
uniquement la partie Ipv4. Voici donc les règles qui sont à mon sens les plus importantes :
28Vous pouvez aussi lire

















































