Similarity Search, Approximate Nearest Neighbors Search and Hashing - Alexis Joly January 21, 2021 - Renater
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Similarity Search, Approximate Nearest Neighbors
Search and Hashing
Alexis Joly
Inria
alexis.joly@inria.fr
January 21, 2021
Alexis Joly (INRIA) Sim Search January 21, 2021 1 / 47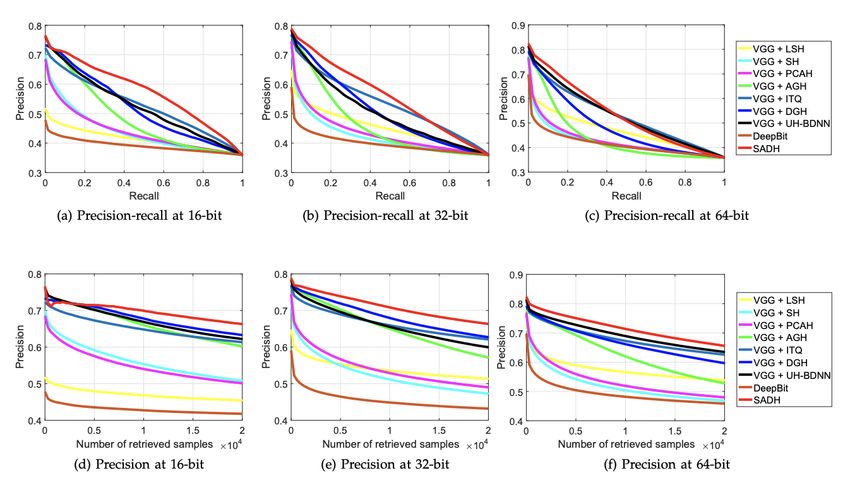
Objectif
Prétraiter une base de N objets
pour qu’étant donné un objet requête,
on puisse rapidement déterminer
les plus proches voisins dans la base
Alexis Joly (INRIA) Sim Search January 21, 2021 2 / 47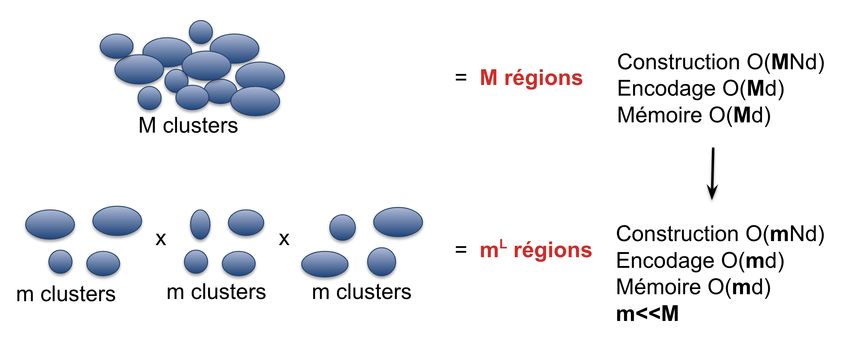
Objectif
Espace de recherche: Espace U (e.g. Rd ), fonction de similarité σ (e.g.
produit scalaire euclidien)
Entrée: ensemble X = {x1 , . . . , xN } ⊆ U
Requête: q ∈ U
Tâche: trouver efficacement arg maxi σ(xi , q) (ou plus généralement les
K plus proches voisins ou les voisins dans un rayon donné)
x2
x5
x4
x3
q
x1 x6
Alexis Joly (INRIA) Sim Search January 21, 2021 3 / 47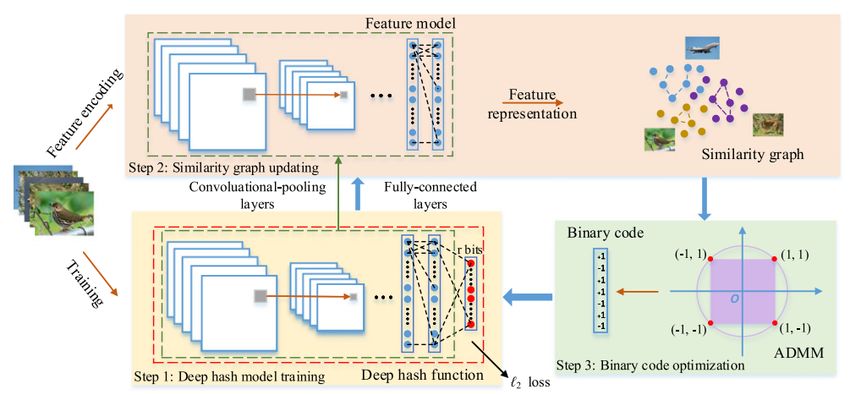
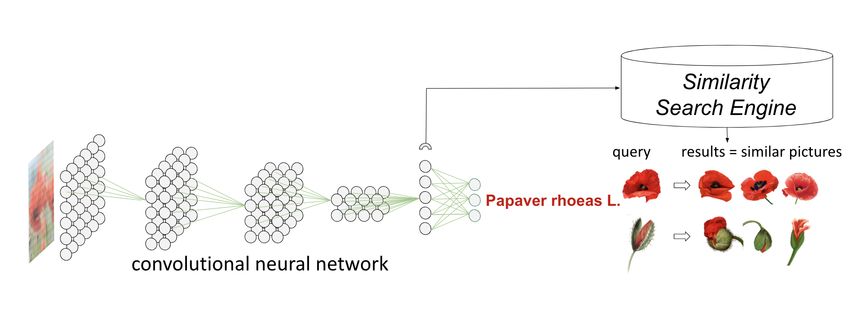
Applications
Google Image: recherche d’images similaires
Shazam: identification de musiques (reverse search)
Pl@ntNet: specimens de la base les plus ressemblant
Machine Learning: passage à l’échelle (K plus proches voisins, manifold
learning, kernel trick, etc.)
Alexis Joly (INRIA) Sim Search January 21, 2021 4 / 47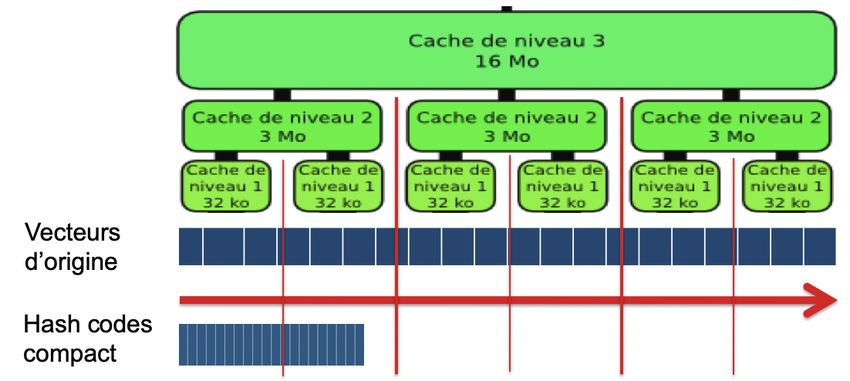
Recherche exhaustive
Principe: parcours exhaustif de tous les objets de la base et calcul de tous
les σ(xi , q)
Méthode naïve: avec un sort O(N.d + N. log N)
Méthode efficace (KNN): avec une Priority Queue O(N.d + N. log K )
Algorithm 1 KNN search with a priority queue
1: TopKQueue=PriorityQueue()
2: for i = 1 to N do
3: TopKQueue.put(σ(xi , q), xi )
4: if i < K then
5: TopKQueue.get()
6: end if
7: end for
Alexis Joly (INRIA) Sim Search January 21, 2021 5 / 47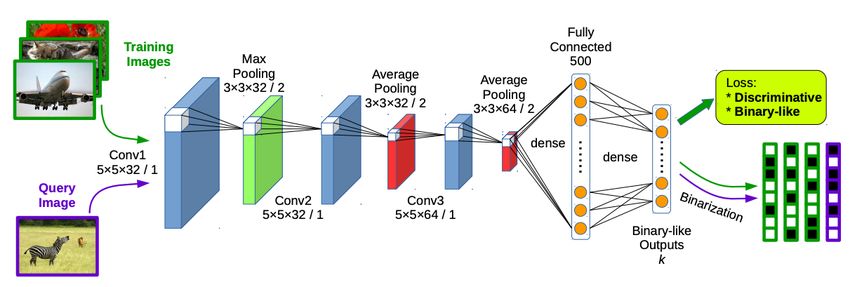
Cas des espaces métriques
M = (U, d), fonction distance d satisfaisant:
Non negativité: ∀x, x 0 ∈ U : d(x, x 0 ) ≥ 0
Symmetrie: ∀x, x 0 ∈ U : d(x, x 0 ) = d(x 0 , x)
Identité: d(x, x 0 ) = 0 ⇒ x = x 0
Inégalité triangulaire: ∀x, x 0 , q ∈ U : d(x, q) ≤ d(x, x 0 ) + d(x 0 , q)
On cherche les xi minimisant d(xi , q).
Exemples:
Rd avec distance Euclidienne ou autres métriques Lp
Chaînes de caractères avec distance de Levenshtein (edit)
|A∩B|
Ensembles finis avec métrique de Jaccard d(A, B) = 1 − |A∪B| ,
distance de Hausdorff, ou Earth Mover Distance (EMD)
Alexis Joly (INRIA) Sim Search January 21, 2021 6 / 47
Branch and Bound: Recherche hiérarchique
(x1 , x2 , x3 , x4 , x5 )
Ensemble X = {x1 , . . . , xN }
représentée par un arbre:
Chaque noeud est un sous-ensemble de X
La racine est X entier (x1 , x2 , x3 ) (x4 , x5 )
L’ensemble père est entièrement couvert
par les ensembles fils
Chaque noeud contient une description de (x1 , x3 ) x2 x4 x5
son sous-arbre fournissant une borne
inférieure pour d(q, ·) dans le
sous-ensemble correspondant
x3 x1
Alexis Joly (INRIA) Sim Search January 21, 2021 7 / 47Branch and Bound: Recherche à un rayon près
(x1 , x2 , x3 , x4 , x5 )
Objectif: Trouver tous les xi tels que
d(xi , q) ≤ r :
1 Parcours en profondeur de l’arbre
(x1 , x2 , x3 ) (x4 , x5 )
(algorithme récursif)
2 A chaque noeud, calcul de la borne
inférieure du sous-ensemble
correspondant (x1 , x3 ) x2 x4 x5
3 Elimination des branches avec une
borne inférieure supérieure à r
x3 x1
Alexis Joly (INRIA) Sim Search January 21, 2021 8 / 47B&B: Recherche du plus proche voisin
Objectif: trouver argminxi d(xi , q):
1 Choisir aléatoirement un xi , initialiser xNN := xi , rNN := d(xi , q)
2 Commencer une recherche à rNN près
3 Lorsque l’on rencontre un xj tel que d(xj , q) < rNN , mise à jour
pNN := xj , rNN := d(xj , q)
Alexis Joly (INRIA) Sim Search January 21, 2021 9 / 47B&B: Best Bin First
Objectif: trouver argminxi d(xi , q):
1 Choisir aléatoirement un xi , initialiser pNN := xi , rNN := d(xi , q)
2 Mettre le noeud racine dans une queue d’inspection
3 Répéter: choisir le noeud de la queue d’inspection ayant la borne inférieure
la plus petite, calculer les bornes inf. des sous-ensembles fils
4 Insérer dans le queue les fils dont la borne inf. est inférieure à rNN ; éliminer
les branches des autres fils
5 Lorsque l’on rencontre un xj tel que d(xj , q) < rNN , mise à jour
pNN := xj , rNN := d(xj , q)
Alexis Joly (INRIA) Sim Search January 21, 2021 10 / 47R-Tree Construction: Guttman, 1984 Partitionnement Top-down ou Bottom-up Rectangles englobant minimum de groupements d’objets A chaque niveau: regroupe les rectangles proches et calcule le rectangle minimum englobant Query processing: Branch and bound standard Insertions/Suppressions: similaire à un B-tree
R-Tree Construction: Guttman, 1984 Partitionnement Top-down ou Bottom-up Rectangles englobant minimum de groupements d’objets A chaque niveau: regroupe les rectangles proches et calcule le rectangle minimum englobant Query processing: Branch and bound standard Insertions/Suppressions: similaire à un B-tree
R-Tree
Construction: Guttman, 1984
Partitionnement Top-down ou Bottom-up
Rectangles englobant minimum de groupements d’objets
A chaque niveau: regroupe les rectangles proches
et calcule le rectangle minimum englobant
Alexis Joly (INRIA) Sim Search January 21, 2021 11 / 47R-Tree
Construction: Guttman, 1984
Partitionnement Top-down ou Bottom-up
Rectangles englobant minimum de groupements d’objets
A chaque niveau: regroupe les rectangles proches
et calcule le rectangle minimum englobant
Query processing:
Branch and bound standard
Insertions/Suppressions: similaire à un B-tree
Alexis Joly (INRIA) Sim Search January 21, 2021 11 / 47Structures basées sur des arbres (1980-2000) !
Sphere Rectangle Tree k-d-B tree
Geometric near-neighbor access tree Excluded middle vantage point
forest mvp-tree Fixed-height fixed-queries tree
Vantage-point tree R∗ -tree Burkhard-Keller tree BBD tree
Voronoi tree Balanced aspect ratio tree Metric tree vps -tree M-tree
SS-tree R-tree Spatial approximation tree Multi-vantage point tree
Bisector tree mb-tree
Generalized hyperplane tree Hybrid tree Slim
tree Spill Tree Fixed queries tree X-tree k-d tree Balltree
Quadtree Octree
SR-tree Post-office tree
Alexis Joly (INRIA) Sim Search January 21, 2021 12 / 47Malédiction la dimension
Weber et al. [1] ont montré en 1998 que les structures d’indexation
étaient moins efficaces que la recherche exhaustive pour des
dimensions supérieures à d ≈ 10
Lorsque la dimension de l’espace devient très grande il faut parcourir
toutes les cellules de la partition pour être sûr de retrouver les k-nn
exacts
c visiondummy.com
Alexis Joly (INRIA) Sim Search January 21, 2021 13 / 47Approximate Similarity Search
En grande dimension, on utilise des techniques approximatives
On cherche à retourner un pourcentage α des vrais voisins (avec ou
sans contrôle de qualité)
La quasi totalité des méthodes de l’état utilise une ou plusieurs des
étapes suivantes:
Réduction de la dimension (changement d’espace)
Compression (quantification avec perte)
Partitionnement de l’espace (structures d’indexation)
Algorithmes de recherche approximative
Alexis Joly (INRIA) Sim Search January 21, 2021 14 / 47VA-file (Weber et al. [1], 1998)
Recherche exhaustive dans un fichier d’approximations des vecteurs
(Vector-Approximation file).
x[j]−t
1 Quantification scalaire de chaque composante: z[j] = b sj j c t.q.
z[j] ∈ J0; 2bj −1 K et le nombre total de bits vaut b = j bj . Avec une
P
distribution uniforme des xi ∈ X , on a une probabilité de collision
Pr [∃xi , xj |zi = zj ] = 1 − (1 − 2−b )N−1 ≈ 2Nb très faible
2 Recherche: (i) on parcours exhaustivement les zi et on filtre avec
d(zq , zi ), (ii) on raffine sur les éléments restant en calculant d(q, xi ).
De 2 à 10 fois plus rapide qu’un scan exhaustif.
Alexis Joly (INRIA) Sim Search January 21, 2021 15 / 47Hamming embedding (Jegou et al. [2], 2008)
1 Partitionnement de l’espace = k-means (x ∈ Rd → g (x) ∈ J1; MK)
Structure d’indexation = liste inversée de clé g (x)
2 Réduction de la dimension = projection dans un espace orthogonal
aléatoire de dimension b
z = Ax avec z ∈ Rb
A ∈ Rbxd matrice orthogonale construite par décomposition QR d’une
matrice aléatoire B ∈ Rdxd (loi normale).
3 Quantification binaire h(x) = sign(Ax − µg (x) ) (µ = médiane)
4 Recherche exhaustive de tous les xi ∈ X t.q. g (x) = g (q) en utilisant
la distance de Hamming comme métrique σ(q, xi ) = −h(q) ⊕ h(xi )
Alexis Joly (INRIA) Sim Search January 21, 2021 16 / 47Extension avec Product Quantization (Jegou et al. [3])
Partitionnement de l’espace = k-means dans L sous espaces
x ∈ Rd → g (x) = (g1 (x), ..., gL (x)) ∈ J1; mKL
On peux créer des partitions de très grande taille sans problème de
temps d’encodage ou d’espace mémoire (e.g. 2568 ≈ 1019 régions)
Recherche avec un assignement multiple: on recherche dans les
régions voisines de g (x) en prenant les centroid voisins.
Alexis Joly (INRIA) Sim Search January 21, 2021 17 / 47Billion-scale similarity search with GPUs
Une implémentation GPU ultra-efficace du Product Quantization offre
les meilleures performances de l’état de l’art (Johnson et al. [4], 2019).
Exemple: N=1B vectors, d = 1024 (CNN features), temps de
recherche=0.0133 ms (10K x plus rapide que méthode naïve CPU)
Inconvénient: pas de contrôle de qualité sur la recherche.
Alexis Joly (INRIA) Sim Search January 21, 2021 18 / 47Focus sur LSH (Locality Sensitive Hashing)
Définition de LSH selon Indyk & Motwani [5] (1998).
Famille de fonctions de hachage locality-sensitive
Une famille de fonction H associée à une distribution de probabilité DH est
dite (c, r , P1 , P2 )-locality-sensitive avec c > 1, P1 ∈ [0, 1], P2 ∈ [0, 1] si
∀x, q ∈ U, h tirée aléatoirement dans H on a:
Si d(q, x) ≤ r alors PrH [h(q) = h(x)] ≥ P1
Si d(q, x) ≥ cr alors PrH [h(q) = h(x)] ≤ P2 < P1
Remarque: pour une mesure de similarité σ(q, x), il faut inverser les
inégalités de gauche.
Alexis Joly (INRIA) Sim Search January 21, 2021 19 / 47Focus sur LSH (Locality Sensitive Hashing)
Définition alternative (Charikar [6], 2002), plus restrictive:
Pour certaines fonctions de hâchage sensible à la localité, la
probabilité de collision peux s’exprimer directement comme une
fonction strictement décroissante avec d(q, x):
PrH [h(q) = h(x)] = φ(d(q, x)) avec φ0 (x) < 0
Alexis Joly (INRIA) Sim Search January 21, 2021 20 / 47Focus sur LSH (Locality Sensitive Hashing)
Exemple: LSH sensible à la "distance" cosinus
Fonction de hâchage: hw (x) = sign(w T x) avec w ∈ Rd variable
aléatoire de distribution p(w ) = N (0, I )
On peux montrer que la fonction de sensibilité est ∀q, v ∈ Rd :
T
1 −1 q x 1
PrH [h(q) = h(x)] = 1 − cos = 1 − d(q, x)
π kqkkxk π
Alexis Joly (INRIA) Sim Search January 21, 2021 21 / 47Focus sur LSH (Locality Sensitive Hashing)
De nombreuses familles de fonction de hâchage existent dans la littérature:
LSH for lp norms based on p-stable distributions (Datar et al. [7],
2004)
MiHash (Broder [8], 1997): LSH for Jacard distance
(d(Q, X ) = |Q ∩ X | /|Q ∪ X |) based on random permutations and
min index in the set.
LSH for Hamming distance based on random bit sampling (Indyk &
Motwani [5], 1998)
Kernalized LSH (Kulis & Grauman [9], 2009): for any kernel
κ(q, x) = Φ(q)> Φ(x) (random hyperplanes + kernel trick)
Alexis Joly (INRIA) Sim Search January 21, 2021 22 / 47Focus sur LSH (Locality Sensitive Hashing)
Construction d’un index de L tables avec LSH
Fonction de hachage multidimensionnelle: g (x) = (h1 (x), . . . , hk (x))
1 Choisir aléatoirement L fonctions de hachage composée de k
composantes chacune
2 Hacher chaque x ∈ S dans les L "cases" g1 (x), . . . , gL (x)
Taille de l’index: O(LN)
Alexis Joly (INRIA) Sim Search January 21, 2021 23 / 47Focus sur LSH (Locality Sensitive Hashing)
Recherche d’un vecteur requête q
1 Calculer les L clés g1 (q), . . . , gL (q)
2 Aller aux cases correspondantes et retourner les objets contenus xj
3 En pratique: vérifier explicitement d(q, xj ) ≤ r ou recherche des K
plus proches voisins
Temps de recherche est O(L)
Alexis Joly (INRIA) Sim Search January 21, 2021 24 / 47Focus sur LSH (Locality Sensitive Hashing)
Contrôle de la qualité de la recherche
Probabilité de collision (rappel):
PrH [h(q) = h(x)] = φ(d(q, x)) = φ(r )
Probabilité de collision dans une table de k bits:
PrH [g (q) = g (x)] = φ(r )k (très faible)
Probabilité de non collision dans une table:
PrH [g (q) 6= g (x)] = 1 − φ(r )k
Probabilité de non collision dans L tables: L
PrH [g1 (q) 6= g1 (x), ..., gL (q) 6= gL (x)] = 1 − φ(r )k
Probabilité de collision dans au moins une table = pourcentage des
voisins réels retrouvés):
L
α = 1 − 1 − φ(r )k (élevée pour r petit)
Alexis Joly (INRIA) Sim Search January 21, 2021 25 / 47Focus sur LSH (Locality Sensitive Hashing)
Contrôle de la qualité de la recherche
Phénomène d’amplification, exemple de LSH sensible à la distance cosinus
(k = 4 bits, L = 4 tables):
Alexis Joly (INRIA) Sim Search January 21, 2021 26 / 47Focus sur LSH (Locality Sensitive Hashing)
Contrôle de la qualité de la recherche
Si on veux retrouver α∗ (e.g 95%) des x ∈ X tels que d(q, x) < r , il
faut: L log(1−α∗ )
α = 1 − 1 − φ(r )k > α∗ soit L > log(1−φ(r )k )
D’un autre côté, le nombre de bits k permet de contrôler le nombre de
collisions des points éloignés:
E(|{x ∈ X |d(q, x) > cr , g (q) = g (x)} |) = Nφ(cr )k
Si on veux que ce nombre n’augmente pas avec N, on peux imposer
que:
Nφ(cr )k = 1 soit k = log( N1 )/log(φ(cr ))
log φ(r )
log(1−α∗ )
En combinant, on obtient: L > log φ(r ) ≈ α∗ N log φ(cr )
log(1− N1 log φ(cr ) )
log φ(r )
Complexité sous linéaire: O(L) = O(N ρ ) avec ρ = log φ(cr )Focus sur LSH (Locality Sensitive Hashing)
Dans la cas de la définition générale:
Si d(q, x) ≤ r alors PrH [h(q) = h(x)] ≥ P1
Si d(q, x) ≥ cr alors PrH [h(q) = h(x)] ≤ P2 < P1
log(P1 )
Notation: ρ = log(P2 )Focus sur LSH (Locality Sensitive Hashing)
Rappel: Recherche d’un vecteur requête q
1 Calculer les L clés g1 (q), . . . , gL (q)
2 Aller aux cases correspondantes et retourner les objets contenus xj
3 Vérifier explicitement d(q, xj ) ≤ r (ou rKNN )
On peux accélérer la 3ème étape en remplaçant le calcul des d(q, xj ) par
dHamming (g (q), g (xj )):
indexation: on remplace les xi par leur hcode g (xi ) dans les tables
(e.g. b bits au lieu de d float).
recherche: on vérifie dHamming (g (q), g (xj )) ≤ rH ou recherche des K
plus proches voisins selon dHamming .
Alexis Joly (INRIA) Sim Search January 21, 2021 29 / 47Focus sur LSH (Locality Sensitive Hashing)
Avantages de remplacer d(q, xj ) par dHamming (g (q), g (xj )) :
g (x)=hashcode compact de b bits (vs. d × 4 × 8 bits pour x en
précision float)
Moins de sortie de caches mémoires à tous les niveaux
Implémentations très efficace de la distance de Hamming (e.g.
popcount, GPU, etc.).
Alexis Joly (INRIA) Sim Search January 21, 2021 30 / 47Focus sur LSH (Locality Sensitive Hashing)
dHamming (g (q), g (xj )): b épreuves de Bernouilli de probabilité
PrH [h(q) 6= h(x)] = 1 − φ(d(q, xj ))
dHamming (g (q), g (xj ))/b est un estimateur non biaisé de
1 − φ(d(q, xj )) (de variance (1 − φ(d(q, xj )))φ(d(q, xj )/b)
Si la fonction de sensibilité φ est inversible on peux construire un
estimateur non biaisé de d(q, xj ) par:
ˆ xj ) = φ−1 1 − dHamming (g (q), g (xj ))
d(q,
b
Pour la recherche à un rayon près on utilise:
ˆ xj ) < r ⇔ dHamming (g (q), g (xj )) < b(1 − φ(r ))
d(q,
Pour la recherche de K plus proches voisins, on peux trier en fonction
de dHamming (g (q), g (xj ))
Alexis Joly (INRIA) Sim Search January 21, 2021 31 / 47Focus sur LSH (Locality Sensitive Hashing)
Exemple: LSH sensible à la "distance" cosinus
Fonction de hâchage: hw (x) = sign(w > x) avec w ∈ Rd variable
aléatoire de distribution p(w ) = N (0, I )
Distance de Hamming entre deux hashcode de dimension
> b:
q x
EH [dHamming (g (q), g (x))] = πb cos −1 kqkkxk
Alexis Joly (INRIA) Sim Search January 21, 2021 32 / 47Focus sur LSH (Locality Sensitive Hashing)
Au delà de la recherche par similarité, on peux approximer tout classifieur
linéaire (Ouertani et al. [10], 2012) pour accélérer l’inférence.
Restriction: x ∈ Rd , kxk= 1
Fonction de hachage h(x) = sign(w > x), g (x) = (h1 (x), ..., hb (x))
Theorem
Tout classifieur linéaire f (x) = sign(ω > x + γ) peut être approximé par un
classifieur discrétisé fˆ(x) tel que:
fˆ(x) = sgn (rω,b− dHamming
(g (x), g (ω)))
γ
rω,γ = Dπ cos −1 kωk (1)
lim ĥ(x) = h(x)
b→∞
Remarque: extension possible à tout noyau avec KLSH (kernel trick)
Alexis Joly (INRIA) Sim Search January 21, 2021 33 / 47Focus sur LSH (Locality Sensitive Hashing)
Limitation de LSH:
La fonction de hachage ne dépend pas des données.
LSH peut conduire à des partitions loin de l’uniformité. Certaines
cases peuvent concentrer presque tous les points:
Augmentation du nombre de fausses collisions et du temps de filtrage
(étape 3 de la recherche)
Problématique dans les contexte distribués (load balancing)
Alexis Joly (INRIA) Sim Search January 21, 2021 34 / 47Focus sur LSH (Locality Sensitive Hashing)
Random Maximum Margin Hashing (Joly & Buisson [11], 2011), utilisé
dans Pl@ntNet.
Apprentissage de partitionnements aléatoires balancés hm (x):
Selectionner M échantillons xi aléatoirement
Labélliser la moitié avec yi = +1, la moitié avec yi = −1
> x + b ) avec
Apprendre un classifieur binaire, e.g. hm (x) = sign(wm m
1 2 >
wm , bm = arg minw ,b 2 kw k sous contraintes yi (w x + b) ≥ 1
Alexis Joly (INRIA) Sim Search January 21, 2021 35 / 47Apprentissage de fonctions de hâchage
De nombreux travaux de la littérature (>2007) proposent d’apprendre la
(ou les) fonction(s) de hachage à partir des données:
g (x) = (h1 (x), ..., hb (x)) = arg min L(gθ (x), X )
θ
La fonction objectif peut contenir un ou plusieurs termes dépendant des
propriétés recherché:
préservation de la distance d’origine, de l’inégalité triangulaire, du
ranking, des knn, etc.
indépendance ou orthogonalité des hi (x)
erreur de quantification / compacité de g (x)
"A survey on learning to hash" par Wang et al. [12] (2017).
Alexis Joly (INRIA) Sim Search January 21, 2021 36 / 47Apprentissage de fonctions de hâchage Alexis Joly (INRIA) Sim Search January 21, 2021 37 / 47
Apprentissage de fonctions de hâchage
Exemples:
Avec une ACP, simple mais efficace:
g (x) = sign(Ax − µ) avec µ médiane de chaque composante
Problème: les bits sont de moins en moins informatifs
ITQ (Gong et al. [13], 2012) = ACP + une rotation additionelle afin
de minimiser l’erreur de quantification
Spectral hashing (Weiss et al. [14], 2008) = relaxation du problème
NP-completP suivant:
minimize i,j σ(xi , xj )kg (xi ) − g (xj )k= trace(G(D − Σ)G> )
subject to (a) gP (xi ) ∈ {−1, 1}b
(b) i g (xi ) = 0
1 P
(c) N i g (xi )g (xi )> = I
Oublier (a) permet de trouver une solution facilement avec les
fonctions propres Laplaciennes.
Alexis Joly (INRIA) Sim Search January 21, 2021 38 / 47Apprentissage profond de fonctions de hâchage
Supervised pairwise image-based deep learning, e.g. Liu et al. [15] (2016),
avec σ(q, x) ∈ {0, 1} (similar or dissimilar):
L(gθ (q), gθ (x), σ(q, x)) =
σ(q, x)kgθ (q) − gθ (x)k22 similar pairs
+ (1 − σ(q, x))max(m − kgθ (q) − gθ (x)k22 , 0) dissimilar pairs
+ λ (k|gθ (q)|−1k1 +kgθ (x)|−1k1 ) relaxed binarization
Alexis Joly (INRIA) Sim Search January 21, 2021 39 / 47Apprentissage profond de fonctions de hâchage
Unsupervised Similarity-Adaptive Deep Hashing (Shen et al. [16], 2018):
Start with fθ (x)= CNN pré-entrainé
Repeat for t ∈ J0; T K:
Etape 2: Calculer S avec sij = σ(fθ (xi ), f θ(xj )) (e.g. RBF kernel)
Etape 3: Optimiser hashcodes G = (g (x1P ), ..., g (xn )) via ADMM
Etape 1: Apprendre CNN en minimisant i ktanh(fθ (xi )) − g (xi )k22
Alexis Joly (INRIA) Sim Search January 21, 2021 40 / 47Apprentissage profond de fonctions de hâchage
Unsupervised Similarity-Adaptive Deep Hashing (Shen et al. [16], 2018)
Très efficace pour des petits hash codes (e.g. pour construire une table).
LSH reste très compétitif pour des hash codes plus longs (e.g. 1024-bit pour
approximer le calcul de la distance d’origine avec un rappel élevé).
Alexis Joly (INRIA) Sim Search January 21, 2021 41 / 47Conclusion
Recherche exacte:
Pour d < 10, utilisation de structures d’indexation classiques (R-tree,
M-tree, KD-tree, etc.)
Pour d ≥ 10, recherche exhaustive
Recherche Approximative:
Fonctions de hâchage apprises ou PQ-code pour construire les tables
(e.g. 16-bits ou 32-bits)
Projections aléatoires ou PCA-like pour approximer la distance (e.g.
128-bits, 256-bits ou 1024-bits)
Seul LSH a des garanties théoriques et converge vers la distance exacte
Pour les autres méthodes, on peux cross-valider les hyper-paramètres
de la recherche sur un ensemble de validation (e.g. a posteriori
multiprobe LSH Joly & Buisson [17]).
Alexis Joly (INRIA) Sim Search January 21, 2021 42 / 47The End
MERCI DE VOTRE ATTENTION
Alexis Joly (INRIA) Sim Search January 21, 2021 43 / 47References I
Weber, R., Schek, H.-J. & Blott, S. A quantitative analysis and
performance study for similarity-search methods in high-dimensional
spaces. in VLDB 98 (1998), 194–205.
Jegou, H., Douze, M. & Schmid, C. Hamming embedding and weak
geometric consistency for large scale image search. in European
conference on computer vision (2008), 304–317.
Jegou, H., Douze, M. & Schmid, C. Product quantization for nearest
neighbor search. IEEE transactions on pattern analysis and machine
intelligence 33, 117–128 (2010).
Johnson, J., Douze, M. & Jégou, H. Billion-scale similarity search
with GPUs. IEEE Transactions on Big Data (2019).
Indyk, P. & Motwani, R. Approximate nearest neighbors: towards
removing the curse of dimensionality. in Proceedings of the thirtieth
annual ACM symposium on Theory of computing (1998), 604–613.
Alexis Joly (INRIA) Sim Search January 21, 2021 44 / 47References II
Charikar, M. S. Similarity estimation techniques from rounding
algorithms. in Proceedings of the thiry-fourth annual ACM
symposium on Theory of computing (2002), 380–388.
Datar, M., Immorlica, N., Indyk, P. & Mirrokni, V. S.
Locality-sensitive hashing scheme based on p-stable distributions. in
Proceedings of the twentieth annual symposium on Computational
geometry (2004), 253–262.
Broder, A. Z. On the resemblance and containment of documents. in
Proceedings. Compression and Complexity of SEQUENCES 1997
(Cat. No. 97TB100171) (1997), 21–29.
Kulis, B. & Grauman, K. Kernelized locality-sensitive hashing for
scalable image search. in 2009 IEEE 12th international conference on
computer vision (2009), 2130–2137.
Alexis Joly (INRIA) Sim Search January 21, 2021 45 / 47References III
Ouertani, S. L., Joly, A. & Boujemaa, N. Hash-based support vector
machines approximation for large scale prediction. in BMVC (2012).
Joly, A. & Buisson, O. Random maximum margin hashing. in CVPR
2011 (2011), 873–880.
Wang, J., Zhang, T., Sebe, N., Shen, H. T., et al. A survey on
learning to hash. IEEE transactions on pattern analysis and machine
intelligence 40, 769–790 (2017).
Gong, Y., Lazebnik, S., Gordo, A. & Perronnin, F. Iterative
quantization: A procrustean approach to learning binary codes for
large-scale image retrieval. IEEE transactions on pattern analysis and
machine intelligence 35, 2916–2929 (2012).
Weiss, Y., Torralba, A. & Fergus, R. Spectral hashing. Advances in
neural information processing systems 21, 1753–1760 (2008).
Alexis Joly (INRIA) Sim Search January 21, 2021 46 / 47References IV
Liu, H., Wang, R., Shan, S. & Chen, X. Deep supervised hashing for
fast image retrieval. in Proceedings of the IEEE conference on
computer vision and pattern recognition (2016), 2064–2072.
Shen, F. et al. Unsupervised deep hashing with similarity-adaptive and
discrete optimization. IEEE transactions on pattern analysis and
machine intelligence 40, 3034–3044 (2018).
Joly, A. & Buisson, O. A posteriori multi-probe locality sensitive
hashing. in Proceedings of the 16th ACM international conference on
Multimedia (2008), 209–218.
Alexis Joly (INRIA) Sim Search January 21, 2021 47 / 47Vous pouvez aussi lire