Wiki Informatique Approche sémantique et ontologique - Université Paris 8 MASTER 2 THYP
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Université Paris 8 Année Universitaire: 2005 - 2006
MASTER 2 THYP
Rapport de stage à l’Université Paris 8
Wiki Informatique
Approche sémantique et ontologique
Présenté par Gérald KEMBELLEC
N° d’étudiant 19099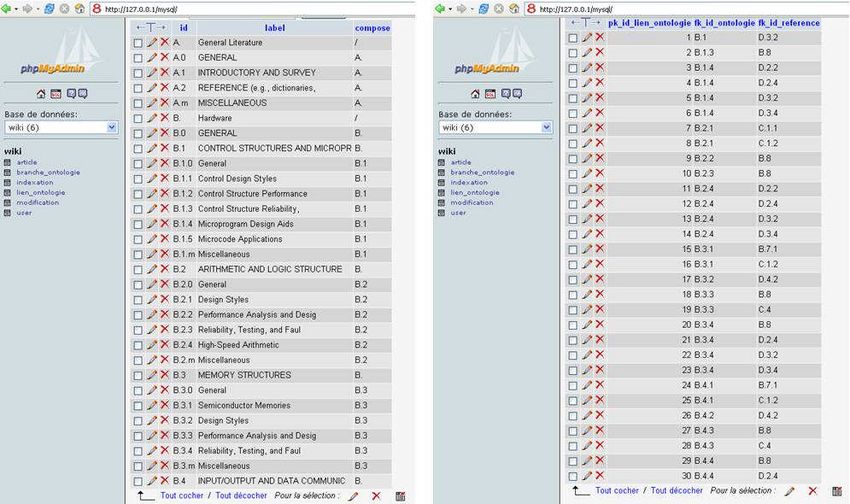
Remerciements :
Je tiens tout parti culi èreme nt à remer cier le Professeur Imad SALEH pour m’avoir
orienté dans les domaines ontologiques et sémantiques avec bienveillance et patience.
Mes remer cieme nts s'ad ress ent à Monsieur Nasser BOUHAI pour son aide précieuse en
début de stage et ses conseils sur les concepts travaillés au cours de ce stage, mais aussi son
aide morale pour surmonter le stress et le découragement. Son enseignement notamment en
PHP et base de données tout au long de l’année fut une des matières premières de la
réalisation de ce wiki.
J’adresse mes remer cieme nts à Bernhard RIEDER pour ses conseils avisés en milieu et
fin de stage, l’excellence de ses cours de Javascript et AJAX sans lesquels une bonne partie de
la programmation du wiki aurait été impossible.
J'aime rais remerci er également à Monsieu r Jean MEHAT de m’avoir demander créer un
wiki pour le département informatique comme support collaboratif de son cours, ce qui m’a
permis de faire mon stage professionnel de fin de MASTER sur mon lieu de travail, sans quoi
rien n’aurait été possible.
Merci également à Monsieur Vincent BOYER qui a pris le temps de lire ce rapport et
de donner son avis tant sur son fond que sur sa forme.
Un grand merci aussi à mon collègue et ami Raoul KUCZYK de m’avoir supporté
durant ma période de stage durant laquelle mes études empiétaient sur mon travail
professionnel.
Je remercie Damien LEGOUAIS qui m’a aidé dans mes recherches documentaires et
dans la modélisation du projet.
Je ne dois pas oublier de remercier tous les étudiants du département informatique qui
ont souffert de mon manque de disponibilité de juin à septembre.
Bien sur je ne peux terminer ces remerciements sans remercier ma fiancée Kim qui a
vécu ces quelques mois au même rythme que moi, dans le stress et quasiment sans vacances,
son aide morale m’a été vitale.
3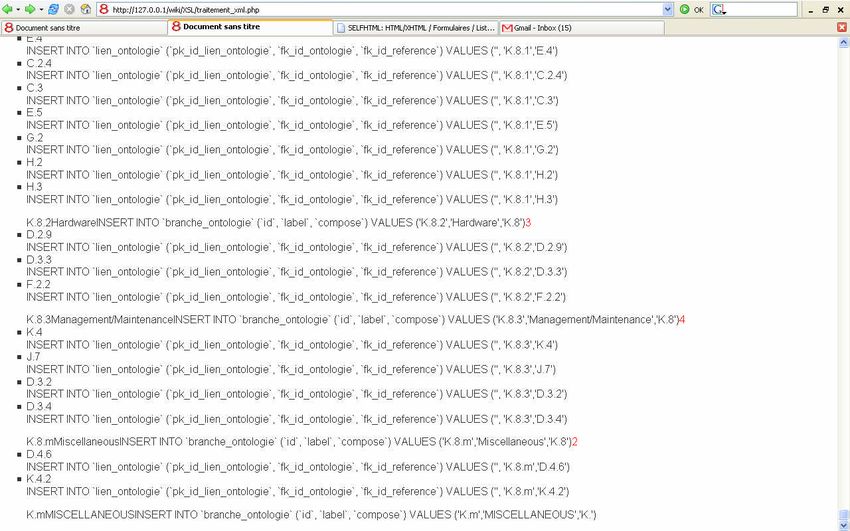
Table des matières
Remerciements : .........................................................................................................................3
Table des matières ......................................................................................................................4
Table des figures ....................................................................................................................7
Table équations ......................................................................................................................8
Table des tableaux ..................................................................................................................8
Introduction ................................................................................................................................9
Introduction ................................................................................................................................9
Plan de lecture .........................................................................................................................10
Contexte du stage .................................................................................................................11
Contexte du stage .................................................................................................................11
Présentation de l’Université Paris 8 : ...............................................................................11
Quelques éléments de définitions relatives au projet : .........................................................13
Le Wiki :...........................................................................................................................13
Le web sémantique :.........................................................................................................14
L’Ontologie informatique : ..............................................................................................14
Moteur d’inférence : .........................................................................................................15
Système expert : ...............................................................................................................15
Matériel et logiciels utilisés : ...................................................................................................16
Ordinateur de développement et test : .................................................................................16
Serveur dédié .......................................................................................................................16
DIA :.....................................................................................................................................16
Analyse SI : ..........................................................................................................................16
EasyPHP :.............................................................................................................................16
Médiawiki : ..........................................................................................................................16
Macromédia Dreamweaver : ................................................................................................16
Avant Projet..............................................................................................................................17
Historique du projet ..............................................................................................................17
Objectif .................................................................................................................................17
La cible .................................................................................................................................17
Valeur ajoutée ......................................................................................................................17
Contraintes techniques .........................................................................................................17
Risques à ne pas faire le wiki ...............................................................................................17
Risques à faire le site ............................................................................................................18
Risques inhérents au projet ..................................................................................................18
Contraintes d’enchaînement de tâches .................................................................................18
Cahier des charges ................................................................................................................19
I. Modélisation du wiki : ..........................................................................................................21
I.1. La méthode UML :.........................................................................................................21
I.1.1. Le diagramme de classes : ......................................................................................21
I.1.2. Le diagramme de cas d’utilisation ou use-case :.....................................................22
I.1.3. Le diagramme de composants :...............................................................................23
I.1.4. Le diagramme de déploiement :..............................................................................24
I.1.5. Le diagramme d’états/transitions : ..........................................................................25
I.1.6. Le diagramme de séquence .....................................................................................26
I.1.7. Le diagramme de collaboration : ............................................................................26
Conclusion de la modélisation UML: ..............................................................................28
I.2. La méthode Merise : ......................................................................................................29
4
I.2.1. L’étude préalable : ..................................................................................................29
I.2.2. Le dictionnaire des données :..................................................................................30
I.2.3. Modèle conceptuel des données..............................................................................31
I.2.4. Modèle logique des données ...................................................................................32
I.2.5. Fonctionnement du système ....................................................................................33
I.2.6. Diagramme Acteurs flux .........................................................................................34
I.2.7. Modèle conceptuel des traitements .........................................................................35
I.2.8. Conclusion de la modélisation Merise et conclusion générale de la modélisation du
projet.................................................................................................................................36
I.3. Etude préalable des options techniques .........................................................................37
I.3.1. Choix entre développement et création...................................................................37
I.3.1.Option 1 : Modification d’un wiki existant..............................................................38
I.3.2 Option 2 : création complète d’un wiki ...................................................................39
I.4.Conclusion de l’étude préalable du wiki .........................................................................40
II Le développement du wiki ...................................................................................................41
II Le développement du wiki ...................................................................................................41
II.1 La création de l’interface graphique ..............................................................................41
II.2.L’intégration de la base de données ..........................................................................44
II.3.L’accueil de l’utilisateur ................................................................................................45
II.3.1 Gestion du login et de la session ............................................................................45
II.3.2 Gestion des droits en fonction du login ..................................................................48
II.4 Le référencement simplifié des articles .........................................................................49
II.4.1 Le principe de l’indexation mixte ...........................................................................49
II.4.2 La visualisation contextuelle des mots clés ............................................................50
II.5 Recherche d’articles ......................................................................................................51
II.5 Recherche d’articles ......................................................................................................51
II.5.1 Un moteur de recherche simple par mot clé ...........................................................51
II.5.2 Un moteur de recherche en langage naturel simplifié ............................................52
II.6.Création et édition d’articles..........................................................................................54
II.6.1 Rédaction d’un article .............................................................................................54
II.6.2.Confirmation de création d’article ..........................................................................55
II.6.2 Edition et modification d’un article........................................................................56
II.7 Application web sémantique : Le flux RSS...................................................................57
II.7.1 Le principe du flux RSS .........................................................................................57
II.7.2 La mise en œuvre de RSS.......................................................................................58
II.7.3 L’exploitation des fils RSS par les étudiants ..........................................................59
II.8 Plan du wiki ...................................................................................................................61
II.8 Plan du wiki ...................................................................................................................61
II.9 Conclusion de la création du wiki .................................................................................62
III. Etude d’une ontologie informatique ...................................................................................63
III. Etude d’une ontologie informatique ...................................................................................63
III.1 Etude des structures approchantes du concept d’ontologie .........................................63
III.1.1 Etude de deux portails qui peuvent s’apparenter à la représentation graphique
d’une ontologie informatique : .........................................................................................63
III.1.2.Deux systèmes d’ontologie couvrant le domaine informatique ............................66
III.1.3.Conclusion de l’étude l’ontologie informatique ....................................................67
III.2. Interfacer une Ontologie avec un navigateur ..................................................................68
III.2.1.Lecture du fichier XML par le navigateur.............................................................68
III.2.1.Traitement XSL du fichier XML pour l’affichage par le navigateur ....................69
III.2.3.Traitement du fichier XML en XSLT par Sablotron.............................................71
5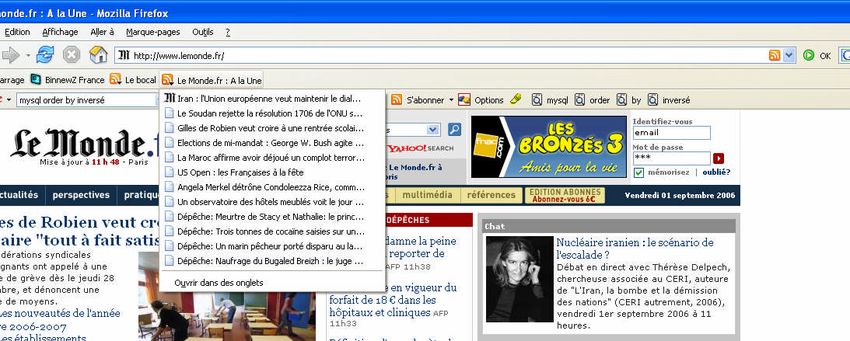
III.3.Les deux méthodes de référencement ontologique d’un article ...................................74
III.3.1.L’indexation manuelle d’un article dans une ontologie ........................................74
III.3.2.L’indexation automatique d’un article dans une ontologie ...................................74
III.4.La recherche grâce à l’ontologie ..................................................................................75
III.4.1.Reherche directe en langage naturel......................................................................75
III.4.2.Champs lexicaux et sémantiques...........................................................................75
III.5.Conclusion de l’étude d’une ontologie informatique ...................................................75
IV. Le moteur sémantique d’indexation et de recherche..........................................................76
IV.1. Choix d’une méthode d’indexation .............................................................................76
IV.2. L‘indexation mixte ......................................................................................................76
IV.2.1. L'analyse du texte .................................................................................................77
IV.2.2.Pondération des mots clés .....................................................................................77
IV.3.Conclusion du moteur d’indexation .............................................................................81
Optimisation du code et migration du projet ............................................................................82
Perspectives d’évolution ..........................................................................................................83
Conclusion :..............................................................................................................................84
Bibliographie ............................................................................................................................86
Sources en ligne : .................................................................................................................86
Sources papier ......................................................................................................................86
Annexes ....................................................................................................................................87
Mots clés ..................................................................................................................................94
6
Table des figures
Figure 1 Diagramme de classes ................................................................................................21
Figure 2 diagramme de cas d'utilisation ...................................................................................22
Figure 3 Diagramme de composants ........................................................................................23
Figure 4 Diagramme de déploiement .......................................................................................24
Figure 5 Diagramme état transition ..........................................................................................25
Figure 6 Diagramme de séquence ............................................................................................26
Figure 7 Diagramme de collaboration ......................................................................................27
Figure 8 M.C.D ........................................................................................................................31
Figure 9 MLD...........................................................................................................................32
Figure 10 Diagramme acteurs / flux .........................................................................................34
Figure 11 M.C.T .......................................................................................................................35
Figure 12 Exemple de réalisation d'un wiki avec médiawiki ...................................................37
Figure 13 L'éditeur de médiawiki.............................................................................................38
Figure 14 Création de l'interface avec dreamweaver ...............................................................41
Figure 15 Détail d'intégration d'une icône logo dans la barre de navigation. ..........................42
Figure 16 Evolutions des sources du bouton ............................................................................42
Figure 17 Affichage des boutons sans les images ....................................................................42
Figure 18 affichage des boutons en condition normale............................................................43
Figure 19 Login et mot de passe ..............................................................................................45
Figure 20 Aide contextuelle à la compréhension des droits utilisateurs ..................................45
Figure 21 Gestion des droits.....................................................................................................48
Figure 22 Exemple de code tenant compte des niveaux d'utilisateur .......................................48
Figure 23 Affichage contextuel des mots clés .........................................................................50
Figure 24 Détail sur le résultat d'une recherche simple ...........................................................51
Figure 25 Cas de résultat négatif à une recherche ....................................................................51
Figure 26 Affichage verbeux (mode de debbugage) d'une recherche en langage naturel........52
Figure 27 Représentation schématique d'une requête ..............................................................52
Figure 28 Création d'un article .................................................................................................54
Figure 29 confirmation de la création d'article et chois de mots clés ......................................55
Figure 30 Edition d'un article ...................................................................................................56
Figure 31 Flux RSS du site du journal 'LE MONDE' ..............................................................57
Figure 32 S'incrire à un fil RSS................................................................................................59
Figure 33 Détail d'utilisation de RSS .......................................................................................59
Figure 34 Flux RSS à Copier dans le logiciel de News ...........................................................60
Figure 35 Lecture du fil RSS du wiki du bocal dans GreatNews ............................................60
Figure 36 Représentation du wiki ............................................................................................61
Figure 37 Portail Wikipédia .....................................................................................................63
Figure 38 Portail "Comment ça marche?" ................................................................................64
Figure 39 Affichage de l'ontologie en xml sans traitement......................................................68
Figure 40 Feuille de style XSL de l'ontologie ..........................................................................69
Figure 41 Affichage de l'ontologie Informatique avec traitement xsl......................................70
Figure 42 Chargement de l'ontologie et de sa feuille de style avec traitement php intégrée ...71
Figure 43 Traitement mixte XSLLT / PHP avec Sablotron .....................................................72
Figure 44 Gestion globale du traitement d'extraction XML vers SQL via XSLT ...................72
Figure 45 Intégration automatisée de l'ontologie dans une base de données ...........................73
Figure 46 Tables Noeud de l'ontologie et Association ............................................................73
Figure 47 Fichier de configuration du wiki ..............................................................................82
7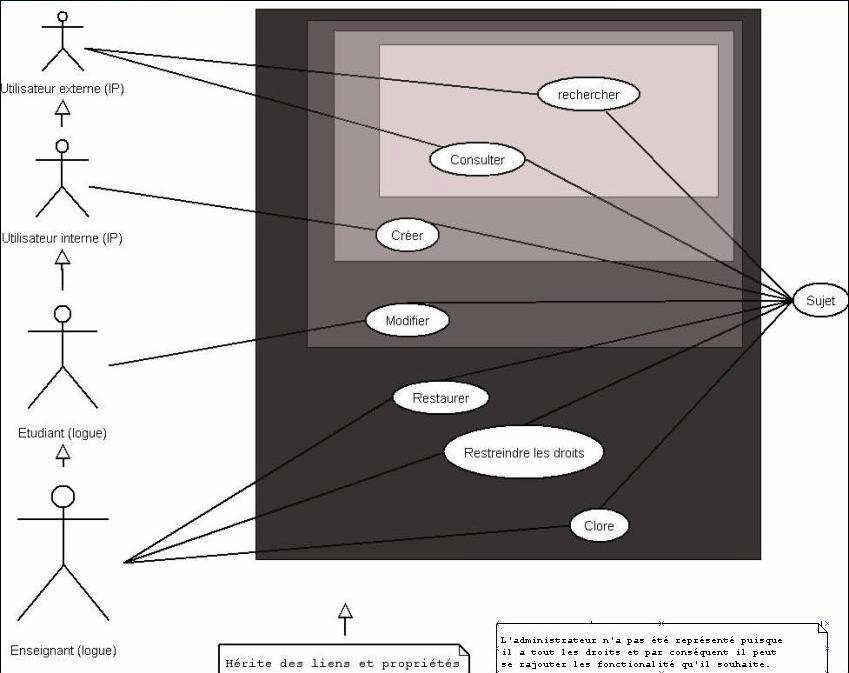
Table équations
Équation 1Calcul du poids d'un mot clé ...................................................................................78
Équation 2 Fréquence d'un mot clé ..........................................................................................78
Équation 3 Algorithme choisi de pondération d'un mot clé .....................................................79
Table des tableaux
Tableau 1 Contrainte d'enchaînement des tâches .....................................................................18
8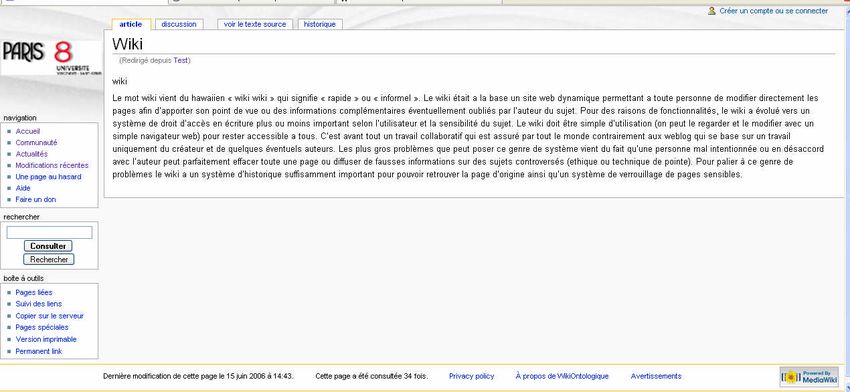
Introduction
Objectifs du stage
Dans ce stage, nous avons réalisé un wiki pour le département informatique de
l’université Paris 8 intégrant un moteur de recherche basé sur le langage naturel. La
motivation de ce stage a été de créer un espace de discussion autour des enseignements pour
les utilisateurs. .
L’ensemble du département doit pouvoir écrire des articles, les compléter, les modifier
ou simplement donner leur opinion. À ce wiki, voulu ontologique, sera associé un moteur de
recherche sémantique permettant de trouver les informations dans le système et de les
restituer sous une forme plus appropriée.
Ce moteur de recherche doit être l’interface d’un moteur d’inférence qui comprenne le
langage naturel, c'est-à-dire que le moteur devait être à même de saisir le sens d’une phrase
humaine et de l’assimiler afin d’en extraire l’essence.
De plus ce même moteur, système expert de notre projet doit être à même de repérer la
ou les cible(s) de la recherche dans un contexte sémantique, c'est-à-dire que les homonymes et
synonymes doivent être gérés ce qui complique notablement la tâche.
Pour rendre le moteur sensible à une recherche sémantique il faut être à même de
synthétiser les articles au sein d’une arborescence de connaissances. C’est ce que nous
appellerons le moteur d’inférence pour l’indexation ontologie qui sera basé sur le même
système expert.
Ce stage professionnel de fin d’études valide le MASTER, il a pour objectif de pré
professionnaliser les étudiants, de les initier au travail dans le monde de l’entreprise. Etant
salarié de l’Université comme administrateur système et réseau, je ne pouvais m’absenter 5 à
6 mois du centre de calcul. J’ai donc effectué ce stage principalement sur mon temps libre et
durant les vacances entre Juin et Septembre 2006.
9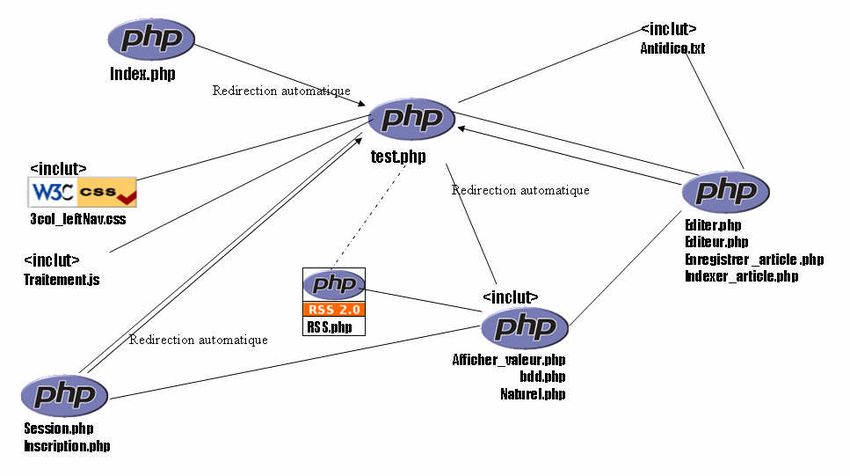
Plan de lecture
Après avoir défini les objectifs du stage, nous allons commencer par présenter le
contexte du stage, c'est-à-dire l’université Paris 8, plus précisément L’UFR6 et le centre de
calcul.
Ensuite nous donnerons quelques éléments de définitions de concepts en relation avec
notre projet. Nous présenterons également le contexte technique du stage, tant matériel que
logiciel.
La suite de ce rapport sera composée d’une partie d’avant-projet et de cahier des
charges, ce qui nous conduira naturellement vers la modélisation du projet et les choix
techniques relatifs qui en découlent.
Nous pourrons à partie de là assister aux étapes de la création du wiki. Nous nous
baserons de notre travail sur le wiki pour adosser le projet d’indexation et de recherche
ontologique et sémantique.
Nous effectuerons une analyse comparative d’éléments d’ontologie, de domaine
informatique pour définir celle qui sera ensuite intégrée au projet pour affiner le
référencement.
Cette analyse nous permettra d’implémenter une ontologie dans le wiki par le biais
d’un traitement PHP/XSLT.
L’étape suivante consiste à réfléchir et à modéliser un système d’indexation mixte
efficace que nous intégrerons au wiki afin d’optimiser le système de recherche sémantique.
Enfin nous expliciterons nos conclusions sur l’ensemble de ce projet en résumant
chaque chapitre.
10
Contexte du stage
Présentation de l’Université Paris 8 :
Historique :
À l’origine l’Université Paris 8 [ P8 ] se trouvait à Vincennes. L’Université était alors
expérimentale au même titre que celle de Paris 9 – Dauphine créée à la même époque dans le
cadre des suites des événements de mai 1968. Elle fut d’emblée gérée selon le principe de
l’autonomie universitaire issue de la loi Edgar Faure à la fin des années 1960. Le département
informatique fut considéré comme très performant dès le départ.
Le site principal de l’Université Paris 8 est situé 2, rue de la liberté à Saint-Denis (93)
depuis son déménagement du site au Bois de Vincennes en 1978. Le domaine public de
l’Université est ouvert librement aux étudiants, aux enseignants, au personnel IATOSS de
l’Université. Les invités et intervenants extérieurs sont autorisés à y pénétrer pour assurer les
fonctions ou les interventions qui nécessitent leur présence.
11L’Unité de recherche et de formation langage, informatique et technologie :
12Quelques éléments de définitions relatives au projet :
Le Wiki :
Le mot wiki vient de l’hawaiien « wiki wiki » qui signifie « rapide » ou « informel ».
Le wiki était à la base un site web dynamique permettant à toute personne de modifier
directement les pages afin d’apporter son point de vue ou des informations complémentaires
éventuellement oubliées par l’auteur du sujet. [WIKI]
Pour des raisons de fonctionnalité, le wiki a évolué vers un système de droit d’accès en
écriture plus ou moins important selon l’utilisateur et la sensibilité du sujet. Le wiki doit être
simple d’utilisation pour rester accessible à tous. C’est avant tout un travail collaboratif qui
est assuré par tout le monde contrairement aux weblogs qui se basent sur un travail
uniquement du créateur et de quelques éventuels auteurs.
En Janvier 2001, une encyclopédie du nom de Wikipédia [WIKIPEDIA] basée sur ce
système a vue le jour. Ce travail collaboratif est réalisé par des volontaires, sur un site Web
utilisant la technologie wiki Wikipédia est libre, grâce à un contenu placé sous la licence de
documentation libre GNU [GNU], souvent abrégée sous la forme GFDL. Le texte de
Wikipédia est modifiable et réutilisable, y compris commercialement, à condition de respecter
les conditions précisées par cette licence. Ce contenu est également gratuit, afin de favoriser
l'accès à la connaissance à un maximum de personnes. En Août 2006, la Wikipédia
francophone compte 351 238 articles et 47 869 fichiers multimédia. Pour l'ensemble des
langues du projet, le nombre d'articles a dépassé les 4 millions.
Nupedia [NUPEDIA] était un projet initié en même temps que Wikipédia qui s’en
distinguait par une politique stricte pour l'intégration des nouveaux articles, le comité
scientifique visant à en faire une encyclopédie de qualité comparable aux encyclopédies
professionnelles sur le marché. Malgré la rareté des contributeurs qui lui fut fatale, Nupedia
été considérée comme plus rigoureuse. Nupedia fut définitivement fermée en septembre 2003.
Au moment où elle cessa ses opérations, 24 articles avaient été intégrés à l'encyclopédie, 3
articles existaient sous une double forme et 74 articles étaient en développement.
Le problème que peut poser ce genre de système vient du fait qu’une personne mal
intentionnée, ignorante ou en désaccord avec l’auteur peut effacer toute une page ou diffuser
de fausses informations. Pour pallier à ce genre de problèmes, le wiki a un système
d’historique pour pouvoir retrouver la page d’origine ainsi qu’un système de verrouillage de
pages sensibles.
13Le web sémantique :
Etymologiquement sémantique vient du grec sem, qui veut dire donner du sens. L’idée
du web sémantique web sémantique est de faire comprendre le langage humain, dit langage
naturel, aux ordinateurs.
L'idée du web sémantique c'est de permettre une recherche intelligente sur le web,
faite par des ordinateurs et basée sur des définitions qu'ils puissent « comprendre », des
définitions données pour le monde entier en mettant à disposition un langage de recherche,
qui complète le web d'aujourd'hui, et qui rendra son contenu intelligible par des applications
différentes. Autrement dit, qui lui donne un sens, c'est la signification du mot « sémantique ».
[WEB SEMANTIC]
Il est nécessaire d’utiliser un langage de description précis et normalisé pour faire
fonctionner le web sémantique.
Resource Description Framework, le RDF est un modèle de graphe pour décrire les
méta données et en permettre un traitement automatique. Une des syntaxes de ce langage est
RDF/XML. En annotant des documents non structurés et en servant d'interface pour des
applications et des documents structurés RDF permet une certaine interopérabilité entre des
applications échangeant de l'information non formalisée et non structurée sur le Web. Un
document structuré en RDF est un ensemble de triplets. Un triplet RDF est une
association entre le sujet, son objet et le prédicat. Dublin Core1 ou RSS2 version 1 sont deux
technologies basées sur le RDF.
L’Ontologie informatique :
En philosophie, l'ontologie (du grec oν , oντος, participe présent du verbe être) est
l'étude de l'être en tant qu'être, c'est-à-dire l'étude des propriétés générales de ce qui existe,
c'est-à-dire l'étude des propriétés générales de ce qui existe[ONTOLOGIE]
En informatique le mot ontologie a été repris pour désigner un moyen de représenter
les concepts, objets et entités ainsi que leurs relations. Pour cela, on classe les informations
dans une architecture structurée et agencée de manière évolutive. Un répertoire de règles
d’inférences est utilisé pour faire le lien et associer les différents objets et entités entre eux.
Les ontologies servent pour le vocabulaire, la structuration et l’exploitation des méta
données, comme représentation pivot pour l’intégration des sources de données hétérogènes
pour décrire les services Web, et en général, partout où il va être nécessaire d’appuyer des
modules logiciels sur des représentations sémantiques nécessitant un certain consensus
[ONTOLOGIE].
Le langage ontologique du web, le OWL est une des nombreuses branches du XML,
qui se basa sur une syntaxe RDF. Il fournit les moyens pour définir des ontologies Web
structurées. Le langage OWL est basé sur la recherche effectuée dans le domaine de la
logique de description. OWL permet de décrire des ontologies, c'est-à-dire qu'il permet de
1
Dublin Core est un système de méta données pour le classement bibliographique.
2
RDF Site Summary ou Rich Site Summary il s’agit d’un résumé contenu pour un site web.
14définir des terminologies pour décrire des domaines concrets. Le domaine qui nous intéresse,
l’informatique, a été décrit en 1998 par l’ ACM Computing Classification System. Plus
récemment le groupe de hacker féminin Lot3k3 et son « L0T3K COMPUTER DECIMAL
CLASSIFICATION ». Ces deux modèles d’ontologie informatique seront abordés
ultérieurement.
Moteur d’inférence :
Un moteur d’inférence est un programme réalisant les déductions logiques d'un
système expert à partir d'une base de connaissances (faits) et d'une base de règles. Les règles
sont utilisées pour manipuler les connaissances et aboutir à des conclusions judicieuses.
Système expert :
Il s’agit d’une application capable d'effectuer dans un domaine des raisonnements
logiques comparables à ceux que feraient des experts humains de ce domaine. Il s'appuie sur
des bases de données de faits et de connaissances, ainsi que sur un moteur d'inférence, lui
permettant de réaliser des déductions logiques.
3
L0T3K: Le Premier Féminin High-tech à vocation interplanétaire
15Matériel et logiciels utilisés :
Ordinateur de développement et test :
Nous avons utilisé un ordinateur portable Acer, processeur Intel Pentium IV 2Ghz
avec une mémoire vive de 1Go sous le système d’exploitation Microsoft Windows XP.
Serveur dédié
Nous avons loué un serveur dédibox, filiale free à Courbevoie. Les serveurs dédiés
sont équipés du processeur VIA C7 2 GHz. Ce processeur bénéficie de nombreuses
fonctionnalités notamment le chiffrement SSL matériel des données en (AES-256) à plus de
20 Go/sec. De par ses fonctionnalités de chiffrement matériel, ce processeur est idéal pour les
applications sécurisées de e-commerce, paiements en ligne et VPN haute performances...
Un giga de mémoire vive permet une confortable charge du serveur en cas d’affluence.
Dans cet esprit, les disques durs sont en SATA2 pour un accès plus rapide aux données.
Comme cela ne coûte pas plus cher nous avons mis le site en HTTPS. Notons que l’OS de ce
serveur est une Gentoo ( un linux ).
DIA :
C’est un logiciel de réalisation de diagrammes (réseau, circuit électrique, programme
informatique, etc.). Initialement pour Linux et développé pour l’interface graphique GNOME,
il peut être installé sous Windows. Nous nous en sommes servi au niveau de la modélisation
UML.
Analyse SI :
C’est un logiciel programmé en JAVA permettant de modéliser des modèles
conceptuels et logiques de données. Nous l’avons utilisé lors de la modélisation avec la
méthode merise.
EasyPHP :
Ce programme installe et configure automatiquement un environnement de travail
complet sous Windows permettant la mise en oeuvre du langage de script PHP ainsi qu'un
système de bases de données (MySQL).
MediaWiki :
MediaWiki est un logiciel wiki créé par Magnus Manske et écrit en PHP. Initialement
développé pour Wikipédia, il sert également de base pour d'autres projets de la fondation
WikiMedia et inclut des fonctionnalités spécifiques à l'encyclopédie, comme la gestion des
espaces de noms, la distinction entre les pages à contenu encyclopédique et les pages de
discussions associées, etc.
Macromedia Dreamweaver :
Dreamweaver est un outils de développement web qui permet de concevoir, de
développer et de maintenir des applications et des sites web répondant aux normes actuelles
(XHTML, CSS, …)
16Avant Projet
Historique du projet
Le site BocaWiki n’existe actuellement pas ; on ne trouve aucune présence sur le Web
une présence d’un wiki dédié au département informatique. Sur la plate forme Claroline
[CLAROLINE] http://ead.cs.univ-paris8.fr qui est le serveur de formation à distance du
département, mis à la disposition de l’ensemble de l’UFR.6 Cependant, bien que pleinement
fonctionnel, ce wiki « en lit » ne correspond pas aux attentes des enseignants du département.
Objectif
Le projet Bocawiki devra proposer quelques articles, des débuts ou résumés d’articles,
qui seront immédiatement accessible en lecture ou à l’édition par interface d’accueil
immédiatement reconnaissable et intuitive. La potentialité de navigation transversale autorisée
par l’ontologie permettra aux lecteurs un accès intuitif et rapide aux articles accessibles en
ligne et aux différents services proposés.
Il y aura deux façons d’accéder au site : via une interface Web publique sur le Net et
via un système de fils RSS, pour un contact plus efficace.
La cible
Le public visé regroupe les étudiants et jeunes travailleurs étudiants du centre calcul de
Paris 8, des jeunes de 18 à 35 ans ; mais aussi des enseignants, des thésards et des chercheurs
soucieux de mettre des idées en ligne et de les laisser évoluer.
Valeur ajoutée
La démarche est clairement orientée C2B (Consumer to Business)[C2B], l'intention
principale de créer un espace de réflexion communautaire autours d’article liés à
l’informatique.
Le but secondaire est de générer des bénéfices en plaçant des liens Adsens, tout du
moins de permettre de rembourser son développement, sa maintenance et la location du
serveur.
Contraintes techniques
Le public concerné n’utilise pas Internet Explorer; et la visualisation se fait sur des
écrans 17 ‘’ pouces CRT d’une résolution de 1280 par 800 px. il faut donc développer un site
adapté à ce niveau d’équipement. Cela va nous permettre de sortir du traditionnel 760 par
420 pixels prévu pour les niveaux d’équipement moyen. Dans la mesure du possible nous
testerons le wiki sous les deux environnements, Firefox et Internet Explorer en privilégiant les
utilisateurs internes avec Firefox.
Risques à ne pas faire le wiki
Le risque à ne pas faire ce projet serait de continuer à utiliser un wiki qui n’est
apprécié ni des enseignants ni des étudiants. De ce risque découle le second, qui est le déficit
en terme d’image de marque [BRANDING] pour les enseignements du département
17Risques à faire le site
On peut penser qu’il y a un risque que l’impact sur l’enseignement ne soit pas celui
escompté. En effet si le wiki est un succès, il est possible que les cours deviennent du e-
learning [E-LEARNING] sans présentiel. Le problème serait que les coûts de gestion du site
ne soient pas couverts par les bénéfices engendrés par la publicité Adsens.
Risques inhérents au projet
Le principal problème est un problème de temps; en effet, à cause de notre travail de
gestion du centre de calcul, nous ne disposons que de deux mois et demi pour réaliser
l’ensemble du projet. Sur ces deux mois un mois de vacances seulement pendant lequel nous
serons à plein temps disponibles pour nous concentrer au projet. L risque est donc d’être hors
délai.
Contraintes d’enchaînement de tâches
Rédactionnel Avant Cahier des Diagram Diagram Notes Rédaction du
projet charges mes mes
document
d’exploitation
Recherches Sur les
concepts
d’ontologie
Etudes Bench- Sur les styles
comparatives marking des autres
wikis
Etapes clés UML MERISE BDD + DEVELOPPEM MISE en
ENT +
Arboresc PRODUCTION
PHASE de
ence
TEST Upload
Serveur
Externe
+TEST externe
Graphisme / Charte Dessin Ecriture des
graphique des logos CSS
mise en page
Tableau 1 Contrainte d'enchaînement des tâches
Axe temporel
Sur ce tableau lisible de gauche à droite, les tâches à effectuer sont notées par
catégories sur l’axe du temps. On ne peut commencer les tâches d’une colonne sans avoir
terminé celles de la colonne précédente. Nous nous sommes donc attachés autant que possible
à respecter cet ordre.
18Cahier des charges
cahier des charges du wiki du bocal
Objectif
- Information : Enseignement et travail collaboratif exclusivement consacré à
l’informatique
- Promotion : Eventuellement mise en place d'une plate forme adsense de google qui met
en relation des sites entre eux, par un système de promotion réciproque.
Public visé
- Clients et futurs clients : Département informatique de l'université Paris 8
- Partenaires : Département informatique de l'université Paris 8
- Adhérents et futurs adhérents : Département informatique de l'université Paris 8
Message
Ce site est un espace de travail collaboratif en ligne, complément des enseignements
présenciels et du e-learning du département sur http://ead.cs.uiv-paris8.fr
Interlocuteur
Gérald KEMBELLEC Raoul KUCZYK
Email : gerald.kembellec@gmail.com Email : progman@bocal.cs.univ-paris8.fr
Poste occupé : Administrateur Système Poste occupé : Administrateur Système
& réseau du centre de calcul & réseau du centre de calcul
Tél : 6584 Tél : 6584
Langues
- Français
Ressources apportées
- Location d’un serveur externe pour effectuer des tests sur une autre plate forme
Spécifications techniques
- Hébergement
- Moteur de recherche
- Nommer chaque page dans la balise TITLE par des titres parlant
- Remplir les balises META pour les descriptions et les mots clés de chaque page
- Préciser la date de création et des mises à jour sur la page d'accueil, voir toutes les
pages
- Pouvoir revenir sur l'accueil en cliquant sur le logo de n'importe quelle page du site
- Appliquer les styles CSS pour les mises en page et présentations
- Tester le site sur plusieurs configurations
Aspect et qualité du site
- Site élaboré aux couleurs douces
- Exemple n°1 http://www.wikipedia.fr
Présentation
- Homogène
- Claire
- Concise
- Simple
19- Intuitive
- Sobre
- Couleurs dominantes : Nuances de bleu et blanc.
- Typologie : arial
Graphisme
- Doux
- Fin
- Frais
Forme du design
- Formes carrées et/ou rectangles
- Lignes fines
Contraintes
- Aucune contrainte
Libertés
- Libre choix de la mise en page
Interactivité
- Email (lien contact)
Contenu
- Nombre de pages : 4
Page 1 : Accueil
La page principale qui sert de portail avec possibilité de se loguer et d'effectuer des
recherches, ainsi que de créer un article.
Page 2 : Création de page
Cette page permet d'écrire le texte ainsi que le résumé de l'article sur un éditeur
sommaire et de choisir les mots clés associès.
Page 3 : Edition de page
Cette page permet d'éditer le texte de l'article choisi sans pouvoir modifier les mots
clés associès, ni le résumé.
Page 4 : Création d'un nouvel utilisateur
Cette page va permettre de s'inscrire comme utilisateur du site et d'acceder aux
fonctions avancées.
Référencement
- Annuaires et moteurs de recherche français
- adsense de google
Maintenance
- Aucune maintenance
Délai
- 3 mois
Budget
- Un coût d'hébergement de 30 euros par mois
20I. Modélisation du wiki :
Afin de mener à bien notre projet et de créer un point de départ, nous avons utilisé des
outils de modélisation tels que les méthodes UML et Merise.
I.1. La méthode UML4 :
UML est une méthode de modélisation servant à analyser un système. A cette fin
différents diagrammes mettant en valeur un aspect différent du système sont utilisés. UML est
devenu une norme de l'OMG (Object Management Group) en 1997. Celui-ci est un organisme
à but non lucratif regroupant les principaux acteurs du secteur informatique dont le rôle de
produire des standards informatiques permettant l'interopérabilité des systèmes.
I.1.1. Le diagramme de classes :
Il s’agit d’un schéma qui représente le concept général d’un système. On y retrouve les
interactions entre les différents objets de celui-ci.
Notons sur la figure la hiérarchie voulue entre les types d’utilisateurs. L’utilisateur de
base que nous appèlerons visiteur interne (identifié par son adresse IP) sera le père de toutes
classes suivantes jusqu’à l’hériter final : l’administrateur qui possède toutes les fonctions de
ses pères.
Figure 1 Diagramme de classes
4
UML = Unified Modelling Language
21I.1.2. Le diagramme de cas d’utilisation ou use-case :
Il peut être assimilé à une table des matières concernant les exigences fonctionnelles
d’un système. Il a pour but de clarifier et d’organiser les besoins des utilisateurs. Pour cela on
se met à la place de l’utilisateur pour imaginer la façon dont il verra le produit et dont il
l’utilisera.
Ce schéma explicite les observation du schéma précèdent sur les droits en cascade des
utilisateurs, selon leur place dans la hiérarchie d’utilisation du site.
Figure 2 diagramme de cas d'utilisation
22I.1.3. Le diagramme de composants :
Il sert à visualiser les dépendances entre les différents composants du système afin
d’obtenir la meilleure organisation possible entre les modules. On y décrit l’architecture d’une
application avec ses fichiers sources, ses librairies, ses exécutables, etc.
L’utilisateur une fois connecté à la page d’accueil aura selon son niveau d’accès le
droit d’effectuer une, deux, ou trois des tâches intégrées au pavé Sujet. Selon la tâche choisie,
l’action sera finalisée, ou pas par une sauvegarde.
Figure 3 Diagramme de composants
23I.1.4. Le diagramme de déploiement :
Ce schéma est souvent rattaché au diagramme de composants à cette différence qu’il
s’attache uniquement à la disposition physique des matériels d’un système et à la répartition
des composants sur ces matériels.
Le décryptage de ce schéma commence à la source des données, sur le serveur de
données (MySQL, MS ACCES, ORACLE), c'est-à-dire la machine serveur intégrant les
fonctionnalités de base de données. Ces données sont chargées lors des requêtes sur le serveur
web, le serveur sur laquelle est lancée le démon http (Apache, TOMCAT, IIS). Enfin, Les
données sont chargées au travers du navigateur sur la machine cliente.
On peut également espérer qu’il existe une méthode de sauvegarde des données
indépendante de la machine sur laquelle sont stockées les données. Cette sauvegarde peut être
sur une simple bande, sur disque ou encore sur un disque dur distant grâce à NFS5.
Il est tout à fait possible que plusieurs services soient regroupés sur une même
machine serveur. C’est le cas notamment pour les plateformes LAMP 6 comme celles ou nous
migrerons le wiki en fin de stage, mais aussi EasyPHP, et IIS / Ms ACCES.
Lors du développement les navigateurs, le serveur web, la base de données, et les
sauvegardes seront stockés sur la même machine. Cependant par précaution des sauvegardes
incrémentielles auront lieu en SFTP vers le serveur web.
Figure 4 Diagramme de déploiement
5
Network File System, système de partage de disque à travers le réseau
6
Linux Apache MySQL PHP
24Vous pouvez aussi lire

















































