Comprendre les données visuelles à grande échelle - ENSIMAG 2021-2022 Karteek Alahari & Diane Larlus
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Comprendre les données
visuelles à grande échelle
ENSIMAG 2021-2022
Karteek Alahari & Diane Larlus
Jeudi 30 septembre 2021
Comprendre les données visuelles à grande échelle
l Site Web: https://project.inria.fr/bigvisdata/
l Intervenants:
► Karteek Alahari, Chargé de Recherche @ INRIA Grenoble
► Diane Larlus, Principal Scientist @ NAVER LABS
l 12 x 1h30 = 18h de cours
l Évaluation
l Examen final écrit
l Présentations et Quizz sur des articles de recherche
Cours 1: Introduction – Image Retrieval (part 1)
Comprendre les données visuelles à grande échelle
30 septembre 2021
Les données à grande échelle
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 30 septembre 2021
Les données à grande échelle
Le big data
• littéralement « grosses données »
• méga données
• données massives
désigne un ensemble de données qui sont tellement
volumineuses qu‘elles en deviennent difficiles à travailler
avec des outils classiques de gestion de base de données.
Wikipedia
• Nécessite le développement d’outils spécifiques
Les données visuelles à grande échelle ou Big Visual Data sont devenues une façon majeure de transférer l’information
Quelques chiffres
l Croissance très importante, en raison de l’accumulation des
contenus numériques auto-produits par le grand public
► ImDb recense plus de 400 000 films
► Images (semi-)pro : Corbis, Getty, Fotolia
► centaines de milliers d’ images
► Facebook – chiffres de 2013
► 350 millions de nouvelles photos / jour
► 250 milliards de photos stockées
► 3,000 années de vidéo générées chaque jour
► Flickr – novembre 2016
► 13 milliards de photos
► Youtube
► 35h / min uloaded in 2011
► 100h / min uploaded in 2014
Les données visuelles à grande échelle
ou Big Visual Data
sont devenues une façon majeure de transférer l’information
Selon la British Security Industry Authority (BSIA), il y aurait autour de 5M de CCTV cameras en GB, soit
une pour 14 habitants (source: telegraph-2013)
La chine projeté d’installer 600 millions de caméras de surveillance sur son territoire
Les données visuelles à grande échelle ou Big Visual Data sont devenues une façon majeure de transférer l’information Seule une partie de ces données est exploitée, et une bonne partie du processus est fait à la main → opportunités de simplification de tâches fastidieuses → opportunités de nouvelles applications et de nouvelles solutions commerciales → développement de l’intelligence ambiante

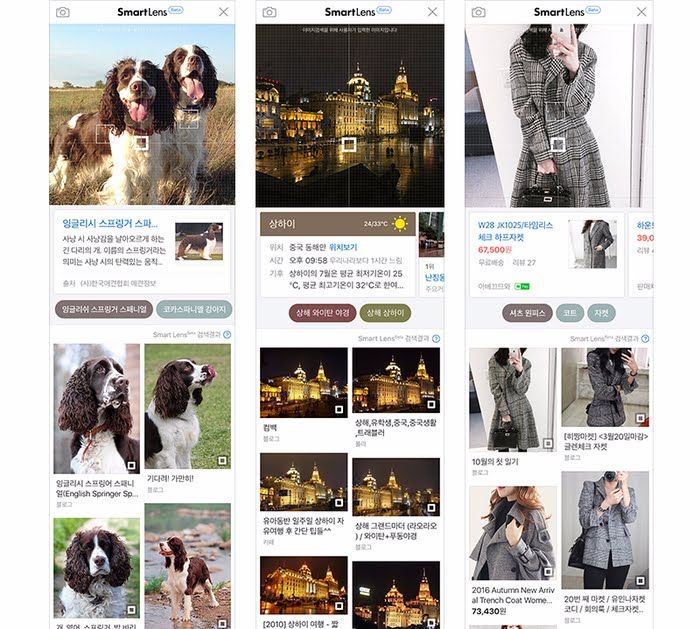
Exemples d’applications du Big Visual Data l News/Films à la demande l Commerce électronique l Informations médicales l Systèmes d’informations géographiques l Architecture/Design l Protection du copyright / traçage de contenu l Géolocalisation, système de navigation l Enquêtes policières l Militaire l Expérimentations scientifiques l Enseignement l Archivage, gestion des bases de données de contenu (personnelles ou professionnelles) l Moteur de recherche (Internet, collections personnelles) l Voitures et autres véhicules autonomes l Robotique, plateformes d’intelligence ambiante l Autres applications industrielles l Etc.
Exemples d’applications à NAVER LABS
Chaîne du Big Visual Data
1. Génération :
• outils de production et de création
2. Représentation
• utilisation de formats de représentation différents
3. Stockage
4. Transmission
• problème de réseaux, architecture
5. Recherche d’information
• recherche d’images basée sur le contenu (image retrieval ou image search)
• Autres taches de vision par ordinateur / d’analyse d’images (voir exemples)
6. Distribution
• conception de serveur de streaming, interfaces de l’application, etc.Annotations d’images: difficulté et ambiguïté
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 30 septembre 2021Contenu et métadonnées
l Les données “brutes” (fichier image, fichier son) contiennent des
informations sémantiques = directement compréhensibles pour
l'utilisateur
l Ces métadonnées proviennent
► Soit de propriétés de descripteurs des objets (ex: couleur moyenne d’une
image, métadonnée surexposé)
► Soit de données d’autres médias (ex: GPS)
► Soit d’annotations manuelles (ex. Tags)
.Exemple: Exchangeable image file format (Exif)
l Spécification pour les formats d’images des appareils numériques
► non uniformisé, mais largement utilisé
l Pour JPEG, TIFF, RIFF, ne supporte pas, PNG ou GIF
l Le format supporte souvent
► Date et heure, enregistrés par l’appareil
► Les paramètres de l’appareil
l Dépendent du modèle : inclus la marque et des informations diverses telles que le temps
d’ouverture, l’orientation, la focale, l’ISO, etc.
► Une vignette de prévisualisation
► La description et les informations de copyright
► Les coordonnées GPS
l Ce format est supporté par de nombreuses applicationsContenu et métadonnées
…. vs acquisition d’annotations spécifiques à la tâche
l Il est parfois nécessaire d’acquérir des annotations spécifiques à la tâche qui
nous intéresse
l On parle de données labélisées
l Elles sont souvent associées à l’apprentissage supervisé
l Dans ce cas elles sont utilisées comme données d’apprentissage pour
apprendre un modèle de prédiction utile à la tâche à résoudre
(Des exemples de tâches automatisables seront données juste après)
l L’apprentissage supervisé est un exemple d’apprentissage machineAnnotation d'images
l Il faut choisir un type d’annotation
l Ensemble de tags / étiquettes (une ou plusieurs étiquettes par image)
l Position approximative de tous les objets (boites englobantes)
l Position précise de tous les objets (masques de segmentation)
l Phrases descriptives
l Il faut une cohérence des annotations sur toute une base
people motorbike people motorbike A motorcyclist turning rightAmbiguïté de l'annotation d'images
l Difficile de se mettre d'accord sur les annotations
l Exemple: Instructions pour la création d’une vérité terrain
pour la compétition PASCAL 2009
All objects of the defined categories, unless:
you are unsure what the object is.
What to label the object is very small (at your discretion).
less than 10-20% of the object is visible.
If this is not possible because too many objects, mark image as bad.
Viewpoint Record the viewpoint of the ‘bulk’ of the object e.g. the body rather than the head. Allow viewpoints within
10-20 degrees.
If ambiguous, leave as ‘Unspecified’. Unusually rotated objects e.g. upside-down people should be left as
'Unspecified'.
Bounding box Mark the bounding box of the visible area of the object (not the estimated total extent of the object).
Bounding box should contain all visible pixels, except where the bounding box would have to be made Ø Malgré ces instructions,
excessively large to include a few additional pixels (Ambiguïté de l'annotation d'images
l Obtenir des annotations précises est une tâche fastidieuse
l Une solution courante: plateformes de crowdsourcing, comme Amazon Mechanical Turk
l Crowdsourcing : externalisation ouverte ou production participative en français
l Amazon Mechanical Turk (AMT)
l Origine du nom : le Turc mécanique ou l’automate joueur d'échecs
est un célèbre canular construit à la fin du XVIIIe siècle :
il s’agissait d'un prétendu automate doté de la faculté de jouer aux échecs
l L’utilisation d’Amazon Mechanical Turk a permis la construction
de bases d’images annotées qui ont grandement participé
à l’avancée de la recherche en vision par ordinateur, par exemple:
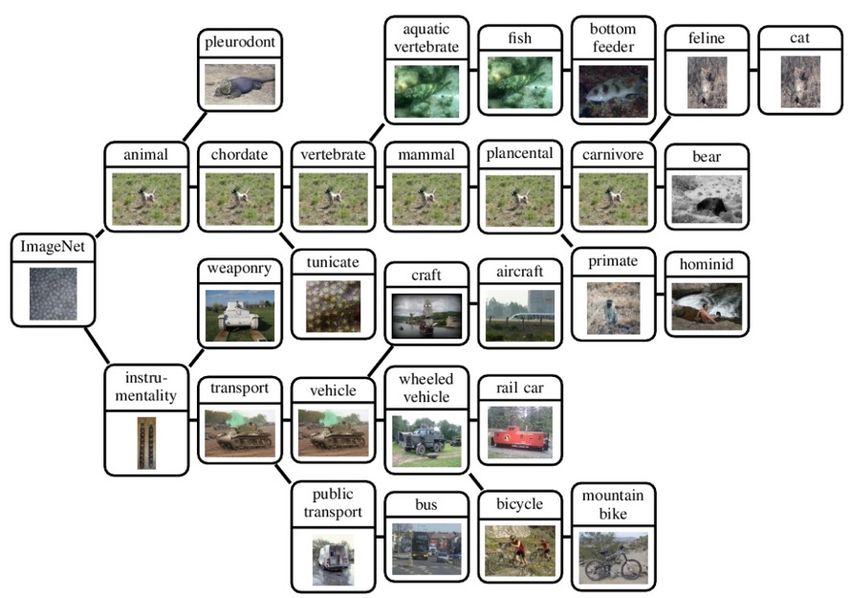
l ImageNet (http://image-net.org/)
l MS Coco (http://mscoco.org/)
l Visual Genome (https://visualgenome.org/)
l Base VQA (http://www.visualqa.org/)ImageNet
Pushing the state of the art • ImageNet challenge: • Task: Categorize images into 1000 classes
Pushing the state of the art
• ImageNet challenge:
• Task: Categorize images into 1000 classes
• Until 2011: “standard” techniques (Fisher Vector)
• Starting 2012: deep learning (CNNs)
(Source: Nervana)MS COCO • Common Objects in Contexts “What is COCO?” from its webpage COCO is a large-scale object detection, segmentation, and captioning dataset COCO has several features: • Object segmentation • Recognition in context • Superpixel stuff segmentation • 330K images (>200K labeled) • 1.5 million object instances • 80 object categories • 91 stuff categories • 5 captions per image • 250,000 people with keypoints http://cocodataset.org
Visual Genome
• 108,077 Images
• 5.4 Million Region Descriptions
• 1.7 Million Visual Question Answers
• 3.8 Million Object Instances
• 2.8 Million Attributes
• 2.3 Million Relationships
• Everything Mapped to Wordnet Synsets
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li Jia-Li, David Ayman Shamma, Michael Bernstein, Li Fei-FeiQuels sont les processus automatisables en analyse
de données visuelles ?
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 30 septembre 20211) Recherche d’images par similarité Principe • Etant donné une image, retrouver les images similaires dans une grande base visuelle
1) Recherche d’images par similarité
l Utilise la notion de proximité, de similarité, ou de distance entre images
l Généralement, la requête est exprimée sous la forme d’un ou de plusieurs
vecteurs dans un espace multidimensionnel.
► définition d’une distance (ou mesure de similarité) sur cet espace
► recherche des objets dont la distance est minimale
l Les vecteurs sont extraits du contenu de l’image
Recherche par le contenu
ou CBIR: content based information retrieval
l Possibilité d’utiliser un retour de pertinence
l L’utilisateur spécifie quels résultats sont les plus pertinents pour sa requête
l Le système raffine les résultats en fonction de ce retourVariation d’apparence d’une instance d’objet donné
scale
reference image viewpoint
occlusion illuminationAutres processus automatisables:
la reconnaissance d’objet
2) Catégorisation d’image
• Catégorie principale associée à l’image, ou
réponse oui/non à une liste de catégories connues
à l’avance
3) Détection d’objet
• Boite englobante pour toutes les instances d’une
catégorie d’intérêt
4) Segmentation d’objet,
segmentation sémantique
• Localisation précise des objets au niveau du pixelDifficultés de la modélisation des catégories d’objet • Illumination, ombres • Orientation et pose • Fond texturé, distracteurs • Occultations • Variations intra-classe
5) Etiquetage d’image
ou Image tagging
• Catégorisation de l’objet principal contenu dans l’image ou des différents objets
• lien avec la reconnaissance d’objet et notamment la classification d’image
• Catégorisation de la scène
• intérieur vs extérieur, paysage urbain ou campagnard, etc.
• Tout autre type d’attributs possible
• Couleur, forme, texture, etc.
Tokyo tower
Landscape
Sunset
UrbanAnnotations avec des critères subjectifs
6) Qualités esthétiques
• Prédire si le plus grand nombre va trouver une image agréable à regarder,
visuellement esthétique
7) Iconicité d’une image
• Prédire si une image est un bon représentant d’un concept, par exemple
dans un but d’enseignement
8) Mémorabilité
• Prédire si une image sera plus facilement remarquée, mémorisée
(remembered)
[AVA: Murray et al. CVPR12]
[What makes an image iconic? Zhang et al. Arxiv 14]
[Image memorability. Khosla et al. ICCV15]Annotations plus complexes
9) Le sous-titrage automatique d’image (image captioning)
Automatic Image Caption Generation
Sample taken from the work of
Andrej Karpathy and
Li Fei-Fei
More recent demo:
https://www.captionbot.ai/Annotations plus complexes
10) La réponse à des questions visuelles
(Visual question answering ou VQA)
http://www.visualqa.org/
More recent demo:
http://vqa.cloudcv.org/Apprentissage automatique et intelligence artificielle
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 30 septembre 2021Vocabulaire • Apprentissage automatique (Machine learning) champ d'étude de l'intelligence artificielle qui se base sur des approches statistiques pour donner aux ordinateurs la capacité d' « apprendre » à partir de données [..]. Il comporte généralement deux phases. - La première consiste à estimer un modèle à partir de données, appelées observations [..] Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. Wikipedia - La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. • Apprentissage profond (Deep Learning) est un ensemble de méthodes d'apprentissage automatique tentant de modéliser avec un haut niveau d’abstraction des données grâce à des architectures articulées de différentes transformations non linéaires • Intelligence artificielle (AI) est l'ensemble des théories et des techniques mises en œuvre en vue de réaliser des machines capables de simuler l'intelligence
AI in the news • 2016: computer beats a top-ranked professional player at the go game, known as one of the most difficult for computers
AI in the news 2019: StyleGAN – and more generally GANs and Deep Fakes • December 2018 – StyleGAN paper + Code • February 2019 – This Person Does Not Exist. Website (https://thispersondoesnotexist.com/)
Recherche visuelle d’images – introduction
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 30 septembre 2021Visual Search - Principle
Visual Search - Principle
Visual Search - Applications Many applications • Reverse Image search • Web search engine • Personal photo collection
Visual Search - Applications Many applications • Geolocalization
Visual Search - Applications Many applications • Query for more information • Landmarks • Paintings • Movies • Book covers • Game covers • Packaged food
Visual Search - Applications Many applications • Shopping interfaces
Inherent ambiguity What can the user mean with such a single query?
Inherent ambiguity What can the user mean with such a single query?
Inherent ambiguity What can the user mean with such a single query? Application dependent! • Inject prior information • Leverage training
Inherent ambiguity
What can the user mean with such a single query?
Information a priori:
• Design à la main de descripteurs
Application dependent! pertinents ou de méthodes pertinentes
pour la vérification en fonction de
l’application visée
• Inject prior information
• Leverage training Apprentissage:
• On laisse le système apprendre tout ou
partie du design, en particulier le
système « choisit » les caractéristiques
pertinentes pour la tâcheDescription locale des images
Comprendre les données visuelles à grande échelle
Cours 1: Introduction, 15 octobre 2020Rappel: variation d’apparence d’une instance d’objet donné
scale
reference image viewpoint
occlusion illuminationLocal representations It is challenging to capture all these invariances in a global representation
Local representations It is challenging to capture all these invariances in a global representation Local representations seem more adapted but require more sophisticated matching
Représentations locales
• Les représentations locales captures l’apparence de l’image localement
• L’apparence locale est extraite à plusieurs positions dans l’image, choisies
avec soin, notamment à l’aide d’un critère de « répétabilité ».
Définition: un détecteur est dit répétable s’il choisit les mêmes régions d’une
scène / d’un objet dans des images potentiellement très différentes de cet objet
Exemple: la fenêtre est choisit par le détecteur dans les deux imagesReprésentations locales
• Les représentations locales captures l’apparence de l’image localement
• L’apparence locale est extraite à plusieurs positions dans l’image, choisies
avec soin, notamment à l’aide d’un critère de « répétabilité ».
Définition: un détecteur est dit répétable s’il choisit les mêmes régions d’une
scène / d’un objet dans des images potentiellement très différentes de cet objet
On utilise pour cela des détecteurs de points d’intérêt
• Exemple de détecteurs: Harris, Hessian, Hessian-Affine, MSER, etc.
[Harris&Stephens1988, Mikolajczyk&Schmid2002, Matas et al, 2004
Survey: [Mikolajczyk, IJCV 2005]Représentations locales
• Les représentations locales captures l’apparence de l’image localement
• Ces représentations locales doivent posséder des propriétés d’invariance et
de discrimination
invariant
Local descriptors
• SIFT, SURF, LBP, etc. compact
discriminative
[Lowe IJCV04, Bay et al, 2008, Ojala et al, 2014]
(plus de détails à venir)Local representations
Overview of the pipeline
image
imageDescription locale - plan l Extraction de points/régions d’intérêt l Descripteurs locaux l Appariement de points
Extraction de points/régions d’intérêt : enjeux
l Extraire des régions qui soient invariantes à de nombreuses transformations,
afin d’être « répétables » (repeatability)
l Transformations géométriques
l Translation
l Rotation
l Similitude (rotation + changement d’échelle isotrope)
l Affine (en 3D, texture localement planaire)
l Transformations photométriques
► Changement d’intensité affine (I -> a I + b)Principaux extracteurs de points/régions d’intérêt
Vus en cours
l Harris
l Harris-Affine
l Hessian-Affine
l Maximally Stable Extremal Regions (MSER)
l Salient Region Detector
[A comparison of affine region detectors » K. Mikolajczyk et al., IJCV 2005 ]Détecteur de Harris : Introduction
l Détecter les « coins », qui correspondent à des structures:
► répétables de l’image
► qui localisent des endroits très discriminants d’une image
l Détecteur de Harris
► analyse locale
► lorsqu’on est sur un «coin», un déplacement dans n’importe quelle direction produit un
fort changement des niveaux de gris
« A Combined Corner and Edge Detector », C. Harris et M. Stephens, 1988Détecteur de Harris • A(x,y): • Faible dans toutes les dimensions -> région uniforme • Large dans une direction -> contour • Large dans toutes les dimensions -> point d’intérêt
Détecteur de Harris l Illustration:
Détecteur de Harris • Comment calculer la fonction d’auto-corrélation ? • Basée sur une approximation du premier ordre
Détecteur de Harris • Basé sur une approximation du premier ordre
Détecteur de Harris : calcul des gradients
• Calcul des gradients
• On calcule indépendamment le gradient dans les deux dimensions x et y
Ix
IyDétecteur de Harris : classification des régions par utilisation d’un seuil
• Détection de points d’intérêt
• Application d’un seuil (absolu, relatif,
nombre de points)
• Extraction des maxima locauxDétecteur de Harris : exemple
Détecteur de Harris : propriété d’invariance
l Invariance à la translation : inhérente à la sélection des maxima locaux
l Invariance aux transformations affines d'intensité
l Invariance à la rotation
► l’ellipse tourne mais la forme reste identique
► les valeurs propres restent identiques
l Mais pas d’invariance à des changements d’échelleDétecteur de Harris : Invariance à l’échelle l Pas d’invariance aux changements d’échelle
Détecteur de Harris : Invariance à l’échelle
l Choix d’un noyau (kernel). ex: Laplacien ou DoG
l Sélection d'une échelle caractéristique :
► prendre les valeurs extrêmes d’une fonction f liée à l’échelle
► Une bonne fonction f présente des pics marqués
Laplacien
invariance de l’échelle caractéristiqueDétecteur de Harris : Invariance à l’échelle
l Détecteur de Harris-Laplace
► Sélectionner le maximum de Harris en espace pour plusieurs échelles
► Sélection des points à leur échelle caractéristique avec le LaplacienDétecteur de Harris-Affine (début)
l Détecteur de région de l’état de l’art
l Algorithme : estimation itérative des paramètres
► Localisation du point d’intérêt: utilisation du détecteur de Harris
► Choix de l’échelle : sélection automatique avec le Laplacien
► Choix d’un voisinage affine :
normalisation avec la matrice des seconds moments
-> jusqu’à convergenceDétecteur de Harris-Affine (suite)
l Estimation itérative de la localisation, de l’échelle, du voisinage
Points initiauxDétecteur de Harris-Affine (suite)
l Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #1Détecteur de Harris-Affine (suite)
l Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #2Détecteur de Harris-Affine (suite)
l Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #3, #4, ...Détecteur de Harris-Affine: pour résumer l Initialisation avec des points d’intérêt multi-échelle grâce au détecteur de Harris l Estimation itérative de la localisation, de l’échelle, du voisinage
Description locale : plan l Extraction de points/régions d’intérêt l Descripteurs locaux l Appariement de points
Et une fois qu’on a défini l’ellipse ?
l Synthèse du patch (imagette)
► On calcule un patch de taille donnée
l Tailles typiques de patch : 21x21, 64x64Objectif
l En utilisant un détecteur, on est capable de détecter des zones robustes (et
informatives) de l’image
l Mais à ce stade, ces zones ne peuvent pas être comparées entre elles
l Qu’est qu’un descripteur ?
► une représentation de la zone d’intérêt invariance
► sous la forme d’un vecteur
► qui appartient à un espace muni d’une distance
compacité
l Qu’est qu’un bon descripteur ?
► invariant
► discriminant
capacité de
► compact
discrimination
l Remarque : ces objectifs sont contradictoiresDescription locale : plan
l Extraction de points/régions d’intérêt
l Descripteurs locaux
l Descripteurs basiques
l État de l’art : le descripteur SIFT
l Appariement de pointsDescripteurs de pixels
l On range les pixels au voisinage du point d’intérêt dans un vecteur
()
descripteur localDescripteurs de pixels
l On range les pixels au voisinage du point d’intérêt dans un vecteur
()
descripteur local
l Calcul simple
l Volumineux (patch de 32x32 = vecteur de 1024 éléments)
l Invariance possible aux transformations affines de luminosité
l Mauvaise « baseline »SIFT (Scale invariant feature transform)
► Calculé sur un patch déjà normalisé : échelle (ou affine)
► Possibilité de normaliser également en orientation (orientation dominante)
Explications au tableauAutres descripteurs locaux
l Il existe de nombreuses autres variantes de SIFT:
► CS-LBP (voisinage au niveau du pixel, comparaisons directes)
► HOG (articles à lire pour les prochaines semaines)
► GLOH (log-polar bins)
► SURF (approximation, Blob detector, HAAR wavelets)
Navneet Dalal et Bill Triggs, “Histograms of Oriented Gradients for Human Detection”. CVPR 2005
M. Heikkila, M. Pietikainen, C. Schmid, “Description of interest regions with local binary patterns”
E. Tola, V. Lepetit, P. Fua, “A fast local descriptor for dense matching”. CVPR 2008
LBPCS-LBP (Center-symmetric local binary pattern)
l Principe du descripteur CS-LBP
l Le patch est divisé en une grille de cellules
l Pour chaque pixel nc dans la grille
l Le comparer à ses 8 voisins (n1 à n8)
l Encoder ces 8 comparaisons (0 ou 1)
en un nombre binaires à 8 chiffres
l Pour chaque cellule
l Construire un histogramme d’occurrence de ces nombres binaires
l Cela donne un histogramme à 256 dimensions
l Concaténer les histogrammes de chaque cellule
l Il existe de nombreuses autres variantes de SIFT:
► CS-LBP (voisinage au niveau du pixel, comparaisons directes)
► HOG (generalization)
► GLOH (log-polar bins)
► SURF (approximation, Blob detector, HAAR wavelets)
Navneet Dalal et Bill Triggs, “Histograms of Oriented Gradients for Human Detection”. CVPR 2005
M. Heikkila, M. Pietikainen, C. Schmid, “Description of interest regions with local binary patterns”
E. Tola, V. Lepetit, P. Fua, “A fast local descriptor for dense matching”. CVPR 2008Descripteurs locaux: conclusion
l Choisir un détecteur avec de nombreuses invariances par
construction
► normalisation affine de la région vers un patch de taille constante en
utilisant un détecteur affine invariant
► normalisation affine en luminosité avant le calcul du descripteur pour
garantir l’invariance affine
l Utilisation d’un descripteur de relativement grande dimension
(par exemple 128 pour SIFT) pour obtenir une bonne capacité
de discriminationDescription locale : plan l Extraction de points/régions d’intérêt l Descripteurs locaux l Appariement de points
Appariement de points
l Problème : étant donné des points ou régions d’intérêt et les descripteurs
associés, comment apparier de manière robuste les points de deux images ?
l Dans ce contexte: robuste = robuste au bruit = aux mauvais appariements locaux
l Dans le suite: sélection des meilleurs couples de pointsSélection des meilleurs couples
l Remarque: ambiguïté
0.9
0.8
0.7
l Différentes stratégies:
► Winner-takes-all (symétrique ou à sens unique)
► Filtrage ultérieur par géométrieSélection des meilleurs couples 0.9
0.8
Entrée
0.7
Différentes stratégies de sélection:
► Winner-takes-all
A sens unique 0.9
0.9
0.8
0.7
0.9
SymétriqueProblème : appariements entre deux images
Un grand nombre des appariements restant est incorrectVérification géométrique par mise en correspondance d’images
Différentes stratégies:
► Filtrage ultérieur par géométrie
Deux méthodes classiques
l RANSAC
l Transformée de HoughVérification par un modèle géométrique
Pour une paire d'images I, I'
l Il existe un vecteur de paramètres p
tel que 2 points en correspondance (x, x') vérifient F(x, x', p) = 0
l le plus souvent x' = T(x, p) avec T transformation
l En indexation:
► si les images sont en correspondance, alors il existe p tel que
“suffisamment” de points (x, x') vérifient F(x, x', p) = 0
Idée intuitive de l’algorithme:
1. estimation de p
2. nombre de points qui vérifient l'équation avec le meilleur p = mesure de
ressemblance entre imagesRANSAC
RANSAC (RANdom SAmple Consensus)
• Algorithme
• Entrée: un ensemble d’appariements locaux entre deux images
• Sortie: paramètres de la transformation estimée entre les deux images
• Pour try dans 1..K
• Sélectionner aléatoirement un ensemble d’appariements (seed)
• Estimer les paramètres de la transformation entre les deux images en utilisant seulement
cet ensemble seed
• Trouver le nombre d’appariements qui correspondent à la transformation estimée (inliers)
• Si ce nombre est suffisamment grand
• Reestimer les paramètres avec tous les inliers
• Garder les paramètres de la transformation qui a le plus d’inliersRANSAC
RANSAC (RANdom SAmple Consensus)
Illustration de RANSAC
sur un autre problème plus facile à visualiser:
l’estimation des paramètres d’une droite.
Rappel: nous voulons l’utiliser pour sélectionner
des appariements tous cohérents pour la
même transformation géométrique.
Les paramètres estimés dans notre cas sont
donc ceux de la transformation.Problème : appariements entre deux images après RANSAC
Local representations
Summary of the pipeline
Bottleneck: pairwise matchingLocal representations Comment accélérer
cette étape ?
Summary of the pipeline
Bottleneck: pairwise matching
Solution au
Prochain cours !Vous pouvez aussi lire

















































