Filtres de Gabor pour CNNs - Ouiame Talbi, Grenoble INP, Laboratoire TIMA May 25, 2018 - Ensimag
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Filtres de Gabor pour CNNs
Ouiame Talbi, Grenoble INP, Laboratoire TIMA
May 25, 2018
1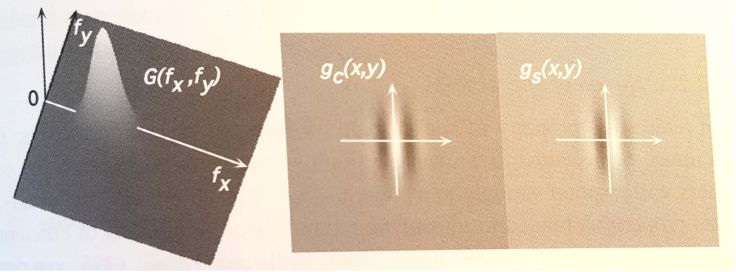
1 Résumé
Les réseaux neuronaux convolutifs(CNNs) sont utilisés dans différentes ap-
plications cognitives, notamment dans la vision par ordinateur. Ils sont très
performants pour la reconnaissance d’image, la classification des objets et
pour les taches de synthèse. Parmi les applications des CNNs les plus con-
nus: Google Image Search, Google speech recognition, Apple’s Siri voice
recognition , et Google street View.
Les principaux défis des réseaux neuronaux convolutifs sont la complexité
calculatrice et le temps demandé pour entrainer un large réseau. L’entrainement
des CNNs nécessitent des accélérateurs comme les GPUs pour les applica-
tions exhaustives. Cela restreint l’usage des CNNs aux clouds et aux serveurs.
Une tendance émergente dans les iOT vise à intégrer les CNNs dans les ap-
pareils mobiles. Pour réaliser cela, il est important de réduire la complexité
de l’entrainement des CNNs et économiser l’énergie déployée.
Mots-clés: Intelligence artificielle, Deep Learning, Réseaux de neurones,
Réseaux de neurones convolutifs (CNN).
2 Introduction
Les chercheurs en machine learning cherchent à améliorer la précision des
résultats de la classification. Actuellement, beaucoup de travaux utilisent
les filtres de Gabor pour améliorer l’entrainement des réseaux neuronaux
convolutifs. Ces filtres sont basés sur le système visuel humain, et sont alors
plus efficace pour la classification. En plus, les filtres de Gabor peuvent être
utilisés pour économiser l’énergie et la mémoire lors de l’entrainement des
CNNs.
Dans cette article, on présente une architecture de CNN utilisant les filtres
de Gabor, afin de réduire l’énergie nécessaire pour l’entrainement. On expli-
quera ensuite un modèle de DCNN (deep CNN) intégrant les filtres de Gabor
pour améliorer la précision des résultats. Enfin, on étudiera l’utilisation des
filtres de Gabor pour une meilleure reconnaissance vocale, comme exemple
d’application.
2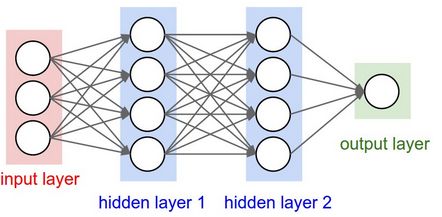
3 Réseaux convolutifs CNNs
Figure 1: À gauche: réseau neuronal de 3 couches. À droite: CNN. Chaque
couche transforme son entrée 3D en une sortie 3D. Dans cet exemple, la
couche rouge représente l’image.
Comme présentée dans l’image 1, un CNN est un réseau de neurones dont
les couches sont de dimension 3( voir annexe). Chaque couche transforme la
sortie de la couche précédente en appliquant des fonctions d’activation. Si
l’entrée est une image de la dataset CIFAR-10 par exemple, la sortie du CNN
serait un score précisant le contenu de l’image: chat,chien, voiture. . . .
Un simple CNN pour la dataset CIFAR-10 pourrait avoir l’architecture
suivante :
• Entrée [32*32*3]: valeurs des pixels de l’image de dimension 32*32.
Chaque pixel contient les 3 couleurs rouge,vert et bleu, d’ou la dimension
3.
• Couche convolutive: calcul la sortie des neurones qui sont liés à des
régions locales de l’entrée,en faisant le produit de leurs poids par de
petites régions auxquelles ils sont liés sur l’entrée. Le résultat pourrait
être [32*32*12] si on utilise 12 filtres par exemple.
• RELU Layer : applique une fonction d’activation comme x—> max(0,x).
La sortie de ce layer est donc de même dimension que son entrée.
• POOL Layer : diminue la dimension de son entrée , sa sortie pourrait
être par exemple de dimension 16*16*12.
• FC(Couche totalement connectée) : calcule les scores des différentes
classes. Pour CIFAR-10, la sortie est donc de dimension [1*1*10] .
3
Figure 2: À gauche: Volume d’entrée en rouge de dimension 32*32*3. À
droite: volume de neurones de la 1ère couche convolutive
Comme illustré dans la figure 2, chaque neurone de la couche convolutive est
connecté à une région local du volume de l’entrée ou de la couche précédente
mais sur toute la profondeur (ici 3). Il existe plusieurs neurones (ici 5) reliés
à la meme région de l’entrée. Si on considère que les dimensions des régions
locales sont de 5 ∗ 5 ∗ 3, et qu’on utilise 12 filtres, chaque neurone aura donc
5 ∗ 5 ∗ 3 poids.Les neurones de la meme profondeur utilisent les memes poids,
on aura donc un total de 12 ∗ 5 ∗ 5 ∗ 3poids.
4 Filtres de Gabor
En 1946, Gabor a proposé un filtre 1D qui optimise la relation entre le temps
et la fréquence. Daugman a ensuite développé cette idée pour construire des
filtres 2D optimisant la relation entre la localisation spatiale et la fréquence
spatiale.
En une seule dimension, on représente un filtre de Gabor par la relation
suivante:
−(f −f0 )2
G(f ) = e 2∗σ 2
La réponse impulsionnelle est complexe: gr (x) + igi (x)
En 2D, l‘expression est un peu plus complexe. Si on considère un filtre centré
en fx = f0 et fy = 0, l’expression de G(fx , fy ) est plus complexe :
−(fx −f0 )2 −(fy )2
G(fx , fy ) = e 2∗σx 2 ∗ e 2∗σy 2
Sa réponse impulsionnelle est complexe aussi: gr (x) + igi (x)
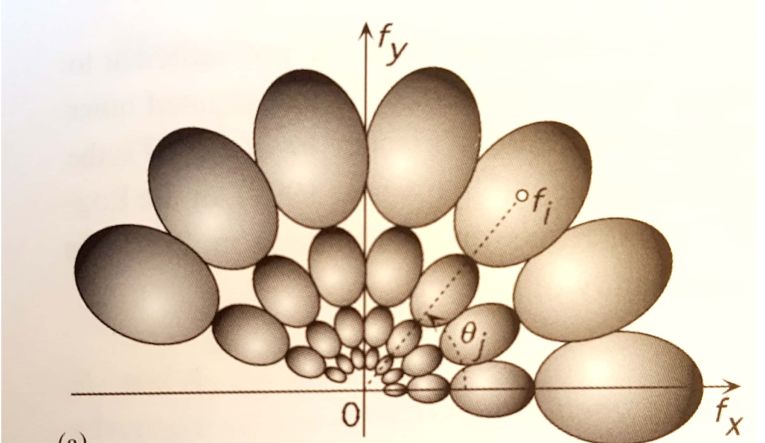
Il est alors facile de générer toute la banque de filtres: en choisissant de dif-
férentes fréquences et en appliquant différentes rotations autour de l’origine,on
est capable de générer tous les filtres.
4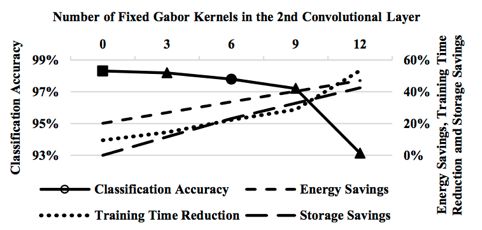
Figure 3: Un filtre de gabor à 2 dimensions. À gauche: représentation
fréquentielle. À droite: partie réelle et imaginaire de la réponse impulsionnel
Figure 4: Banque de filtres de Gabor dans le domaine fréquentiel.
5 Optimisation d’énergie et de mémoire
5.1 Modèle de calcul d’énergie pour l’entrainement des
CNNs
Dans [1] , les auteurs ont développé un modèle de calcul d’énergie afin de
mesurer la distribution de l’énergie consommée lors de l’entrainement d’un
large réseau convolutif. Ce modèle est basé sur le nombre de multiplication
et d’additions effectué lors de l’entrainement .
En utilisant ce modèle sur un CNN contenant 2 couches convolutives, suiv-
ies chacune par une couche POOL, et finalement d’une couche FC, il a été
découvert que la 1ère couche convolutive utilise 20 % de l’énergie global con-
sommée pour l’entrainement, et que la 2ème utilise 27% de l’énergie totale.
Une partie importante de l’énergie consommée est utilisée pour calculer les
gradients (Back-propagation) et pour mettre à jour les poids des couches con-
volutives et des FC. Pour optimiser l’énergie totale de l’entraînement,il faut
donc optimiser l’énergie déployée par les couches convolutives en utilisant les
filtres de Gabor comme des filtres fixes.
5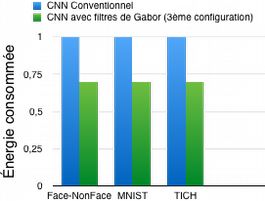
5.2 Filtres de Gabor dans les couches convolutives
Les auteurs de [1] ont conçu un CNN constitué de 2 couches convolutives
suivies chacunes par une couche POOL et finalement d’une couche FC. La
1ère couche convolutive possède k filtres, et la 2ème couche convolutive est
constituée de 2k filtres pour chaque filtre des k filtres de la 1ère couche
convolutive pour un total de 2k 2 . Des filtres de Gabor ont été intégrés dans
les couches convolutives selon différentes configuration :
• 1ère configuration: Filtres de Gabor utilisés dans la 1ère couche convo-
lutive seulement
• 2ème configuration: Filtres de Gabor utilisés dans les deux couches
convolutives
• 3ème configuration: Filtres de Gabor utilisés dans la 1ère couche , et
dans une partie des filtres de la 2ème couche
1. 1 ère configuration
En prenant k=6, la 1ère couche convolutive possède 6 filtres et la 2ème
en possède 72 . Les 6 filtres de la 1ère couche convolutive sont des filtres
de Gabor de taille 5*5 équitablement espace en orientation : O◦ , 30◦ ,
60◦ , 90◦ ,120◦ , et 150◦ . Le réseau a été entrainé sur la dataset MNIST.
Avec cette configuration, on observe une économie d’énergie de 20,7%
et une réduction du temps de l’entrainement de 10%, avec une perte de
précision de seulement 0.62%.
Figure 5: Comparaison entre la configuration 1 et la configuration stan-
dard
2. 2 ème configuration
Pour optimiser encore mieux l’énergie, les filtres de la 2ème couche sont
remplacés par des filtres de Gabor équitablement espacés en orienta-
tion. Au lieu de 72 filtres, on aura besoin de seulement 2*6= 12 filtres
de Gabor. Dans ce cas, ces 12 filtres font des convolutions avec tous
6les filtres de la 1ère couche. Grace à cette configuration , on observe
une économie d’énergie de 48,28 pour cent, une réduction du temps de
l’entrainement de 50 pour cent, et une optimisation de la mémoire de
42,48% . Par contre, on perd 5,85% en précision, même pour une simple
dataset comme MNIST.
Figure 6: Comparaison entre la configuration 2 et la configuration stan-
dard
3. 3 ème configuration
Pour régler le problème de la perte en précision, on change le nombre
de filtres de Gabor présents dans la 2ème couche convolutive ( noté i )
afin de trouver le nombre optimal pour une perte en précision minimale
. La data MINST a été entrainé avec i =0, 3, 6, 9, 12. Les résultats
sont représentés dans la figure suivante .
Pour la dataset MINST, on observe que la configuration moitié Gabor-
moitié entraînable ( 6 filtres de Gabor et 6 filtres entrainable pour chaque
7filtre de la 1ère couche) dans la 2ème couche convolutive est optimale. Le
nombre de filtres entrainables est donc 6*6=36. Les 36 autres filtres sont
fixes et peuvent donc être remplacés par 6 filtres de Gabor seulement
—> Optimisation de mémoire. Avec cette configuration, on observe
une économie d’énergie de 34,49 pour cent, une réduction du temps de
l’entrainement de 34,49%, et une optimisation de la mémoire de 22,30%,
avec une perte en précision de 1,14% seulement.
Figure 7: Comparaison entre la configuration 3 et la configuration stan-
dard
Remarque : Pour la structure de MINST, la configuration moitié
Gabor-moitié entraînable dans la 2ème couche est optimale. Pour d’autres
réseaux avec d’autres structures, la configuration optimal serait dif-
férente ( i=9 au lieu de 6 par exemple).
4. Filtres de Gabor dans les DCNNs (deep CNN)
L’utilisation des filtres de Gabor pour des CNN plus larges et plus com-
plexes, de type [1024x3 (5x5)192c 160fc (3x3)p (5x5)192c 192fc 192fc
(3x3)p (3x3)192c 192fc 10s] avec c=couche convolutive, fc: couche FC,
p: couche POOL, et s: sortie. Ce réseau est composé de 3 blocs de
couches convolutives composées de 192 filtres. L’utilisation des filtres
de Gabor directement dans les couches convolutives (dans les 2/3 des
192 couches convolutives) optimise efficacement l’énergie, la mémoire et
le temps de l’entrainement, mais cause une perte de 3% en précision.
Ce problème peut être mitigé en entrainant partiellement les filtres de
Gabor: permettre aux filtres de Gabor de s’entrainer pour quelques
itérations (20% du nombre total des cycles d’entrainement par exem-
ple). Ces filtres apprennent rapidement et convergent en quelques cycles
d’entrainement seulement.
8Figure 8: Comparaison entre les différentes configurations
d’entrainement
5.3 Filtres de Gabor dans différentes architectures
Afin de démontrer l’avantage des filtres de Gabor, les CNNs formés selon
la 3ème configuration sont implémentés dans l’entrainement de différentes
datasets: MNIST,Face-NonFace (reconnaissance des visages)et TICH. Ces
datasets ont des architectures différentes.
Figure 9: architecture des CNNs utilisés pour l’expérience
95.4 Résultats
A.Précision :
Figure 10: Comparaison de la précision des CNN conventionnels et des CNNs
formés selon la 3ème configuration
Remarque: On remarque que pour la dataset Face-NonFace, la précision
de la classification augmente après l’utilisation des filtres de Gabor: les filtres
de Gabor détectent mieux les bords et les orientations, ce qui rend la tache
de détecter des visages plus facile.
B.Optimisation d’énergie :
Figure 11: Comparaison de la consommation d’énergie des CNNs conven-
tionnels et des CNNs formé selon la 3ème configuration
10C.Optimisation de mémoire
Figure 12: Comparaison de la consommation de mémoire des CNNs conven-
tionnels et des CNNs formé selon la 3ème configuration
D.Réduction du temps d’entrainement
Figure 13: Comparaison du temps de l’entrainement des CNNs convention-
nels et des CNNs formé selon la 3ème configuration
6 Réseaux convolutifs de Gabor
Les auteurs de [2] présentent un nouveau modèle pour les DCNNs ( Deep
Convolutional Neural Network), en intégrant les filtres de Gabor dans toutes
les couches convolutives afin d’améliorer la capacité des filtres à détecter les
rotations et les variations d’échelle. Dans cette partie on va étudier ce modèle
noté GCN ( Réseau convolutionel de Gabor) et comparer ses performances
aux CNNs.
116.1 Filtres convolutifs de Gabor (GoF)
Après l’entrainement du réseau, on convolue les filtres entrainés avec des
filtres de Gabor de U directions différentes et de V échelles, pour créer des
filtres convolutifs de Gabor. Soit une couche entrainé de taille N*W*W avec
W*W la taille des filtres 2D et N le nombre de filtres utilisés. On obtient les
filtre convolutifs de Gabor associé(GoF) en convoluant cette couche avec U
filtres de Gabor suivant la relation suivante:
Civ = (Ci,1
v v
, ...Ci,U v
) tel que Ci,u = Ci,o ◦ G(u, v)
avec :
• Ci,o un filtre entrainé ,
• ◦ le produit élément par élément .
• G(u,v) filtre de Gabor de direction u et d’échelle v
• Civ : GoF
La figure 14 explique graphiquement cette relation :
Figure 14: Construction d’un GoF à partir d’une banque de filtres de Gabor
de 4 directions, et de 4 filtres entrainés de taille 3 ∗ 3.
Explication: Dans cet exemple, le 1er filtre à gauche du GoF est le produit
des 4 filtres 2D de taille 3*3 avec le 1er filtre de Gabor, de la banque utilisée,
de taille 3*3, résultant un filtre 3D de taille 4*3*3. Ainsi le GoF construit
est de taille 4*4*3*3 ( car 4 filtres de Gabor sont utilisés).
126.2 Convolution dans un réseau convolutif de Gabor
Comme déjà expliqué, les filtres dans un réseau convolutionnel de Gabor sont
remplacé par les GoF(filtres convolutifs de Gabor). Les convolutions se font
alors avec les GoFs.
Figure 15: Convolution d’un GoF avec 4 canaux
Les canaux de F̂ se calculent à partir de la relation:
N
X (n)
F̂i,k = F (n) ◦ Ci,u=k
n=1
ou (n) réfère au n ème canal de F et de Ci,u .
Explication: Dans la figure 15, le 1er canal de F est la somme des convolu-
tions du 1er canal de F avec tous les filtre 2D du 1er filtre 3D (à gauche) de
GoF.
6.3 Effet des paramètres de la banque de Gabor sur la
précision des résultats
La banque de filtres de Gabor utilisée pour générer les GoF a 2 paramètres:
• U: Nombre de directions = Nombres de filtres de Gabor utilisés
• V: Nombre d’échelles= nombre de couches convolutives du CNN.
La précision des résultats obtenus à partir de l’entraînement d’un réseau
convolutif de Gabor sur la dataset MNIST en changeant les paramètres U et
V est affichée dans les tableaux 16 et 17:
Figure 16: Précision (%) en fonction de U.
13Figure 17: Précision (%) en fonction de V.
Explication: Pour V=4, on obtient un taux d’erreur plus petit que celui
pour V =1. En plus, le GCNs a une meilleure performance pour U entre 3
et 6.
6.4 Implémentation et expérience
Dans cette partie, on évalue la performance des réseaux convolutifs de Gabor
sur la dataset MNIST, et sur sa version ayant subi des rotations aléatoires
d’un angle entre 0 et 2pi: MNIST-rot. Pour cela, on utilise un GCN de
4 directions ( U=4), et 4 couches convolutives(V=4), et le compare aux
performances d’un CNN de 4 couches convolutives et des filtres de taille 3*3.
Remarque: Le nombre de paramètres pour un GCN est proportionnelle
avec le carré de l’épaisseur des couches convolutives, c’est pour cela que la
complexité d’un GCN est plus petite par rapport aux CNNs.
Figure 18: Comparaison des résultats sur la dataset MNIST
Commentaire: GCN avec des filtres 3*3, a de meilleures performances que
CNN (0.63 % de taux d’erreurs pour MNIST et 1.45% pour MNIST-rot), on
utilisant 1/12 paramètres seulement. On remarque que les GCNs avec des
filtres de 5*5 ou 7*7 atteignent des taux d’erreurs plus bas, et sont donc plus
performants. On explique cela par le fait que les filtres de plus grande taille
portent plus d’informations et donnent donc de meilleurs résultats.
147 Filtres de Gabor pour une meilleure recon-
naissance vocale
Les auteurs de [3] proposent la même architecture que celle expliquée dans la
partie 5, afin d’améliorer la reconnaissance vocale. Pour montrer l’avantage
de l’architecture proposée, on compare sa performance sur Aurora 4 à celles
d’un CNN normal et d’autres méthodes utilisée pour la reconnaissance vocale
notamment PNCC.
La dataset Aurora 4 contient des sons propres (sans bruit) et des sons
bruités. Les sons propres ont été enregistrés par 83 personnes utilisant 1
seul microphone/personne. Les sons bruités ont été enregistrés par le même
nombre de personnes utilisant 2 microphone à la fois, et ont été bruités
aléatoirement par 6 types de bruit( voiture, train. . . ). Pour l’expérience, les
voix de 8 personnes ont été utilisées, pour donner 4 types de sons:
• type A: son propre
• type B: son bruité
• type C: son propre avec distorsion de microphone
• type D: son bruité avec distorsion de microphone
Pour montrer l’avantage de cette architecture, on compare ses perfor-
mances à celle d’un CNN sans filtres de Gabor, et à d’autres méthodes sou-
vent utilisées pour la reconnaissance de la voix: PNCC par exemple.Le CNN
contient 120 filtres , et un POOL layer qui réduit la dimension par un facteur
de 2. En ce qui concerne l’architecture proposée, on utilise la même archi-
tecture du CNN sauf pour les filtres dont 59 filtres ont été initialisées comme
étant des filtres de Gabor et 61 filtres ont été initialisés aléatoirement. Le
tableau 19 montre que le l’architecture proposée est meilleure: taux d’erreur
de 16.6%.
Figure 19: Taux d’erreurs des différentes architectures
158 Conclusion
Dans cet article, nous avons montré l’importance de l’utilisation des filtres
de Gabor dans les CNNs, afin de mimiser l’énergie, la mémoire et le temps
consommés lors de l’entrainement des CNNs. Nous avons également expliqué
le role de ces filtres dans l’amélioration des résultats des CNNs en réduisant
le taux d’erreurs, et nous avons illustré cela par une application courante :
la reconnaissance vocale.
9 Remerciements
Ce travail de recherche effectué dans le cadre du module de l’initiation à
la recherche en laboratoire, lors du 4ème semestre du cycle ingénieur à
Grenoble-INP ENSIMAG, m’a permis de découvrir le monde de la recherche
scientifique, et d’apprendre d’une façon différente de la méthode classique.
Je souhaiterais donc remercier Mr Stéphane Mancini, d’avoir accepté d’etre
mon encadrant lors de ce projet, et de m’avoir guidée durant tout le 4ème
semestre afin de produire ce travail.
10 Références
[1] R. Kaushik, "Gabor filter assisted energy efficient fast learning convolu-
tional neural networks" IEEE 2017
[2] S.Luan et al., " Gabor convolutional networks" 2017 ,arXiv:1705.01450
[3] M. Nelson , " Robust CNN-based Speech recognition with gabor filter
kernels" EECS Department, Unuversity of California-Berkeley.
[4] [online] http://cs231n.stanford.edu/2016/
[5] G. Hinton et al., "Deep neural networks for acoustic modelling in
speech recognition: The shared views of four researchgroups", Signal Pro-
cessing Magazine IEEE, vol. 29, no. 6, pp. 82-97, 2012.
[6] P. Panda et al., "Invited-Cross-layer approximations for neuromorphic
computing: from devices to circuits and systems", Proc. of the 53rd DAC.
ACM, 2016.
[7] S. Chetlur et al., "cuDNN: Efficient primitives for deep learning", ar
Xiv preprint arXiv:1410.07592014.
[8] T. Liu et al., "Implementation of training convolutional neural net-
works", arXiv preprint arXiv:1506.01195 2015.
[9]G. S. Budhi et al., "The use of Gabor filter and back-propagation neural
network for the automobile types recognition", 2nd International Conference
SIIT, 2010.
1611 Annexe
11.1 Représentation matricielle d’une image:
On représente une image par une matrice. Dans le cas des images de la
dataset CIFAR-10, on représente une image par une matrice M32,32,3 ( ou
M3072,1 ). Un pixel d’une image est constitué de 3 couleurs : rouge, bleu et
vert; d’ou la dimension 3 dans la représentation matricielle.
11.2 Algorithme du voisin le plus proche ( Nearest neigh-
bour):
Pour détecter le contenu d’une image: chat, chien ou voiture par exemple, une
méthode naïve serait de construire une base de donnée de plusieurs images de
chats, chien et de voiture; et de trouver l’image de la dataset la plus proche
à notre image. Cet algorithme s’appelle l’algorithme du plu proche voisin.
11.3 Classifiant linéaire :
Dans cet algorithme, on a pas besoin de toute la base de donnée comme
dans l’algorithme précédent. On a uniquement besoin d’un vecteur W qu’on
nomme le poids, et d’un vecteur B qu’on appelle le biais. Pour détecter le
contenu de notre image représentée par la matrice X, on calcule f (X, W ) =
W X + B. Dans le cas de CIFAR-10, X est une matrice M3017,1 , W est
M10,3072 et B est M10,1 . f(X,W) est donc une matrice M10*1 représentant le
score des 10 classes de la dataset. Le contenu de l’image est donc la classe
de plus grand score.
X———> f (X, W ) = W X + B (scores des différentes classes)
Remarque: f est dite fonction d’activation.
11.4 Fonction de perte et optimisation:
La fonction de perte (ou loss function en anglais) est une fonction mathéma-
tique qui donne le vecteur W résultant la meilleure classification. On choisit
donc W qui minimise la fonction de perte.
1711.5 Réseau neuronal :
Un réseau neuronal est une collection de neurones connectés entre eux.
Figure 20: Réseau neuronal à 2 couches
Remarque:
• Les neurones de la même couche ne sont pas reliés
• On ne compte pas la couche d’entrée.
• Un réseau neuronal à une seule couche = la sortie est directement liée
à l’entrée ( pas de couche cachée)
• Le classifiant linéaire est donc un réseau neuronal à 1 seule couche
11.6 Caractéristiques d’un réseau neuronal:
On peut caractériser un réseau neuronal par le nombre de paramètres, les
poids et les paramètres apprenables.
Le nombre de paramètres = le nombre de neurones de toutes les couches
sauf la couche d’entrée. Dans l’exemple de la figure 20, on a 4+2= 6
paramètres.
Les poids = nombre de relations entre les neurones de toutes les couches
sauf la couche rentrée. Dans l’exemple de la figure 20, on a (3*4) + (4*2)=
20 poids
Les paramètres apprenables= Nombre de paramètres + Nombre de poids.
Dans cet exemple, on a 20+6= 26.
1811.7 Modèle du neurone :
On peut modéliser un neurone par un classifiant linéaire: un neurone peut
s’activer ( activation proche de 1) ou ne pas s’activer ( activation proche de
0) en fonction de ce qu’il reçoit en entrée. Les fonctions d’activation les plus
connues sont :
1. sigmoïde:
Figure 21: Fonction sigmoide
Cette fonction est très peu utilisée car elle présente 2 désavantage sig-
nificatifs :
• Elle sature le gardient: Comme la fonction sature vers 0 et1, le gra-
dient est presque nulle aux alentours de ces valeurs. Conséquence:
Durant la rétro-propagation, le signal transmis par le neurone précé-
dent est "tué" lorsqu’on fait le produit avec le gradient local.
• Elle n’est pas centrée sur 0: cela impacte la dynamique de la rétro-
propagation.
2. TanH :
19Figure 22: La fonction tanH
Cette fonction est préférée à la sigmoïde , car elle présente les mêmes
caractériqtues que la sigmoïde mais centrée sur 0.
3. ReLU:
Figure 23: La fonction ReLU
Cette fonction est très utilisée ces dernières années car elle offre de
bonnes performances lors de l’apprentissage :
• Elle améliore la convergence du gradient.
• Elle est moins couteuse en calcul. Les fonctions tanH et sigmoïde
nécessitent des calculs complexes.
11.8 Exemple de réseaux de neurone
On considère le réseau neuronal suivant:
Figure 24: Réseau neuronal à 3 couches
20Matriciellement, on peut représenter la couche d’entrée par X=M3,1 ,la
1ère couche cachée par un vecteur W1 = M4,3 et son biais B1= M4,1 , la 2ème
couche cachée par W2= M4,4 et son biais B2= M4,1 , et la couche de sortie
par W3=M1,4 , et son biais B= M4,1 .
Soit f la fonction d’activation des 2 couches cachées ( sigmoide par exemple),
dans ce cas on a :
h1= f(W 1 ∗ X + B1) = M4,1
h2=f(W 2 ∗ h1 + B2 = M4,1
sortie = W 3 ∗ h2 + B
Remarque: Pour la sortie, on calcule directement W3*h2+B, sans
fonction d’activation.
21Vous pouvez aussi lire