Change the game with smart innovation
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Change the game with smart
innovation
Master Thesis 2012 – 2013 Faculty of
29/02/2012
Science engineering
Master Thesis proposal for the academic year 2012-2013. This document covers four main
topics: (1) distributed graph processing, (2) Distributed Processing, (3) Cloud and (4) Social
Enterprise.
CONTENTS
Section Un Introduction 3
EURA NOVA R&D 3
Section Deux Mémoires 2012-2013 4
Distributed Graph processing – Social Networks 4
Etude comparative des plateformes distribuées de stockage et de traitement de
graphes 5
Etude et Implémentation d’un entrepôt de donnée orienté graphes en tuilisant les
frameworks et techniques de traitement de graphes distribués 7
Proposition d’une GraphDB « in-memory » distribuée sur data grid 8
Distributed Processing – Big Data 10
Etude et comparaison des évolutions de Map Reduce pour le traitement de grands
volumes de données 10
Etude et comparaison frameworks de traitement distribué de données 11
Etude et implémentation d’un éditeur de Framework DFG pour le traitement de grands
volumes de données sous Eclipse 12
SQL MR, VOLTDB, MYSQL CLuster 7.2, ... La réponse des rdbms à la mouvance
nosql ? 14
Cloud 16
Etude et conception d’un framework de gouvernance cloud – Intégration d’ITIL 16
Etude et implémentation d'un gestionnaire distribué de topologie de service pour un
service de messagerie elastique. 18
Social Enterprise 20
Définition et étude d’un nouveau modèle de gestion des process en ligne avec les
problématiques de l’entreprise 20
Réferences 22
SECTION UN
INTRODUCTION
EURA NOVA R&D
EURA NOVA est une société Belge s’appuyant notamment sur une perception
constituée depuis le 1er Septembre 2008. entrepreneuriale de la carrière.
Notre vision est simple: « Être un
incubateur technologique focalisé sur Nous proposons ici des mémoires dans
l’utilisation pragmatique des notre département Recherche &
connaissances ». Développement. L’étudiant travaillera en
collaboration avec les ingénieurs de
Les activités de recherche sont associées recherche et sera amené à partager ses
à des voies technologiques et à des travaux à travers l’outil de gestion de la
opportunités concrètes sur le court, moyen connaissance utilisé en interne par EURA
et long terme. EURA NOVA découple la NOVA.
gestion de carrière de la relation client en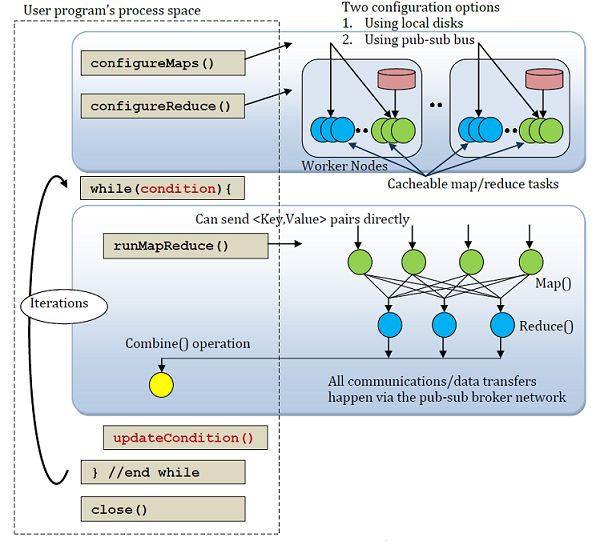
SECTION DEUX MÉMOIRES 2012-2013 DISTRIBUTED GRAPH PROCESSING – SOCIAL NETWORKS
ETUDE COMPARATIVE DES PLATEFORMES DISTRIBUÉES
DE STOCKAGE ET DE TRAITEMENT DE GRAPHES
Contexte : Dans le contexte du Web 2.0, les réseaux sociaux sont devenus le quotidien des
internautes, comme moyen de partage et de diffusion de l'information. De ceci, les quantités des
informations n’ont pas cessé d’accroitre dans les réseaux sociaux : en nombre d’utilisateurs,
informations par utilisateurs et interaction en utilisateurs. De point de vue computationnel, les
graphes forment la structure la plus adaptée pour modéliser un réseau social. Par ailleurs, les
algorithmes classiques de traitement de graphes n’étaient pas conçus pour gérer des très grands
graphes (plusieurs centaines de millions de noeuds). Afin de permettre le passage à l’échelle de ces
algorithmes, un certains nombres des outils open-sources ont été proposés récemment (Apache
Giraph, Apache Hama, GoldenOrb, Twister, Haloop…). Néanmoins, jusqu’à présent, il n’y a aucune
étude faite pour comparer ces différentes plateformes et déterminer les avantages et les
inconvénients de chacune. Ce problème apparait aussi dans les nouvelles solutions de stockage de
graphes (Neo4j, OrientDB, FlockDB…).
Figure 1 (a) un réseau social à analyser. (b)le modèle de distribution de Pregel de Google.
Contribution : Le mémoire sera organisé en deux parties :
1. La première partie consiste à (2) étudier les différentes plateformes de base de données
orientées graphe (3) définir un ensemble de patterns de comparaison à travers une série
d’expérimentations et de validation théoriques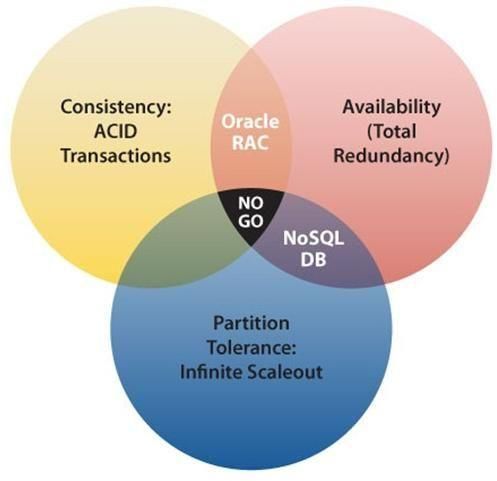
2. La deuxième partie traitera la comparaison des plateformes distribuées de traitement de
graphes à travers différents algorithmes de graphe. La conclusion de cette partie permettra
aux futurs utilisateurs de choisir la solution la plus adaptée selon les besoins (temps de
calcul, type d’algorithmes …).
Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D.
L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D.
ETUDE ET IMPLÉMENTATION D’UN ENTREPÔT DE
DONNÉE ORIENTÉ GRAPHES EN TUILISANT LES
FRAMEWORKS ET TECHNIQUES DE TRAITEMENT DE
GRAPHES DISTRIBUÉS
Contexte : Très récemment Google et Microsoft Research se sont associé pour publier ensemble des
travaux sur l’application des techniques traditionnelles de data warehouse sur des entrepôts de
graphes *15+. Ce travail trahit l’importance capitale du « graph mining » aujourd’hui, que ce soit en
marketing pour des modèle de d’adoption de nouveaux produits ou biochimie pour la conception de
nouveaux médicament ou l’analyse de tendances dans les réseaux sociaux. Cependant, le travail
mené par Google et MSF ne considère que le traitement centralisé et utilise les techniques
traditionnelles d’optimisation des data warehouse pour la matérialisation partielle des données.
Dans ce mémoire nous proposons d’utiliser les framework de traitement de graphe distribué pour
palier à ces limitations.
Figure 2 Dashboard de mining de graphes.
Contribution : L’objectif de ce mémoire est (1) d’étudier le project GraphCube, (2) d’étudier un
framework de graphe distribué comme Apache Giraph, (3) de proposer une implémentation
distribuée de GraphCube.
Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D.
L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D.
PROPOSITION D’UNE GRAPHDB « IN-MEMORY »
DISTRIBUÉE SUR DATA GRID
Contexte : Les grands graphes sont devenus une source importante de recherche. Aujourd’hui ils se
retrouvent dans de nombreux domaines. Dans le contexte du Web 2.0, les réseaux sociaux sont
devenus le quotidien des internautes, comme moyen de partage et de diffusion de l'information. De
ceci, les quantités des informations n’ont pas cessé d’accroitre dans les réseaux sociaux : en nombre
d’utilisateurs, informations par utilisateurs et interaction entre utilisateurs. Du point de vue
computationnel, les graphes forment la structure la plus adaptée pour modéliser un réseau social.
Dans le contexte biomédical, les réseaux biochimiques sont définis par un graphe d’interaction entre
protéines, les catalyseurs et inhibiteurs, ces protéines étant codés par des gènes. Ces interactions
forment un gigantesque graphe qui doit être analysé dans différent domaines : conception de
médicaments, analyse génétiques, etc.
Figure 3 le traitement et l’analyse de réseaux sociaux en temps réels nécessitent de nouvelles
approches. Les grilles données sont très récentes mais peuvent représenter une alternative
très intéressante.
Très récemment de nouveaux Frameworks de graphes distribués sont apparus, notamment sous
l’impulsion de Google et de Pregel (utilisé pour l’indexation de pages web). Cependant tout ces
Frameworks stockent les nœuds et arcs dans un système de fichier. D’autre part, de nouvelles génération de cache distribuées commencent à apparaitre, les data grid (JSR 347). A la différence des caches traditionnelles elles offrent des fonctions d’indexation, de distribution de données, d’API type SQL et OQL, une API pour contrôler le groupement d’objets et surtout une interface pour le traitement distribué type map reduce. Ces nouvelles génération de cache nous offre un nouveau et formidable terrain de jeux pour implémenter un système de stockage et de traitement de graphes en mémoire. Contribution : l’objectif de ce mémoire est (1) d’étudier INFINISPAN (data grid open source), (2) de proposer un modèle d’objet pour les graphes, (3) de proposer une API graphes en s’inspirant de Neo4J et (4) d’implémenter un prototype. En fonction de l’état du prototype l’étudiant pourra effectuer des tests de comparaison avec les solutions de stockage traditionnelles. Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D. L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D et ses experts en traitement de graphes et distribution de données.
DISTRIBUTED PROCESSING – BIG DATA
ETUDE ET COMPARAISON DES ÉVOLUTIONS DE MAP
REDUCE POUR LE TRAITEMENT DE GRANDS VOLUMES
DE DONNÉES
Contexte : Le célèbre MapReduce de Google est désormais incontournable lorsque l’ont évoque le
traitement en batch distribuée de grands volumes de données. Cependant, les seules phases de map
et de reduce étant limités pour une série de domaines d’application, des évoluons du concept de
base sont apparues au cours du temps. Nous pouvons principalement cité : les version itératives
(Perigrine project), l’optimisation des scheduler (de Facebook et Standford, Disco de Nokia
Research), notamment en améliorant le concept de co-location, et l’intégration au stream processing
via le Stream map reduce[2].
Figure 4 vue haut niveau dun map reduce iterative[3].
Ces différentes versions rendent difficile le choix du Framework pour data manager, quelles sont les
spécificités de chacun? Sont-ils plus adaptés à certains types de traitements ? Sont-ils applicables sur
les mêmes ensembles d’algorithmes ? L’objectif de ce mémoire est de répondre à ces questions en
définissant une taxonomie de ces Frameworks et en expérimentant chacun d’eux sur un cluster.Contribution : L’objectif du mémoire est (1) de lister et d’étudier les principales variantes de map
reduce à travers les projets open sources et papiers scientifiques, (2) de les tester sur le cluster de
l’ULB et/ou d’EURA NOVA, et de (3) proposer une taxonomie de ces variantes.
Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D.
L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D avec nos experts en traitement de
données distribuées.
ETUDE ET COMPARAISON FRAMEWORKS DE
TRAITEMENT DISTRIBUÉ DE DONNÉES
Contexte : Mapreduce s’est imposé comme le Framework de distribution de traitement de doonées
incontournable, principalement car il a été porté et popularisé par Yahoo ! Cependant, le but de
simplification extrême de MapReduce le rend totalement inefficaces pour certaines problématiques.
Dans un mémoire réalisé à l’ULB en 2010-2011, nous avons montré que d’autres paradigmes
pouvaient se révéler beaucoup adapté dans certaines circonstances. Ce mémoire s’est concentré
principalement sur l’étude de Dryad *4+ et sa comparaison avec MapReduce, mais d’autres
alternatives de choix existent.
Figure 5 The Spark project [6]
L’objectif de ce mémoire est d’étudier et d’expérimenter les alternatives à Mapreduce comme Dryad
de Mircrosfot research *4+, Spark de UC Berkeley *6,7+, Transformer de l’Académies des Sciences
Chinoise, Storm de Backtype et twitter [8,9], etc.
Contribution : L’objectif de ce mémoire (1) d’étudier Dryad, Transformer et Spark (2) de rechercher
d’autres alternatives possibles, (3) d’expérimenter ces Frameworks sur les clusters de l’ULB et/ou
d’EURA NOVA et (4) de proposer une taxonomie de ces Frameworks.Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D.
L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D.
ETUDE ET IMPLÉMENTATION D’UN ÉDITEUR DE
FRAMEWORK DFG POUR LE TRAITEMENT DE GRANDS
VOLUMES DE DONNÉES SOUS ECLIPSE
Contexte : Les DFG (Data Flow Graph) sont des Frameworks de traitement de données distribués qui,
à l’instar de MapReduce qui ne présente qu’une phase map et reduce, présentent un graphe comme
expression des traitements à effectuer. Les DFG sont donc beaucoup plus flexibles que leurs cousins
MR et permettent une définition plus large du traitement de données. Cependant leurs éditions n’est
pas simples et demande parfois une réflexion intense afin de représenter le graphe de traitement.
Dans ce mémoire nous proposons d’implémenter un éditeur sous Eclipse en utilisant les techniques
récentes d’ingénieries des modèles. Cet éditeur sera utilisé pour la définition et le déploiement sur
un cluster de job Naiad, la version open source de Dryad, implémenté dans le cadre d’un mémoire
précédent.
Figure 6 exemple de libraire graphique sous Eclipse pour la conception d’éditeur de workflow
(Graphiti, développé par SAP)Contribution : L’objectif de ce mémoire (1) d’étudier Dryad et notre implémentation open source, (2) d’étudier EMF et les concepts de base de l’ingénierie des modèles, (3) de proposer un éditeur graphique de job Naiad (4) d’écrire un générateur ou assembleur de code pour le job à déployer. Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D. L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D, nos experts en modèles et en processing distribué.
SQL MR, VOLTDB, MYSQL CLUSTER 7.2, ... LA RÉPONSE
DES RDBMS À LA MOUVANCE NOSQL ?
Contexte : Ces dernières années ont vu se développer la mouvance des bases de données dites
NoSQL (Not Only SQL) dont les principaux contributeurs ne sont autres que les grands acteurs issus
du monde des réseaux sociaux : Facebook pour Cassandra, Twitter pour HBase, LinkedIn pour
Voldemort, etc... La mouvance NoSQL préconise une relaxation des contraintes par rapport au
modèle ACID relationnel (RDBMS) et ce afin de pouvoir assurer une meilleure scalabilité vis-à-vis de
la quantité de données traitées [17]. Le modèle NoSQL permet ainsi des schémas de données plus
souples, ou plus simplifiés et le plus souvent des garanties de consistance et transactionnalité
variables dans le but de pouvoir assurer une scalabilité au niveau des données. Les process utilisés
sur ces bases de données concernent par exemple l'élaboration de statistiques sur l'usage du réseau
social (analytics) ou le stockage de données principalement accédées en lecture.
Figure 7 Le théorème CAP, à la base
de la mouvance NoSQL
Néanmoins, le relâchement de contraintes sur la consistance, la transactionnalité et le modèle de
données ne peuvent souvent pas convenir pour des applications business critiques dans lesquelles
Illustration
les garanties ACID et relationnelles sont primordiales 1:
[18].
Après une vague d'engouement pour le NoSQL, les acteurs du monde des DBs reviennent à présent à
la charge sur bases des expériences acquises par les DB NoSQL et proposent à présent des DBs
garantissant le modèle relationnel tout en incorporant les avantages et la souplesse des bases de
données NoSQL.
Dans ce mémoire, nous proposons d'étudier cette évolution du modèle RDBMS et de dégager les
nouveaux cas d'utilisations qui peuvent en être faits.Contribution : l'objectif de ce mémoire est (1) d'étudier les nouveaux modèles de bases de données relationnelles incorporant les concepts et innovations des NoSQL (2) d'étudier la valeur ajoutée des ces nouvelles DBs par rapport aux DBs traditionnelles et d'évaluer la performance de quelques solutions sur un problème canonique (benchmark). Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec Euranova R&D. L’étudiant sera accompagné par l’équipe d’Euranova R&D.
CLOUD
ETUDE ET CONCEPTION D’UN FRAMEWORK DE
GOUVERNANCE CLOUD – INTÉGRATION D’ITIL
Contexte : les premiers grands déploiements cloud commencent à apparaitre dans le paysage IT des
entreprises, mais l’euphorie de la nouveauté à vite fait place à la complexité de la gestion de ce type
d’infrastructure. C’est pourquoi les constructeurs débutent le déploiement de système de gestion de
ressources et d’orchestration de processus de configuration et de provisioning. Nous touchons là à
une problématique de gouvernance. Les systèmes de gouvernance cloud actuels possèdent encore
un grand nombre de limitations : ils sont loin de couvrir une gouvernance « end-to-end », ils ne
répondent à aucune interfaces- standard, ils n’intègrent pas des standard d’organisation IT comme
ITIL, etc.
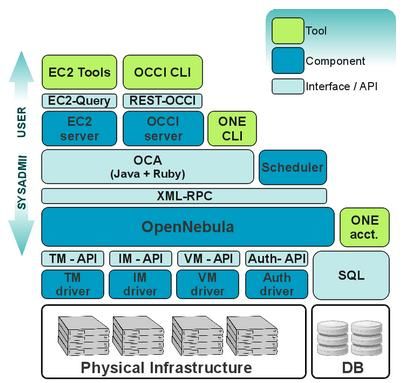
Figure 8 L’architecture OpenNubla [1].
Le but de ce mémoire est donc de définir comment implémenter une telle gouvernance. L’étudiant
devra étudier les modèles de gouvernance IT existant et définir dans quelless mesures ils peuvent
être appliqués au monde cloud. D’un autre côté, l’étudiant devra étudier l’architecture des
infrastructures cloud afin de définir quelles extensions sont nécessaires afin d’implémenter les
fonctionnalités de gouvernance définies par la première partie du mémoire. Enfin, l’étudiant
réalisera un prototype en implémentant quelques processus de provisioning sur le projet cloud
Open Source OpenNebula.Contribution : L’étudiant devra (1) étudier les standards de gouvernance existant, (2) étudier les infrastructures cloud et leurs architectures, (3) définir l’impact de la gouvernance sur l’architecture cloud et de proposer une extension possible et (4) implémenter un prototype sur OpenNebula. Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D. L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D avec nos experts cloud et nos experts IT standards.
ETUDE ET IMPLÉMENTATION D'UN GESTIONNAIRE
DISTRIBUÉ DE TOPOLOGIE DE SERVICE POUR UN
SERVICE DE MESSAGERIE ELASTIQUE.
Contexte : Dans l'architecture orientée évènement (Event-Driven Architecture), le bus de message
joue un rôle central en véhiculant les évènements de manière asynchrone et permet un couplement
faible entre les acteurs. Les produits de messagerie actuels (Message Oriented Middleware – MOM)
sont principalement basés sur une architecture de type cluster. Ce type d'architecture montre
néanmoins des limitations quant à la scalabilité en termes d'agents concurrents, de messages
envoyés simultanément et de dynamisme des connexions [19]. Or, le déploiement d'applications EDA
à grande échelle sur le cloud doit passer par la scalabité du bus de messages.
Illustration 2: Le bus de messages
joue un rôle central en EDA
Dans le cadre d'un projet interne, Euranova R&D a développé EQS (Elastic Queue Service) [20], un
prototype de service de messagerie basé autour d'une architecture entièrement distribuée et
déployable sur une infrastructure de type cloud computing. Dans ce premier protoype, l'élasticité
(propension du service à réguler sa capacité en démarrant ou éteignant de nouvelles instancess) et la
gestion de la topologie (gestion des ressources actives, rééquilibrage de la charge du service) sont
gérés de manière monolithique ou délégués à des services tiers de gestion de plateforme cloud (ex :
Scalr, Rightscale, ...)
Le but de ce mémoire est d'étudier les gestionnaires distribués de topologie de différents services
cloud existant. L'étude de ces gestionnaires devra permettre de proposer une architecture de
gestionnaire de topologie adaptée à EQS, le prototype développé par Euranova R&D, et déployable
sur cloud.
Contribution : L'objectif de ce mémoire est (1) d'étudier les architectures de gestionnaires de service
et de topologie existants, (2) de proposer une architecture distribuée de gestionnaire de topologiepour le prototype EQS et (3) de tester et valider cette architecture en situation réelle sur une infrastructure cloud. Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec Euranova R&D. L’étudiant sera accompagné par l’équipe d’Euranova R&D.
SOCIAL ENTERPRISE
DÉFINITION ET ÉTUDE D’UN NOUVEAU MODÈLE DE
GESTION DES PROCESS EN LIGNE AVEC LES
PROBLÉMATIQUES DE L’ENTREPRISE
Contexte : Dans le contexte du « one process for everything » ambiant dans les entreprises actuelles,
les rôles des process sont répartis, souvent en suivant un modèle du type « ITIL », cependant tous les
acteurs ne sont pas certifiés ITIL ou bien conscient de l’intérêt de la certification ISO 20000, les
retombées en sont multiples :
Certaines personnes ne savent pas qu'elles font partie d'un (ou plusieurs) process
Certains process existent mais personne ne le sait
Des process sont tellement complexes que le jeu à la mode devient "Comment faire sans
suivre le process ?"
Des process existent mais sans réel moyen de contrôle, ni de gouvernance
Figure 9 JBPM weg designer
D’un autre côté, ces dernières années, le milieu de l’entreprise as vu émerger un concept tout à fait
intéressant venant du monde internet, la social Enterprise. L’idée est de transposer l’activité de
collaboration et de partage d’information des réseaux sociaux au monde de l’entreprise. Ce travail de
fin d’étude vise à appliquer le modèle de collaboration sociale à la gestion efficace des process.Figure 10 Acitity framework for process and task management
Dans ce mémoire nous allons aborder deux principaux aspects. D’abord l’étudiant devra comprendre
ce qui empêche l’adhésion de tous aux process, et définir ce qu’est un « bon process » (simplicité de
mise en place, de compréhension et de contrôle), de définir un nouveau cadre de gestion simple,
communiquant et intuitif pour permettre à tout un chacun de comprendre son rôle dans le process,
de voir la valeur ajoutée de l’utilisation d’un process plutôt que d’essayer de le contourner, tout en
permettant au management d’avoir une vue claire sur leur évolution et performance.
Le deuxième aspect sera plus pratique, l’étudiant devra appliquer ce nouveau cadre dans la création
d’un outil de gestion collaborative des process, visant à :
Simplifier la création des process
Permettre à chacun de retrouver son rôle et ses actions
Fournir une plateforme de communication efficace pour les utilisateurs des process
Permettre le contrôle et l’analyse des process via des dashboards
Permettre la visualisation du fonctionnement d’un process en cours d’utilisation, et de suivre
son exécution.
Cet outil devra être réalisé sous forme d’un portail social Enterprise dans lequel l’étudiant définira en
fonction des différents rôles, différentes perspectives d’outils et de Dashboard qui permettront une
création de process collaborative.
Contribution : L’objectif de ce mémoire est (1) d’étudier les mécanismes d’adhésion aux process et le
replacer dans un contexte de change Management, (2) d’étudier et concevoir une plateforme web
pour la gestion collaborative des process : (a) définition des rôles et accès, (b) architecture & design
mais aussi le choix du framework cible à étendre, (c) Implémentation, et enfin (3) validation auprès
d’acteurs de terrains au sein d’une multinational bancaire.
Organisation: ce mémoire est organisé par l’UNIVERSITÉ en collaboration avec EURA NOVA R&D.
L’étudiant sera accompagné par l’équipe d’EURA NOVA R&D.RÉFERENCES [1] OpenNebula web site, http://opennebula.org/documentation:archives:rel2.2:introapis [2] Andrey Brito, Andre Martin, Thomas Knauth, Stephan Creutz, Diogo Becker de Brum, Stefan Weigert, Christof Fetzer, Scalable and Low-Latency Data Processing with Stream MapReduce. CloudCom 2011: 48-58 [3]Twister blog, http://www.iterativemapreduce.org/ [4] Michael Isard and al., Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks, in European Conference on Computer Systems (EuroSys) 2007 [5] P. Wang and al., Transformer: A New Paradigm for Building Data-Parallel Programming Models, in MICRO IEEE 2010 [6] The Spark project, http://www.spark-project.org/ [7] Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. Spark: Cluster Computing with Working Sets, in USENIX HotCloud 2010. June 2010. [8] The Storm project, https://github.com/nathanmarz/storm/wiki [9] Storm - a Twitter project, http://engineering.twitter.com/2011/08/storm-is-coming-more-details- and-plans.html [10] Bolton, Ruth N., A Dynamic Model of the Duration of the Customer’s Relationship with a Continuous Service Provider: The Role of Satisfaction,” Marketing Science, 17 (1), 45-65. 1998 [11] Rust, Roland T. and Tuck Siong Chung, Marketing Models of Service and Relationships, Marketing Science, 25 (6), p. 560-580. 2006 *12+ Villanueva, Julian and Dominique M. Hanssens , “Customer Equity: Measurement, Management and Research Opportunities,” Foundations and Trends in Marketing, 1 (1) 1–95. 2007 [13] Nitzan I, Social Effects on Customer Retention, In Journal of Marketing , American Marketing Association 2011 [14] Eagle, Nathan, A. Pentland, and D. Lazer, Inferring Social Network Structure Using Mobile Phone Data, Proceedings of the National Academy of Sciences, 106 (36), 15274–15278. 2009 [15] Peixiang Zhao, Xialolei Li, Dong Xin, Jiawei Han. Graph cube: on warehousing and OLAP multidimensional networks, In SIGMOD - Proceedings of the 2011 International Conference on Management of Data.
[16] NoSQL, NewSQL and Beyond: The answer to SPRAINed relational databases, http://blogs.the451group.com/information_management/2011/04/15/nosql-newsql-and-beyond/
Vous pouvez aussi lire

















































