CHAPITRE 4: SONDAGES AREOLAIRES
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Sondages Aréolaires 1
CHAPITRE 4:
SONDAGES AREOLAIRES
Chapitre 4: Sondages Aréolaires
Les techniques de sondage permettent d'obtenir rapidement et à coût modéré,
une information pertinente sur la plupart des variables socio-démographiques
intéressant l'aménagement urbain. Ces propriétés prédisposent donc cette
approche à l'analyse de villes à forte croissance dans des pays pauvres.
L'efficacité des sondages peut être améliorée de nombreuses manières. On
développera ici une approche associant une stratification basée sur un critère de
morphologie urbaine dérivé des données SPOT, et une structuration en deux
niveaux utilisant des placettes définies sur photographies aériennes et des parcelles
analysées au cours d'une enquête par questionnaire. Les propriétés de la
stratification géographique et de l'estimation des densités sur photographies
aériennes feront l'objet de commentaires particuliers.
Le choix d'un critère de stratification sera justifié statistiquement, et les
avantages et inconvénients de diverses stratégies de sondage seront discutés, dans
l'optique d'une application opérationnelle.
Contrairement au chapitre précédent, les sondages n'ont pas donné lieu au développement
de nouvelles méthodes. L'originalité de notre recherche a d'avantage porté sur la manière
dont les nombreuses possibilités offertes par les techniques de sondage pouvaient être
exploitées dans le cadre des estimations de population urbaine dans les PVD.
Sondages Aréolaires 2
4.1 PRINCIPES ET UTILITE DES SONDAGES EN
GEOGRAPHIE DE LA POPULATION
A première vue, la meilleure connaissance de la population d'une ville devrait
provenir d'une analyse exhaustive de tous ses habitants, ou recensement. Pour-
tant, cette information n'est pas nécessairement exempte d'erreurs, dues entre au-
tres à la mauvaise application du questionnaire (incompréhension, mauvais report,
etc.), à l'oubli de certaines populations (dans les zones d'habitat spontané par
exemple) ou le plus souvent à la volonté de certains résidents de se soustraire au
dénombrement officiel. De plus, l'organisation pratique d'un recensement, sa mise
en oeuvre et son analyse sont si longs que lorsque les premiers résultats sont pu-
bliés, ils sont déjà dépassés, surtout lorsque les villes concernées évoluent rapi-
dement. Les coûts de ces opérations sont si élevés (1 milliard de Dollars pour le
recensement des USA en 1980, selon BRUGIONI [1983]) que la plupart des pays ne
peuvent même plus se conformer à la recommandation de recensement décennal
prônée par les Nations Unies. Un avantage décisif du recensement exhaustif réside
dans la possibilité de référencer géographiquement tous les individus, ce qui
permettrait une analyse spatiale fine des résultats (effets sociaux du "front de rue",
poches de pauvreté ou d'insalubrité au sein des quartiers, stratification verticale des
revenus dans les quartiers commerçants, etc.). Malheureusement, les résultats des
recensements ne sont généralement disponibles que agrégés au niveau de
secteurs statistiques dont la définition n'est pas toujours idéale, loin s'en faut.
Le principe de l'évaluation d'un ensemble au moyen d'un échantillon est très
couramment employé: on se forge une "opinion" sur quelques observations isolées.
De manière assez surprenante, l'usage des sondages est relativement récent pour
l'étude des populations humaines, puisque ces méthodes n'ont été utilisées
régulièrement que depuis la seconde guerre mondiale [DESABIE, 1965, page VII], alors
que les méthodes impliquées ont été développées au début du siècle.
Les principaux avantages de sondages sont une importante réduction des
coûts et des délais nécessaires. Cette réduction de coûts et de moyens permet
d'envisager l'application de questionnaires plus complets, mais aussi d'utiliser des
enquêteurs mieux formés et donc plus efficaces. Il est ainsi possible que l'utilité
opérationnelle d'une enquête par sondage, plus complète, mieux contrôlée, et
plus récente soit meilleure que celle obtenue par un recensement exhaustif de la
population.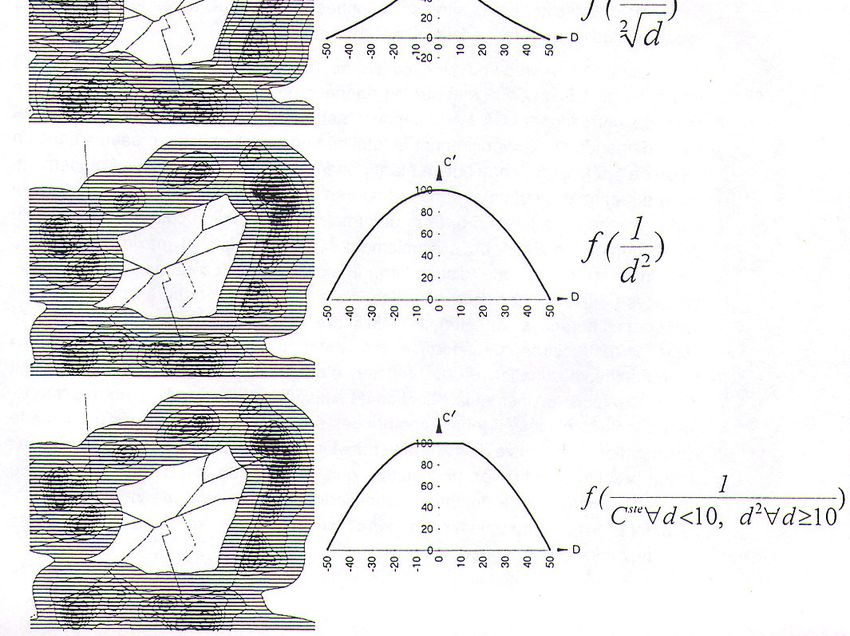
Sondages Aréolaires 3
Il existe une très grande variété de méthodes de sondage, parmi lesquelles il
convient de sélectionner une approche qui convienne bien au problème envisagé.
L'objectif de cette recherche ne portait pas sur les techniques de sondage; nous
nous sommes limité à évaluer, parmi l'éventail de méthodes disponibles, celles qui
semblaient le mieux adaptées à l'estimation des populations des quartiers des villes
dans les PVD. Cependant, le recours aux techniques de télédétection a permis de
définir des approches particulières, dont l'originalité sera soulignée dans le texte.
Pour l'essentiel, il s'agit d'utiliser une stratification basée sur la typologie des
quartiers déterminée sur les images SPOT, et d'appuyer les différents niveaux du
sondage sur des données à échelles emboîtées (satellite / photos aériennes /
enquête de terrain).
4.2 SONDAGES ALEATOIRES SIMPLES
Remarque: dans la première partie de ce chapitre essentiellement méthodologique,
les passages en caractères italiques font plus particulièrement référence à l'appli-
cation pratique concernée, à savoir l'estimation des caractéristiques socio-
démographiques d'une population urbaine en Afrique.
Notre premier objectif est d'estimer la population de la ville. Il est possible
d'effectuer cette estimation de nombreuses manières: densité moyenne x surface,
nombre de personnes par bâtiment x nombre de bâtiments, etc. Pour des raisons
exposées plus loin, nous avons choisi d'effectuer une estimation du nombre de
personnes par parcelle x nombre de parcelles (densité (parcelles/ Ha) x surface). La
prise en compte d'autres caractéristiques de la population s'effectuera également au
niveau de la parcelle.
4.2.1 NOTATIONS
Les conventions de notation utilisées, ainsi que l'approche générale, ont été
largement empruntées à COCHRAN [1977].
Soit une population de N individus dont on mesure un caractère y. La mesure de ce
caractère chez le ième individu est notée yi. Le total du caractère y sur l'ensemble de
la population est noté Y. Sa moyenne, mesurée sur l'ensemble de la population est
notée Y et est donnée par:
N
∑yi
i =1
Y=
N
Dans la plupart des cas, la population n'est pas homogène, et la valeur du caractère
Y n'est pas identique pour tous les individus. Le degré d'hétérogénéité de la
population (en ce qui concerne ce caractère ) est appréhendé par la variance,
calculée comme suit.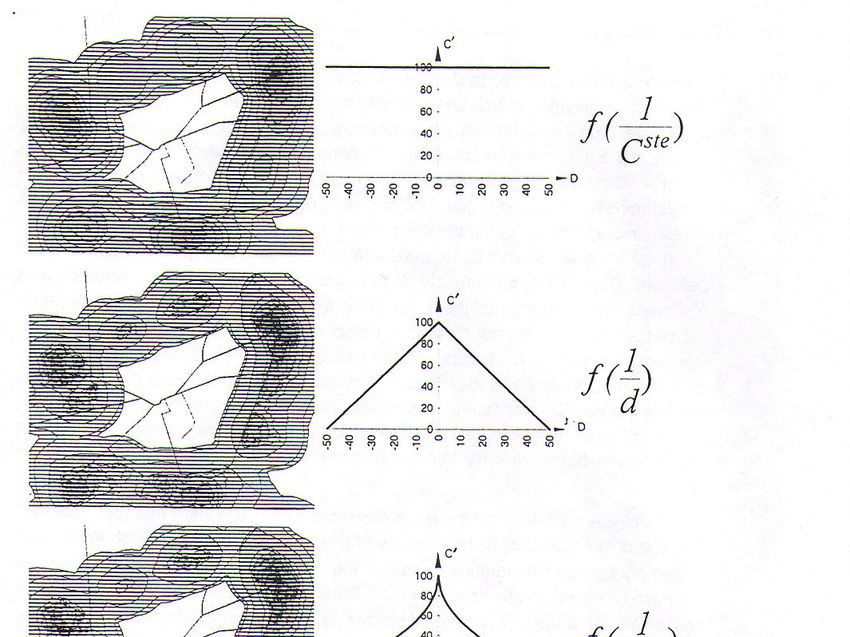
Sondages Aréolaires 4
N
∑(y −Y ) i
2
S2 = i =1
N −1
Si on sélectionne au hasard n individus de cette population, la moyenne et la
variance de cet échantillon sont:
n n
∑ yi ∑ ( y − y)
i
2
y= i =1
s2 = i =1
n n
L'objectif des sondages est de produire des estimations, notées ^ . L'estimation
ˆ
de la moyenne de la population totale Y est donnée par la moyenne calculée sur
l'échantillon. Il est démontré que la moyenne et la variance d'un l'échantillon sont
des estimateurs non-biaisés de la moyenne et variance de la population (pour
autant que sa distribution soit normale).
Yˆ = y , Yˆ = Ny et Sˆ ² = s²
Si l'on répète un grand nombre de fois le calcul de la moyenne et de la variance
sur des échantillons prélevés chaque fois de manière indépendante, les valeurs de
moyenne et variance de l'échantillon vont fluctuer. Ces variations sont évaluées par
la variance de l'estimateur, qui dépend de la variance de la population (ou de celle
de l'échantillon) et de la taille de l'échantillon:
s2 n
v( y) = ( 1− f ) avec f =
n N
(le terme 1-f pourra être négligé lorsque la taille de l'échantillon est nettement plus
petite que celle de la population). La racine carrée de la variance de l'estimateur est
appelée erreur-type.
La précision de l'estimation est couramment exprimée par l'écart maximum qu'il
risque d'exister (avec une probabilité donnée) entre l'estimation basée sur
l'échantillon et la valeur réelle de la population. L'estimation permet d'assurer que le
nombre total d'individus ( Y ) est compris dans l'intervalle de valeurs suivants:
[
Y ∈ Yˆ − 1,96 V (Yˆ ) , Yˆ + 1,96 V (Yˆ ) ]
Cet écart sera utilement exprimé en pourcentage de variation par rapport à la
variable estimée. On dira par exemple que la taille moyenne des arbres d'un
échantillon est de 17,4 m et qu'il y a 95% de chances pour que la taille moyenne
réelle des arbres de l'ensemble de la forêt ne diffère pas de plus de 7% de cette
valeur (17,4 m ±7 %).
Si on dispose d'une estimation de la variance de la population, on peut donc
déterminer la précision attendue pour un échantillon de taille donnée. Mais il est
Sondages Aréolaires 5
également possible de déterminer, en fonction de la variance de la population, la
taille no d'un échantillon nécessaire pour produire une estimation dont on impose la
précision:
t .s 2
no = , ou s est la racine carrée de la variance, y la moyenne.
r .y
r est l'erreur relative tolérée et t est la valeur de la statistique de Student im-
posée par le niveau de fiabilité de l'estimation souhaitée (classiquement, pour
un risque accepté de 5%, t vaut 1,96).
4.3 SONDAGES STRATIFIES
Le principe des sondages stratifiés est intuitivement assez évident:
si on doit estimer un caractère par un échantillon pris sur un ensemble, et que cet
ensemble est formé de sous-groupes, il est possible effectuer une estimation de
chaque sous-ensemble (au moyen d'un sous-échantillon), puis de déterminer l'es-
timation globale en fonction de l'importance relative de chaque sous-ensemble. Si
les sous-ensembles présentent une meilleure homogénéité que l'ensemble complet,
les estimations partielles gagneront en fiabilité, ainsi que l'estimation globale.
Le découpage en sous-ensembles peut s'effectuer selon divers critères (taille,
type, etc.), toujours dans le but de créer des sous-ensembles homogènes du point
de vue de la variable à étudier. Ces critères doivent donc présenter une relation di-
recte avec cette variable. D'autre part, l'évidente anisotropie spatiale de nombreu-
ses variables suggère la prise en compte de la répartition spatiale des individus
comme base de groupement. La création de sous-ensembles homogènes s'appa-
rente alors à une opération de zonage. La prise en compte de la seule composante
spatiale définira des sous-ensembles topologiques (p. ex. des zones concentriques
autour du centre-ville). En définissant des zones (contrainte topologique) répondant
aussi à un critère de typologie urbaine (critère lié par hypothèse à la variable
analysée), on définit une contrainte à la fois spatiale et conceptuelle ce qui est ab-
solument conforme aux habitudes cartographiques.
A l'évidence, le nombre moyen de personnes par parcelle, ainsi que la surface
moyenne des parcelles, ne sont pas constants dans tous les quartiers de la ville. Si
ces paramètres sont liés à un critère de morphologie urbaine, alors un découpage
en zones morphologiquement homogènes permettra d'affiner les estimations et de
spatialiser les résultats.
Ce découpage s'effectue par interprétation visuelle des images SPOT P+XS
(voir paragraphe 3.6 ). Il permet également de préciser l'étendue spatiale de la
fonction résidentielle qui constituera l'univers de l'enquête.
Sondages Aréolaires 6
4.3.1 NOTATIONS
Supposons une stratification en L strates (k=1,2,...,L)
La population totale est notée:
Nh : nombre d'individus dans la strate h
Dans notre application, il s'agit du nombre de parcelles
L
N= ∑N h : nombre total d'individus ( il y a L strates)
h=1
Nh
Wh = : poids relatif de la strate h dans l'ensemble de la
N
population.
Les notations relatives à l'échantillon sont:
nh : nombre d'individus dans l'échantillon pris dans la
strate h
Dans notre application, il s'agit du nombre de
parcelles visitées
L
n= ∑n h : taille de l'ensemble de l'échantillon
h =1
nombre total de parcelles visitées
yi : valeur prise par le caractère y pour l'individu i
Il s'agit du nombre de personnes occupant la
parcelle i
n
∑y i
i=1
y= : moyenne du caractère y de l'échantillon
n
C'est le nombre moyen de personnes / parcelle
nh
fh = : taux de sondage dans la strate h.
Nh
Ah : superficie de la strate h ( A: superficie totale)
Sondages Aréolaires 7
Nh
∑y
i =1
hi
Y = est la moyenne prise par la variable Y dans la
h Nh
strate h
C'est le nombre moyen de personnes par
parcelles dans la strate.
Nh
2
∑ ( y hi − Y h )
i=1
s 2h = est la variance de cette variable
N h−1
nh
∑ y hi
i =1
yh = est la moyenne de l'échantillon prélevé dans la
nh
strate h.
4.3.2 ESTIMATEURS - PROPRIETES DES ESTIMATEURS
Cas général
La moyenne de l'échantillon peut être utilisée pour estimer la moyenne de la
population. L'estimateur de moyenne exploitant le principe de la stratification, est
donné par:
L
∑Nhyh L
= ∑ Wh y h
h =1
y st =
N h =1
La variance de cet estimateur est donnée par:
S2
V( y ) = ( 1− f )
n
Allocation Proportionnelle
Si les taux de sondages sont identiques dans toutes les strates, ( fh = Cste), cet
estimateur de moyenne est strictement identique à l'estimateur non stratifié y .
Cette condition se rencontre lorsque les taux de sondage par strate
nh Nh
vérifient la condition n = N , c.-à-d. lorsque l'importance de l'échantillon tiré
dans chaque strate est proportionnelle à l'importance relative (en nombre d'indivi-
dus) de la strate correspondante. Cette distribution de l'échantillon dans les strates
est appelée allocation proportionnelle. Elle génère un échantillon auto-pondéré, ce
qui facilite l'exploitation ultérieure des données, puisque, par exemple, la moyenne
de l'échantillon donne directement la moyenne de la population.
A la condition que les échantillons aient été tirés de manière indépendante dans
les différentes strates, si l'on répète les tirages d'échantillons dans la strate h, la
variance de l'estimateur de moyenne générale ( V ( y ) ) sera fonction des variances
st
des estimateurs de moyennes dans chaque strate ( V ( y ) )
h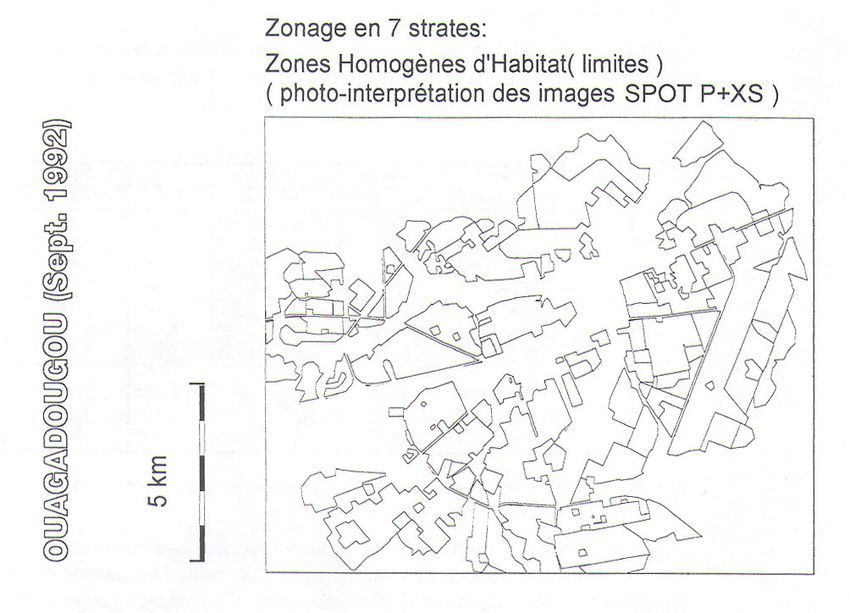
Sondages Aréolaires 8
L L S 2h
V( y ) = ∑ W 2h V( yh ) = ∑ W 2h ( 1− f h )
st
h=1 h=1 nh
(Le terme de correction pour population finie (1-fh) peut être ignoré lorsque la taille
de l'échantillon est faible par rapport à la taille de la population).
Si l'allocation est proportionnelle, ( nh = nNh / N ),
1− f L
V( y = ∑ W 2h S 2h
st ) n h=1
On perçoit aisément l'intérêt de l'estimation par stratification lorsque les strates sont
définies pour minimiser les variances internes, dont la somme pondérée devient
plus faible que la variance globale.
La variance globale de la population, S² (et son équivalent dans les strates) n'est
généralement pas connue. On l'estime au moyen d'un estimateur non biaisé,
nh
2
sh =
1
n h −1
∑ ( y hi − y ) 2
i =1
Alors, un estimateur non biaisé de la variance de y st est donné par:
W 2h s 2h L W h s 2h
L
v ( y st ) = s ( y ) = ∑
2
−∑
st h=1 n h h =1 N
Allocation optimisée
Chaque strate contribue donc à la variance de l'estimateur (et par conséquent à
l'imprécision du sondage) en fonction de sa variance propre et de son importance
relative (au carré), et en fonction inverse du nombre d'échantillons qui y sont
prélevés. On conçoit donc intuitivement que, dans les strates présentant une faible
variance, il est possible de diminuer le nombre d'échantillons sans beaucoup nuire à
la précision d'ensemble. Un échantillonnage idéal ajusterait donc les taux de
sondages pour équilibrer la contribution de chacune des strates dans l'erreur glo-
bale. Ce type de distribution de l'échantillon est connu sous le nom d'allocation
optimisée (ou allocation de Neyman).
Sondages Aréolaires 9
W 2h S 2h
Elle impose que les valeurs soient égales, ce qui se vérifie si
nh
Wh S h
nh = n
∑Wh S h
L'optimisation de l'allocation peut encore être affinée si l'on prend en compte le
coût d'acquisition d'un point sondé, qui peut varier d'une strate à l'autre (distance,
difficulté d'accès, etc.). L'objectif est alors de minimiser le coût global d'enquête,
pour une précision donnée, ou plus généralement de maximiser cette précision en
fonction d'un budget imposé. Si le coût unitaire d'enquête dans la strate h est noté
ch , la ventilation de l'échantillon au sein des strates devra respecter la proportion
suivante:
nh Wh S h ch
≡
n ∑ ( Wh S h ch )
Nous reviendrons plus loin sur cette possibilité intéressante.
Il est également possible de moduler l'allocation aux strates en fonction d'exi-
gences spécifiques à telle ou telle strate. Par exemple, on pourrait concevoir qu'une
enquête destinée à un projet d'équipement urbain s'intéresse plus particulièrement à
la situation dans les quartiers les plus démunis.
4.3.3 AVANTAGES DU SONDAGE STRATIFIE
Amélioration de la précision des estimations
Utilisé à bon escient, le sondage stratifié améliore pratiquement toujours la
précision des estimations. COCHRAN [1977] démontre que la variance de l'estimateur
de la moyenne d'une population donnée au moyen d'un échantillon de taille fixée
diminuera en passant d'un sondage aléatoire simple V alé (y) à un sondage stratifié
avec allocation proportionnelle V pro (y) , puis à un sondage stratifié avec allocation
optimisée V opt (y) :
V alé (y) ≥ V pro (y) ≥ V opt (y )
Le gain de précision peut être estimé par:
1 ( 1− f )
V alé = V opt + n ∑ W h ( S h − S ) 2 + n
∑ W h ( Yh − Y ) 2Sondages Aréolaires 10
De la qualité de la stratification va dépendre l'importance du gain de précision.
DESABIE [1966], montre que "une stratification, même très imparfaite, est préférable à
une absence de stratification". Cela est vrai pour une stratification avec allocation
proportionnelle. Par contre, sous certaines conditions, l'application d'un plan de
sondage incorrectement balancé pourrait produire une estimation moins précise que
celle obtenue par un simple sondage aléatoire. Dans la mesure où l'organisation et
l'exploitation d'un sondage optimisé sont sensiblement plus complexes, il est
conseillé de ne recourir à cette méthode que lorsque les gains de précision attendus
seront suffisamment importants.
Pour être efficace, la stratification doit se faire sur base d'un critère étroitement
lié avec la variable à analyser (idéalement, cela devrait être la variable elle-même!).
Se pose alors le problème de l'organisation d'un sondage optimisé pour l'estimation
de plusieurs variables. Il est évident qu'il n'est pas possible de procéder à autant
des sondages (et d'enquêtes) qu'il y a de variables à estimer. En espérant qu'il soit
possible de trouver un critère de stratification satisfaisant pour les différentes
variables, il faudra encore trouver un compromis entre les plans de sondages (le
taux de sondage par strate) optimisés pour chacune des variables prises individuel-
lement. Des solutions théoriques ont été proposées (CHATTERJEE ET YATES, cités par
COCHRAN [1977], DALENIUS, cité par DESABIE [1966]), mais dans la plupart des appli-
cations pratiques, les solutions seront déterminées de manière empirique. Signalons
pour mémoire que des outils courants d'analyse par simulation permettent de
résoudre ce genre de système de manière efficace, à défaut d'être élégante.
Régionalisation des Estimations
Le critère de stratification peut prendre de nombreuses formes. Dans le cadre
d'estimations des caractéristiques de populations urbaines, on pourrait regrouper
les individus en fonction de leur âge, de leur profession, de leurs revenus. Des
stratifications sur base d'un critère purement spatial pourraient être envisagées
(distance au centre, p. ex.). Dans de nombreux cas, une combinaison de critères
socio-démographiques et spatiaux s'avère particulièrement efficace. La prise en
compte de la dimension spatiale lors de la stratification offre en outre l'incontestable
avantage de permettre une régionalisation des résultats: l'enquête ne porte plus
uniquement sur l'estimation des caractéristiques générales de la population mais
aussi et surtout sur ses variations spatiales.Sondages Aréolaires 11
4.4 SONDAGES A DEUX NIVEAUX
L'organisation pratique des sondages se heurte assez rapidement à des coûts
logistiques rédhibitoires. Ainsi, lors de la définition préliminaire de l'enquête menée
à Ouagadougou, il a été estimé que la ville comptait près de 1 million de personnes,
occupant environ 150 000 unités d'habitations distribuées sur un territoire de plus ou
moins 120 km². Un sondage à 1% nécessiterait donc la visite d'environ 1 500 unités.
En supposant des trajets à vol d'oiseau menés à partir d'une base centrale, la
distance à parcourir représente près de 7 000 km !
( (120 /2)/ π = 4, 37 km ). De plus, dans la mesure où nous souhaitions effectuer
une prise de vue aérienne de chaque parcelle enquêtée (pour analyser la typologie
du bâti, l'occupation du sol et mesurer les emprises au sol), il aurait pratiquement
fallu couvrir par photographie aérienne la totalité de la ville. Heureusement, l'ap-
proche du sondage à deux niveau a permis d'améliorer de manière radicale l'effi-
cacité des opérations: si l'on sélectionne 150 placettes (ou îlots) sur l'ensemble de
l'agglomération, et que dans chaque îlot, on enquête 10 parcelles tirées au sort, le
taux de sondage global reste de 1%, mais les déplacements entre quartiers et les
coûts d'acquisition des photographies seront réduits d'un facteur 10 ! En effet, les
coûts de déplacements des enquêteurs au sein d'un même îlot sont négligeables,
alors que les coûts de réalisation de chaque interview restent inchangés.
L'application de sondages à niveaux multiples permet une grande souplesse
d'utilisation: il est possible d'effectuer la sélection des individus par tirage aléatoire
simple, par tirage systématique, avec ou sans stratification, etc., et ce, à chacun des
niveaux envisagés. Nous nous sommes limité à envisager deux niveaux (unité
primaire = placette et unité secondaire = parcelle), mais il va de soi qu'il aurait été
possible de développer un niveau supplémentaire, par exemple au niveau de mé-
nages ou des individus occupant une même parcelle. Pour la suite de ce chapitre,
nous utiliserons les abréviations U.P. et U.S. pour indiquer les Unités Primaires et
les Unités Secondaires.
Nous cherchons donc à estimer la population totale de chacune des strates en
évaluant d'une part la population moyenne d'une parcelle (nombre de personnes)
et d'autre part le nombre de parcelles dans la strate. Cette estimation s'effectue
dans un échantillon de blocs de parcelles ou placette. Une placette est une zone
urbanistiquement homogène délimitée de manière précise. Elle inclut des affecta-
tions spécifiquement résidentielles, leurs dépendances directes, ainsi que la voirie
de desserte. Dans l'application menée à Ouagadougou, les îlots définis par le tracé
de la voirie structurante sont très grands, et souvent peu homogènes. Nous avons
donc utilisé des placettes de taille plus réduite, grâce aux facilités de repérage sur le
terrain offertes par l'utilisation de photographies aériennes à grande échelle
( fig 4-1)Sondages Aréolaires 12
Fig.4-1: Photo aérienne d'une placette (Ouagadougou, Déc. 1992)
La taille des U.P. (en nombre d'U.S., c.-à-d. en nombre de parcelles) n'est pas
constante, ce qui complique légèrement l'analyse des résultats. La prise en compte
d'U.P. de taille constante alourdirait cependant de manière considérable les
opérations de sélection et d'enquête.
4.4.1 NOTATIONS
Dans l'ensemble, les notations utilisées respectent celles développées plus
haut, à quelques adaptations près. Ces notations font référence à une seule strate.
La prise en compte de différentes strates sera envisagée ultérieurement.
yij est la valeur observée pour la j ème unité secondaire
(U.S.) de la i ème unité primaire (U.P.)
Il s'agit donc du nombre de personnes occupant la j ème
parcelle
N et n nombre d'U.P. dans la strate et nombre d'U.P. sondées
nombre de placettes
Mi et mi nombre d'U.S. dans l'U.P i et nombre d'U.S. sondées
nombre de parcelles dans la placette.
Mo , mo nombre total d'U.S. (parcelles) dans la strate et dans
N n
l'échantillon ( M o = ∑ Mi
i =1
, m o = ∑ mi )
i=1Sondages Aréolaires 13
N et n nombre d'U.P. et nombre d'U.P. sélectionnées dans
l'échantillon.
nombre de placettes
m y ij
yi = ∑ m
moyenne de l'échantillon prélevé dans la i ème U.P.
j=1
population moyenne d'une parcelle de la i ème placette
n yj
yi = ∑ moyenne des valeurs moyennes de toutes les U.P
i=1 n
Nombre moyen de personnes / parcelles, pour
l'ensemble de la strate
N
∑ ( Yi − Y ) 2
i =1
S 12 = variance entre U.P., ou variance "inter U.P."
N−1
(variance au 1er degré)
N
∑( y i − y) 2
i=1
s 12 = variance entre U.P. dans l'échantillon
n−1
∑ ∑ ( y ij − Y i ) 2
i j
S 22 = variance entre U.S. au sein des U.P. ou variance
N ( M − 1)
"Intra U.P." (variance au 2nd degré)
∑ ∑ ( y ij − y i ) 2
i j
s 22 = variance entre U.S. au sein des U.P.
n ( m − 1)
4.4.2 ESTIMATEURS - PROPRIETES DE CES ESTIMATEURS
La population d'une placette est la somme des populations de toutes les
Mi
parcelles qui la composent ( Yi = ∑ Y j ). La population totale de la strate est la
j=1
N
somme des populations de toutes les placettes ( Y = ∑ Yi ).
i=1
mi
1
La moyenne d'une U.P. est y i = ∑y .
m i j=1 ij
La population totale d'une U.P. est Y i = M i Y i . Si Y i est estimé par y i , la
population estimée de l'U.P. est: Yˆ = M y i i i
Le tirage des U.P. servant d'échantillon est effectué par sondage aléatoire
simple, avec remplacement. On tire ainsi les coordonnées d'un point qui sert à
sélectionner la placette qui le comprend. La probabilité de sélection de chaque pla-
cette ( zi ) est donc proportionnelle à sa surface.
zi = ai A et ∑z i = 1Sondages Aréolaires 14
Le taux de sondage au 1er degré (les U.P.- placettes) est f 1 = n N ; le taux de son-
dage au 2nd degré est f 2 = ∑ m i Mo . Au niveau d'une U.P. donnée, il est
nm
f 2 i = mi M i . Le taux de sondage global est alors f o = f 1 * f 2 =
N
Yˆi ai est la densité de population estimée sur la placette i. Extrapolée à l'ensemble
( i )
de la strate, Yˆ a A = Yˆ z est une estimation de la population totale de la strate.
i i i i
Dans ces conditions, l'estimation de population totale est donnée par la moyenne de
n estimations de ce type:
1 M y 1 Yˆ
Yˆ = ∑ i i = ∑ i
n zi n zi
La variance de cet estimateur est:
2
1 N Y 1 N M 2 (1 − f 2 i ) S 22i
V(Yˆ ) = ∑ z i i − Y + ∑ i
n i =1 z i n i =1 mi z i
Cette variance est constituée de deux termes. le premier terme fait intervenir la
variabilité entre U.P. alors que le second tient compte de la variabilité entre U.S.
d'une même U.P. Il faut noter que dans le premier terme, ce n'est plus la variabilité
entre les Yi qui intervient, mais bien la variabilité entre les Yi / zi . Si les probabilités
d'inclusion dans l'échantillon (zi) sont plus élevées lorsque la taille Yi est élevée, le
premier terme sera très nettement réduit. Cette condition se rencontre lorsque les
probabilités de tirage dépendent du poids de l'U.P. dans le total de la strate
(allocation proportionnelle à la taille).
Un estimateur non-biaisé de cette variance prend la forme très simple de:
Yˆi ˆ 2
n
∑(−Y)
i =1 zi
v(Yˆ ) =
n(n − 1)
Pour avoir un plan de sondage auto-pondéré, il faut que la probabilité de
z i nm i ste
tirage de toutes les U.S. soit identique, soit f o =
Mi
=C .
Sous ce type de plan de sondage, l'estimateur de la variance de cet estimateur de
la population totale prend une forme encore plus simple.
n n
v(Yˆ ) = 2 ∑ ( yi − y ) 2 avec yi = ∑ yij
(n − 1) f o i =1 jSondages Aréolaires 15
Ce type d'allocation à deux niveaux, avec équilibrage des taux de sondages
aux deux niveaux, présente de plus l'avantage de simplifier le dépouillement des
enquêtes [KISH, 1965]. En effet, sous ces conditions, la moyenne de l'échantillon
donne directement la moyenne de la population, sans avoir recours à des termes de
pondération.
4.4.3 DETERMINATION DES TAUX DE SONDAGE
AUX 1ER ET 2ND DEGRES
Le problème peut se poser comme suit: si l'on dispose d'un budget permettant
d'enquêter 1000 ménages, regroupés selon la commune de résidence, vaut-il mieux
sélectionner 20 communes au sein de chacune desquelles on choisit 50 ménages,
ou tirer 50 communes dans lesquelles on tire chaque fois 20 ménages ? A priori,
plus la dispersion spatiale de l'échantillon sera importante, meilleure sera
l'estimation. A l'extrême, il faudrait enquêter 1000 ménages disséminés sur l'en-
semble du territoire, c.-à-d. renoncer à l'utilisation d'un sondage à 2 degrés. Mais
cette option induirait des coûts opératoires nettement plus importants, surtout à
cause des nombreux déplacements. D'un autre côté, minimiser à l'extrême les coûts
en choisissant tout l'échantillon dans la même commune biaiserait de manière
insupportable l'estimation, sauf si la distribution géographique de la variable
considérée était absolument homogène. Il convient donc de déterminer un com-
promis efficace entre deux exigences contradictoires, en assurant un nombre suffi-
samment important de ménages par commune pour que cet échantillon soit repré-
sentatif de l'ensemble de la commune, et en multipliant le nombre de communes
échantillonnées, pour être représentatif de l'ensemble du territoire.
Dans certaines situations, des considérations pratiques peuvent imposer un
nombre (ou un taux) d'U.P. (sondage de 5% minimum des communes), ou déter-
miner le taux de sondage des U.S. Une connaissance a priori des caractéristiques
de la population concernée peut également orienter ce choix. Une autre approche
consiste à modéliser les coûts d'enquête et à déterminer les taux de sondages afin
d'optimiser le coût global d'enquête.
Modèles de coût
La détermination précise des coûts d'une enquête est probablement impossible
a effectuer dans des conditions réelles, vu le grand nombre d'impondérables. Cette
remarque est particulièrement vraie lorsque l'on travaille en Afrique. Néanmoins,
une analyse de la ventilation des coûts peut être tentée: Plaçons-nous dans la
situation d'une enquête à deux niveaux, sans stratification. Le coût global peut être
décomposé comme suit
n
C = c 0 + nc 1 + ∑ m i c 2
i=1
avec:
c0 : coût fixe - inclut les coûts généraux d'organisation de l'enquête
(voyage, séjour, données SPOT, salaires, etc.). Ce coût de baseSondages Aréolaires 16
n'intervient pas dans la détermination de la répartition de
l'échantillon.
c1 : Coût unitaire par U.P.: photographie aérienne, calcul des surfaces,
sélection des U.S., déplacement des enquêteurs,... (Il y a n
placettes).
c2 : coût d'enquête d'une parcelle ≅ coût de questionnaire (les
déplacements au sein d'une même placette sont quasi nuls). Si m i est
le nombre moyen d'U.S. par U.P., il y a n * m i U.S. à enquêter.
COCHRAN [1977] a démontré que la valeur de m qui optimise le sondage en
termes de coût ( V(Yˆ ) minimum) est donnée par:
S2 c1
m opt =&
2
S −S /M
b
2
2
c2
²
N
²
∑ M i Yi − Y( )
avec Sb² = i =1
M ² (N − 1)
qui est la variance entre moyennes d'U.P., pondérée selon la taille des U.P.
D'autres modèles sont également proposés dans la littérature, en fonction de l'im-
portance et du type de trajets entre U.P.
Considérations pratiques
A strictement parler, ce modèle-ci n'est applicable que dans le cas d'un plan de
sondage entièrement auto-pondéré. D'autre part, les valeurs précises des variances
intra U.P et inter U.P. ne sont en général pas connues, mais seulement estimées
soit d'après une enquête antérieure, soit par une bonne connaissance de la ville. Il
convient donc d'utiliser cette analyse de manière circonstanciée et de n'en retenir
qu'une indication générale sur les taux respectifs des deux degrés, dans la mesure
où des fluctuations autour de l'optimum théorique n'engendrent pas de dégradation
importante des résultats ([KISH, 1965] p. 265, [COCHRAN, 1977] p. 290). Nous
tiendrons compte de cette observation au moment de proposer une stratégie
d'enquête pleinement opérationnelle.
4.4.4 PLANS DE SONDAGE
Le type de stratification et la répartition de l'échantillon en unités primaires
(U.P.) et unités secondaires (U.S.) permettent de définir un très grand nombre de
variantes définissant autant de stratégies d'échantillonnage. Il convient donc
d'adopter un plan de sondage qui convienne bien aux objectifs de l'étude mais qui
tienne également compte de ces spécificités et de considérations pratiques.Sondages Aréolaires 17
Méthode proposée par l'ORSTOM
Une étude très intéressante menée antérieurement par une équipe pluridisci-
plinaire de l'ORSTOM sur la ville de Quito (Equateur), proposait la stratégie suivante
([DUREAU ET AL, 1989]):
L'univers à sonder correspond à l'ensemble des surfaces bâties de la ville.
Cette information est extraite d'une image SPOT, soit par interprétation visuelle du
périmètre d'agglomération, soit par analyse semi-automatique d'un indice de végé-
tation et d'un critère d'hétérogénéité spatiale (cfr. § 3.5 ).
Cet univers est décomposé en 6 strates en fonction d'un critère de densité de
bâti obtenu par l'indice de végétation (calculé d'après les données SPOT XS), cali-
bré en fonction de valeurs de densité de bâti mesurées sur le terrain pour des
îlots-test.
Le sondage en deux niveaux utilise des îlots comme U.P. et des ménages
comme U.S.
Le nombre de ménages à échantillonner ( n ) est défini en fonction du budget
disponible (B) et du coût moyen d'enquête d'un ménage (c) : n = B / c
Sachant que la variance intra-îlot est nettement plus faible que la variance inter-
îlots, ils décident d'échantillonner un nombre réduit et constant de ménages dans
chacun des îlots sélectionnés (environ 5 à 10). Ce nombre est apparemment déter-
miné de manière empirique. Le calcul du nombre d'îlots à sélectionner pour
atteindre le nombre de ménages voulu se complique par la présence d'îlots ne
comprenant pas le nombre voulu de ménages. Ce problème est résolu de manière
très pragmatique.
Le nombre d'îlots par strate est déterminé en divisant la surface totale de la
strate par la surface moyenne d'un îlot, estimée à partir de sources externes.
Connaissant le nombre d'îlots à sonder, et le nombre total d'îlots dans la ville, le
taux de sondage global au premier degré est défini. La répartition des îlots-
échantillon au sein des strates peut s'effectuer par allocation proportionnelle, mais
l'équipe suggère fortement le recours à une allocation optimisée en fonction des
variances internes, mais sans tenir compte d'éventuelles différences de coût
d'enquête entre les strates.
L'allocation des U.P. aux strates définit pour chaque strate les taux de son-
dages primaires ( f1h ), qui servent à élaborer des grilles de tirage pour chaque
strate. La sélection des U.P. se fait donc par tirage systématique aligné, ce qui n'est
pas tout à fait conforme aux méthodes d'estimation utilisées par la suite. Bien que
les auteurs aient justifié ce choix par la suite [DUREAU ET BARBARY, 1991], nous le
comprenons mal, dans un environnement technique par ailleurs conséquent
(logiciels d'exploitation statistique, traitement d'image,...) autorisant sans problèmes
la génération de tirages strictement aléatoires.
La localisation d'un noeud de la grille sélectionne l'îlot correspondant (ou le plus
proche, selon une procédure préétablie). La probabilité de sélection des U.P.
dépend donc de la strate et est proportionnelle à la surface de l'îlot. Les ména-Sondages Aréolaires 18
ges sont tirés de manière équiprobable systématique sur une liste des ménages
de l'îlot, recensés lors du levé de l'îlot. Dans les U.P., on sélectionne un nombre
constant d'U.S., identique pour toutes les strates. Le fait de tirer sur liste un nombre
constant de ménages dans chaque îlot sélectionné rend la probabilité de tirage au
second degré inversement proportionnelle au nombre de ménages dans l'îlot. Ce
type de sondage n'est donc pas strictement auto-pondéré, sauf si la taille moyenne
des parcelles est identique dans toutes les placettes d'une même strate. La
stratification, basée sur un critère assez élémentaire de densité de surfaces mi-
nérales, ne permet pas de vérifier cette condition. En conséquence, s'il existe des
grands îlots occupés par peu de ménages, ils risquent d'être sur-représentés dans
l'échantillon. L'ORSTOM considère que cela n'est pas gênant, dans la mesure où
les îlots les plus peuplés sont source d'une variance importante. N'étant pas stric-
tement auto-pondéré, l'échantillon doit être corrigé pour son exploitation: cette cor-
rection consiste à affecter à toutes les U.S. appartenant à un même îlot un poids
inversement proportionnel à la probabilité d'inclusion des U.S.
Pour tester l'efficacité de ce plan de sondage, la variance des estimateurs est
comparée à celle obtenue selon un sondage aléatoire simple, non stratifié. Le re-
cours à la stratification, avec tirage des U.P. équiprobable diminue la variance de
l'estimateur de population totale de 59%. L'application de probabilités d'inclusion
des U.P. proportionnelles à la surface des îlots réduit cette variance de 75%.
Plan de sondage partiellement auto-pondéré
Si les strates sont très différentes, et/ou que l'on souhaite surtout optimiser
l'analyse de certaines strates, l'estimation globale étant secondaire, il sera souhai-
table de tenir compte des particularités des strates. On pourra alors procéder
comme suit:
On détermine de manière approximative le nombre d'U.S. qu'il est possible
d'enquêter avec le budget donné. Le nombre d'U.S. attribué à chaque strate
est déterminé par allocation optimisée, en fonction des variances des strates et des
différences de coût par parcelle enquêtée des U.S. des différentes strates.
Dans chaque strate, on détermine le nombre moyen optimal d'U.S. par
U.P., ( m opt ) en fonction des variances inter et intra U.P. estimées, ainsi qu'en
fonction des coûts d'enquêtes correspondant à chaque étape. Ceci permet de cal-
culer le nombre d'U.P. à tirer au premier degré (nombre total d'U.S. dans la strate /
nombre moyen d'U.S. par U.P.). Les nh U.P. sont tirées par sondage aléatoire sim-
ple, avec remplacement. Ce tirage s'effectue par génération d'un semis de nh points
sur l'ensemble de la strate. Les coordonnées géographiques de ces points sont
relevées. Nous proposons d'effectuer une photographie aérienne détaillée des
environs des points sélectionnés, par la méthode décrite au § 3.1 ). Sur ces photos,
on délimite de manière précise l'extension de l'îlot ou placette sélectionné, et on
mesure sa surface. Les probabilités d'inclusion des U.P. sont donc proportionnelles
à leur surface et varient d'un îlot à l'autre.
L'ensemble des Mi U.S. de chaque U.P. sélectionnée sont identifiées et numé-
rotées. S'il s'agit de parcelles, cette énumération se fait sur les photographies aé-Sondages Aréolaires 19
riennes, mais s'il s'agit de ménages, cela s'effectuera lors de l'enquête proprement
dite. La sélection des U.S. s'effectue par tirage systématique sur la liste ainsi for-
mée, au moyen de procédures classiques (génération aléatoire d'une "semence",
puis incrément d'un pas constant) [DESABIE, 1965], soit au moyen d'un générateur de
nombres aléatoires tel qu'existant sur de nombreuses calculettes. Le nombre d'U.S.
à sélectionner dans l'U.P., qui définit le taux de sondage au second degré, va être
choisi de manière à équilibrer le taux global. Cette condition se vérifie si:
mi fo
=
Mi n⋅ z i
Les estimations de population se font donc de manière très simple, par extrapolation
directe à partir de l'ensemble de l'échantillon prélevé, sans pondérations: la
moyenne de la population est donnée par la moyenne simple de l'échantillon. Dans
cette stratégie, il convient d'optimiser le nombre d'U.P. allouées à chaque strate.
C'est donc en fonction des variances entre U.P. et en fonction des coûts différentiels
d'enquête des U.P. qu'il faudra effectuer cette optimisation.
La variance de l'estimateur d'un sondage auto-pondéré prend une forme plus
simple:
n m
n
v(Yˆ ) =
( n − 1) f o2
∑ ( yi − y ) 2 , avec yi = ∑ yij
i j
Une solution particulièrement efficace de plan de sondage auto-pondéré consiste à
tirer les U.P. avec des probabilités proportionnelles non plus à leur surface, mais
à leur taille (en nombre d'individu, c.-à-d. en nombre de parcelles). Dans ce cas, la
sélection d'un nombre constant d'U.S. dans chaque U.P. assure une auto-pondé-
ration du sondage, puisque la probabilité d'inclusion au second degré est inverse-
ment proportionnelle à la taille de la placette. L'estimateur (non biaisé) du total
devient alors:
n
Mo
Ŷ =
n
∑y i
et sa variance est:
M o2 n Yˆ 2
v(Yˆ ) = ∑
n(n − 1) i
( yi −
Mo
)
Cette possibilité intéressante figure ici pour mémoire, car dans le type d'application
qui nous occupe, la taille des placettes (en nombre de parcelles), n'est a priori pas
connue lors de la sélection des U.P.)
Les estimations concernant l'ensemble des strates se font selon les méthodes
décrites en début de chapitre.Sondages Aréolaires 20
Plan de sondage globalement auto-pondéré
Si l'on s'intéresse surtout aux estimations démographiques concernant l'en-
semble de la ville, il pourra être préférable de définir un plan de sondage entière-
ment auto-pondéré. Dans ce cas, chaque U.S. a la même probabilité d'inclusion, et
le sondage peut être dépouillé comme un recensement: la moyenne de l'échantillon
est un estimateur direct de la moyenne de la population. La population totale est
très simplement estimée:
1
Yˆ = ∑ yi
fo
Si les taux de sondage aux 1er et 2nd degré sont notés respectivement f1 et f2,
le taux global de sondage est fo = f1*f2. Si ce taux est le même pour toutes les
strates ( foh = fo ), le sondage est globalement auto-pondéré. Cette condition se
vérifie si le taux de sondage au premier degré est le même pour toutes les strates
( f1h = f1 ) et que le taux au second degré f2h est également constant. Ce type de
plan de sondage est effectivement auto-pondéré, mais ne bénéficie d'aucun
avantage de l'optimisation.
Si le nombre d'U.P. attribuées à chaque strate suit une allocation optimisée, les
taux de sondage au 1er degré ne sont plus identiques dans toutes les strates. Par
contre, si les taux au 2nd degré sont modulés de telle manière que
foh = f1h * f2h = fo=Cste, alors on bénéficiera des avantages de l'optimisation, tout en
gardant un échantillon aisément exploitable.
4.4.5 CONSIDERATIONS PRATIQUES
Nous venons de voir qu'il était possible, par une approche théorique, d'optimi-
ser de nombreux aspects d'un plan de sondage, en fonction des objectifs, mais
aussi des caractéristiques de l'univers statistique considéré.
Cependant, la plupart de ces opérations d'affinage se basent sur des estima-
tions qu'il n'est pas toujours aisé d'obtenir. En particulier, l'estimation fiable des
coûts d'enquête associés aux différentes opérations et aux différentes strates reste
à notre avis assez chimérique, surtout lorsque l'on est confronté avec quantité
d'impondérables inévitables lorsque l'on travaille en déplacement, dans une ville
africaine en particulier. De plus, les modèles de coûts proposés sont très simples,
voire simplistes, et rendent mal compte des difficultés d'accessibilité de certains
quartiers.
Les modèles d'optimisation requièrent également une connaissance a priori des
différentes composantes de variance, et ce pour chacune des strates. Nous avons
expérimenté à nos dépens la difficulté d'effectuer des estimations empiriques de ces
variances. On considère en général que ces paramètres doivent être estimés partir
du résultat d'enquêtes existantes. Dans le genre d'applications visées, il n'est pas
garanti que de tels résultats fiables existent. Dans les villes à forte croissance, une
estimation ancienne peut se révéler trompeuse. Enfin, à supposer que de tellesSondages Aréolaires 21
estimations récentes et fiables existent, il y a très peu de chances pour qu'elles
soient agrégées selon le même découpage que celui utilisé pour la stratification.
Dans la plupart des cas, il sera donc nécessaire de recourir à une enquête-
pilote préalable, destinée à estimer les paramètres utiles à l'optimisation; elle ser-
vira également à tester le questionnaire, à vérifier la pertinence et à corriger le cas
échéant la stratification, etc. Cette procédure risque bien évidemment d'allonger les
délais et de gonfler les coûts d'une méthode qui devrait être, selon nos objectifs
opérationnels, rapide et peu onéreuse.
Il serait possible, et raisonnable, d'envisager une enquête se déroulant en deux
phases. La moitié du budget servirait à une première phase basée sur une
allocation aux strates proportionnelle, avec une balance des taux de sondages op-
timisée globalement. En fonction des résultats (moyennes, variances et coûts réels)
notés lors de cette première phase, la seconde moitié du budget serait allouée de
manière optimisée (allocation aux strates et taux de sondages aux deux degrés).
Cette approche est rendue possible par la vitesse des traitements et la possibilité de
traiter les données sur place, grâce aux moyens informatiques portables désormais
disponibles.
Enfin, la plupart des spécialistes des sondages s'accordent pour considérer que
les erreurs d'observation peuvent à elles seules ruiner la stratégie de sondage la
plus élaborée. Ces erreurs proviennent d'une mauvaise conception du
questionnaire, de la mauvaise qualité (consciente ou non) des prestations des en-
quêteurs, de la mauvaise compréhension de certaines questions par les enquêtés,
etc. A nouveau, nous sommes forcé de constater que les enquêtes que nous avons
menées ne se sont pas déroulées dans les conditions idéales.
Il serait alors illusoire de vouloir peaufiner à l'extrême un plan de sondage, si
son application risque de s'effectuer de manière approximative. Mieux vaut au
contraire simplifier autant que faire se peut les procédures, pour alléger au maxi-
mum la tâche des enquêteurs, et pour faciliter l'exploitation des résultats. On con-
seillera donc, à la suggestion de DESABIE [1966], de tenir compte dans les grandes
lignes des valeurs optimales proposées par l'analyse des coûts et variances, mais
de s'en tenir à des fractions d'échantillonnage simples à manipuler, et si possible, à
n'utiliser qu'un nombre réduit de taux de sondages, (p.ex. un taux de base pour
toutes les strates, et un taux double pour les strates plus "délicates"). L'introduction
des valeurs estimées de coût, de variances et leurs relations principales dans une
"feuille de calcul électronique" ( type LOTUS ou EXCEL, etc.) permet de tester par
simulation l'effet de diverses simplifications sur la qualité des estimations
résultantes.Vous pouvez aussi lire

















































