Demain, les nains - Framablog
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Demain, les nains… Et si les géants de la technologie numérique étaient concurrencés et peut-être remplacés par les nains des technologies modestes et respectueuses des êtres humains ? Telle est l’utopie qu’expose Aral Balkan ci-dessous. Faut-il préciser que chez Framasoft, nous avons l’impression d’être en phase avec cette démarche et de cocher déjà des cases qui font de nous ce qu’Aral appelle une Small Tech (littéralement : les petites technologies) par opposition aux Big Tech, autrement dit les GAFAM et leurs successeurs déjà en embuscade pour leur disputer les positions hégémoniques. Article original sur le blog d’Aral Balkan : Small technology L’antidote aux Big tech : la Small Tech Les géants du numérique, avec leurs « licornes » à plusieurs
milliards de dollars, nous ont confisqué le potentiel
d’Internet. Alimentée par la très courte vue et la rapacité du
capital-risque et des start-ups, la vision utopique d’une
ressource commune décentralisée et démocratique s’est
transformée en l’autocratie dystopique des panopticons de la
Silicon Valley que nous appelons le capitalisme de
surveillance. Cette mutation menace non seulement nos
démocraties, mais aussi l’intégrité même de notre personne à
l’ère du numérique et des réseaux1.
Alors que la conception éthique décrit sans ambiguïté les
critères et les caractéristiques des alternatives éthiques au
capitalisme de surveillance, c’est l’éthique elle-même qui est
annexée par les Big Tech dans des opérations de relations
publiques qui détournent l’attention des questions systémiques
centrales 2 pour mettre sous les projecteurs des symptômes
superficiels3.
Nous avons besoin d’un antidote au capitalisme de surveillance
qui soit tellement contradictoire avec les intérêts des Big
Tech qu’il ne puisse être récupéré par eux. Il doit avoir des
caractéristiques et des objectifs clairs et simples
impossibles à mal interpréter. Et il doit fournir une
alternative viable et pratique à la mainmise de la Silicon
Valley sur les technologies et la société en général.
Cet antidote, c’est la Small Tech.
Small Tech
4
elle est conçue par des humains pour des humains ;
elle n’a pas de but lucratif 5 ;
elle est créée par des individus et des organisations
sans capitaux propres6 ;
elle ne bénéficie d’aucun financement par le capitalisme
de la surveillance des Big Tech7 ;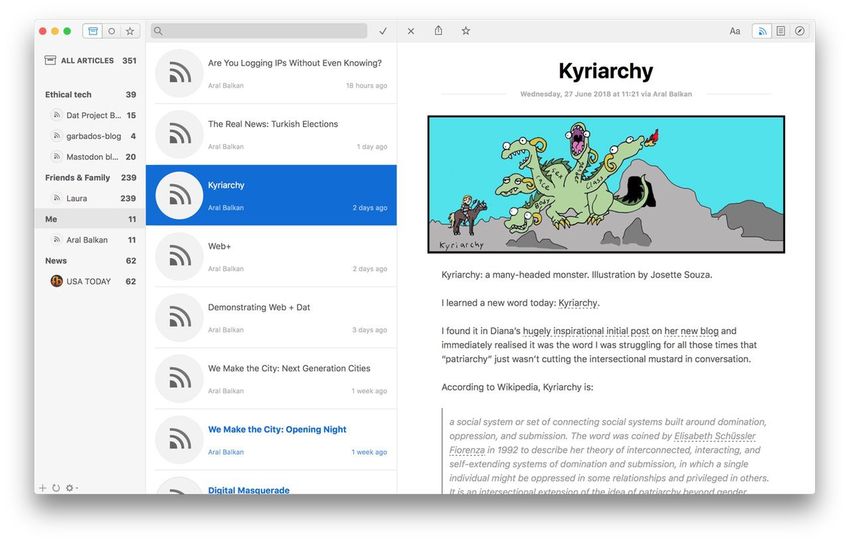
elle respecte la vie privée par défaut8 ;
elle fonctionne en pair à pair9 ;
elle est copyleft10 ;
elle favorise les petits plutôt que les grands, les
simples plutôt que les complexes et tout ce qui est
modulaire plutôt que monolithique11 ;
elle respecte les droits humains, leurs efforts et leur
expérience12 ;
elle est à l’échelle humaine13.
Ces critères signifient que la Small Tech :
est la propriété des individus qui la contrôlent, et non
des entreprises ou des gouvernements ;
respecte, protège et renforce l’intégrité de la personne
humaine, des droits humains, de la justice sociale et de
la démocratie à l’ère du numérique en réseau ;
encourage une organisation politique non-hiérarchisée et
où les décisions sont prises à l’échelle humaine ;
alimente un bien commun sain ;
est soutenable ;
sera un jour financée par les communs, pour le bien
commun.
ne rapportera jamais des milliards à quiconque.
1. Lectures suggérées : La nature du « soi » à l’ère
numérique, Encourager la maîtrise de chacun et la bonne
santé des biens communs, et Nous n’avons pas perdu le
[retour]
contrôle du Web — on nous l’a volé
2. Nous avons un système dans lequel 99.99999% des
investissements financent les entreprises qui reposent
sur la surveillance et se donnent pour mission de
croître de façon exponentielle en violant la vie privée
de la population en général [retour]
3. « Attention » et « addiction ». S’il est vrai que les
capitalistes de la surveillance veulent attirer notre
attention et nous rendre dépendants à leurs produits,
ils ne le font pas comme une fin en soi, mais parce que
plus nous utilisons leurs produits, plus ils peuvent
nous exploiter pour nos données. Des entreprises comme
Google et Facebook sont des fermes industrielles pour
les êtres humains. Leurs produits sont les machines
agricoles. Ils doivent fournir une façade brillante pour
garder notre attention et nous rendre dépendants afin
que nous, le bétail, puissions volontairement nous
autoriser à être exploités. Ces institutions ne peuvent
être réformées. Les Big Tech ne peuvent être
réglementées que de la même manière que la Big Tobacco
pour réduire ses méfaits sur la société. Nous pouvons et
devrions investir dans une alternative éthique : la
[retour]
Small Tech.
4. La petite technologie établit une relation d’humain à
humain par nature. Plus précisément, elle n’est pas
créée par des sociétés à but lucratif pour exploiter les
individus – ce qu’on appelle la technologie entreprise
vers consommateur. Il ne s’agit pas non plus d’une
technologie construite par des entreprises pour d’autres
[retour]
entreprises
5. Nous construisons la Small Tech principalement pour le
bien commun, pas pour faire du profit. Cela ne signifie
pas pour autant que nous ne tenons pas compte du système
économique dans lequel nous nous trouvons actuellement
enlisés ou du fait que les solutions de rechange que
nous élaborons doivent être durables. Même si nous
espérons qu’un jour Small Tech sera financé par les
deniers publics, pour le bien commun, nous ne pouvons
pas attendre que nos politiciens et nos décideurs
politiques se réveillent et mettent en œuvre un tel
changement social. Alors que nous devons survivre dans
le capitalisme, nous pouvons vendre et faire des profits avec la Small Tech. Mais ce n’est pas notre but premier. Nos organisations se préoccupent avant tout des méthodes durables pour créer des outils qui donnent du pouvoir aux gens sans les exploiter, et non de faire du profit. Small Tech n’est pas une organisation caritative, mais une organisation à but non lucratif.[retour] 6. Les organisations disposant de capitaux propres sont détenues et peuvent donc être vendues. En revanche, les organisations sans capital social (par exemple, les sociétés à responsabilité limitée par garantie en Irlande et au Royaume-Uni) ne peuvent être vendues. De plus, si une organisation a du capital-risque, on peut considérer qu’elle a déjà été vendue au moment de l’investissement car, si elle n’échoue pas, elle doit se retirer (être achetée par une grande société ou par le public en général lors d’une introduction en bourse). Les investisseurs en capital-risque investissent l’argent de leurs clients dans la sortie. La sortie est la façon dont ces investisseurs font leur retour sur investissement. Nous évitons cette pilule toxique dans la Small Tech en créant des organisations sans capitaux propres qui ne peuvent être vendues. La Silicon Valley a des entreprises de jetables qu’ils appellent des startups. Nous avons des organisations durables qui travaillent pour le bien commun que nous appelons Stayups (Note de Traduction : jeu de mots avec le verbe to stay signifie « demeurer »).[retour] 7. La révolution ne sera pas parrainée par ceux contre qui nous nous révoltons. Small Tech rejette le parrainage par des capitalistes de la surveillance. Nous ne permettrons pas que nos efforts soient utilisés comme des relations publiques pour légitimer et blanchir le modèle d’affaires toxique des Big Tech et les aider à éviter une réglementation efficace pour mettre un frein à leurs abus et donner une chance aux alternatives

éthiques de prospérer.[retour]
8. La vie privée, c’est avoir le droit de décider de ce que
vous gardez pour vous et de ce que vous partagez avec
les autres. Par conséquent, la seule définition de la
protection de la vie privée qui importe est celle de la
vie privée par défaut. Cela signifie que nous concevons
la Small Tech de sorte que les données des gens restent
sur leurs appareils. S’il y a une raison légitime pour
laquelle cela n’est pas possible (par exemple, nous
avons besoin d’un nœud permanent dans un système de pair
à pair pour garantir l’accessibilité et la
disponibilité), nous nous assurons que les données sont
chiffrées de bout en bout et que l’individu qui possède
l’outil possède les clés des informations privées et
puisse contrôler seul qui est à chacun des « bouts »
[retour]
(pour éviter le spectre du Ghosting).
9. La configuration de base de notre technologie est le
pair à pair : un système a-centré dans lequel tous les
nœuds sont égaux. Les nœuds sur lesquels les individus
n’ont pas de contrôle direct (p. ex., le nœud toujours
actif dans le système pair à pair mentionné dans la note
précédente) sont des nœuds de relais non fiables et non
privilégiés qui n’ont jamais d’accès aux informations
personnelles des personnes.[retour]
10. Afin d’assurer un bien commun sain, nous devons protéger
le bien commun contre l’exploitation et de
l’enfermement. La Small Tech utilise des licences
copyleft pour s’assurer que si vous bénéficiez des biens
communs, vous devez redonner aux biens communs. Cela
empêche également les Big Tech d’embrasser et d’étendre
notre travail pour finalement nous en exclure en
utilisant leur vaste concentration de richesse et de
pouvoir.[retour]
11. La Small Tech est influencé en grande partie par la
richesse du travail existant des concepteurs et
développeurs inspirants de la communauté JavaScript qui
ont donné naissance aux communautés DAT et Scuttlebutt.
Leur philosophie, qui consiste à créer des composants
pragmatiques, modulaires, minimalistes et à l’échelle
humaine, aboutit à une technologie qui est accessible
aux individus, qui peut être maintenue par eux et qui
leur profite. Leur approche, qui est aussi la nôtre,
repose sur la philosophie d’UNIX.[retour]
12. L a S m a l l T e c h a d h è r e au manifeste du Design
éthique.[retour]
13. La Small Tech est conçue par des humains, pour des
humains ; c’est une approche résolument non-coloniale.
Elle n’est pas créée par des humains plus intelligents
pour des humains plus bêtes (par exemple, par des
développeurs pour des utilisateurs – nous n’utilisons
pas le terme utilisateur dans Small Tech. On appelle les
personnes, des personnes.) Nous élaborons nos outils
aussi simplement que possible pour qu’ils puissent être
compris, maintenus et améliorés par le plus grand
nombre. Nous n’avons pas l’arrogance de supposer que les
gens feront des efforts excessifs pour apprendre nos
outils. Nous nous efforçons de les rendre intuitifs et
faciles à utiliser. Nous réalisons de belles
fonctionnalités par défaut et nous arrondissons les
angles. N’oubliez pas : la complexité survient d’elle-
même, mais la simplicité, vous devez vous efforcer de
l’atteindre. Dans la Small Tech, trop intelligent est
une façon de dire stupide. Comme le dit Brian Kernighan
: « Le débogage est deux fois plus difficile que
l’écriture du premier jet de code. Par conséquent, si
vous écrivez du code aussi intelligemment que possible,
vous n’êtes, par définition, pas assez intelligent pour
le déboguer. » Nous nous inspirons de l’esprit de la
citation de Brian et l’appliquons à tous les niveaux :
financement, structure organisationnelle, conception du
produit, son développement, son déploiement et au-
delà.[retour] Crédit photo : Small Things, Big Things by Sherman Geronimo- Tan. Licence Creative Commons Attribution. [retour] À propos de l’auteur Aral Balkan est un militant, designer et développeur. Il a co- fondé Ind.ie, une toute petite organisation sans but lucratif qui travaille à la justice sociale à l’ère du numérique. Pour soutenir son travail, vous pouvez acheter Better Blocker pour iOS et Better Blocker pour macOS ou encore vous pouvez faire un don. Il est disponible pour des conférences publiques et des interviews Nous devons nous passer de Chrome Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination

d’Internet par Google. Cet article détaille les raisons pour
lesquelles Chrome asphyxie le Web ouvert et pourquoi il
faudrait passer sur un autre navigateur tel Vivaldi ou
Firefox.
Article original :
https://redalemeden.com/blog/2019/we-need-chrome-no-more
Traduction Framalang : mo, Khrys, Penguin, goofy, Moutmout,
audionuma, simon, gangsoleil, Bullcheat, un anonyme
Nous n’avons plus besoin de Chrome
par Reda Lemeden
Il y a dix ans, nous avons eu besoin de Google
Chrome pour libérer le Web de l’hégémonie des
entreprises, et nous avons réussi à le faire
pendant une courte période. Aujourd’hui, sa
domination étouffe la plateforme même qu’il a
autrefois sauvée des griffes de Microsoft. Et
personne, à part Google, n’a besoin de ça.
Nous sommes en 2008. Microsoft a toujours une ferme emprise
sur le marché des navigateurs web. Six années se sont écoulées
depuis que Mozilla a sorti Firefox, un concurrent direct
d’Internet Explorer. Google, l’entreprise derrière le moteur
de recherche que tout le monde aimait à ce moment-là, vient
d’annoncer qu’il entre dans la danse. Chrome était né.
Au bout de deux ans, Chrome représentait 15 % de l’ensemble du
trafic web sur les ordinateurs fixes — pour comparer, il a
fallu 6 ans à Firefox pour atteindre ce niveau. Google a
réussi à fournir un navigateur rapide et judicieusement conçu
qui a connu un succès immédiat parmi les utilisateurs et les
développeurs Web. Les innovations et les prouesses
d’ingénierie de leur produit étaient une bouffée d’air frais,
et leur dévouement à l’open source la cerise sur le gâteau. Au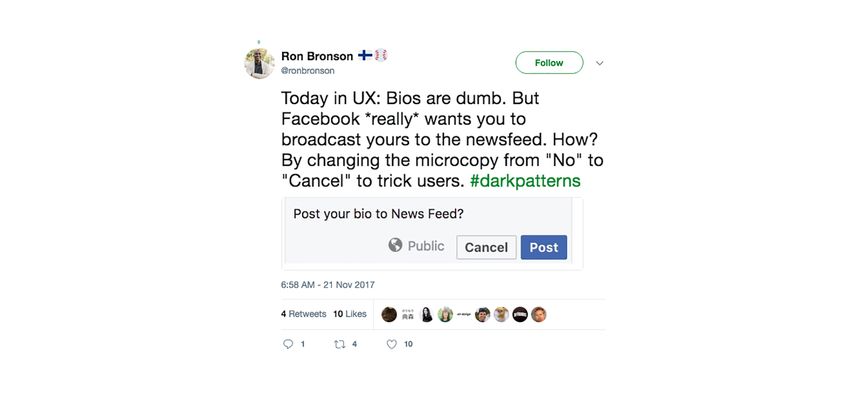
fil des ans, Google a continué à montrer l’exemple en adoptant les standards du Web. Avançons d’une décennie. Le paysage des navigateurs Web est très différent. Chrome est le navigateur le plus répandu de la planète, faisant de facto de Google le gardien du Web, à la fois sur mobile et sur ordinateur fixe, partout sauf dans une poignée de régions du monde. Le navigateur est préinstallé sur la plupart des téléphones Android vendus hors de Chine, et sert d’interface utilisateur pour Chrome OS, l’incursion de Google dans les systèmes d’exploitation pour ordinateurs fixe et tablettes. Ce qui a commencé comme un navigateur d’avant- garde respectant les standards est maintenant une plateforme tentaculaire qui n’épargne aucun domaine de l’informatique moderne. Bien que le navigateur Chrome ne soit pas lui-même open source, la plupart de ses composantes internes le sont. Chromium, la portion non-propriétaire de Chrome, a été rendue open source très tôt, avec une licence laissant de larges marges de manœuvre, en signe de dévouement à la communauté du Web ouvert. En tant que navigateur riche en fonctionnalités, Chromium est devenu très populaire auprès des utilisateurs de Linux. En tant que projet open source, il a de nombreux adeptes dans l’écosystème open source, et a souvent été utilisé comme base pour d’autres navigateurs ou applications. Tant Chrome que Chromium se basent sur Blink, le moteur de rendu qui a démarré comme un fork de WebKit en 2013, lorsque l’insatisfaction de Google grandissait envers le projet mené par Apple. Blink a continué de croître depuis lors, et va continuer de prospérer lorsque Microsoft commencera à l’utiliser pour son navigateur Edge. La plateforme Chrome a profondément changé le Web. Et plus encore. L’adoption des technologies web dans le développement des logiciels PC a connu une augmentation sans précédent dans les 5 dernières années, avec des projets comme Github
Electron, qui s’imposent sur chaque OS majeur comme les standards de facto pour des applications multiplateformes. ChromeOS, quoique toujours minoritaire comparé à Windows et MacOS, s’installe dans les esprits et gagne des parts de marché. Chrome est, de fait, partout. Et c’est une mauvaise nouvelle Don’t Be Evil L’hégémonie de Chrome a un effet négatif majeur sur le Web en tant que plateforme ouverte : les développeurs boudent de plus en plus les autres navigateurs lors de leurs tests et de leurs débogages. Si cela fonctionne comme prévu sur Chrome, c’est prêt à être diffusé. Cela engendre en retour un afflux d’utilisateurs pour le navigateur puisque leurs sites web et applications favorites ne marchent plus ailleurs, rendant les développeurs moins susceptibles de passer du temps à tester sur les autres navigateurs. Un cercle vicieux qui, s’il n’est pas brisé, entraînera la disparition de la plupart des autres navigateurs et leur oubli. Et c’est exactement comme ça que vous asphyxiez le Web ouvert. Quand il s’agit de promouvoir l’utilisation d’un unique navigateur Web, Google mène la danse. Une faible assurance de qualité et des choix de conception discutables sont juste la surface visible de l’iceberg quand on regarde les applications de Google et ses services en dehors de l’écosystème Chrome. Pour rendre les choses encore pires, le blâme retombe souvent sur les autres concurrents car ils « retarderaient l’avancée du Web ». Le Web est actuellement le terrain de jeu de Google ; soit vous faites comme ils disent, soit on vous traite de retardataire. Sans une compétition saine et équitable, n’importe quelle plateforme ouverte régressera en une organisation dirigiste. Pour le Web, cela veut dire que ses points les plus importants — la liberté et l’accessibilité universelle — sont sapés pour
chaque pour-cent de part de marché obtenu par Chrome. Rien que cela est suffisant pour s’inquiéter. Mais quand on regarde de plus près le modèle commercial de Google, la situation devient beaucoup plus effrayante. La raison d’être de n’importe quelle entreprise est de faire du profit et de satisfaire les actionnaires. Quand la croissance soutient une bonne cause, c’est considéré comme un avantage compétitif. Dans le cas contraire, les services marketing et relations publiques sont mis au travail. Le mantra de Google, « Don’t be evil« , s’inscrivait parfaitement dans leur récit d’entreprise quand leur croissance s’accompagnait de rendre le Web davantage ouvert et accessible. Hélas, ce n’est plus le cas. Logos de Chrome L’intérêt de l’entreprise a dérivé petit à petit pour transformer leur domination sur le marché des navigateurs en une croissance du chiffre d’affaires. Il se trouve que le modèle commercial de Google est la publicité sur leur moteur
de recherche et Adsense. Tout le reste représente à peine 10 % de leur revenu annuel. Cela n’est pas forcément un problème en soi, mais quand la limite entre navigateur, moteur de recherche et services en ligne est brouillée, nous avons un problème. Et un gros. Les entreprises qui marchent comptent sur leurs avantages compétitifs. Les moins scrupuleuses en abusent si elles ne sont pas supervisées. Quand votre navigateur vous force à vous identifier, à utiliser des cookies que vous ne pouvez pas supprimer et cherche à neutraliser les extensions de blocage de pub et de vie privée, ça devient très mauvais1. Encore plus quand vous prenez en compte le fait que chaque site web contient au moins un bout de code qui communique avec les serveurs de Google pour traquer les visiteurs, leur montrer des publicités ou leur proposer des polices d’écriture personnalisées. En théorie, on pourrait fermer les yeux sur ces mauvaises pratiques si l’entreprise impliquée avait un bon bilan sur la gestion des données personnelles. En pratique cependant, Google est structurellement flippant, et ils n’arrivent pas à changer. Vous pouvez penser que vos données personnelles ne regardent que vous, mais ils ne semblent pas être d’accord. Le modèle économique de Google requiert un flot régulier de données qui puissent être analysées et utilisées pour créer des publicités ciblées. Du coup, tout ce qu’ils font a pour but ultime d’accroître leur base utilisateur et le temps passé par ces derniers sur leurs outils. Même quand l’informatique s’est déplacée de l’ordinateur de bureau vers le mobile, Chrome est resté un rouage important du mécanisme d’accumulation des données de Google. Les sites web que vous visitez et les mots-clés utilisés sont traqués et mis à profit pour vous offrir une expérience plus « personnalisée ». Sans une limite claire entre le navigateur et le moteur de recherche, il est difficile de suivre qui connaît quoi à votre
propos. Au final, on accepte le compromis et on continue à vivre nos vies, exactement comme les ingénieurs et concepteurs de produits de Google le souhaitent. En bref, Google a montré à plusieurs reprises qu’il n’avait aucune empathie envers ses utilisateurs finaux. Sa priorité la plus claire est et restera les intérêts des publicitaires. Voir au-delà Une compétition saine centrée sur l’utilisateur est ce qui a provoqué l’arrivée des meilleurs produits et expériences depuis les débuts de l’informatique. Avec Chrome dominant 60 % du marché des navigateurs et Chromium envahissant la bureautique sur les trois plateformes majeures, on confie beaucoup à une seule entreprise et écosystème. Un écosystème qui ne semble plus concerné par la performance, ni par l’expérience utilisateur, ni par la vie privée, ni par les progrès de l’informatique. Mais on a encore la possibilité de changer les choses. On l’a fait il y a une décennie et on peut le faire de nouveau. Mozilla et Apple font tous deux un travail remarquable pour combler l’écart des standards du Web qui s’est élargi dans les premières années de Chrome. Ils sont même sensiblement en avance sur les questions de performance, utilisation de la batterie, vie privée et sécurité. Si vous êtes coincés avec des services de Google qui ne marchent pas sur d’autres navigateurs, ou comptez sur Chrome DevTools pour faire votre travail, pensez à utiliser Vivaldi2 à la place. Ce n’est pas l’idéal —Chromium appartient aussi à Google—, mais c’est un pas dans la bonne direction néanmoins. Soutenir des petits éditeurs et encourager la diversité des navigateurs est nécessaire pour renverser, ou au moins ralentir, la croissance malsaine de Chrome.
Je me suis libéré de Chrome en 2014, et je n’y ai jamais
retouché. Il est probable que vous vous en tirerez aussi bien
que moi. Vous pouvez l’apprécier en tant que navigateur. Et
vous pouvez ne pas vous préoccuper des compromissions en
termes de vie privée qui viennent avec. Mais l’enjeu est bien
plus important que nos préférences personnelles et nos
affinités ; une plateforme entière est sur le point de devenir
un nouveau jardin clos. Et on en a déjà assez. Donc, faisons
ce que nous pouvons, quand nous le pouvons, pour éviter ça.
Sources & Lectures supplémentaires
“Parts de marché des navigateurs web”,
https://fr.wikipedia.org/wiki/Parts_de_march%C3%A9_des_n
avigateurs_web, Wikipédia.
“Chrome is Not the Standard”,
https://www.chriskrycho.com/2017/chrome-is-not-the-stand
ard.html, Chris Krycho.
“Why I’m done with Chrome”,
https://blog.cryptographyengineering.com/2018/09/23/why-
im-leaving-chrome/, Matthew Green.
“Browser Diversity Starts with US”,
http://www.zeldman.com/2018/12/07/browser-diversity-star
ts-with-us/, Jeffrey Zeldman.
Un navigateur pour diffuser
votre site web en pair à pair
Les technologies qui permettent la décentralisation du Web
suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous
permettent d’échapper aux silos propriétaires qui collectentet monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et
autres ressources qui reposent sur le protocole activityPub.
Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt
?
Aujourd’hui nous vous proposons la traduction d’un bref
article introducteur à une technologie qui permet de produire
et héberger son site web sur son ordinateur et de le diffuser
sans le moindre serveur depuis un navigateur.
L’article original est issu de la série Dweb (Decentralized
Web) publiée sur Mozilla Hacks, dans laquelle Dietrich Ayala
met le projecteur sur toutes les initiatives récentes autour
du Web décentralisé ou distribué.
Traduction Framalang : bengo35, goofy
Blue Link Labs et Beaker
par Tara Vancil
Nous sommes Blue Link Labs, une équipe de trois
personnes qui travaillent à améliorer le Web avec le
protocole Dat et un navigateur expérimental pair à
pair qui s’appelle Beaker.L’équipe Blue Link Labs Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place. Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? » Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web ! Architecture Beaker utilise un réseau pair-à-pair distribué pour publier
des sites web et des jeux de données (parfois nous appelons ça
des « dats »).
Les sites web dat:// sont joignables avec une clé publique
faisant office d’URL, et chaque donnée ajoutée à un site web
dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce
à une table de hachage distribuée3, puis ils synchronisent les
données entre eux, agissant à la fois comme téléchargeurs et
téléverseurs, et vérifiant que les données n’ont pas été
altérées pendant le transit.
Une illustration basique du réseau
dat://
Techniquement, un site Web dat:// n’est pas tellement
différent d’un site web https:// . C’est une collection de
fichiers et de dossiers qu’un navigateur Internet va
interpréter suivant les standards du Web. Mais les sites web
dat:// sont spéciaux avec Beaker parce que nous avons ajouté
une API (interface de programmation) qui permet aux
développeurs de faire des choses comme lire, écrire, regarder
des fichiers dat:// et construire des applications web pair-à-
pair.Créer un site Web pair-à-pair
Beaker rend facile pour quiconque de créer un nouveau site web
dat:// en un clic (faire le tour des fonctionnalités). Si vous
êtes familier avec le HTML, les CSS ou le JavaScript (même
juste un peu !) alors vous êtes prêt⋅e à publier votre premier
site Web dat://.
Les développeurs peuvent commencer par regarder la
documentation de notre interface de programmation ou parcourir
nos guides.
L’exemple ci-dessous montre comment fabriquer le site Web lui-
même via la création et la sauvegarde d’un fichier JSON. Cet
exemple est fictif mais fournit un modèle commun pour stocker
des données, des profils utilisateurs, etc. pour un site Web
dat:// : au lieu d’envoyer les données de l’application sur un
serveur, elles peuvent être stockées sur le site web lui-même
!
// index.html
Submit message
// index.js
// first get an instance of the website's files
var files = new DatArchive(window.location)
document.getElementById('create-json-
button').addEventListener('click', saveMessage)
async function saveMessage () {
var timestamp = Date.now()
var filename = timestamp + '.json'
var content = {
timestamp,
message: document.getElementById('message').value
}
// write the message to a JSON file// this file can be read later using the DatArchive.readFile
API
await files.writeFile(filename, JSON.stringify(content))
}
Pour aller plus loin
Nous avons hâte de voir ce que les gens peuvent faire de
dat:// et de Beaker. Nous apprécions tout spécialement quand
quelqu’un crée un site web personnel ou un blog, ou encore
quand on expérimente l’interface de programmation pour créer
une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
Pour Beaker, suivez le guide !
Tara Vancil en conférence au JSConf EU 2018 : (YouTube)
A Web Without Servers
Documentation de Beaker
Documentation de DAT
p2pforever.org – un modeste carrefour de ressources
pair-à-pair sur le Web
Beaker sur GitHub
Installer Beaker Browser
et parcourir l’article ci-dessus en DAT :
dat://12420d10773ccc076898b7d782263cde666112b74dff
6d4e1eabf2e4bfcdb672/
Documentation plus technique
How Dat works, un guide en anglais qui expose tous les
détails sur le stockage des fichiers avec Dat
The Dat Protocol Book, également en anglais, plus
complet encore.
À propos de Tara Vancil
Tara est la co-créatrice du navigateur Beaker. Elle atravaillé précédemment chez Cloudflare et participé au Recurse Center. Les fourberies du Dark UX L’expérience utilisateur (abrégée en UX pour les professionnels anglophones) est une notion difficile à définir de façon consensuelle, mais qui vise essentiellement à rendre agréable à l’internaute son parcours sur le Web dans un objectif le plus souvent commercial, ce qui explique l’intérêt particulier que lui vouent les entreprises qui affichent une vitrine numérique sur le Web. Sans surprise, il s’agit de monétiser l’attention et les clics des utilisateurs. L’article ci-dessous que Framalang a traduit pour vous évoque les Dark UX, c’est-à-dire les techniques insidieuses pour manipuler les utilisateurs et utilisatrices. Il s’agit moins alors de procurer une expérience agréable que d’inciter par toutes sortes de moyens à une série d’actions qui en fin de compte vont conduire au profit des entreprises, aux dépens des internautes. Comment les artifices trompeurs du Dark UX visent les plus vulnérables article original How Dark UX Patterns Target The Most Vulnerable par Ben Bate, Product Designer Traduction Framalang : jums, maryna, goofy, sonj, wyatt, bullcheat + 1 anonyme
Les pièges du Dark UX permettent aux entreprises d’optimiser leurs profits, mais au détriment des plus vulnérables, et en dégradant le Web pour tout le monde. Il faut voir l’expérience utilisateur basée sur ces astuces comme un moyen d’orienter les utilisateurs et utilisatrices vers un certain comportement. Leurs actions ainsi prédéfinies servent les intérêts des entreprises à la manœuvre, et les utilisateurs en sont pour leurs frais d’une manière ou d’une autre. Quelquefois sur le plan financier, d’autres fois au prix des données personnelles ou même au détriment de leurs droits. Les astuces les plus connues incluent de la publicité déguisée, un ajout insidieux de nouveaux objets dans le panier de l’utilisateur, une annulation de souscription particulièrement difficile, ou encore une incitation à dévoiler des informations personnelles que les utilisateurs n’avaient pas l’intention de dévoiler. La liste s’allonge de jour en jour et devient un problème de plus en plus préoccupant. À l’instar des mastodontes du Web tel qu’Amazon et Facebook, la concurrence suit. Faisant peu à peu passer ces astuces dans la norme. Il existe une différence entre marketing bien conçu et tromperie. Ces pratiques s’inscrivent dans cette dernière, et se concentrent uniquement sur l’exploitation des utilisateurs et utilisatrices par des moyens peu respectables. Pour bien mesurer l’étendue de l’application de ces techniques, en voici quelques exemples. Tout d’abord, Amazon. Voici l’exemple d’un rendu d’affichage pour tous les utilisateurs qui ne sont pas des membres premium (Amazon Prime). La première incitation au clic est frontale en plein milieu de l’écran. Alors que l’on pourrait s’attendre à un bouton « Suivant » ou « Continuer », ce bouton débite directement 7,99 £ de votre carte bleue. L’option pour continuer sans être débité est située à côté du bouton. Elle
est présentée sous la forme d’un simple lien hypertexte peu visible au premier coup d’œil, celui se confondant avec le reste de la page. Pour les moins avertis, comme les personnes âgées, les personnes peu habituées à la langue, ou celles qui souffrent d’un handicap, ce type de pratiques peut provoquer beaucoup de perplexité et de confusion. Même pour un concepteur habitué à ce genre de pratiques, il est extrêmement facile de tomber dans le panneau. Sans parler des désagréments que cela entraîne et qui peuvent rompre la confiance établie entre l’entreprise et le consommateur. Dans un monde idéal, Amazon tirerait avantage d’un format simple à lire avec un appel à l’action élémentaire qui permettrait aux utilisateurs de passer outre et continuer. Mais en réalité, les détails sont cachés en tout petits caractères, trop petits à lire pour un peu plus de 5 % de la population mondiale. Les informations sont présentées dans un format bizarrement structuré avec un mélange perturbant de textes en gras de divers poids, de couleurs différentes et une telle quantité de texte qu’on est dissuadé de tout lire. Tant que de telles pratiques seront légales et ne cesseront de
connaître un taux de conversion élevé, les entreprises continueront à les employer. Pendant qu’Amazon s’attaque aux portefeuilles des consommateurs les plus fragiles, Facebook préfère se concentrer sur ses utilisateurs en leur faisant partager un maximum d’informations les concernant, même si ceux et celles qui partagent le font à leur insu. Même si Facebook a fait des progrès sur les questions de confidentialité par rapport à des versions précédentes, l’entreprise continue d’utiliser des techniques de conception subtiles mais insidieuses et déroutantes, comme on peut le voir dans l’exemple ci-dessous. On a beau passer en revue chaque paramètre de confidentialité et sélectionner « Seulement moi », les sections qui contiennent des informations très personnelles et détaillées sont toujours partagées publiquement par défaut. Il ne s’agit pas seulement d’un problème de confidentialité, mais aussi de sécurité. La facilité avec laquelle les pirates peuvent ensuite obtenir des informations pour répondre à des questions de sécurité est stupéfiante. La liste déroulante est subtile et ne demande pas autant d’attention que l’appel à l’action principale. Des fenêtres modales utilisent des mini- instructions pour tromper les utilisateurs. Voyez par exemple :
À première vue, rien ne semble trop bizarre, mais en y regardant de plus près, il devient clair que Facebook incite fortement ses utilisateurs à partager leur bio sur le Fil d’Actualités. Pour cela, il est suggéré qu’en cliquant sur Cancel (Annuler), vous annulez les modifications que vous avez faites à votre bio. En réalité, Cancel signifie Non. Là encore, c’est un genre de pratique qui peut induire en erreur même les personnes les plus vigilantes sur leur confidentialité. Pour les autres cela démontre jusqu’où Facebook est prêt à aller pour que les utilisateurs partagent et interagissent toujours plus. Menant ainsi à des profits publicitaires de plus en plus conséquents. Dans l’industrie des produits et de la conception de sites Web, l’esthétique, les techniques de vente et les profits passent souvent bien avant l’accessibilité et le bien-être des utilisateurs. Shopify, LinkedIn, Instagram, CloudFlare, et GoDaddy sont seulement quelques noms parmi ceux qui ont de telles pratiques pour avoir un impact sur leur profit. Ça peut être simplement de faire un lien de désabonnement de mail écrit en tout petits caractères. Ou de rendre impossible la fermeture de votre compte. Ou quelque chose de plus subtil encore, comme de vous obliger à donner votre identité et votre adresse complète avant de fournir une estimation des frais
d’expédition d’un achat. Mais ce sont bien de telles pratiques trompeuses pour l’expérience utilisateur qui dégradent de façon sévère l’accessibilité et l’utilisabilité du Web. Pour la plupart d’entre nous, c’est simplement une nuisance. Pour les personnes les moins averties, cela peut rendre les sites presque impossibles à utiliser ou à comprendre. Il se peut qu’elles ne puissent pas trouver ce lien de désabonnement caché. Il se peut qu’elles ne remarquent pas que quelque chose a été ajouté à leur panier au moment de passer à la caisse. Et elles peuvent être plongées dans la plus totale confusion entre les paramètres de confidentialité, les publicités déguisées et les spams d’apparence amicale. Le Web est devenu un endroit où vous devez être extrêmement conscient et informé dans des domaines comme la sécurité, la vie privée et les trucs et tromperies, même venant des grandes entreprises les plus réputées au monde. Ce n’est tout simplement pas possible pour tout le monde. Et ici on parle de tromperies, on n’aborde même pas les questions bien plus vastes d’accessibilité comme la lisibilité et les choix de couleurs. Les concepteurs et les équipes doivent être conscients de leur responsabilité non seulement envers les clients, les employeurs et les actionnaires, mais aussi envers les utilisateurs au quotidien. Les problèmes d’accessibilité et les astuces trompeuses impactent le plus durement les plus vulnérables, et il en va de la responsabilité de chacun au sein des équipes de produits et de marketing de veiller à ce qu’il existe des garde-fous. Tant que de meilleures réglementations et lois ne seront pas mises en place pour nous en protéger, il est du devoir des équipes de concevoir des pages de façon responsable et de maintenir un équilibre entre le désir de maximiser le profit et la nécessité de fournir une accessibilité optimale à tous ceux et celles qui utilisent le Web.
* * *
D’autres lectures en anglais sur le même sujet
https://uxplanet.org/5-common-ux-dark-patterns-and-user-
friendly-alternatives-6c8c2f127242
https://uxplanet.org/sinister-ux-how-to-recognize-and-av
oid-dark-ux-patterns-95acdb15767f
… et cet autre article en français, repéré par Khrys dans son
Expresso :
https://open-freax.fr/rgpd-dark-patterns/
Les flux RSS, maintenant !
Il n’y a pas si longtemps, les flux RSS nous étaient familiers
et fort utiles. Aral Balkan nous invite à nous en servir
partout et explique pourquoi ils sont peut-être l’avenir d’un
autre Web en gestation..
Peu compliqués à mettre en place sur une page web, ilspermettent un lien sans intermédiaire entre la production de contenu et son audience, court-circuitant ainsi les plateformes centralisatrices que nous avons laissé parasiter nos communications. Tandis que se confirme une tendance forte à la fédération des contenus, la pertinence des flux RSS qui permet de les découvrir pourrait être un allié important pour re-décentraliser le Web. On veut retrouver les flux RSS D’après le billet d’Aral Balkan Reclaiming RSS Bien avant Twitter, avant que les algorithmes ne filtrent notre réalité à notre place, avant le capitalisme de surveillance, existaient déjà les flux RSS : acronyme de Really Simple Syndication, c’est-à-dire la syndication vraiment simple.4 C’est quoi déjà ? Pour ceux et celles qui sont né⋅e⋅s dans le monde des silos du Web centralisateur, les RSS sont une antique technologie du Web 1.0 (« le Web ingénu des premiers âges » ?). Comme pour beaucoup de choses de cette époque, le nom dit la chose : ils permettent de syndiquer facilement les contenus de votre site, c’est-à-dire de les partager. Les personnes que cela intéresse de suivre vos publications souscrivent à votre flux et reçoivent ainsi les mises à jour en utilisant leur lecteur de RSS. Pas de Twitter ni de Facebook pour s’interposer avec des
algorithmes pour censurer… euh … « modérer » vos billets. RSS est d’une simplicité enfantine à implémenter (juste un fichier XML). Vous pouvez l’écrire à la main si vous voulez (même si je ne le recommande pas). Voici un extrait du flux RSS de mon site, qui vous montre quelques-uns des champs de l’entrée courante de ce billet : Aral Balkan https://ar.al/ Recent content on Aral Balkan Fri, 29 Jun 2018 11:33:13 +0100 … Rediscovering RSS https://ar.al/2018/06/29/rediscovering-rss/ Fri, 29 Jun 2018 11:33:13 +0100 mail@ar.al (Aral Balkan) (The content of this post goes here.) … De plus son implémentation est quasi-universelle. Où est mon RSS ? Il y a bien des chances, si vous avez un site web, que vous ayez déjà un flux RSS, que vous le sachiez ou non. Si par exemple vous utilisez comme moi Hugo pour créer votre site, votre flux RSS est là : /index.xml D’autres générateurs peuvent les insérer ici ou là : at /rss,
/feed, /feed.xml, etc. Le Noun Projet présente une belle sélection d’icônes RSS qui sont à votre disposition À une époque, vous ne pouviez pas surfer sur le Web sans voir partout les séduisantes icônes RSS décorer gracieusement les belles vitrines du Web 1.0. Mais ça, c’était avant qu’elles ne soient vampirisées par les traqueurs espions … euh … « les boutons de partage social » des Google et autres Facebook qui pratiquent la traite intensive d’internautes. Il existait aussi auparavant une saine propension des navigateurs à détecter automatiquement et afficher les flux RSS. Aujourd’hui, il semble qu’aucun navigateur majeur ne le fasse bien nettement. Il est grand temps de revenir à la charge pour exiger une prise en charge de premier plan des flux RSS, une brique importante pour re-décentraliser le Web.
Mais vous n’avez pas besoin d’attendre que les éditeurs de navigateurs se décident (certains comme Google sont eux-mêmes des agents du capitalisme de surveillance et d’autres, comme Mozilla, doivent leurs ressources financières aux capitalistes de la surveillance). Vous pouvez dès maintenant remettre à l’honneur les flux RSS en retrouvant l’adresse URL de votre propre RSS et en l’affichant fièrement sur votre site. Rien de bien compliqué : il suffit d’un lien dans la partie de votre page 5 et d’un lien dans le avec une icône RSS et hop vous voilà dans la famille du Web décentralisé. voici le lien à insérer dans le : et voilà l’en-tête à mettre dans le qui établit le lien avec le flux RSS avec une icône visuellement repérable. Jetez un coup d’œil au Noun Project pour choisir votre icône
RSS, elles sont toutes sous licence Creative Commons. RSS lourd ou léger ? Le lecteur de RSS Leaf affiche parfaitement l’intégralité du contenu HTML. Lorsque vous créez un flux RSS pour votre site, vous avez le choix entre inclure seulement un résumé de votre billet ou bien son contenu intégral. J’ai modifié la configuration de mon Hugo et le modèle de RSS par défaut en suivant les instructions de Brian Wisti pour inclure le contenu intégral dans le flux et je vous recommande d’en faire autant. Il y a six ans, je préconisais l’inverse ! J’écrivais « le RSS lourd n’est qu’une copie du contenu sous un autre nom ». J’avais tort. J’étais trop obsédé par le maintien d’une mainmise formaliste sur mes conceptions et je n’ai donc pas réussi à faire un choix réfléchi en utilisant des critères de
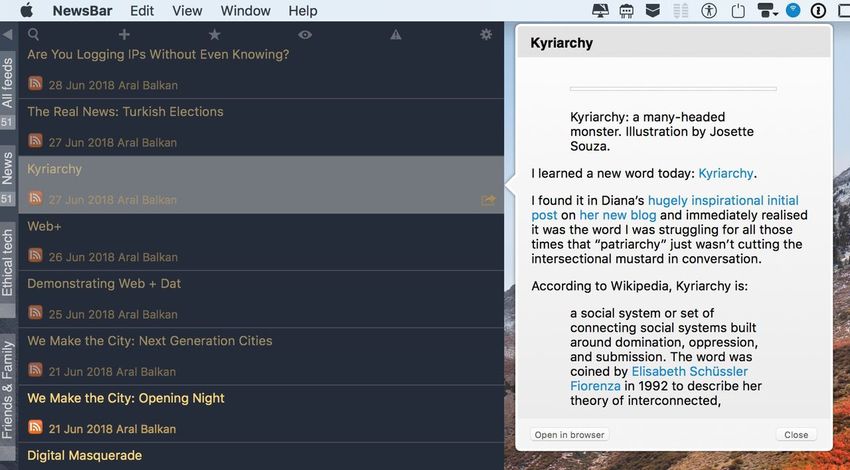
conception éthiques. Le lecteur de RSS Newsbar n’affiche pas les images ni le style correctement dans l’aperçu du contenu. Capture d’écran du lecteur de RSS NewsBar RSS sur macOS qui affiche mes souscriptions, la liste des billets de mon blog et un aperçu de mon billet sur Kyarchy, avec l’image et les styles qui ont disparu. Plus les personnes ont de moyens d’accéder à vos contenus publiés, plus ces contenus ont des chances de rester en ligne et meilleur c’est pour la liberté de tous. Des contenus dupliqués ? Oui, sans problème ! Plus on en a et mieux ça vaut. Eh eh, avec la version web en pair à pair de mon site, le but est idéalement de dupliquer le contenu autant de fois qu’il y aura de personnes pour le parcourir. Certes, votre contenu peut être légèrement différent d’un lecteur RSS à l’autre, car certaines applications ne sont pas conformes aux standards, mais c’est leur problème, pas le vôtre. D’après mes tests partiels, le lecteur Leaf pour macOS affiche mon flux RSS lourd parfaitement alors que NewsBar ne
le fait pas. Pas grave. (et j’espère que l’équipe de NewsBar
en prendra bonne note pour améliorer le rendu dans une
prochaine mise à jour. Après tout, aucune application n’arrive
parfaite sur le marché).
Maintenant que nous nous éloignons du Web centralisé pour
aller vers un Web pair à pair, il est temps de redécouvrir,
adopter et exiger les flux RSS.
Tout ce qui est ancien reprend une nouvelle force.
RSS était un élément essentiel du Web 1.0 avant que le
capitalisme de surveillance (Web 2.0) ne s’en empare.
Ce sera une composante précieuse du Web+ et au-delà.
[Copyright © 2018 Aral Balkan. Licence : Creative Commons
Attribution-ShareAlike.]
Pour aller plus loin sur le sujet des flux RSS, un
autre article du même auteur publié plus récemment
: Refining the RSS
et ses aventures nocturnes pour tenter de faire apparaître
cette maudite icône de RSS.
Pour s’abonner aux flux du Framablog, c’est par ici en
bas à droite
Avec Firefox, il n’est pas très compliqué de s’abonneraux flux web, que ce soit RSS ou autres formats Une entrée de menu dans les marque-pages ou plus direct encore, une icône à mettre dans votre barre personnelle. Davantage de détails dans cet article de SUMO Le nuage de Cozy monte au troisième étage Tristan Nitot est un compagnon de route de longue date pour l’association Framasoft et nous suivons régulièrement ses aventures libristes, depuis son implication désormais « historique » pour Mozilla jusqu’à ses fonctions actuelles au sein de Cozy, en passant par la publication de son livre Surveillance:// Nous profitons de l’actualité de Cozy pour retrouver son enthousiasme et lui poser quelques questions qui nous démangent… — Bonjour Tristan, je crois bien qu’on ne te présente plus. Voyons, depuis 2015 où tu es entré chez Cozy, comment vis-tu tes fonctions et la marche de l’entreprise ?
Tristan Nitot par Matthias Dugué, licence CC-BY — Ça va faire bientôt trois ans que je suis chez Cozy, c’est incroyable comme le temps passe vite ! Il faut dire qu’on ne chôme pas car il y a beaucoup à faire. Ce job est pour moi un vrai bonheur car je continue à faire du libre, et en plus c’est pour résoudre un problème qui me tient énormément à cœur, celui de la vie privée. Autant j’étais fan de Mozilla, de Firefox et de Firefox OS, autant je détestais l’idée de faire un logiciel libre côté navigateur… qui poussait malgré lui les gens dans les bras des GAFAM ! Heureusement Framasoft est là avec Degooglisons-Internet.org et CHATONS, mais il y a de la place pour d’autres solutions plus orientées vers la gestion des données personnelles. C’est quoi l’actualité de Cozy ? La grosse actu du moment, c’est le lancement de Cozy pour le grand public. Le résultat de plusieurs années de travail va enfin être mis à disposition du grand public, c’est très excitant ! Fin 2016, nous avons commencé une réécriture complète de Cozy. Ces deux derniers mois, nous avons ouvert une Bêta privée pour près de 20 000 personnes qui en avaient fait la demande. Et puis hier, nous avons terminé cette phase Bêta pour ouvrir l’inscription de Cozy en version finale à tous. Autrement dit, chacun peut ouvrir son Cozy sur https://cozy.io/ et disposer instantanément de son espace de stockage personnel.
Vous pouvez aussi lire

















































