Développement d'outils de navigation hypermedia (sons) pour dispositifs mobiles (Android).
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Université de Mons
Faculté des Sciences
Institut d’Informatique
Développement d’outils de navigation hypermedia
(sons) pour dispositifs mobiles (Android).
Mémoire réalisé par Daniel DZIAMSKI en vue de l’obtention
du grade de Master en Sciences Informatiques finalité spécialisée
Directeur : Mr Stéphane DUPONT
Année académique 2010-2011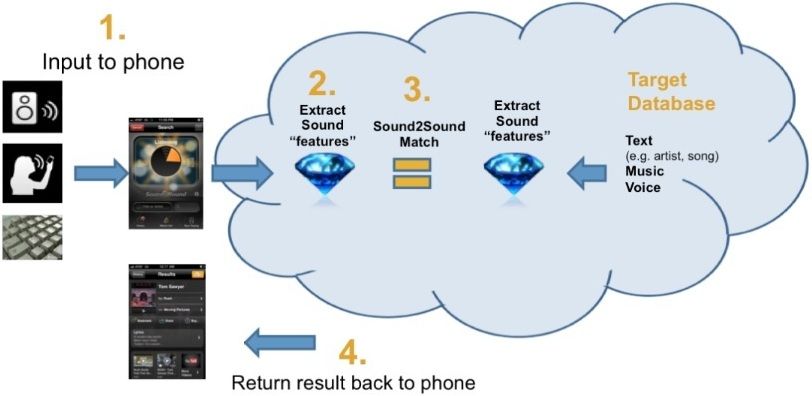
i
Remerciements
En préambule de ce mémoire, je souhaite adresser mes remerciements les plus sincères aux
personnes qui m’ont apporté leur aide et qui ont contribué à l’élaboration de ce travail.
Je tiens tout d’abord à remercier Monsieur Stéphane Dupont, mon Directeur de mémoire,
pour m’avoir permis de réaliser ce travail et pour sa disponibilité tout au long de cette année.
Je remercie également Messieurs Xavier Siebert et Christian Frisson, ainsi que mes Rappor-
teurs, pour les nombreux conseils avisés dont ils m’ont fait part et l’aide précieuse qu’ils m’ont
apportée.
ii
Table des matières
1 Introduction 1
2 Etat de l’art 3
2.1 Technologies mobiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Téléphonie mobile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 Tablette PC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Types de médias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Média . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.2 Multimédia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.3 Hypermédia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.4 Rich média . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Solutions existantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1 Shazam . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.2 Midomi-SoundHound . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 MediaCycle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5 Les apports du mémoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Fingerprinting 10
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 Concepts et définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.2 Caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2.3 Représentation de l’audio en images . . . . . . . . . . . . . . . . . . . . . 14
3.3 Extraction d’empreinte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.2 Extraction d’empreintes . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.4 Recherche et correspondance dans une base de données . . . . . . . . . . . . . . . 26
3.4.1 LookUp table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.4.2 Hachage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4.3 Locality Sensitive Hashing (LSH) . . . . . . . . . . . . . . . . . . . . . . 31
3.4.4 Min-Hash . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.5 Motivation de nos choix . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.5 Protocole expérimental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5.1 Mise en place du protocole . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5.2 Implémentation du prototype . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.5.3 Résultats obtenus avec le prototype . . . . . . . . . . . . . . . . . . . . . 40
iii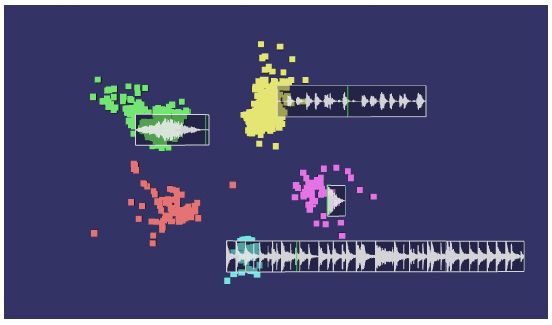
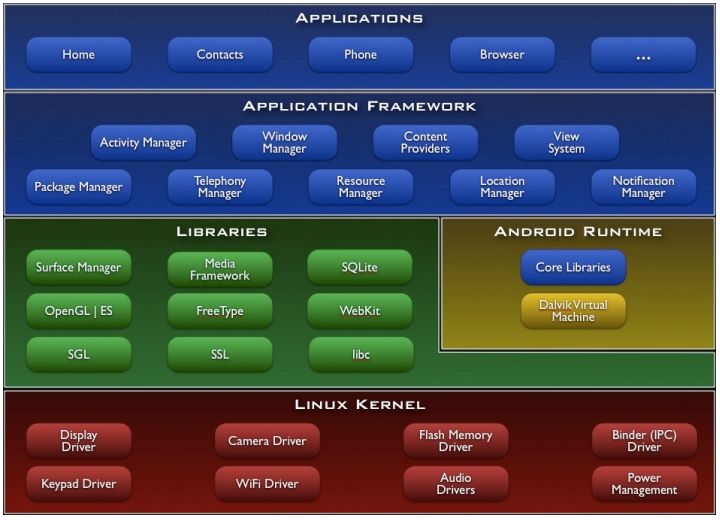
4 Présentation de l’application 47
4.1 Android . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.2 Protocole REST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.2.1 REST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.2.2 Avantages et inconvénients de REST . . . . . . . . . . . . . . . . . . . . . 52
4.3 Base de données SQLite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3.1 SQLite pour Android . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.4 Serveur Apache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.4.1 Apache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.5 Base de données du serveur et de MediaCycle . . . . . . . . . . . . . . . . . . . . 54
4.6 MediaCycle-AudioCycle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.6.1 MediaCycle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.6.2 AudioCycle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.6.3 Visualisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.7 Présentation des différents modules de l’application . . . . . . . . . . . . . . . . . 58
4.7.1 Interface d’accueil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.7.2 Informations de l’application . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.7.3 Enregistrer un son . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.7.4 Tagging et géolocalisation . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.7.5 Lister les sons . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.7.6 Envoyer des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.7.7 Visualiser les clusters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5 Conclusion 71
Annexes 77
A HashTable et HashList 77
B Commandes SoX 80
C Utilisation du prototype de recherche d’empreintes 82
C.1 Interface d’accueil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
C.2 Traitement des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
C.3 Recherche d’empreintes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
D Différents résultats obtenus grâce au prototype 86
iv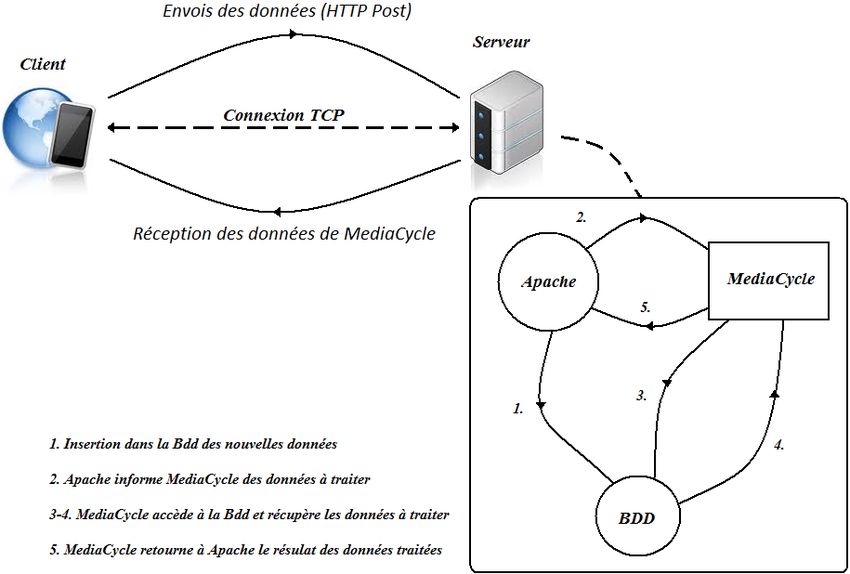
Chapitre 1
Introduction
Le contenu de ce rapport est ciblé sur le processus d’extraction d’empreinte et l’analyse des
algorithmes de recherche de correspondance dans une base de données. Ce document est réalisé
en suivant plusieurs objectifs. D’une part, il a pour but d’expliquer les différentes phases du pro-
cessus d’extraction et d’étudier l’efficacité des différents algorithmes de recherche. D’autre part, il
présente le développement d’un prototype de recherche d’empreinte basé sur ces théories et l’im-
plémentation d’une application Android fonctionnant à partir de ces éléments.
Le laboratoire de Théorie des Circuits et Traitement du Signal (TCTS) a développé un logi-
ciel d’analyse de données multimédias appelé MediaCycle. Ces données peuvent par exemple être
des sons, des images ou encore des vidéos. Le fonctionnement de MediaCycle et les résultats que
l’on obtient grâce à son utilisation sont présentés de façon détaillée dans la suite de ce rapport. La
volonté du TCTS est de pouvoir profiter des fonctionnalités de ce logiciel au travers de nouveaux
terminaux mobiles s’exécutant sous Android.
L’idée est d’exploiter au maximum les équipements des smartphones et tablettes interactives.
Ceux-ci, étant munis de nombreux senseurs (GPS, audio, vidéo, ...) et de possibilités d’actions mul-
titactiles, offrent un potentiel important pour le développement d’applications pervasives. Grâce à
l’utilisation de ces outils et des multiples fonctionnalités qu’ils offrent, il est possible aujourd’hui
de lier plus aisément le monde réel au contenu numérique présent sur internet. Le but est de déve-
lopper un système qui tire parti de ces senseurs et qui permet de rechercher des éléments multimé-
dias dans une base de données par l’intermédiaire de MediaCycle.
Les objectifs principaux du mémoire sont donc dans un premier temps : se focaliser sur une
composante des algorithmes de recherche par similarité et fingerprinting, le hachage perceptuel. Le
but est d’étudier l’impact du hachage sur la vitesse et la qualité de la recherche, ainsi que l’impact
perturbateur du bruit sur le "hash code" obtenu. Dans un second temps, nous développons une ap-
plication fonctionnant sous Android. Celle-ci permet d’exploiter les fonctionnalités et les résultats
de MediaCycle sur les différentes surfaces tactiles, gsm ou tablette. L’application a pour utilité de
traiter des données audio dans le but de trouver des éléments sonores ayant des caractéristiques
similaires.
A la fin de son développement, l’application est évaluée et testée. Si les résultats obtenus
sont convaincants, l’application peut éventuellement trouver sa place sur l’Android Market 1 et être
disponible gratuitement pour les utilisateurs désirant l’acquérir. Le souhait est d’offrir un logiciel
1. https://market.android.com/
1
libre, gratuit, mais aussi innovant afin de concurrencer les différentes applications similaires qui
sont déjà présentes sur le marché.
La suite de ce document est organisée comme suit.
Au chapitre 2, nous présentons une description de l’état de l’art. Nous y abordons notamment
les différentes technologies mobiles qui regroupent principalement la téléphonie mobile et les ta-
blettes PC. Nous donnons également un rappel sur les types de médias qui existent dans le monde
actuel. Enfin, nous y présentons les solutions qui réalisent un travail similaire à l’application que
nous développons et les apports de ce mémoire par rapport à ces solutions.
Au chapitre 3, nous nous focalisons sur le hachage perceptuel qui est une composante des al-
gorithmes de recherche par similarité et fingerprinting. On y énonce une définition de fingerprinting
et les concepts qui lui sont liés. Par la suite, nous expliquons en détails les différentes phases qui
constituent le processus d’extraction d’empreinte. L’analyse des algorithmes de recherche de cor-
respondance dans une base de données permet de clôturer ces éléments théoriques. Nous concluons
ce chapitre, en exposant le protocole expérimental mis en place. Nous y présentons le prototype
que nous avons développé et les résultats que nous avons obtenus à partir de celui-ci.
Le chapitre 4 est consacré à l’implémentation de l’application Android. Nous y présentons
dans un premier temps les différents éléments nécessaires au bon fonctionnement de l’application.
Il s’agit tout d’abord du protocole REST. Ensuite, nous expliquons le serveur Apache et la base de
données que nous utilisons. Enfin, nous exposons de façon avancée le fonctionnement de Media-
Cycle. La suite du chapitre est dédiée à la présentation et à l’explication de l’ensemble des modules
qui composent l’application Android que nous avons développée.
Enfin, nous clôturons ce rapport par une conclusion dans laquelle nous rappelons l’essentiel
du travail accompli et les résultats obtenus. Nous y présentons également les perspectives futures.
2
Chapitre 2
Etat de l’art
Dans ce chapitre, nous faisons tout d’abord le point sur les différentes technologies mobiles
qui existent et avec lesquelles nous travaillons afin de réaliser ce mémoire. Nous parlons ensuite des
données que nous traitons. Celles-ci peuvent être de différents types (multimédia, hypermédia, ...).
Au cours de la réalisation de ce mémoire, nous nous appuyons également sur un logiciel existant :
MediaCycle. Nous allons expliquer de façon brève et claire en quoi il consiste. Celui-ci est détaillé
de manière beaucoup plus précise dans la Section 4.6. Pour terminer, nous parlons des solutions
et des applications qui existent déjà sur le marché, ainsi que des apports supplémentaires que ce
mémoire peut offrir en comparaison à ces applications.
2.1 Technologies mobiles
Selon les articles publiés par le CNUCED 1 [10] et le Forum du Commerce International [23],
les technologies mobiles changent le monde plus rapidement et plus profondément que toute autre
innovation. Les tendances observées durant l’année précédente, montrent une croissance rapide et
continue de l’utilisation de ces technologies. Aujourd’hui, elles sont devenues la principale forme
de connectivité et d’accès aux TIC 2 . A l’heure actuelle, nous pouvons les distinguer suivant deux
grandes catégories : la téléphonie mobile qui est présente depuis de nombreuses années et les
tablettes qui envahissent les marchés.
2.1.1 Téléphonie mobile
La téléphonie mobile, comme son nom l’indique, est un moyen de communication par télé-
phone sans fil. Elle fut inventée dans les années 40 par le docteur Martin Cooper [43], Directeur
de la recherche et du développement chez Motorola. Cependant, il faut attendre l’année 1983 pour
voir le premier téléphone mobile commercialisé par cette même marque.
Ce moyen de communication s’est largement répandu à la fin des années 90, grâce aux amé-
liorations des composants électroniques et notamment leur miniaturisation. Bien que sa fonction
d’usage soit la communication vocale, cette évolution permet alors aux téléphones d’acquérir des
fonctions plus évoluées tels que l’appareil photo, le Web, le GPS, ... On parle alors de smartphone.
Ces appareils font désormais logiquement partie de notre quotidien.
1. Conférence des Nations Unies sur le Commerce et le Développement
2. Technologies d’information et de communication
3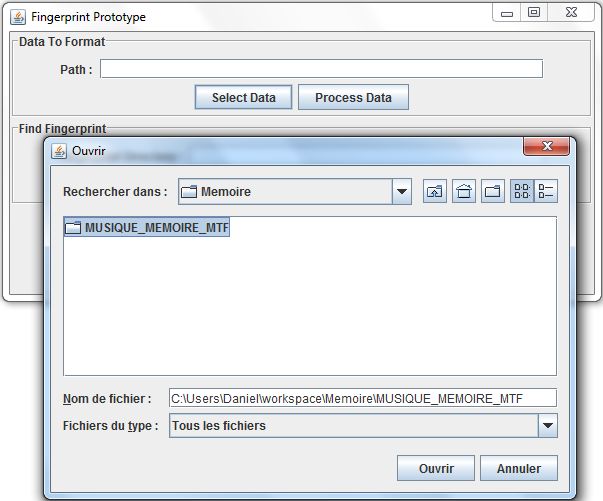
Grâce aux informations annoncées par le CNUCED [10], nous pouvons résumer l’utilisation des
téléphones mobiles en quelques chiffres par :
• Huit fois plus de téléphones mobiles que de lignes fixes.
• Trois fois plus de téléphones mobiles que d’ordinateurs personnels.
• Près de deux fois plus de téléphones mobiles que de téléviseurs.
2.1.2 Tablette PC
La dénomination de tablette PC [42] sert en général à désigner un ordinateur mobile de la
forme d’une ardoise. Celui-ci est équipé d’un écran tactile et ne possède pas de clavier physique.
Ce terme a été rendu populaire grâce à un produit mis sur le marché en 2001 par Microsoft,
un stylo-ordinateur. Celui-ci a tiré avantage des évolutions technologiques pour remettre au goût
du jour un concept existant depuis de nombreuses années via Apple et Atari. Différent des PDA
par la taille et des tablettes graphiques par son côté "PC", il n’arrive cependant pas à s’imposer,
jusqu’en 2010 et l’arrivée de l’iPad.
L’iPad d’Apple a eu pour effet de revigorer le marché de la tablette PC. Dès lors, une guerre
entre les différentes grandes marques du monde informatique a été déclenchée afin de conquérir
ce nouveau domaine. Parmi celles-ci, nous pouvons citer comme étant le principal concurrent de
l’iPad, le Samsung Galaxy Tab sous Android.
Volume des ventes de tablettes en 2010 :
Selon Strategy Analytics [24], le volume des ventes de tablettes pour l’année 2010 s’élève à
17, 6 millions d’unités, dont 14, 8 millions sont à mettre à l’actif de l’iPad. Cela représente 84% du
marché. Avec 2, 1 millions de tablettes vendues au cours du dernier trimestre 2010 (T4), le Galaxy
Tab semble offrir une alternative crédible à l’iPad. Cependant, toujours d’après Strategy Analytics,
Apple devrait conserver plus de 70% du marché des tablettes en 2011 grâce au lancement de sa
nouvelle perle : l’iPad2. On estime les ventes de tablettes à 55 millions en 2011 dont 40 millions
pour Apple. Les Figures 2.1 et 2.2 montrent le résultat des ventes en 2010.
F IGURE 2.1 – Nombre, en million d’unités, de tablettes vendues au cours du 3ème et 4ème trimestres
de 2010 (respectivement T3 et T4) ainsi que sur l’ensemble de l’année écoulée [24].
4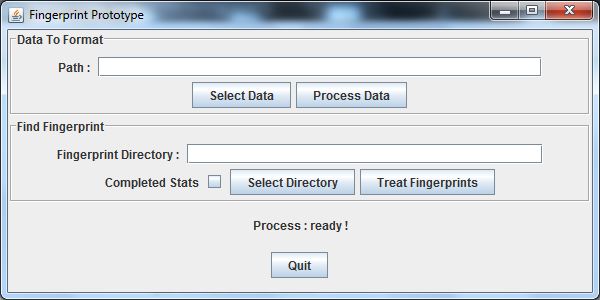
F IGURE 2.2 – Pourcentage des ventes au cours du 3ème et 4ème trimestres de 2010 (respectivement
T3 et T4) ainsi que sur l’ensemble de l’année écoulée [24]
2.2 Types de médias
Dans le Chapitre 1, nous avons affirmé que le logiciel MediaCycle pouvait travailler sur
diverses données multimédias. Dans cette section, nous donnons une définition de ce que représente
un média dans le monde d’aujourd’hui. En réalité, il existe des données multimédias, hypermédias
et des rich médias. Nous allons définir ces trois types de données et voir les différences qui existent
entre eux.
2.2.1 Média
De façon générale en 2.2.1, nous allons définir ce qu’est un média. Grâce à cela, il sera plus
facile de comprendre les différents éléments mentionnés ci-dessus.
Définition 2.2.1. Un média [35] correspond à un moyen impersonnel de diffusion d’informations.
Il est utilisé pour communiquer avec un grand nombre d’individus. Cependant, aucune personna-
lisation du message ou du contenu n’est possible, on parle alors parfois de médias de masse.
Les médias sont devenus un moyen de communication extrêmement important dans la société
contemporaine. Ils sont, par exemple, le fondement du marketing et de la publicité. Actuellement,
les sept principaux médias sont le langage, la presse, l’affichage, le cinéma, la radio, la télévision
et dernièrement Internet mais il en existe beaucoup d’autres. Les trois premiers représentent des
moyens de diffusion naturels, tandis que les autres sont des moyens de diffusion techniques.
2.2.2 Multimédia
Le terme multimédia [36] a fait son apparition vers la fin des années 1980 avec la popu-
larisation des CD-ROM et des bornes interactives. Il servait alors à désigner les applications qui
mélangeaient différents médias simultanément tels que le son, la musique, l’image ou la vidéo.
Cela était désormais possible grâce à la capacité de stockage des CD-ROM et aux performances
grandissantes des ordinateurs.
Cependant, il faut attendre la fin des années 90 avec l’arrivée des méthodes de compression
audio et vidéo, liée à une croissance significative du nombre et de la puissance des ordinateurs,
pour obtenir une qualité semblable aux divers autres médias réunis. Aujourd’hui, le multimédia est
considéré comme la convergence de médias textuels, d’images, de vidéos et de sons dans un seul
et même élément.
D’un point de vue informatique, une donnée multimédia fait appel à deux techniques proches,
l’hypertexte et l’hypermédia. L’hypertexte consiste à lier un ensemble de fichiers par un réseau de
5relations non séquentiel. Grâce à ce réseau de liens, l’utilisateur peut naviguer parmi les différents
sujets sans se soucier de l’ordre dans lequel ils sont rangés. On parle de navigation non-linéaire,
contrairement à un fichier vidéo qui offre un contenu linéaire.
2.2.3 Hypermédia
Un hypermédia [46] est un hypertexte présentant une différence essentielle. Il représente un
média dans lequel les données ne sont pas seulement de type texte mais aussi de type image, son,
vidéo ou même multimédia. De manière simple, un hypermédia est une combinaison de l’hyper-
texte à des données multimédias, permettant d’inclure des liens entre des éléments textuels, visuels
et sonores.
Comme nous l’avons dit dans la Sous-Section 2.2.2, grâce au mécanisme d’hypertexte, l’en-
tièreté des informations sont liées et offrent une navigation non-linéaire et interactive dans un
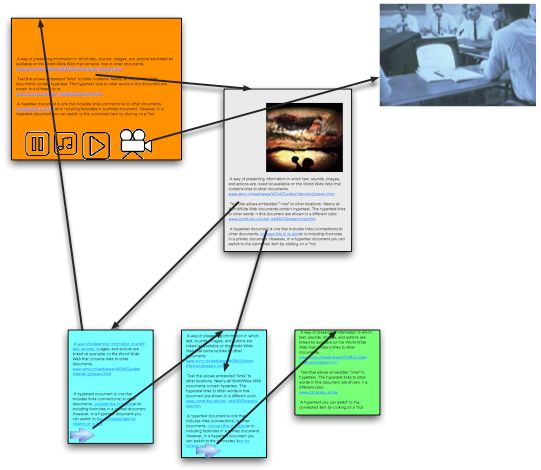
ensemble de données textuelles, visuelles et sonores. La Figure 2.3 représente un exemple de do-
cument hypermédia où l’utilisateur peut naviguer de page en page en cliquant sur les différents
éléments multimédia.
F IGURE 2.3 – Exemple de document hypermédia [19]
Le document hypermédia le plus simple et le plus connu à l’heure actuelle n’est autre que le
World Wide Web. La quasi totalité des applications disponibles sur Internet optent désormais pour
une architecture où l’information est présentée en suivant cette approche.
62.2.4 Rich média
La famille du rich média [5] est une appellation générique pour tous les formats permettant
une interaction poussée avec l’internaute. De ce fait, il est souvent associé à la notion d’interfaces
riches. Généralement, le rich média définit un format publicitaire Internet remplissant au moins
une des conditions suivantes :
• Proposer aux utilisateurs une interaction au delà du clic habituel.
• Utiliser une technologie d’affichage dynamique hors des espaces classiques prédéfinis.
• Intégrer du son ou de la vidéo.
2.3 Solutions existantes
Comme énoncé dans le Chapitre 1, le but de notre application est d’analyser des éléments
sonores afin d’extraire d’une base de données du contenu audio ayant des caractéristiques simi-
laires. Dans cette section, nous présentons les différentes applications existantes sur le marché des
technologies mobiles et qui réalisent un travail similaire.
Après quelques recherches, deux applications semblent se détacher des autres. La première
se nomme Shazam et la seconde porte le nom de Midomi-SoundHound. Ces deux logiciels sont
disponibles gratuitement sur l’Android Market.
2.3.1 Shazam
Shazam [31] est une application disponible pour les technologies mobiles dont le principe se
base sur la reconnaissance musicale. L’idée, développée en 2002 par Avery Li-Chun Wang, était
uniquement disponible au Royaume-Uni. Aujourd’hui, Shazam se décline dans tous les pays et sur
tous les appareils mobiles. Il est l’outil d’identification musicale le plus utilisé et existe en deux
versions. La version gratuite donne cinq identifications par mois à un utilisateur, contrairement à
la payante qui offre un usage total.
Fonctionnement
De manière simple, Shazam [7] consiste à utiliser le microphone intégré aux dispositifs mo-
biles afin de capturer un morceau de musique (environ 30 secondes). Ensuite, des techniques de
hachage et de fingerprinting sont appliquées sur le spectrogramme de l’échantillon obtenu. Nous
expliquons celles-ci de façon approfondie dans le Chapitre 3.
Lorsque ces méthodes ont été appliquées, nous comparons les caractéristiques extraites avec
celles disponibles dans une base de données. A l’origine, la base de données utilisée pour Shazam
contenait 1, 8 millions d’entrées. Aujourd’hui, on en compte plus de 8 millions. Si une corres-
pondance est trouvée dans la base de données, des informations telles que l’artiste, le titre de la
chanson, le nom de l’album, ... sont retournées à l’utilisateur.
7Résultat
La qualité de la recherche dépend de la qualité de l’échantillon enregistré. Cependant, Sha-
zam est réputé pour fonctionner de manière efficace même avec des morceaux sonores de qualité
moyenne ou avec des bruits de fond. Les réponses obtenues sont correctes et rapidement affichées
à l’utilisateur.
2.3.2 Midomi-SoundHound
Midomi-SoundHound a été développé il y a peu d’années par un groupe de chercheurs ca-
liforniens. Le principe de base est identique à celui proposé par Shazam. Cependant, Midomi-
SoundHound va plus loin et offre non seulement une identification des musiques à partir d’échan-
tillons enregistrés mais aussi via des sifflements ou des fredonnements de la part de l’utilisateur. Le
fonctionnement des deux applications et les résultats obtenus sont similaires. Un bref comparatif
est proposé en [4].
La Figure 2.4 montre le fonctionnement de Midomi-SoundHound suivant quatre étapes prin-
cipales. A noter qu’il en va de même pour Shazam.
1. A la première étape, un utilisateur à le choix entre capturer un extrait sonore, indiquer le nom
d’un artiste ou le titre d’une chanson.
2. L’extrait capturé est ensuite envoyé sur un serveur afin d’être traité. L’objectif est d’extraire
certaines caractéristiques qui seront utilisées pour effectuer la recherche dans la base de
données.
3. La troisième étape consiste à faire correspondre les caractéristiques obtenues à celles pré-
sentes dans la base de données dans le but de trouver une correspondance.
4. Enfin, si une correspondance est trouvée, des informations telles que le titre, l’artiste ou les
paroles de la chanson sont retournées à l’utilisateur.
F IGURE 2.4 – Fonctionnement de Midomi-SoundHound suivant 4 étapes [4]
82.4 MediaCycle
MediaCyle est un logiciel d’analyse de données multimédias. Celui-ci a été principalement
développé par le laboratoire de Théorie des Circuits et Traitement du Signal (TCTS). Les méthodes
utilisées pour son fonctionnement sont différentes de celles employées pour Shazam ou Midomi-
SoundHound. A savoir, MediaCycle n’intègre pas des techniques de hachage et de fingerprinting.
Pour faire face à cet inconvénient, nous avons développé un prototype qui permet de réaliser de la
recherche d’empreinte. Celui-ci est détaillé dans la Section 3.5. D’autres différences sont à énon-
cer, notamment au niveau de son utilisation.
Premièrement, contrairement à Shazam et Midomi-SoundHound, MediaCycle n’est pas li-
mité à un seul type de média. Il peut être utilisé pour des données sonores ou visuelles sans néces-
siter de changement. Evidemment, l’analyse se fait suivant des descripteurs différents selon le type
de données mais cette globalisation a pour avantage de rendre MediaCycle plus générique.
Deuxièmement, nous savons que les deux applications présentées dans la Section 2.3 sont
spécialisées dans la recherche de contenu identique. L’utilisateur veut retrouver le titre de la chan-
son qu’il entend et rien d’autre. L’idée de MediaCycle est plutôt axée sur une recherche des conte-
nus "similaires".
MediaCycle a déjà trouvé sa place dans de nombreux projets réalisés par Numédiart pour
différents clients. Nous pouvons par exemple citer Laughter Cycle [14], Audio Cycle [13] ou encore
le projet Dancers [34] dont nous pouvons voir le résultat en [1].
2.5 Les apports du mémoire
Le but est de développer une application Android afin de pouvoir profiter des avantages cités
ci-dessus qu’intègre Mediacycle par rapport à Shazam ou Midomi. L’idée est évidemment d’utili-
ser cette application sur les nouvelles technologies mobiles.
Ensuite, l’application sera développée de façon à offrir aux utilisateurs un outil de recherche
novateur. Nous exposons dans le Chapitre 4 les différentes vues et méthodes de recherche qu’il est
possible d’utiliser.
Enfin, nous désirons offrir une application libre et gratuite aux utilisateurs. Comme nous
l’avons dit précédemment, MediaCycle peut travailler sur plusieurs types de médias. La nouveauté
à ce niveau résidera dans le fait que les bases de données contenant ces médias seront constituées
grâce à la contribution des utilisateurs.
9Chapitre 3
Fingerprinting
Dans ce chapitre, nous développons l’ensemble des éléments théoriques liés à la technique
du fingerprinting. Tout d’abord, nous introduisons le sujet en le situant historiquement et dans dif-
férents domaines. Ensuite, nous proposons une définition de ce qu’est le fingerprinting et dans la
Section 3.3, nous parlons du principe d’extraction d’empreinte. Nous expliquons les différentes
phases qui composent le processus d’extraction et les descripteurs sonores que nous utilisons. Les
méthodes de recherche d’empreinte dans une base de données sont quant à elles expliquées en
Section 3.4. La Section 3.5 permet de clôturer ce chapitre en présentant le protocole expérimental
que nous avons mis en place.
Afin d’être le plus complet et le plus clair possible dans ce chapitre, nous nous basons prin-
cipalement sur deux documents reconnus dans le milieu. Il s’agit des articles publiés par J.A.
Haitsma [21] et Yan Ke [48].
3.1 Introduction
Lorsque nous parlons d’empreinte ou de fingerprint, nous pensons directement aux em-
preintes digitales. Cela vient inévitablement du fait qu’il s’agisse du système d’empreinte le plus
connu à ce jour. Il a été mis en place à partir de 1893 par Sir Francis Galton, qui a été le premier
à prouver qu’une empreinte digitale est unique et de ce fait qu’il n’existe pas deux humains ayant
des empreintes identiques. Dès lors, même si parfois ces dernières possèdent des similarités, nous
pouvons identifier n’importe quel être humain via ses empreintes digitales.
Récemment, au niveau du monde scientifique, nous notons à nouveau un intérêt croissant
dans le domaine du fingerprinting. Ce soudain regain d’intérêt n’est pas provoqué cette fois par
les empreintes digitales, mais par les empreintes de données multimédias, notamment audio. Les
chercheurs croient que certains problèmes du domaine audio peuvent être naturellement dérivés en
une forme accessible par les techniques informatiques. La principale idée est de transformer des si-
gnaux audio à une dimension dans le temps en des représentations visuelles 2D temps-fréquences.
De manière simple, il s’agit de transformer un son en une ou plusieurs images appelées spectro-
grammes.
Le principal objectif de la recherche d’empreintes sur des données multimédias est de dé-
terminer si deux données sont perceptivement équivalentes. Par perceptivement équivalent, nous
entendons que la comparaison entre les deux objets multimédias ne s’effectue pas au niveau de
10leur contenu mais grâce aux empreintes associées.
Aujourd’hui, dans la plupart des systèmes qui utilisent la technologie de fingerprinting, les
empreintes ainsi que les meta-data (nom de l’artiste, titre de la chanson, ...) d’un grand nombre
de données multimédias sont stockées conjointement dans la base de données. Dans ce type de
base de données, les empreintes servent d’index et sont utilisées pour effectuer des requêtes. Nous
pouvons citer trois avantages à l’utilisation de ces empreintes et non du contenu multimédias :
1. Diminution de la mémoire et des espaces de stockage nécessaires. En effet, nous ne gardons
que les empreintes et celles-ci sont de plus petite taille que le contenu.
2. Comparaison efficace étant donné que les caractéristiques perceptives non pertinentes ont
déjà été retirées des empreintes.
3. Recherche plus efficace et plus rapide de données car celles-ci sont plus petites.
Deux grands domaines se partagent principalement cette technologie. Il s’agit du contrôle
de la diffusion des médias et de la reconnaissance de contenu audio. Le premier consiste à vérifier
les données audio émises aussi bien à la télévision ou à la radio. Cela a pour avantage d’examiner
les droits de diffusion et de collecter des statistiques. Un exemple de site Web qui réalise cela est
Yacast 1 . Le second domaine trouve son intérêt dans le monde scientifique, pour les traitements so-
nores, mais aussi grâce à des applications telles que Shazam ou Midomi-SoundHound présentées
dans la Section 2.3.
Pour conclure cette introduction, nous pouvons dire d’après ce que nous avons énoncé ci-
dessus, qu’un système de fingerprint est constitué de deux éléments principaux : une méthode
d’extraction d’empreinte et une méthode efficace de recherche d’empreinte dans une base de don-
nées.
3.2 Concepts et définition
Dans cette section, nous définissons en quoi consiste une fonction de fingerprint, les carac-
téristiques nécessaires au fonctionnement d’un système basé sur cette méthode et finalement, nous
illustrons les différentes représentations que peut prendre une donnée audio.
3.2.1 Définition
Si nous prenons en considération ce que nous avons décrit dans la section précédente, et
que nous gardons à l’esprit qu’une empreinte audio peut être vue comme le "résumé" d’un média
sonore, nous pouvons énoncer la définition suivante :
Définition 3.2.1. Une fonction de fingerprint F devrait faire correspondre une donnée audio X,
composée d’un grand nombre de bits, à une empreinte de cette donnée, composée d’un nombre
limité de bits.
Nous pourrions naturellement penser que les fonctions de hachage cryptographique sont de
bons candidats pour les fonctions de fingerprint. Cependant, en considérant la Définition 3.2.2,
1. http://www.yacast.fr/fr/index.html
11l’égalité mathématique au sens "strict" exclu cette possibilité car nous sommes intéressé par des si-
milarités perceptives et non de contenu identique. L’Exemple 3.2.1 illustre le concept de similarités
perceptives.
Définition 3.2.2. Une fonction de hachage cryptographique permet de comparer deux objets, X
et Y, de taille conséquente, en comparant les valeurs de hachage H(X) et H(Y). Si H(X) = H(Y)
alors X = Y.
Exemple 3.2.1. Si l’on prend une chanson de Michael Jackson - "Smooth Criminal". La version
originale sur CD et la version MP3 à 128Kb/s vont être perçues de façon identique par l’oreille
humaine. Néanmoins, leurs structures internes (spectrogramme) peuvent être différentes. Bien que
ces deux versions soient perceptivement similaires, elles sont mathématiquement différentes.
Le dernier concept nécessaire pour finaliser notre définition est énoncé dans la Propriété 3.2.1.
Elle se base sur le fait que deux données audio perceptivement similaires ont des empreintes simi-
laires.
Propriété 3.2.1. Afin de pouvoir faire une distinction entre deux données audio différentes, il doit
y avoir une très forte probabilité que ces données différentes se traduisent par des empreintes
différentes. De façon mathématique, nous pouvons dire que pour une fonction de fingerprint F,
nous définissons un seuil T tel qu’il existe une forte probabilité que X et Y soient similaires si
||F (X) − F (Y )|| ≤ T et différentes si ||F (X) − F (Y )|| > T
Dans la propriété ci-dessus, || · || définit une norme. Une norme est une fonction qui assigne
une longueur strictement positive à tous les vecteurs dans un espace vectoriel. Cependant, elle peut
aussi définir une distance entre deux vecteurs. Dans notre cas, nous pouvons donc considérer que
||F (X) − F (Y )|| est la distance entre deux spectres ou deux empreintes binaires.
Il existe différents types de normes dont les plus connues sont : la norme euclédienne, la
norme de Manhattan ou encore la ρ-norme. Si nous prenons comme exemple les séquences de bits
ci-dessous, nous pouvons définir la norme euclédienne et la norme de Manhattan de la manière
suivante :
séquence 1 0 0
séquence 2 0 1
séquence 3 1 0
séquence 4 1 1
• Norme euclédienne : la norme euclédienne est définie comme suit :
v
u n
uX
||x||2 = t |xi |2 (3.1)
i=1
Nous obtenons donc comme résultats pour les différentes séquences :
séquence 1 → 0
séquence 2 → 1
séquence
√ 3 → 1√
séquence 4 → 12 + 12 = 2 ≈ 1.41
12• Norme de Manhattan : la norme de Manhattan est définie comme suit :
n
X
||x||1 = |xi | (3.2)
i=1
Nous obtenons dans ce cas ci pour les différentes séquences :
séquence 1 → 0
séquence 2 → 1
séquence 3 → 1
séquence 4 → 2
A partir de cet exemple, nous pouvons dire que les différentes normes présentées ci-dessus
peuvent convenir et être employées dans la propriété 3.2.1.
Grâce à la Définition 3.2.1 et la Propriété 3.2.1, nous avons maintenant une définition claire
et précise de ce qu’est une fonction de fingerprinting ainsi que la principale propriété sur laquelle
elle repose.
3.2.2 Caractéristiques
Suite à notre définition de fingerprint, nous pouvons nous focaliser sur les caractéristiques
nécessaires au bon fonctionnement d’un système basé sur cette méthode.
• Robustesse : dans le but d’avoir un système efficace, la recherche d’empreinte doit être
réalisée sur des caractéristiques perceptives invariantes à la dégradation des signaux. Idéa-
lement, des données audio fortement dégradées devraient mener à des empreintes quasi-
ment similaires.
• Fiabilité : elle correspond au nombre de comparaisons d’empreintes qui ont réussi. Ce
phénomène se produit lorsqu’une identification retourne un résultat qui est celui attendu.
Pour caractériser la fiabilité, nous pouvons mettre en avant les concepts de vrai positif et
de faux positif. Ceux-ci seront développés dans la Section 3.5.3
• Taille de l’empreinte : pour augmenter la rapidité de la recherche d’empreintes, celles-ci
sont généralement stockées en mémoire vive (RAM). La taille des empreintes, qu’elles
soient en bits par seconde ou bits par chanson, détermine fortement les ressources néces-
saires pour la mise en place d’une base de données d’empreintes.
• Granularité : nous pouvons considérer la granularité comme étant la taille de la donnée,
de l’extrait à fournir à l’application. Ce paramètre dépend du type d’application mis en
place et des données que celle-ci traite.
• Vitesse et croissance : ces deux critères sont essentiels lors d’un déploiement commercial
d’un système de recherche d’empreinte sonore. La vitesse de recherche dépend de la crois-
sance de la base de données. Nous savons que la taille de celle-ci deviendra relativement
importante avec le temps. Si la recherche effectuée par un utilisateur prend trop de temps,
celui-ci délaissera le système pour un autre plus performant.
13La mise en place d’un tel système peut représenter un "challenge", car il requiert un équilibre
entre ces cinq paramètres. Ces éléments ont une forte influence les uns sur les autres. Par exemple
un système exigeant une haute fiabilité demande une empreinte de taille plus importante et une
granularité plus élevée. L’augmentation de la taille de l’empreinte a pour effet de diminuer les
performances de recherche dans la base de données où elle est stockée.
3.2.3 Représentation de l’audio en images
Dans cette sous-section, nous prenons le temps d’illustrer les différentes représentations qui
existent pour un média audio. Nous expliquons chacune d’elles afin d’avoir un aperçu et une bonne
idée des données sur lesquelles nous travaillons dans la suite.
Onde sonore
Quand nous parlons de représenter un son, nous pensons directement à une onde sonore
comme nous pouvons le voir dans la Figure 3.1. Ce graphique illustre l’amplitude en fonction du
temps. Cette vision du son est la plus courante car elle est fortement utilisée dans le monde de la
musique, notamment des mixeurs et des ingénieurs du son pour ajuster leurs compositions.
F IGURE 3.1 – Représentation 2D d’une onde sonore pour un extrait audio [2]
Néanmoins, bien que couramment utilisée, cette représentation sera inutile car elle ne permet
pas de réaliser des comparaisons d’empreintes.
Spectrogramme
Comme nous l’avons énoncé dans la Section 3.1, la seconde façon de représenter des données
audio à une dimension, sous la forme d’une image en deux dimensions, est le spectrogramme. Ceci
est possible grâce à une technique appelée Transformée de Fourier. La Définition 3.2.3 explique
de manière plus technique en quoi consiste un spectrogramme.
Définition 3.2.3. Un spectrogramme [41] est une représentation spectrale des facteurs temps-
fréquence (sous forme d’une image) qui montre comment la densité spectrale d’un signal varie
avec le temps. Dans le domaine du traitement des signaux "temps-fréquence", il est l’une des
représentations les plus couramment utilisées. Aussi connu sous le nom de sonogramme ou encore
empreinte vocale, ils sont utilisés pour identifier des sons, de la musique ou pour effectuer du
traitement vocal.
14Aujourd’hui, il existe deux façons d’illustrer un spectrogramme : une image en deux ou en
trois dimensions. La Figure 3.2 montre une représentation en deux dimensions qui reste l’approche
majoritairement utilisée à l’heure actuelle.
F IGURE 3.2 – Spectrogramme d’un morceau de musique d’une durée de 5 secondes et dont la
fréquence est comprise entre 0 et 5000 Hertz [8]
Exemple
Nous clôturons cette sous-section en réalisant une analogie entre la visualisation d’un même
son sous la forme d’une onde et d’un spectrogramme. Cela permet de mieux observer les effets que
produisent une modification de la fréquence sur les deux types de représentations. Nous voyons,
par exemple, dans la Figure 3.3 que la fin du morceau analysé subit des variations de rythme
importantes et cela se remarque très clairement dans son spectrogramme.
F IGURE 3.3 – Onde sonore et spectrogramme d’un même extrait audio
La zone encadrée de rouge de la figure ci-dessus, possède un spectrogramme de couleur plus
foncée, plus intense. Dans cette zone se produit un changement de rythme musical important et la
fréquence devient brusquement élevée.
15En réalité, la notion de fréquence est directement liée à une autre notion que nous appelons
longueur d’onde. Cette dernière, correspond à la distance qui sépare deux pics ou deux creux suc-
cessifs de la courbe de l’onde sonore.
Ces deux notions sont inversement proportionnelles. Ainsi, plus la longueur d’onde est courte
plus la fréquence est élevée, et inversement. Une longueur d’onde courte signifie donc une vibra-
tion de l’air, dans lequel se propage le son, plus rapide et par conséquent un son plus aigu. Les
Figures 3.4 et 3.5 illustrent différents exemples de longueur d’onde.
F IGURE 3.4 – Différentes longueurs d’onde pour des sons graves ou aigus [26]
F IGURE 3.5 – Vibration des molécules d’air en fonction de l’onde sonore [22]
Nous pouvons conclure que la zone mise en évidence dans la Figure 3.3, correspond à un
extrait de la chanson où le son devient particulièrement aigu.
Afin de réaliser les illustrations 3.2 et 3.3, nous avons utilisé le logiciel Praat développé par
Paul Boersma et David Weenink [8]. Il s’agit d’un logiciel libre et gratuit qui permet d’analyser,
synthétiser et manipuler des données audio. Il offre en sortie des représentations graphiques de
haute qualité de ces sons.
163.3 Extraction d’empreinte
3.3.1 Introduction
Comme nous l’avons dit dans les sections précédentes, l’objectif principal des empreintes
audio est de permettre une extraction efficace des caractéristiques perceptives. Cette action doit
être facile et rapide à réaliser pour ne pas ajouter des contraintes supplémentaires à l’ensemble du
processus.
Si nous nous basons sur ce qui est écrit dans la littérature actuelle, nous pouvons de façon
générale séparer l’ensemble des caractéristiques perceptives suivant deux grandes catégories :
• Caractéristiques sémantiques : cela peut être le genre, le rythme ou encore l’ambiance.
Ces caractéristiques sont facilement identifiables par l’oreille humaine et servent à classi-
fier la musique.
• Caractéristiques non-sémantiques : elles ont une nature plus mathématique et il est dif-
ficile pour les humains d’arriver à les interpréter directement à partir de la musique.
Parmi ces deux catégories, uniquement la seconde nous intéresse. Nous nous basons donc
sur les caractéristiques perceptives non-sémantiques d’extraits audio pour effectuer notre travail.
Le choix d’utiliser cette deuxième catégorie a été motivé par les inconvénients que présentent les
caractéristiques sémantiques. A savoir :
1. Elles peuvent parfois être ambigües. Par exemple, le genre d’une chanson peut dépendre de
l’opinion de la personne qui l’écoute. Il peut aussi varier selon les époques.
2. Elles sont généralement plus compliquées à calculer que les non-sémantiques.
3. Elles ne sont pas universellement applicables. Si nous prenons par exemple une chanson de
musique classique, il n’est pas approprié de calculer le nombre de battements par minute.
3.3.2 Extraction d’empreintes
La majorité des algorithmes d’extraction d’empreintes suivent la même approche. Dans un
premier temps, le signal audio est divisé en plusieurs trames. Ensuite, une représentation spectrale
de ces dernières est calculée en appliquant une transformée de Fourier. L’étape suivante consiste
à créer un banc de filtre afin d’obtenir les sous-empreintes ou sub-fingerprints. La phase finale a
pour but d’obtenir l’empreinte binaire.
L’ensemble de ces étapes est détaillé dans la suite de cette sous-section. Pour ce faire, nous
nous basons sur l’article écrit pas Jaap Haitsma [21] car nous implémenterons la méthode qu’il
propose afin d’obtenir une empreinte binaire de nos extraits musicaux.
1. Framing
Le framing consiste à scinder chaque signal audio en blocs superposés de plus petite taille
que l’on appelle trames. Habituellement, nous utilisons un taux de recouvrement de 1/2 et des
trames d’une durée de 30ms. Le taux de recouvrement correspond à la superposition des différentes
trames. Lorsque la valeur vaut 1/2, cela signifie qu’arrivé à la moitié de la première trame, la
seconde débute. La Figure 3.6 illustre ce que nous venons de dire.
17F IGURE 3.6 – Représentation du phénomène de recouvrement avec un taux de 1/2
Haitsma propose quant à lui, d’utiliser un taux de recouvrement de 31/32 ce qui nous permet
d’obtenir une sous-empreinte toutes les 11.6ms comme représenté dans la Figure 3.7. En effet,
nous voyons que la durée totale des trames superposées est de 371ms. Nous obtenons :
371ms
≈ 11.6ms
32 trames
Nous avons donc 32 sous-empreintes toutes les 371ms et par conséquent 256 sous-empreintes
après 3 secondes (371ms ∗ 8 ≈ 3 secondes) ce qui est l’objectif recherché.
Un taux de recouvrement élevé garantit que même dans le pire des cas, c’est à dire des si-
gnaux fortement dégradés, les sous-empreintes du morceau à identifier restent similaires aux sous-
empreintes d’origine. Cela vient du fait qu’avec un tel taux de recouvrement, les sous-empreintes
successives ont de nombreuses similarités entre elles et qu’elles varient très peu au cours du temps.
F IGURE 3.7 – Superposition des trames
182. Transformation de Fourier
Tout d’abord, nous allons définir précisément en quoi consiste la transformée de Fourier
en 3.3.1. Nous expliquons par la suite pourquoi nous l’utilisons. Cette action sert à préparer la
phase 3 dans laquelle nous allons créer un banc de filtre.
Définition 3.3.1. La transformée de Fourier discrète (TFD) [44] est un outil mathématique de
traitement du signal numérique. Nous avons tendance à le confondre avec la transformée de Fou-
rier rapide (Fast Fourier Transform) définit en 3.3.2, qui n’est pourtant qu’un algorithme particu-
lier de calcul de la transformée de Fourier discrète. Sa définition mathématique pour un signal s
de N échantillons est la suivante :
N −1
n
X
S(k) = s(n) · e−2iπk N pour 06kPour les différentes valeurs de k, nous allons multiplier les valeurs du signal échantillonné
par celles illustrées dans la Figure 3.8. Plus la valeur de k augmente plus on accentue les hautes
fréquences (les périodes sont plus courtes).
F IGURE 3.8 – Partie réelle de l’exponentielle complexe suivant la valeur de k
Nous pouvons dire que la transformée de Fourier discrète peut-être vue comme une transfor-
mation linéaire appliquée au vecteur s(n) afin de retourner le vecteur S(k).
L’intérêt d’effectuer cette transformation est que les caractéristiques perceptives les plus im-
portantes pour l’extraction d’empreinte se trouvent au niveau de la fréquence. Dès lors, nous ap-
pliquons sur chaque trame produite à l’étape précédente une transformée de Fourier rapide, afin
d’obtenir une représentation spectrale du signal audio (c.f. Figure 3.2). La Figure 3.9 montre un
spectrogramme ou les points de forte densité sont en rouge. Ils représentent les points les plus
importants du spectrogramme.
F IGURE 3.9 – Spectrogramme montrant des points de forte densité [37]
20La Figure 3.10 schématise les deux premières étapes du processus. Nous y voyons les diffé-
rentes phases ainsi que les résultats obtenus à chaque niveau.
F IGURE 3.10 – Schéma des deux premières phases [29]
3. Division en bandes
Grâce aux transformées de Fourier effectuées à l’étape précédente, nous pouvons désormais
créer un banc de filtres. Le but est d’obtenir une représentation compacte d’une seule trame appe-
lée sous-empreinte ou sub-fingerprint. Le signal audio initial est décomposé en sous-signaux de
manière à ce que chaque bande ne comporte qu’une seule fréquence. Ce processus de décomposi-
tion porte le nom d’analyse.
Cependant, une seule de ces sous-empreintes ne suffit pas pour identifier un morceau audio
car elle ne contient pas assez de données. Si nous nous basons une nouvelle fois sur l’article de
Haitsma [21], nous allons travailler dans la suite de ce chapitre avec des blocs d’empreintes com-
posés, par exemple, de 256 sous-empreintes.
Il existe plusieurs échelles lors de la réalisation d’un banc de filtres. Nous pouvons principa-
lement citer l’échelle Bark ou encore l’échelle Mel. Nous allons expliquer en quoi elles consistent.
Echelle de Bark :
Le Bark [29] est une unité de psychoacoustique, et non physique, proposé par Eberhard Zwi-
cker en 1961. L’échelle de Bark consiste à diviser l’échelle des fréquences en 24 bandes dites
bandes critiques comprises entre 0 et 15500 Hz. Ce système permet de modéliser une meilleure
approximation de l’audition humaine. Les bandes de Bark sont utilisées pour calculer l’intensité,
la netteté ou la propagation du son. La Figure 3.11 montre la répartition des bandes de Bark de
manière graphique. Les valeurs précises correspondantes, peuvent être lues dans le Tableau 3.1.
La conversion d’une fréquence en Hertz vers des Bark se fait à l’aide de la formule suivante,
dans laquelle B exprime la fréquence en Bark et f en Hertz.
f f
B = 13 · arctan + 3.5 · arctan
1315.8 7518
21Vous pouvez aussi lire

















































