ETAT DE L'ART ET MISE EN PRATIQUE DE LA TECHNIQUE DES TESTS DE MUTATION - Vincent Passau
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
ETAT DE L’ART ET MISE EN
PRATIQUE DE LA TECHNIQUE DES
TESTS DE MUTATION
Mémoire présenté en vue de l’obtention du grade académique de
Master en Sciences Informatiques
Vincent PASSAU
Service de Génie Logiciel
Directeur de mémoire : Tom MENS
Année académique 2018-2019
ETAT DE L’ART ET MISE EN
PRATIQUE DE LA TECHNIQUE DES
TESTS DE MUTATION
Mémoire présenté en vue de l’obtention du grade académique de
Master en Sciences Informatiques
Vincent PASSAU
Service de Génie Logiciel
Directeur de mémoire : Tom MENS
Année académique 2018-2019
Remerciements
Je souhaite adresser en préambule mes remerciements aux personnes qui m’ont soutenu durant le
déroulement de ce Master et plus particulièrement pendant la rédaction de ce mémoire.
En premier lieu, je souhaite exprimer toute ma gratitude au directeur de ce mémoire, le professeur
Tom Mens, pour m’avoir offert son temps et m’avoir épaulé et conseillé au travers de ses nombreuses
relectures et remarques.
Ensuite, je remercie l’ensemble des professeurs pour m’avoir instruit en partageant leurs connais-
sances pendant toute la durée de mon cursus.
Je remercie mon grand-père, M. Bernard Passau, pour la précieuse aide qu’il m’a apportée en reli-
sant et commentant l’intégralité de ce mémoire à plusieurs reprises.
Je remercie chaleureusement ma chère compagne, Mlle Marie-Élise Larché, pour son soutien indé-
fectible au quotidien, ainsi que les encouragements permanents qu’elle m’a témoignés.
Enfin, j’adresse mes plus sincères remerciements à ma famille pour les nombreux encouragements
qu’ils m’ont prodigués.
Abstract
Mutation testing is a technique used to measure a test suite’s capacity to detect small faults in a
program. Faults are intentionally introduced into the source code of a program to create a series of
corrupted programs, called mutants, all of which contain a limited set of different changes.
The testing technique consists then to run the test suite on all the mutants to verify that it succeeds
to identify the introduced errors (it succeeds to detect a mutant if the test suite fails on it). If a mutant is
detected, it is considered as killed, otherwise it is considered as a survivor.
This approach makes it possible to compute the mutation score, which is an indicator of the test
suite quality. This score is the ratio of killed mutants over the total number of non-equivalent generated
mutants. The result should not take into account the mutants that are equivalent to the original program,
i.e., those that cannot be detected because they act in exactly the same way as the correct program.
Once we obtain the mutation score, any mutant that survived can be analyzed to find a way to kill
it, if it is effectively not equivalent to the original program. It can be done either by writing more tests,
or by modifying the source code or the existing test suite.
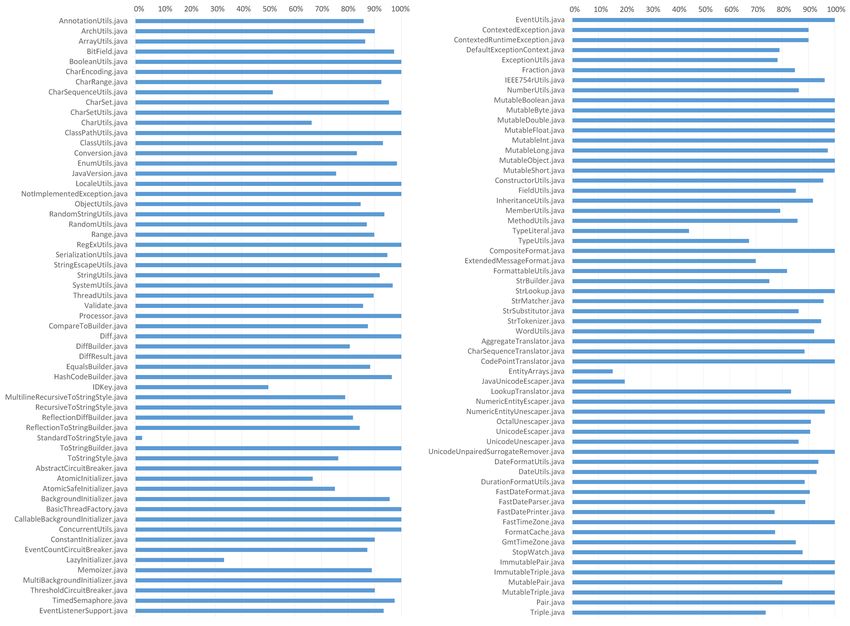
This master thesis studies more precisely what is the mutation analysis, how it works and when it
can be used. The state-of-the art section presents several recent studies about resolving the problems
faced when using the technique in the real world.
One of them is the compilation time because a build must be compiled for each mutant, before the
test suite can be run entirely. That’s why there is a lot of research to make the technique more viable.
To validate the practical use of mutation testing, we reviewed a panel of existing solutions to apply
mutation testing for programs written in Java, Python, C or C++. We tried two existing open source
solutions « PIT » and « Cosmic Ray », respectively on a Java project (Apache Commons Lang) and on
a Python project (Maya). We found that the mutation analysis is effectively time-consuming compared
to the simple unit tests, but some of the mutants allowed us to enrich the test suite.
We concluded that projects with tens of thousands of lines of code in Java or Python are able to
improve the quality of their test suites by using mutation testing tools.
Keywords—mutation testing, software testing, fault-based testing, test suite quality, mutation testing
tools review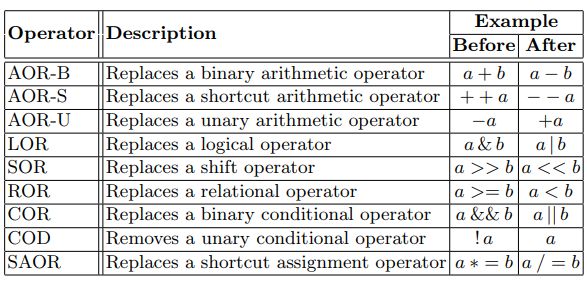
Table des matières
Table des figures 3
1 Introduction 5
2 Techniques de test 6
2.1 Tests unitaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Fonctionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2 Couverture des tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Tests d’intégration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Tests système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 État de l’art des tests de mutation 12
3.1 Introduction générale au fonctionnement et à la terminologie . . . . . . . . . . . . . . . . 12
3.1.1 Mutation forte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1.2 Score de mutation et mutants équivalents . . . . . . . . . . . . . . . . . . . . . . 14
3.1.3 Mutation faible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Opérateurs de mutation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.1 Contexte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.2 Langages de programmation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.3 Développement mobile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2.4 Deep learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Équivalence des mutants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3.1 Comparaison du code machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.2 Détection dynamique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 Pertinence du score de mutation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.5 Hypothèses de travail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.5.1 Hypothèse du programmeur compétent . . . . . . . . . . . . . . . . . . . . . . . 30
3.5.2 Hypothèse de l’effet de couplage . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.6 Accélération de l’exécution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.6.1 Parallélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.6.2 Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.6.3 Minimisation de la suite de tests . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.7 Réduction du nombre de mutants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.7.1 Supermutant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.7.2 Suppression des lignes arides et mutant unique par ligne modifiée . . . . . . . . . 37
3.7.3 Échantillonnage aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
1
4 Solutions existantes 40
4.1 Présentation des outils . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1.1 Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1.2 C/C++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.1.3 Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2 Comparatif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Sélection d’un outil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5 Mise en pratique des tests de mutation 51
5.1 Python, cas d’étude avec Cosmic Ray . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.1 Analyse de performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.2 Analyse du rapport de mutation . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.1.3 Analyse détaillée des mutants . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.2 Java, cas d’étude avec PIT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.2.1 Analyse de performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.2.2 Analyse du rapport de mutation . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.2.3 Analyse détaillée des mutants . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6 Conclusion générale 67
Bibliographie 69
Webographie 73
Annexes 76
A Script d’exécution de dix tests complets de Cosmic Ray 76
B Script Java pour exploiter les logs générés par Cosmic Ray 77
2
Table des figures
1 Procédure d’illustration de la couverture des tests . . . . . . . . . . . . . . . . . . . . . . 8
2 Suite de tests de la figure 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Exemple de machine à états finis et de son mutant . . . . . . . . . . . . . . . . . . . . . . 11
4 Procédure factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
5 Suite de tests incomplète de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6 Suite de tests améliorée de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
7 Mutant de la procédure factorial - opérateur de comparaison . . . . . . . . . . . . . . . . 13
8 Variante de la procédure factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
9 Mutant #1 de la variante de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
10 Mutant #2 de la variante de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
11 Mutant #3 de la variante de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
12 Mutant #4 de la variante de factorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
13 Suite de tests adéquate de la variante de factorial . . . . . . . . . . . . . . . . . . . . . . 17
14 Opérateurs de mutation de Mothra pour le langage Fortran . . . . . . . . . . . . . . . . . 20
15 Algorithme triangle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
16 Exemple de mutation de type ABS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
17 Exemple de mutation de type AOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
18 Exemple de mutation de type LCR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
19 Exemple de mutation de type ROR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
20 Exemple de mutation de type UOI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
21 Opérateurs de mutation du langage C++ . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
22 Comparaison entre développement classique et orienté deep learning . . . . . . . . . . . . 26
23 Mutation dans un système de deep learning . . . . . . . . . . . . . . . . . . . . . . . . . 27
24 Opérateurs de mutation orientés deep learning . . . . . . . . . . . . . . . . . . . . . . . . 27
25 Matrice des tests exécutés sur des mutants redondants . . . . . . . . . . . . . . . . . . . . 29
26 Ensemble de mutants minimums . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
27 Procédure et test d’illustration de la parallélisation . . . . . . . . . . . . . . . . . . . . . . 32
28 Vue de l’exécution traditionnelle de la procédure . . . . . . . . . . . . . . . . . . . . . . 33
29 Exécution parallèle avec l’approche Split-Stream . . . . . . . . . . . . . . . . . . . . . . 34
30 DiMuTesTas : vue architecturale du traitement . . . . . . . . . . . . . . . . . . . . . . . . 35
31 Tableau comparatif des ensembles de tests minimums . . . . . . . . . . . . . . . . . . . . 36
32 Fonctionnement d’un supermutant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
33 Opérateurs de mutation de µJava . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
34 Opérateurs de mutation par défaut de PIT . . . . . . . . . . . . . . . . . . . . . . . . . . 42
35 Opérateurs de mutation activables de PIT . . . . . . . . . . . . . . . . . . . . . . . . . . 42
36 Opérateurs de mutation généraux de LittleDarwin . . . . . . . . . . . . . . . . . . . . . . 43
37 Opérateurs de mutation de LittleDarwin spécifiques à la gestion des NULL . . . . . . . . 43
38 Opérateurs de mutation de MAJOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
39 Opérateurs de mutation de AccMut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
40 Fichier de configuration de Cosmic Ray . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
41 Commandes de lancement d’une analyse avec Cosmic Ray . . . . . . . . . . . . . . . . . 52
3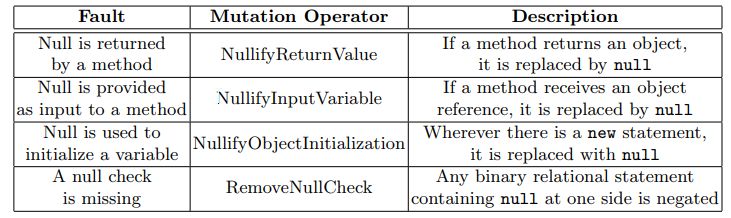
42 Rapport HTML partiel de l’analyse Cosmic Ray . . . . . . . . . . . . . . . . . . . . . . . 54
43 Mutant survivant exposé dans l’analyse Cosmic Ray . . . . . . . . . . . . . . . . . . . . . 55
44 Nombre de mutants par opérateur de Maya . . . . . . . . . . . . . . . . . . . . . . . . . . 56
45 Mutant de Maya . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
46 Nouveau test unitaire pour l’intersection de deux intervalles . . . . . . . . . . . . . . . . . 57
47 Rapport de mutation de Maya avec le test de la figure 46 . . . . . . . . . . . . . . . . . . 58
48 Ajout du plugin de PIT dans le fichier pom.xml du projet . . . . . . . . . . . . . . . . . . 59
49 Ouverture du rapport pour la classe WordUtils . . . . . . . . . . . . . . . . . . . . . . . . 60
50 Rapport partiel de la classe WordUtils . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
51 Scores de mutation par package de Commons Lang . . . . . . . . . . . . . . . . . . . . . 61
52 Scores de mutation par classe de Commons Lang . . . . . . . . . . . . . . . . . . . . . . 62
53 Mutations sur une ligne de la procédure initials . . . . . . . . . . . . . . . . . . . . . . . 63
54 Rapport de mutation de la procédure invert . . . . . . . . . . . . . . . . . . . . . . . . . . 64
55 Nouvelle procédure de test de invert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
56 Rapport de mutation incluant le nouveau test de invert . . . . . . . . . . . . . . . . . . . . 65
41 Introduction
La réalisation de ce mémoire a pour cadre l’obtention d’un Master en Sciences Informatiques à l’Uni-
versité de Mons.
L’objectif est d’expliciter la technique des tests de mutation et de définir pourquoi celle-ci s’inscrit
dans une optique d’amélioration générale de la qualité des programmes. Nous allons également mettre en
évidence les difficultés d’implémentation et les pistes explorées par les chercheurs pour y remédier.
Pour ce faire, l’état de l’art va être dressé dans le but d’exposer les progrès effectués ces dernières
années et de comprendre les avantages, les inconvénients et les enjeux des futures recherches. Enfin, la
technique va être appliquée à un cas d’étude concret après avoir comparé les outils existants pour détermi-
ner si, et sous quelles conditions, elle est utilisable sur de vrais projets.
Les tests de mutations ont été imaginés en 1971 par Richard J. Lipton [1] et poussés plus avant en
1978 par DeMillo, Lipton et Sayward [2]. Finalement, ils ont été implémentés par la suite pour les langages
Cobol et Fortran par Acree et al.[3].
La technique des tests de mutation a pour but de mettre à l’épreuve la validité de la suite de tests
d’un programme en soumettant à cette suite des versions corrompues du programme, des mutants. Ceux-
ci possèdent des profils variés, ils sont formés en appliquant un ou plusieurs opérateurs de mutation au
programme. Deux exemples d’opérateur sont la suppression d’une déclaration et le remplacement d’un
opérateur arithmétique.
Basiquement, soit les tests parviennent à discriminer un mutant et il est tué, soit le mutant survit. Cela
peut se passer si les tests sont incomplets ou si le mutant ne peut pas être détecté (e.g., s’il équivaut au
programme, si la mutation a lieu dans du code mort...).
Tout l’intérêt de la manipulation est donc de se baser sur les mutants survivants pour améliorer la suite
de tests. Soit en y ajoutant de nouveaux tests afin de couvrir des parties de code qui ne l’étaient pas, soit en
mettant à jour une partie de ceux qui ont été mis à l’épreuve si ceux-ci ne sont pas assez efficaces (e.g., en
y ajoutant des assertions).
De nos jours, des solutions ont été développées pour faire des tests de mutation avec des langages mo-
dernes tels que Java [4, 5, 6], Python [7, 8, 9] et C/C++ [10, 11, 12]. Des outils qui prennent en compte des
opérateurs de mutation sur les spécificités des technologies récentes, comme celles liées à l’utilisation d’un
téléphone Android [13, 14], existent aussi (permissions d’une application sur un téléphone, localisation
GPS...).
52 Techniques de test
Les tests de mutation s’inscrivent dans l’ensemble des pratiques qui visent à s’assurer de la fiabilité du
code produit par les concepteurs de logiciels au moyen de techniques de test. Les standards internationaux
qui définissent ces pratiques sont décomposés en cinq normes [15] :
— ISO/IEC 29119-1 - concepts et définitions : ce standard contient le vocabulaire utilisé dans les
différentes normes et des exemples de mise en pratique.
— ISO/IEC 29119-2 - processus de test : elle décrit les couches des processus de test au niveau orga-
nisationnel, de la gestion et de la dynamique.
— ISO/IEC 29119-3 - documentation des tests : elle fournit des modèles de documentation qui couvrent
l’entièreté du cycle de test.
— ISO/IEC 29119-4 - techniques de test : c’est dans cette norme que les standards pour la conception
des tests sont décrits.
— ISO/IEC 29119-5 - tests pilotés par mot-clé : la norme qui contient les standards pour le support
des tests dirigés par mot-clé 1 .
Les différentes techniques de test peuvent être implémentées avec une approche ouverte (boîte blanche,
white box testing) ou fermée (boîte noire, black box testing) :
White box testing
Cette approche consiste à créer les tests d’un logiciel en se basant sur son code source. Plus spécifique-
ment, les branches, les conditions et les déclarations sont ciblées par le développeur au moment où il
écrit son test [16].
Black box testing
Avec cette approche, les tests sont écrits sur base des descriptions du programme telles que les spécifi-
cations techniques et fonctionnelles [16].
Nous allons détailler dans les prochaines sous-sections certaines pratiques auxquelles les tests de mu-
tation sont liés. Ils peuvent être mis en place à plusieurs niveaux.
Par exemple, au moment du développement pour vérifier le fonctionnement de procédures (e.g., avec les
tests unitaires) ou les interactions entre plusieurs procédures ou ressources (e.g., avec les tests d’intégration),
ou bien dans la phase de test qui succède à la conception du logiciel (e.g., avec les tests système).
1. Ce type de test consiste à décrire son cas de test avec des mots-clés, ensuite le programmeur définit les actions que ce
mot-clé provoque ainsi que les données éventuelles que le test doit recevoir.
62.1 Tests unitaires
2.1.1 Fonctionnement
Pour introduire la notion, commençons par une définition. Whittaker [17] la décrit de la façon suivante :
Les tests unitaires testent des composants individuels d’un logiciel ou une collection de composants.
Les testeurs définissent le domaine des paramètres entrants pour ce ou ces composants et ils ignorent le
reste du système.
Écrire des tests unitaires consiste donc à tester un à un de petits modules d’un logiciel, c’est le dé-
veloppeur qui produira ces tests. Ils sont indépendants les uns des autres, c’est pourquoi l’ordre de leurs
exécutions n’a pas d’importance.
Ils peuvent être lancés automatiquement, par exemple, les outils JUnit [18] (Java) et TestNG [19] (Java)
offrent cette fonctionnalité. Cette automatisation peut être exploitée entre autres pour les déclencher après
chacun des commits 2 du code d’un programme afin de s’assurer que les changements n’ont pas cassé du
code existant.
Plusieurs possibilités existent quant au moment adéquat pour définir les tests. Par exemple, une ap-
proche consiste à les écrire avant le code en adoptant l’approche du développement piloté par les tests [20].
Dans ce cas, le développeur commence par produire un test qui éprouve la fonctionnalité de base qui est
attendue d’un morceau de code. Ensuite, il écrit le code et vérifie que le test réussit. Tant que le code n’est
pas terminé, soit le développeur remanie le test pour contrôler ce qu’il reste à programmer, soit il remanie
le code pour qu’il corresponde mieux aux besoins qui sont testés. Dans le second cas, le test doit toujours
réussir sans qu’il soit nécessaire de le corriger.
Le code peut aussi être écrit d’abord et, dans un second temps, les tests sont alors définis en se basant
sur la structure du programme. Cela permet notamment de tester spécifiquement certains points critiques
d’un programme (e.g., les cas limites d’une condition technique qui n’a pas forcément de liens évidents
avec l’objectif final du programme).
Les tests de mutation sont liés aux tests unitaires car ce sont typiquement ces derniers qui sont lancés
sur les mutants du programme afin de calculer la proportion d’entre eux qui sont tués.
2.1.2 Couverture des tests
Une fois les tests écrits, la couverture de ceux-ci peut être déterminée lorsqu’ils sont lancés. C’est une
mesure qui définit le pourcentage du code qui est couvert par au moins un test dont les assertions n’ont pas
échoué.
Des outils permettent de la calculer directement selon les métriques choisies (expliquées ci-dessous).
Celles-ci définissent les conditions qui font qu’une ligne est couverte ou pas. Par exemple, ECLEmma [21]
(Java) et FrogLogic Coco [22] (C, C++, C#) sont des outils qui calculent automatiquement la couverture
2. Envoi du code modifié localement à un logiciel de gestion de versions du code source.
7des tests.
Il est généralement admis que si une partie de code est couverte, alors elle est supposée correcte, bien
que cela ne soit pas toujours le cas. Le taux de couverture permet donc d’avoir un indicateur sur la fiabilité
du programme.
Il existe de nombreux types de couverture des tests, les principaux sont les suivants [23] :
— La couverture de déclarations : c’est la proportion des déclarations exécutées au moins une fois
par la suite de tests pour le programme considéré.
— La couverture de branches ou couverture de décision : indique le rapport du nombre de branches
qui ont été exécutées par la suite de tests sur le nombre total de branches. N branches sont créées
lorsqu’une expression donne lieu à l’exécution de N parties de code différentes. Par exemple, une
déclaration switch peut posséder un certain nombre de cases ainsi qu’un cas par défaut, la couverture
de branche de cette déclaration sera de 100% si tous les cas et celui par défaut sont testés.
— La couverture de conditions : ce type requiert que tous les résultats possibles de chaque condition
de chaque branche soient testés au moins une fois afin d’atteindre les 100% de couverture. Il n’est
donc pas requis que chaque combinaison possible soit testée, mais bien que chaque résultat possible
soit essayé une fois au moins par condition. Cela signifie également qu’une couverture de conditions
de 100% ne garantit pas une couverture de branches complète.
— La couverture de décisions et conditions : c’est la fusion des deux types précédents, toutes les
conditions doivent être testées avec tous les résultats possibles au moins une fois et toutes les
branches doivent être testées une fois ou plus. Cette approche pose un problème semblable à la
précédente parce que toutes les conditions seront testées, mais pas toutes les combinaisons.
— La couverture des conditions multiples : suffisamment de tests doivent être créés pour que chaque
combinaison de conditions soit testée. Si ce type de couverture est de 100%, alors tous les autres le
sont également.
Pour illustrer les différentes couvertures, prenons la procédure de la figure 1 et la suite de tests de la
figure 2.
F IGURE 1 Procédure d’illustration de la couverture des tests [23]
1: procedure FOO (a, b, x)
2: if a > 1 && b = 0 then
3: x ← x/a
4: if a = 2 || x > 1 then
5: x ← x+1
6: return x
Exécutons la suite de tests et chiffrons les différentes couvertures. La couverture de déclarations est de
100% ( 55 déclarations visitées), car les décisions des deux if sont vraies pour le premier test et fausses pour
le deuxième, la couverture de branches est de la même valeur pour la même raison ( 44 branches exécutées).
Calculons maintenant la couverture de conditions, nous pouvons voir qu’il y en a quatre (a>1, b=0,
8F IGURE 2 Suite de tests de la figure 1 [23]
1: procedure FOOT EST 1
2: result ← foo(2,0,4)
3: assert (result = 3)
4: procedure FOOT EST 2
5: result ← foo(1,1,1)
6: assert (result = 1)
a=2 et x>1) qui peuvent chacune être vraie ou fausse. Le premier test en couvre quatre (vrai, vrai, vrai, vrai)
et le deuxième couvre les autres (faux, faux, faux, faux). La couverture de conditions est donc de 88 = 100%.
Dans notre exemple, la couverture de décisions et conditions est de la même valeur ( 88 conditions+4 de´cisions
conditions+4 de´cisions ),
mais cela n’est pas lié au fait que la couverture de conditions soit de 100%. En effet, si nos tests avaient
utilisé les paramètres A=1, B=0, X=3 et A=2, B=1, X=1 les huit conditions auraient été testées pour seulement
trois branches.
Enfin, la couverture des conditions multiples porte sur les huit combinaisons possibles, nos tests en
exécutent quatre (pour les deux conditions vrai-vrai et faux-faux) et elle s’élève donc à 50%.
Les différentes techniques de couverture de tests permettent donc de visualiser la proportion du code
d’un programme sur laquelle les tests passent. En supposant que les tests soient pertinents, nous pouvons
donc avoir une certaine idée de la qualité du code en fonction de la couverture. Or, dans la réalité, les tests
ne sont pas toujours bien écrits.
La technique des tests de mutation offre une solution à ce manque de fiabilité possible des tests. En
effet, elle permet de quantifier l’efficacité de la suite de tests pour savoir à quel point le développeur peut
s’y fier. Cela sera détaillé dans la section 3.
2.2 Tests d’intégration
Supposons que les tests unitaires s’avèrent fiables et qu’ils offrent une couverture de test satisfaisante.
Celle-ci donne une idée de la qualité du code du point de vue d’une classe ou d’un module pris séparément,
mais pas forcément de celle du programme dans une vue un peu plus globale, comme lorsque ces modules
communiquent entre eux.
Les tests d’intégration ont pour objectif de pallier ce problème. Au lieu de tester des parties isolées du
programme, c’est l’interaction entre plusieurs composants qui est vérifiée.
Si des ressources externes sont utilisées par le programme (par exemple, des interactions avec une base
de données, une imprimante, un serveur mail...), ce type de test visera à s’assurer du déroulement correct
des échanges.
Plus généralement, la bonne marche des appels réciproques entre plusieurs modules de l’application est
testée, là où les tests unitaires font plutôt intervenir des mocks qui simulent le comportement attendu des
9ressources ou des procédures externes au code testé 3 .
Ces deux types de tests diffèrent donc puisqu’un test d’intégration peut rater en raison d’une panne
externe, alors qu’un test unitaire qui échoue induit que c’est forcément le code source qui pose problème
(toujours en supposant que les tests sont fiables). De plus, les tests unitaires sont exécutés relativement
rapidement contrairement aux tests d’intégration pour lesquels l’exécution peut durer plus longtemps en
raison des temps d’accès aux ressources externes.
Encore une fois, ce type de test donne une indication sur la qualité du code source pour autant que ceux
qui sont réalisés soient fiables. Les tests de mutation peuvent être utilisés pour fabriquer des mutants qui
jouent sur les interactions entre modules/ressources externes (modification des paramètres des méthodes
appelées [16], modification de requête SQL [26]...) et pour vérifier que les tests d’intégration parviennent à
les tuer.
2.3 Tests système
Le but des tests système est de vérifier la conformité du programme sur divers aspects par rapport
aux besoins. Ils sont basés sur des cas de test fonctionnels de bout en bout, c’est-à-dire à partir de la pre-
mière jusqu’à la dernière interaction avec l’application. D’autres acteurs que le concepteur de logiciel (e.g.,
l’équipe de test, l’analyste...) peuvent prendre part aux tests système au moyen de nombreuses approches
différentes [23].
Voici quelques exemples :
— Tests d’installation : pour un logiciel à installer, vérification de la vitesse, de la rapidité, de la
simplicité... pour exécuter l’installation.
— Tests de fiabilité : surveillance de la disponibilité de l’application sur une longue période.
— Tests de stockage : vérification de la quantité de données gardées en mémoire.
— Tests de performance : vérification du temps de réponse selon différentes configurations.
— Tests de stress : soumission d’un pic de requêtes afin d’analyser le comportement du programme.
— Tests de charge : envoi continu de requêtes sur une longue durée.
— Tests d’ergonomie : est-ce que l’interface est adaptée à un utilisateur moyen ? Les messages d’erreur
sont-ils clairs ? N’y a-t-il pas trop d’options ou de menus présentés par défaut à l’usager ? ...
Une approche des tests système qui convient particulièrement bien aux tests de mutation est la modé-
lisation du fonctionnement d’un programme sous la forme d’une machine à états finis. C’est-à-dire sous
la forme d’un graphe G composé d’un ensemble de nœuds N, les états, dont un sous-ensemble N0 ⊆ N
contient les nœuds initiaux et un autre, N f ⊆ N, les nœuds finaux. L’ensemble des arêtes E ⊆ N × N indique
les transitions entre les nœuds [16].
Cette façon de modéliser permet de montrer le comportement du système dans son entièreté, ce qui est
exploité dans le but de vérifier la validité d’un cas de test de bout en bout comme expliqué au début de cette
3. Par exemple, les outils Mockito [24] (Java) et NSubstitute [25] (.NET) permettent de configurer des mocks dans les tests
d’un programme.
10sous-section.
Ce type de test de haut niveau aide à trouver des fautes difficilement détectables avec des tests unitaires
ou d’intégration. Par exemple, l’explosion de la fusée Ariane 5, le 4 juin 1996, était due à une erreur de
conversion en point flottant du système de guidage. Celui-ci a été récupéré d’Ariane 4, pour laquelle la
faute ne pouvait pas se produire en raison de sa trajectoire. Or les tests système qui auraient pu détecter le
problème pour la trajectoire d’Ariane 5 n’ont pas été exécutés à cause du coût de ceux-ci [16].
Les tests de mutation peuvent être utilisés pour créer des versions modifiées du diagramme de la
machine à états afin de s’assurer que les tests système qui sont prévus parviennent effectivement à tuer des
transitions non désirées [27].
Par exemple, prenons la machine à états et son mutant qui sont exposés dans la figure 3. Un cas de test
qui tue le mutant peut être constitué d’une séquence d’états qui sont autorisés par le diagramme correct,
mais pas par le mutant. En l’occurrence, il suffit d’un test qui passe par l’état display. Ce test devrait donc
faire partie de la suite de tests système afin de ne pas laisser le mutant survivre.
F IGURE 3 – Exemple de machine à états finis et de son mutant
2.4 Conclusion
Dans cette section, nous avons montré que des tests de mutation peuvent être utilisés pour tester le bon
fonctionnement de plusieurs procédés différents allant d’un niveau assez bas (test unitaire, requête SQL...)
jusqu’à modifier le flux du programme qui est vérifié par des tests système.
Nous allons maintenant expliquer plus précisément dans l’introduction de l’état de l’art le fonctionne-
ment détaillé de la technique.
113 État de l’art des tests de mutation
3.1 Introduction générale au fonctionnement et à la terminologie
3.1.1 Mutation forte
Tout d’abord, essayons de comprendre l’intuition derrière les tests de mutation, pourquoi sont-ils utiles
si des tests sont déjà présents pour un programme ? Comme nous l’avons vu dans la section 2, il est difficile
d’évaluer la qualité des tests eux-mêmes. Celle-ci est souvent réduite à une métrique, comme la couverture
des tests sur le code que cette suite produit lorsqu’elle est lancée sur le programme. Or cette approche pose
plusieurs problèmes.
Premièrement, une ligne peut être couverte par un test qui n’est pas pertinent, par exemple si ses asser-
tions sont des tautologies. Prenons le cas le plus simple, soit une procédure factorial (cf. figure 4) à tester
pour laquelle nous créons une suite de tests. Elle ne contient qu’un test dont l’assertion est toujours vraie
(cf. figure 5).
De nombreuses lignes seront couvertes, mais cela n’a que peu d’intérêt ; éventuellement, une procédure
présentant par exemple une boucle infinie pourrait être détectée parce que le test ne finirait pas. Ce genre
de test est doublement dangereux puisque cela produit une fausse impression de qualité.
F IGURE 4 Procédure factorial
1: procedure FACTORIAL (n)
2: if n < 0 then
3: return −1
4: res ← 1
5: for i ← 2, n do
6: res ← res ∗ i
7: return res
F IGURE 5 Suite de tests incomplète de factorial
1: procedure MY U NIT T EST
2: n←1
3: res ← factorial(n)
4: assert (n = 1)
Deuxièmement, une ligne peut être couverte partiellement. C’est-à-dire que si cette ligne contient une
expression qui peut être résolue de plusieurs façons (typiquement, une expression composée d’opérateurs
logiques donnant un résultat booléen) et que le test ne couvre qu’un cas, alors la ligne n’est pas mise à
l’épreuve pour toutes les combinaisons logiques possibles. Or, selon le type de couverture utilisée, comme
la couverture de déclarations (cf. section 2.1.2), cela n’est pas forcément visible.
Par exemple, la ligne 5 de la figure 4 peut avoir deux comportements : rentrer dans la boucle for, ou
pas. Notre test de la figure 5 n’en couvrirait qu’un, même s’il était pertinent. Notre suite de tests est donc
12incomplète, elle devrait tester à la fois la première valeur valide de la borne et la valeur invalide la plus
proche. La figure 6 montre la suite de tests corrigée pour la boucle for.
Enfin, même quand une suite de tests bénéficie d’une couverture de conditions multiples de 100%,
comme définie à la section 2.1.2, cela n’est pas pour autant une garantie que le programme ne présente pas
de bogues.
F IGURE 6 Suite de tests améliorée de factorial
1: procedure INF B ORNE F OR
2: n←1
3: res ← factorial(n)
4: assert (res = 1)
5: procedure SUP B ORNE F OR
6: n←2
7: res ← factorial(n)
8: assert (res = 2)
Ces problèmes amènent à penser qu’il faudrait pouvoir vérifier la fiabilité de la suite de tests elle-même.
C’est précisément pour atteindre cet objectif que les tests de mutation rentrent en jeu.
Le but de cette technique est de valider l’efficacité des tests en les exécutant sur des mutants du pro-
gramme afin de vérifier qu’ils parviennent à les tuer.
Concrètement, une fois le programme P et sa suite de tests T écrits, une série de mutants P1 , P2 , ..., Pn va
être créée. Chacun de ces mutants sera une copie de P avec une ou plusieurs modification(s) à base d’opé-
rateur(s) de mutation. Ceux-ci peuvent être de comparaison (e.g., remplacement de >= par ==), logique
(e.g., remplacement de && par ||), de changement de constante (e.g., remplacement d’une initialisation de
variable à true par f alse), etc.
Un exemple de mutant construit avec un opérateur de comparaison est montré dans la figure 7. Il serait
facilement tué par notre suite de tests parce qu’un paramètre d’entrée supérieur à 0 est testé dedans.
F IGURE 7 Mutant de la procédure factorial - opérateur de comparaison (ligne 2)
1: procedure FACTORIAL (n)
2: if n > 0 then
3: return −1
4: res ← 1
5: for i ← 2, n do
6: res ← res ∗ i
7: return res
13Un mutant Px composé d’une seule modification (cf. figure 7) par rapport à P est appelé un mutant de
premier ordre. C’est la forme la plus courante car l’implémentation traditionnelle de la technique repose
sur les deux hypothèses suivantes :
Hypothèse du programmeur compétent
Un programmeur compétent, après qu’il ait terminé de concevoir, de développer et de tester, écrit un
programme qui est soit correct soit qui l’est presque, car il diffère du programme correct uniquement
par des erreurs triviales [3].
Hypothèse de l’effet de couplage
Les tests qui distinguent tous les mutants P1 , P2 , ..., Pn qui diffèrent d’un programme P correct par de
simples erreurs sont si sensibles qu’ils distinguent aussi implicitement les erreurs plus complexes [2].
De la première, nous pouvons considérer qu’un programmeur n’écrit pas du code aléatoirement et donc
qu’un mutant qui altérerait tellement le programme qu’il n’y aurait plus de ressemblance serait détecté par
d’autres moyens. C’est la raison pour laquelle il est uniquement nécessaire de tester des mutants « simples »,
c’est-à-dire qui n’ont que quelques modifications par rapport au programme correct.
De la deuxième hypothèse 4 , nous supposons que les erreurs « complexes » sont couplées aux erreurs
simples. Par extension, nous supposons que si nous parvenons à discriminer tous les mutants de premier
ordre, alors les mutants d’ordre supérieur (dits aussi mutants de haut ordre, c’est-à-dire ceux qui sont
composés de plus qu’une modification) sont automatiquement détectés également.
En nous cantonnant à cela, nous pouvons construire et tester tous les mutants de premier ordre pour
valider notre suite de tests, c’est la mutation forte.
3.1.2 Score de mutation et mutants équivalents
Une fois les tests de mutation effectués, la qualité de la suite de tests peut être représentée par son
score de mutation décrit par Richard DeMillo [31]. Plus ce score tend vers 100%, plus la suite de tests est
efficace.
DM(P, T )
ms(P, T ) = (1)
M(P) − EM(P)
Où ms(P, T ) représente le score de mutation des mutants du programme P exécutés par la suite de tests
T , DM(P, T ) le nombre de mutants de P tués par T , M(P) le nombre de mutants de P créés et EM(P) le
nombre de mutants équivalents à P.
Un mutant Px équivaut à P si l’erreur introduite dans P n’en était pas une et ne change donc pas son
comportement.
4. Cette hypothèse a été étudiée à de multiples reprises notamment en avril 2010 par Papadakis et Nicos [28] et en décembre
2010 par Langdon, Harman et Jia [29]. Les auteurs ont conclu empiriquement que les mutants de premier ordre sont plus difficiles
à tuer que ceux de haut ordre, et qu’une suite de tests adéquate pour les mutants de premier ordre a donc effectivement de grandes
chances de tuer la plupart des mutants de haut ordre.
Une recherche plus récente menée par Gopinath, Jensen et Groce [30] en 2017 a apporté des améliorations à cette hypothèse
et cela est détaillé dans la section 3.5.2.
14Par exemple, construisons un mutant pour la procédure de la figure 8 dans lequel il y a un remplacement de la constante 1 par 0 à la ligne 5. Ce mutant (cf. figure 9) est rigoureusement équivalent au programme correct et ne devrait pas être tué par la suite de tests parce que son seul effet est d’ajouter une opération neutre au calcul (l’opération res * 1). F IGURE 8 Variante de la procédure factorial 1: procedure FACTORIAL (n) 2: if n < 0 then 3: return −1 4: res ← 1 5: i←1 6: while + + i
F IGURE 11 Mutant #3 de la variante de factorial 1: procedure FACTORIAL (n) 2: if n < 0 then 3: return −1 4: res ← 1 5: i←1 6: while + + i
F IGURE 13 Suite de tests adéquate de la variante de factorial
1: procedure INF B ORNE I F
2: n ← −1
3: res ← factorial(n)
4: assert (res = −1)
5: procedure SUP B ORNE I F
6: n←0
7: res ← factorial(n)
8: assert (res = 1)
9: procedure INF B ORNE F OR
10: n←1
11: res ← factorial(n)
12: assert (res = 1)
13: procedure SUP B ORNE F OR
14: n←2
15: res ← factorial(n)
16: assert (res = 2)
3.1.3 Mutation faible
La mutation forte induit beaucoup de mutants à tester au vu du nombre de points de mutation exploi-
tables (points d’action d’au moins un opérateur de mutation). Avec des programmes composés d’une grande
quantité de lignes de code, des problèmes de performance risquent d’apparaître.
Pour pallier ce problème, de multiples recherches ont été menées et seront exposées dans les autres
sections de l’état de l’art. Il existe notamment une variante de la mutation forte appelée mutation faible
qui a été proposée d’abord par Howden [33] et ensuite évaluée empiriquement par Offutt et Lee [34].
Elle consiste à gagner du temps d’exécution en ne testant pas la valeur de retour d’une procédure. À
la place, il y a une vérification qu’au moins un test atteint le point de mutation et que celui-ci change
localement le comportement normal.
C’est-à-dire que lors de l’exécution des tests, si la mutation est rencontrée et qu’elle donne un résultat
local différent du programme correct, alors le test est supposé apte à discriminer le mutant. Dans ce cas,
ce dernier est dit « faiblement tué ». Par exemple, dans la figure 9, la mutation de la ligne 5 produira une
valeur différente pour i que la procédure normale, il sera donc tué faiblement.
Plus formellement, voici la définition que Howden proposa [33] :
Supposons que P est un programme, que C est un composant simple 5 de P et qu’une mutation est
appliquée à C pour produire C0 . Soit P0 la version mutée de P qui contient C0 .
Un test de mutation faible vérifiera que pour le lancement d’une suite de tests T sur C0 pendant l’exé-
cution de P0 , la valeur de C0 est différente au moins une fois pour au moins un test de la valeur obtenue
5. Howden définit un composant simple comme « correspondant normalement aux structures de calcul élémentaires d’un
programme ». Il donne une liste non exhaustive d’exemples : les variables, les expressions arithmétiques et relationnelles et les
expressions booléennes. En pratique, il n’y a donc pas de définition arrêtée de ce terme, car tout dépend des opérateurs de mutation,
et du langage cible.
17quand T est lancé sur C du programme P.
La mutation faible coûte moins cher sur le plan du temps de traitement que la forte, parce que les
mutants ne sont pas exécutés entièrement. En revanche, elle est aussi moins fiable puisqu’en pratique il est
possible qu’un état interne change, mais que le résultat final du programme soit le bon.
C’est le cas si nous reprenons l’exemple de la figure 9, nous avons vu que le mutant est tué faiblement
alors qu’il équivaut en fait au programme correct. Le score de mutation faible sera donc moins précis.
Ce manque de vérification forte la fait se rapprocher plus d’une métrique de couverture de code que la
mutation traditionnelle. Effectivement, comme il suffit de produire un test qui atteint les différents points de
mutation, des tests avec des assertions toujours vraies comme celui de la figure 5 peuvent tuer faiblement
des mutants. Cependant, ils seraient incapables de les tuer fortement.
L’endroit exact dans le programme où la comparaison entre le composant du programme correct et celui
du mutant doit être effectuée peut varier, en effet, cela dépend de l’implémentation de la mutation faible.
Offutt et Lee ont analysé en 1996 différentes possibilités et ils ont mis en place celles-ci dans un sys-
tème de mutation faible appelé « Leonardo » [34] :
— EX-WEAK : la valeur du composant interne et celle du mutant sont comparées au niveau de l’ex-
pression.
Par exemple, pour le mutant de la figure 10, les expressions ++i et i++ donnent toutes les deux le
même résultat et le mutant est donc marqué comme survivant (bien que nous ayons vu précédem-
ment qu’il n’est pas équivalent).
— ST-WEAK : la valeur du composant interne et celle du mutant sont comparées au niveau de la
déclaration.
Par exemple, pour le mutant de la figure 10, la comparaison au niveau de la déclaration est différente.
La raison est que le mutant incrémente la variable i après la comparaison, ce qui donne un résultat
différent à celle-ci pour au moins un test (quand n=1). Il est donc faiblement tué.
— BB-WEAK/1 : la valeur du composant interne et celle du mutant sont comparées à la fin du premier
bloc dans laquelle la mutation a lieu.
Par exemple, toujours pour le mutant de la figure 10, les valeurs des variables i et res sont compa-
rées avec celles de la version originale après la fin de la première itération de la boucle. Pour autant
que n soit supérieur à 1, i et res auront la même valeur après le premier bloc et le mutant survit.
Avec notre suite de tests, res a une valeur différente quand n=1 et le mutant est tué faiblement.
— BB-WEAK/N : c’est le cas général de BB-WEAK/1, le N peut varier et l’état des composants
internes est comparé à la fin de la boucle après chacune des N premières itérations, si cela est
possible.
Reprenons une dernière fois comme exemple le mutant de la figure 10. Si N est suffisamment grand
pour couvrir la dernière exécution du bloc (i.e., N ≥ n où n est la borne de la boucle for), alors le
mutant sera faiblement tué. En effet, res sera différent dans le mutant compte tenu de l’exécution
supplémentaire de la boucle. Celle-ci a lieu en raison de l’incrémentation de i après la résolution
de la condition d’arrêt.
18Les auteurs ont conclu empiriquement à l’aide de Leonardo que le point de comparaison ST-WEAK est
celui qui donne des résultats les plus proches de ceux de la mutation forte. D’après eux, il serait également
intéressant de combiner mutation faible et forte pour pallier les manques de la mutation faible seule.
En résumé, la technique des tests de mutation permet d’améliorer la qualité des tests d’un programme,
mais son coût est élevé et c’est donc sur ce point que la recherche se concentre principalement.
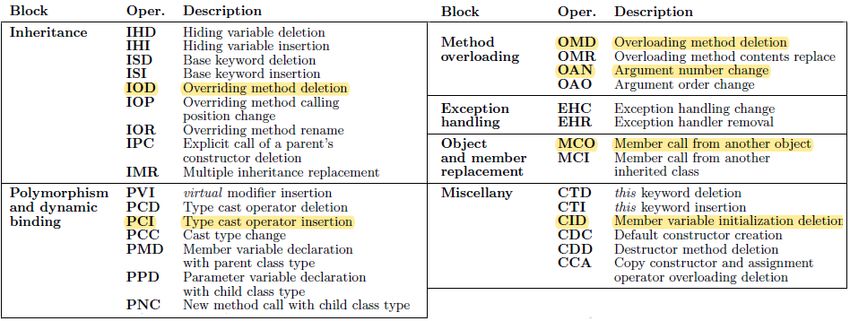
3.2 Opérateurs de mutation
3.2.1 Contexte
Une étape indispensable pour la création des mutants est de mettre en place la liste des opérateurs de
mutation à considérer. C’est-à-dire l’inventaire des mutations qui seront appliquées au programme testé.
Ce point est critique, car le nombre d’opérateurs est corrélé avec la quantité de mutants générés. Les
opérateurs doivent donc être choisis dans l’optique de maximiser l’efficacité, c’est-à-dire de calculer le
score de mutation le plus proche de la réalité avec le moins de mutants possible. C’est la mutation sélec-
tive [35].
La première tentative d’optimisation de la liste d’opérateurs adaptée au monde réel en comptait vingt-
deux répartis dans trois classes et elle était implémentée dans le logiciel Mothra dédié au langage For-
tran [36] (cf. figure 14).
Les trois classes d’opérateurs décrites par King et Offutt sont les suivantes :
— Statement analysis (sal) : altération de GOTO, remplacement d’une déclaration par TRAP, CONTINUE
ou RETURN.
— Predicate analysis (pda) : prendre la valeur absolue d’expressions, remplacer des opérateurs arith-
métiques ou logiques, insérer des opérateurs unaires, altérer des constantes.
— Coincidental correctness (cca) : remplacer des variables par d’autres, des références de tableau par
d’autres.
Cette première tentative présentait un nombre de mutants en O(n2) [37], où n est le nombre de points
de mutation (déclarations, constantes, opérateurs arithmétiques/logiques/de comparaison, etc.) dans le pro-
gramme. Une sélection plus fine s’est donc avérée indispensable afin de pouvoir appliquer la technique à
des programmes volumineux en termes de lignes de code.
Elle s’est faite en mettant au point de façon expérimentale la distribution des mutants construits pour
chaque opérateur de Mothra, ainsi qu’en analysant le résultat pour supprimer ceux qui étaient les plus en-
clins à générer un grand nombre de mutants.
Suite à cela, Offutt et al. ont démontré qu’une sous-sélection de cinq opérateurs de base permet de
calculer un score de mutation similaire à celui obtenu avec tous les opérateurs. De plus, la quantité de
19F IGURE 14 – Opérateurs de mutation de Mothra pour le langage Fortran [36]
mutants fabriquée par celle-ci est cette fois en O(n) [37] :
1. Absolute value insertion (abs) : insertion de valeur absolue (cf. figure 16).
2. Arithmetic operator replacement (aor) : remplacement d’opérateur arithmétique (cf. figure 17).
3. Logical connector replacement (lcr) : remplacement de connecteur logique (cf. figure 18).
4. Relational operator replacement (ror) : remplacement d’opérateur relationnel (cf. figure 19).
5. Unary operator insertion (uoi) : insertion d’opérateur unaire (cf. figure 20).
Cet ensemble présente l’avantage d’être adaptable à d’autres langages, car il est plus générique dans
ses opérateurs que la sélection Mothra qui en contenait certains spécifiques au Fortran.
F IGURE 15 Algorithme triangle [38]
1: procedure TRIANGLE (a, b, c)
2: if a + b > c and a + c > b and b + c > a then
3: if a = b and b = c then
4: return “Equilateral”
5: if a = b or b = c or a = c then
6: return “Isocele”
7: return “Scalene”
8: return “Not a triangle”
20F IGURE 16 Exemple de mutation de type ABS
1: procedure TRIANGLE (a, b, c)
2: if a + b > abs(c) and a + c > b and b + c > a then
3: if a = b and b = c then
4: return “Equilateral”
5: if a = b or b = c or a = c then
6: return “Isocele”
7: return “Scalene”
8: return “Not a triangle”
F IGURE 17 Exemple de mutation de type AOR
1: procedure TRIANGLE (a, b, c)
2: if a * b > c and a + c > b and b + c > a then
3: if a = b and b = c then
4: return “Equilateral”
5: if a = b or b = c or a = c then
6: return “Isocele”
7: return “Scalene”
8: return “Not a triangle”
F IGURE 18 Exemple de mutation de type LCR
1: procedure TRIANGLE (a, b, c)
2: if a + b > c and a + c > b and b + c > a then
3: if a = b or b = c then
4: return “Equilateral”
5: if a = b or b = c or a = c then
6: return “Isocele”
7: return “Scalene”
8: return “Not a triangle”
F IGURE 19 Exemple de mutation de type ROR
1: procedure TRIANGLE (a, b, c)
2: if a + b > c and a + c < b and b + c > a then
3: if a = b and b = c then
4: return “Equilateral”
5: if a = b or b = c or a = c then
6: return “Isocele”
7: return “Scalene”
8: return “Not a triangle”
21Vous pouvez aussi lire

















































