Mining the COVID-19 Open Research Dataset using T etralogie - Preliminary analysis - IRIT
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Mining the COVID-19 Open Research Dataset
using Tétralogie - Preliminary analysis
Fouille de la collection de recherche ouverte COVID-19 avec Tétralogie -
Analyse préliminaire
Bernard Dousset, Josiane Mothe
(1) IRIT, UMR5505, CNRS & Univ. Toulouse, France
Abstract. This paper reports a very short time and brief analysis of a
large data collection of scientific papers on COVID-19. The objective of
this analysis was to get a very quick overview of a domain we did not
know at all apart from the pieces of news that were looped on TV:the
COVID-19. We considered first the meta data file from the open data set
that the Allen Institute for AI and collaborators announced (CORD-19).
We then consider the PubMed subpart only, but with more information
in terms of meta-data. Less than 1 day was devoted to make the analyse
and write the report on this data set for which we present the results
here. We aim at publishing these first results while we will now check
and analyse deeper since quick analyse is also subject to potential errors.
We also will complete the analysis base on textual document contents.
Abstract. Ce document rapporte une analyse réalisée en très peu de
temps sur une vaste collection d’articles scientifiques. L’objectif de cette
analyse était d’obtenir un aperçu très rapide d’un domaine que nous ne
connaissions pas du tout, à part les informations en boucle à la télévision
: le COVID-19. Nous avons d’abord considéré l’ensemble des données
ouvertes que l’Institut Allen pour l’IA et ses collaborateurs ont annoncé
(CORD-19). Nous avons ensuite considéré la sous-partie Medline avec
un peu plus de meta-données. Moins d’une journée a été consacrée à
l’analyse et à la rédaction du rapport sur cet ensembles de données dont
nous présentons ici les résultats. Nous avons pour objectif de publier ces
premiers résultats rapidement, mais nous allons maintenant vérifier et
analyser plus en profondeur, car une analyse rapide est également sujette
à des erreurs potentielles. Par ailleurs, nous complèterons l’analyse en
prenant en compte les contenus des documents.
Keywords: Information retrieval, COVID-19, COVID-19 Open Research Dataset,
Domain overview, Mining scientific papers
1 Introduction
COVID-19 is certainly one of the most important topic these days. While news
are looped on TV, a very few people know deeply on it. A lot of fake news started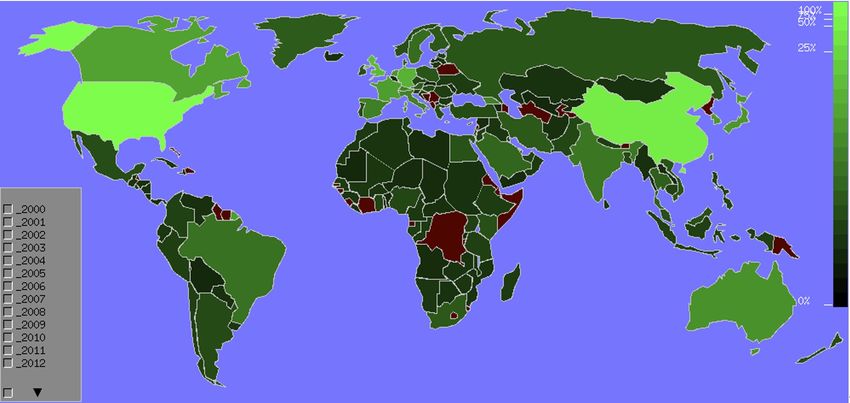
to circulate and speard as fast as the virus it-self. In such situation, scientific
papers are reliable sources that could be used for helping people knowing more
about it and being informed in an reliable and accurate way.
Mining scientific resources is also a mean to know the main institutes or
groups working in the field, what countries collaborate, what the sub-topics are,
etc... Such overview on a large quantity of research papers can help decision
makers to take decisions based on the educated views of the state of the art.
It can also help new comers in the COVID-19 research field by providing an
overview first.
Recently the COVID-19 Open Research Dataset (CORD-19), a free resource
of over 44,000 scholarly articles has been made available thanks to the effort of
the Allen Institute for AI and partners, including Medline. Part of this data set
is the resource for the analysis presented in this paper.
Introduction
COVID-19 est certainement l’un des sujets les plus importants de nos jours. Bien
que les informations soient diffusées en boucle à la télévision, très peu de gens
en savent beaucoup sur ce sujet. Beaucoup de fausses nouvelles ont commencé
à circuler et à se propager aussi vite que le virus lui-même. Dans une telle
situation, les articles scientifiques sont des sources fiables qui pourraient être
utilisées pour aider les gens à en savoir plus et à être informés de manière fiable
et précise. L’exploitation des ressources scientifiques est également un moyen
de connaı̂tre les principaux instituts ou groupes travaillant dans ce domaine,
les pays qui collaborent, les sous-sujets, etc. Une telle vue d’ensemble sur une
grande quantité de documents de recherche peut aider les décideurs à prendre
des décisions basées sur les vues éclairées de l’état de l’art. Elle peut également
aider les nouveaux venus dans le domaine de la recherche sur le COVID-19 en
leur fournissant une vue d’ensemble comme point de départ.
Récemment, la base de données de recherche ouverte COVID-19 (CORD-19),
une ressource gratuite de plus de 44 000 articles scientifiques, a été mise à dis-
position grâce aux efforts de l’Institut Allen pour l’IA et de ses partenaires. Une
partie de cet ensemble de données constitue la ressource pour l’analyse présentée
dans ce document.
2 Processing sequence
2.1 Genesis
I checked my emails this morning (March 25, 2020) where I read an email men-
tioning the release of the COVID-19 Open Research Dataset. I went to the
associated page and find out the Meta data file that fits with the type of data
file our system Tétralogie can analyse. With a colleague we thus decided to make
a brief analysis of it.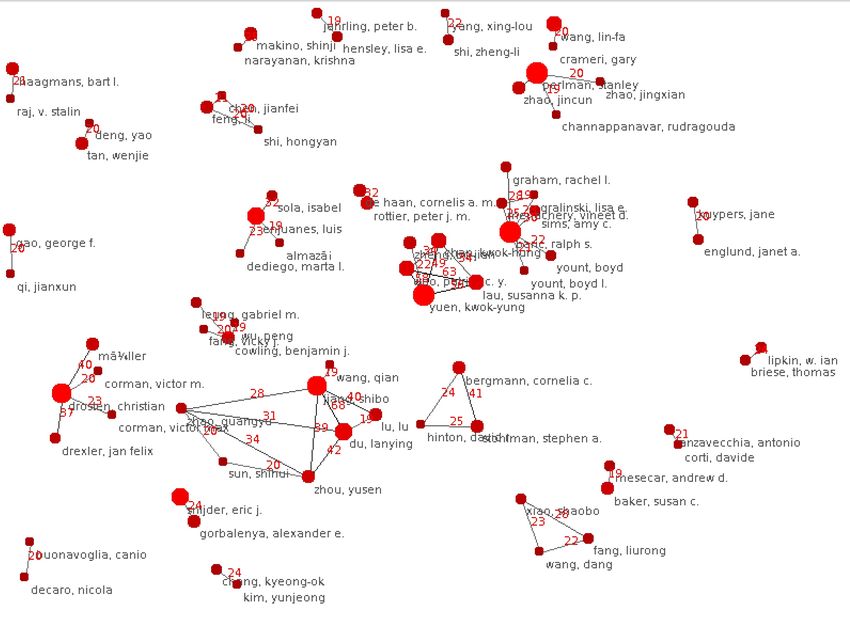
2.2 Tasks
My collegue and I decided to conduced a quick analysis of the data collection
using Tétralogie1 ; this software allows data analysis and visualization of semi-
structured data. Its development started more than a decade ago and is mainly
used to analyse publications and patents to get a view of a specific domain.
Examples of such studies are the analysis of strategic alliance networks in the
field of monoclonal antibodies[2], the analysis of the collaboration of a research
lab like in [5]. It relies on a variety of tools that are interactively combined during
the analysis [3, 4, 1].
We chose some analysis objectives that need as less as possible manual check-
ing to be reliable enough.
This paper does no mention other tools that could have been used to conduce
the analysis. It does not consider other analysis made on the same domain either.
Séquence de traitement
Génèse J’ai consulté mes e-mails à 9h55 ce matin (25 mars 2020) où j’ai lu
un e-mail mentionnant la publication de l’ensemble de données de recherche ou-
vert COVID-19. Je suis allé sur la page associée et j’ai trouvé le fichier de
métadonnées qui correspond parfaitement au type de fichier de données que
Tétralogie peut analyser. Avec un collègue, nous avons donc décidé de réaliser
une brève analyse sur cette base.
Tâche Mon collègue et moi avons décidé de procéder à une analyse rapide de
la collection de données en utilisant Tétralogie2 ; ce logiciel permet l’analyse et
la visualisation de données semi-structurées. Son développement a commencé il
y a plus de dix ans et il est principalement utilisé pour analyser les publications
et les brevets afin d’obtenir une vue d’un domaine spécifique. Des exemples de
telles études sont l’analyse des réseaux d’alliance stratégique dans le domaine
des anticorps monoclonaux[2], l’analyse de la collaboration d’un laboratoire de
recherche comme dans [5]. Il s’appuie sur une variété d’outils qui sont combinés
de manière interactive lors de l’analyse [3, 4, 1].
Nous avons choisi des objectifs d’analyse qui nécessitent le moins possible de
contrôles manuels pour être suffisamment fiables.
Ce document ne mentionne pas d’autres outils qui auraient pu être utilisés
pour mener l’analyse. Il ne prend pas non plus en considération d’autres analyses
effectuées sur le même domaine.
3 Data set
The CORD-19 data set is available at https://pages.semanticscholar.org/
coronavirus-research. This data set consists of multiple files.
1
https://atlas.irit.fr/PIE/Outils/Tetralogie.html
2
https://atlas.irit.fr/PIE/Outils/Tetralogie.html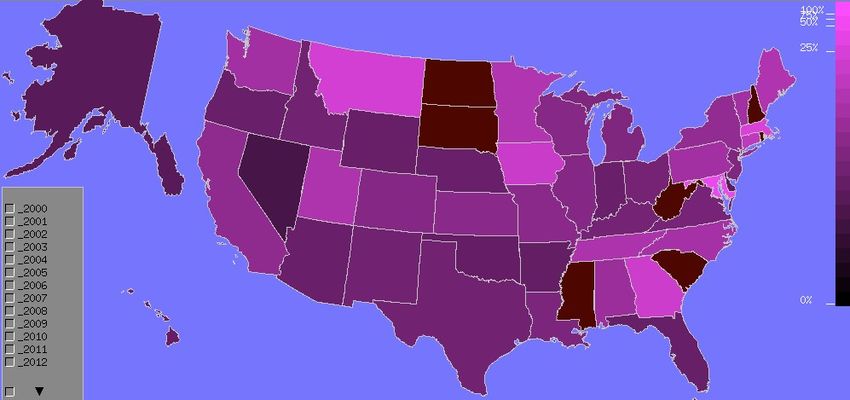
Among them, the Metadata file (60Mb) is a CSV file corresponding to 44,270
research articles with links to PubMed, Microsoft Academic and the WHO
COVID-19 database of publications. The fields of the structure of the records
are as follows: title, doi, abstract, date of publication, authors, journal, as well
as internal document ids (PMC ID, PUBMED ID, Microsoft Academic Paper
ID, WHO ID) and information whether the full text is available or not.
While the meta file is a rich source of information, other information can
be very useful such as the affiliation of the authors. For this reason we also
considered a more complete set regarding the attributes that are provided, also
if it does not contains all the 44k scientific papers but about 25k papers. We
focused on the documents from PubMed only.
The query used to query the collection is
”COVID-19” OR Coronavirus OR ”Corona virus” OR ”2019-nCoV” OR ”SARS-
CoV” OR ”MERS-CoV” OR “Severe Acute Respiratory Syndrome” OR “Middle
East Respiratory Syndrome”
Données
L’ensemble de données CORD-19 est disponible sur
https: // pages. semanticscholar. org/ coronavirus-research . Cet ensem-
ble de données est constitué de plusieurs fichiers. Parmi eux, le fichier de
métadonnées (60Mb) est un fichier CSV correspondant à 44 270 articles de
recherche avec des liens vers PubMed, Microsoft Academic et la base de données
de publications COVID-19 de l’OMS. Les champs de la structure des enreg-
istrements sont les suivants : titre, doi, résumé, date de publication, auteurs,
revue, ainsi que les ID de documents internes (PMC ID, PUBMED ID, Mi-
crosoft Academic Paper ID, WHO ID) et des informations indiquant si le texte
intégral est disponible ou non.
Bien que le métafichier soit une source d’information très riche, d’autres in-
formations peuvent être très utiles, comme l’affiliation des auteurs. C’est pourquoi
nous avons également étudié un ensemble plus complet vis à vis des champs de
données disponibles, même s’il ne contient pas l’ensemble des 44 000 articles
scientifiques mais environ 25 000 articles. Nous nous sommes concentrés sur les
documents de PubMed uniquement. La requête utilisée pour collecter la collec-
tion est:
”COVID-19” OR Coronavirus OR ”Corona virus” OR ”2019-nCoV” OR ”SARS-
CoV” OR ”MERS-CoV” OR “Severe Acute Respiratory Syndrome” OR “Middle
East Respiratory Syndrome”
4 Preliminary comment
The information we use is raw data and for this reason the conclusions drawn
have to be handle with caution because in this rapid analysis, we did not solved
content anomalies such as variants of entities spelling (e.g. author names). There
are also missing values that we did not consider either.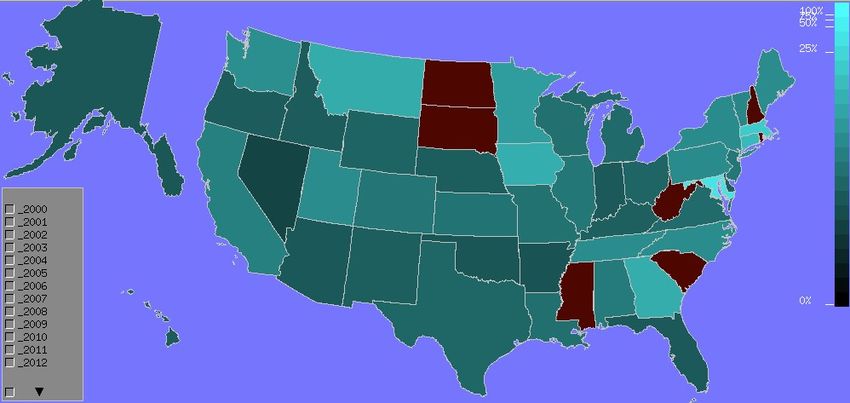
Authors Venues
131 BARIC, RALPH S. 2537 JOURNAL OF VIROLOGY
125 PERLMAN, STANLEY 1560 PLOS ONE
123 YUEN, KWOK-YUNG 749 EMERGING INFECTIOUS DISEASES
116 DROSTEN, CHRISTIAN 559 VIRUSES
111 JIANG, SHIBO 509 ARCHIVES OF VIROLOGY
91 ENJUANES, LUIS 488 SCIENTIFIC REPORTS
90 SNIJDER, ERIC J. 474 JOURNAL OF CLINICAL MICROBIOLOGY
75 DU, LANYING 421 PROC. OF THE NAT. ACADEMY OF SCIENCES OF THE USA
72 WEISS, SUSAN R. 359 PLOS PATHOGENS
72 WANG, LIN-FA 354 VIROLOGY JOURNAL
Table 1. 10 top authors (full author names), venues and the number of times they are
associated to a publication within the analysed data base.
As an illustration, without making any treatment on possible variants in the
journal names nor in the full authors names (different spelling and/or abbrevi-
ations), the 10 most frequent journals and authors that are mentioned in this
data set are as presented in Table 1 (the number corresponds to the number of
papers published in that journal or by that author among the 25k papers):
Despite its undeniable merits, the data base contains indeed some misspellings
and various writings of entities (which is a well known problem in data analysis)
that can make difficult to conclude on some points. For example, while PERL-
MAN (the first author in Table 1) has only two spellings in the file, DROSREN
has 5 and BARIC, Ralph Steven has potentially 8 as follows (with their fre-
quency):
131 BARIC, RALPH S.
31 BARIC, RALPH
11 BARIC, R S
8 BARIC, RALPH S
2 BARIC, R. S.
1 BARIC, RALPH STEVEN
1 BARIC., RALPH
1 BARIC, RALPH A.
Considering now the various spellings of the first four authors the rank of the
more occurring authors changes slightly but also the number of papers associated
to each author changes. There are 108,890 author occurrences (an author may
occurs in different publications) in this collection. The number of occurrences of
the 4 first authors from Table 1 are presented in Table 2 when variants in name
spelling are conflated into a single one.
This can be considered as a minor problem in some cases, specifically for fast
analysis but can be a more important problem in deeper analysis. Moreover, in
the collection, not all the publications are described both by the full name of the
authors and their short names. Specifically, the oldest publications seem not to
contain full author names.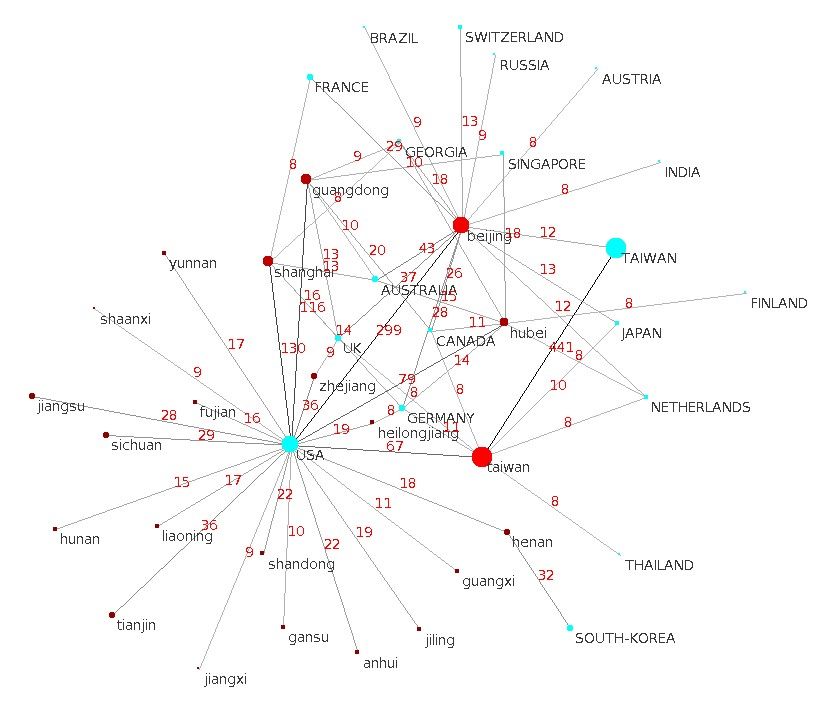
Authors without variants with variants
BARIC, RALPH S. 185 131
PERLMAN, STANLEY 132 125
YUEN, KWOK-YUNG 149 123
DROSTEN, CHRISTIAN 118 116
Table 2. 4 top authors from Table 1 when solving different spelling problems.
The same type of unsolved different spelling and missing data occur for the
other fields as well. In the rest of the document, we consider raw data for which
we did not solve the problem of missing values, nor the one of variants in name
entities because even if we have some automatic treatment to do so, manual
checking remains necessarely which is time consuming and not applicable for a
rapid analysis.
Commentaires préliminaires
Les informations que nous utilisons sont des données brutes et, pour cette raison,
les conclusions tirées doivent être manipulées avec des précaution. En effet, dans
cette analyse rapide, nous n’avons pas résolu les anomalies de contenu telles que
les variantes orthographiques des entités (par exemple les noms d’auteurs). Il y
a également des valeurs manquantes que nous n’avons pas non plus prises en
compte.
À titre d’illustration, sans faire de traitement sur les variantes possibles dans
les noms des revues ni dans les noms complets des auteurs (orthographe différente
et/ou abréviations), les 10 revues et auteurs les plus fréquents qui sont men-
tionnés dans cet ensemble de données sont présentés dans le tableau 1 (le nom-
bre correspond au nombre d’articles publiés dans cette revue ou par cet auteur
parmi les 25k articles) :
Malgré ses mérites indéniables, la base de données contient en effet quelques
fautes d’orthographe et diverses écritures d’entités (ce qui est un problème
bien connu dans l’analyse des données) qui peuvent rendre difficile la conclu-
sion sur certains points. Par exemple, alors que PERLMAN (le premier auteur
du tableau 1) n’a que deux orthographes dans le fichier, DROSREN en a 5 et
BARIC, Ralph Steven en a potentiellement 8 comme suit (avec leur fréquence):
131 BARIC, RALPH S.
31 BARIC, RALPH
11 BARIC, R S
8 BARIC, RALPH S
2 BARIC, R. S.
1 BARIC, RALPH STEVEN
1 BARIC., RALPH
1 BARIC, RALPH A.
En considérant maintenant les différentes orthographes des quatre premiers
auteurs, le rang des auteurs les plus présents change légèrement mais également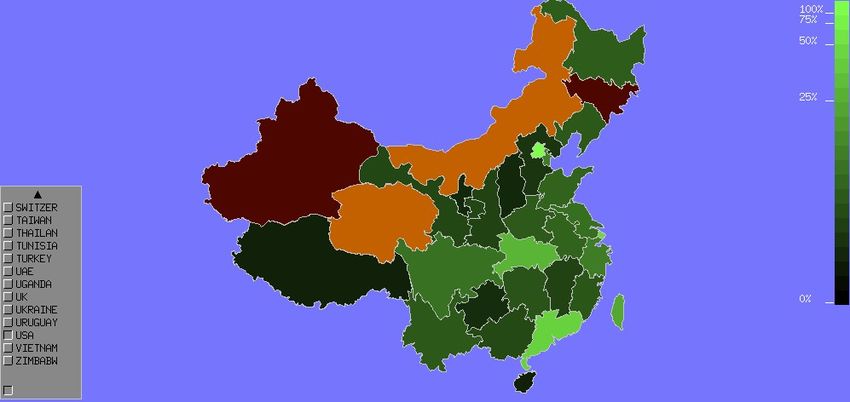
Fig. 1. Number of publications - Evolution (Nombre de publications - Evolution)
.
le nombre d’articles associés à chaque auteur change. Il y a 108 890 occurrences
d’auteurs (un auteur peut se trouver dans différentes publications). Le nombre
d’occurrences des 4 premiers auteurs du tableau 1 est présenté dans le tableau 2
lorsque les variantes de l’orthographe du nom sont ramenées à une seule.
Cela peut être considéré comme un problème mineur dans certains cas, en
particulier pour une analyse rapide, mais peut constituer un problème plus cru-
cial dans le cadre d’une analyse plus approfondie. En outre, dans la collection,
toutes les publications ne sont pas décrites à la fois par le nom complet des au-
teurs et par leur nom abrégé. Plus précisément, les publications les plus anciennes
ne contiennent pas les noms complets des auteurs.
Le même type d’orthographe différente non résolue et de données manquantes
se produisent également pour les autres champs de données. Dans le reste du
document, nous considérons les données brutes sans résoudre ces problèmes qui
nécessite des interventions humaines de vérification et qui n’est donc pas appro-
prié pour une analyse rapide.
5 Number of publications
Figure 1 shows the evolution of the number of publications over time. There are
finally classical curves that are common to various topics with a rapid increase
in recent years and a large number of publications in USA and China although
it would be worth looking at the European case as a unit.
Fig. 2. Baric’s network (considering publications where the full author name occur)
.
Nombre de publications
La figure 1 présente l’évolution du nombre de publications au cours du temps.
Ce sont des courbes finalement classiques dans de nombreux domaines avec une
augmentation des publications dans les années récentes et une part importante
des publications signées par les USA et la Chine. Il pourrait être intéressant de
prendre en compte l’Europe comme une unité.
6 Collaborations at the author level
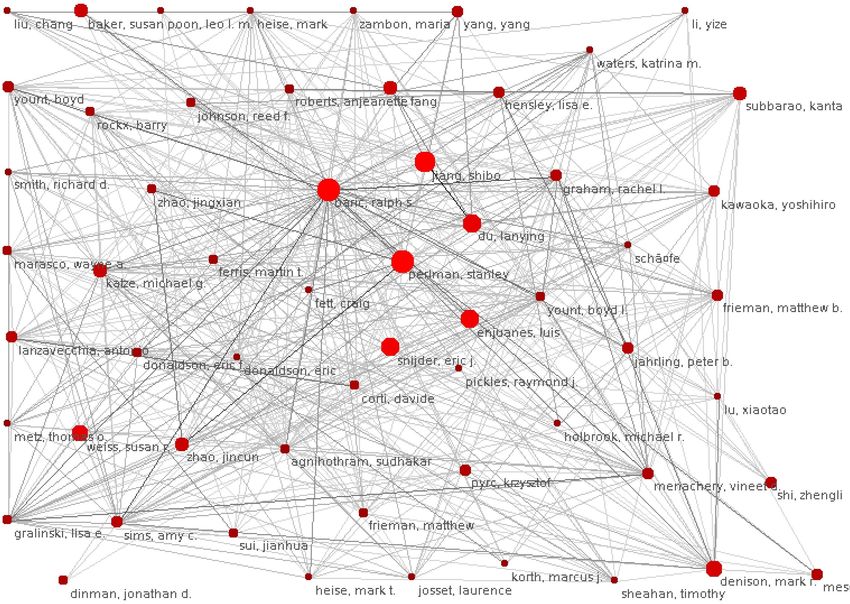
Figure 2 displays BARIC, RALPH S.’s direct network (co-authors). This net-
works considers the publications from the dataset where the full author names
are included. Notice that the other most occurring authors (See Table 2) are in
this network.
In a similar way, Figure 3 displays BARIC, RALPH S.’s direct network with
journals. This networks considers the publications from the dataset where the
full author names are included as well as the journal; journals in which a single
publication of the author occurs have been removed. Combined with the most
frequent venues, it provides an additional information on venues.
Finally, Figure 4 displays the strongest communities based on co-authorship.
This network considers the publications from the dataset where the full author
names are included and for which co-authoring occurs in at least 20 publications.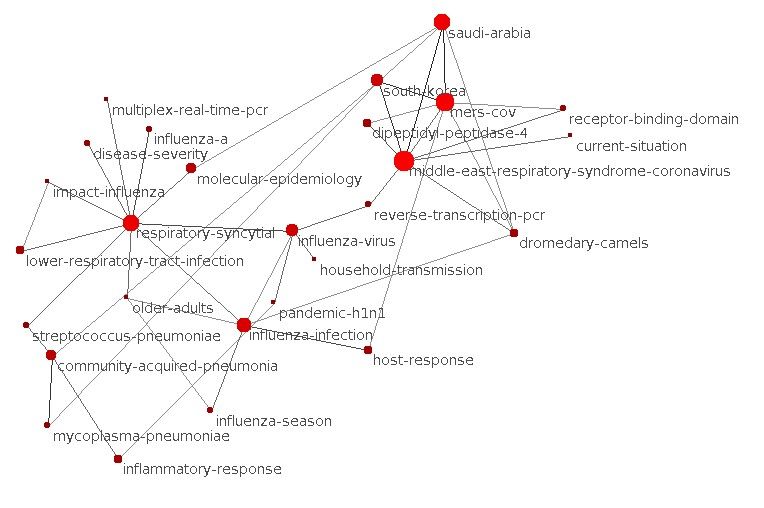
Fig. 3. Baric’s network with journals
.
Fig. 4. Strongest author networks (considering publications where the full author name
occur)
.
Collaboration au niveau des auteurs
La Figure 2 affiche le réseau direct de BARIC, RALPH S. (co-auteurs). Ce
réseau prend en compte les publications de l’ensemble de données où les noms
complets des auteurs sont inclus. Les autres auteurs les plus fréquents (Voir
Table 2) se trouvent dans ce réseau.
De façon similaire, la Figure 3 affiche le réseau direct de BARIC, RALPH
S. avec les journaux. Ce réseau prend en compte les publications de l’ensemble
de données dans lesquelles les noms complets des auteurs sont inclus et lorsque
la revue est mentionnée ; les revues dans lesquelles l’auteur n’apparait qu’une
seule fois ont été supprimées. Combinée avec les lieux les plus fréquents, cette
vue fournit une information supplémentaire sur les journaux.Fig. 5. Geographic overview of the contributions - the brighter, the larger
.
La Figure 4 affiche les communautés les plus fortes sur la base des co-auteurs.
Ce réseau prend en compte les publications de l’ensemble de données où les noms
complets des auteurs sont inclus et pour lesquelles la co-publication est présente
dans au moins 20 publications.
7 Collaboration and engagement at the geographic level
In this section, we consider the authors’ affiliation when mentioned in the data
collection. We made a focus on China and USA with two different perspectives
as presented below.
In Figure 5, we can see the contribution of the different countries to the
collection. Not surprisingly USA and China are dominating. We are then giving
two different types of focus in what follows.
Figure 6 presents the network of the collaborations between the various parts
of China (in red) and the other countries (in blue) based on the authors’ affili-
ations. The weights on the links correspond to the number of publications that
are mentioned as being written by authors from both linked locations. For ex-
ample, one of the strongest is between USA and Beijing institutions. Another
important one is with Guang Dong. A deeper analysis could be made at the
institution level.
In Figure 7 we can observe the collaborations that are mentioned with USA.
For garnet-colored parts, there are no collaboration with other countries men-
tioned. In orange, there are collaborations, but not with USA, in various levels
of green, the collaboration with USA are mentioned.
With regard to USA, we looked at another dimension which is related to the
effort each state put according to various criteria. Rather than observing theFig. 6. Focus on China collaborations
.
absolute values of the number of publications, the maps represent the ratio with
either the population or the gross national income (See Figure 8).
Collaboration et engagement au niveau géographique
Dans cette section, nous considérons l’affiliation des auteurs lorsqu’elle est men-
tionnée dans la collection de données. Nous avons mis l’accent sur la Chine et
les États-Unis avec deux perspectives différentes, présentées ci-dessous.
La figure 6 présente le réseau des collaborations entre les différentes parties
de la Chine (en rouge) et les autres pays (en bleu) en fonction des affiliations
des auteurs. Les poids sur les liens correspondent au nombre de publications
mentionnées comme étant écrites par des auteurs des deux endroits liés. Par ex-
emple, l’un des liens les plus forts est celui entre les États-Unis et les institutions
de Pékin. Un autre lien important est celui avec Guang Dong. Une analyse plus
approfondie pourrait être faite au niveau des institutions.Fig. 7. Focus on China-USA collaborations.
Fig. 8. Contribution of the different states relatively to the population (left side part)
and relatively to the gross national income (right side part).
Dans la figure 7, nous pouvons observer les collaborations qui sont men-
tionnées avec les États-Unis. Pour les pièces de couleur grenat, il n’y a pas de
collaboration avec les autres pays mentionnés. En orange, il y a des collabora-
tions, mais pas avec les États-Unis. En vert, nous voyons la collaboration avec
les États-Unis à différents niveaux.
En ce qui concerne les États-Unis, nous avons examiné une autre dimension
qui est liée à l’effort que chaque État déploie selon divers critères. Plutôt que
d’observer les valeurs absolues du nombre de publications, les cartes représentent
le rapport avec la population ou le produit national brut (See Figure 8).
8 Textual analysis
We considered the title only in this analysis while abstracts would be much
appropriate to consider because they are more complete. Authors’ or editor’s
key-words were not available thus were not used.Fig. 9. Examples of phrases that have been generated from titles and extracted.
Fig. 10. Examples of clusters of phrases from titles.
Figure 9 presents some of the phrases we automatically extracted from the
titles. Some phrases are used together in titles. When considering the phrase
co-occurrences larger than 1, it is then possible to extract phrase clusters as the
one presented in Figure 10. As one can see, some of these phrases are deeply
connected with population concerns about the COVID-19 such as ”Early stage
infection” or ”factor associated with severity” or ”wearable proximity”. These are
very interesting starting point for deeper analysis. These key phrases extracted
from free text are also a very good way to detect topical subjects of interest that
can be difficult to extract from keywords fields when provided.
Analyse textuelle
Nous n’avons tenu compte que du titre dans cette analyse, alors que les résumés
seraient tout à fait appropriés à considérer car ils sont plus complets. Les mots-
clés des auteurs ou des éditeurs n’étant pas disponibles, ils n’ont pas été utilisés
ici.La figure 9 présente certains des groupes de mots que nous avons automa-
tiquement extraits des titres. Certains groupes de mots sont utilisés ensemble
dans les titres. Si l’on ne considère que les cooccurrences de phrases supérieures
à 1, il est alors possible d’extraire des groupes de phrases comme celui présenté
dans la figure 10. Comme on peut le voir, certaines de ces expressions sont
étroitement liées aux préoccupations de la population concernant la COVID-19,
telles que ”infection à un stade précoce” ou ”facteur associé à la gravité” ou
”proximité de la personne”. Ce sont des points de départ très intéressants pour
une analyse plus approfondie. Ces phrases clés extraites de textes libres sont
également un très bon moyen de détecter des sujets d’actualité intéressants qui
peuvent être difficiles à extraire des champs de mots clés lorsqu’ils sont fournis.
9 Conclusion
The purpose of this short report was to present a quick overview of a set of
scientific documents collected on the topic of COVID-19. We focused on the
simplest metadata to analyse. This study should be extended by a more detailed
study at the level of institutions for example. The European effort as a unit could
also be included. Finally, the analysis of the content of the paper abstracts would
be a particularly interesting contribution. We do believe that this analysis will
be also useful for the coming COVIDSearch task https://dmice.ohsu.edu/
hersh/COVIDSearch.html.
It is important to mention that this document and the analysis it presents
were completed in less than 24 hours. There are necessarily some details missing
and certainly important ones.
Conclusion
Cet article avait pour objectif de présenter une vue rapide d’un ensemble de
documents scientifiques collectés sur le thème du COVID-19. Nous nous sommes
focalisés sur les méta-données les plus simples à analyser. Cette étude devrait être
prolongée par une étude plus fine au niveau des institutions par exemple. L’effort
de l’Europe considérée comme une unité pourrait également être inclue. Enfin,
l’analyse du contenu des résumés serait un apport particulièrement intéressant.
Nous pensons que cette analyse sera également utile pour la tâche COVIDSearch
à venir https: // dmice. ohsu. edu/ hersh/ COVIDSearch. html .
Enfin, ce document et l’analyse qui y est présenté ont été réalisés en moins
de 24 heures. Il manque forcément alors des détails et certainement importants.
Nous nous sommes appuyés sur DeepL pour certaines traductions dans ce
document www. DeepL. com/ Translator( versiongratuite) .
References
1. Z. Boulouard, L. Koutti, N. Chouati, A. El Haddadi, B. Dousset, A. El Haddadi,
and F. Bouhafer. Visualizing large graphs out of unstructured data for competitiveintelligence purposes. In Proceedings of SAI Intelligent Systems Conference, pages
605–626. Springer, 2016.
2. B. Gay and B. Dousset. Les réseaux d’alliances stratégiques dans le domaine
des anticorps monoclonaux: étude longitudinale. In Journées sur les systèmes
d’information élaborée, 2005.
3. I. Ghalamallah, A. Grimeh, and B. Dousset. Processing data stream by relational
analysis. Dans: REVUE MODULAD, pages 67–70, 2007.
4. J. Mothe, C. Chrisment, T. Dkaki, B. Dousset, and S. Karouach. Combining mining
and visualization tools to discover the geographic structure of a domain. Computers,
environment and urban systems, 30(4):460–484, 2006.
5. J.-L. MULTON, G. BRANCA-LACOMBE, and B. DOUSSET. Analyse bib-
liométrique des collaborations internationales de l’inra. In VSST’2001: veille
stratégique scientifique & technologique: systèmes d’information élaborée, bib-
liométrie, linguistique intelligence économique (Barcelone, 15-19 octobre 2001),
pages Vol1–261, 2001.Vous pouvez aussi lire

















































