Le choix MongoDB dans l'architecture BIG DATA du projet KARMA - Refonte du Système de Revenue Management d'Air France KLM Conférence BIG DATA ...
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Le choix MongoDB dans l’architecture BIG DATA du projet KARMA Refonte du Système de Revenue Management d'Air France KLM Conférence BIG DATA - Master MBDS Université de Nice Sophia Antipolis 26 Janvier 2016 Martial AYAS – maayas@airfrance.fr
2 Agenda
1. Présentation de KARMA 4. Utilisation de MongoDB dans KARMA
- Le Revenue Management - Objectifs & contraintes
- Définitions et concepts - Technologies et critères d’évaluation
- Chiffres clés - Le choix MongoDB
- Données et traitements du RM - Architecture et fonctionnement
2. Utilisation d’Hadoop dans KARMA 5. Cas d’utilisation
- Le choix d’Hadoop - POC Flights Availability
- L’architecture technique - Eureka
- Design d’un batch Hadoop
- Etat des lieux technique et
fonctionnel
6. Evolutions à venir
3. Axes d’amélioration
- Les performances
- Accès aux données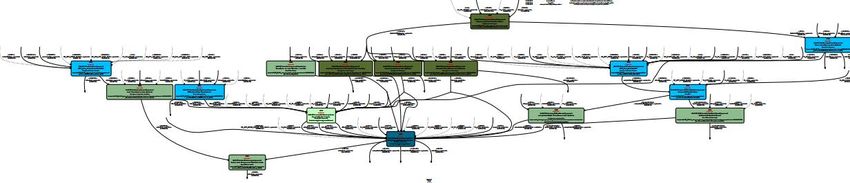
3 Présentation de KARMA Faible
contribution
200€
Moyenne Haute
contribution contribution
350€ 500€
Le Revenue Management
Contribution moyenne :
260€
Remplissage
« naturel »
J : Départ vol
M-12 : Ouverture du vol M-2 : Saturation vol
M-4 : Fermeture BC M-1 : Fermeture MC
Contribution moyenne :
310 €
Maximalisation du revenu
par contrôle des ventes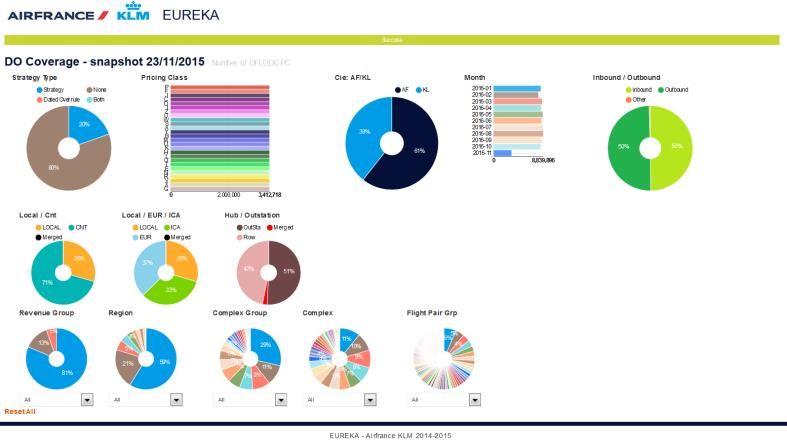
4 Présentation de KARMA
Définitions et concepts
• KARMA KLM Air France
Revenue Management L’objectif principal de
Application
KARMA
• RMS : Revenue Management
System
• KARMA permet d’optimiser le
« To sell the right seat
revenu grâce à la prévision : to the right person
- Demande at the right moment »
- Annulation
- Overbooking
• Permet aux analystes de vols
d’agir sur les recommandations
du système en fonctions : Et d’influer sur la disponibilité des
- Des marchés sièges à vendre pour un tarif
- Des périodes donné à une date donnée.
- Des évènements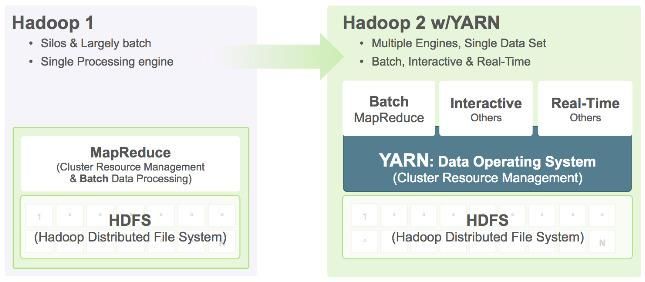
5 Présentation de KARMA
Chiffres clés (2015)
• Le programme de vol
- 2500 vols / jour
- 231 destinations / 103 pays
• L’activité « Passage »
- 77,5 millions de passagers
• Les avions
- 569 avions
- De 40 à 520 sièges
• La tarification
- 26 classes
- 30 000 tarifs
- Prix carburant
- La concurrence
- La demande
Volumes initiaux + Combinatoire = Démultiplication des volumes
Augmentation des volumes = Problématiques de performances
6 Utilisation d’Hadoop dans KARMA
Le choix d’Hadoop (1/2)
• Contexte fonctionnel et technique au démarrage du projet :
- Refonte du RM = Nouvelle approche + Nouveaux besoins
- Forte augmentation des volumes nécessaires aux calculs de prévision
- Forte augmentation de la fréquence des évènements à prendre en compte
pour avoir un système réactif
Augmentation des volumes et du stockage
Augmentation de la puissance de traitement
- Infaisabilité des traitements batch en BD
- Le volume des données lié aux évènements et aux combinaisons possibles
- Temps de traitements incompatibles avec la fréquence nécessaire des MAJ
Nécessité de paralléliser et distribuer les traitements et les données
- Interfaçage avec les moteurs de RO
- Les moteurs de Recherche Opérationnelle (Prévision + Optimisation)
- Développés en C++ (CPlex), utilisent l’approche Map Reduce / Fichiers
L’alimentation des moteurs doit se faire sous la forme de fichiers
7 Utilisation d’Hadoop dans KARMA
Le choix d’Hadoop (2/2)
• Le choix Hadoop n’est pas sans contraintes …
- Contraintes d’exploitation
- Haute disponibilité / Tolérance aux pannes
- Seuls la Base de données et le NFS sont supportés (backup) par la production
Mécanisme de synchronisation entre la BD, le NFS et le HDFS
- Maitrise du stockage malgré les volumes Utilisation du format Avro + compression
- Contraintes de développement / Maintenabilité
- Apprentissage de l’approche et des API
- Démultiplication des composants : 1 req SQL 1 à n jobs Hadoop
Ex : Le traitement d’optimisation quotidien comporte 765 jobs dont 376 en Hadoop
Création d’un Framework de développement pour harmoniser le dev des jobs Hadoop
- Chaque job de MapReduce crée une nouvelle copie des données
Besoin d’un outil de design des jobs est de suivi du cycle de vie des traitements et des
données produits par Hadoop (Voir diagramme)
- Contraintes métier
- Concilier les 3 activités : Batch / Utilisateur / Evènementielle (Problématique de
concurrence sur l’accès et la mise à jour des données)
Séparation des traitements par la planification / contraintes de perfs importantes
8 Utilisation d’Hadoop dans KARMA
Design technique d’un Batch Hadoop
Extractions Traitements Injections
DB Oracle 11g DB HDFS DB HDFS DB Oracle 11g
Métier
3To ~350 tables SQOOP SQL*Loader 3To ~350 tables
C++ CPlex
Transformations Transformations
Avro, CSV, XML Agrégations Avro Formatage Avro, CSV
Hadoop / PIG Hadoop / PIG NFS
NFS Copies Copies
1,5To Traitements 1,5To
NFS HDFS Avro, CSV, XML Métier Avro, CSV HDFS NFS
CSV, XML, … DistCp CSV, XML, …
DistCp Hadoop / PIG
• Accès aux données DB • Traitements métier
- SQOOP + OraOop : Extractions en // - Hadoop MapReduce : traitements hors RO
- SQL*Loader : Injection en // - C++ Cplex : Moteurs de prévisions,
(Suppression des contraintes d’intégrité, d’optimisations (Recherche Opérationnelle)
dénormalisation, recalcul des indexs)
• Reporting
• Accès aux données NFS - PIG : Statistiques et KPI vérification de la
- DistCp : Copies HDFS NFS qualité des données
• Préparation des données • Exploitation / Supervision
- Hadoop MapReduce : Transformation, - Error collector, compacteurs, archivage,
comparaisons, jointures, agrégations, purge
filtres, fusion, …9 Utilisation d’Hadoop dans KARMA
Etat des lieux technique et fonctionnel
Revue Technique Exemple du RSU (OAC27)
Ferme de serveurs Profil du batch (MAJ 01/2016)
- 21 Serveurs : 32 CPU et 128 Go de RAM par serveur - Exécution quotidienne
- Durée approximative : 10 Heures (11h30)
Grille de calcul - Nombre d’Unités de tâches : 117 (128)
- Nombre de jobs total : 603 (765)
- Pour une capacité d’environ 850 slots d’exécution en - Nombre de jobs en séquence : 244 (232)
parallèle
- Nombre de jobs en parallèle : 359 (533)
Grille de stockage (HDFS) - Nombre de jobs Hadoop : 313 (376)
- Répartit sur les 21 serveurs Stockage nécessaires (HDFS)
- 3,2 To par serveur soit 67 To au total
- 700GB, soit 2,1TB avec la réplication x3
(1,2TB soit 3,6 TB avec la réplication x3)
Revue Fonctionnelle Typologie des traitements
Traitements Batchs (uniquement) - Job Java Hibernate
- 45 batch (métiers / techniques / KPI) - Job techniques Shell
- 8 process planifiés > 1H dont 7 utilisent Hadoop - Jobs techniques Hadoop
- 7 process à la demande > 1H dont 7 utilisent Hadoop (préparation / transformation / agrégation)
- Jobs fonctionnels Hadoop
- Moteurs de RO (C++)10 Axes d’amélioration
Performances et accès aux données
• La performance des batch
- Optimisation du séquencement des jobs au sein des Batchs
- Optimisation / limitation des extractions / injections entre la DB et le
HDFS
• La performance des traitements interactifs et évènementiels
- Normalisation + Volumes = Jointures et agrégations couteuses
• Multiplication et diversification de l’accès aux données
- A des traitements batch d’applications tierces
- A des traitements non batch
- Traitements interactifs
- Traitements évènementiels
Les pistes : Nouvelles approches + nouvelles technologies11 Utilisation de mongoDB dans KARMA
Objectifs et contraintes
• Constats
- KARMA bénéficie d’une architecture et de moyens uniques au sein du SI
- Cependant la puissance de calcul et les données sont « sous utilisées »
- Traitements batch très évolués / optimisés
- Traitements interactifs limités / optimisation couteuse
• Objectifs
- Réutiliser la puissance de calcul et les données de KARMA pour
améliorer les traitements interactifs
- Améliorer et faire évoluer KARMA
- Proposer de nouveaux services
- Ouvrir les données à des applications tierces
• Contraintes
- Pas d’impact sur les performances
- Activité batch la nuit et les week-ends
- Base de données Oracle dédiée au RM (Forte sensibilité qualité / perfs)
- Sortir des contraintes propres à KARMA
- Eclipse RCP12 Utilisation de MongoDB dans KARMA
Technologies et critères d’évaluation
• Points faibles de l’accès interactif aux données
- Jointure et Agrégation des données
- Oracle est déjà surchargée (GUI + Alimentation temps réel)
- La plupart des jointures et agrégations existent déjà sur le HDFS
Techno Type Support Performances Compatibilité / Impacts
Hive Metastore HDFS Usage interactif Impact uniquement lors de l’utilisation
exclu couteux
HBase BD NoSQL – Colonne HDFS OK Impact continu sur la grille Hadoop
mongoDB BD NoSQL – Document FS OK Pas d’impact direct mais de nouveaux
investissements
• Aucune technologie ne se démarque vraiment
- D’autres critères doivent être pris en compte …13 Utilisation de mongoDB dans KARMA
Le choix mongoDB
• Choix de privilégier mongoDB pour ses autres atouts :
- Approche document
- Dénormalisation de l’information
- Plus proche de l’utilisation de la donnée que du stockage
- Interopérabilité : JSON, Drivers
- Format optimisé BJSON
- Agrégation Framework Performances
• Développement / Exploitation
- Courbe d’apprentissage et mise en œuvre rapide
- Communauté très active
- HA (Haute Disponibilité) / Sharding (Scalabilité horizontale)
• MongoDB et nouvelles tendances :
- Développements Agile
- MongoDB + AS + AngularJs + D3.js + CSS = Rich Modern Web Apps
- Applications Web mono page
- Applications multi supports (PC, Smartphones, Tablettes, …)14 Cas d’utilisation
POC Flight Availability
• Proposer un outils de recherche de disponibilité des vols
- Réutilisation des données du HDFS
- Client léger (Navigateur Web)
- Interface graphique riche et dynamique
• Données
- Oracle : YS_DFLS (15M), YS_DFLCS (25M), référentiel géographique
- MongoDB : Vols (3,7M), Trajets (~1000), référentiel géographique
• Démo15 Cas d’utilisation
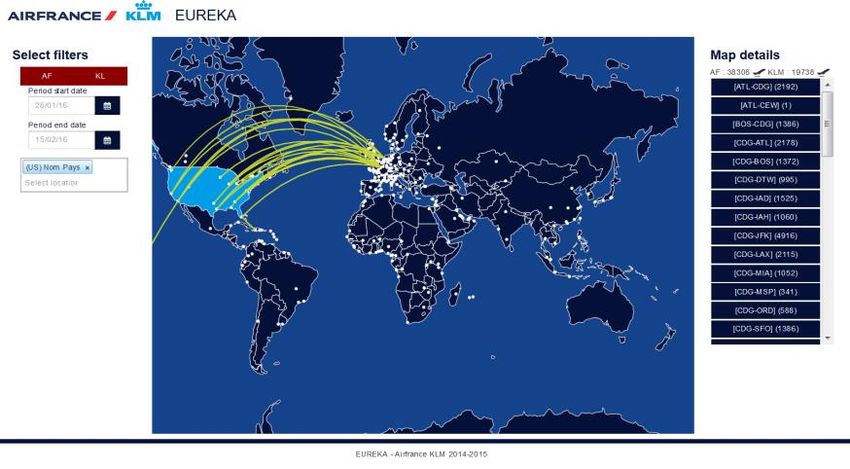
Eureka
• Proposer un outils de monitoring de l’activité utilisateur
- Analyser de quelle façon les utilisateurs maximisent le revenue
- Analyser la couverture des marchés
- Identifier les bonnes pratiques afin de les diffuser
- Identifier les lacunes et les combler
• DémoEvolutions à venir
16
• MongoDB en complément et non en remplacement d’Oracle
• L’idée est donc de spécialiser chaque technologie en fonction des
usages
- Oracle :
- Normalisation et intégrité des données
- Usage transactionnel / interactif
- MongoDB :
- Performances liées à l’agrégation des données
- Usage interactif / BI dynamique
- Hadoop (MapReduce + HDFS) :
- Performances des batch
- Préparation / spécialisation des données
• Prochaine étape :
- Spark Streaming / Kafka
- Usage temps réel / évènementielAnnexes
18 Présentation d’Hadoop
Fonctionnement général / Architecture
• Objectifs d’Hadoop TWS
- Paralléliser et distribuer des Planification des Jobs
traitements sur une ferme de serveurs
pour améliorer les performances et Hadoop Master
permettre des traitements dont les
JobTracker NameNode
volumes de données sont (très) Gestion de la Gestion du HDFS
importants. soumission et de répartition et
l’exécution des jobs réplication des données
• Ce que fournit Hadoop
- Moteur d’exécution
- Gère la // et la distribution des traitements
Serveur 1 Serveur 2 Serveur N
- Gère la distribution et la réplication des
données TaskTracker TaskTracker TaskTracker
- Des API qui implémentent l’approche Grille Nœud
UC UC UC
MapReduce et l’accés au HDFS de
calcul (CPU) (CPU) (CPU)
d’exécution
- Un système de stockage distribué le
HDFS (Supporte différents formats (CSV,
XML, JSON, AVRO, …) Grille US US US Nœud
de (HDD) (HDD) (HDD)
de
• Des outils complémentaires stockage
HDFS DataNode DataNode DataNode
stockage
- Supervision
- Import / Export DB HDFS
- Abstraction (PIG, HIVE, …)19 Présentation d’Hadoop
L’approche MapReduce
• Un traitement MapReduce se décompose en 3 étapes :
1 - L’étape de Map : Préparation des données
Permet de lire, extraire / créer une clé de regroupement, transformer / formater, filtrer, …
2 - L’étape de Shuffle : Tri, regroupement et distribution
Les données en sortie du Mapper sont automatiquement triées et regroupées par clé dans
différents blocks.
3 - L’étape de Reduce : Traitement métier
Applique les règles métier sur les données regroupées par clé : Filtrer, agréger, sommer,
transformer, …
Contexte d’exécution Hadoop
Job Hadoop
Shuffle
~64 MB
Map key ~X MB
Grp1 Reduce
~1GB ~64 MB Map ~Z MB
key
Grp2 Reduce ~Y MB
Map
~64 MB20 Présentation d’Hadoop
Fonctionnement général
• Objectifs d’Hadoop TWS
- Paralléliser et distribuer des traitements Planification des Jobs
sur une ferme de serveurs pour
améliorer les performances et permettre Hadoop Master
des traitements dont les volumes de
JobTracker NameNode
données sont (très) importants. Gestion de la Gestion du HDFS
soumission et de répartition et
• Ce que fournit Hadoop l’exécution des jobs réplication des données
- Moteur d’exécution
- Gère la // et la distribution des traitements
- Gère la distribution et la réplication des
Serveur 1 Serveur 2 Serveur N
données
- Des API de développement qui TaskTracker TaskTracker TaskTracker
implémentent l’approche MapReduce et Grille de
UC UC UC
permet d’accéder au HDFS calcul
(CPU) (CPU) (CPU)
- Un système de stockage distribué le
HDFS (fichiers)
- Supporte différents formats (CSV, XML, US US US
Grille de
JSON, AVRO, …) stockage
(HDD) (HDD) (HDD)
HDFS
• Des outils complémentaires DataNode DataNode DataNode
- Supervision
- Import / Export DB HDFS
- Abstraction (PIG, HIVE, …)21 Cas d’utilisation
Mise à jour du programme de vol
D Purge Job Avec Hadoop
Map Task D Compare Job
64 MB
Xml
Xml Map Task Reduce Task
Read Sort
Extract
20 GB 64 MB blocks keys Process all
Keys Xml Xml Xml
Xml Xml from store grouped New
Purge
splited Into keys Xml Flights
XML
64 MB
files blocks Read Xml together
Xml Read Sort Sort
Xml data, apply Canc.
blocks keys keys Xml
extract Xml
business Flights
from store store Xml
keys, rules
splited Into Into
and determine
files blocks Xml blocks Modif.
D-1 Purge Jobs values new Xml Flights
Cxl, upd,
20 GB Xml
unchanged
Purge Xml Xml Unch.
Xml Purge flights Xml
Xml Flights
Purge
Xml Resquest, compare, apply rules, and update data
20 GB Split and Xml
Launch and
manage Resquest, compare, apply rules, and update data
Avec un
Xml purge data
Xml
Threads SGBD
Resquest, compare, apply rules, and update data
Complexité à la charge du développeur La quasi-totalité du traitement repose sur la BD PB Contention
PB Puissance
Actions implemented by Developers Actions supported by Hadoop Framework22 Cas d’utilisation
Optimisation des traitements (1/2)
Décomposer pour mieux paralléliser
• Approche séquentielle
Donnée X Donnée X Donnée X Donnée X
• A • A • A • A
• B • B • B • B
• C Job 1 • C Job 2 • C Job 3 • C
• D • D • D • D
• Approche optimisée Donnée X
• A
• B Conf.
• C
• D règles
Job 1 • Signature
Donnée X Donnée X
Donnée X
• A • A • A
• B • B Job 3 • B
Job 2 •
• C C Merger • C
• D
• D • Signature • D
Job 3 Donnée X
• A
• B
• C
• D
• Signature23 Cas d’utilisation
Optimisation des traitements (2/2)
• Optimiser par le séquencement et la disponibilité des données
- Démultiplication du nombre de jobs Hadoop
- Analyse des entrées / sorties de chaque jobs
- Déterminer le séquencement optimal des traitements
- Les traitements se lancent uniquement lorsque l’ensemble des données
sont prêtes
- Plus il y a de traitements parallélisés mieux on utilise la grille24 Cas d’utilisation
Equilibrage des traitements (1/2)
Donnée Y Job 2
Grp clé 1
Map Reduce
Donnée X Donnée Z
Job 1 Grp clé 2
Map Reduce
Grp clé 3
Map Reduce
L’application des
règles métier créent Grp clé 4
Map Reduce
un déséquilibre dans
le volume des
données regroupées
selon la clé choisie Le temps de traitement est égal au temps du job le plus long
(dont le volume de données à traiter et le plus important)
Risque qu’un reducer ne tienne pas en mémoire25 Cas d’utilisation
Equilibrage des traitements (2/2)
Donnée Y Donnée Y
Grp clé 1 Job 2
Grp clé 1
Grp clé 2a Map Reduce
Donnée Job Job
X Job 1 Grp clé 2 Map Reduce
Stats Stats Grp clé 2b
(Map) (Map) Map Reduce Donnée Z
Grp clé 3 Grp clé 3
L’application des règles Grp clé 4a
Map Reduce
métier créent un
Grp clé 4 Map Reduce
déséquilibre dans le Grp clé 4b
volume des données Map Reduce
regroupées Stats Grp clé 4c
volumes
Les temps de traitement sont
Analyse les volumes / clé équilibrés
et calcul un discriminant Levée du risque lié à la
technique pour mieux mémoire nécessaire au
équilibrer les groupes de traitement du reduce
clés26 Axes d’amélioration et évolutions
Migration vers Hadoop 2
• Introduction de YARN
- Plusieurs moteurs
d’exécution
- Meilleure gestion des
ressources
- amélioration des
performances
- Permet de gérer
plusieurs applications
• Traitement interactifs
- HIVE, HBASE, …
- Ouverture des données du HDFS à des applications tierces
- Accès aux données simplifié par l’utilisation de langages de Scripts / SQL Like
• Traitement temps réel :
- Storm, Spark Streaming, …
- Intégration des évènements / CEPVous pouvez aussi lire

















































