HBASE - HADOOP PIG - HIVE BIEN DEBUTER - Ce document est mis à disposition selon les termes de la Licence Creative Commons Attribution 4.0 ...
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
HBASE - HADOOP
PIG - HIVE
BIEN DEBUTER
Ce document est mis à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International.
1/90 Tondeur Hervé(2017)
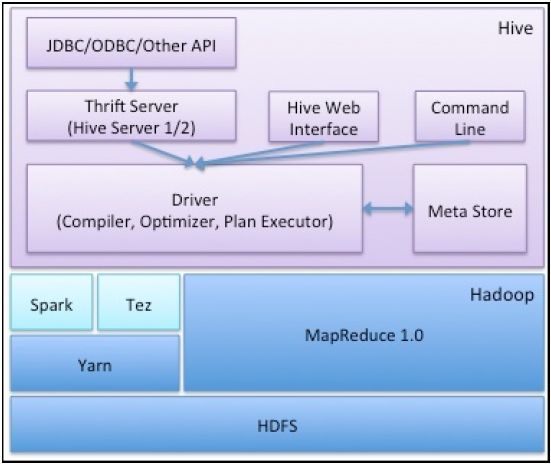
Introduction au BigData et au Bestiaire des outils Apache Hadoop et BigData sont devenus des synonymes. Mais Hadoop n'est pas simplement Hadoop. Au fil du temps, il a évolué en un grand groupe d'outils divers, chacun destiné à servir un but différent. Mais associés ensemble, ils vous donnent un boite à outils surpuissante. Cela dit, il faut être prudent lors du choix de ces outils car leur cas d'utilisation spécifique ne convient pas à tous. Ce qui fonctionne pour certains pourrait ne pas être aussi productif pour vous. ci dessous une brève introduction à des outils très utiles. 1- Hadoop: Hadoop est fondamentalement 2 outils, un système de fichiers distribué (HDFS) qui constitue la couche de stockage de Hadoop et un framework de calcul distribué (MapReduce) qui constitue la couche de traitement. Vous adopterez Hadoop si vos données sont énormes (en quantité). Hadoop n'est pas adapté pour les manipulations en temps réel. Vous configurez un cluster Hadoop sur un groupe de machines connectés ensemble sur un réseau (appelé cluster). Vous stockez alors d'énormes quantités de données dans l'outil HDFS et traitez ces données en écrivant des programmes MapReduce. Étant distribué, HDFS est réparti sur toutes les machines d'un cluster et MapReduce traite ces données dispersées localement en allant sur chaque machine, de sorte que vous n'avez pas à déplacer cette quantité gigantesque de données. 2- Hbase: Hbase est une grande banque de données répartie et évolutive, modélisée à partir de BigTable de Google. Il stocke les données sous forme de paires clé / valeur. C'est fondamentalement une base de données, une base de données NoSQL et comme toute autre base de données son plus grand avantage est qu'il vous fournit des capacités aléatoires de lecture / écriture. Hadoop n'est pas très bon pour vos besoins en temps réel, donc vous pouvez utiliser Hbase pour servir à cette fin de temps réel. Si vous avez des données auxquelles vous souhaitez accéder en temps réel, vous pouvez les stocker dans Hbase. Hbase possède son propre ensemble d'API qui peut être utilisé pour pousser / obtenir les données. Hbase peut être intégré de façon transparente avec MapReduce afin que vous puissiez faire des opérations en vrac, comme l'indexation, l'analyse, etc... Conseil: Vous pouvez utiliser Hadoop comme référentiel pour vos données statiques et Hbase comme datastore qui contiendra des données qui vont probablement changer avec le temps après un certain traitement (metadonnées). 3- Hive: Développé à l'origine par Facebook, Hive est essentiellement un entrepôt de data. Il se place au-dessus de votre cluster Hadoop et vous fournit une interface SQL. Vous pouvez ensuite écrire des requêtes SQL like en utilisant le langage de requête Hive, appelé HiveQL et exécuter des opérations comme store, select, join, et bien d'autres. Il rend le traitement beaucoup plus facile. Rédigez des requêtes Hive est simple et vous obtenez des résultats rapidement. Hive est très apprécié par les utilisateurs des SGBDR. Il suffit de mapper les fichiers HDFS dans les tables Hive et de commencer à interroger les données. Non seulement cela, vous pouvez également mapper les tables Hbase, et opérer sur ces données. Astuce: Utilisez Hive quand vous avez des besoins d'entreposage et vous connaissez le SQL et ne voulez pas écrire des programmes MapReduce. Un point important cependant, les requêtes Hive sont converties en un job MapReduce correspondant en arrière plan et qui s'exécute sur votre cluster 2/90 Tondeur Hervé(2018)
et vous donne le résultat. Mais tous les problèmes ne peuvent pas être résolus en utilisant HiveQL. Parfois, si vous avez besoin d'un traitement avec une fine granularité et un grande complexité, vous devrez peut-être réaliser ces travaux avec les API de MapReduce. 4- Pig: Pig est un langage de flux de données qui vous permet de traiter des quantités énormes de données très facilement et rapidement en la transformant de façon répétée par étapes. Il y a fondamentalement 2 parties, le PigInterpreter et la langue PigLatin. Pig a été initialement développé par Yahoo et ils l'utilisent largement. Comme Hive, les requêtes PigLatin sont également converties en un job MapReduce et vous donnent le résultat en retour. Vous pouvez utiliser Pig pour les données stockées à la fois dans HDFS et Hbase très commodément. Tout comme Hive, Pig est également très efficace dans ce qu'elle est censée faire. Il économise beaucoup de vos effort et de temps en vous permettant de ne pas écrire des programmes MapReduce et de faire l'opération grâce à de simples requêtes Pig. Astuce: Utilisez Pig lorsque vous voulez faire beaucoup de transformations sur vos données et ne veulent pas prendre la peine d'écrire des programmes MapReduce. 5- Sqoop: Sqoop est un outil qui vous permet de transférer des données entre les bases de données relationnelles et Hadoop. Il prend en charge les charges incrémentielles d'une table unique ou d'une requête SQL libre ainsi que des tâches enregistrées qui peuvent être exécutées plusieurs fois pour importer des mises à jour effectuées dans une base de données depuis la dernière importation. Les importations peuvent également être utilisées pour remplir des tables dans Hive ou HBase. Sqoop vous permet également d'exporter les données dans la base de données relationnelle du cluster. Astuce: Utilisez Sqoop lorsque vous avez beaucoup de données héritées et que vous souhaitez qu'elles soient stockées et traitées sur votre cluster Hadoop ou lorsque vous souhaitez ajouter progressivement les données à votre stockage existant. 6- Oozie: Maintenant, vous avez tout mis en place et voulez faire le traitement, mais il est inconcevable de commencer les travaux et de gérer le flux de travail manuellement tout le temps. Spécialement dans les cas où il est nécessaire de chaîner plusieurs jobs MapReduce ensemble pour atteindre un objectif. Vous souhaitez avoir un moyen d'automatiser tout cela. Pas de soucis, Oozie vient à la rescousse. Il s'agit d'un système de planification de workflow évolutif, fiable et extensible. Vous définissez simplement vos workflows une fois et le reste est pris en charge par Oozie. Vous pouvez planifier des travaux MapReduce, Pig jobs, Hive jobs, Sqoop imports et même vos programmes Java en utilisant Oozie. Astuce: Utilisez Oozie lorsque vous avez beaucoup de travaux à exécuter et que vous voulez un moyen efficace d'automatiser tout cela en les basant sur un certain temps (fréquence) et la disponibilité des données. 7- Flume / Chukwa: Flume et Chukwa sont des outils d'agrégation de données et vous permettent d'agréger les données d'une manière efficace, fiable et distribuée. Vous pouvez sélectionner des données à partir d'un endroit et les transférer dans votre grappe. Il est plus logique de le faire de manière distribuée et parallèle. Il vous suffit de définir vos flux et de les fournir à ces outils et le reste des choses sera fait automatiquement par eux. Astuce: Utilisez Flume / Chukwa lorsque vous devez regrouper d'énormes quantités de données dans votre environnement Hadoop de manière distribuée et parallèle. 3/90 Tondeur Hervé(2018)
8- Avro: Avro est un système de sérialisation de données. Il fournit des fonctionnalités similaires à des systèmes tels que protocol Buffers, Thrift etc. En plus de cela, il fournit quelques autres fonctionnalités importantes telles que des structures de données riches, un format de données compact, rapide, binaire, un fichier conteneur pour stocker des données persistantes, un mécanisme RPC et l'Intégration des langues dynamiques. Et la meilleure partie est que Avro peut facilement être utilisé avec MapReduce, Hive et Pig. Avro utilise JSON pour définir les types de données. Astuce: Utilisez Avro lorsque vous souhaitez sérialiser votre BigData avec une bonne flexibilité. 9- Thrift/Thrift2 : Le framework logiciels Apache Thrift et Thrift2, est utile pour le développement de services inter-langues évolutifs, il combine une pile logicielle avec un moteur de génération de code pour construire des services qui fonctionnent efficacement et en toute transparence entre C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, Cocoa, JavaScript, Node.js, Smalltalk, OCaml et Delphi et d'autres langues. 10- Ambari :Le projet Apache Ambari vise à rendre la gestion de Hadoop plus simple en développant des logiciels pour le provisionnement, la gestion et la surveillance des clusters Apache Hadoop. Ambari fournit une interface utilisateur intuitive et facile à utiliser de gestion Web Hadoop soutenue par ses API RESTful. Ambari permet aux administrateurs système de: - Fournir un cluster Hadoop. - Ambari fournit un assistant pas à pas pour installer des services Hadoop sur un nombre illimité d'hôtes. - Ambari gère la configuration des services Hadoop pour le cluster. - Gérer un cluster Hadoop. - Ambari fournit une gestion centrale pour démarrer, arrêter et reconfigurer les services Hadoop sur l'ensemble du cluster. - Surveiller un cluster Hadoop. - Ambari fournit un tableau de bord pour surveiller la santé et l'état du cluster Hadoop. - Ambari s'appuie sur le système Ambari Metrics pour la collecte de métriques. - Ambari exploite Ambari Alert Framework pour alerter le système et vous avertira quand votre attention est nécessaire (par exemple, un nœud descend, l'espace disque restant est faible, etc). Ambari permet aux développeurs d'applications et aux intégrateurs de systèmes d': - Intégrez facilement les fonctionnalités de gestion, de gestion et de suivi de Hadoop à leurs propres applications avec les API Ambari REST. 4/90 Tondeur Hervé(2018)
HBASE Introduction HBase est un système de gestion de base de données de type NoSQL (non relationnelle) basé sur le stockage en mode colonnes, et est hautement distribué car il repose sur Hadoop et son système de fichier HDFS, écrit en Java donc portable, HBase peut contenir plusieurs milliards d'enregistrements distribués sur plusieurs serveurs tout en ayant un temps de réponse performant. Basées sur une architecture maître/esclave, les bases de données de ce type sont capables de gérer d'énormes quantités d'informations. Hadoop (HDFS) pourra servir dans ce cas de conteneur de gros fichiers et Hbase comme référentiel documentaires. Hbase repose sur le principe des tables en mode colonnes et est inspirée des publications de Google sur BigTable. Clé Famille de colonne 1 Famille de colonne 2 Famille de colonne n RowId col1 col2 col3 col1 col2 col3 coln coln+1 coln+2 1 a c d h i o p q 2 b j k r s 3 e f g l m n t u HBase est un sous-projet d'Hadoop, un framework d'architecture distribuée. La base de données HBase s'installe généralement sur le système de fichiers HDFS d'Hadoop pour faciliter la distribution, même si ce n'est pas obligatoire et qu'on peut l'utiliser en StandAlone avec le système de fichier de votre OS. Caractéristiques de Hbase Hbase est linéairement extensible. Supporte de manière automatique les erreurs. Propose des lectures/écritures consistantes. S’intègre parfaitement avec Hadoop/HDFS. Propose des API java simples. Propose des réplications au travers des clusters. Quand utilisé Hbase ? Apache HBase est utilisé pour effectuer des lectures écritures a accès aléatoire sur le Big Data. Quand il est nécessaire d'avoir de très larges tables . Quand il est nécessaire de stocker énormément de données sans structures. Quand il est nécessaire de manipuler rapidement énormément de données et que la partie relationnelle des SGBDR n'est pas nécessaire a ces manipulations. 5/90 Tondeur Hervé(2018)

Installation de Hbase en mode StandAlone
Prérequis :
Il faut que vous ayez un JDK 8 ou JRE 8 java installé sur votre machine et que la variable
JAVA_HOME soit correctement renseignée (conseillé).
Pour contrôler cette variable JAVA_HOME
$>echo $JAVA_HOME
Pour contrôler la version de votre JDK ou JRE
$>java -version
En cas de mauvaise installation, vous pouvez vous reporter à cette adresse pour obtenir la
procédure d'installation du JDK et le paramétrage de la variable JAVA_HOME.
http://docs.oracle.com/javase/8/docs/technotes/guides/install/linux_jdk.html
Vous pouvez également suivre la procédure (simplifiée) suivante :
0) Verifiez votre type d'OS avec la commande uname :
$> uname -a
Linux lmdeherve 3.16.0-4-amd64 #1 SMP Debian 3.16.36-1+deb8u2 (2016-10-19) x86_64 GNU/Linux
1) Télécharger le JDK 8 pour Linux (32 ou 64 bits selon votre OS)
http://download.oracle.com/otn-pub/java/jdk/8u112-b15/jdk-8u112-linux-i586.tar.gz
2) Décompressez la package avec la commande :
$> tar -xvf jdk-8u112-linux-i586.tar.gz
3) déplacez le package décompressé vers le home directory :
$> mv jdk1.8.0_112 ~/jdk8
4) Éditez le fichier ~/.bashrc et ajoutez les lignes suivantes (en ligne 1) :
export set JAVA_HOME=~/jdk8
export set PATH=$PATH:$JAVA_HOME/bin
5) Relancer votre terminal, testez les variables JAVA_HOME et PATH.
$> echo $JAVA_HOME
$> echo $PATH
Téléchargement du package Hbase
Il faut télécharger le package d'installation à l'adresse suivante :
https://hbase.apache.org/
A la date d'écriture de ce document c'est la version 1.2.4 qui est active et c'est donc cette version
6/90 Tondeur Hervé(2018)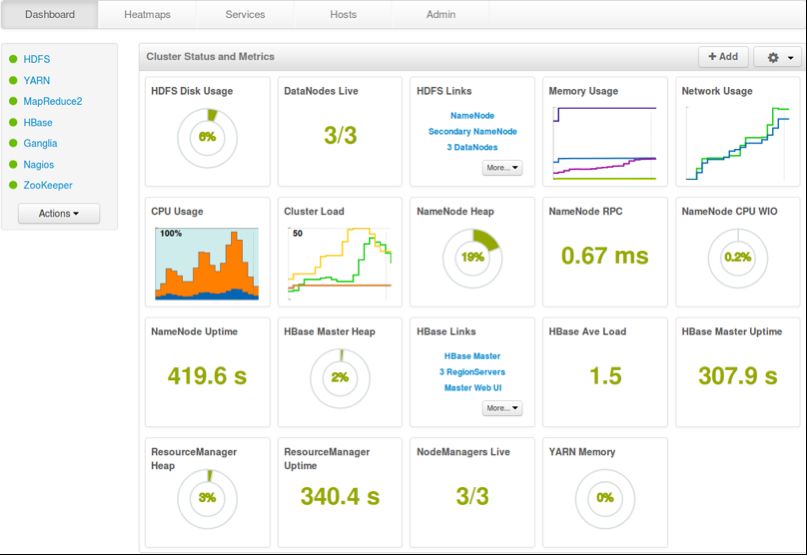
de Hbase que nous allons manipuler.
Le téléchargement peut se réaliser sur ce miroir, bien sur il est possible de le télécharger sur un autre
miroir du site apache
http://apache.crihan.fr/dist/hbase/
Télécharger le fichier : hbase-1.2.6-bin.tar.gz
Ce fichier fait environ 100Mo
En ligne de commande Shell, cela peut se réaliser avec la commande « wget », placer vous dans
votre dossier de réception et lancez la commande :
$>wget http://apache.crihan.fr/dist/hbase/stable/hbase-1.2. 6-bin.tar.gz
En attendant vous pouvez commencer à consulter la documentation de HBase à l'adresse
7/90 Tondeur Hervé(2018)
suivante :
http://hbase.apache.org/book.html
Décompacter le fichier vers un dossier hbase-x.x.x avec la commande ci dessous...
$>tar -xvf hbase-1.2.6-bin.tar.gz
Vous obtenez un dossier hbase-1.2.6 dans votre dossier local.
Si cela vous semble nécessaire, vous pouvez le déplacer vers un autre emplacement, à la racine de
votre home directory par exemple et le renommer en hbase...
$> mv hbase-1.2.6 ~/
$> cd ~
$> mv hbase-1.2.6 hbase
On reste dans l’hypothèse que vous avez déplacer et renommé le nom du dossier et que celui se
trouve dans votre home directory, on désignera par la variable ${HBASE_HOME} le dossier
d'installation de base de l'application Hbase.
${HBASE_HOME}=~/hbase
$>cd ~/hbase
$>ls -l
Affichera la structure du dossier hbase...
Description rapide du dossier hbase
On trouve les dossiers :
- bin/ qui contient les scripts d’exécution des différent daemon et outils pour hbase (pour le Shell et
Batch DOS).
- conf/ qui contient l'ensemble des fichiers de configuration de hbase.
- docs/ l'ensemble de la documentation (doc hbase et api java).
- hbase-webapps/ contient les sources des interfaces web de hbase.
- lib/ contient tous les package jar utile pour hbase, c'est le cœur de l'application hbase.
Paramétrer Hbase en mode StandAlone
Le mode StandAlone est la manière la plus simple de faire fonctionner Hbase, ce mode rend Hbase
non distribué, donc on est limité par l'espace disque de notre machine et on utilise le système de
fichier de notre machine pour stocker les informations et non HDFS (Hadoop voir mode Pseudo-
distributed et Full Distributed plus loin dans ce document).
Nous allons ici utiliser le dossier ~/tmp de votre home directory pour stocker les données Hbase et
8/90 Tondeur Hervé(2018)
Zookeeper
Vérifier que ce dossier existe bien sur votre machine Linux avec la commande :
$> ls ~/tmp
Il faut ensuite éditer le fichier ${HBASE_HOME}/conf/hbase-site.xml et ajouter la configuration
suivante :
(Adaptez vos chemins par rapport à votre home directory!)
hbase.rootdir
file:///home/herve/tmp/hbase
hbase.zookeeper.property.dataDir
/home/herve/tmp/zookeeper
La propriété « hbase.rootdir » attend une url de destination de stockage des données Hbase, ici on
utilise le système de fichier local, on passe donc une url de type file:// et on fait pointer notre url
vers le dossier ~/tmp/hbase.
De même la propriété « hbase.zookeeper.property.dataDir » attend le chemin de stockage des
fichiers de maintient de la configuration zookeeper (ici c'est un chemin local à la machine et non
une url qui est attendu).
Vous pouvez également de manière optionnelle, modifier le fichier «$
{HOME_HBASE}/conf/hbase-env.sh », en ajoutant la ligne suivante :
export JAVA_HOME=/home/herve/bin/jdk8
Si et seulement si votre variable JAVA_HOME n'est pas configuré (sinon cela n'est pas nécessaire).
Lancer Hbase en mode StandAlone
Pour lancer Hbase, il faut se rendre dans le dossier ${HBASE_HOME}/bin et lancer la commande :
$>./start_hbase.sh
Seul un message simple s'affiche pour indiquer que le daemon Hmaster est démarré et ou se
trouvent les fichiers logs.
Nb : avec Java 8 vous aurez aussi quelques autres messages pour vous prévenir que certains
paramètres de la ligne de commande ne sont plus pris en charge (peut importe, la JVM 8 sait gérer
le Heap et il est possible de désactiver cela dans le fichier hbase-env.sh).
starting master, logging to /home/herve/hbase/bin/../logs/hbase-herve-master-lmdeherve.out
les commandes suivantes vous permettrons de vérifier que l'application Hbase est bien démarré :
$>ps -ef | grep hbase
$>ps -ef | grep Hmaster
9/90 Tondeur Hervé(2018)
Vous pouvez également utiliser la commande « jps », celle ci appartient au JDK et se trouve dans le
dossier « bin » de celui ci.
Cette commande permet de lister les processus Java en cours.
Vous pouvez également surveiller ces processus avec la commande « jvisualvm ».
VisualVM est un outil visuel intégrant des outils JDK de ligne de commande et des fonctionnalités
de profilage léger. Conçu pour le développement et la production.
Exemple de profilage du processus Hmaster.
Ce profiler vous permet surtout de surveiller la consommation de cpu et de mémoire pour chacun
des processus Java en jeu et vous permettre dans un domaine de production d'équilibrer les charges
ou prévoir les upgrades nécessaires en termes de matériel.
Stopper Hbase
Pour arrêter Hbase, il faut se rendre dans le dossier ${HBASE_HOME}/bin et lancer la
10/90 Tondeur Hervé(2018)commande :
$>./stop_hbase.sh
Pour vous entraîner: Installez Hbase et démarrez une instance Hbase en mode StandAlone
sur votre machine Linux. Ecrire un Script Shell qui permet de démarrer une instance Hbase
et de lancer le Shell automatique aprés le démarrage de l'instance.
Structures de stockage du dossier Hbase
rendez vous dans le dossier ~/tmp/hbase
$>cd ~/tmp/hbase
vous pourrez naviguer dans les différents dossier de la structures de stockage de Hbase.
Présentation et utilisation de la console Shell pour Hbase
La base de données Hbase est fournie avec un Shell développé en RUBY et qui permet de
communiquer avec le moteur NoSQL, c'est une première approche, la moins conviviale pour utiliser
Hbase, mais qui permet de manipuler toutes les commandes disponibles de ce moteur NoSQL et
très utile pour les administrateurs.
On va pour cela utiliser l'application ${HBASE_HOME}/bin/hbase, cette application possède plusieurs
options.
Usage: hbase [] []
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
--auth-as-server Authenticate to ZooKeeper using servers configuration
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
snapshot Create a new snapshot of a table
snapshotinfo Tool for dumping snapshot information
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
version Print the version
CLASSNAME Run the class named CLASSNAME
Pour lancer un Shell il faut se rendre dans le dossier bin de l'application HBase et lancer le script
hbase avec l'option Shell.
11/90 Tondeur Hervé(2018)$>cd ${HBASE_HOME}/bin
$>./hbase shell
Vous obtenez un Shell comme celui ci dessus, nous sommes maintenant dans le Shell de travail de
Hbase et toutes les commandes que nous utiliserons seront interprétées directement par Hbase.
Pour connaître toutes les commandes possibles, il suffit de taper la commande « help » dans ce
Shell, vous obtenez toutes la liste des commandes disponibles.
HBase Shell, version 1.2.6, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table,
is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch,
close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch,
split, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication,
list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quotas, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
12/90 Tondeur Hervé(2018)command parameters. Type after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
Ci dessus l'aide mise en couleur, on remarquera que les commandes sont regroupés en « Groupe de
commandes », et que ces commandes ressembles un peu aux ordres SQL que l'on connaît, mais
attention ce n'est pas du SQL et hormis la ressemblance, l'usage en est pas du tout le même.
Pour vous entraîner: Démarrer un Shell Hbase sur votre machine Linux et tester les
commandes générales status, help, version et whoami. Ecrire un script en Shell qui permet de
démarrer le Shell Hbase, de lui passer des commandes qui se trouve dans un fichier texte et
quitter le Shell Hbase.
On va ici essentiellement s'intéresser aux groupes de commandes « general », « dml », « ddl »,
« namespace ».
Nous allons créer une base qui va gérer des patients d'un « hôpital », on va pour cela de manière
simpliste gérer une table d' « identité » comportant éventuellement (Numéro SS, nom, prénom, nom
marital, ddn, Adresse, cp, ville, tel, commentaire, etc.).
Il faut se rappeler que Hbase est un système de gestion en mode colonnes, et que pour cette raison
chaque table est contenu dans un espace de nom et que chaque table contient des familles de
colonnes et chaque famille de colonnes contient des données…
Pour vous entrainer: Ecrire un Script Shell Linux qui va permettre de regrouper toutes les
commandes de création d’espace de nom, de création de tables, des éléments des tables, et
autres commandes que vous allez rencontrez ci dessous.
Quelques commandes d'administrations pour débuter :
La commande Shell « version » permet d'afficher la version de votre Hbase.
hbase(main):003:0> version
1.2.2, r3f671c1ead70d249ea4598f1bbcc5151322b3a13, Fri Jul 1 08:28:55 CDT 2016
La commande Shell « whoami » permet de connaître votre appartenance aux groupes, votre nom
d'utilisateur et votre type d'authrntification.
hbase(main):003:0> whoami
herve (auth:SIMPLE)
groups: herve, adm, dialout, fax, cdrom, floppy, tape, sudo, audio, dip, video, plugdev, users, netdev,
lpadmin, scanner, sambashare, bluetooth
13/90 Tondeur Hervé(2018)La commande Shell « status » qui peut prendre des options comme 'simple', 'summary', «'detailed' et permet d'afficher l'état de votre système Hbase. hbase(main):013:0> status 'summary' 1 active master, 0 backup masters, 1 servers, 0 dead, 5.0000 average load Gestion des snapshots Hbase : HBase Snapshots vous permet de prendre un instantané d'une table sans trop d'impact sur les serveurs régionaux. Les opérations d'instantané, de clonage et de restauration n'impliquent pas de copie de données. En outre, l'exportation de l'instantané vers un autre cluster n'a pas d'impact sur les serveurs régionaux. La commande « snapshot » permet de créer une image instantanée d'une table hbase(main):020:0> snapshot 'ARNUM:DOC', 'DOCSnap1' 0 row(s) in 0.8430 seconds La commande « list_snapshots » permet de lister les snapshots existants. hbase(main):021:0> list_snapshots SNAPSHOT TABLE + CREATION TIME DOCSnap1 ARNUM:DOC (Wed Mar 01 20:23:07 +0100 2017) shorterSnapShot SHORTER:URL (Tue Feb 21 21:43:26 +0100 2017) 2 row(s) in 0.0230 seconds La commande « clone_snapshot » crée une nouvelle table en clonant le contenu de l'instantané. Il n'y a aucune copie des données concernées. Et l'écriture sur la table nouvellement créée n'influencera pas les données de d’instantanées. hbase(main):024:0> clone_snapshot 'DOCSnap1', 'ARNUM:DOC2' 0 row(s) in 0.9240 seconds hbase(main):026:0> list TABLE ARNUM:DOC ARNUM:DOC2 HOPITAL:identite SHORTER:URL 4 row(s) in 0.0070 seconds => ["ARNUM:DOC", "ARNUM:DOC2", "HOPITAL:identite", "SHORTER:URL"] Les commandes « delete_snapshot », « delete_all_snapshot » permettent de supprimer un snapshot désigné ou tous les snapshots existant, pour cette dernière commande vous pouvez passer un regex permettant de filter les noms de snapshots a supprimer. La commande « restore_snapshot », restaurer un instantané spécifié. La restauration remplacera le contenu de la table d'origine, en ramenant le contenu à l'état d'instantané. (!) La table doit être désactivée. hbase(main):030:0> disable 'ARNUM:DOC' 0 row(s) in 2.5350 seconds hbase(main):031:0> restore_snapshot 'DOCSnap1' 0 row(s) in 1.6840 seconds 14/90 Tondeur Hervé(2018)
Dans le cas de notre gestion de patients :
Espace de Nom
Table 1 Table X
Famille 1 Famille 2
Créer et gérer un espace de nom
Par défaut il existe un espace de nom dans Hbase qui se nomme « default » et que l'on peu omettre
dans les chemins d’accès aux données.
Nb : il existe également un NameSpace qui se nomme « hbase » celui ci comme pour les SGBDR,
contient les méta données des objets Hbase (on peut assimiler cela aux tables systèmes des
SGBDR).
Pour notre petit projet, nous allons créer un espace de projet pour cloisonner correctement nos
tables dans un espace de nom qui se nommera « HOPITAL ».
hbase(main):005:0>create_namespace 'HOPITAL'
cette commande ci dessus permet de créer notre espace de nom avec la configuration par défaut
(c'est très souvent le cas), il est possible de vérifier que notre espace de nom est bien créé en le
demandant a Hbase.
hbase(main):007:0> list_namespace
NAMESPACE
HOPITAL
default
hbase
2 row(s) in 0.0810 seconds
ou
hbase(main):013:0> describe_namespace 'HOPITAL'
DESCRIPTION
{NAME => 'HOPITAL'}
1 row(s) in 0.0120 seconds
Il est possible de créer un espace de nom qui comportera des propriétés (qui permettrons soit de
modifier la configuration de base [dans ce cas elle commencerons par hbase.xxxx.yyyy], soit servir
de tags informatives), ces propriétés pourront être consulté lors de la demande de description de
votre NameSpace avec la commande 'describe_namespace', et également via les API Java
d'exploitation de Hbase.
15/90 Tondeur Hervé(2018)hbase(main):013:0> create_namespace 'GEDMED', {'level'=>'PROD', 'owner'=>'Herve Tondeur',
'version'=>'1.0'}
Il est possible également de supprimer un espace de nom vide (drop_namespace), de modifier le
nom d'un espace de nom (alter_namespace) et lister les tables appartenant à une espace de nom
(list_namespace_tables).
Modification des propriétés d'un espace de nom :
hbase(main):013:0> alter_namespace 'GEDMED', {METHOD=>'set', 'subversion'=>'b0115'}
hbase(main):014:0> alter_namespace 'GEDMED', {METHOD=>'unset', NAME=>'owner'}
hbase(main):015:0> describe_namespace 'GEDMED'
DESCRIPTION
{NAME => 'GEDMED', level => 'PROD', subversion => 'b0115', version => '1.0'}
On à ici ajouté une propriété à l'espace de nom 'subversion' et on supprime la propriété 'owner' de
notre espace de nom.
Suppression d'un espace de nom :
hbase(main):017:0> drop_namespace 'GEDMED'
Attention on ne peut supprimer un espace de nom que s'il est vide (plus de tables).
Créer et gérer une table
On va créer notre table « identite », qui comportera des familles de colonnes, ici pour notre petit
projet on va créer quatre familles de colonnes « social », « coordonnees », « professionnel »,
« autre ».
Il est fortement recommandé de ne pas mettre de nom long pour les noms de familles, et l'équipe
Hbase recommande même d'utiliser un caractère uniquement, ici dans notre projet nous n'allons pas
respecter cette consigne pour les besoin de la démonstration, mais en production il faudra respecter
cette consigne.
hbase(main):004:0> create 'HOPITAL:identite','social','coordonnees','professionnel','autre'
0 row(s) in 1.3020 seconds
=> Hbase::Table – HOPITAL:identite
Il est possible lors de la création d'un table d'y modifier un certains nombres de METADATA,
comme OWNER, SPLIT, VERSION, TTL, etc. Ces METADATA contrôles le comportement de
votre table, il est recommandé de ne pas trop y toucher si vous ne savez pas à quoi cela sert.
hbase(main):004:0>create 'HOPITAL:identite', {NAME => 'social', VERSIONS => 1, TTL => 2592000,
BLOCKCACHE => true}
On peut obtenir pour contrôle une description de la table que l'on vient de créer avec la commande
« describe 'NOMTABLE' »
hbase(main):005:0> describe 'HOPITAL:identite'
Table HOPITAL:identite is ENABLED
HOPITAL:identite
COLUMN FAMILIES DESCRIPTION
16/90 Tondeur Hervé(2018){NAME => 'autre', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '0'}
{NAME => 'coordonnees', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '0'}
{NAME => 'professionnel', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '0'}
{NAME => 'social', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '0'}
4 row(s) in 0.1250 seconds
Lister les tables de l'espace de nom 'HOPITAL'
hbase(main):009:0> list_namespace_tables 'HOPITAL'
TABLE
identite
1 row(s) in 0.0250 seconds
Gestion de la structure d'une tableaux
Il est possible de modifier la structure d'une table en :
- Supprimant une famille de colonnes
hbase(main):009:0> alter 'HOPITAL:identite',{METHOD=>'delete',NAME=>'autres'}
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 3.5250 seconds
- Ajoutant une famille de colonnes
hbase(main):007:0> alter 'HOPITAL:identite','autres'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 3.8100 seconds
Tester l’existence d'une table
hbase(main):017:0> exists 'HOPITAL:identite'
Table HOPITAL:identite does exist
0 row(s) in 0.0240 seconds
Activer ou Désactiver une table ou des tables
17/90 Tondeur Hervé(2018)hbase(main):021:0> disable 'HOPITAL:identite'
0 row(s) in 4.4560 seconds
Une table désactivée n'est plus accessible en lecture et écriture, mais peut être supprimé avec la
méthode DROP, il est possible également d'utiliser la commande disable_all 'ns:t.*' avec une
expression regex pour rendre « disable » plusieurs tables.
hbase(main):022:0> enable 'HOPITAL:identite'
0 row(s) in 4.4560 seconds
Une table activée est accessible en lecture et écriture, mais ne peut pas être supprimé avec la
méthode DROP, il est possible également d'utiliser la commande enable_all 'ns:t.*' avec une
expression regex pour rendre « enable » plusieurs tables.
Il est possible de tester l'état d'une table avec les commandes is_disable et is_enable, ces fonctions
retournent un booleen (true/fasle).
hbase(main):027:0> is_disabled 'HOPITAL:identite'
true
0 row(s) in 0.0160 seconds
hbase(main):028:0> is_enabled 'HOPITAL:identite'
false
0 row(s) in 0.0140 seconds
Représentation des données et insertion de données
Les données dans une famille de colonne est représenté par un paire {clé:Valeurs}, une clé doit être
unique pour une famille de colonne.
Exemples :
Social coordonnees
{1234:nom=tondeur,prenom=herve} {1234:adresse=UVHC}
{2345:nom=Dean,prenom=james} {2345:ville=NewYork}
{3456:nom=Dervy,prenom=jimmy,nommar=Dean} {3456:tel=0102030405}
On va utiliser la commande « PUT » pour insérer ces données…
hbase(main):002:0> put 'HOPITAL:identite','1234','social:nom','TONDEUR'
0 row(s) in 1.0440 seconds
hbase(main):003:0> put 'HOPITAL:identite','1234','social:prenom','HERVE'
0 row(s) in 0.0080 seconds
hbase(main):004:0> put 'HOPITAL:identite','1234','social:ddn','01/01/1969'
0 row(s) in 0.0050 seconds
18/90 Tondeur Hervé(2018)hbase(main):005:0> put 'HOPITAL:identite','1234','coordonnees:adresse','UVHC'
0 row(s) in 0.0190 seconds
Les lignes ci dessus permettent d’insérer les données du patients dont la clé est '1234' dans la table
'identite' de l'espace de nom 'HOPITAL' et pour les trois premières lignes on insère le
(nom,prenom,ddn) dans la famille de colonne 'social' et pour la dernière ligne on insère l'adresse
dans la famille de colonne 'coordonnees'.
Lister les données d'une table
la commande « SCAN » permet de lister toutes les éléments d'une table.
base(main):010:0> scan 'HOPITAL:identite'
ROW COLUMN+CELL
1234 column=coordonnees:adresse, timestamp=1481889565735, value=UVHC
1234 column=social:ddn, timestamp=1481889483410, value=01/01/1969
1234 column=social:nom, timestamp=1481889426355, value=TONDEUR
1234 column=social:prenom, timestamp=1481889437486, value=HERVE
1 row(s) in 0.0470 seconds
quand il y a beaucoup de ligne, il est possible d'obtenir un groupe d'éléments particulier (il faut
connaître sa clé) et utiliser la commande « GET » .
hbase(main):012:0> get 'HOPITAL:identite', '1234'
COLUMN CELL
coordonnees:adresse timestamp=1481889565735, value=UVHC
social:ddn timestamp=1481889483410, value=01/01/1969
social:nom timestamp=1481889426355, value=TONDEUR
social:prenom timestamp=1481889437486, value=HERVE
4 row(s) in 0.0940 seconds
Notion de filtrage avec la commande SCAN :
#!/bin/bash
cat '0002',
COLUMNS=>'social:nom'}
scan 'HOPITAL:identite', {FILTER=>"RowFilter(>=, 'binary:0001') AND RowFilter(Le deuxième fait exactement pareil, mais avec un filtre. Le troisième scan affiche les valeurs social:nom de toutes les lignes. Le quatrième scan cherche les colonnes dont la valeur vaut le nom indiqué. Le cinquième affiche les n-uplets dont la (dernière version de la) colonne professionnel:salaire est inférieure ou égale à 1990. Le dernier filtre est plus complexe, il cherche les n-uplets dont la clé commence par “000” et dont l’une des valeurs correspond à l’expression régulière, à vous de vous souvenir comment on les écrit. La liste des jokers est sur cette page. • Notez que tous ces « scans » retournent à chaque fois le n-uplet complet, toutes ses colonnes, puisqu’on ne les a pas limitées avec COLUMNS. • Attention à bien orthographier les champs, sinon tous les n-uplets sont sélectionnés. • Ne pas mélanger une condition type FILTER avec une condition COLUMNS, ça ne marche pas du tout. • Ne pas oublier binary: ou binaryprefix : ou substring : devant les constantes à comparer. Les filtres possibles DependentColumnFilter KeyOnlyFilter ColumnCountGetFilter SingleColumnValueFilter PrefixFilter SingleColumnValueExcludeFilter FirstKeyOnlyFilter ColumnRangeFilter TimestampsFilter FamilyFilter QualifierFilter ColumnPrefixFilter RowFilter MultipleColumnPrefixFilter InclusiveStopFilter PageFilter ValueFilter ColumnPaginationFilter Ou un élément unique (une cellule) : hbase(main):013:0> get 'HOPITAL:identite', '1234', 'social:nom' COLUMN CELL social:nom timestamp=1481889426355, value=TONDEUR 1 row(s) in 0.0950 seconds hbase(main):014:0> get 'HOPITAL:identite', '1234', 'social:nom','coordonnees:adresse' COLUMN CELL coordonnees:adresse timestamp=1481889565735, value=UVHC social:nom timestamp=1481889426355, value=TONDEUR 2 row(s) in 0.0130 seconds hbase(main):015:0> get 'HOPITAL:identite', '1234', 'social:nom','coordonnees:adresse','professionnel:job' 20/90 Tondeur Hervé(2018)
COLUMN CELL
coordonnees:adresse timestamp=1481889565735, value=UVHC
social:nom timestamp=1481889426355, value=TONDEUR
Dans le premier exemple on demande uniquement l'objet nom de la famille de colonne 'social' de la
table 'HOPITAL:identite'.
Dans le second exemple on demande les objets nom de la famille de colonne 'social' et adresse de la
famille de colonne 'coordonnees' de la table 'HOPITAL:identite'.
Dans le troisième exemple on demande les objets nom de la famille de colonne 'social' et adresse de
la famille de colonne 'coordonnees' et job de la famille de colonne 'professionnel' de la table
'HOPITAL:identite', on remarquera ici le fait que l'objet 'professionnel:job' n'existe pas et pourtant
cela ne pose pas de problème a HBase pour réponse, il ne retourne rien pour cette information
inexistante.
Par contre si vous essayer de retourner un élément d'une colonne de famille en indiquant un nom de
famille de colonne inexistant, alors HBase retourne une erreur.
hbase(main):017:0> get 'HOPITAL:identite', '1234', 'social:nom','coordonnees:adresse','toto:job'
COLUMN CELL
ERROR: org.apache.hadoop.hbase.regionserver.NoSuchColumnFamilyException: Column family toto does not exist in region
HOPITAL:identite,,1481884010419.4b116fcccf7d30583229c5d66665a851. in table 'HOPITAL:identite', {NAME => 'autre',
BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE =>
'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}, {NAME => 'coordonnees', BLOOMFILTER => 'ROW', VERSIONS => '1',
IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'},
{NAME => 'professionnel', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE =>
'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}, {NAME => 'social', BLOOMFILTER => 'ROW', VERSIONS => '1',
IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
at org.apache.hadoop.hbase.regionserver.HRegion.checkFamily(HRegion.java:7752)
at org.apache.hadoop.hbase.regionserver.HRegion.get(HRegion.java:6800)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.get(RSRpcServices.java:2032)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:33644)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2180)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
at java.lang.Thread.run(Thread.java:745)
Dans l'état ce Shell est pratique pour apprendre à utiliser Hbase, a faire quelques manipulations sur
les structures des espaces de noms, des tables, le contenu des tables, de l’administration en général,
mais ne répond en aucun cas à un espace de travail quotidien permettant de manipuler les données,
pour cela on développera des interfaces graphiques en Java, Python, ou autres langage qui
permettrons de proposer une interface graphique entre l'utilisateur et cette base de données NoSQL,
on pourra également travailler avec des interfaces Web développé en JEE, qui pourront utiliser
directement les API Java proposées par Hbase, ou utiliser des Web Services REST, d'autres modes
de dialogues existent également pour Hbase, la langage Avro, Thrift ou Thrift2, en sachant que
Thrift, Thrift2 et REST sont implémentés en natif dans Hbase et nécessitent simplement une
activation via une commande Hbase.
Manipuler les données
21/90 Tondeur Hervé(2018)compter le nombres de ligne
Il est possible de compter les lignes d'une tables (nombre de clé différentes) avec la commande
COUNT qui s'utilise de la manière suivante
hbase(main):007:0> count 'HOPITAL:identite'
2 row(s) in 0.3090 seconds
=> 2
Supprimer des données
Il est possible de supprimer un élément particulier d'une table ou une ligne complète d'une table en
utilisant respectivement les commandes DELETE table, ligne, colonne et DELETEALL table, ligne.
hbase(main):011:0> delete 'HOPITAL:identite', '2345', 'professionnel:salaire'
0 row(s) in 0.0750 seconds
hbase(main):013:0> deleteall 'HOPITAL:identite', '2345'
0 row(s) in 0.0080 seconds
La commande truncate, permet de vider une table en réalisant les étapes suivante (disable, drop,
create)
hbase(main):038:0> truncate 'ARNUM:DOC2'
Truncating 'ARNUM:DOC2' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 6.5630 seconds
A connaître :
dans votre Shell Linux vous pouvez demander l'aide sur la syntaxe de commande du Shell Hbase
$> ./hbase shell -h
Usage: shell [OPTIONS] [SCRIPTFILE [ARGUMENTS]]
--format=OPTION Formatter for outputting results.
Valid options are: console, html.
(Default: console)
-d | --debug Set DEBUG log levels.
-h | --help This help.
-n | --noninteractive Do not run within an IRB session
and exit with non-zero status on
first error.
Deux options sont remarquable, la première est qu'il est possible de passer en mode debug et
d'obtenir beaucoup d'information lors de l’exécution du Shell et de vos commandes Hbase, c'est très
verbeux et très riche pour en faire une explication exhaustive dans ce document.
La seconde option est de pouvoir passer en paramètre à notre Shell un script contenant des
commandes Hbase, il est possible d'utiliser en plus l'option -n pour lancer ce script en mode non
interactive.
Soit le script monScript.hb contenant les commandes :
22/90 Tondeur Hervé(2018)list
exit
$> ./hbase shell -n monScript.hb
TABLE
HOPITAL:identite
1 row(s) in 0.2370 seconds
Ce qui permet de proposer le script Shell suivant par exemple pour contrôler le statut de sortie de
notre script HBase :
#!/bin/bash
./hbase shell -n $1 2>/dev/null
status=$?
echo "Le statut de retour est " $status
if [ $status -eq 0 ]
then
echo "La commande a réussie"
else
echo "La commande a échouée."
fi
exit $tatus
Autre manière d'appeler des commandes Hbase par un script Shell :
Soit le script monScript.sh contenant les commandes :
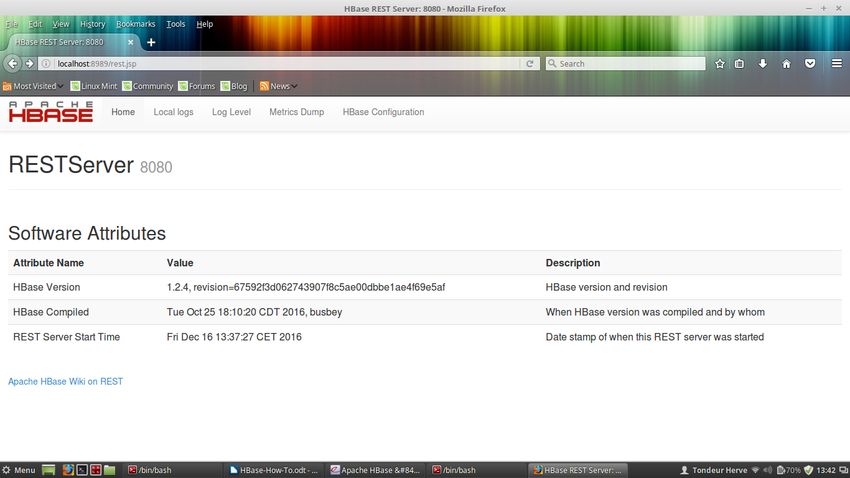
cat CMD./hbase rest start --infoport 8989 –port 8080
Cette commande permet d'activer les services Web de type REST sur le port 8080 et l'interface
graphique de ces services sur le port 8989.
23/90 Tondeur Hervé(2018)Une fois activé vous devez pouvoir accéder à l'interface graphique avec l'adresse
http://localhost:8989
Vous obtenez normalement la page web ci dessus qui vous donnes des informations sur les web
services et la configuration de HBase.
Les exemples ci dessous prennent en compte l'URL de démarrage des web services sur le localhost
et le port 8080 http://localhost:8080, pour pouvez utiliser les commandes curl ou wget pour
interroger ces web services. Vous pouvez demander du texte brut (par défaut), XML , or JSON en
sortie en ajoutant dans l'entête http rien pour du texte brut, ou "Accept: text/xml" pour XML,
"Accept: application/json" pour JSON, ou "Accept: application/x-protobuf" pour le protocole
protobuf.
Gestion globale
Verbe
services Description Exemple
HTTP
curl -vi -X GET \
Version de HBase
/version/cluster GET -H "Accept: text/xml" \
exécité sur ce cluster
"http://localhost:8080/version/cluster"
curl -vi -X GET \
/status/cluster GET Statut du Cluster -H "Accept: text/xml" \
"http://localhost:8080/status/cluster"
curl -vi -X GET \
Liste de toutes les tables
/ GET -H "Accept: text/xml" \
non-système
"http://localhost:8080/"
Gestion des espaces de noms
24/90 Tondeur Hervé(2018)Vous pouvez aussi lire

















































