Un aperçu de alpha Go - M1 Informatique 2018-2019 Intelligence Artificielle Stéphane Airiau - LAMSADE
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Un aperçu de alpha Go
M1 Informatique 2018–2019 Intelligence Artificielle
Stéphane Airiau
LAMSADE
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 1
Motivation et But de cette leçon
L’intelligence artificielle est médiatisé - en particulier sur les
résultats sur des jeux comme Go et Poker
Même si on n’entrera pas dans les détails, le but est de montrer que
vous connaissez (la plupart) des techniques de base utilisées dans
alpha-Go
ë vous montrez que vous pouvez comprendre en gros le
fonctionnement de alpha go.
David Silver et al
Mastering the game of Go without human knowledge
Nature. Vol 550, pp 354–359, 2017
Slides de David Silver IJCAI 2016
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 2
Go in numbers
3,000 40M 10^170
Years Old Players Positions
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 3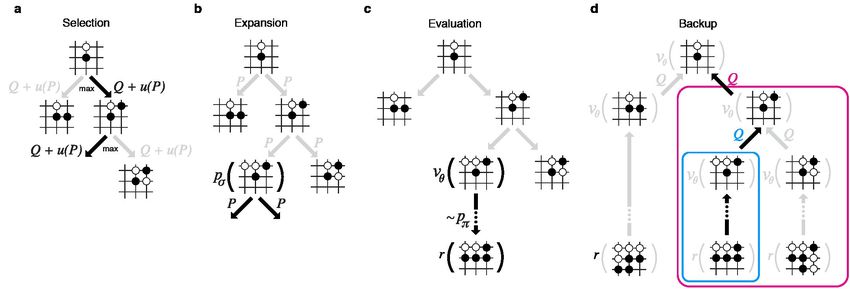
Why is Go hard for computers to play?
Brute force search intractable:
1. Search space is huge
2. “Impossible” for computers
to evaluate who is winning
Game tree complexity = bd
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 4
Octobre 2015 : alphaGo Fan : bat le champion européen
deux réseaux de neurones
un pour donner la probabilité de chaque action
(utilisation d’apprentissage supervisé avec connaissance d’expert, puis
amélioration policy gradient RL)
l’autre pour évaluer la qualité de l’état
prédit la valeur d’un état basé sur des parties contre l’algorithme
lui-même
Utilisation de MCTS avec ces deux réseaux
on se concentre sur les actions avec les plus hautes probabilités
utilisation du second réseau pour évaluer l’état
Mars 2016 : même technique mais plus d’apprentissage
AlphaGo Lee bat le Lee Sedol, vainqueur de 18 tournois
internationaux.
Octobre 2017 : AlphaGo Zéro : gagne contre AlphaGo Lee sans avoir
recours à des connaissances humaines
simplement en jouant contre lui-même !
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 5
Les ingrédients
un réseau de neurones ë cours 8 et 9
une variante d’un algorithme MCTS (Monte Carlo Tree Search) ë
cours 6
apprentissage par renforcement ë cours M2 IASD
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 6Monte-Carlo rollouts M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 7
Un type d’apprentissage : apprentissage par renforcement
apprentissage supervisé :
les données contiennent des observations dont la réponse
pour les arbres de décision une classification
pour les réseaux de neurones on nous donne la valeur de la fonction
objective
apprentissage non-supervisé
On nous donne des données, on cherche à trouver des similitudes
ex : clustering
apprentissage par renforcement on donne un signal dont l’intensité
indique si on agit bien ou non
encouragement, on veut refaire !
punition, on a fait quelque chose de mal, et se doit de changer quelque
chose
la récompense n’est pas donnée de manière instantanée (délais)//
ë peut être il est difficile de savoir exactement ce qu’on a bien fait !)
ë en accumulant de l’expérience, on va apprendre à modifier le
comportement pour optimiser a récompense
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 8Exemples d’application
On peut utiliser l’apprentissage par renforcement pour résoudre des pro-
blèmes ou l’objectif est d’optimiser une fonction cumulative.
optimisation dans des usines, régulation du traffic aérien
(simulations)
ordonnancement (ex : quel taxi choisir pour une course)
jouer à des jeux (ex. les vieux jeux Atari, mieux que les meilleurs
humains)
faire marcher un robot humanoid
jeux
en 1995 Tesauro (IBM Watson) à utilisé l’apprentissage par
renforcement pour son programme TD-Gammon qui joue au
backgammon au niveau des meilleurs mondiaux
avec les réseaux de neurones, l’apprentissage par renforcement est
utilisé par AlphaGo pour jouer au jeu de Go et gagner contre le
meilleur joueur humain
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 9Apprentissage par renforcement
Etat du monde st
Le monde change st →
Observe le monde ot Choix de l’action
st+1
accès à un ensemble at suivant la poli-
observe Ot+1
d’actions possibles en tique
obtient récompense r
st
Mise à jour de la politique pour
l’état st
dans l’état st+1 avec la récom-
pense rt
But : accumuler le plus de récompense
Apprentissage par renforcement : comment spécifier la fonction de
mise à jour ?
Pour l’apprentissage des jeux, il n’y a pas d’environnement
L’algorithme va jouer contre une version de lui-même !
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 10Idée générale
Une politique est ce qui gouverne la décision de l’agent.
En général c’est une fonction qui donne pour chaque état la
probabilité de jouer chaque action
π : S × A 7→ R
Une technique pour apprendre
1. évalue une politique π : estime la valeur d’utiliser cette politique
2. améliore la politique π : améliore la politique avec la nouvelle
estimation de la valeur
ë c’est le principe de l’algorithme de base "Value itération"
Quand le nombre d’états est très grand, on ne peut pas maintenir
une table de la valeur des états
ë approximation. Ici l’idée est d’utiliser un réseau de neurones !
ë apprentissage par renforcement profond
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 11Réseau de neurones de AlphaGo Zéro
en entrée : la position des pierres noires et blanches et son historique
en sortie :
la probabilité de selection de chaque coup ë joue le rôle de la politique
la valeur de l’état courant ë joue le rôle de la fonction de valeur
ici, la valeur est une estimation de la probabilité de gagner à partir de
l’état courant
L’architecture du réseau de neurones utilise différentes techniques,
mais il est compliqué !
entrainement du réseau : en jouant contre lui-même avec un nouvel
algorithme d’apprentissage par renforcement qui utilise MCTS
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 12Utilisation de MCTS
MCTS est utilisé à la fois pour
évaluation de la politique
amélioration de la politique
Amélioration de la politique
on utilise MCTS avec le réseau pour choisir les actions
ë donne un politique π, sûrement meilleure que la politique du réseau
de neurones.
on utilise le résultat pour mettre à jour la politique ë faire évoluer la
politique du réseau à une politique plus proche de π
ë ici, cela voudra dire entrainer le réseau de neurones
Evaluation de la politique
l’algorithme joue des jeux contre lui-même pour estimer la qualité
de sa politique
ë on utilise ce résultat pour entrainer le réseau de neurones
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 13Entrainement du réseau de neurones
joue une partie s1 , . . . contre
lui-même
à chaque état st , MCTS est exécuté
les coups sont choisis selon le
résultat de MCTS
la valeur de l’état final est
calculée selon les règles du jeu
Entrainement du réseau de
neurones
on cherche à rapprocher la
probabilité du réseau avec
celle de MCTS
on cherche à minimiser
Figure 1: Self-play reinforcement learning in AlphaGo Zero. a The program plays a game s1 , ..., sT against itself. l’erreur entre le gagnant
n each position st , a Monte-Carlo tree search (MCTS) ↵✓ is executed (see Figure 2) using the latest neural network
f✓ . Moves are selected according to the search probabilities computed by the MCTS, at ⇠ ⇡ t . The terminal position
prédit et le véritable gagnant
sT is scored according to the rules of the game to compute the game winner z. b Neural network training in AlphaGo
Zero. The neural network takes the raw board position st as its input, passes it through many convolutional layers ë descente de gradient
with parameters ✓, and outputs both a vector pt , representing a probability distribution over moves, and a scalar value
vt , representing the probability of the current player winning in position st . The neural network parameters ✓ are
updated so as to maximise the similarity of the policy vector pt to the search probabilities ⇡t , and to minimise the
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 14MCTS dans AlphaGo Zéro
Figure select : on choisit
2: Monte-Carlo tree searchl’action
in AlphaGo qui
Zero. mène à l’étattraverses
a Each simulation le plus fort
the tree lorsqu’on
by selecting the edgese
trouve
with maximum dans Q,
action-value unplus
intervalle de confiance
an upper confidence bound U that depends on a stored prior probability P and
visit count N for that edgeon
expansion (which is incremented
évalue chaque once traversed).
action de b The
laleaf node is expanded
feuille dont on and the associated
n’est pas
position sûr.
s is evaluated by the neural network (P (s, ·), V (s)) = f (s); the vector of P values are stored in the outgoing
edges from s. c Action-values Q are updated to track the mean of all evaluations V in the subtree below that action. d
on evalue l’état avec le réseau de neurones les états suivants
Once the search is complete, search probabilities are returned, proportional to N
1/
, where N is the visit count of
onfrom
each move met à jour
the root state and is a parameter controlling temperature.
once by the network to generate both prior probabilities and evaluation, (P (s , ·), V (s )) = f (s ).
Each edge (s, a) traversed in the simulation is updated to increment its visit count N (s, a), and to
update its action-value to the mean evaluation over these simulations, Q(s, a) = 1/N (s, a) s |s,a s V (s ),
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 15Evaluation : version 1
3 jours d’entrainement en partant d’une politique aléatoire.
4.9 million de jeux
1.600 simulation pour chaque exécution de MCTS
une seule machine avec 4 TPU
bat Alpha Go Lee au bout de 36h
Il avait fallu plusieurs mois pour entrainer Alpha Go Lee !
Alpha Go Lee utilisait 48 TPUs
Figure 3: Empirical evaluation of AlphaGo Zero. a Performance of self-play reinforcement learning. The plot
shows the performance
M1 Informatique of each
2018–2019 Intelligence MCTS (Stéphane
Artificielle– player Airiau)
i
from each iteration i of reinforcement learning in AlphaGo Zero.de alpha Go 16
Un aperçuConnaissances
Alpha Go Zéro a appris des stratégies déjà connues
Alpha Go Zéro a découvert de nouvelles stratégies
un type de stratégies apprises en premier par les joueurs humains a
été découverte plutôt vers la fin de l’apprentissage de Alpha Go Zéro
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 17Evaluation : version 2
réseau de neurones plus grand
temps d’apprentissage plus important 29 million de jeux (40 jours)
Figure 6: Performance of AlphaGo Zero. a Learning curve for AlphaGo Zero using larger 40 block residual network
over 40 days. The plot shows the performance of each player i
from each iteration i of our reinforcement learning
algorithm. Elo ratings were computed from evaluation games between different players, using 0.4 seconds per search
(see Methods). b Final performance of AlphaGo Zero. AlphaGo Zero was trained for 40 days using a 40 residual block
neural network. The plot shows the results of a tournament between: AlphaGo Zero, AlphaGo Master (defeated top
human professionals 60-0 in online games), AlphaGo Lee (defeated Lee Sedol), AlphaGo Fan (defeated Fan Hui), as
well as previous Go programs Crazy Stone, Pachi and GnuGo. Each program was given 5 seconds of thinking time
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 18Evaluation : sur d’autres jeux
sur les échecs : bat le meilleur programme en s’entrainant moins de
24h
shogi (jeu japonais similaire aux échecs, mais plus dur) : idem
M1 Informatique 2018–2019 Intelligence Artificielle– (Stéphane Airiau) Un aperçu de alpha Go 19Vous pouvez aussi lire

















































