CONCEPTION DE WORKFLOWS DE TRAITEMENT DE DONNÉES - L'EXPÉRIENCE DE MAIAGE AVEC GALAXY, ALVISNLP ET OPENMINTED ROBERT BOSSY AG ICAT 5 DÉCEMBRE 2016 ...
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Conception de workflows de traitement de données
L’expérience de MaIAGE avec Galaxy, AlvisNLP et OpenMinTeD
Robert Bossy
Bibliome
AG ICAT 5 décembre 2016
1 / 30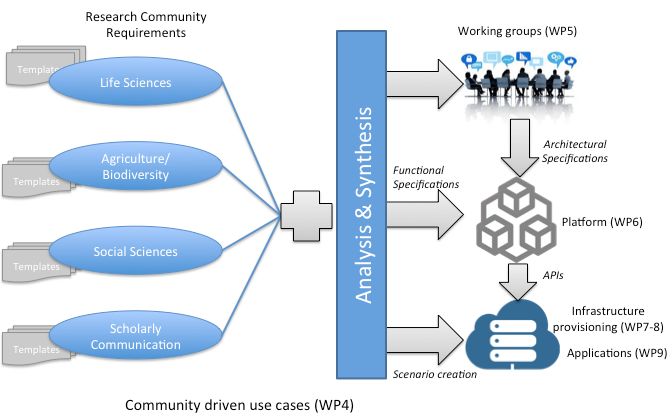
1 Introduction
2 Gestionnaire de workflows
3 OpenMinTeD
4 Conclusions
2 / 30
Introduction
3 / 30
Introduction
Retour d’expérience sur l’utilisation et le développement de worflows
logiciels de traitement de données.
Exemples
Taitement Automatique de la Langue (TAL), Extraction
d’Information (IE)
Bioinformatique
Bibliome passe progressivement d’une pratique empirique vers une
approche méthodique (H2020 OpenMinTeD).
4 / 30Workflow, qu’est-ce que c’est ?
Définition
Série de traitements de données
automatisés
interdépendants
dans l’objectif de produire des données secondaires.
Exemples
TAL : annotation sémantique de textes
Bioinformatique : annotation fonctionnelle des gènes d’un
génome
5 / 30Exemple détaillé
Quelques caractéristiques
Composants logiciels avec des
tâches distinctes identifiées
Le flot de données impose une
interdépendance entre ces
composants
Chaque composant utilise des
ressources externes
6 / 30Comment fait-on ?
Majorité des cas : un script
La série de traitements est plus ou moins explicite.
Le flot de données est implicite.
Problèmes
La reproductiblité des résultats dépend de la maintenance du
script.
L’adaptation à de nouvelles données n’est pas toujours triviale.
Le passage à l’échelle est limité.
Le code est un obstacle au transfert et au partage.
La valorisation se borne à la distribution du code.
7 / 30Comment faire ?
Reproductibilité
Assurer systématiquement la provenance des données produites.
Centralisation et isolement de la spécification de la séquence de
traitements,
et des ressources externes utilisées.
Adaptation
Possibilité d’insérer de nouveaux traitements, de réassembler les
workflows.
Identification et isolement des paramètres des algorithmes et des
ressources externes.
8 / 30Comment faire ?
Transfert et partage
Résultats enrichis de leur provenance.
Transfert du processus, et non du code.
Valorisation des développements
Assurer la synergie des développements, mutualisation des
compétences.
Penser chaque nouveau développement comme un composant
de workflows, élaboration d’une bibliothèque.
9 / 30Comment faire ?
Passage à l’échelle
Optimiser le flot de données.
S’affranchir du modèle d’éxecution machine unique.
Assurer le rapport et la surveillance.
Séparation des responsabilités : exécution des composants
logiciels, gestion des données.
10 / 30Et si on s’attaquait à ces problèmes ?
Le script devient logiciel
Cela necessite une compétence de développement logiciel.
Il existe un acquis sur les workflows, problématique très
ancienne.
Exemples
AlvisNLP/ML (TAL, Bibliome)
UIMA (TAL, Apache)
Galaxy (Bioinfo, Univ. de Pennsylvanie)
OpenMinTeD (TAL, E-INFRA)
11 / 30Que va permettre un gestionnaire de workflow ?
Assembler les workflows de traitement de données.
Prendre en charge complètement le flot de données.
Prendre en charge les “corvées”.
Vérifier et exécuter le workflow spécifié.
12 / 30Gestionnaire de workflows
13 / 30Focus sur trois fonctions
1 Interprétation du workflow
2 Prise en charge des données
3 Animation du workflow
→ Standardisation des composants logiciels.
14 / 30Interprétation du workflow
Écrire de façon déclarative le workflow
Décrire une séquence des processus de façon déclarative.
Expliciter les paramètres et les ressources externes.
Centralisation déclarations
→ Adaptabilité
→ Transfert et partage
15 / 30Exemples
../corpus/Quaero_t3.2_gene_dev+train-v1.1
../../bibliome/share/xslt/gene-train2alvisnlp.xslt
/bibdev/install/tree-tagger-3.2/bin/tree-tagger
/bibdev/install/tree-tagger-3.2/lib/english.par
weka.classifiers.bayes.NaiveBayes
classifier.model
attributes.xml
documents[@set=="train"].sections.layer:candidates
16 / 30Flux de données
Intégrer les données produites par les difféérents composants
Encapsuler la conversion des données E/S.
Aligner la sémantique des données.
Abstraction des formats de données
→ Transfert et partage
→ Reproductibilité
→ Adaptabilité
17 / 30Deux approches pour le flux de données
Galaxy
Les données manipulées sont une signature de chaque logiciel.
+ Assistance à l’assemblage des workflows
- Scénarios prédéfinis, conversions explicites
AlvisNLP, UIMA
Définition d’une représentation universelle, d’un format pivot.
+ Liberté d’assemblage, conversion implicite
- Pas toujours possible
18 / 30Animation du workflow
Coordoner l’exécution des composants logiciels
Sur la base d’une séquence spécifiée par l’utilisateur (workflow).
Support pour des environnements variés : serveur unique, ferme
de calcul, virtualisation des composants. . .
Rapport d’exécution : logs, moniteur d’avancement, échec
grâcieux.
Prise en charge de l’exécution
→ Passage à l’échelle
→ Reproductibilité
19 / 30Standardisation des composants logiciels
Les composants doivent être décrits et encapsulés de façon uniforme
de façon à :
coopérer avec l’animation,
concrétiser le flux de données.
Exemple simple : commandes Unix
cut -f 4 tableau.txt | sort | uniq -c | sort -n
20 / 30Description des composants
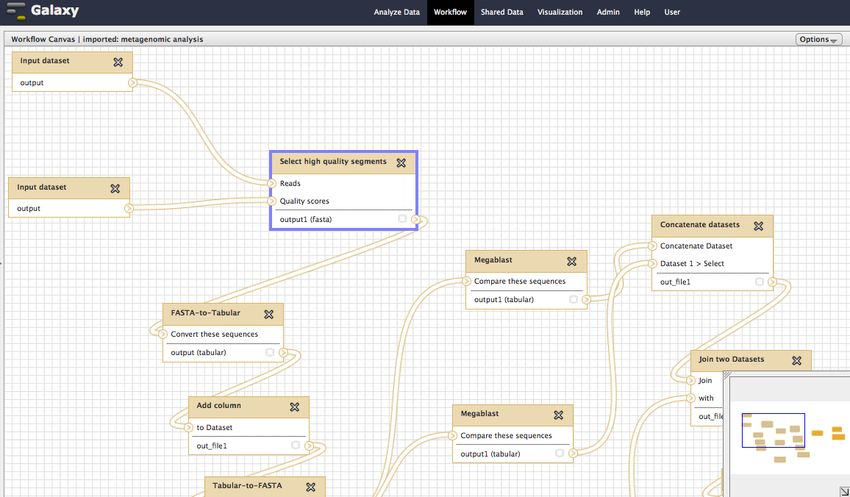
AlvisNLP
Galaxy
21 / 30OpenMinTeD
22 / 30Constat
Multiples gestionnaires de workflow développés spécifiques au
TAL (AlvisNLP, DKPro, Argo, GATE).
Composants intégrés distincts dans chacune des plate-formes.
Les plate-formes ne sont pas interopérables.
Exploiter l’état de l’art en TAL nécessite plus de compétences
que nécessaire.
23 / 30Objectifs de OpenMinTeD
Démocratiser le TAL.
Créer une “union” des bilbiothèques de composants.
Composer, réutiliser et partager des workflows,
indépendamment.
Centraliser l’accès aux documents et aux ressources.
Puissance de calcul et de stockage (GRNET).
24 / 30Méthodologie OpenMinTeD
25 / 30Les choix de OpenMinTeD
Flux de données : XMI+RDF
Constante en TAL : représentation unique
Représentation des corpus (RDF), et des annotations (XMI).
Animation du workflow : Galaxy
Large base d’utilisateurs, durable
Qualités techniques : grilles, cloud, stockage, API. . .
Interfaces graphiques
Adaptation à la logique “représentation universelle” : s’appuyer
sur l’expérience de LAPPS et CLARINO
Annuaire des ressources
Dépôt, description et recherche de ressources.
Ressources : lexiques, ontologies, composants logiciels. . .
Interface REST et graphique.
26 / 30Verrous
Droits associés aux données traitées.
Logiciels interactifs : éditeur d’annotations, rythme différent,
statut des données.
Versionnement des ressources et mises à jour.
Interaction avec les applications qui exploitent les résultats.
27 / 30Conclusions
28 / 30Que choisir ?
Flux de données
La nature des données manipulées est déterminante :
Paradigme intrinsèque : tables, signaux, graphes. . .
Hétérogénéité parmi les logiciels
Volume et granularité
Délimitation
Étroite
I données plus homogènes
I repousse des problèmes d’intégration inévitables
Large :
I plus de couverture
I données plus hétérogènes
29 / 30Discussion : CATI Workflows
Réflexion autour de une ou plusieurs applications
Objectif applicatif réel.
Mutualiser des développements et des données distinctes.
Définition et spécifications pour un gestionnaire de workflows.
Développement de prototype(s).
30 / 30Vous pouvez aussi lire

















































