DEEP LEARNING 2 MODÈLES ET APPLICATIONS - DR BERNARD GIUSIANO, MD, PHD - HYPOTHESES.ORG
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Deep Learning 2 Modèles et applications Dr Bernard GIUSIANO, MD, PhD bernard.giusiano@univ-amu.fr 15/05/2020 – Deep Learning 1
Plan • Deep Learning 1 : Introduction aux réseaux de neurones et à l’apprentissage profond. • Histoire des débuts de l’IA : symbolique vs neuromimétique • L’impasse de l’apprentissage symbolique ; l’évolution vers les méthodes statistiques et les méthodes expérimentales connexionnistes • Le perceptron • Réalisation d’un perceptron, puis d’un perceptron multicouche (MLP) • Réalisation d’un modèle de classification d’images • Deep Learning 2 : Modèles et applications. • Paramètres, hyperparamètres, architectures • Différentes architectures et différents modèles de deep learning • Terrains de jeu pour mieux comprendre le deep learning • Etc. 15/05/2020 – Deep Learning 2
Paramètres, hyperparamètres, architectures • Classiquement, on appelle « paramètres » les poids synaptiques. La valeur des paramètres est déterminée par l’apprentissage. Ils sont donc liés aux données présentées en entrée lors de l’apprentissage. • Les hyperparamètres sont des paramètres dont la valeur est déterminée avant la phase d’apprentissage. Ils sont indépendants des données présentées en entrée. Ils influencent la façon dont se fera l’apprentissage. • Initialisation des poids synaptiques • Nombre d’époques : nombre de passages de l’ensemble des « exemples » d’apprentissage • Taille du lot (batch size) : nombre d’exemples traités avant de mettre à jour les poids • Vitesse d’apprentissage (learning rate) • Momentum : paramètre modulant la vitesse d’apprentissage (et autres astuces…) Certains hyperparamètres sont liés à des fonctions caractérisant le réseau : • Fonction d’activation (transformation de la somme des ∗ en sortie) • Fonction d’erreur (ou « de perte » entre sortie obtenue et sortie attendue -> loss function) • Optimiseur (façon de mettre à jour les poids) • Méthodes de régularisation : dropout, … • L’architecture dépend du nombre de couches, du nombre d’unités (neurones) par couche et des connexions entre les neurones et entre les couches. Le nombre de couches et le nombre de neurones sont souvent considérés comme des hyperparamètres. 15/05/2020 – Deep Learning 3
Exemples de fonctions d’activation 15/05/2020 – Deep Learning 4
Exemples de fonctions d’erreur ℒ = Θ , avec Θ les paramètres (poids, bias), les entrées, la sortie attendue • Valeur absolue (norme L1) : • Distance euclidienne (norme L2): • Cross-entropy : Cf. Loss functions : https://www.slideshare.net/xavigiro/loss-functions-dlai-d4l2-2017-upc-deep-learning-for- artificial-intelligence 15/05/2020 – Deep Learning 5

Exemples d’optimiseurs • L’optimiseur (mise à jour des poids) historique est la règle delta (delta rule). • Un des optimiseurs les plus utilisés est adam. • A part RMSprop, la plupart des optimiseurs se différencient surtout par leur rapidité pour obtenir la meilleure précision (accuracy). 15/05/2020 – Deep Learning 6
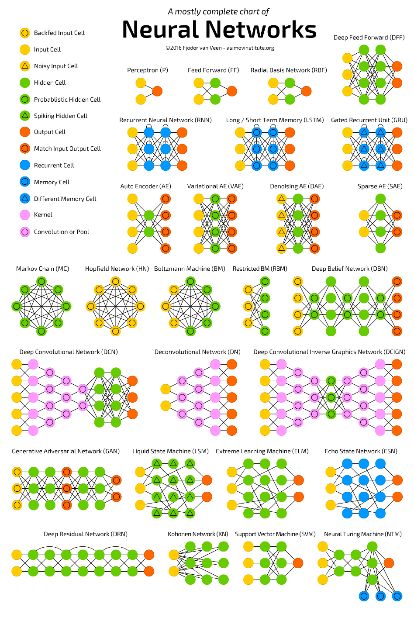
Architectures de réseaux de neurones The neural network zoo Cf. http://www.asimovinsti tute.org/neural- network-zoo/ 15/05/2020 – Deep Learning 7
Nombre de neurones cachés • Les réseaux de neurones avec un plus grand nombre de neurones peuvent représenter des fonctions plus complexes. • Dans les exemples ci-dessous, les données sont représentées par des cercles colorés par leur classe et les régions de décision par les couleurs du fond. • Cf. une démonstration du réseau ConvNetsJS à l’adresse https://cs.stanford.edu/~karpathy/convnetjs/demo/classify2d.html. 15/05/2020 – Deep Learning 8
Quelques architectures • Perceptrons multicouches • Couches entièrement connectées • Autoencodeurs • Les sorties attendues sont les entrées • Réseaux de neurones convolutifs (CNN) • Extraction des caractéristiques des entrées par des filtres à convolution • Réseaux de neurones récurrents (RNN) • Des séquences en entrée 15/05/2020 – Deep Learning 9

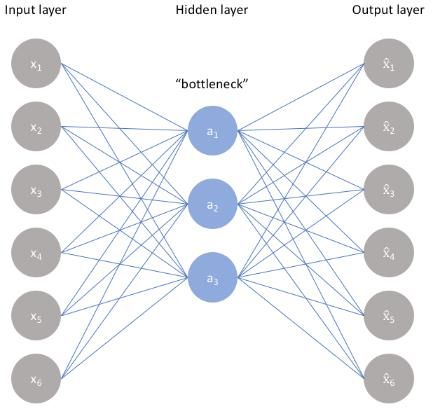
Autoencodeur • C’est un perceptron multicouches dont la couche centrale constitue un goulot d’étranglement. • L’apprentissage y est à moitié non supervisé. • Les sorties attendues sont identiques aux entrées. Le réseau doit apprendre à reconstruire les entrées malgré le goulot d’étranglement. • La couche centrale correspond à une réduction des dimensions des données d’entrée. • Il réalise l’équivalent d’une analyse en composantes principales (ACP) mais capable de transformations non- linéaires. 15/05/2020 – Deep Learning 10
Autoencodeur • La contrainte du goulot d’étranglement oblige le modèle à extraire la variabilité suffisante pour reconstruire les entrées sans prendre en compte les informations redondantes. • Utilisations : • Compression des données • Suppression du bruit • Préapprentissage dans des architectures plus complexes (contenant un ou plusieurs autoencodeurs) 15/05/2020 – Deep Learning 11
Réseaux convolutifs (CNN) • Ils extraient les caractéristiques (features) des entrées. • Deep learning : de nombreuses couches convolutives successives permettent d’obtenir des caractéristiques à différents niveaux de résolution. • Ils résistent aux translations, rotations et changements d’échelle. • Très utilisés dans la reconnaissance des images. Mais aussi dans de nombreuses autres applications où les données peuvent être représentées comme des images (structures spatiales). 15/05/2020 – Deep Learning 12
Réseaux convolutifs • Imaginons un réseau de neurones devant reconnaître des « X » et des « O » • Les images présentées en entrée peuvent être de mauvaise qualité https://medium.com/@CharlesCrouspeyre/comment-les-r%C3%A9seaux-de-neurones-%C3%A0-convolution-fonctionnent-b288519dbcf8 15/05/2020 – Deep Learning 13
Réseaux convolutifs • L’idée des CNN est de chercher à repérer les caractéristiques qui permettent de distinguer les « X » des « O ». • Les concepteurs de cette architecture se sont basés sur les connaissances acquises sur la vision des objets chez le chat. 15/05/2020 – Deep Learning 14
Réseaux convolutifs • Le CNN compare les images fragment par fragment (les caractéristiques). • En trouvant des caractéristiques approximatives qui se ressemblent à peu près dans deux images différentes, le CNN est bien meilleur à détecter des similitudes que par une comparaison entière image à image. 15/05/2020 – Deep Learning 15
Réseaux convolutifs • Plusieurs types différents de caractéristiques peuvent être recherchés grâce à différents filtres de convolution. • Les différents filtres sont automatiquement appris, donc déterminés, par le réseau à partir des caractéristiques les plus fréquemment rencontrées dans les entrées. Résultat du filtrage Filtre détectant les diagonales de gauche-haut à droite-bas Fenêtre analysée par le filtre Image présentée 15/05/2020 – Deep Learning 16
Réseaux convolutifs • Chaque filtre correspond à une fenêtre (par exemple de 3 x 3 pixels) qui balaye la totalité de l’image. Ce balayage résulte en fait de la façon dont les neurones sont connectés dans les couches de convolution. 15/05/2020 – Deep Learning 17
Réseaux convolutifs • Après une couche de convolution, une couche de regroupement (pooling) peut être utilisée pour résumer (diminuer la taille) du résultat de la convolution. • Après les convolutions, les résultats servent d’entrées à des couches entièrement connectées pour aboutir à une classification (par exemple). 15/05/2020 – Deep Learning 18
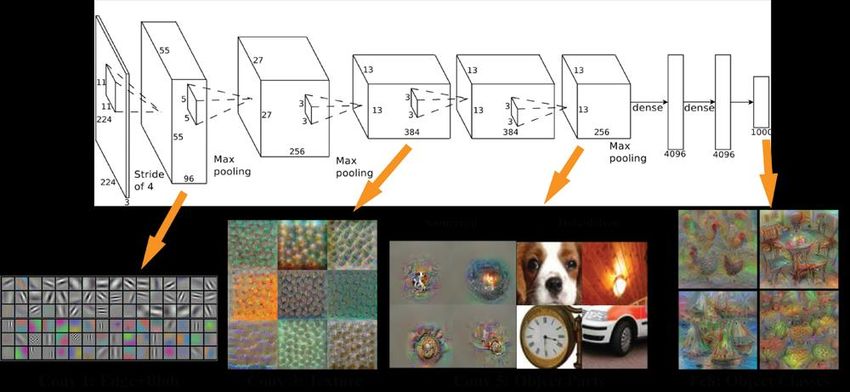
Réseaux convolutifs • Chaque couche de convolution détecte des types de caractéristiques de même niveau structurel. • Les premières couches détectent des caractéristiques simples. • Les couches les plus hautes détectent des patterns de niveaux d’intégration plus élevés. 15/05/2020 – Deep Learning 19
Réseaux convolutifs • x 15/05/2020 – Deep Learning 20
Réseaux convolutifs 15/05/2020 – Deep Learning 21
Réseaux convolutifs • Exemple d’architectures plus complexes : le modèle Inception 9 15/05/2020 – Deep Learning 22
Réseaux récurrents (RNN) • Ils présentent des connexions récurrentes, c’est-à-dire des connexions permettant aux résultats d’une couche de constituer une partie des entrées de cette couche ou d’une couche plus basse. • Très utilisés dans le traitement du langage. Mais aussi dans de nombreuses autres applications où les données constituent des séquences (structures temporelles). 15/05/2020 – Deep Learning 23
Réseaux récurrents • La boucle de récurrence fait que le passé influe sur le présent (les résultats des données passées influent sur celui des données présentes). Représentations pliée et dépliée : Rolled version 15/05/2020 – Deep Learning 24
Réseaux récurrents • Il y a de nombreuses façon d’introduire la récurrence dans un réseau • One to one : pas de récurrence • Les autres architectures sont en représentation dépliée 15/05/2020 – Deep Learning 25
Réseaux récurrents • Exemple de fonctionnement : prédiction d’un mot à la suite d’une séquence de mots Sortie attendue Sortie calculée 15/05/2020 – Deep Learning 26
Réseaux récurrents • Exemple d’utilisation : traduction • Exemple d’utilisation : description textuelle d’une image 15/05/2020 – Deep Learning 27
Long Short-Term Memory networks (LSTM) • Espèce de réseaux récurrents utilisant des unités (neurones) plus sophistiquées qui permettent la prise en compte de plusieurs échelles de temps avec la capacité de gérer l’oubli. 15/05/2020 – Deep Learning 28
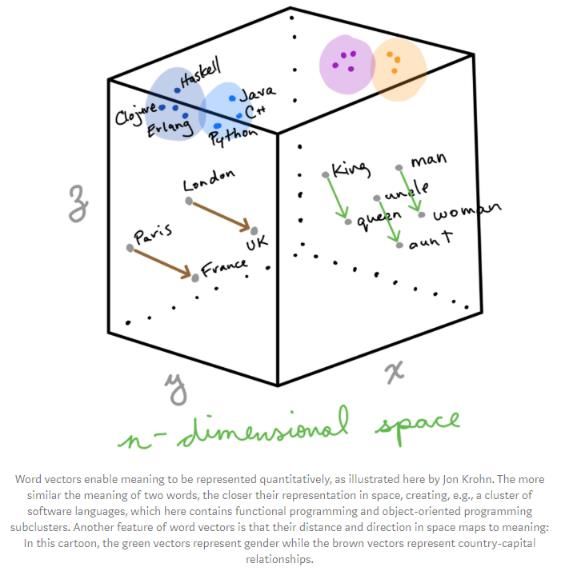
Exemples de préparation des données • Comment code-t-on les entrées textuelles ? • One-hot encoding • Word embedding • Projection d’un ensemble de mots dans un espace continu. • Cette projection doit permettre des calculs du type : vecteur(ROI) – vecteur(HOMME) + vecteur(FEMME) = vecteur(REINE) • Peut être réalisé par des méthodes statistiques utilisant la proximité entre les mots dans des corpus de textes, ou calculé grâce à un réseau de neurones (word2vec). 15/05/2020 – Deep Learning 29
Exemples de préparation des données • Word embedding sur deux dimensions (2 neurones pour un mot) 15/05/2020 – Deep Learning 30
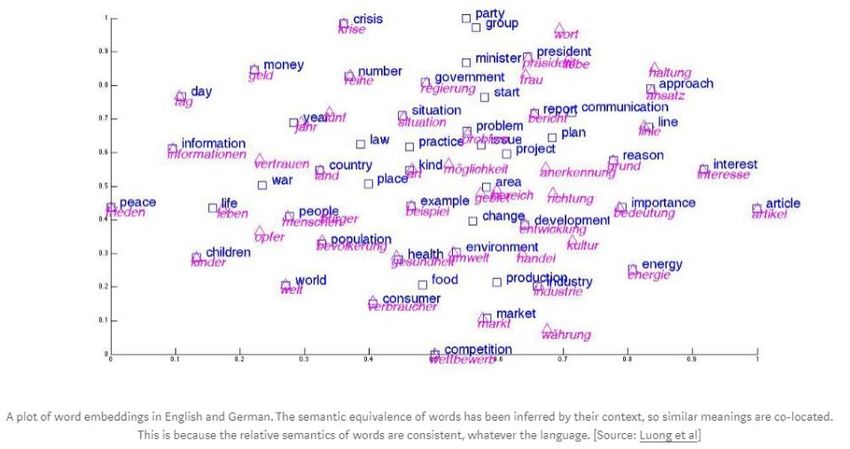
Exemples de préparation des données • Word embedding sur trois dimensions (3 neurones pour un mot) https://insights.untapt.com /deep-learning-for-natural- language-processing- tutorials-with-jupyter- notebooks-ad67f336ce3f 15/05/2020 – Deep Learning 31
Modèles plus complexes • Hand Gesture Recognition Using Compact CNN Via Surface Electromyography Signals https://www.researchgate.net/publication/338847538_Hand_Gesture_Recognition_Using_Compact_CN N_Via_Surface_Electromyography_Signals 15/05/2020 – Deep Learning 32
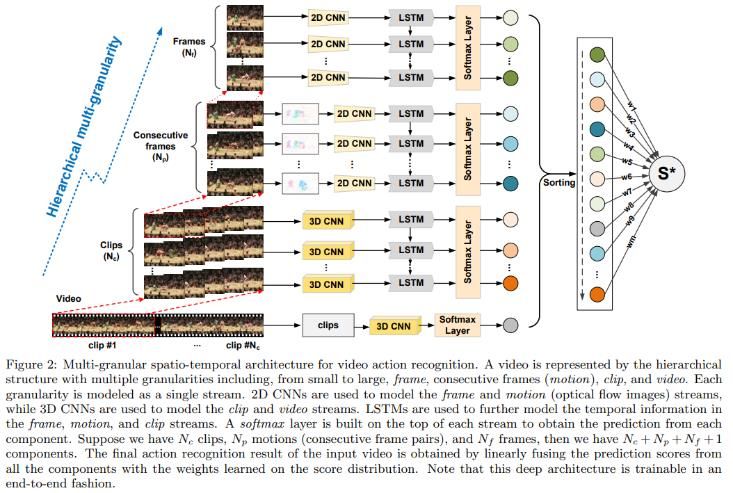
Modèles plus complexes • Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation https://dl.acm.org/doi/pdf/10.1145/2911996.2912001 15/05/2020 – Deep Learning 33
Generative Adversial Network • Un modèle récent très en vogue… dont les applications sont à explorer. • Modèle génératif où deux réseaux sont placés en compétition dans un scénario de théorie des jeux. Le premier réseau est le générateur, il génère un échantillon (ex. une image), tandis que son adversaire, le discriminateur essaie de détecter si un échantillon est réel ou bien s'il est le résultat du générateur. https://poloclub.github.io/ganlab/ 15/05/2020 – Deep Learning 34
A Neural Network Playground https://playground.tensorflow.org/ 15/05/2020 – Deep Learning 35
ConvnetJS demo https://cs.stanford.edu/~karpathy/convnetjs/demo/classify2d.html 15/05/2020 – Deep Learning 36
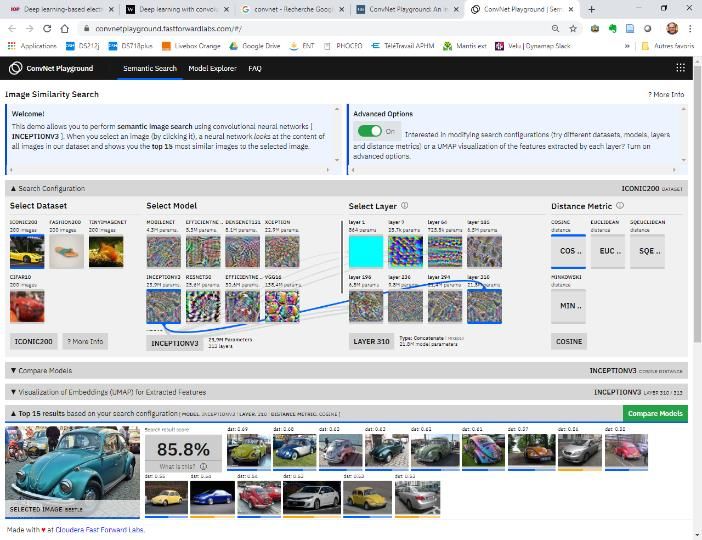
Convnet Playground https://convnetplayground.fastforwardlabs.com/#/ 15/05/2020 – Deep Learning 37
Autres exemples • Top 10 Deep Learning experiences run on your Browser https://www.dlology.com/blog/top-10-deep-learning-experiences-run-on-your-browser/ et https://www.tensorflow.org/js/demos • Sur kaggle.com 15/05/2020 – Deep Learning 38
Quelques articles • Toward an Integration of Deep Learning and Neuroscience https://www.frontiersin.org/articles/10.3389/fncom.2016.00094/full • A Cognitive Neural Architecture Able to Learn and Communicate through Natural Language https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0140866 • Deep learning-based electroencephalography analysis: a systematic review https://iopscience.iop.org/article/10.1088/1741-2552/ab260c • Recurrent Neural Network Grammars https://arxiv.org/pdf/1602.07776.pdf • Applying deep learning to single-trial EEG data provides evidence for complementary theories on action control https://www.nature.com/articles/s42003-020-0846-z • Neurolinguistic and machine-learning perspectives on direct speech BCIs for restoration of naturalistic communication https://www.tandfonline.com/doi/full/10.1080/2326263X.2017.1330611 • Linguistic Regularities in Sparse and Explicit Word Representations? https://levyomer.files.wordpress.com/2014/04/linguistic-regularities-in-sparse-and-explicit-word-representations-conll- 2014.pdf • A Beginner's Guide to Graph Analytics and Deep Learning https://pathmind.com/wiki/graph-analysis • Relating Simple Sentence Representations in Deep Neural Networks and the Brain https://www.aclweb.org/anthology/P19-1507.pdf • What deep learning can tell us about higher cognitive functions like mindreading? https://arxiv.org/ftp/arxiv/papers/1803/1803.10470.pdf 15/05/2020 – Deep Learning 39
Datasets • List of datasets for machine-learning research https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research • Datasets on kaggle.com https://www.kaggle.com/datasets • EEG / ERP data available for free public download https://sccn.ucsd.edu/~arno/fam2data/publicly_available_EEG_data.html 15/05/2020 – Deep Learning 40
Vous pouvez aussi lire

















































