Guide d'utilisation d'Epi Info 7 pour réaliser des analyses statistiques
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Guide d’utilisation d’Epi Info 7 pour réaliser des analyses statistiques Loïc Desquilbet, PhD en Santé Publique Professeur en Biostatistique et en Epidémiologie Clinique Département des Sciences Biologiques et Pharmaceutiques Ecole nationale vétérinaire d’Alfort Version 1.0 (24/01/2022) Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0
Préface Comment lire ce guide Chaque partie de ce guide d’utilisation du logiciel Epi Info 7 ne peut pas se lire avant d’avoir lu les parties précédentes. Ainsi, si par exemple vous souhaitez utiliser un modèle de Cox pour analyser vos données, vous devrez lire … l’intégralité de ce guide ! Contrat de diffusion Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International (BY NC ND 4.0). Le résumé de la licence se trouve ici : https://creativecommons.org/licenses/by-nc-nd/3.0/fr/. Attribution — Vous devez créditer l'Œuvre, intégrer un lien vers la licence et indiquer si des modifications ont été effectuées à l'Oeuvre. Vous devez indiquer ces informations par tous les moyens raisonnables, sans toutefois suggérer que l'Offrant vous soutient ou soutient la façon dont vous avez utilisé son Oeuvre. Pas d’Utilisation Commerciale — Vous n'êtes pas autorisé à faire un usage commercial de cette Oeuvre, tout ou partie du matériel la composant. Pas de modifications — Dans le cas où vous effectuez un remix, que vous transformez, ou créez à partir du matériel composant l'Oeuvre originale, vous n'êtes pas autorisé à distribuer ou mettre à disposition l'Oeuvre modifiée. Citation du document Vous pouvez citer ce document de la façon suivante : Desquilbet, L. 2022. Guide d’utilisation d’Epi Info 7 pour réaliser des analyses statistiques. [En ligne, disponible à : https://hal.archives-ouvertes.fr/hal- numéro à modifier] Suggestions de modifications de ce document Si vous avez des suggestions de modifications de ce guide (coquilles dans le texte, souhaits de clarification de certains passages, etc.), n’hésitez pas à me les signaler par email (loic.desquilbet(at)vet- alfort.fr). Je vous remercie beaucoup par avance. Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0
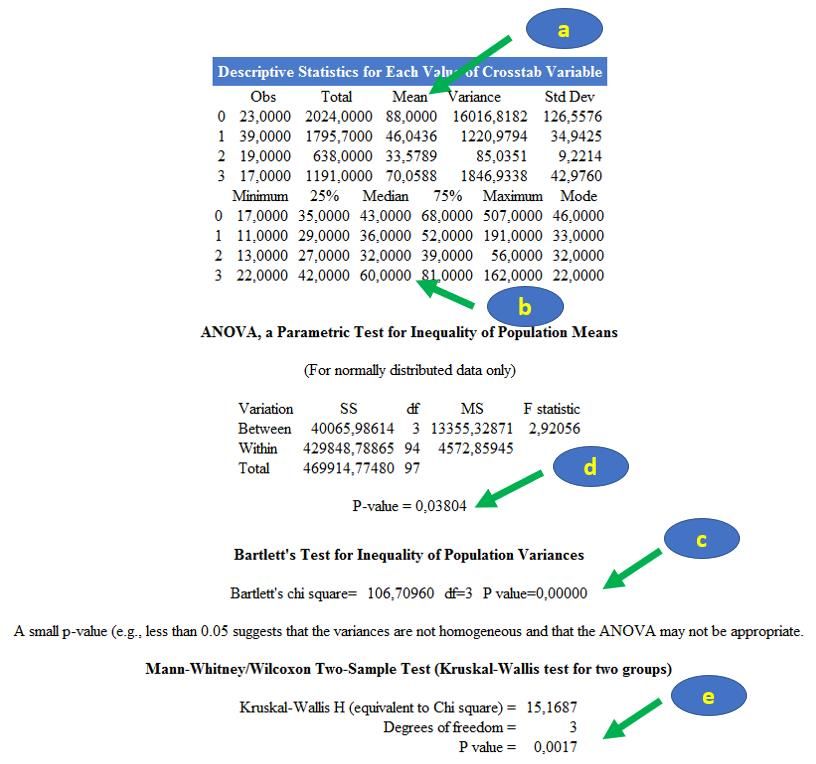
Table des matières Préface ....................................................................................................................................................................................... 1 Comment lire ce guide .......................................................................................................................................................... 2 Contrat de diffusion............................................................................................................................................................... 2 Citation du document ............................................................................................................................................................ 2 Suggestions de modifications de ce document ..................................................................................................................... 2 Chapitre 1 - Préambule I. Présentation rapide du logiciel Epi Info 7 ......................................................................................................................... 4 A. Téléchargement d’Epi Info 7 et comparaison avec d’autres logiciels .......................................................................... 4 B. Premier lancement d’Epi Info 7 ................................................................................................................................... 4 II. Quelques rappels indispensables ...................................................................................................................................... 7 A. Ressources utilisées dans ce guide .............................................................................................................................. 7 B. Rappel sur la structure d’un fichier de données pour analyses statistiques ................................................................ 7 C. Définitions de critère de jugement, d’exposition, et de variable ................................................................................. 8 D. Rappel sur les différents types de variables................................................................................................................. 8 1. Variables binaires .................................................................................................................................................... 8 2. Variables qualitative nominales .............................................................................................................................. 8 3. Variables qualitative ordinales ................................................................................................................................ 9 4. Variables quantitatives ........................................................................................................................................... 9 III. Présentation du fichier de données fictif .......................................................................................................................... 9 IV. Importer les données à analyser et sauvegarder un programme ................................................................................... 10 A. Création préalable d’un « projet » ............................................................................................................................. 10 B. Importation de données d’un fichier Excel (ou sous un autre format) ...................................................................... 12 C. Sauvegarder son programme..................................................................................................................................... 14 Chapitre 2 - Analyses statistiques de base I. Introduction .................................................................................................................................................................... 15 A. Vérifications préliminaires avant les analyses statistiques ........................................................................................ 15 B. Convention de présentation des résultats issus des copies d’écran d’Epi Info .......................................................... 17 II. Statistiques descriptives ................................................................................................................................................. 17 A. Décrire une variable binaire ou qualitative ................................................................................................................ 17 B. Décrire une variable quantitative .............................................................................................................................. 18 III. Association statistique entre deux variables .................................................................................................................. 19 A. Croisement de deux variables binaires ou qualitatives, et test statistique................................................................ 19 1. Introduction .......................................................................................................................................................... 19 2. Croisement de deux variables binaires ................................................................................................................. 19 3. Croisement d’une variable binaire avec une variable qualitative ......................................................................... 22 4. Croisement de deux variables qualitatives ........................................................................................................... 23 B. Croisement d’une variable binaire ou qualitative avec une variable quantitative, et tests statistiques ................... 24 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 1
1. Croisement d’une variable binaire avec une variable quantitative....................................................................... 24 2. Croisement d’une variable qualitative avec une variable quantitative ................................................................. 27 IV. Travailler dans un sous échantillon ................................................................................................................................. 28 V. Analyse de survie à l’aide des courbes de Kaplan-Meier ................................................................................................ 30 A. Courbe de survie globale dans l’ensemble de l’échantillon ....................................................................................... 30 B. Courbes de survie selon les modalités d’une variable binaire ................................................................................... 31 C. Courbes de survie selon les modalités d’une variable qualitative ............................................................................. 33 Chapitre 3 - Modèles de régression I. Introduction .................................................................................................................................................................... 35 A. Gestion du symbole de la décimale des variables quantitatives ............................................................................... 35 II. Théorie des modèles de régression ................................................................................................................................ 35 A. Ecriture d’un modèle de régression ........................................................................................................................... 35 B. Choix d’un modèle de régression et écriture mathématique du modèle .................................................................. 36 C. Problématique des données manquantes ................................................................................................................. 36 III. La régression linéaire ...................................................................................................................................................... 37 A. Introduction ............................................................................................................................................................... 37 B. Interprétation des résultats d’une régression linéaire univariée ............................................................................... 39 1. Cas général ............................................................................................................................................................ 39 2. Modèle de régression linéaire univarié avec variable binaire ............................................................................... 40 3. Modèle de régression linéaire univarié avec variable quantitative ...................................................................... 41 4. Modèle de régression linéaire univarié avec variable qualitative ordinale ........................................................... 42 5. Modèle de régression linéaire univarié avec variable qualitative nominale ......................................................... 43 C. Interprétation des résultats d’une régression linéaire multivariée ........................................................................... 48 1. Interprétation générale......................................................................................................................................... 48 2. En pratique avec Epi Info ...................................................................................................................................... 49 IV. Vérification de la linéarité de l’association avec une variable quantitative ou qualitative ordinale ............................... 51 A. Introduction ............................................................................................................................................................... 51 B. Cas d’une variable qualitative ordinale ...................................................................................................................... 51 1. Aspect théorique................................................................................................................................................... 51 2. En pratique avec Epi Info ...................................................................................................................................... 53 C. Cas d’une variable quantitative ................................................................................................................................. 55 1. Aspect théorique................................................................................................................................................... 55 2. En pratique avec Epi Info ...................................................................................................................................... 56 V. La régression logistique .................................................................................................................................................. 58 A. Introduction ............................................................................................................................................................... 58 B. Interprétation des résultats d’une régression logistique univariée ........................................................................... 59 1. Modèle de régression logistique avec variable binaire ......................................................................................... 59 2. Modèle de régression logistique univarié avec variable quantitative................................................................... 60 3. Modèle de régression logistique univarié avec variable qualitative ordinale ....................................................... 63 4. Modèle de régression logistique univarié avec variable qualitative nominale ..................................................... 65 C. Interprétation des résultats d’une régression logistique multivariée ........................................................................ 66 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 2
VI. Le modèle (à risques proportionnels) de Cox ................................................................................................................. 68 A. Introduction ............................................................................................................................................................... 68 B. Interprétation des résultats d’un modèle de Cox univarié ........................................................................................ 68 C. Interprétation des résultats d’un modèle de Cox multivarié ..................................................................................... 70 D. Vérification de l’hypothèse de la proportionnalité des risques ................................................................................. 72 1. Introduction .......................................................................................................................................................... 72 2. Vérification avec Epi Info ...................................................................................................................................... 72 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 3
Chapitre 1 - Préambule I. Présentation rapide du logiciel Epi Info 7 A. Téléchargement d’Epi Info 7 et comparaison avec d’autres logiciels Epi Info 7 est un logiciel gratuit qui ne fonctionne (malheureusement) que sur PC. Il peut se télécharger en cliquant ici. Ce logiciel permet entres autres de concevoir des questionnaires, de saisir des données, et de réaliser des analyses statistiques sur des données. C’est cette dernière fonctionnalité du logiciel que traite ce guide, et ce, de façon non exhaustive. L’aide (en anglais) du logiciel dans sa partie « analyse des données » se trouve ici. Pour quelle raison utiliser Epi Info et non pas d’autres logiciels de statistique ? Tout d’abord, citons quelques logiciels de statistique que l’on peut utiliser, dont certains sont payants, et d’autres gratuits(*) : BiostaTGV*, R*, GraphPad, XLSTAT, et SAS*1. Les avantages d’Epi Info par rapport aux trois logiciels gratuits précédemment cités sont les suivants. Par rapport à BiostaTGV, Epi Info travaille directement sur un fichier de données importé d’Excel par exemple et il permet de réaliser des modèles de régression (linéaire, logistique, et Cox). Par rapport à R et SAS, Epi Info est beaucoup plus simple d’utilisation, et ne demande aucune connaissance / appétence en langage de programmation. Le gros inconvénient d’Epi Info est qu’il ne fonctionne que sur PC, et pas sur Mac. Il est aussi bien plus limité que ne le sont les autres logiciels de statistique dans les différentes méthodes d’analyses statistiques proposées. B. Premier lancement d’Epi Info 7 Après avoir installé Epi Info, en lançant Epi Info, vous obtenez la fenêtre ci-dessous (cf. Figure 1). La toute première démarche que je vous suggère (et que vous n’aurez à faire qu’une seule fois) est de choisir l’anglais comme langue par défaut (si tel n’est pas déjà le cas juste après le téléchargement). Ainsi, les analyses statistiques décrites dans Epi Info correspondront à celles que vous lisez dans la littérature scientifique (majoritairement anglophone). 1 Gratuit pour les universitaires et les étudiants Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 4
Figure 1 Pour cela, vous cliquez sur « Créer questionnaires » (Figure 1.a), puis sur « Outils » → « Options » → « Langue » et on sélectionne « English (default) ». Puis vous redémarrez Epi Info pour prendre en compte le changement de langue. En relançant Epi Info, vous obtenez la fenêtre ci-dessous (Figure 2). Figure 2 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 5
Vous cliquez sur « Classic » dans « Analyse data » (Figure 2.a), car c’est en effet la seule fenêtre que je vais utiliser dans ce guide (à part au moment de créer un projet pour enregistrer un programme). On obtient alors la fenêtre ci-dessous (Figure 3). Figure 3 La fenêtre qui apparait est formée de quatre parties : la liste des commandes (Figure 3.a), l’éditeur de programme (Figure 3.b), c’est-à-dire le champ où s’écrit le programme après avoir cliqué sur une des commandes de la liste des commandes (c’est aussi dans ce champ que vous pouvez écrire vous-même votre programme une fois que vous serez à l’aise avec le code de programmation d’Epi Info !), la sortie des résultats de l’analyse statistique (Figure 3.c), la sortie pour les éventuels messages d’erreurs (Figure 3.d). Les commandes listées dans la liste des commandes se regroupent en neuf sections (Figure 3.a). Je vais décrire très succinctement les cinq premières sections, car ce sont certaines commandes de ces sections que je vais traiter dans ce guide. Les commandes sous « Data » permettent de créer une base de données, soit à partir d’un import, soit à partir de bases de données existantes, soit à partir d’un export (Figure 4.a). Les commandes sous « Variables » permettent de créer des variables dans le fichier de données en cours de lecture (Figure 4.b). Les commandes sous « Select/if » permettent (entre autres) de travailler sur une sélection de lignes du fichier de données (Figure 4.c). Les commandes sous « Statistics » permettent de réaliser des statistiques simples (pourcentages, moyennes, médianes, tests statistiques classiques, graphiques) (Figure 4.d). Les commandes sous « Advanced statistics » permettent de réaliser des statistiques avancées (entre autres des modèles de régression et des courbes de survie de Kaplan-Meier) (Figure 4.e). Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 6
Figure 4 II. Quelques rappels indispensables A. Ressources utilisées dans ce guide Je ferai de temps en temps référence au cours de ce guide à quatre documents téléchargeables sur Internet : un polycopié de bases en biostatistique et un document « Utilisation d’Excel et du site Internet BiostaTGV pour réaliser quelques statistiques de base » (tous deux disponibles ici, sous « Bases en Biostatistique »), un polycopié d’analyse de survie (disponible ici, sous « Analyse de survie »), et un polycopié d’épidémiologie clinique (disponible ici, sous « Epidémiologie clinique »). Ces documents contiennent les bases théoriques de ce que je vais présenter ici. En effet, à part pour les modèles de régression, je ne présenterai ici aucun aspect théorique (ou alors, très peu), et je vous recommande de vous référer à ces documents pour ces aspects théoriques. B. Rappel sur la structure d’un fichier de données pour analyses statistiques Avant une analyse statistique, un fichier de données doit être structuré de façon rigoureuse pour ensuite conduire des analyses statistiques sur ces données. Pour vérifier cette structure, je vous propose de lire le document « Comment structurer un fichier de données Excel avant analyses statistiques » ici, dans la partie intitulée « Collecte des données d'une enquête épidémiologique et structure d'un fichier de données ». Vous y verrez notamment que le fichier de données doit comporter le nom des variables sur la première ligne, et les individus sont présentés en ligne. Pour être analysable statistiquement, une variable doit être numérique. C’est-à-dire qu’elle doit être renseignée pour chaque individu sous forme d’un nombre. Ce nombre affecté à chaque individu varie selon le type de variable. Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 7
C. Définitions de critère de jugement, d’exposition, et de variable Le « critère de jugement »2 (abrégé « CdJ » à partir de maintenant) est l’état de santé que l’on étudie seul (de façon descriptive), ou bien dont on étudie l’association avec une ou plusieurs « expositions ». Une « exposition » est une caractéristique intrinsèque d’un animal (âge, sexe, race, concentration en urée, …), ou extrinsèque (environnement, traitements reçus, …), qui ne soit pas le CdJ étudié. Une « variable » représente une caractéristique d’un individu dans le fichier de donnée. Par exemple, si l’on veut savoir si, parmi les chiens, la présence d’une hypercholestérolémie est associée à la présence d’un décès dans les 3 ans suivant une consultation vétérinaire, l’exposition est la présence (versus absence) d’une hypercholestérolémie, le CdJ est la présence (versus absence) d’un décès dans les 3 ans. Dans le fichier de données, l’exposition sera représentée, par exemple, par la variable HYPERCHOLESTEROLEMIE, le CdJ sera représenté, par exemple, par la variable DECES_3ANS. Dans ce guide, j’écrirai en majuscules sans guillemets le nom des variables utilisées. Il existe quatre types de variables que je vais présenter ci-dessous. Dans toute la suite de ce guide, je ne vais quasiment plus parler que de « variable » (sauf exception), même si parfois, le terme « exposition » aurait été plus pertinent. D. Rappel sur les différents types de variables 1. Variables binaires Une variable binaire est une variable à deux modalités (ou classes). On peut citer comme exemple le sexe d’un animal (mâle ou femelle) ou la présence ou absence d’une maladie. Par convention, il est recommandé de coder en 0/1 dans le fichier de données une variable binaire (et en l’occurrence, pour interpréter les sorties d’Epi Info, je vous recommande très fortement de coder les variables binaires en 0/1). Le nom d’une variable binaire devrait être le nom de la modalité pour laquelle « 1 » a été attribué (c’est un conseil que je vous donne pour grandement faciliter l’interprétation des résultats fournis par le logiciel). Par exemple, si pour le sexe de l’animal, dans le fichier de données, « 1 » a été attribué aux femelles et « 0 » aux mâles, la variable devrait être nommée « Femelle » dans le fichier de données. Dans le cas d’une exposition binaire, la catégorie « exposée » est celle pour laquelle « 1 » a été attribuée à la variable correspondante, et la catégorie « non exposée » est celle pour laquelle « 0 » a été attribuée à cette même variable. De même, dans le cas d’une maladie binaire, la catégorie « malade » est celle pour laquelle « 1 » a été attribuée à la variable correspondante, et la catégorie « non malade » est celle pour laquelle « 0 » a été attribuée à cette même variable. 2. Variables qualitative nominales Une variable qualitative nominale est une variable avec trois modalités ou plus, chacune des modalités n’étant a priori pas ordonnée les unes par rapport aux autres. On peut citer comme exemple la race d’un animal. Le codage d’une variable qualitative nominale peut être en 0/1/2/etc. ou bien en 1/2/3/etc. 2 « outcome » en anglais Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 8
3. Variables qualitative ordinales Une variable qualitative ordinale est une variable avec trois modalités ou plus, chacune des modalités étant ordonnée les unes par rapport aux autres. On peut citer comme premier exemple le format de la race d’un chien (petite race, race moyenne, grande race, race géante). Une variable qualitative ordinale peut aussi être obtenue à partir d’un recodage en classes d’une variable initialement quantitative, comme par exemple le temps passé par semaine à jouer avec son chien (0-30 min, 30 min – 2 heures, 2-3 heures, > 3 heures). 4. Variables quantitatives Une variable quantitative est une variable continue avec un chiffre après la virgule (existant, ou possible si l’instrument de mesure était idéalement très précis) ou bien une variable discrète représentant un dénombrement. On peut citer comme exemple l’âge d’un animal, un score clinique recueilli à partir d’une échelle sur 10 points, ou bien le nombre de nodules cutanés. III. Présentation du fichier de données fictif Le fichier de données qui va être utilisé dans ce guide est un fichier de données fictif, provenant d’une étude prospective, fictive elle aussi, mais s’inspirant d’une précédente étude (Hua et al., 2016). Cette étude a recruté 99 chiens adultes qu’elle a suivis au cours des années à partir d’une consultation chez un vétérinaire (J0), avec un suivi minimum de 3 ans. Il n’y a eu aucun perdu de vue. Les variables contenues dans ce fichier de données sont listées ci-dessous. DECES : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien était toujours en vie à la fin de l’étude, « 1 » s’il était décédé (quelle que soit la cause du décès) au cours de l’étude. DECES_3_ANS : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien était toujours en vie 3 ans après l’inclusion dans l’étude, « 1 » s’il était décédé dans les 3 ans après l’inclusion. SURVIE : variable quantitative représentant le délai, en années (avec 1 chiffre après la virgule), entre la date d’inclusion dans l’étude (le J0) et soit la date de fin d’étude pour les chiens toujours en vie à la fin de l’étude soit la date de décès pour les chiens décédés. RACE_4CL : variable qualitative nominale, codée en 0/1/2/3. Elle vaut « 0 » pour les chiens de race Golden, « 1 » pour la race Labrador, « 2 » pour la race croisée Golden/Labrador, « 3 » pour une autre race. LABRADOR : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien n’était pas de race Labrador, « 1 » s’il l’était. GOLDEN : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien n’était pas de race Golden, « 1 » s’il l’était. CROISEE : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien n’était pas de race croisée Golden/Labrador, « 1 » s’il l’était. AUTRE_RACE : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien était de race Labrador, Golden, ou de race croisée Golden/Labrador, et « 1 » s’il était d’une autre race. FEMELLE : variable binaire, codée en 0/1, « 0 » si le chien était un mâle, « 1 » s’il était une femelle. AGE : variable quantitative représentant l’âge du chien à la consultation, en années entières. AGE_4CL : variable qualitative ordinale, codée en 0/1/2/3 à partir des quartiles de la variable AGE. Cette variable vaut « 0 » pour les chiens avec dont l’âge est < 7 ans, « 1 » pour les chiens avec un âge compris entre 7 et 9 ans (exclu), « 2 » pour les chiens avec un âge compris entre 9 et 11 ans (exclu), et « 3 » pour les chiens avec un âge supérieur ou égal à 11 ans. Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 9
ALAT : variable quantitative représentant la concentration en ALAT, en UI/L. UREE : variable quantitative représentant la concentration en urée, en g/L. UREE_4CL : variable qualitative ordinale, codée en 0/1/2/3 à partir des quartiles de la variable UREE. Cette variable vaut « 0 » pour les chiens avec une concentration en urée < 0,24 g/L, « 1 » pour les chiens avec une concentration en urée comprise entre 0,24 g/L et 0,28 g/L (exclu), « 2 » pour les chiens avec une concentration en urée comprise entre 0,28 g/L et 0,33 g/L (exclu), et « 3 » pour les chiens avec une concentration en urée supérieure ou égale à 0,33 g/L. CHOLES_3CL : variable qualitative ordinale, codée en 0/1/2. Elle vaut « 0 » pour les chiens avec une hypocholestérolémie, « 1 » pour les chiens avec une normocholestérolémie, et « 2 » pour les chiens avec une hypercholestérolémie. HYPER_CHOLES : variable binaire, codée en 0/1. Elle vaut « 0 » si le chien ne présentait pas d’hypercholestérolémie, et « 1 » s’il en présentait une. DEMARCHE_ANORMALE : variable binaire, codée en 0/1, « 0 » si le chien avait une démarche normale, « 1 » s’il avait une démarche anormale. CONSTANTE : variable créée pour l’utilisation d’EI, valant « 1 » pour tous les chiens de l’échantillon (utile uniquement dans le cas de la réalisation d’un courbe de Kaplan-Meier globale). IV. Importer les données à analyser et sauvegarder un programme A. Création préalable d’un « projet » Avant de commencer à importer un fichier Excel pour ensuite l’analyser statistiquement dans Epi Info, je vous recommande de créer un « projet » au préalable. Cela vous permettra d’enregistrer votre programme comprenant toutes vos analyses statistiques. Pour cela, après avoir lancé Epi Info, on clique sur « Create Forms » (cf. Figure 5.a). Figure 5 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 10
Ensuite, on clique sur « New project » (Figure 6.a), on remplit le champ « Name » avec un nom de votre choix (Figure 6.b), on clique sur « Browse » (Figure 6.c) pour choisir d’enregistrer ce projet à l’emplacement de votre choix, on met ce que l’on veut dans le champ « Form name » (Figure 6.d), puis on clique sur « Ok » (Figure 6.e). Figure 6 On ferme ensuite la fenêtre qui apparait, en cliquant sur « File » → « Exit » (cf. Figure 7). Figure 7 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 11
B. Importation de données d’un fichier Excel (ou sous un autre format) Avant d’importer un fichier de données, vous devez vous assurer de l’avoir enregistré sous format .xls (ce qui est possible si vous utilisez le logiciel LibreOffice Calc). Pour importer un fichier .xls, tout comme pour réaliser les analyses statistiques, on clique sur « Classic » dans la fenêtre de démarrage d’Epi Info (cf. Figure 8). Figure 8 On clique ensuite sur « Read » (Figure 9.a), on sélectionne « Microsoft Excel 97-2003 » (Figure 9.b), on va chercher le fichier de données .xls en cliquant sur « Browse » deux fois ((Figure 9.c) et (Figure 9.d)), on clique sur « First row contains header information » (parce que la première ligne du fichier de données comporte le nom des variables ; Figure 9.e), on clique sur « Ok » (Figure 9.f), on sélectionne l’onglet qui comprend les données que l’on souhaite analyser (Figure 9.g), et on clique sur « Ok » (Figure 9.h). Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 12
Figure 9 Dans la sortie des résultats (Figure 10.a), Epi Info indique que votre fichier a été importé, et qu’il comprend 99 individus (devant « Record Count »). Le programme d’import de vos données a été automatiquement écrit dans la fenêtre d’éditeur de programme (Figure 10.b). Figure 10 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 13
C. Sauvegarder son programme Pour éviter de refaire la même (et longue) manipulation d’import de données, pour éviter de retaper systématiquement votre programme, et/ou pour garder une trace (indispensable) de toutes vos analyses que vous avez réalisées sur un fichier de données, il est indispensable d’enregistrer votre programme. Pour cela, on clique sur « Save pgm » dans l’éditeur de programme (Figure 11.a), on sélectionne son projet (Figure 11.b), on tape le nom du programme de son choix (Figure 11.c), puis on clique sur « Ok » (Figure 11.d). Figure 11 Une fois cette première étape d’enregistrement réalisée, on n’aura qu’à cliquer sur « Save pgm » au fur et à mesure des analyses (Figure 12.a) (vous devrez néanmoins suivre à nouveau les étapes décrites sur la Figure 11). Figure 12 A la fin de la journée de travail, on enregistre le programme une dernière fois. Le lendemain, pour reprendre le travail, on cliquera sur « Open Pgm » (Figure 12.b) (et on sélectionnera le projet puis le programme enregistré la veille). Ensuite, pour exécuter certaines lignes du programme (et notamment, la première qui correspond à l’import du fichier de données au moment de recommencer à utiliser Epi Info après une bonne nuit de sommeil), on sélectionne la ligne de commande à exécuter (en double- cliquant dessus), puis on clique sur « Run Commands » (Figure 12.c). Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 14
Chapitre 2 – Analyses statistiques de base I. Introduction A. Vérifications préliminaires avant les analyses statistiques Avant de commencer à faire des analyses statistiques, il est indispensable de vérifier que les variables sur lesquelles vous comptez travailler sont bien des variables numériques. Pour cela, on clique sur « Display » (Figure 13.a), puis sur « Ok » (Figure 13.b). Figure 13 On obtient le résultat ci-dessous. Dans la colonne « Field Type » (Figure 14.a), on voit bien que toutes les variables du fichier de données sont bien numériques (« Number » indiqué dans la colonne). Il est fondamental de bien vérifier que toutes les variables que vous souhaitez utiliser dans vos analyses statistiques sont effectivement numériques. Si tel n’est pas le cas pour une variable, alors vous devez retourner sur votre fichier Excel de données, et trouver la raison pour laquelle Epi Info considère la variable comme du texte, et non pas de façon numérique. Sachez que nettoyer un fichier de données pour que toutes les variables que vous voulez utiliser pour vos analyses statistiques soient numériques est une tâche qui prend souvent beaucoup de temps, et une tâche sur laquelle on avait tout sauf prévu de passer du temps ! Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 15
Figure 14 Ensuite, on pourrait vouloir vérifier visuellement la structure et le contenu du fichier de données qui a été importé. Pour cela, on clique sur « List » (Figure 15.a), puis sur « Ok » (Figure 15.b). Figure 15 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 16
On obtient la base de données sur laquelle on va travailler (cf. Figure 16). Figure 16 Maintenant, nous sommes prêts à réaliser les analyses statistiques à partir des données, qui sont « propres », du fichier de données. B. Convention de présentation des résultats issus des copies d’écran d’Epi Info Lorsque je vais écrire les résultats statistiques qu’Epi Info fournit, je ne vais volontairement faire aucun arrondi, pour que vous puissiez repérer tout de suite où se trouve, dans la copie d’écran, les chiffres que je mentionne. Une exception néanmoins à cela : lorsque je mentionnerai les Odds Ratios ou Hazard Ratio fournis par le logiciel dans le Chapitre III sur les modèles de régression, que j’arrondirai à deux chiffres après la virgule. II. Statistiques descriptives A. Décrire une variable binaire ou qualitative Pour décrire une variable binaire ou qualitative, nous allons utiliser le « tableau de fréquences », qui est un tableau qui présente les effectifs et les pourcentages pour chaque modalité d’une variable binaire ou qualitative. Nous allons prendre pour l’exemple la variable RACE_4CL. Pour obtenir le tableau de fréquences, on clique sur « Frequencies » (Figure 17.a), on sélectionne la variable RACE_4CL dans la liste déroulante (Figure 17.b), puis on clique sur « Ok » (Figure 17.c). Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 17
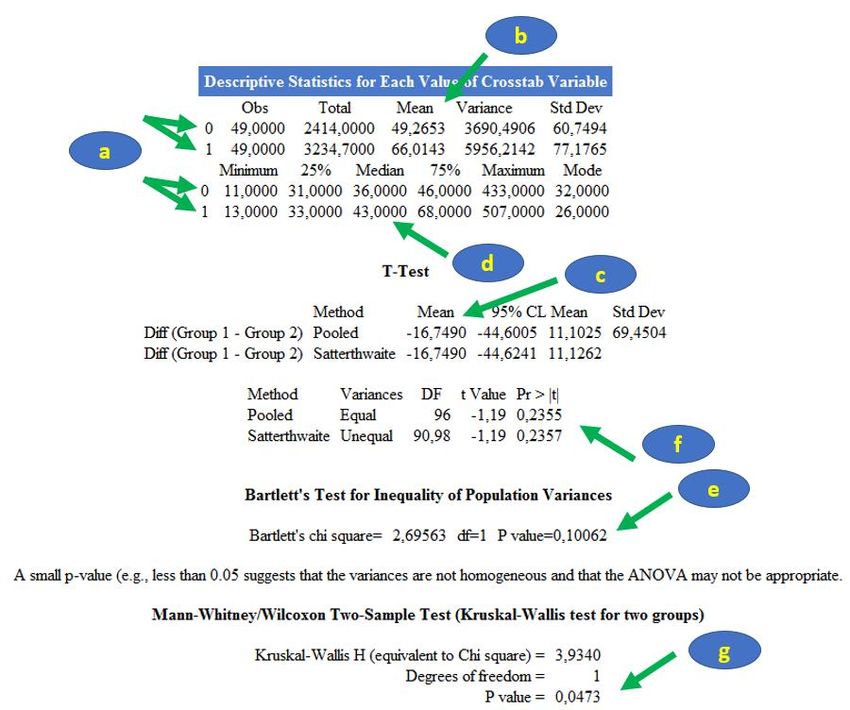
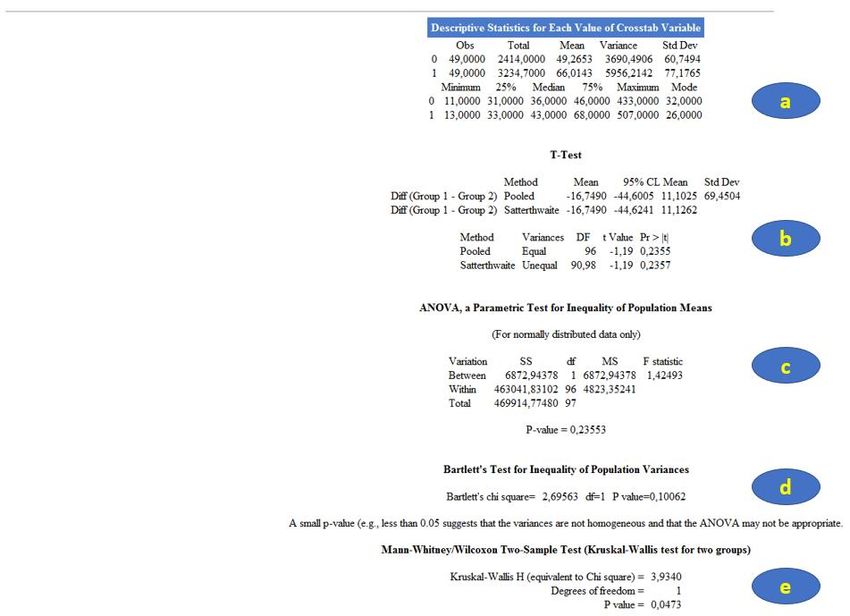
Figure 17 Le résultat est présenté sur la Figure 18. On peut lire que les chiens de race Golden (RACE_4CL = 0) sont au nombre de 23, ce qui représente 23,23% de l’échantillon des 99 chiens (Figure 18.a). L’intervalle de confiance à 95% (noté « IC95% » dans toute la suite de ce guide) de chaque pourcentage est fourni par Epi Info (Figure 18.b). Celui du pourcentage de Golden de 23,23% est : [15,33% ; 32,79%]95%. Figure 18 B. Décrire une variable quantitative Pour vous montrer comment obtenir avec Epi Info les différents indicateurs statistiques décrivant une variable quantitative, nous allons prendre pour l’exemple la variable ALAT. Pour cela, on clique sur « Means » (Figure 19.a), on sélectionne la variable « ALAT » (Figure 19.b), puis on clique sur « Ok » (Figure 19.c). Figure 19 Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 18
On obtient alors le résultat présenté sur la Figure 20. On observe ainsi qu’il y a 98 données non manquantes sur les ALAT (« Obs = 98,000 »), donc il y a une donnée manquante sur ce paramètre biologique (puisqu’il y a 99 chiens dans l’échantillon). La moyenne de la concentration en ALAT est de 57,6398 UI/L, la Standard Deviation3 (SD) de 69,6023 UI/L, le minimum de 11 UI/L, le 1er quartile (25ème percentile) de 32 UI/L, la médiane de 39 UI/L, le 3ème quartile (75ème percentile) de 53 UI/L, et le maximum de 507 UI/L. Figure 20 Je n’ai pas trouvé le moyen de dresser un histogramme avec Epi Info. C’est dommage. Pour cela, je vous recommande la lecture de la partie « Vérifier la normalité d’une variable quantitative » dans le document « Utilisation d’Excel et du site Internet BiostaTGV ». III. Association statistique entre deux variables A. Croisement de deux variables binaires ou qualitatives, et test statistique 1. Introduction Le croisement de deux variables (binaires ou qualitatives) permet d’étudier l’association entre ces deux variables. Je ne reviendrai pas dans ce guide sur la façon de correctement lire un tableau croisant deux variables (notamment, savoir faire la distinction entre les « bons » et les « mauvais » pourcentages à citer). Si ce n’est pas clair pour vous, relisez certaines parties du polycopié de biostatistique. 2. Croisement de deux variables binaires Nous allons prendre pour l’exemple les deux variables suivantes : FEMELLE et DECES_3_ANS. Pour croiser ces deux variables, on clique sur « Tables » (Figure 21.a), on sélectionne ensuite sous « exposure variable » la variable qui joue le rôle d’exposition (ici, FEMELLE ; Figure 21.b) et sous « outcome variable » celle qui joue le rôle du CdJ (ici, DECES_3_ANS ; Figure 21.c), puis on clique sur « Ok » (Figure 21.d). 3 Cf. polycopié de biostatistique. Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 19
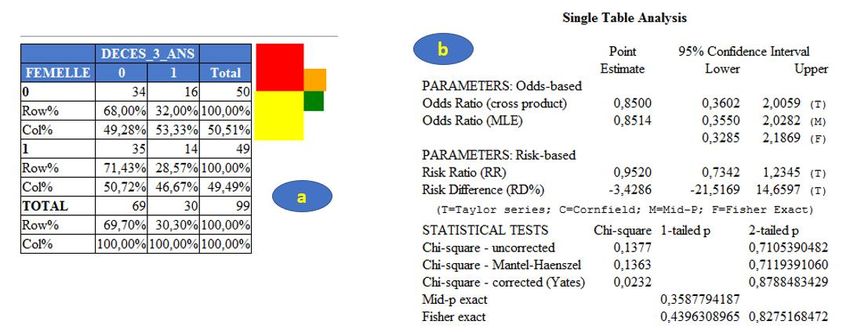
Figure 21 On obtient alors la sortie de résultats sur la Figure 22, qui comporte deux parties : le tableau d’effectifs et de pourcentages (Figure 22.a) et d’autres indicateurs statistiques (Figure 22.b). Figure 22 Je vais tout d’abord me focaliser sur le tableau d’effectifs et de pourcentages. Tout d’abord, Epi Info fournit une représentation graphique (sommaire) de la répartition des effectifs dans chacune des cases du tableau (Figure 23.a). La surface des carrés de couleurs est proportionnelle aux effectifs dans chacune des quatre cases : 34 chiens non décédés dans les trois ans (rouge), 16 chiens décédés dans les trois ans (orange), 35 chiennes non décédées dans les trois ans (jaune), et 14 chiennes décédées dans les trois ans (vert). Les effectifs (b) de la Figure 23 nous renseignent sur le fait qu’il y a en tout 69 chiens non décédés dans les trois ans, et 30 chiens décédés dans les trois ans (avec un total bien évidemment de 99 chiens). Ensuite, l’indication « Row% » (Figure 23.c) signifie que les pourcentages sur cette ligne sont des pourcentages en ligne (donc lecture horizontale) : parmi les 50 chiens mâles (FEMELLE = 0), 34 ne sont pas décédés dans les trois ans, et 34/50 = 68,00%. Enfin, l’indication « Col% » (Figure 23.c) signifie que les pourcentages dans cette colonne sont des pourcentages en colonne (donc lecture verticale) : parmi les 69 chiens non décédés dans les trois ans, 34 sont des mâles, et 34/69 = 49,28%. Pour savoir si ces deux variables binaires sont associées, quatre couples de pourcentages peuvent être calculés et être comparés. Je vais choisir les deux pourcentages (en ligne) suivants : le pourcentage de chiens décédés parmi les chiens mâles (16/50=32,00%) et le pourcentage de chiens décédés parmi les chiens femelles (14/49=28,57%) (Figure 23.d). Dans l’échantillon, le pourcentage de chiens décédés est légèrement inférieur parmi les chiens femelles que parmi les chiens mâles (28,57% Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 20
< 32,00%). Numériquement, ces deux pourcentages étant très proches, dans l’échantillon, l’association entre le sexe du chien et le fait qu’il soit décédé dans les trois ans est quasi inexistante. Figure 23 Passons maintenant à la sortie des autres indicateurs statistiques. La partie (a) de la Figure 24 concerne les tests statistiques testant l’association entre les deux variables (FEMELLE et DECES_3_ANS). Vous voyez que trois lignes sont dévolues au test du Chi-2, une ligne au test du mid-p, et une ligne au test exact de Fisher. Si Epi Info ne mentionne pas en bas de la sortie (a) de la Figure 24 « At least one cell has expected size
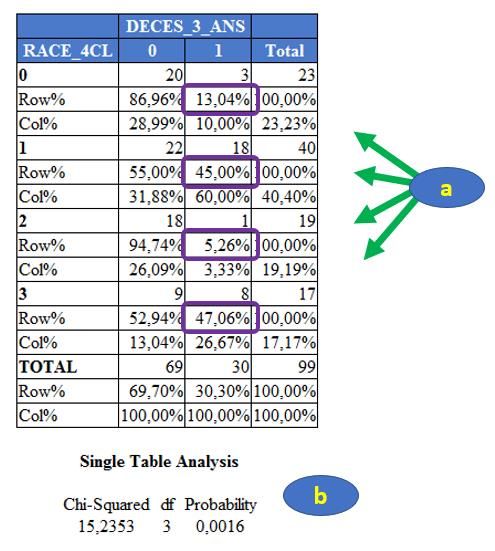
Figure 24 Epi Info fournit aussi les indicateurs statistiques qui permettent de quantifier l’association entre deux variables binaires : l’Odds Ratio (OR) et le Risque Relatif (RR). Je n’entrerai pas dans les détails du calcul de ces deux indicateurs, mais si cela vous intéresse, vous pourrez lire les parties du polycopié d’épidémiologie clinique qui sont consacrées à ces indicateurs. Dans la partie (b) de la Figure 24, il y a deux OR. En fait, c’est parce qu’Epi Info calcule l’OR de deux façons différentes : le produit en croix (« cross product »), et par l’estimation du maximum de vraisemblance (MLE6). Je vous recommande l’estimation selon le produit en croix. Ainsi, dans la mesure où la catégorie « exposée » est celle des chiens femelles (car le « 1 » pour la variable FEMELLE concerne les chiens femelles ; cf. Chapitre 1, Partie II.D.2, page 8), et dans la mesure où les chiens présentant le CdJ sont les chiens décédés dans les trois ans (car le « 1 » pour la variable DECES_3_ANS concerne les chiens décédés), l’OR Femelles versus mâles = 0,8500 [0,3602 ; 2,0059]95%. Cet OR est plus petit que « 1 », et c’est normal, puisque nous avions vu précédemment que la proportion de chiens présentant le CdJ (les chiens décédés) était (légèrement) inférieure parmi les chiens « exposés » (les chiens femelles) que parmi les chiens « non exposés » (les chiens mâles). La valeur du RR correspondante est de 0,9520 [0,7342 ; 1,2345]95% (Figure 24.c). 3. Croisement d’une variable binaire avec une variable qualitative Nous allons prendre pour l’exemple les deux variables suivantes : RACE_4CL et DECES_3_ANS. Pour croiser ces deux variables, nous utilisons la même démarche que celle décrite dans la Figure 21, sauf que nous sélectionnons la variable RACE_4CL au lieu de la variable FEMELLE. Nous obtenons les résultats présentés sur la Figure 25. 6 MLE = maximum likelihood estimation (plus d’infos ici) Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 22
Figure 25 Nous pouvons déjà observer qu’il y a beaucoup moins de résultats statistiques que sur la Figure 22 ! Les pourcentages qui doivent être comparés pour savoir s’il existe une association entre la race et la présence d’un décès sont les pourcentages suivants : le pourcentage de chiens décédés parmi les chiens de race Golden (3/23 = 13,04%), le pourcentage de chiens décédés parmi les chiens de race Labrador (18/40 = 45,00%), le pourcentage de chiens décédés parmi les chiens de race croisée Golden/Labrador (1/19 = 5,26%), et le pourcentage de chiens décédés parmi les chiens d’autre race (8/17 = 47,06% ; Figure 25.a). Dans la mesure où Epi Info n’indique pas « An expected value is < 5. Chi-squared may not be a valid test. », le test du Chi-2 est valide, et son degré de signification se lit sur la sortie : 0,0016 (Figure 25.b). (Si au moins un des effectifs attendus avait été inférieur à 5, alors il aurait fallu réaliser le test statistique de Fisher, qui n’est pas proposé par Epi Info dans le cas de croisement d’une variable binaire avec une variable qualitative. Dans ce cas-là, je vous recommande d’utiliser le site Internet BiostaTGV7.) Le degré de signification étant inférieur à 0,05, on peut dire qu’il existait dans l’échantillon une association significative entre la race et le décès du chien. 4. Croisement de deux variables qualitatives Cette situation produisant un tableau à plus de deux lignes et plus de deux colonnes, elle conduit à des résultats ininterprétables : les pourcentages à comparer, qui sont testés par le test statistique du Chi- 2, ne peuvent pas s’exprimer de façon claire et intelligible. Je ne fournirai donc aucun exemple d’une telle situation, et je vous invite plus que fortement à rendre binaire (au moins) une des deux variables lorsque vous souhaitez croiser deux variables qualitatives. Par exemple, si vous souhaitiez savoir s’il existe une association entre la race (en 4 classes, avec la variable RACE_4CL) et la cholestérolémie (en 3 classes, avec la variable CHOLES_3CL), il aurait fallu soit recoder la variable RACE_4CL en une variable 7 https://biostatgv.sentiweb.fr/?module=tests/fisher. Licence Creative Commons – Guide d’utilisation d’Epi Info 7 – Loïc Desquilbet – Version v1.0 23
Vous pouvez aussi lire

















































