L'informatique : la science au coeur du numérique
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Académie des Sciences et Lettres de Montpellier 1
Séance du 29 Mai 2017
L’informatique : la science au cœur du numérique
Michel CHEIN
Professeur émérite d’informatique à l’Université de Montpellier
MOTS-CLÉS
Informatique, numérique, discrétisation, numérisation, programmation,
machine de Turing, réseaux.
RÉSUMÉ
Cet article vise au moins deux buts : indiquer quelques pistes pour comprendre
que l’informatique est une science autonome (et complexe) et pas un conglomérat
d’outils disparates ou une partie des mathématiques et s’interroger sur l’usage extensif
du terme numérique en lieu et place de celui d’informatique.
1 Introduction
Tout le monde a entendu parler du bitcoin, la monnaie informatique qui a été
rendue possible grâce à la technologie des « blockchains » (cf. par exemple [1])
Cependant, même si la création du bitcoin connait un succès certain, la
technologie sous-jacente semble porteuse de nombreux espoirs et The Economist titrait,
sur sa couverture de novembre 2015, Comment la technologie des blockchaines
pourrait changer le monde.
Une blockchaine serait, comme l’écrit Jean-Paul Delahaye, « un très grand
cahier que, librement et gratuitement, tout le monde puisse lire, sur lequel chacun
puisse écrire, mais qui soit impossible à modifier et indestructible. Pour que cela soit
commode et pour empêcher les tricheurs de prendre des engagements en votre nom ou
écrire en se faisant passer pour vous, il faudrait que l'on puisse signer les messages
déposés de telle façon que personne ne puisse se substituer à vous. Il serait utile aussi
que l'instant précis où est inscrit un texte soit indiqué à chaque fois (horodatage). Cette
idée d'un grand cahier informatique, partagé, infalsifiable et indestructible du fait
même de sa conception est au cœur d'une nouvelle révolution, celle de la blockchaine,
ou plus explicitement et en français : la révolution de la programmation par un fichier
partagé et infalsifiable. »
Pour les promoteurs des blockchaines cette technologie est une des
technologies structurantes de la prochaine décennie, elle serait disruptive dans le sens
où, appelée parfois « The world computer », elle devrait permettre, dit le Livre blanc
sur la technologie blockchaine, « à tout développeur de concevoir et distribuer des
projets qui repensent les organisations politiques (régulations, démocratie, …),
économiques (gouvernance d’entreprise, modèles économiques,…) et sociales (gestion
des organisations, …). »
Dans la figure 1 ci-dessous, extraite de ce même livre blanc, des outils sont
mentionnés mais ce qui n’est pas dit c’est que ces outils utilisent de très nombreuses
notions informatiques : réseau pair-à-pair, protocole, fonction de hachage, clé
publique-clé privée, preuve de travail, horodatage, fichier partagé, etc… et des
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)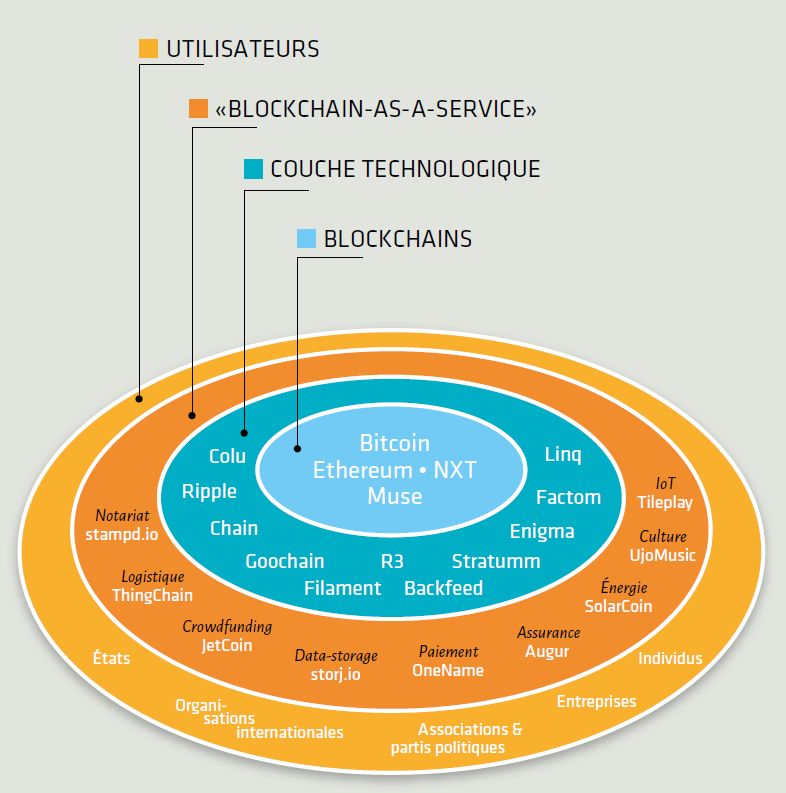
2 Communications présentées en 2017
algorithmes, des algorithmes et encore des algorithmes ! Ce n’est qu’en ayant une idée
de ce que l’on peut faire et ne pas faire avec ces notions informatiques, que l’on peut
avoir une idée sur la réponse à la question : « les blockchaines : rêve ou cauchemar ? »
Ou, plus prosaïquement pour un entrepreneur, j’investis ou non, et combien dans cette
technologie ?
Figure 1 : Blockchaines
Dans ces différentes notions informatiques, on utilise peu ou pas de
mathématiques, peu ou pas de nombres, essentiellement quelques résultats simples
concernant les probabilités et les nombres entiers (en particulier la difficulté du
problème de factorisation). Ces mathématiques sont compréhensibles par un lycéen en
terminal scientifique, ce sont des mathématiques basiques par rapport aux
mathématiques utilisées, par exemple, en physique et pourtant tout est numérique
aujourd’hui, même la République ! Depuis la loi pour une République numérique
d’octobre 2016 il faudrait modifier l’article premier de la Constitution en le faisant
commencer par « La France est une République indivisible, laïque, démocratique,
sociale et numérique … ».
Il ne faut plus dire l’INRIA, acronyme de Institut national d’informatique et
d’automatique mais Inria, qui est devenu un nom propre … et, accompagnant le logo
publique d’INRIA on trouve le slogan « inventeurs du monde numérique ».
L’accroche de l’INS2I, qui est toujours l’Institut des sciences de l’information et de
leurs interactions, est « L’excellence scientifique au service de la révolution
numérique ». Une manière de voir ce que recouvre le terme numérique est de lire les
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)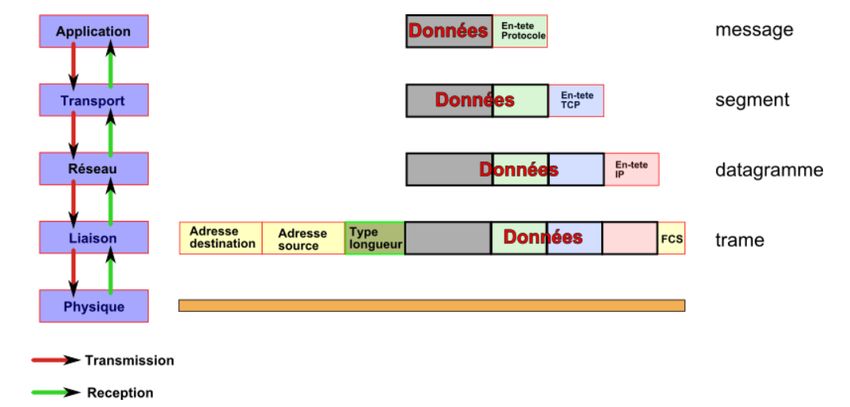
Académie des Sciences et Lettres de Montpellier 3
objectifs de ces deux organismes ; on peut aussi feuilleter le Journal du CNRS. En
effet, les rubriques actuelles de ce journal sont les suivantes : Vivant, Matières,
Sociétés, Univers, Terre, Numérique … voici les titres de quelques articles étiquetés
« Numérique » : La justice à l’ère du numérique, Le numérique nous fait-il perdre la
mémoire ?, Le tourisme en mode numérique, La justice à l’heure des algorithmes et du
big data, Les premiers pas de la robotique aérienne, L'intelligence artificielle devient
stratège, Les algorithmes menacent-ils la démocratie?, Les défis de l’Internet des
objets, Protection des données: le chiffrement ne suffit pas, Claude Shannon, le père du
binaire, Les premiers pas de la robotique aérienne, De l’égyptologie aux robots, les
sciences humaines innovent, Comment classer les joueurs d’échecs?, Voici Pyrène, le
nouveau robot humanoïde, Traduire comme on joue au Go ?
A la place de numérique on utilise aussi parfois, dans certains domaines,
digital. Dans sa séance du 7 novembre 2013, l’Académie Française dans sa rubrique
dire, ne pas dire déclare : « L’adjectif digital en français signifie « qui appartient aux
doigts, se rapporte aux doigts ». Il vient du latin digitalis, « qui a l’épaisseur d’un
doigt », lui-même dérivé de digitus, « doigt ». C’est parce que l’on comptait sur ses
doigts que de ce nom latin a aussi été tiré, en anglais, digit, « chiffre », et digital, « qui
utilise des nombres ». On se gardera bien de confondre ces deux adjectifs digital, qui
appartiennent à des langues différentes et dont les sens ne se recouvrent pas : on se
souviendra que le français a à sa disposition l’adjectif numérique ». Digital est peu
utilisé en France, dans la communication ce terme est parfois utilisé pour insister sur
l’utilisateur, ce qui est devant l’écran, numérique étant réservé à ce qui est derrière
l’écran. Cet usage a suscité certaines plaisanteries pas toujours de bon goût (Figure 2) !
Figure 2 Digital ?
Même si cette expression sonne comme un oxymore aux oreilles de
certains, on parle aussi d’Humanités digitales, un manifeste des Digital Humanities a
été publié en français en 2010 sous ce titre anglais ! …
Pour faire la part des choses entre numérique, digital et informatique, en
français, on peut se rappeler que numérique a d’abord été utilisé comme un adjectif, un
appareil photo numérique ou une montre à affichage numérique, avant d’être
substantivé.
2 Informations numériques ou discrètes ?
L’informatique étant souvent définie comme étant la science du traitement
rationnel et automatique de l’information, commençons par dire un mot de ces
informations en nous posant la question est-ce-que ce sont des informations
numériques ou numérisées ?
Au début est le codage des caractères. Prenons l’exemple du codage ISO/CEI
8859-1, appelé Latin-1, extension du codage ASCII de 128 caractères. Dans ce codage,
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)4 Communications présentées en 2017
qui permet de représenter 256 caractères, la lettre A majuscule est représentée par 65
en notation décimale, et la lettre B majuscule par 66, mais ce ne sont pas des nombres :
AB est représenté par 6566, on n’additionne pas on concatène ! Au lieu d’utiliser la
notation décimale, on utilise souvent la notation hexadécimale qui est basée sur un
alphabet de 16 lettres (0, 1, 2, …, 9, A, B, C, D, E, F) et des mots de deux lettres soit
256 (= 16x16) mots.
On peut aussi représenter ces 256 éléments par des octets. Un octet c’est
simplement un mot de 8 lettres construit avec un alphabet n’ayant que deux lettres.
L’ensemble de ces 256 mots de huit lettres construits avec l’alphabet contenant
exclusivement les lettres a et b est, dans l’ordre alphabétique : aaaaaaaa, aaaaaaab,
aaaaaaba, …, bbbbbbbb.
Au lieu de considérer des lettres on utilise souvent les chiffres 0 et 1, mais on
ne fait pas d’arithmétique, même binaire, dans ce cas, ce ne sont pas des nombres ! Un
bit est une unité élémentaire d’information qui peut simplement prendre deux valeurs
distinctes mais qui est rarement considérée comme un nombre ! Insistons, il ne s’agit
pas de compter mais simplement de coder, de représenter un certain nombre d’éléments
différents par un codage univoque.
On appelle langage formel, en informatique, un ensemble de mots construits
sur un alphabet et un mot est simplement une séquence d’éléments de cet alphabet
(pour simplifier nous ne considérerons que des alphabets et des mots ayant un nombre
fini d’éléments). Les langages formels, dont les codages décrits ci-dessus ne sont que
des exemples très simples et les langages de programmation des exemples plus
complexes, sont une des notions fondamentales de l’informatique.
Voici un exemple simple de propriété d’un langage formel que l’on étudie
dans le cas des codes. Un langage est dit préfixe lorsqu’aucun mot n’est préfixe d’un
autre. Tous les codes de longueur fixe sont préfixes mais construire des codes préfixes
dont tous les mots n’ont pas la même longueur peut permettre de construire des
codages courts en codant les lettres de telle sorte que plus une lettre est fréquente plus
son code est petit.
Considérons par exemple le mot baabccabdbaa. Dans ce mot de 12 lettres, a
apparait cinq fois, b quatre fois, c deux fois et d une fois. Avec le code préfixe suivant :
code(a)=0, code(b)=10, code(c)=110, code(d)=111, le codage du mot baabccabdbaa est
1000101101100101111000, dont la longueur est 22. Alors qu’en utilisant le codage
Latin-1 on obtient un mot de longueur est de 12x8 = 96.
Considérons un langage que tous ceux qui ont fait du scoutisme connaissent
bien : le code Morse. Ce code, de longueur variable, n’est pas préfixe ce qui oblige à
séparer les lettres, par exemple le codage de SOS en Morse · · · — — — · · · pourrait se
lire, si on n’utilisait pas un séparateur de lettres, de différentes manières:
· ·/ · — — —/ ·/ · · IJEI ou · · · —/ — — ·/· · VGI
Naturellement, les nombres, l’arithmétique et plus généralement les
mathématiques sont nécessaires pour étudier les codes. Par exemple dans la définition
d’un code optimal pour un texte : c’est un code tel que la somme, pour tous les
caractères du texte, de la fréquence d’un caractère multipliée par la longueur de son
codage est minimale, de même qu’en botanique il peut être utile de compter le nombre
de pétales d’une fleur ou en entomologie le nombre de pattes d’une scolopendre !
Donc, en informatique, on représente des informations par des chaînes de
caractères, on traduit, on analyse, on détecte et on corrige des erreurs dans de telles
représentations. Voici un exemple très simple de détection et de correction d'une
erreur : avant l'envoi d'un message, par exemple aabababba, on triple les caractères et
si, à la réception, trois caractères consécutifs ne sont pas identiques, c'est qu'il y a
erreur. Par exemple, si au lieu de recevoir « aaaaaaabbbaaabbbaaabbbbbbaaa », le
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)Académie des Sciences et Lettres de Montpellier 5
message reçu est « aaaaaaabbbaaabbbaaabbbbbbaba », on détecte une erreur sur le
dernier caractère. Le protocole de communication peut décider de corriger (dans
certains cas) un message comportant des erreurs, en gardant le caractère le plus
fréquent : cans cet exemple, comme il y a deux a et un b on peut supposer que le
caractère correct est un a. Le protocole de communication peut aussi décider de
demander à l'expéditeur d'envoyer à nouveau le message.
Le traitement informatique des informations consiste à discrétiser et non pas
à numériser des caractères, des textes, des images, des sons, …, et aussi des nombres,
à les compresser, corriger, crypter et aussi à les structurer pour pouvoir les utiliser
dans des algorithmes.
La structure fondamentale de l’informatique est la structure d’arbre. Dans la
figure 3 nous avons représenté à gauche le code préfixe proposé précédemment pour
représenter le mot baabccabdbaa et, à droite, un exemple d’arbre syntaxique. Les arbres
généalogiques, les arbres syntaxiques, les hiérarchies, l’organisation d’un ensemble de
fichiers en répertoires et sous-répertoires sont d’autres exemples bien connus de cette
structure que l’on munit de différentes opérations (comme ajouter ou supprimer des
feuilles ou des branches) pour pouvoir les manipuler dans des algorithmes.
Figure 3 Arbres (informatiques)
Un dernier mot : on distingue parfois, en informatique, données, informations
et connaissances.
Donnée : SOS ; Information : appel au secours ; Connaissance : si réception
SOS alors contrôler l’appel, si appel crédible alors déterminer meilleur moyen
d’intervention, etc …
Il y a quelques années on parlait d’Informatique numérique, d’Informatique
non numérique ou combinatoire, d’algorithmes numériques et d’algorithmes non
numériques. Aujourd’hui, alors que l’essentiel des traitements informatiques
concernent des caractères et pas des nombres, numérique est devenu quasi-synonyme
d’informatique. Avant de revenir sur cette question, il est temps de préciser la notion
d’algorithme souvent mentionnée dans ce qui précède et qui permet de préciser ce
qu’on entend par « traitement automatique » dans l’informatique est la science du
traitement rationnel et automatique de l’information. Le paradoxe du singe savant
réussissant à écrire Hamlet en tapant suffisamment longtemps au hasard sur un clavier,
dont la forme moderne est parfois attribuée à Emile Borel (directeur de thèse de
Georges Valiron, qui fut le directeur de thèse de Jean Kuntzmann …), sera la seule
illustration d’un traitement non rationnel !
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)6 Communications présentées en 2017
3 Algorithmes
Alan Turing a décrit en 1936 un modèle d’algorithme qu’Alonzo Church, son
directeur de thèse, proposa d’appeler Machine de Turing. Une machine de Turing peut
être considérée comme un modèle abstrait de quelqu’un en train de réaliser une tâche
avec un crayon et une feuille de papier. Imaginez-vous devant un ruban de papier
découpé en cases sur lequel quelques cases sont remplies, les autres étant vides. Vous
avez un problème à résoudre dont les données sont représentées par ces cases remplies.
Vous regardez une case et suivant son contenu et suivant l’état d’avancement de la
résolution du problème que vous voulez résoudre, vous pouvez faire l’une des
opérations simples suivantes : remplacer ou non le caractère lu par un autre et passer
dans la case à gauche ou à droite et c’est tout (et ne faire ces opérations qu’un nombre
fini de fois).
En guise d’exemple nous allons construire une machine de Turing permettant
de résoudre un problème très simple qui consiste à remplacer dans un mot les
minuscules par des majuscules (et on laisse les majuscules …).
Nous avons besoin de deux états. Un état de travail noté par T et un état final
noté par F. On va parcourir le mot de la gauche vers la droite. Initialement on lit la
première lettre du mot, la plus à gauche, et on est dans l’état T.
Pour simplifier nous allons écrire une machine de Turing faisant ce travail sur
un mot ne contenant que les trois premières lettres de l’alphabet. Le fonctionnement de
la machine consiste à appliquer les règles ci-dessous tant que c’est possible.
Si on lit a dans l’état T alors on remplace a par A, on lit la case droite et on reste en T
Si on lit b dans l’état T alors on remplace b par B, on lit la case droite et on reste en T
Si on lit c dans l’état T alors on remplace c par C, on lit la case droite et on reste en T
Si on lit A dans l’état T alors on lit la case droite et on reste en T
Si on lit B dans l’état T alors on lit la case droite et on reste en T
Si on lit C dans l’état T alors on lit la case droite et on reste en T
Si on lit une case vide dans l’état T alors on passe dans l’état F
Une telle machine est donc un mécanisme très simple et la thèse de Church-
Turing dit que : tout traitement mécanique (d’une séquence de caractères) peut être
réalisé par une machine de Turing.
Turing a également défini ce qu’on appelle une machine de Turing
universelle. Si la description d’une machine de Turing universelle n’est pas très simple,
son fonctionnement est simple. Une machine de Turing universelle U est une machine
qui, lorsque sur son ruban sont écrits une machine de Turing M (comme celle que nous
venons de voir) et une donnée D (comme un mot composé de minuscules et
majuscules), produit comme résultat celui que fournit la machine M dont le ruban
contient initialement D et ceci quels que soient M et D.
Ceci peut s’écrire symboliquement de la manière suivante : si M(D) représente
le résultat du fonctionnement de la machine de Turing M sur la donnée D et si U(M,D)
représente le résultat du fonctionnement de la machine universelle U sur la donnée
(M,D) alors U(M ,D)= M(D).
Qu’est-ce que c’est qu’une machine qui, étant donné un programme et une
donnée, exécute le programme à partir de cette donnée ? C’est un ordinateur ! Un
ordinateur est une machine de Turing universelle, mais on pourrait aussi dire qu’un
ordinateur n’est qu’une machine de Turing universelle et, comme une machine de
Turing n’est pas très maline par rapport à ce qu’un être humain sait faire on pourrait
dire, d’une manière pédagogiquement très efficace, comme Gérard Berry, professeur
au Collège de France, Membre de l’Académie des Sciences et de l’Académie des
Technologies, Médaille d’or du CNRS 2014, « Fondamentalement, l’ordinateur et
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)Académie des Sciences et Lettres de Montpellier 7
l’homme sont les deux opposés les plus intégraux qui existent. L’homme est lent, peu
rigoureux et très intuitif. L’ordinateur est super rapide, très rigoureux et complètement
con. » (interview à Rue89)
4 Programmation
La programmation est au cœur de l’informatique. La programmation consiste
à traduire un algorithme, qui peut être très astucieux parce qu'il a été conçu et réalisé
par un être humain, dans un langage compréhensible par une machine stupide (stupide
dans ses actions, pas dans sa conception), de plus limitée en taille et en rapidité.
La programmation est une activité créatrice, comme composer un morceau de
musique ou trouver un théorème, c’est une activité difficile à normaliser et l’œuvre
monumentale, toujours en construction, de Donald Ervin Knuth, s’appelle, à juste
titre, The Art of Computer Programming.
Il y a de nombreux paradigmes de programmation. La programmation par
machines de Turing a un intérêt essentiellement théorique et pédagogique et nous
dirons un mot de la programmation procédurale.
Dans ce type de programmation, un programme est une séquence
d’expressions et d’instructions qui décrivent et font varier le contenu de la mémoire, et
la sémantique d’une séquence d’instructions consiste à faire ces instructions les unes à
la suite des autres.
La mémoire d’un ordinateur est composée d’un ensemble de cases, similaires
à des boites aux lettres, chaque case ayant une adresse, un nom (ce qui est écrit sur la
boite) et une valeur (le contenu de la boite). Par exemple, la case mémoire d’adresse
10001 pourra avoir pour nom CodePiece et pour valeur la chaine de caractères
‘Pneu_123_X’. La programmation procédurale a trois instructions élémentaires :
l’affectation, le test et la boucle, qui peuvent être décrites intuitivement sur des
exemples de la manière suivante.
– Une instruction (simple) d’affectation s’écrit : NomA ← Expression.
La sémantique d’une affectation consiste à évaluer l’expression Expression
qui est à droite du signe d’affectation et à mettre cette valeur dans la case dont le nom
NomA est à gauche du signe d’affectation.
Considérons les affectations suivantes :
PrixHT ← 10 ;
Taxe ← 0.2 ;
PrixTTC ← PrixHT + PrixHTxTaxe ;
Com ← 0.1xPrixHT ;
Ainsi, la première affectation consiste à mettre 10 dans la mémoire de nom
PrixHT, la deuxième consiste à mettre 0.2 dans Taxe, la troisième consiste à calculer la
valeur de PrixHT + PrixHTxTaxe est égale à 12 et à mettre cette valeur dans PrixTTC,
puis 1 dans Com.
Si ensuite on exécute l’affectation : PrixTTC ← PrixTTC + Com on évaluera
ce qui est à droite et qui vaut 12 +1 = 13 et on mettra cette valeur 13 dans la mémoire
de nom PrixTTC (dont la valeur est ainsi passée de 12 à 13).
– Une instruction de test s’écrit de la manière suivante : si condition alors instruction1
sinon instruction2.
La sémantique d’une telle instruction est la suivante : si la condition est
satisfaite alors on exécute instruction1, sinon (si la condition n’est pas satisfaite) on
exécute instruction2.
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)8 Communications présentées en 2017
Par exemple, supposons qu’après les affectations ci-dessus le programme
contienne le test :
si PrixHT < 20 alors Nbre ← 100 sinon Nbre ← 50
Comme PrixHT est égal à 10 (qui est plus petit que 20) on mettra 100 dans
Nbre, mais si PrixHT avait été supérieur ou égal à 20 on aurait mis 50 dans Nbre.
– Une instruction de boucle dite boucle tantque : s’écrit de la manière suivante :
tantque condition faire instructionboucle.
La sémantique d’une telle instruction est la suivante : on évalue la condition,
si elle est satisfaite on effectue l’instruction instructionboucle si elle n’est pas
satisfaite on passe à l’instruction suivante et on fait cela tant qu’on peut, on « boucle ».
Par exemple, supposons qu’après les instructions précédentes le programme
contienne la boucle :
tantque Nbre < 300 faire Nbre ← Nbre +150
Comme initialement Nbre vaut 100 on fera deux fois la boucle et la dernière
valeur de Nbre sera 400.
A la fin du programme composé des 5 affectations, du test et de la boucle ci-
dessus, les valeurs des différentes cases mémoires sont les suivantes :
PrixHT = 10, Taxe = 0.2, PrixTTC = 13, Com = 0.1 , Nbre = 400
Ce programme n’avait pour seul but que de donner des exemples simples des
opérations d’affectation, de test et de boucle, il est naturellement stupide et si vous
demandez à un programme de faire des choses stupides il les fera sans renâcler !
Les problèmes que vous pouvez résoudre par un algorithme programmable
avec ces 3 opérations sont exactement les mêmes que ceux que vous pouvez résoudre
en utilisant une machine de Turing.
5 Communication
Un système informatique est composé d’ordinateurs connectés par des
réseaux, et de logiciels qui permettent de les utiliser. Il aurait fallu parler de
l’organisation d’un ordinateur : non seulement de sa mémoire, mais aussi des
entrées/sorties, de l’unité de traitement, de bus, de langage machine, de système
d’exploitation, etc. Si cette organisation est souvent décrite, l’aspect réseau est parfois
oublié voici donc quelques mots à ce sujet.
La notion fondamentale concernant les réseaux est celle de protocole. Un
protocole de communication est un ensemble de règles et de procédures permettant de
définir un type de communication particulier. C’est un modèle de référence d'un réseau
informatique qui permet la connexion entre des architectures différentes et qui est mis
en œuvre par une hiérarchie de logiciels [2]. Pour décomposer et ordonner les
différentes tâches, les protocoles sont hiérarchisés en couches. Le modèle TCP/IP, qui
est le plus utilisé sur le web, est présenté en cinq couches dans la figure 4.
Lors d'une transmission, les données traversent chacune des couches au niveau
de la machine émettrice. À chaque couche, une information est ajoutée au paquet de
données, il s'agit d'un en-tête, ensemble d'informations qui garantit la transmission. Ce
mécanisme s’appelle : encapsulation des données.
– Au niveau de la machine réceptrice, lors du passage dans chaque couche, l'en-tête est
lu, puis supprimé. Ainsi, à la réception, le message est dans son état originel.
– La couche application assure l’interface avec les applications, c’est le niveau le plus
proche des utilisateurs (ex. HTTP, HTTPS, FTP, SMTP, …)
– La couche transport découpe en paquets, gère des erreurs de transmission, et précise
à quelle application les paquets doivent être délivrés (ex. TCP, UDP, …)
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)Académie des Sciences et Lettres de Montpellier 9
– La couche réseau gère l’adressage et le routage (l’acheminement) des paquets de
données, fragmente le message à l’envoi, et regroupe les paquets en réception (ex. IP,
ICMP, ARP, …)
– La couche liaison spécifie comment les paquets sont transportés sur la couche
physique, et en particulier insère les séquences particulières de bits qui marquent le
début et la fin des paquets (ex.Ethernet, Token Ring, …)
– La couche physique décrit les caractéristiques physiques de la communication
(câbles, liens par fibre optique, connecteurs etc.).
Figure 4 : Protocole TCP/IP
Les protocoles sont des logiciels, Vinton Cerf et Robert Kahn pour TCP/IP et
Tim Berners-Lee pour le Web ont d’ailleurs été récipiendaires du prix Turing, prix le
plus prestigieux en informatique. Louis Pouzin aurait dû, pour les datagrammes et le
réseau Cyclades, obtenir ce prix, nous y reviendrons plus tard.
6 Conclusion
Les aperçus sur l’informatique qui précèdent sont tellement simples que
certains pourraient penser que l’informatique n’est qu’un ensemble informe de
techniques. Pour les compléter voici quelques questions et objectifs scientifiques
actuels de l’informatique.
En ce qui concerne les INFORMATIONS, en plus des problèmes de
représentation et de structuration, de maintenance, de correction de grandes masses de
données, de nombreuses recherches sont nécessaires pour prendre en compte des
données incertaines, incomplètes, ou bruitées et développer de bons modèles formels ;
la recherche d’informations précises dans des grandes bases de données est un
problème qui est loin d’être résolu, et le traitement informatique de la langue naturelle,
qui est fondamental car les informations ou les connaissances sont souvent exprimées
en langue naturelle, n’en est qu’à ses premiers pas, etc.
Il existe de nombreux problèmes à résoudre en ce qui concerne les
ALGORITHMES : affiner la hiérarchie de la complexité des algorithmes et des
problèmes (ce qu’on peut faire ou ne peut pas faire compte tenu du temps ou de
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)10 Communications présentées en 2017
l’espace) ; développer des algorithmes probabilistes ou des algorithmes approchés
lorsque les algorithmes exacts sont trop couteux ; développer des algorithmes parallèles
sur des machines multicoeurs ou sur des réseaux, et naturellement développer de
nouveaux algorithmes pour de nouvelles applications etc.
En ce qui concerne la PROGRAMMATION, les problèmes de recherche sont
aussi très nombreux. En plus de la conception de nouveaux langages et de leurs
traducteurs dédiés à des nouvelles applications, de nombreuses recherches concernent,
par exemple, la sémantique formelle des programmes, la construction automatique de
programmes à partir de spécifications, la preuve de programmes etc.
En ce qui concerne les SYSTEMES, le « ransonware WannaCry », les
« leaks » divers (Wiki, Luxembourg, Panama, Macron), le trafic des données privées,
prouvent tous les jours que les problèmes liés à la sécurité sont loin d’être résolus.
Depuis 2009, plus de 100 failles de sécurité ont été découvertes chaque année dans le
navigateur Firefox, ceci grâce au fait que c’est un logiciel open source, les failles dans
les systèmes propriétaires sont tout aussi fréquentes mais plus difficiles à découvrir
puisque seuls, même très brillants, les employés de l’entreprise propriétaire peuvent y
contribuer. Des recherches sont également menées, et ce ne sont que quelques
exemples, sur les systèmes répartis hiérarchisés de grande taille, les données
distribuées, internet et la structure du Web, en bref sur ce qu’on appelle l’informatique
dans les nuages.
Pour compléter tout ceci on peut consulter les objectifs stratégiques d’Inria ou
ceux de l’INS2I.
La liste des prix Turing, décernés chaque année par l’Association for
Computing Machinery, depuis 1966, est une autre manière de voir ce qu’est la science
informatique [3]. Cette liste suscite immédiatement une question qui fâche : pourquoi
un seul Français ? Les raisons sont multiples :
– Culturelles : en particulier, l’attachement, aujourd’hui disparu, des chercheurs
français à la langue française ;
– Industrielles et politiques : pendant de nombreuses années l’industrie française des
ordinateurs a fait jeu égal avec celle des USA. Le démantèlement de Bull, le
remplacement d’une option informatique européenne par une option franco-
américaine,…, en bref l’échec du plan calcul (sur lequel des livres entiers ont été
écrits) a conduit à la disparition de cette industrie. L’arrêt de Cyclades qui suscitait un
intérêt mondial fut tué par les télécoms qui développaient Transpac et le Minitel et qui
furent balayés par le développement de l’internet ;
– Scientifiques : de nombreux mathématiciens ne voulaient pas entendre parler de
science informatique, pas tous naturellement, mon patron Jean Kuntzmann, à qui je ne
rendrai jamais assez hommage, fut une de ces exceptions. Mathématicien « pur »
comme on disait à l’époque, Jean Kuntzmann, élève de Georges Valiron, créa la
première école d’ingénieurs en informatique l’ENSIMAG en 1959 et devint
informaticien ; de nombreux physiciens pensaient que l’informatique n’était qu’un
conglomérat de techniques, pas tous naturellement, Jacques Arsac, astronome, dont je
fus l’assesseur pour l’enseignement à Paris 6, créa l’Institut de programmation de
Paris, et devint un spécialiste de la programmation ;
– Institutionnelles (même si de nombreuses personnes dans ces institutions ont aidé le
développement de l’informatique) : l’Académie des Sciences dans laquelle il n’existe
pas de section informatique et dont la création d’une section sciences mécaniques et
informatiques fut bien tardive. Aujourd’hui encore, il est difficile de déterminer, sur le
site de l’Académie, qui sont les informaticiens académiciens. L’ENS et l’X qui ont
tardé à créer des laboratoires de recherche en informatique, sans parler des grands
corps ou de la société des agrégés.
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)Académie des Sciences et Lettres de Montpellier 11
Il y a aussi, et surtout, la puissance de l’industrie et des universités états-
uniennes qui fait que bien qu’internationale l’Association for Computing Machinery est
largement dominée par les Américains.
En plus de Louis Pouzin, je ne donnerai qu’un autre exemple, car la liste serait
trop longue, d’informaticiens français qui aurait dû avoir le prix Turing, c’est celui
d’Alain Colmerauer, disparu il y a quelques jours, inventeur de la programmation
logique et du langage PROLOG, pionnier de l’Intelligence Artificielle.
Pour terminer : pourquoi le sens du terme numérique a-t-il pris une telle
extension ? Nous avons vu que l’explication par les nombres qui seraient sous-jacents à
n’importe quoi de « numérique» n’était pas convaincante.
Certains disent que le numérique c’est l’informatique plus la communication
… ce qui laisserait sous-entendre que la communication en question n’est pas une
communication informatique ! Or, cette communication se déploie sur des réseaux
informatiques et les réseaux existent depuis le début de l’informatique … D’autres
pensent que l’obésité de la sémantique de numérique provient peut-être de la naissance
du Web au début des années 90 ou du fait que l’informatique étant présente partout il
fallait utiliser un autre terme pour représenter l’ensemble de ses applications ?
En fait, aucune des explications n’est convaincante. Cet usage extensif de
numérique est spécifique du français, c’est, il me semble, un pur idiotisme. Essayez en
anglais (avec numeric ou numerical) vous ne trouverez pas de substantif et, de plus, en
tant qu’adjectif il s’agit généralement, dans des expressions comme « analyse
numérique » ou « calcul numérique », de nombres, sinon l’anglais utilise digital
comme dans digital camera. Et je me demande ce que peut bien signifier analyse
numérique pour un jeune français aujourd’hui … sans doute pas la méthode de Gauss-
Seidel pour résoudre les systèmes d’équations linéaires ni la méthode d’intégration de
Simpson !!!
Un dernier exemple qui me touche de prés. L’IRIA, créé à Rocquencourt il y a
50 ans, fut renommé INRIA lorsque des centres furent créés en province et que
l’Institut de Recherche en Informatique et Automatique devint ainsi national. Il y a
quelques années l’INRIA s’est transformée en Inria qui n’est plus un acronyme mais un
nom propre… et accompagnant le logo institutionnel d’Inria on trouve le slogan
« inventeurs du monde numérique ».
Si, comme le dit Michel Serres, « L’informatique crée le monde dans lequel
nous travaillons, vivons et pensons » pourquoi parler tout le temps de numérique ? Je
partage le point de vue de Maurice Nivat qui, dans la revue Epinet, écrit : « Le mot
numérique est un cas typique de ce que Éric Hazan appelle « l'évitement des mots du
litige » consistant, en changeant de vocabulaire, à faire disparaître des sujets qui
fâchent, des sujets trop polémiques, des sujets dont on ne sait pas bien comment se
dépêtrer. » [4]
Mais les choses changent, lentement, trop lentement … création en 2012 de la
Société informatique de France reconnue et acceptée comme égale par les autres
sociétés savantes françaises ; création en 2012, après quelques chaires annuelles, d’une
chaire d’informatique au collège de France ; accroissement du nombre d’informaticiens
à l’Académie des Sciences, et comme le dit Guillaume Bagot, « Retirez les Français de
la Silicon Valley, des studios Pixar, de la City ou de Singapour et vous verrez la
globalisation caler ». Enfin, un signe tout récent, la question posée par des
scientifiques prestigieux aux candidats à l’élection présidentielle. Des académiciens,
des professeurs au collège de France, des responsables de sociétés savantes ont, enfin !,
posé aux candidats à la présidentielle une question simple « comment enseigner la
science informatique dans l’enseignement secondaire sans former des professeurs
d’informatique, donc sans créer CAPES et Agrégation ? » [5]. La simple formulation
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)12 Communications présentées en 2017
de cette question est importante puisqu’elle exprime un consensus du milieu
scientifique sur la science informatique et la nécessité de son enseignement dans
l’enseignement secondaire. Mais les réponses des 8 candidats qui ont répondu ne me
rendent pas très optimiste. Même pas celle, pourtant la plus détaillée, de notre actuel
Président de la République.
Trois choses m’inquiètent dans sa réponse. Premièrement, il propose une
conversion à l’informatique de professeurs d’autres disciplines. Nous avons
expérimenté cela dans l’enseignement supérieur à la fin des années 60 : les stages
d’une année et de plus de 600 h de conversion à l’informatique de professeurs du
second degré ou d’assistants d’autres disciplines, n’ont pas toujours été une réussite,
sauf pour ceux qui ont ensuite complété un cursus d’informatique. Deuxièmement, je
cite « Il faudra d’autre part examiner la possibilité … en étudiant la création d’un
CAPES et/ou d’une Agrégation d’informatique » … ceci annonce une commission à
venir alors qu’en 1978 le rapport Simon Nora et Alain Minc sur l’informatisation de la
société préconisait la création d’un CAPES d’informatique ! Troisièmement, une
option d’informatique dans le CAPES de mathématiques a été créée, c’est mieux que
rien mais ceci n’est pas satisfaisant. En effet, l’essentiel des mathématiques que l’on
enseigne en licence et master de mathématiques ne sont pas les mathématiques qui
concernent directement l’informatique (les mathématiques discrètes), et même pire les
mathématiques classiques (disons l’analyse pour simplifier) rebutent souvent les
informaticiens.
A ce sujet, ne me faites pas dire que les nombres ou plus généralement les
mathématiques sont inutiles en informatique, et personnellement si, depuis 1962,
j’aime l’informatique, j’ai eu quelques aventures avec les mathématiques, en particulier
les mathématiques discrètes. Ce que je conteste c’est l’utilisation du terme numérique
qui pourrait faire croire que l’informatique n’est qu’une partie des mathématiques alors
que l’informatique est une science originale, complexe et autonome ! Je sais que, pour
l’usage de numérique il est sans doute trop tard, mais le titre de mon exposé, qui
reprend celui d’un manifeste de la Société Informatique de France [6], me semble être
un compromis acceptable.
RÉFÉRENCES
[1] http://www.editions-eyrolles.com/Livre/9782212566659/blockchain (sur les
blockchaines)
[2] http://www.zeitoun.net/articles/les_protocoles_reseaux/start (sur TCP/IP et les
protocoles)
[3] http://awards.acm.org/about/turing-laureates-spotlight (sur les lauréats du prix
Turing)
[4] http://www.epi.asso.fr/revue/articles/a1512c.htm (Maurice Nivat sur la
propagande numérique)
[5] http://science-et-technologie.ens.fr/ (questions aux candidats à la présidentielle)
[6] http://www.societe-informatique-de-france.fr/
Bull. Acad. Sc. Lett. Montp., vol. 48 (2017)Vous pouvez aussi lire

















































