Modèle prédictif des troubles psychiatriques en combinant scores de risque génétique et variables socio-économiques - Mémoire Meriem Bahda ...
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Modèle prédictif des troubles psychiatriques en
combinant scores de risque génétique et variables
socio-économiques
Mémoire
Meriem Bahda
Maîtrise en biostatistique - avec mémoire
Maître ès sciences (M. Sc.)
Québec, Canada
© Meriem Bahda, 2022
Modèle prédictif des troubles psychiatriques en
combinant scores de risque génétique et variables
socio-économiques
Mémoire
Meriem Bahda
Sous la direction de:
Alexandre Bureau, directeur de recherche
Maripier Isabelle, codirectrice de recherche
Résumé
Le présent projet vise à construire un modèle prédictif des troubles psychiatriques en
combinant des variables génétiques, les scores de risque polygéniques (PRS), et des
variables socio-économiques. Les PRS seront construits grâce à une méthode que nous
avons développée et que nous avons nommée Multivariate lassosum. L’issue d’intérêt
à prédire sera l’apparition d’un trouble mental chez l’individu. Le modèle considéré
sera le modèle de régression de Cox. Le pouvoir prédictif du modèle construit sera
évalué en calculant l’aire sous la courbe ROC, en utilisant la méthode validation
croisée.
ii
Abstract
The present project aims to build a predictive model of psychiatric disorders by
combining genetic variables, polygenic risk scores (PRS), and socioeconomic variables.
The PRS will be constructed using a method we have developed called Multivariate
lassosum. The outcome of interest to be predicted will be the onset of a mental
disorder in the individual. The model considered will be the Cox regression model.
The predictive power of the model constructed will be evaluated by calculating the
area under the ROC curve, using the cross-validation method.
iii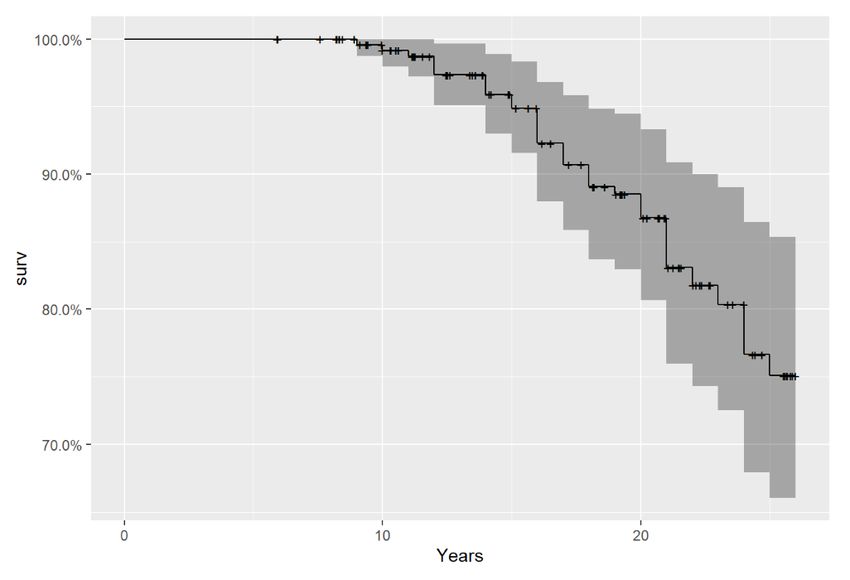
Table des matières
Résumé ii
Abstract iii
Table des matières iv
Liste des tableaux vi
Liste des figures vii
Remerciements viii
Avant-propos x
Introduction 1
1 Aspects génétiques des troubles psychiatriques 4
1.1 Présentation des scores de risque polygéniques . . . . . . . . . . . 4
1.2 Présentation des troubles mentaux . . . . . . . . . . . . . . . . . . . 6
1.3 Utilisation des scores de risque polygéniques en psychiatrie . . . . 7
2 Aspects socio-économiques des troubles psychiatriques 10
2.1 Association entre le statut socio-économique et les troubles mentaux 10
2.2 L’indice Blishen comme mesure du statut socio-économique . . . . 12
2.3 Le revenu comme mesure du statut socio-économique . . . . . . . . 14
3 Better prediction of correlated traits using polygenic risk scores and
socioeconomic variables 17
3.1 Résumé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.4 Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5 Simulation study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.6 Real data analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.7 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
References 48
ivConclusion 53
Bibliographie 55
Appendix A : Linearization of the PEL function 64
Appendix B : Supplementary tables and figures 69
Appendix C : Amendment of our project with CARTaGENE to use their data 72
vListe des tableaux
3.1 Descriptive statistics of the correlation of the PRS with the true predic-
tor of each method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2 95% Confidence interval of the prediction accuracy of each method . . 37
3.3 Mean difference estimate and 95% Confidence interval of the mean dif-
ference estimate of prediction accuracy between Multivariate lassosum
and the other methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4 Descriptive statistics of the Blishen index, the income market and the age 42
3.5 Summary of model 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.6 Summary of model 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.7 AUC scores for model 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.8 AUC scores for model 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
B.1 Descriptive statistics of the correlation between the estimated SNPs
weights and the simulated SNPs weights . . . . . . . . . . . . . . . . . 69
viListe des figures
3.1 Mean and standard deviation of the correlation of the PRS with the
true predictor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2 Survival curve of model 2 . . . . . . . . . . . . . . . . . . . . . . . . . . 45
B.1 Prospective group . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
B.2 Retrospective group . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
B.3 Full estimating sample . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
viiRemerciements
Avant de commencer, permettez-moi, chers lecteurs, de présenter mes plus sincères
remerciements et exprimer ma profonde gratitude aux personnes qui ont grandement
contribué à la réalisation de ce mémoire.
Tout d’abord, je tiens à remercier mon directeur de recherche, Alexandre Bureau et
ma codirectrice de recherche, Maripier Isabelle. Vous m’avez initiée au monde de la
recherche, et vous m’avez guidée et orientée tout au long de mon projet de recherche
et j’en suis grandement reconnaissante. Je remercie également Jasmin et Loïc pour
leur aide, et à tous les membres de notre équipe de recherche qui ont contribué, de
loin ou de près, à ce travail.
Je tiens également à exprimer ma reconnaissance à l’université Laval, l’établissement
qui m’a accueilli et qui m’a permis d’entreprendre mes études au Canada.
Je souhaite offrir mes remerciements les plus chaleureux à mes chers parents, à mes
deux frères, Youssef et Soulaimane, et à toute ma famille, pour leurs sacrifices, leur
dévouement, et surtout, leur amour inconditionnel. Vous m’avez toujours encouragée
à poursuivre mes ambitions, et faire de mes rêves une réalité.
Un grand merci à mes compagnons de parcours, Sana, Yasmine, Laila, Oumayma,
Safwane, Anass, Hamza, Lamia, Marwane et Imad, pour avoir fait de mon parcours
académique, une réelle aventure.
viiiEnfin, je tiens à remercier les amis qui sont devenus ma seconde famille et qui ont
fait du Canada mon deuxième foyer heureux. Fatima ezzahraa, Yasmina, Ahmed,
Sarah, Oussama, Yassine, Asmaa, Oumaima, Fouad, Younes, Abdou, Hakim, Mona,
Soufiane, je ne pourrai jamais vous remercier assez pour les merveilleux moments
que nous avons passés ensemble, et j’espère sincèrement que nous en aurons encore
des meilleurs.
ixAvant-propos
Le troisième chapitre de ce mémoire se présente sous la forme d’un article scientifique
rédigé en anglais. L’article n’a pas été soumis pour publication. L’auteur principal
de l’article est l’étudiante Meriem Bahda, et les coauteurs sont ses directeurs de
recherche, Alexandre Bureau et Maripier Isabelle. Meriem Bahda a été responsable
de la rédaction de l’article, a participé au développement de la méthode présentée et
a effectué les analyses des résultats obtenus, sous la supervision de ses directeurs de
recherche. Alexandre Bureau a supervisé le volet génétique du projet, notamment
le développement méthodologique de la méthode présentée, et Maripier Isabelle a
supervisé le volet économique du projet, notamment la construction des variables
socio-économiques.
xIntroduction
Les troubles mentaux sont aujourd’hui considérés comme un enjeu majeur de santé
publique, qui pèse de plus en plus lourd sur la charge mondiale de morbidité. Au
Canada, environ 20% des jeunes souffrent d’un trouble mental (Institut canadien
d’information sur la santé 2020) et 70% des personnes atteintes d’un trouble mental
ont développé des symptômes avant l’âge de 18 ans (Commission de la santé mentale
du Canada 2021). La présence d’une maladie mentale peut avoir des conséquences
néfastes sur la vie de l’individu, en particulier quand celle-ci n’est pas diagnostiquée.
C’est pour cette raison qu’il est nécessaire d’aspirer à améliorer les méthodes de
prévention et de détection précoce des troubles mentaux, surtout chez les jeunes et
les enfants.
L’aspect génétique des troubles psychiatriques a été longuement exploré. Des études
ont montré que certains sujets sont plus vulnérables génétiquement à développer
des troubles psychiatriques à cause de l’héritabilité de celles-ci. (Roy et al. 2001). La
vulnérabilité génétique du sujet à développer un trouble mental peut être évaluée
grâce aux composantes de scores de risque polygénique (PRS). Les PRS peuvent être
calculés pour tout trouble ou phénotype en général, permettant ainsi d’évaluer le
degré de prédisposition du sujet par rapport à ce phénotype. En outre, le PRS calculé
pour un trouble mental peut également prédire la présence d’autres troubles qui
lui sont apparentés (ou corrélés), ce qui suggère que la susceptibilité génétique est
largement partagée entre les troubles (Zheutlin et al. 2019 , Lee et al. 2013 , Ruderfer
1et al. 2018). Étant donné que les maladies mentales sont corrélées génétiquement,
prendre en considération cette corrélation entre les troubles pourrait donc améliorer
la qualité de la prédiction.
Différentes méthodes de calcul des PRS ont déjà été élaborées, chacune ayant ses
propres caractéristiques et son propre contexte d’application. On citera par exemple,
la méthode lassosum de Mak et al. (2017) et la méthode LDpred2 de Privé et al. (2020).
Il demeure néanmoins important de toujours chercher à améliorer et affiner le calcul
des PRS.
Bien que la vulnérabilité génétique du sujet soit prédéterminée à sa naissance, le
risque qu’il développe un trouble psychiatrique ne se résume pas entièrement à
la génétique. Des facteurs de risque environnementaux sont également associés à
l’apparition des troubles psychiatriques. En particulier, le statut socio-économique
(SES) a été lié à l’incidence de la dépression (e.g. Dohrenwend et al. 1992 pour les
femmes adultes, Tracy et al. 2008 pour les enfants) et à d’autres troubles du cerveau,
comme dans Sareen et al. (2011). Toutefois, rares sont les études qui se sont intéres-
sées à évaluer quantitativement si le SES a des effets additifs avec la vulnérabilité
génétique indexée par le PRS, pour la prédiction des troubles psychiatriques. Il serait
alors intéressant d’évaluer si l’inclusion de la dimension socio-économique pourrait
améliorer la prédiction des troubles psychiatriques.
Dans le cadre de ce mémoire, nous avons entrepris une nouvelle approche pour la
prédiction des troubles psychiatriques, qui fusionne la génomique, la modélisation
statistique et certains concepts issus de la science économique.
Nous proposons ainsi une nouvelle méthode pour le calcul des PRS, et qui, selon nos
études de simulation, a une performance prédictive meilleure que celle des méthodes
lassosum de Mak et al. (2017) et LDpred2 de Privé et al. (2020).
Nous développons également un modèle prédictif des troubles psychiatriques, en
combinant des variables génétiques et des variables socio-économiques, et ce, pour
2des enfants et jeunes dont au moins l’un des deux parents est atteint d’un trouble
mental (qui sont donc considérés à risque de développer un trouble mental).
Notre choix de nous intéresser aux enfants et aux jeunes à risque est motivé par de
récents travaux, qui ont suggéré qu’il serait prometteur de s’intéresser en particulier
à la prédiction des troubles psychiatriques chez une population d’enfants nés d’un
parent affecté par des troubles psychiatriques (Maziade 2017).
Le 1er chapitre de ce mémoire sera consacré aux aspects génétiques des troubles
psychiatriques. Nous y présentons les scores de risque polygéniques ainsi que les
troubles mentaux. Nous y explorons également les diverses utilisations des scores de
risque polygénique dans le domaine de la psychiatrie.
Le 2ème chapitre quant à lui, sera consacré aux aspects socio-économiques des
troubles psychiatriques. Nous y explorons l’association entre le statut socio-économique
et les troubles mentaux, et nous y présentons également les variables socio-économiques
que nous utiliserons dans la construction de notre modèle prédictif, présenté au 3ème
chapitre.
Le 3ème chapitre, qui est sous forme d’un article scientifique rédigé en anglais, intro-
duit la nouvelle méthode que nous avons développée pour le calcul des PRS, nommée
Multivariate Lassosum. Nous y présentons également une application de la méthode
sur des données réelles et le modèle prédictif des troubles psychiatriques construit.
Dans notre application, nous nous intéresserons à deux traits, la schizophrénie et le
trouble bipolaire. Notre analyse s’appuiera en partie sur les données fournies par
le programme scientifique et clinique Horizon Parent-Enfant (HoPE), une approche
continue de prévention et de traitement personnalisé centrée sur la famille et impli-
quant des parents affectés et leurs enfants. Il contient des informations longitudinales
sur la situation clinique et socio-économique de centaines de familles participantes,
en plus des données génétiques. Nous utiliserons également les données de sujets de
familles de l’Est du Québec, atteints de schizophrénie et de trouble bipolaire.
3Chapitre 1
Aspects génétiques des troubles
psychiatriques
1.1 Présentation des scores de risque polygéniques
Un polymorphisme d’un seul nucleotide (communément appelé SNP pour single
nucleotide polymorphism en anglais) est défini comme une variation de la séquence
d’ADN qui se produit lorsqu’un seul nucléotide (qui contient l’une des bases sui-
vantes : adénine, thymine, cytosine ou guanine) de la séquence du génome est modifié
et que cette altération particulière est présente dans au moins 1% de la population
(National Cancer Institute). Ainsi, les SNPs sont un type de polymorphisme impli-
quant la variation d’une seule paire de bases.
Certaines variations génétiques peuvent n’avoir aucun effet sur le sujet, tandis que
d’autres sont associés avec certains phénotypes. Les SNPs peuvent être associés à un
seul phénotype en particulier comme ils peuvent être associés à plusieurs phénotypes.
Étant donné que la plupart des troubles prévalents sont polygéniques, par exemple
le diabète de type 2, la contribution individuelle de chaque SNP ne représente qu’un
faible pourcentage de la variance phénotypique. Cependant, ces variants peuvent être
4regroupés en un score que l’on appelle, le score de risque polygénique (communément
appelé PRS pour polygenic risk score en anglais), qui peut être associé de manière
significative au trouble. Un score de risque polygénique est calculé pour chaque
individu et pour chaque phénotype, et est généralement défini comme une somme
pondérée des SNPs, comme suit :
m
X
P RS = Xj β̂j (1.1)
j=1
où Xj est l’un des allèles du SNP j, m est le nombre de SNPs, et β̂j est le poids associé
au SNP j.
Les PRS jouent un rôle dans la prévention et la détection précoce des maladies. En
effet, ils permettent d’évaluer la prédisposition génétique de l’individu par rapport à
un phénotype, d’où l’importance accordée à leur calcul.
La complexité du calcul des PRS réside dans l’estimation des coefficients β̂, en parti-
culier, au niveau des deux éléments suivants :
• Comment sélectionner les SNPs qui contribuent à la prédiction des phénotypes
d’intérêt ?
• Quels poids accorder aux SNPs qui contribuent à la prédiction des phénotypes
d’intérêt ?
Plusieurs méthodes de construction des PRS ont été développées, chacune ayant ses
propres spécificités, avantages et inconvénients. Certaines méthodes de calcul des
PRS sont présentées dans l’introduction du 3ème chapitre de ce mémoire.
51.2 Présentation des troubles mentaux
Les troubles mentaux, ou troubles psychiatriques, désignent l’ensemble de troubles
conduisant à des problèmes émotionnels et comportementaux chez l’individu, et
dont les causes varient d’un sujet à l’autre, et d’un trouble à l’autre. Le trouble mental
peut être chronique ou permanent, et sa gravité varie d’un sujet à un autre.
Le Manuel diagnostique et statistique des troubles mentaux, et des troubles psychia-
triques de l’Association Américaine de Psychiatrie (souvent appelé DSM-5) définit et
caractérise un trouble mental comme suit :
"Un trouble mental est un syndrome caractérisé par une perturbation cliniquement
significative de la cognition, de la régulation des émotions ou du comportement d’un
individu qui reflète un dysfonctionnement des processus psychologiques, biologiques
ou de développement qui sous-tendent le fonctionnement mental. Les troubles men-
taux sont généralement associés à une détresse ou à une incapacité significative dans
les activités sociales, professionnelles ou autres activités importantes. Une réponse
attendue ou culturellement approuvée à un facteur de stress commun ou à une perte,
comme la mort d’un être cher, n’est pas un trouble mental. Les comportements so-
cialement déviants (par exemple, politiques, religieux ou sexuels) et les conflits qui
opposent principalement l’individu à la société ne sont pas des troubles mentaux, à
moins que la déviance ou le conflit ne résulte d’un dysfonctionnement de l’individu,
tel que décrit ci-dessus." (American Psychiatric Association 2013).
Dans le cadre de ce projet, nous allons nous intéresser en particulier à deux troubles
mentaux, la schizophrénie et le trouble bipolaire.
1.2.1 La schizophrénie
La schizophrénie fait partie de la catégorie du spectre de la schizophrénie et les autres
troubles psychotiques tel que défini dans le DSM-5 (American Psychiatric Association
62013). Les troubles de cette catégorie se définissent par des anomalies dans un ou
plusieurs des cinq domaines suivants : délires, hallucinations, désorganisation de la
pensée (discours), comportement moteur grossièrement désorganisé ou anormal (y
compris la catatonie), et des symptômes négatifs.
1.2.2 Le trouble bipolaire
Le DSM-5 distingue entre deux types de troubles bipolaires, le trouble bipolaire de
type I et le trouble bipolaire de type II (American Psychiatric Association 2013).
Les critères du trouble bipolaire I représentent la compréhension moderne du trouble
maniaco-dépressif classique ou de la psychose affective, décrits au XIXe siècle, et
ne diffèrent de cette description classique que dans la mesure où ni la psychose ni
l’expérience d’un épisode dépressif majeur ne sont requises. Cependant, la grande
majorité des personnes dont les symptômes répondent entièrement aux critères d’un
épisode maniaque connaissent également des épisodes dépressifs majeurs au cours
de leur vie.
Le trouble bipolaire II requiert la survenue d’au moins un épisode de dépression
majeure et d’au moins un épisode d’hypomanie au cours de la vie du patient. Ce
trouble n’est plus considéré comme une affection "plus légère" que le trouble bipolaire
I, principalement en raison du temps que les personnes atteintes de ce trouble passent
en dépression et de l’instabilité de l’humeur qu’elles connaissent.
1.3 Utilisation des scores de risque polygéniques en
psychiatrie
L’utilisation des PRS pour la détection précoce des maladies, la prévention et l’inter-
vention connaît un intérêt croissant, et ce, dans différentes branches de la médecine.
Des études ont montré que les PRS peuvent prédire la survenue de la maladie. Par
7exemple, dans l’étude cas-témoins de Mavaddat et al. (2019), les auteurs ont construit
un PRS qui serait un prédicteur puissant et fiable du risque de cancer du sein, et qui
pourrait améliorer les programmes de prévention du cancer du sein.
Étant donné que la majorité des troubles mentaux sont polygéniques (Sullivan and
Geschwind 2019), l’utilisation des PRS pour la détection et prédiction de ces troubles
semble être une voie prometteuse.
Une comparaison exhaustive de dix méthodes de calcul des PRS pour les troubles
psychiatriques est présentée dans Ni et al. (2021). Les auteurs se sont particulièrement
intéressés à la schizophrénie et à la dépression majeure. La méthode de référence
utilisée est PC+T (en anglais, p value–based clumping and thresholding), qui est
la méthode la plus élémentaire et la plus couramment utilisée pour le calcul des
PRS. Les résultats de l’étude indiquent que les PRS calculés par les neuf méthodes
qui modélisent l’architecture génétique de façon plus formelle ont une meilleure
performance predictive du risque que les PRS calculés par la méthode de référence
PC+T. Bien que les différences entre les neuf méthodes étaient faibles, les méthodes
MegaPRS, LDpred2 et SBayesR ont constamment conduit à de meilleurs résultats.
Dans la revue de Murray et al. (2021), les auteurs évaluent l’utilisation potentielle
des PRS en psychiatrie. Ils expliquent que les PRS permettent d’évaluer une part de
la contribution génétique au risque de la maladie, certes. Toutefois, ils soulignent
qu’utiliser les PRS comme seul prédicteur ne sera jamais suffisant pour établir de
manière définitive le diagnostic des maladies complexes courantes (par exemple, les
troubles du cerveau), car les facteurs génétiques ne contribuent qu’à une part du
risque absolu de la maladie. Combiner les PRS avec d’autres facteurs de risques non
génétiques, par exemple les traumatismes ou le style de vie de l’individu, pourrait
améliorer la prédiction de la survenue du trouble.
8Dans Agerbo et al. (2021), les auteurs tentent de répondre à la question suivante :
dans quelle mesure le score de risque polygénique de la dépression, combiné avec les
facteurs psychosociaux parentaux, détermine-t-il le risque absolu de dépression avant
l’âge de 30 ans ? Les résultats de leur étude cas-témoins suggèrent que les PRS pour
la dépression ne sont pas plus susceptibles d’être associés au trouble dépressif majeur
que d’autres facteurs de risque connus. Toutefois, combinés avec d’autres facteurs de
risques, les PRS peuvent être utiles pour l’identification du risque de l’apparition du
trouble.
Dans le cadre du présent travail, le facteur de risque non génétique considéré est le
statut socio-économique des individus.
9Chapitre 2
Aspects socio-économiques des
troubles psychiatriques
2.1 Association entre le statut socio-économique et les
troubles mentaux
Le dictionnaire de la santé publique définit le statut socio-économique (commu-
nément appelé SES pour socioeconomic status en anglais) comme étant un terme
descriptif de la position des personnes dans la société, basé sur une combinaison de
critères professionnels, économiques et éducatifs, souvent exprimés sur une échelle
ordinale (Last 2007).
L’association entre le SES et l’incidence de troubles du cerveau a été explorée dans
plusieurs travaux. Dans Sareen et al. (2011), les auteurs examinent la relation entre
le revenu du ménage et les troubles mentaux, à travers une étude longitudinale
basée sur la population des États-Unis. Les résultats de leur étude indiquent qu’une
réduction du revenu du ménage est associée à un risque accru de troubles mentaux
incidents, et qu’un faible niveau de revenu du ménage est associé à plusieurs troubles
mentaux qui perdurent dans le temps.
10Dans Silva et al. (2016), les auteurs présentent une revue narrative non systématique
des résultats publiés sur l’association entre la santé mentale et les facteurs sociodé-
mographiques et économiques aux niveaux individuel et régional. La majorité des
150 études incluses dans la revue ont rapporté des associations entre au moins une
caractéristique sociodémographique ou économique et l’état de la santé mentale.
Plusieurs facteurs individuels ayant une association indépendante et statistiquement
significative avec une détérioration de la santé mentale ont été identifiés. Parmi ces
facteurs, on cite par exemple, un faible revenu, un faible niveau d’éducation, un faible
statut socio-économique, le chômage et la pression financière ressentie.
Toutefois, la direction de la causalité entre ces déterminants sociaux et la santé mentale
demeure indéterminée.
Dans Ridley et al. (2020), les auteurs s’intéressent à la relation entre la pauvreté et les
troubles du cerveau communs, comme la dépression et l’anxiété. Ils considèrent que
cette relation est causale et bidirectionnelle.
D’une part, les auteurs considèrent que la pauvreté peut contribuer au développement
de maladies mentales à travers plusieurs mécanismes sous-jacents. On citera par
exemple, les inquiétudes et les incertitudes permanentes causées par la pauvreté,
qui peuvent menacer la santé mentale des individus. Un autre mécanisme serait les
facteurs environnementaux, comme la polution et les températures extrêmes, qui
affectent les personnes les plus démunies de façon disproportionnée, et qui ont été
directement associés aux maladies mentales.
D’autre part, les auteurs estiment que les maladies mentales peuvent à leur tour
causer la pauvreté par le biais de plusieurs mécanismes sous-jacents. Un exemple de
mécanisme serait l’impact des maladies mentales sur les fonctions cognitives. Les
auteurs expliquent que la dépression et l’anxiété, à titre d’exemple, peuvent avoir
des effets économiques car elles réduisent directement la capacité des individus à
travailler, mais aussi affectent leurs fonctions cognitives. Cet impact cognitif pourrait
modifier toute une série de décisions économiques, comme la recherche d’emploi et
11l’épargne.
Les individus ayant des problèmes de santé mentale souffrent également d’une
discrimination sur le marché de travail. En effet, dans Bjørnshagen (2021), les auteurs
examinent dans quelle mesure la discrimination à l’embauche limite les opportunités
d’emploi des jeunes candidats qui révèlent des antécédents de problèmes de santé
mentale, en se basant sur des données d’une expérience de terrain. Leurs résultats
montrent que les candidats qui révèlent des problèmes de santé mentale sont victimes
de discrimination à l’embauche. Plus précisément, les candidats ayant des problèmes
de santé mentale ont environ 27% de chances en moins de recevoir une invitation à un
entretien d’embauche et environ 22% de chances en moins de recevoir une réponse
positive de l’employeur.
Il existe plusieurs mesures du statut socio-économique des individus. Dans le cadre
du présent travail, les mesures du statut socio-économique considérées seront l’indice
Blishen et le revenu.
2.2 L’indice Blishen comme mesure du statut
socio-économique
L’indice Blishen est une échelle occupationnelle pour le Canada, dont une première
version a été présentée dans Blishen (1958). Dans son article, l’auteur décrit un
système qui permet de classifier les professions en fonction du revenu et du niveau
d’éducation moyens des titulaires de chacune d’elles, calculés grâce aux données
du recensement de 1951. L’indice Blishen accorde une valeur numérique à chaque
profession, permettant ainsi de mesurer le statut socio-économique d’un individu
en se basant sur sa profession. L’indice Blishen a classifié 343 professions lors de sa
première construction. La valeur la plus élevée de l’indice Blishen était de 90.0 pour
12la profession de juge, alors que la valeur la plus faible était de 32.0 pour la profession
de chasseurs et de trappeurs.
L’indice Blishen a par la suite été révisé, dans le but d’améliorer sa construction et de
le mettre à jour avec les données du recensement le plus récent.
Une première révision de l’indice Blishen en utilisant les données du recensement de
1961 est présentée dans Blishen (1967). Une seconde révision de cet indice en utilisant
les données du recensement de 1971 est présentée dans Blishen and Roberts (1976).
Il est à noter que lors des révisions de 1967 et 1976, les auteurs n’ont considéré que les
caractéristiques des hommes dans la population active qui exercent les professions
classifiées pour la construction de l’indice Blishen, en partant du principe que le statut
social de la famille dépend de la profession du mari plutôt que de celle de la femme
lorsque les deux travaillent.
Une 3ème révision de l’indice Blishen en utilisant les données du recensement de
1981 est présentée dans Blishen et al. (1987). Les auteurs ont considéré cette fois-ci les
caractéristiques des hommes et des femmes qui exercent les professions classifiées
lors de la construction l’indice Blishen. Ce dernier classifie 514 professions et a une
moyenne de 42.74 et un écart-type de 13.28. C’est la profession dentiste qui présente
la valeur la plus élevée de l’indice Blishen avec 101.74 , tandis que c’est la profession
de livreur et vendeurs de journaux qui présente la valeur la plus faible de l’indice
Blishen avec 17.81.
Les auteurs de Blishen et al. (1987) ont soulevé un certain nombre de problèmes
dans la construction et l’interprétation de cet indice. On citera par exemple le fait
que l’indice Blishen est construit avec des statistiques nationales qui ne sont pas
nécessairement représentatives de la réalité des sous-groupes de la population active.
Pour illustrer cela, les auteurs donnent l’exemple des différences de revenus entre
les hommes et les femmes. Bien que leurs revenus puissent être très disparates, les
femmes et les hommes exerçant des professions identiques sont par définition égaux
13dans leur statut socio-économique au sens de l’indice Blishen. En effet, malgré l’écart
important entre le revenu médian des femmes qui était, en 1981, de 7 847 $ et celui
des hommes qui était de 15 804 $, il n’y avait qu’une légère différence entre l’indice
Blishen médian des femmes calculé en 1987, dont la valeur était de 38.15, et celui des
hommes, dont la valeur était de 39.19.
En raison des problèmes liés à l’indice Blishen, les auteurs de Blishen et al. (1987)
et la littérature en sciences sociales concluent donc que l’indice Blishen est surtout
applicable dans les situations où l’accès aux données socio-économiques se limite
aux professions des individus, et où l’on désire un indicateur unidimensionnel et
contextuel qui situe les individus dans la hiérarchie professionnelle canadienne à un
moment donné, et c’est notamment le cas pour les données utilisées au chapitre 3.
2.3 Le revenu comme mesure du statut
socio-économique
2.3.1 Définition du revenu
Le revenu est considéré comme l’un des indicateurs les plus communs pour mesurer
le statut socio-économique. En particulier, le revenu du marché est souvent employé
à cet effet. L’Institut de la statistique du Québec définit le revenu du marché comme
étant " la somme des revenus suivants : les revenus de travail (qui comprennent les
salaires et traitements avant déductions ainsi que les revenus du travail autonome),
les revenus de placements, les pensions de retraite privées (incluant les rentes d’un
REER), les pensions alimentaires reçues et les autres revenus de sources privées".
(Institut de la statistique du Québec 2020)
Il existe d’autres mesures du revenu qui peuvent mesurer le statut socio-économique
d’un individu, de manière à représenter davantage son pouvoir d’achat. On citera par
14exemple le revenu après taxes et impôts, qui permet de tenir compte des mécanismes
de redistribution mis en place par l’État dans lequel vit un individu.
Lorsque l’information sur le revenu n’est pas disponible, il est possible de l’approxi-
mer en fonction de l’information dont on dispose.
Dans le cadre du présent travail, l’information disponible était la localisation géogra-
phique du domicile (code postal) des individus. La section 2.3.2 présente ainsi une
approche pour approximer le revenu en utilisant ces données géographiques.
2.3.2 Construction de la variable revenu
En supposant que les individus vivant dans un même quartier ont un niveau socio-
économique similaire, il est possible d’approximer le revenu d’un individu par le
revenu moyen du quartier dans lequel il vit. Dans le contexte canadien, les quartiers
sont souvent définis, dans la littérature empirique, au niveau des secteurs de recense-
ment. Statistique Canada définit un secteur de recensement comme suit :
"Les secteurs de recensement (SR) sont de petites régions géographiques relativement
stables qui comptent habituellement une population de 2 500 à 8 000 habitants. Ils
sont créés au sein de régions métropolitaines de recensement et d’agglomérations de
recensement dont le noyau comptait 50 000 habitants ou plus d’après le recensement
précédent." (Statistique Canada 2018)
À partir de données administratives de Revenu Canada, en particulier grâce au fichier
de familles T1 (communément appelé T1FF pour T1 Family Files en anglais) qui
regroupe une série d’informations fiscales pour tous les contribuables canadiens, il
est possible de calculer des statistiques descriptives sur les distributions de revenu à
l’échelle des secteurs de recensement à travers le pays, incluant le revenu moyen du
marché.
15Lorsqu’on connaît le lieu de résidence d’un individu sans avoir accès à ses informa-
tions fiscales privées, il donc possible d’approximer son revenu en lui imputant le
revenu moyen du marché du secteur de recensement auquel il appartient.
Nos données cliniques ne contenant d’information que sur le code postal des indivi-
dus, nous convertissons l’information contenue dans ce dernier à l’échelle à laquelle
les données de revenu agrégé sont disponibles (dans le cas présenté ci-haut, le secteur
de recensement). Cette conversion peut être réalisée à l’aide d’outils produits par
Statistiques Canada et Postes Canada, notamment le fichier de conversion des codes
postaux (PCCF pour Postal Code Conversion File en anglais). Le PCCF est un docu-
ment qui fournit une correspondance entre le code postal et les zones géographiques
standard de Statistique Canada (notamment le secteur de recensement) (Statistics
Canada 2016).
Il suffit alors d’associer chaque individu au secteur de recensement auquel il appar-
tient pour obtenir une approximation de son revenu, et ce, pour l’année à laquelle
l’information sur son lieu de résidence a été collectée. Finalement, il faut ajuster le
revenu estimé pour l’inflation en utilisant l’indice des prix pour la région où vit
l’individu, afin d’obtenir une variable revenu en dollars constants (Statistics Canada
2022). Dans le cadre de ce travail, nous utilisons 2002 comme année de base.
16Chapitre 3
Better prediction of correlated traits
using polygenic risk scores and
socioeconomic variables
3.1 Résumé
Le score de risque polygenique (PRS) est un indicateur qui permet d’évaluer la pré-
disposition génétique d’un sujet par rapport à un phénotype. Les PRS sont souvent
utilisés dans un cadre prédictif de l’apparition des phénotypes, d’où l’importance
accordée à leurs calculs. Plusieurs méthodes de construction des PRS ont déjà été
développées, chacune ayant ses propres spécifités, avantages et inconvénients. Dans
cet article , nous proposons une nouvelle méthode pour le calcul des PRS, nommée
Multivariate lassosum, qui utilise l’information disponible dans les statistiques réca-
pitulatives, qui tient compte du déséquilibre de liaison et qui prend en considération
la corrélation génétique entre les phénotypes. Notre méthode est basée sur un modèle
de régression mixte pénalisé, avec une pénalité LASSO. Notre étude de simulation
a montré que Multivariate lassosum a une meilleure performance predictive que
lassosum et LDpred2, deux méthodes efficaces pour la construction des PRS.
17Better prediction of correlated traits using
polygenic risk scores and socioeconomic
variables
Meriem Bahda1,2* , Alexandre Bureau2 , and Maripier Isabelle3
1
Department of Mathematics and Statistics, Université Laval, Canada.
2
Department of Social and Preventive Medicine, Université Laval,
Canada.
3
Department of Economics, Université Laval, Canada.
*
Corresponding author. Email : meriem.bahda.1@ulaval.ca
Feb, 2022
3.2 Abstract
The polygenic risk score (PRS) is an indicator that assesses the genetic predisposition
of a subject to a phenotype. PRS are often used in a predictive framework for the
appearance of phenotypes, hence the importance given to their calculation. A variety
of methods for PRS calculation are available, each with its own characteristics. In
this paper, we propose a new method for calculating the PRS, named Multivariate
18lassosum, which uses the information available in the summary statistics, takes into
account the linkage disequilibrium (LD) and considers the genetic correlation between
phenotypes. Our method is based on a penalized mixed regression model, with a
LASSO penalty. In our simulations, we compare the performance of our method
with lassosum and LDpred2, two effective methods for the construction of PRS, for
two traits mimicking schizophrenia (SCZ) and bipolar disorder (BIP). Our method,
Multivariate lassosum, led to a better predictive performance than both lassosum and
LDpred2. However, Multivariate lassosum was significantly slower than lassosum.
3.3 Introduction
Genome-wide association studies (GWASs) have proven extremely effective in dis-
covering Single Nucleotide Polymorphism (SNPs) linked to a variety of complex
human disorders. Since most prevalent disorders are polygenic, each SNP accounts
for only a small percentage of the phenotypic variance. However, these variants may
be aggregated into a score, a polygenic risk score (PRS), which can be significantly
associated with the disorder. A polygenic risk score is usually defined as a weighted
sum of the SNP alleles. The main issue is then to estimate the weight of each SNP, in
a way that maximizes the prediction accuracy of the PRS.
The most common estimates of the PRS weights are the SNPs’ regression coefficients
with a single phenotype. A threshold on the SNP’s coefficient p-value is then used
to conduct the SNPs’ selection (Euesden et al. 2015). Some issues arise when using
this standard method for estimating the PRS, such as choosing the optimal threshold
value and how to use the Linkage disequilibrium (LD), which is important, since
ignoring the LD information often leads to an exaggerated estimation of the PRS
information.
A recent proven effective method for calculating the PRS is lassosum, presented in
Mak et al. (2017). Lassosum is based on a penalized regression model framework,
19and uses summary statistics as data entry, which are publicly available data. The
method also takes into account the Linkage Disequilibrium among SNPs. As for the
SNPs’s selection, the authors used a LASSO penalisation, which is quite effective in a
predictive framework, and especially when the number of variables is high, which is
often the case with genetic data sets.
LDpred (Vilhjálmsson et al. 2015) is also a popular method for PRS calculation. It
is based on a Bayesian approach and estimates the PRS using summary statistics
and a matrix of correlation between genetic variants. A new version of the method,
LDpred2 presented in Privé et al. (2020) was recently proposed that addresses some
of LDpred’s limitations that may reduce its predictive performance. For example,
LDpred is unstable in long-range LD regions. The LDpred2 method also has a new
sparse option that can learn SNP effects that are exactly 0, thus, discarding the SNPs
that are not important in the calculation of the PRS.
However, the lassosum and LDpred2 methods are used in a univariate framework, i.e,
they calculate the PRS for each phenotype separately. Since many disorders are highly
correlated, estimating the individual PRS for multiple disorders simultaneously might
improve prediction accuracy. Using a multivariate approach, which takes into account
the strong genetic correlation between schizophrenia, bipolar disorder and major
depressive disorder resulted in a significant increase in the prediction accuracy of the
disorders, as found in Maier et al. (2015).
In this paper, we present the Multivariate lassosum method, which is an extension
of lassosum to a multivariate framework, taking into consideration the genetic cor-
relation between disorders to further improve the prediction accuracy of the PRS.
Our method calculates the PRS, using a modified version of the multivariate mixed
model of Maier et al. (2018), to which we add a LASSO penalization for SNP selection.
Simulations with two dichotomous traits mimicking schizophrenia (SCZ) and bipolar
disorder (BIP) showed that Multivariate lassosum achieves a higher correlation of PRS
20with the simulated PRS than univariate PRS calculated with lassosum and LDpred2.
We also computed PRS with a real-world dataset using Multivariate lassosum, and
built a predictive model for the onset of a psychiatric disorder using the constructed
PRS and socioeconomic variables.
3.4 Methods
3.4.1 Multivariate estimation of SNPs weights
The method presented in this paper was initially designed for continuous phenotypes,
but in the scope of this work, we apply this method to binary phenotypes. The reason
behind this choice is that by working with a model for a binary outcome, we were
not able to derive SNPs weight estimates from publicly available summary statistics.
Other authors have used a similar approach, like Mak et al. (2017) and Maier et al.
(2018).
Similarly to Maier et al. (2018), we consider the following linear mixed model :
y = Xβ + ε (3.1)
where y is a vector of centered phenotypes, X is a standardized matrix of SNP
q
genotypes, such as the ij th element is defined as : xij = (wij − 2pj ) / 2pj (1 − pj )
with wij the number of minor alleles (0,1 or 2) for the ith individual at the j th SNP
and pj the minor allele frequency, β are the genetic effects for each SNP, distributed as
such, β ∼ N (0, B), and ε represents a random error with E(ε) = 0 and V ar(ε) = Σe .
We denote the number of phenotypes by q, the number of SNP markers by p, the
number of subjects by n.
For each subject, we measure the outcome for all of the phenotypes. Note that in the
theoretical framework, genotypes and phenotypes are assumed to be measured on
the same subjects for model derivation, but in practice, phenotypes are measured in
21different subjects and in different numbers.
We denote the outcome of the subject i for the phenotype k by yik . We define then y as
a vector of the outcome of length n × q defined as y = (y11 ,..,y1q ,y21 ,..,y2q ,..,yn1 ,...,ynq )⊤ .
X is a (n × q) × (p × q) matrix of standardized SNP genotypes defined as
X11 X12 . . . X1p xij 0 ... 0
X21 X22 . . . X2p 0 xij . . . 0
X= with Xij = , with xij is the geno-
.. .. ..
.. .. ..
. . . . . .
Xn1 Xn2 · · · Xnp 0 0 · · · xij
type for the subject i and for the SNP j. xij is the same for all phenotypes, since the
SNP genotype does not vary by phenotype.
β is a vector of length p × q defined as β = (β11 ,..,β1q ,β21 ,..,β2q ,..,βp1 ,...,βpq )⊤ .
For each SNP, we estimate the genetic effet β for all of the phenotypes. Therefore : βjk
is the genetic effect for the SNP j for the phenotype k.
Using C. R. Henderson’s expression for the logarithm of the joint probability density
function of Y and β, found for example, in the book Linear and Generalized Linear
Mixed Models and Their Applications by Jiang (2007), Equation (2.36), we can derive
the log-likelihood of the model (3.1) :
1h i
f (β) = C − (y − Xβ)⊤ Σ−1
e (y − Xβ) + β ⊤ −1
B β (3.2)
2
where B = Ip ⊗ Σb and B −1 = Ip ⊗ Σ−1
b , with ⊗ being the Kronecker’s product.
Σb is a (q×q) variance-covariance matrix of genetic effects, B is a (p×q)×(p×q) matrix.
Σe = In ⊗ Σs is a (n × q) × (n × q) diagonal residual matrix where Σs = diag (σε2 ) is a
diagonal q × q matrix and σε2 = (σε21 ,...,σε2q ). We note that we use a diagonal residual
matrix in order to identify the model with unrelated subjects.
22In general, the heritability of phenotypes and their genetic correlation are estimated
from summary statistics of large GWAS, using a set of methods, like the LD score
regression for example (Bulik-Sullivan et al. 2015).
We follow a similar methodology as in Mak et al. (2017) to derive estimates of β using
the LASSO penalty (Tibshirani 1996). We therefore minimize the following objective
function :
f (β) = (y − Xβ)⊤ Σ−1 ⊤ −1 1
e (y −Xβ) + β B β + 2λ∥β∥1
= y ⊤ Σ−1 βj⊤ Σs
X X
e y−2 Xij yi
j i
(3.3)
( " ! # )
Xij⊤ Xil βj ⊤ Σ−1 ⊤ −1 1
X X X
+ s βl + βj Σb βj + 2λ∥β∥1
j l i
The summation indices, j and l, represent the SNPs, while the summation index i
denotes the subjects.
X1T yk
Using a similar notation as in Mak et al. (2017), we denote by rk = n
, the SNP-wise
X1T X1
correlation between the SNPs and the phenotype k, and by R = n
, the linkage
disequilibrium (LD) matrix, a matrix of correlations between SNPs, with yk being the
outcome for the phenotype k, X1 being the genotype matrix for a single phenotype,
y1k x11 · · · x1p
..
.. . . .
defined as yk = . and X1 = . . .. . Estimates of rk can be found
ynk xn1 · · · xnp
in publicly available summary statistics, and estimates of R can be found in publicly
available genotype.
Equation (3.3) becomes then
f (β) = y ⊤ Σ−1 βj⊤ Σ−1 βj⊤ nRjl Σ−1 βj⊤ Σ−1 1
X XX X
e y−2 s nrj + s βl + b βj +2λ∥β∥1 (3.4)
j j l j
However, since the genotype matrices X used to estimate R and r will in general be
XrT Xr
different, it is more accurate to write R = nr
, where nr is the number of subjects
23in the genotypes Xr used to derive LD. Furtheremore, as mentioned previously, in
practice, phenotypes are measured in different subjects and in different numbers. It is
therefore more accurate to consider n as a vector n = (n1 ,...,nk ,...,nq ) of the number of
subjects in the sample used to compute the summary statistics for the q phenotypes
rather than an integer. We can then redefine the vector of the SNP-wise correlation
X1T yk
between SNPs and the phenotype k as rk = We note that in this framework,
nk
.
√
unlike Mak et al. (2017), we do not divide y and X by n, since the number of
subjects in the sample used to compute the summary statistics can be different for the
q phenotypes.
Equation (3.4) becomes then
f (β) = y ⊤ Σ−1 βj⊤ Σ−1
X
e y−2 s diag(n)rj
j
βj⊤ diag(n)Rjl Σ−1 βj⊤ Σ−1 1
XX X
+ s βl + b βj + 2λ∥β∥1
j l j
(3.5)
= y ⊤ Σ−1 βj⊤ Σ−1
X
e y−2 s diag(n)rj
j
⊤
P !
( i Xrij Xril ) −1
βj⊤ βj⊤ Σ−1 1
XX X
+ diag(n) Σs βl + b βj + 2λ∥β∥1
j l nr j
However, we are no longer be in the framework of a LASSO problem. In order to
overcome this issue, we use a similar regularization as the one used by Mak et al.
Xr⊤ Xr Xr⊤ Xr
(2017), by replacing nr
with Rs = (1 − s) nr
+ sI for some 0 < s < 1.
Equation (3.5) becomes then
f (β) = y ⊤ Σ−1 βj⊤ Σ−1
X
e y−2 s diag(n)rj
j
h i (3.6)
βj⊤ X̃j⊤ X̃l Σ−1 βj⊤ Σ−1 2λ∥β∥11
XX X
+ diag(n) + sI s βl + b βj +
j l j
√
where X̃ = 1 − s √Xnrr and Xrj is a nr × q genotype matrix for the SNP j, each column
of Xrj refers to a phenotype.
24Therefore, for the SNP j and phenotype k, we find the βjk estimate by minimizing
the objective function
h i
2
f (βjk ) = βjk nk X̃j⊤ X̃j + s σ −2 εk + Σ−1
b
k kk
1X X
− 2 × βjk − (Σb )−1 −1
kh βjh + Σs nk rj − nk Σ−1
s X̃j⊤ X̃l · βl (3.7)
2 h̸=k k kk
ℓ̸=j
+ 2λ |βjk |
Following a similar scheme as in Mak et al. (2017), the solution to the minimization
of f (βjk ) is found by iteratively updating βjk as follows :
If A < 0 :
0
if A + λ > 0
(t)
βjk = (3.8)
A+λ
otherwise
nk (X̃j⊤ X̃j +s) σε−2 +(Σ−1
b )
k k kk
If A > 0 :
0
if A − λ < 0
(t)
βjk = (3.9)
A−λ
otherwise
nk (X̃j⊤ X̃j +s) σε−2 +(Σ−1
b )
k k kk
Where
1X X
(Σb )−1
(t−1) −1 −1 (t−1)
A = (− β
kh jh + Σs nk rj − n k Σs X̃j⊤ X̃l · βl )
2 h̸=k k kk
ℓ̸=j
An R package that performs β estimation is available at https://github.com/
abureau/multivariateLassosum
3.4.2 Selection of tuning parameters
In order to choose the tuning parameters of our model, λ and s, we performed the
pseudovalidation method developed by Mak et al. (2017). This procedure can choose
25Vous pouvez aussi lire

















































