Scality et le stockage distribué objet JRES 2017
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Scality et le stockage distribué objet JRES
2017
Alexandre Salvat
CNRS DSI
358 Rue Pierre Gilles de Gennes
31670 Labège
Résumé
Dans le contexte du service MyCore du CNRS, cette présentation fera un retour d'expérience sur le choix
et la mise en place d'un projet innovant de stockage distribué objet à fortes contraintes de disponibilité et
d'évolutivité de la volumétrie.
Il sera présenté en détail les raisons du choix d'une solution de type Software Defined Storage, et en
particulier de Scality (www.scality.com), avec une introduction aux principes de fonctionnement de ce type
d'infrastructure.
Il sera ensuite abordé les différentes phases du projet :
- la définition de l'architecture hyper-convergée ;
- la mise en œuvre ;
- l'importance de la phase pilote ;
- l'exploitation actuelle (run, capacity planning, sécurité).
La présentation abordera également les aspects coûts liés au projet et à son exploitation.
Pour conclure, il sera exposé les évolutions envisagées de l'infrastructure afin d'améliorer le service et de
développer de nouveaux usages.
Mots-clefs
SDS, Scality, Stockage distribué objet, Stockage capacitif
1 Rappel du contexte et besoin initial
Dans le but d’élargir sa gamme de service à destination des laboratoires et personnels CNRS, la DSI a pris
le parti de lancer le service My CoRe (http:// ods.cnrs.fr/mycore.html), basé sur le logiciel libre ownCloud
(http://www.owncloud.org/).
Via un espace personnel « gratuit » de 20 Go, ce service permet aux agents travaillant dans des unités
CNRS :
d’échanger des fichiers avec d’autres personnes, partenaires privés ou personnels du monde de la
recherche, de façon souple ;
de partager et de synchroniser des fichiers dans un espace accessible de n’importe quel lieu dispo-
sant d’un accès internet (nomadisme), avec tout type de plate-forme ;
d’assurer une sauvegarde "simple" et "sécurisée" de ses fichiers professionnels.
JRES 2017 - Nantes 1/15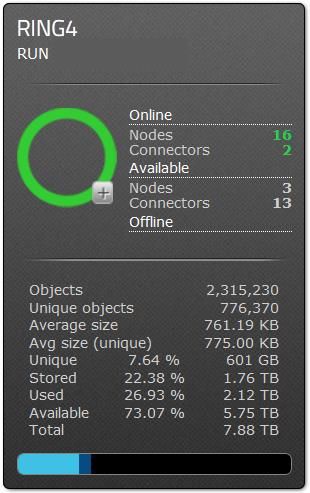
Le service est hébergé physiquement au CC IN2P3 de Villeurbanne. L’exploitation est réalisée par un
prestataire. Le CNRS quant à lui assure la gestion de projet, le pilotage de l’exploitation et la cohérence
technique de la plateforme.
L’ouverture en production du service a débuté en octobre 2015 après près de deux ans de préparation.
2 Choix de la solution technique
Le stockage a fait l’objet d’une étude particulière, car étant donné les volumes à gérer à la cible, si le service
a du succès, une solution résiliente au meilleur coût était nécessaire. Parmi les diverses solutions du marché,
trois ont fait l’objet d’une attention poussée, car répondant à divers critères internes. Ces trois solutions ont
au final été évaluées ainsi :
Critère Scality Dell Compellent EMC² Isilon
Architecture Solution distribuée Solution industrielle Solution industrielle
adaptée aux stratégies centralisée distribuée
cloud
Maturité Solution récente mais Excellente Excellente
disposant de bons ReX
Administrabilité Exploitation complexe Très industrialisée Solution la plus simple
mais outillage suffisant à exploiter
Coûts Plus cher à la cible Moins cher à la cible Coût à la cible impor-
(dans le strict contexte tant
projet)
Évolutivité Forte (multi projets et Faible Bonne (mais en des-
multi sites) sous de Scality)
Qualité de service at- Pas de différenciation Pas de différenciation Pas de différenciation
tendue nette nette nette
Conclusion Solution la plus souhai- Solution qui répond aux Solution facile d’utilisa-
table mais la plus oné- besoins projet de stock- tion mais trop liée à un
reuse age, sans permettre matériel donné (par op-
d’évolution position à Scality)
Ce sont les critères de résilience, de disponibilité (architecture en ARC, pas de RAID matériel, voir section
4.2) ainsi que la variété du matériel utilisable qui a fait pencher la balance du côté de Scality.
Nous avons opté pour une implémentation sur du matériel Dell de type R630 avec des baies d’extension de
stockage MD3460. Les serveurs et leurs extensions sont couplés en attachement direct avec une
connectique supportant 12 Gbits/s. Chaque baie contient 40 slots pour les disques qui accueilleront les
données utilisateurs. L’ajout de disques pouvant se faire au fur et à mesure des besoins, le parti n’a pas été
pris de peupler au maximum les baies de stockage pour des questions de sobriété budgétaire. Une première
JRES 2017 - Nantes 2/15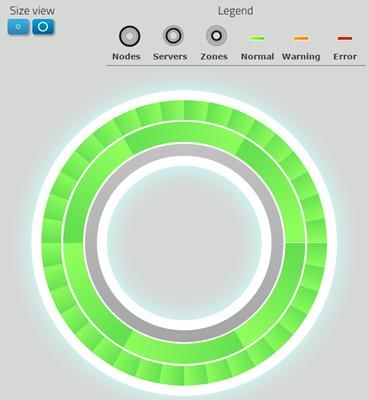
extension a été réalisée à la fin de la phase pilote portant ainsi la capacité de la plateforme à 500 To utiles.
Actuellement, avec des disques de 10 To, nous pouvons encore ajouter 792 To utiles sans ajouter de
serveurs.
À l’initialisation côté disque SSD dont l’utilité sera précisée après, chaque serveur embarquait un disque
SSD de 800 Go. Lors de la seconde année d’exploitation, nous avons porté la capacité SSD totale de 4,8 à
34 To.
Scality a aussi l’avantage de pouvoir servir de support de stockage pour plusieurs solutions logicielles via
ses différentes API. Même si l’usage qui en est fait actuellement par My CoRe est de type filesytem
classique, les API de type REST ou Amazon S3 sont natifs à la solution. La solution peut aussi servir de
support de stockage pour OpenStack (stockage des objets du catalogue). La solution ne permet pas
l’exécution des machines virtuelles.
L’implémentation de la solution Scality peut se faire de plusieurs façons en ce qui concerne la répartition
physique des équipements. Il y a trois mode d’implémentation :
mono-site (exemple My CoRe) ;
dual-sites avec réplication asynchrone ;
multi-sites avec une réplication synchrone.
3 Les concepts généraux
Dans ce chapitre sera expliqué au lecteur les différents concepts généraux sur lesquels repose la solution de
stockage Scality. La majeure partie de ces concepts sont transposables sur d’autres solutions de stockages
distribués.
3.1 Software Defined Storage (SDS)
Le stockage défini par logiciel (SDS) est un terme commercial pour les logiciels de stockage de données.
Celui-ci permet la fourniture et la gestion du stockage présenté via le biais de politiques à définir en fonction
des solutions, indépendamment du matériel sous-jacent.
Le stockage défini par logiciel comprend généralement une forme de virtualisation du stockage pour séparer
le matériel du logiciel qui le gère. La couche logicielle du SDS permet également en fonction des produits
de définir un certain nombre de politiques telles que la réplication et ou la déduplication de données, le thin
provisionning (allocation fine), les snapshots et la sauvegarde.
Le matériel SDS peut ou non avoir un logiciel d'abstraction, de mise en commun ou d'automatisation propre.
Si les fonctions de politique et de gestion comprennent également une forme d'intelligence artificielle pour
automatiser la protection et la récupération, elle peut être considérée comme une abstraction intelligente.
Le stockage défini par logiciel peut être implémenté via des appareils sur un réseau de stockage traditionnel
(SAN), ou mis en œuvre en tant que stockage réseau (NAS) ou encore en utilisant un stockage objet.
JRES 2017 - Nantes 3/15
3.2 Stockage objet Le stockage objet, dit également stockage orienté objet, est un terme générique décrivant une approche du traitement et de la manipulation d'entités de stockage indépendantes appelées « objets ». À l'instar des fichiers, les objets contiennent des données, mais ils ne sont pas organisés de manière hiérarchique. Chaque objet existe au même niveau dans un espace d'adressage linéaire (ou plat) appelé pool de stockage. Et un objet ne peut pas être placé à l'intérieur d'un autre. Les fichiers comme les objets intègrent des métadonnées associées aux données qu'ils contiennent, à la différence près que les métadonnées des objets sont étendues. Chaque objet se voit affecter un identifiant unique qui permet à un serveur ou à un utilisateur de l'extraire sans avoir besoin de connaître l'emplacement physique des données. Cette approche s'avère pratique pour automatiser et rationaliser le stockage de données dans les environnements informatiques en cloud. 3.3 Erasure Coding L’erasure coding est une méthode de protection des données qui divise les données en fragments développés et chiffrés. Ceux-ci contiennent des éléments de données redondants et sont stockés sur différents sites ou supports de stockage. L'objectif est de pouvoir reconstruire les données qui ont été altérées lors du processus de stockage sur disque à partir des informations stockées dans d'autres emplacements de la baie. L’erasure coding est souvent utilisé à la place du RAID classique, car il réduit la durée et le traitement nécessaires à la reconstruction des données. L'inconvénient de cette méthode est qu'elle s'avère parfois plus gourmande en CPU et qu'elle augmente la latence. Celui-ci est utile pour les importants volumes de données et les applications ou systèmes qui doivent être tolérants aux pannes. Le stockage orienté objets dans le Cloud en est un des cas d'utilisation courants. L’erasure coding crée une fonction mathématique pour décrire un ensemble de chiffres afin d'en vérifier la précision et de récupérer ceux qui sont perdus. Cette notion, appelée interpolation polynomiale ou suréchantillonnage, est la clé de la méthode. En termes mathématiques, la protection qu'elle offre est représentée par l'équation suivante : n = k + m. La variable k est le volume de données ou de symboles d'origine. La variable m représente les symboles supplémentaires ou redondants ajoutés pour protéger des défaillances. La variable n est le nombre total de symboles créés après le traitement. Par exemple, dans une configuration de 10 sur 16 ou « EC 10/16 », six symboles supplémentaires (m) sont ajoutés aux 10 symboles de base (k). Les 16 fragments de données (n) sont dispersés sur 16 disques, nœuds ou lieux géographiques. Le fichier original peut être reconstitué à partir de 10 fragments vérifiés. JRES 2017 - Nantes 4/15
3.4 Code Reed Solomon
Les codes Reed-Solomon sont des codes de correction d'erreurs basés sur des blocs avec une large gamme
d'applications dans les communications et le stockage numériques. Les codes Reed-Solomon sont utilisés
pour corriger les erreurs dans de nombreux systèmes, y compris:
dispositifs de stockage (y compris les bandes, les disques compacts, les DVD, les codes à barres,
etc.) ;
communications sans fil ou mobiles (y compris les téléphones cellulaires, les liaisons hyperfré-
quences, etc.) ;
communications par satellite ;
télévision numérique / DVB ;
modems haute vitesse tels que ADSL, xDSL, etc.
L'encodeur Reed-Solomon prend un bloc de données numériques et ajoute des bits « redondants »
supplémentaires. Des erreurs surviennent pendant la transmission ou le stockage pour plusieurs raisons (par
exemple, des bruits ou des interférences, des rayures sur un CD, etc.). Le décodeur Reed-Solomon traite
chaque bloc et tente de corriger les erreurs et de récupérer les données d'origine. Le nombre et le type
d'erreurs pouvant être corrigés dépendent des caractéristiques du code Reed-Solomon.
Un code Reed-Solomon est spécifié comme RS (n, k) avec les symboles s-bit. Cela signifie que l'encodeur
prend k symboles de données de s bits chacun et ajoute des symboles de parité pour créer un mot de code
symbole n. Il existe des symboles de parité n-k de s bits chacun. Un décodeur Reed-Solomon peut corriger
les symboles t qui contiennent des erreurs dans un mot de code, où 2t = n-k.
4 Principes et spécificités Scality
Dans les différents paragraphes ci-dessous seront exposés les différents composants physiques et logiciels
permettant à la solution de stockage de fonctionner. L’idée étant de donner au lecteur une vision globale
des mécanismes à l’œuvre sur la plateforme.
4.1 Prérequis matériels et logiciel
Le produit Scality est compatible avec tout type de serveurs de type x86, la solution s’installe sur un système
Linux RedHat ou CentOS et Ubuntu. Un disque SSD est nécessaire par serveur physique. Scality n’est pas
compatible avec Windows.
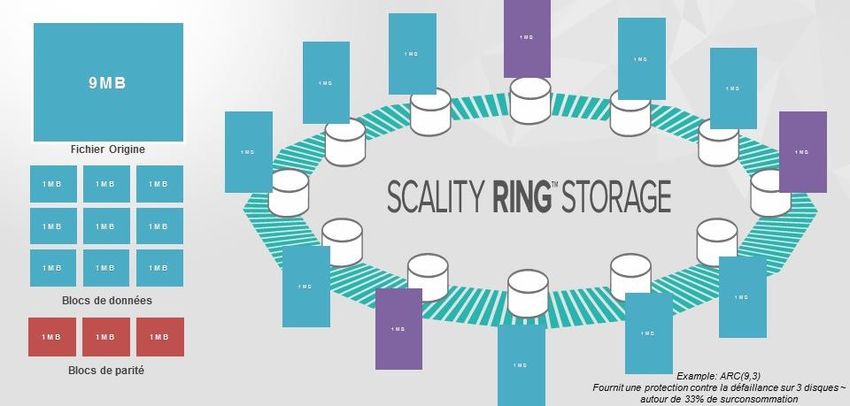
4.2 La notion d’ARC ou de réplication
La notion d’ARC (Advanced Resilience Configuration) répond à la même problématique que les
périphériques RAID. Comment augmenter la tolérance de panne ? Et ce, à un coût inférieur à la réplication
classique des données sur différents disques. Il utilise les mêmes calculs mathématiques d'arrière-plan
(codage basé sur Reed-Solomon) que la technologie RAID. Cependant, le système ARC organise les
données d'une manière complètement différente, plus adapté à un pool de stockage. Il assure la disponibilité
des données en gérant une complexité supplémentaire pour les opérations de reconstruction et les
JRES 2017 - Nantes 5/15commandes GET s'il y a des données manquantes. Le code à effacement est implémenté à l'aide de la
bibliothèque Jerasure.
Il existe plusieurs façons d’implémenter la notion d’ARC et celle-ci s’implémente en définissant deux
valeurs. La première étant de nombre de blocs dans lequel le fichier va être découpé. La seconde valeur
correspond au nombre de blocs de parités.
À l’installation, on définit la taille d’un bloc de données sur la solution de stockage.
Le schéma ci-dessous illustre cette répartition sur les différents serveurs du cluster.
Figure 1 - Un exemple d’architecture ARC 9+3
Le type d’ARC est paramétrable, 4+2, 6+2 ou 9+3. La gestion de l’ARC a une influence directe sur le ratio
Gigas brut / Gigas utiles.
4.3 Le Ring Meta Data
Le Ring Meta Data (disques SSD) :
contient les données utiles des applications ou des utilisateurs pour les fichiers ayant une taille
inférieure à la taille du bloc défini lors de la mise en œuvre du Ring Data ;
pas de répartition de la donnée sur plusieurs disques ;
contient les entrées et indexes de répertoires ;
contient les liens symboliques ;
la liste des "morceaux" de fichiers bruts existants.
JRES 2017 - Nantes 6/154.4 Le Ring DATA
Le Ring Data (disques SATA) :
contient les données brutes des applications ou des utilisateurs ;
organisé dans des containeurs ;
pas de limitation d'inodes ;
pas de limitation de block-size ;
pas de fragmentation, les données sont intelligemment réarrangées au fil du temps ;
la répartition des blocs est fonction de l’architecture de l’ARC ;
utilise des disques à faible coûts.
4.5 Les bizobjs
Les bizobjs
stockés sur les SSD en dehors du ring Meta Data ;
contient les métadonnées utilisateurs des données brutes pour un disque donné
un fichier bizobj par disque et par ring géré sur ce disque ;
données contenues :
o filename
o CRC (Cyclic Redundancy Check)
o permissions
o emplacement dans le conteneur
o taille
o version
o etc.
4.6 Concept de Store Node
Un store node est un processus d'exécution qui fait partie du ring de stockage (basé sur du peer-to-peer) et
est responsable d'une gamme de données. Le ring fournit la sécurité des données en répliquant les données
vers différents store node. Chaque serveur physique de l'anneau héberge généralement plusieurs store nodes
(6 dans notre cas).
Sur chacun d’eux, le processus bizstorenode communique avec le processus biziod pour effectuer des
opérations d'I/O impliquant l'accès au stockage sur disque.
4.7 Le superviseur
Le superviseur est une interface web permettant la configuration et l’exploitation de la solution de stockage.
Celui-ci permet la gestion des serveurs physiques, des opérations de maintenances ainsi que des différents
JRES 2017 - Nantes 7/15composants logiciels. Il embarque aussi un rôle de supervision et indiquant l’état des actions en cours ainsi
que des différents composants physiques ou logiciels.
Il permet d’opérer un certain nombre d’opérations sur le ring telles que la sortie ou l’intégration d’un
serveur physique, les mécanismes de purges et de réallocation, entre autres.
Le superviseur remonte un plusieurs d’indicateurs de haut niveau
tels que :
l’état des connecteurs ;
le nombre de serveurs en ligne et hors ligne ;
le taux usage de l’espace disque ;
le nombre d’objets ;
etc.
Le graphe ci-contre représente de l’extérieur du
cercle vers l’intérieur :
le nombre et l’état des « nodes » ;
les serveurs physiques ;
la zone logique.
À partir de la version 6 du ring, la remontée de logs repose sur Elasticsearchet celles des métriques sur
Topbeat. La mise en forme de l’ensemble est effectuée par Grafana.
JRES 2017 - Nantes 8/154.8 Les connecteurs SFUSE Par défaut le ring est un système de stockage objet, et ne fonctionne donc pas comme un système de fichiers traditionnel. Pour permettre aux systèmes UNIX et aux applications d’utiliser « normalement » le stockage, il faut passer par un composant logiciel appelé connecteur. Le Ring Connector SFUSE, également appelé sfused (Scality Fuse Daemon), est l’interface logicielle de la solution de stockage SOFS (Scale Out File System), fournissant la capacité d’écriture sur le ring en mode système de fichiers. Dans le modèle SFUSE, chaque objet (répertoire ou fichier) a une existence sur le ring et peut être consulté via un point de montage POSIX UNIX normal dans un seul espace de nommage global (par exemple /var/spool/imap). Enfin SFUSE permet aussi un accès via CIFS ou NFS. JRES 2017 - Nantes 9/15
Figure 2 - fonctionnement de SFUSE 5 Phase pilote Au début du projet et comme explicité au début de cet article, un comparatif des différentes solutions a été effectué côté équipe projet CNRS. Avant d’en venir à l’implémentation avec du matériel CNRS fraichement acquis, plusieurs séries de tests ont été réalisées sur différentes plateformes. Nous nous sommes dans un premier temps servi d’un « lab » mis à disposition par l’éditeur de la solution, puis nous sommes passés à une implémentation sur machines virtuelles. Ces étapes et les études qui les accompagnent ont servies à l’établissement de l’étude de charge et de dimensionnement décrite par David Rousse lors de sa présentation aux JRES de 2015, voir le chapitre bibliographie. Les performances de la solution de stockage étant un point crucial de la qualité de service, la vitesse de communication entre les serveurs est déterminante. C’est ce qui a conduit l’équipe CNRS à opter pour une architecture de type hyper convergée. Deux baies ont été mobilisées pour ce besoin, reliées entre elles par un lien fibre à 10 Gb/s, le lien entre le serveur et sa baie étant à 12 Gb/s. Les équipes du CC IN2P3 ont participé à l’implémentation physique. Architecture implémentée au lancement de la production JRES 2017 - Nantes 10/15
L’installation initiale a été réalisée avec le minimum de matériel requis, à savoir 6 serveurs physiques et 6 disques SATA par baie d’extension. Cette première implémentation nous a permis de dérouler la phase pilote avec un volume certes limité mais suffisant pour valider la solution. Cette phase a aussi été nécessaire au prestataire pour former les équipes d’exploitation de niveau 1 et 2. Il est impératif de faire partir les exploitants en formation afin de bien comprendre les spécificités d’une solution de type. Le fonctionnement étant très différent d’une baie SAN classique, certains ingénieurs systèmes peuvent avoir des difficultés à appréhender la solution. Pour les personnes souscrivant le contrat de support étendu, le coût de la formation est inclus dans le contrat de service. Lors de cette phase pilote, il n’y a pas eu de problème de disponibilité du service dû à la solution de stockage. Avant d’ouvrir le service à la production, nous avons réalisé une extension du stockage de 300 To. Des retards pris dans la livraison et dans l’installation du matériel ont très sérieusement contraint le planning. La date d’ouverture ayant été officiellement communiquée, nous avons dû nous adapter au mieux. Cette opération n’était pas seulement une extension du stockage, mais plutôt une mise à l’échelle des ring meta data et SATA avec des modifications au niveau des points de montages virtuels des rings. Suite à une erreur de configuration lors de cette opération, le lien entre les bizobjs contenant les adresses logiques des fichiers et leurs emplacements réels sur les disques physiques a été rompu. En conséquence, les fichiers étaient inaccessibles en téléchargement via l’application. Avec le concours du support de l’éditeur, nous avons pu reconstruire ce lien et rétablir le service sans perte de données aucune. JRES 2017 - Nantes 11/15
6 Exploitation au quotidien
6.1 Les tâches d’exploitations
Les tâches d’exploitations consistent principalement à gérer les entrées et sorties des serveurs physiques
pour maintenance et mise à jour. Dans notre contexte, nous pouvons supporter sans aucun impactla perte
d’un serveur et/ou la vision de tous ces disques. Cette tolérance aux pannes nous permet de pouvoir gérer
les maintenances sans aucun arrêt de service.
Dans un premier temps, il convient de « sortir » le serveur du ring via le superviseur. Cette opération
reconfigure le système afin de préserver l’intégrité des données en recalculant la gestion des blocs sur
5 serveurs au lieu de 6. Cette opération peut prendre quelques minutes. Une fois la maintenance de
l’équipement réalisé, il faut par la suite le réintégrer dans le ring, le serveur passe alors en balancing, ce
qui consiste à répartir à nouveau de façon équitable les blocs entre les différents serveurs. Dans notre
contexte, cette opération prend environ deux heures par serveur. Une mise à jour des OS nous prend par
exemple deux jours ouvrés.
Depuis la mise en service de la solution de stockage, nous avons déjà fait plusieurs montées de version du
ring. Nous avons commencé en version 4 et nous sommes actuellement en train d’implémenter la version
6.4. Les mises à jour se font sans arrêt de service si on reste dans la matrice de compatibilité des composants
logiciels.
Il convient de monter de version les différents composants superviseurs, nœuds de stockage et connecteurs
dans cet ordre-là.
En prenant les précautions de rigueur intégrant la validation du bon fonctionnement, il nous a fallu plus de
5 jours ouvrés pour migrer de la version 4 à la version 5. Aucun arrêt de service ou perte de données n’a
été déploré.
Pour les titulaires du contrat de support étendu (DCS), le support de l’éditeur est au plus près des équipes
d’exploitation et peut effectuer un certain nombre de tâches en cas de besoin.
6.2 Capacity Planning
Afin de garantir une exploitation de qualité, les points suivants sont à suivre avec attention :
la quantité de données utiles (données réelles des utilisateurs) ;
la quantité totale de données (données utiles + blocs de parités + corbeille de rétention) ;
le volume du Ring Meta Data (SSD) ;
la consommation de RAM (des clés sont stockées en RAM) ;
le taux d’I/O sur les SSD
Dans la série des éléments sur lesquels nous avons évolué, il y a la surveillance des disques SSD que ce
soit en termes d’I/O ou de volume ; et l’usage de la RAM des serveurs physiques. J’attire l’attention du
lecteur sur le fait qu’il est une chose de superviser d’un point de vue « standard » et une autre que de suivre
de façon primordiale. Les données, certes identiques, ne sont pas traitées avec la même grille de lecture.
JRES 2017 - Nantes 12/15Focus sur ces trois problématiques spécifiques : Le volume consommé sur le Ring Meta Data est fonction pour partie du nombre d’objets et du temps. Plus il y a d’objets sur la solution de stockage et plus celui-ci augmente, les bizobjs stockent l’emplacement physique des blocs, plus il y a d’objets, plus l’espace nécessaire augmente en fonction du temps. L’accès à chaque fichier se fait par l’interrogation du bizobj correspondant pour aller récupérer les différents blocs gérés par les store nodes. Cet état de fait explique pour partie que ce type de solution n’est pas le plus adapté au stockage de fichiers de quelques kilos. S’ils sont en nombre conséquent, d’autres outils sont plus adaptés. De cet état de fait découle naturellement la problématique des I/O sur les disques SSD. Si pour chaque action sur un fichier il y a un accès SSD, sur une durée suffisamment longue, la capacité des SSD devient un facteur limitant. Avec plus de 20 To utiles au moment où nous avons ressenti les ralentissements et une taille moyenne de fichiers inférieures à 1 Mo, nous avons pu constater que 1 seul SSD par serveur pour plus de 25 millions d’objets s’avérait être insuffisant en termes de performance et de taille. C’est pour cela que nous sommes passés à 3 SSD par serveur à une taille unitaire par machine autour des 5 To, quintuplant ainsi la volumétrie et quadruplant les I/O. Le dernier point « surprise » fut celui de de l’occupation de la RAM des serveurs physiques, suite à un manquement à la procédure de remise en service du ring nécessité par une mise à jour. Les mécanismes de « purge » n’avaient pas été réactivés et le volume brut de données était monté à plus de 250 To, pour plusieurs milliards d’objets, ce qui nous à amener à saturer la RAM de nos serveurs à hauteur de 98%. Chaque serveur physique stocke en RAM une clé relative aux fichiers et bizobjs de 47 octets, quel que soit la taille du fichier. Ceci explique pour partie la non adaptation de ce type de stockage aux fichiers de petites tailles en grand nombre. Un reboot du serveur physique est nécessaire après avoir supprimé totalement les fichiers du stockage utile et de la rétention de bas niveau pour terminer de libérer la RAM. 7 Évolutions et nouveaux usages Plusieurs options sont actuellement à l’étude pour faire évoluer la solution de stockage pour les besoins du projet My CoRe ou pour d’autres usages. Afin d’augmenter la résilience du service et d’en assurer la montée en charge, nous étudions la possibilité de nous répartir sur deux sites géographiques. Le cluster de stockage sera alors réparti entre les deux sites et ceci pourrait aussi nous permettre de servir d’autres populations que celles du périmètre initial de My CoRe. D’autres acteurs de la recherche étudient actuellement les solutions de stockage de ce type. Une sauvegarde croisée des données en mode asynchrone serait tout à fait possible. Enfin, dans l’idée de fournir un nouveau service de stockage capacitif, nous étudions la possibilité d’utiliser les capacités natives S3 du ring, ce qui représenterait une évolution importante de l’architecture physique de la plateforme. JRES 2017 - Nantes 13/15
Remerciements Ce retour d’expérience est le fruit du travail de différentes équipes CNRS qui se sont succédées depuis le lancement du projet jusqu’au second anniversaire du service en octobre 2017. Les différents prestataires de la DSI impliqués sur le projet sont aussi à remercier. JRES 2017 - Nantes 14/15
Bibliographie https://github.com/CNRS-DSI-Dev/mycore_press/blob/master/JRES2015/JRES-20151208-article.pdf https://github.com/CNRS-DSI-Dev/mycore_press/blob/master/JRES2015/JRES-20151208-presse- annexes.pdf http://www.lemagit.fr/definition/Erasure-Coding http://www.lemagit.fr/definition/Stockage-Objet https://docs.scality.com/display/R6/Start JRES 2017 - Nantes 15/15
Vous pouvez aussi lire

















































