Utilisation d'ontologies pour la recherche de jeux de données météorologiques.
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Université de Toulouse
Utilisation d’ontologies pour la recherche
de jeux de données météorologiques.
Rédigé par: Superviseurs:
Alexandre Champagne Nathalie Aussenac-Gilles
Spécialité: Cassia Trojahn
M2 Données et Amina Annane
Connaissances Laboratoire:
Durée du stage: MELODI - IRIT
29 Mars 2021 au 1er Tutrice universitaire:
Septembre 2021 Lynda Tamine
Année Universitaire 2020-2021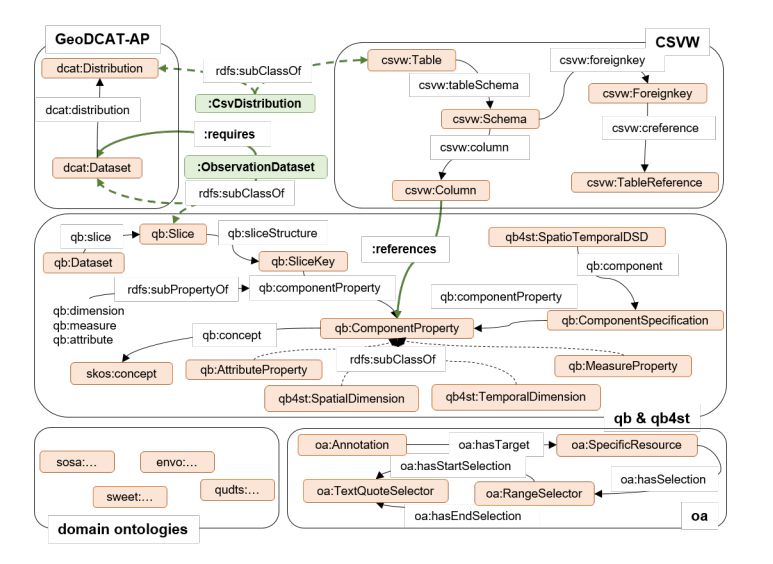
Table des matières
Liste des tableaux iii
Liste des schémas iv
Résumé 1
Abstract 2
Remerciements 3
1 Introduction 4
2 Contexte 7
3 Présentation du sujet 9
4 Démarche méthodologique 11
5 État de l’art 13
5.1 Principes FAIR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.2 Recherche de jeux de données . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
5.3 Recherche sémantique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.4 Étude de vocabulaires de représentation des métadonnées . . . . . . . . . . . . 19
5.4.1 Data Catalog Vocabulary . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.4.2 RDF Data Cube Vocabulary . . . . . . . . . . . . . . . . . . . . . . . 22
5.4.3 CSVW Namespace Vocabulary Terms . . . . . . . . . . . . . . . . . . . 23
5.5 Portails de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.5.1 European data portal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.5.2 Dataosu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.5.3 Google dataset search . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.5.4 Harvard Dataverse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.5.5 DRIIHM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.5.6 AIR BREIZH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.5.7 Récapitulatif des portails . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6 Travaux réalisés 28
6.1 Étude de l’existante : les fonctions de recherche dans la plate-forme DataNooS 28
6.2 Spécifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
6.2.1 Diagramme de composant . . . . . . . . . . . . . . . . . . . . . . . . . 29
6.2.2 Maquette interface de recherche . . . . . . . . . . . . . . . . . . . . . . 30
6.2.3 Cas d’utilisations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
6.3 Implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.3.1 Interface de recherche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.3.2 Recherche par facette . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.3.3 Recherche sémantique . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7 Conclusion 39
7.1 Bilan des résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.1.1 Atteinte des objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
i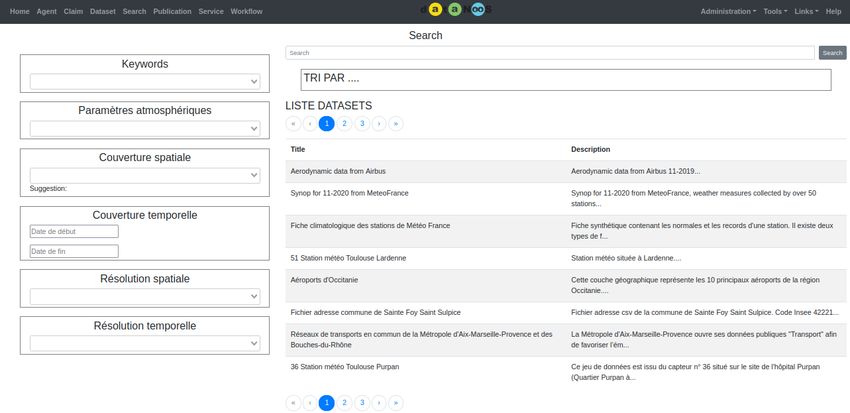
7.1.2 Apport du travail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.1.3 Perspectives d’évolution . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.2 Bilan personnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7.3 Ouverture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Glossaire 41
Acronymes 42
References 43
ii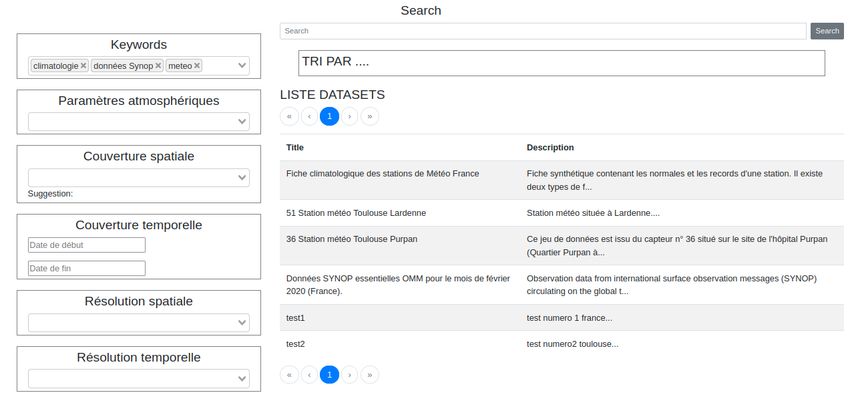
Liste des tableaux
Table 5.1 Tableau synthétisant les critères de recherches sur les sites ex-
istants. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
iii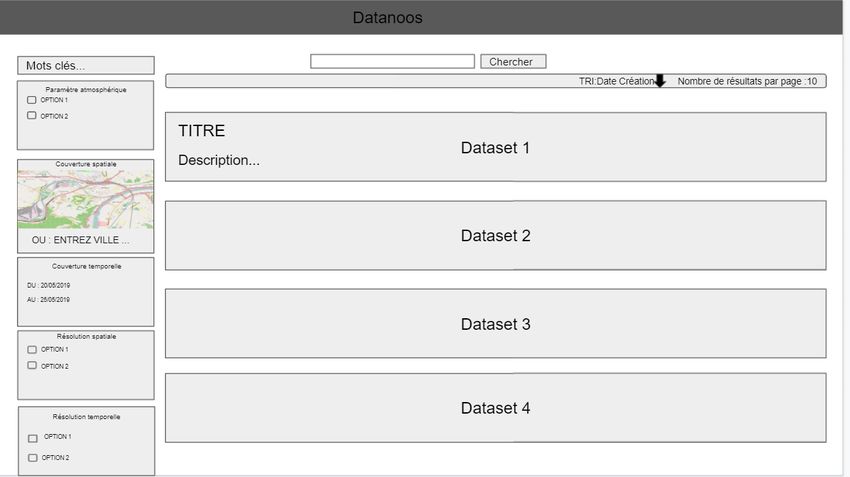
Liste des schémas
3.1 Modèle Ontologique de Semantics4Fair . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Modules de Template et de Recherche de Données . . . . . . . . . . . . . . . . 10
4.1 Diagramme de Gantt du stage . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
5.1 Les principes FAIR (selon [8]). . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
6.1 Diagramme de composants pour la gestion de template et recherche de jeux de
données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6.2 Maquette originale de l’interface de recherche . . . . . . . . . . . . . . . . . . . 31
6.3 Diagramme de séquence pour le premier cas d’utilisation "Recherche par facette" 31
6.4 Diagramme de séquence pour le deuxième cas d’utilisation "Recherche sémantique" 32
6.5 Interface de recherche sur la plate-forme DatanooS . . . . . . . . . . . . . . . 32
6.6 Requête SPARQL sur GraphDB . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.7 Résultat partiel de requête SPARQL sur GraphDB . . . . . . . . . . . . . . . . 34
6.8 Recherche par facette avec un seul type de de critère . . . . . . . . . . . . . . . 34
6.9 Recherche par facette avec plusieurs type de de critères . . . . . . . . . . . . . 35
6.10 Exemple d’une hiérarchie pour la ville de Toulouse . . . . . . . . . . . . . . . . 35
6.11 Recherche pour la France et visualisation des suggestions proposées . . . . . . 36
6.12 Recherche sémantique suggérée pour l’Europe . . . . . . . . . . . . . . . . . . . 37
6.13 Paramètre atmosphérique "température" lié à l’ontologie AWS grâce à qb:concept 37
6.14 Propriétés de l’instanciation air_temperature . . . . . . . . . . . . . . . . . . . 37
6.15 Instances du concept "Temperature" dans AWS (différents types de température) 38
6.16 Paramètres atmosphériques liés au concept "air" dans l’ontologie AWS. . . . . 38
iv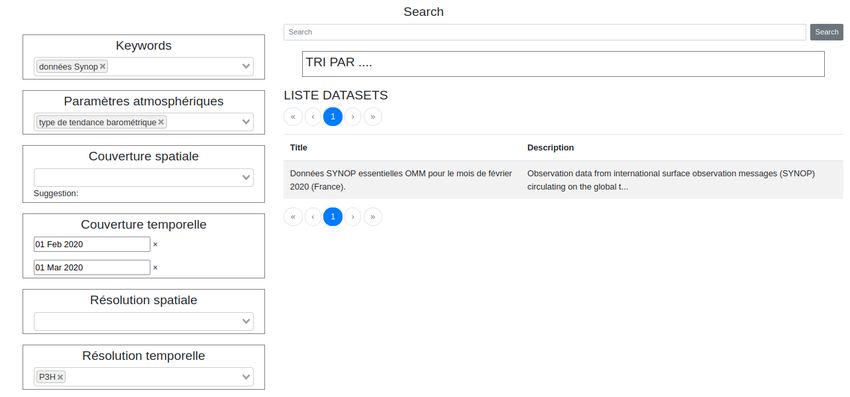
Résumé
Les communautés scientifiques de recherche produisent de grandes quantités de données
qui peuvent être traitées au sein de diverses applications. Ainsi, le centre de recherche de
MétéoFrance rend disponible une partie de ses jeux de données sur le Web. Cependant, rendre
les données ouvertes et accessibles nécessite des efforts considérables si on veut garantir la
qualité des données et leur respect des principes Faciles à trouver, Accessibles, Interopérable, et
Réutilisables (FAIR).
Le domaine de la recherche de jeux de données est très actif dans la mesure où énormément
de portails de données sont aujourd’hui disponibles. Le projet Semantics4fair se focalise sur
des jeux de données particuliers : ceux produits par les chercheurs. Il propose d’implémenter
une approche qui facilite leur réutilisation au service la science ouverte et dans le respect des
principes FAIR. Pour cela, le projet a fait le choix d’implémenter un service de recherche des
jeu de données grâce à une recherche par facette s’appuyant sur des métadonnées sémantiques.
L’originalité de l’approche proposée dans ce projet est double : (i) mise en oeuvre d’une
démarche ergonomique pour le recueil des besoins et des vocabulaires des utilisateurs ; (ii)
une approche sémantique pour relever le défi de la "findability" (rendre les données faciles à
retrouver).
Le cas d’étude support du projet Semantics4FAIR porte sur des données météorologiques,
dont on veut améliorer la facilité à les retrouver, y compris par des scientifiques venant d’autres
domaines, comme des botanistes spécialistes des pollens. En effet, les données produites par
MétéoFrance sont en parties publiques et ouvertes, comme s’y engagent tous les organismes
gouvernementaux. Malgré cela, il reste difficile, pour un non spécialiste de ces données, de les
retrouver, mais aussi, parmi toutes celles offertes, de sélectionner le jeu de données pertinent
pour une étude ciblée.
Les objectifs du stage sont d’implémenter un Module de Recherche de Données (MRD) qui
suppose que les jeux de données sont décrits avec des métadonnées sémantiques, c’est-à-dire
faisant référence aux concepts et propriétés définis dans une ontologie. Le premier objectif
est d’étudier différents portails de données offrant des données météorologiques ouvertes et les
possibilités de recherche sur ces portails. Le second objectif est d’implémenter des fonctions,
interfaces et patrons de requêtes SPARQL facilitant la recherche de jeux de données selon des
critères associés aux méta-données sémantiques.
Dans de ce rapport, nous rendons compte du travail réalisé lors du stage en 2 parties
qui répondent à chacun des objectifs. La première partie est un état de l’art, au cours de
cet état de l’art, différents sujets seront abordés comme les principes FAIR, la recherche de
jeux de données, la recherche sémantique, des portails de jeux de données ou bien encore des
vocabulaires d’ontologies. Les supports consultés correspondent à des articles scientifiques, des
documentations et des portails de données. La seconde partie présente ma contribution qui tient
compte de l’état de l’art afin de réaliser le MRD. La première partie présente la spécification de
ce système, la deuxième partie les choix d’implémentation concernant l’interface et les méthodes
de recherche.
Enfin nous faisons un bilan sur le sujet dans une conclusion.
1Abstract
Scientific research communities produce large amounts of data that can be processed in
various applications. For example, the MétéoFrance research center makes part of its data
available on the Web. However, making data open and accessible requires considerable effort
if one wants to guarantee the quality of the data and their respect for the principles of data
protection.
The field of research is very active as a lot of data is available today. The Semantics4fair
project focuses on particular jeux de données: those produced by researchers. It proposes to
implement an approach that facilitates their reuse in the service of open science and in respect
of the principles of fairness. To do this, the project has chosen to implement a search service for
the jeu de données thanks to a search by facet based on semantic métadonnées.
The originality of the approach proposed in this project is twofold: (i) implementation of an
ergonomic approach for the collection of users’ needs and vocabularies; (ii) a semantic approach
to meet the challenge of "findability" (making data easy to find).
The case study of the Semantics4FAIR project concerns meteorological data, for which we
want to improve the ease of retrieval, including by scientists coming from other domains, such
as botanists specialized in pollens. Indeed, the data produced by MétéoFrance are partly public
and open, as all governmental organizations are committed to do. Despite this, it remains
difficult for a non-specialist of these data to find them, but also, among all those offered, to
select the relevant data set for a targeted study.
The objectives of the internship are to implement a system that assumes that datasets
are described with semantic metadata, i.e. referring to concepts and properties defined in an
ontology. The first objective is to study different portals offering open weather data and the
search possibilities on these portals. The second objective is to implement functions, interfaces
and SPARQL query patterns facilitating the search of portails de données according to criteria
associated with semantic metadata.
In this report, we report on the work done during the internship in 2 parts that meet each
of the objectives. The first part is a state of the art, during this state of the art, various
subjects will be approached like the principles FAIR, the search of jeux de données, the recherche
sémantique, portals of data sets or even vocabularies of ontologies. The consulted supports
correspond to scientific articles, documentations and portails de données. The second part
presents my contribution which takes into account the state of the art in order to realize the
MRD. The first part presents the specification of this system, the second part the choices of
implementation concerning the interface and the search methods.
Finally, we make an assessment of the subject in a conclusion.
2Remerciements
Je tiens dans un premier temps à remercier ma professeure, Mme Trojahn Cassia qui m’a
aidé dans ma recherche de stage et m’a permis d’obtenir le stage sur Semantics4Fair. Ses conseils
à un moment où il y avait peu de stages disponibles à cause du COVID-19, m’ont permis de
trouver ce stage qui était totalement en accord avec mes capacités.
Je remercie également ma tutrice universitaire Mme Lynda Tamine pour m’avoir fait confi-
ance. L’écoute et l’accompagnement dont j’ai bénéficié m’ont permis de passer un stage sans
soucis quelconques.
Je souhaiterais remercier tout particulièrement Mme Nathalie Aussenac-Gilles et Mme Amina
Annane mes tutrices de stage, qui m’ont épaulé et conseillé et qui m’ont surtout transmis leur
expertise dans le domaine du web sémantique.
Je tiens également à remercier l’équipe du projet DataNoos et les stagiaires avec qui j’ai pu
collaborer pour les échanges enrichissant que l’on a eus sur le projet.
D’autre part, je remercie le corps enseignant du Master Données et Connaissances qui m’a
appris les connaissances nécessaires afin de réaliser ce stage.
Enfin je n’oublie pas non plus mes proches qui m’ont sans cesse soutenu dans la réalisation
du stage et m’ont aidé à chaque étape de ce rapport de stage.
3A. Champagne 1. Introduction
1 Introduction
Présentation succinte
Des millions de jeux de données sont disponibles sur le web afin d’être exploités ou réutilisés
par d’autres utilisateurs. Cependant, en l’absence de métadonnées qui les documentent en
indiquant leur contenu, leur indexation par les moteurs de recherche ne suffit pas pour les
retrouver. À l’heure de l’ouverture des données de la recherche, beaucoup de jeux de données
restent difficilement accessibles, et il faut déployer des efforts considérables pour retrouver les
données qui répondent à un besoin. De la part des producteurs de données, des améliorations
doivent être apportées afin de garantir la qualité des données et leur conformité aux principes
FAIR (Faciles à trouver, Accessibles, Interopérables and Réutilisables).
Le projet Semantics4FAIR1 a pour but de faciliter la tâche de recherche et d’accès aux
données scientifiques résultant à la fois de la recherche et de la production par une communauté
scientifique afin de soutenir le développement de nouveaux usages par d’autres communautés.
L’originalité de l’approche proposée est double :
• une méthode basée sur l’ergonomie visant à saisir les besoins et le vocabulaire des utilisa-
teurs;
• une approche sémantique, basée sur l’utilisation d’ontologies standards et de vocabulaires
contrôlés, pour relever le défi de la découverte des données (findability)
L’approche sémantique choisie dans Semantics4FAIR consiste à définir un vocabulaire formel
(ou ontologie) qui organise et structure les métadonnées associées aux jeux de données, en
prenant en compte la différence de conceptualisation entre les producteurs de données et les
utilisateurs recherchant ces données.
Enrichir les jeux de données par des métadonnées est un préalable nécessaire pour retrouver
plus rapidement des jeux de données pertinents avant leur utilisation à grande échelle par
des algorithmes d’Intelligence Artificielle (IA). De plus, l’utilisation de vocabulaires standards
et formalisés pour représenter ces métadonnées permet de réduire les ambiguïtés lors de la
formulation des requêtes pour exprimer des besoins et retrouver les jeux de données y répondant.
Le cas d’étude support du projet Semantics4FAIR porte sur des données météorologiques,
dont on veut améliorer la facilité à les retrouver, y compris par des scientifiques venant d’autres
domaines, comme des botanistes spécialistes des pollens. En effet, les données produites par
Météo France sont en parties publiques et ouvertes, comme s’y engagent tous les organismes
gouvernementaux et académiques. Malgré cela, il reste difficile, pour un non-spécialiste de
ces données, de les retrouver, mais aussi, parmi toutes celles offertes, de sélectionner le jeu de
données pertinent pour une étude ciblée.
Cette problématique est traitée de manière plus générale par le chantier DataNooS2 , un projet
toulousain qui veut rendre plus visibles les données de la recherche à l’échelle de l’université
de Toulouse, et faciliter leur réutilisation de manière interdisciplinaire. Dans le cadre de ce
projet, des cas d’usage servent de terrain d’expérimentation et de production de solutions
conceptuelles et techniques. Le projet Semantics4FAIR est un de ces projets. À titre de preuve
de concept, DataNooS met en place une plateforme de gestion de jeux de données de recherche,
qui respecte les critères FAIR et fournit un catalogue de jeux de données. Ce travail est en
1
https://www.irit.fr/semantics4fair/
2
https://datanoos.univ-toulouse.fr/
Août, 2021 Page 4 of 43A. Champagne 1. Introduction
cours de réalisation. Il sert aussi de contexte à notre travail.
Concernant les objectifs demandés, le stage doit contribuer à une solution méthodologique
et à des logiciels pour faciliter la recherche de jeux de données de Météo France au sein d’un
référentiel dans lequel ceux-ci sont décrits à l’aide de métadonnées adaptées à une démarche
FAIR et aux données météorologiques.
Pour cela, le stage a comporté les tâches suivantes :
• étudier différents portails offrant des données météorologiques ouvertes et les possibilités
de recherche sur ces portails ;
• s’approprier les travaux effectués dans DataNooS et les premières études menées dans
Semantics4FAIR ;
• implémenter des fonctions, interfaces et patrons de requêtes SPARQL facilitant la recherche
de jeux de données selon les scénarios identifiés.
Intérêts du stage
Ce stage offre l’opportunité d’approfondir les connaissances acquises lors du second semestre
de Master 2 en Ontologies, qui est la matière où j’avais le plus de lacunes. Donc c’est une
bonne opportunité d’améliorer mes compétences. Il porte également sur un nouveau domaine
d’application qui m’intéresse, la météorologie. C’est un domaine que je n’ai pas eu la chance de
côtoyer lors de mes études alors que c’est, avec l’aviation, un des domaines prédominants sur la
région toulousaine.
Le stage a pour but de répondre à la problématique d’accès aux données de recherche dans le
cadre du projet Semantics4FAIR. Il est complémentaire du stage de Louis Mendy qui a consisté
à définir des formulaires de saisie de métadonnées pour décrire des jeux de données d’un même
domaine. Ces formulaires utilisent des vocabulaires contrôlés et des ontologies qui permettent
une représentation sémantique des méta-données.
En effet, l’objectif du projet est de développer des algorithmes de recherche sémantique
basés sur le modèle ontologique développé pour ce même projet, selon lequel les données
météorologiques sont décrites. On souhaite ainsi améliorer l’adhérence de ces données au critère
"Findable" (Facile à trouver) des principes FAIR. Cela répond en partie aux spécifications
requises par le projet Semantics4FAIR pour permettre à Météo France ainsi qu’aux chercheurs
scientifiques d’autre domaines (non-spécialistes en météorologie) de retrouver plus sûrement et
plus rapidement des jeux de données.
Plan du mémoire
Le reste de ce rapport est organisé comme suit:
• D’abord, nous présentons le contexte du stage, en présentant notamment l’équipe de
recherche MEthodes et ingénierie des Langues, des Ontologies et du DIscours (MELODI)
au sein de laquelle s’est déroulé le stage, et les deux projets scientifiques Semantics4FAIR
et DataNooS dans lesquels le stage s’inscrit.
• Ensuite, nous décrivons le sujet du stage et ses objectifs d’une manière plus détaillée.
• Après cela, nous abordons la démarche méthodologique qui a été suivie tout au long de ce
stage.
Août, 2021 Page 5 of 43A. Champagne 1. Introduction
• Le travail réalisé sera ensuite présenté de manière chronologique en suivant la démarche
méthodologique.
• Enfin, nous concluons ce rapport en présentant le bilan des résultats obtenus, ainsi qu’un
bilan personnel.
Le Glossaire qui reprend la liste des mots clés et la liste des acronymes utilisés dans ce
rapport sont présentés après la conclusion pour les personnes qui ne sont pas très familières
avec le Web sémantique.
Août, 2021 Page 6 of 43A. Champagne 2. Contexte
2 Contexte
Nous avons effectué notre stage au sein de l’équipe MELODI, une équipe de chercheurs
scientifiques basée à l’Institut de Recherche en Informatique de Toulouse (IRIT).
C’est une équipe qui travaille dans plusieurs domaines des sciences informatiques: l’Ingénierie
des connaissances, les Ontologies, le Web Sémantique ainsi que le Traitement Automatique du
Langage Naturel.
L’équipe s’appuie sur une variété d’approches de recherche, allant de l’étude théorique
des fondements linguistiques de la sémantique et de sa représentation formelle, des structures
d’interaction et de discours, à des travaux plus expérimentaux basés sur des développements
logiciels, sur la construction de ressources (telles que des corpus annotés, des lexiques ou des
ontologies) et des expériences basées sur des corpus.
Le stage s’inscrit dans le cadre du projet de recherche Semantics4FAIR3 . Le but de ce
projet est de faciliter la tâche de recherche et d’accès aux données scientifiques résultant à
la fois de la recherche et de la production par une communauté scientifique donnée, afin de
soutenir le développement de nouveaux usages par d’autres communautés. L’approche adoptée
est basée sur l’utilisation des ontologies pour la représentation des métadonnées des jeux de
données. Semantics4FAIR repose sur la collaboration d’un laboratoire d’informatique (IRIT
équipe MELODI) et en facteurs humains (Maison des Sciences de l’Homme et de la Société de
Toulouse (MSH-T)) avec des communautés scientifiques souhaitant rendre leurs ensembles de
données FAIR et des communautés scientifiques souhaitant réutiliser ces données pour leurs
propres projets de recherche.
Plus particulièrement, le projet propose un travail conjoint avec la communauté scientifique
de l’atmosphère (Centre National de Recherche en Météorologie (CNRM) et Observatoire Midi
Pyrénée (OMP)) en tant que fournisseur de données de météorologie et avec la communauté des
palynologues (Géosciences Environnement Toulouse (GET)) et les services opérationnels de la
météorologie (MétéoFrance) qui seront les deux communautés utilisatrices de données.
D’autre part, le projet Semantics4FAIR s’intègre à un autre projet intitulé DataNooS. Le pro-
jet DataNoos est une alliance académique regroupant chercheur.e.s, enseignant.e.s chercheur.e.s,
ingénieur.e.s, postdoctorant.e.s, étudiant.e.s en Doctorat/Master/Licence autour du partage
de ressources numériques (les données, les plateformes de capture/simulation de données, les
plateformes de calcul et de stockage, les outils de traitement, d’analyse et de visualisation) et
des pratiques de la connaissance.
Le projet DataNooS travaille sur plusieurs cas d’étude notamment sur le croisement des
données en sciences de l’environnement, et plus précisément à la difficulté de trouver les bonnes
données produites par différentes disciplines pour répondre à un besoin précis et à des usages
particuliers. Ainsi, il contribue à définir les conditions nécessaires pour que des jeux de données
soient véritablement conformes aux principes FAIR, y compris pour des personnes d’autres dis-
ciplines que celle des données. Une plateforme qui porte le même nom que le projet "DataNoos"
est en cours de développement afin de récupérer et comparer les expériences scientifiques et les
données de recherche de plusieurs acteurs scientifiques au niveau de Toulouse et ses alentours
tout en prenant en compte le fait qu’elles peuvent être multi-disciplinaire.
La plateforme a plusieurs objectifs :
• Favoriser l’ouverture et le partage des données, notamment celles provenant de différents
domaines de la recherche ;
3
https://www.irit.fr/semantics4fair/
Août, 2021 Page 7 of 43A. Champagne 2. Contexte
• Garantir que les données partagées suivent les principes FAIR ;
• Faciliter le référencement croisé de multiples sources de données ;
• Préparer les données afin qu’elles soient utilisées pour être analysées ou exploitées par des
algorithmes d’apprentissage automatique en IA.
Afin de remplir ces objectifs, le projet DataNooS mène 3 différents types d’actions :
• Collecter des informations provenant de questionnaires, état de l’art, recommandations à
adopter, évolution des méthodes ;
• Promouvoir des preuves de concepts ou des démonstrations ;
• Intégrer les résultats de recherche sur le partage de jeux de données ainsi que des expériences
provenant de cas d’utilisation.
Août, 2021 Page 8 of 43A. Champagne 3. Présentation du sujet
3 Présentation du sujet
Le sujet du stage consiste à spédifier et implémenter une fonction de recherche de jeux
de données au sein d’un portail de jeux de données. Cette recherche doit exploiter sur les
métadonnées qu’ils possèdent en s’appuyant sur le modèle ontoogique Semantics4Fair[1] que
l’on peut voir ci-dessous:
Figure 3.1: Modèle Ontologique de Semantics4Fair
Le modèle ontologique de Semantics4Fair est assez complexe, et il est composé de plusieurs
modules représentés par les concepts encadrés dans la figure 3.1. En effet, il a pour vocation de
décrire toutes les métadonnées au mieux possibles afin de répondre au problème que sont les
sciences ouvertes et respecter un maximum les principes FAIR.
Ce modèle est une agrégation de différents vocabulaires ontologiques (en orange sur l’image) et
les additions de Semantics4Fair (en vert sur l’image).Chaque vocabulaire permet de décrire un
pan des métadonnées qui leur sont spécifiques. Les principaux vocabulaires standards réutilisés
seront approfondis et expliqués dans la partie de l’état de l’art.
Des problèmes se présentent donc:
• comment implémenter des algorithmes de recherche efficaces?
• comment représenter et manipuler des métadonnées au format Resource Description
Framework (RDF)4 ?
Les objectifs du stage consistent à répondre à ces questions.
4
https://www.w3.org/RDF/
Août, 2021 Page 9 of 43A. Champagne 3. Présentation du sujet
En effet, le premier objectif est d’étudier différents portails offrant des données météorologiques
ouvertes et les possibilités de recherche sur ces portails. Il s’agit d’un travail de recherche et de
documentation. Il permettra de répondre au premier problème que l’on se pose.
Le second objectif est d’implémenter des fonctions, interfaces et patrons de requêtes SPARQL
facilitant la recherche de jeux de données selon les scénarios identifiés. Ce travail comporte
une partie documentaire, une phase de spécification mais la majeure partie consiste à réaliser
le développementdu MRD présenté sur la figure 3.2. Ce module s’intègrera à la plateforme
Datanoos en se basant sur le Modèle de Sémantics4Fair.
Figure 3.2: Modules de Template et de Recherche de Données
Août, 2021 Page 10 of 43A. Champagne 4. Démarche méthodologique
4 Démarche méthodologique
Les objectifs du sujet ont été les principaux facteurs pour déterminer la démarche adoptée
tout au cours stage.
Dans un premier temps, le but était de scinder le stage en deux phases égales en terme de
charge de travail:
• Une première partie pour réaliser l’état de l’art, et étudier la documentation concernant
Semantics4Fair, en apprendre plus sur le modèle en lui-même ainsi que les différents
vocabulaires ontologiques. Ce travail a permis une compréhension approfondie du sujet.
Ainsi, j’ai mieux compris les attentes de mes tuteurs de stage. Un travail d’analyse a
également été effectué sur différents portails de données afin de déterminer les métadonnées
et les critères les plus utilisés pour la recherche. L’analyse a aussi porté sur la manière dont
les interfaces de recherche sont implémentées. De manière complémentaire, des articles
scientifiques ont permis d’identifier les méthodes de recherche les plus utilisées et les plus
efficaces pour la recherche de jeux de données.
Toute cette première partie est une base pour la seconde car ces analyses vont permettre
de faire des choix concernant l’interface et les méthodes de recherche à implémenter. Ces
choix vont déterminer les développements à effectuer.
• La deuxième partie est consacrée au second objectif, c’est-à-dire à réaliser l’implémentation
du MRD.Elle est elle-même composée de deux parties, une consacrée à la spécification et
à la documentation et une autre au développement.
La documentation est nécessaire, car les deux environnements de travail utilisés sur la
plate-forme Datanoos (Vue.js5 et Django6 ) me sont inconnus J’ai donc dû apprendre les
bases de ces environnements pour pouvoir travailler efficacement. Comme une partie de la
plate-forme existait déjà, les nouveaux développements doivent s’adapter aux informations
décrites dans la documentation sur GitHub7 . Après avoir pris en main les outils, le
développement devait commencer avec la création de l’interface graphique puis la création
de méthodes et d’algorithmes de recherche en s’appuyant sur l’interface.
Ceci était le plan de travail initial. Au cours du stage, intégrer la plate-forme DataNooS
au serveur utilisé pour les développements s’est avéré plus difficile que prévu. Il a donc été
décidé de commencer la seconde partie plus tôt pour ne pas être pris de cour dans le cas où
des problèmes surviendraient.Les deux parties se chevauchent donc comme on peut le voir sur
la figure 4.1. On peut noter que le rapport a été maintenu à jour tout au long du stage : dès
qu’une étude était terminée ou qu’une fonction était réalisée, sa description était immédiatement
intégrée au rapport.
Cela a eu plusieurs effets bénéfiques :
• lorsque l’on doit se remémorer des informations concernant sur une partie qui avait déjà
été étudiée il suffisait d’aller chercher les informations nécessaires dans le rapport.
• comme le rapport était souvent mis à jour, la rédaction finale a été plus rapide.
5
https://vuejs.org/
6
https://www.djangoproject.com/
7
https://github.com/
Août, 2021 Page 11 of 43A. Champagne 4. Démarche méthodologique
Figure 4.1: Diagramme de Gantt du stage
Enfin, concernant l’organisation, les conditions de travail ont été compliquées par les obliga-
tions liées au COVID-19. Il a donc fallu s’adapter en conséquence. Quand le travail en présentiel
était possible, il a été choisi de venir 2 jours par semaine sur le site de l’IRIT pour collaborer
avec Louis Mendy qui travaille sur le Module de construction de Template de Semantics4Fair.
Sur place, j’ai pu aussi poser des questions directement aux encadrantes de Semantics4Fair en
cas de difficultés rencontrées.
En plus de cela, il y avait une réunion en visioconférence par semaine avec les encadrantes afin de
leur montrer les avancées réalisées, poser des questions si nécessaire et définir les futurs objectifs
au fur et à mesure. Une autre réunion était organisée chaque semaine en visioconférence avec
les encadrantes, les membres du projet DataNooS et 4 autres stagiaires travaillant sur le projet
afin de faire part de nos avancées et définir comment intégrer les différentes parties dans un
ensemble cohérent.
Août, 2021 Page 12 of 43A. Champagne 5. État de l’art
5 État de l’art
Dans cette section, nous présentons une synthèse des travaux de l’état de l’art que nous
avons étudiés. Nous avons regroupé ces travaux selon les axes suivants : (i) les principes
FAIR, (ii) la recherche de jeux de données, (iii) la recherche sémantique, (iv) les vocabulaires de
représentation des métadonnées, (v) les portails de données. Le format des supports consultés
ne se limite pas aux articles scientifiques ; des documentations et des plateformes de données
ont également été consultées.
La lecture d’articles a été facilitée grâce au cours dispensé en M1 Données et Connaissances:
Travaux d’Initiation à la Recherche (TIR). En effet, ce cours m’a aidé à parcourir et à extraire
les informations les plus pertinentes de ces articles. Des outils comme Zotero8 ont également
permis un ajout simple et rapide des références au rapport.
L’état de l’art de ce stage n’a pas pour but de proposer une étude détaillée de la recherche
sémantique de jeux de données, mais plutôt de prendre connaissances des systèmes existant afin
de s’en inspirer, d’en faire la base des "Travaux réalisés" .
5.1 Principes FAIR
Le projet Semantics4FAIR a pour but de faciliter la réutilisation des données météorologiques
en améliorant leur degré de FAIRisation. Une bonne maîtrise de ces principes était donc nécessaire
pour mener à bien ce stage.
Les principes FAIR ont été proposés pour répondre de façon globale à la problématique
de partage des données en vue de leur réutilisation [8]. Ils consistent en un ensemble de
15 recommandations pour rendre les données faciles à (re)trouver (Findable), accessibles
(Accessible), intéropérables (Interoperable) et réutilisables (Reusable) (Fig. 5.1).
Findable (re-trouvable) Accessible (Accessible)
• F1. Les (méta)données sont associées à un identifiant unique et • A1. Les (méta)données sont accessibles par leur identifiant, via un
pérenne. protocole standardisé.
• F2. Les (méta)données sont décrites avec des métadonnées • A1.1 Le protocole utilisé est ouvert, libre et peut être
riches. implémenté de manière universelle.
• F3.Les métadonnées incluent clairement et explicitement • A1.2 Le protocole utilisé permet l’accès par autorisation
l'identifiant des données qu'elles décrivent et authentification si besoin.
• F4. Les (meta)données sont enregistrées ou indexées dans un • A2. Les métadonnées restent accessibles même si les
dispositif permettant de les rechercher. données ne le sont pas ou plus.
Interoperable (Interopérable) Reusable (Réutilisable)
• I1. Les (méta)données utilisent un langage formel, accessible, • R1. Les (méta)données ont des attributs multiples et pertinents.
partagé et largement applicable pour la représentation des • R1.1. Les (méta)données sont mises à disposition selon
connaissances. une licence explicite et accessible.
• I2. Les (méta)données utilisent des vocabulaires qui adhèrent aux • R1.2. Les (méta)données sont associées à leur
principes FAIR. provenance.
• I3. Les (méta)données ont des liens documentés vers d’autres • R1.3 Les (méta)données sont conformes aux standards
(méta)données. des communautés indiquées.
Figure 5.1: Les principes FAIR (selon [8]).
L’acronyme est un jeu de mot avec le mot anglais "FAIR" qui signifie "équitable" et qui
correspond au fait que tous les chercheurs peuvent avoir accès aux données déposées d’une
manière plus équitable en suivant ces principes.
Dans ce qui suit, nous présentons brièvement chacun des principes FAIR :
• Facile à trouver : Les métadonnées et les données doivent être faciles à trouver, tant
pour les humains que pour les ordinateurs. Les métadonnées lisibles par machine sont
8
https://www.zotero.org/
Août, 2021 Page 13 of 43A. Champagne 5.1 Principes FAIR
essentielles pour la découverte automatique de ensembles de données et de services. Par
ailleurs, il essentiel d’affecter un identifiant persistant et unique à chaque jeu de données.
• Accessible : Une fois les données trouvées, l’utilisateur a besoin de savoir comment accéder
à ces données, éventuellement avec des mécanismes d’authentification et d’autorisation.
Notez que des données FAIR ne sont pas forcément des données gratuites.
• Interoperable : leurs métadonnées des jeux de données doivent être représentées avec des
langages de représentation de connaissances qui soient formels, accessibles, et largement
adoptés par la communauté. La mise en œuvre courante de ce principe est l’utilisation
des technologies du web sémantique (RDF, Web Ontology Language (OWL)9 , Simple
Knowledge Organization System (SKOS)10 , etc.) pour représenter et lier les données et
les métadonnées. Cependant, les principes FAIR ne sont pas liés à ces technologies, et
d’autres approches peuvent être mises en œuvre. En effet, les principes FAIR sont des
lignes directrices et non une norme [5].
• Réutilisable : La réutilisation est le but ultime des principes FAIR. Il est implémenté
principalement via le renseignement de la license d’utilisation de chacun des jeux de
données, ainsi que des métadonnées riches décrivant la provenance des données, leur
contenu, peur format et leur structuration, etc.
Depuis leur introduction en 2016, les principes FAIR ont suscité beaucoup d’intérêt de la
part des scientifiques mais aussi des gouvernements qui veulent rendre leurs données publiques
et transparentes. Néanmoins, et même si tout le monde est d’accord sur le but de ces principes
(maximiser la réutilisation des données), ils sont souvent mal interprétés et confondus avec
d’autres principes. Pour éviter les mauvaises interprétations, dans [6], les auteurs ont précisé ce
que sont les principes FAIR et ce qu’ils ne le sont pas en définissant chacun des principes et
discutant ses possibles implémentations. Notamment, les auteurs ont expliqué que les principes
FAIR:
• Ne sont pas un standard.
• Ne sont pas dépendants ou équivalents aux technologies du Web sémantique, au web des
données, ni à l’utilisation du langage RDF pour représenter les (méta)données.
• N’ont pas pour objectif que les données soient retrouvées et réutilisée uniquement par
les humains, les machines aussi doivent être en mesure de retrouver les données et les
exploiter.
• Ne sont pas synonymes des données ouvertes/gratuites.
• Ne sont pas réservés aux données en sciences de la vie.
Notre compréhension des principes FAIR est conforme à ces affirmations et la vocation de
notre stage est bien de faciliter la réutilisation des données. Pour réaliser cela, le projet prévoit
de décrire les jeux de données avec le plus de métadonnées possible grâce au modèle onotlogique
de Semantics4Fair.
9
https://www.w3.org/OWL/
10
https://www.w3.org/2004/02/skos/
Août, 2021 Page 14 of 43A. Champagne 5.2 Recherche de jeux de données
5.2 Recherche de jeux de données
La recherche de jeux de données se réalise sur des portails de données. Il en existe énormé-
ment et leur diversité est tout aussi grande. Ils varient en terme de portée (mondial, continental,
national, régional) et également en terme de domaines de jeux de données ; certains sont
spécifiques à un domaine précis alors que d’autres englobent tous les jeux de données possibles.
Leur étude va fortement influencer l’implémention du MRD par la suite.
Plusieurs composants d’une recherche sont étudiés dans les travaux analysés :
• les différentes méthodes de recherche utilisées par les portails de données ;
• les métadonnées utilisées comme critères pour réaliser la recherche ;
• les problèmes liés à la recherche de données et comment les éviter.
Prenons dans un premier temps l’exemple de Google Dataset Search et les méthodes qu’il
emploie [7]. Il y a des millions de jeux de données éparpillés partout sur le web. Google Dataset
Search a pour but de regrouper les métadonnées de ces jeux de données et un lien pour accéder
à ces jeux de données sur leur plate-forme d’origine.
Il est assez compliqué de trouver des jeux de données sur le web pour différentes raisons :
• Il y a de plus en plus d’éditeurs de données différents et à différents niveaux. Ddonc quand
une personne recherche des jeux de données particuliers, il se peut qu’elle doive parcourir
des dizaines de sites avant de trouver ce qu’elle cherche.
• La plupart des jeux de données sont trouvés à partir de requêtes dans des portails de
données, mais il est très difficile de les trouver à partir de moteurs de recherches du web.
• Les scientifiques travaillent souvent dans un seul domaine et ont besoin de critères précis
lors de leur recherche. Plusieurs portails de données spécifiques à certains domaines
existent pour permettre à ces communautés de savoir ce qui existe. Mais de ce fait, pour
chercher des jeux de données de plusieurs domaines, il faut consulter plusieurs portails. Ou
si on cherche des données d’un domaine qu’on connaît mal, on ne connaît pas l’existence
des portails ni les bons mots clés pour y effectuer des recherches. De ce fait, la tâche
devient plus compliquée.
Les constats ci-dessus montrent que les portails de jeux de données ne satisfont pas les
principes FAIR. C’est donc un défi important à relever que de proposer un MRD qui fonctionne
en respectant les principes FAIR.
Réaliser un outil qui regroupe les métadonnées et les liens vers des jeux de données présentés
sur plusieurs portails de données soulève plusieurs verrous techniques :
• La qualité des métadonnées est importante car elle est au coeur de la recherche. Et de
nombreux jeux de données ne sont pas conformes aux standards qu’utilise Google Dataset
Search. Il est alors extrêmement difficile de les scruter.
• On trouve des doublons dans les métadonnées lors des recherches.
• On trouve de doublons des jeux de données en entier quand ils sont présents sur différents
portails de données.
Août, 2021 Page 15 of 43A. Champagne 5.2 Recherche de jeux de données
• Il se peut qu’un site qui contenait des jeux de données n’existe plus, ou que le jeu de
données se trouve sur une page qui existe mais n’est pas référencée par le portail de
données.
• Le classement pour ordonner les jeux de données répondant à une recherche se fait
majoritairement grâce aux métadonnées., alors que les classements actuels sur le web ne
les prennent pas en compte.
• Plusieurs standards de données sont utilisés (notamment Schema.org et Data Catalog
Vocabulary (DCAT)) ce qui ne permet pas un accès unique et oblige à reformuler la
recherche pour chaque standard utilisé.
Voici comment se déroule l’algorithme de recherche de Google Dataset Search:
1. L’utilisateur sélectionne les triplets RDF qui l’intéressent (Dataset de schema.org11 ,DataCatalog
de schema.org12 , et Dataset de DCAT13 ) dans les portails de données.
2. L’algorithme normalise et nettoie les métadonnées.
3. Il regroupe les métadonnées sous forme de graphe de connaissances
4. L’algorithme cherche les doublons pour les regrouper et remplir (si possible) des métadon-
nées qui n’étaient pas présentes.
5. Adaptation du backend
6. On indexe et utilise des algorithmes du web pour classer les résultats des recherches couplés
avec la qualité des métadonnées.
L’utilisation de vocabulaire comme DCAT par Google Dataset Search nous conforte sur le
fait que c’est une bonne solution d’utiliser GeoDCAT-AP (version plus restrictive de DCAT)
dans Semantics4Fair. Plus il y a de jeux de données définis par un même modèle plus c ses jeux
de données sont faciles à retrouver, et respectent mieux les critères FAIR.On voit également que
des algorithmes web classiques sont utilisés.
La recherche sémantique n’est pas utilisée pour la recherche de jeux de données. C’est donc
un point innovant dans le projet Semantics4Fair .
Ensuite on s’intéresse à l’étude des requêtes et des critères de recherche effectués sur les
portails de données, plus précisément sur 4 portails nationaux [4].
La plupart des personnes qui ont consulté un portail de données l’on fait à partir d’un moteur
de recherche externe. De plus, les requêtes sont très courtes. Ça peut s’expliquer par le fait que
l’utilisateur, ne voulant pas rendre la requête confuse, donne juste les informations minimales
pour trouver ce qu’il cherche. Les critères les plus fréquents lors des recherches sont les critères
spatiaux, temporels, type de données ainsi que la granularité (résolution temporelle et spatiale).
Ces informations vont être très utiles lors de la phase de spécification du MRD. En identifiant
les critères les plus utilisés, on détermine également les métadonnées importantes et utilisées en
priorité pour la recherche.
11
http://schema.org/Dataset
12
http://schema.org/DataCatalog
13
http://www.w3.org/ns/dcatDataset
Août, 2021 Page 16 of 43A. Champagne 5.2 Recherche de jeux de données
Les méthodes de recherche web ne sont pas très efficaces. Les méthodes de recherche ver-
ticales semblent mieux adaptées car elles prennent en compte les informations additionnelles
et métadonnées des ressources.En effet, les méthodes de recherche comme la recherche par
facette sont plus populaires au niveau des portails de données. Comme elles tirent parti des
métadonnées. C’est une plus-value concernant les principes FAIR.
Les données des portails sont majoritairement utilisées pour la recherche. Donc il est im-
portant de voir qui est le public cible, ce qu’il recherche et justement ce qu’il n’arrive pas
à trouver. En effet, la plupart des recherches effectuées sur les portails sont réalisées car la
ressource n’est pas trouvable ou les métadonnées liées à la ressource sont erronées ou insuffisantes.
Pur terminer, nous avons identifié des problèmes ouverts concernant la recherche sur les jeux
de données et des options possibles pour essayer de les résoudre [3].
Un utilisateur va faire une recherche contenant des mots-clés et possiblement définir un
sous-ensemble grâce à différents filtres. Ces mots-clés vont ensuite être utilisés pour rechercher
des similarités dans les métadonnées des jeux de données et produire un résultat. C’est pour
cette raison qu’il est important de bien ajouter les métadonnées lorsqu’on ajoute la ressource,
notamment grâce à DCAT. Or la création et la maintenance de métadonnées nécessite actuelle-
ment un grand volume de ressources.
Les architectures de recherche générique sont basées sur la Recherche de l’Information (RI)
et le Web sémantique. Pour ce type de recherche, on sélectionne des jeux de données à partir
d’une requête. Parmi les jeux de données résultats, on utilise d’autres méthodes pour déterminer
les plus pertinents.
Dans les portails de données ouverts, la plate-forme la plus populaire pour les portails
gouvernementaux est la Comprehensive Knowledge Archive Network (CKAN) qui indexe les
documents grâce à Lucene14 .
Les problèmes les plus fréquents sont les suivants :
• Manque d’informations sur le fait que certaines données existent et sont disponibles ;
• Manque de clarté concernant qui a l’autorité sur la ressource ;
• Manque de clarté sur les termes utilisés ;
• Données disponibles uniquement dans certains formats et par conséquent difficiles à
exploiter
14
https://lucene.apache.org/
Août, 2021 Page 17 of 43A. Champagne 5.3 Recherche sémantique
5.3 Recherche sémantique
La recherche sémantique est la plus-value qu’offre le projet Semantics4Fair par rapport
aux autres portails de données. Elle permet d’améliorer la recherche originale lancée par un
utilisateur grâce à des structures de données comme des ontologies ou bien des fichiers Extensible
Markup Language (XML).
Ici, on va se consacrer à la recherche sémantique à base d’ontologies et son utilisation possible
pour le futur [2].
Voici comment la recherche est implémentée. Dans un premier temps le modèle classique de
recherche d’information, le modèle vectoriel couplé avec tf/idf est utilisé. Ensuite, la navigation
sémantique et ses atouts notamment grâce à la relation d’héritage est utilisée.
Pour proposer une nouvelle méthode de recherche utilisant les propriétés sémantiques et
se basant sur le modèle de recherche classique, il faut dans un premier temps connaître trois
paramètres :
• le seuil de pertinence ( si le score est supérieur au seuil le résultat est valide)
• le nombre de documents pertinents souhaités
• la requête.
On commence ensuite par faire une recherche “simple”. Si le nombre de résultats est atteint,
l’algorithme s’arrête et retourne les résultats. Si ce n’est pas le cas, on étend la recherche grâce
à la navigation sémantique puis on réitère jusqu’à avoir assez de résultats ou qu’un délais expire.
Dans notre cas, il est peu probable que l’on couple la recherche sémantique à une recherche
de RI classique. En effet, on traite des jeux de données donc il est plus probable que le couplage
se fasse avec une recherche par facette.
Août, 2021 Page 18 of 43Vous pouvez aussi lire

















































