Abdelkrim Hadjidj Architect Big Data Responsable offre Big Data
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Abdelkrim Hadjidj
Architect Big Data
Responsable offre Big Data
Abdelkrim.hadjidj@fastconnect.fr
Your business technologists. Powering progress © Confidential
Sommaire
1 Introduction
2 Big Data Uses Cases
3 Les Technologies Big Data
Ingestion des données
Stockage des données
Traitement des données
Analyse & restitution des données
2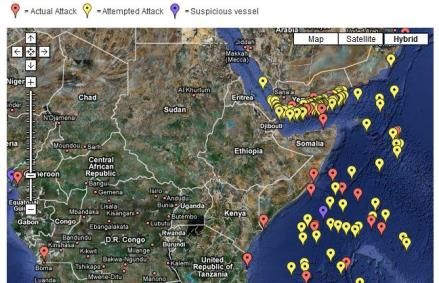
Big Data ?
▶ Être capable de gérer les nouvelles formes de données
– Provenant de différentes sources (réseaux sociaux, capteurs machines,
mobiles, centres d’appels, …)
– Ayant différentes structures ou souvent non structurés
▶ Être capable d'en extraire les connaissances cachées afin de les réutiliser pour
augmenter la performance des métiers
▶ Dérivations du BIG DATA
– SMART DATA
– FAST DATA
« Ceux qui contrôleront les données et sauront
les utiliser détiendront la valeur ajoutée »
Une référence au GAFA : Google, Apple, Facebook, Amazon
3
Les 5 V du Big Data
volume : calcul à véracité des
moindre coût sur des informations et
volumes de données traçabilité
toujours plus grands des sources
vélocité : une vitesse
variété : données
de traitement pouvant
internes / externes
aller jusqu’au temps
structurées ou non
réel
4
Des idées remises en question
Totalité des
données Données brutes
Exploration globale Temps réel
5
La donnée, une matière première abondante
et de différents types
Externes
IoT
Fournisseurs de Réseaux
données sociaux
B2B Web
Open Data
CMS
DataWarehouse Email, Chat,
ODS Stockage,
CRM Réseaux
ERP sociaux
d’Entreprise
non
Internes Structurées Structurées
6
Questions à se poser
• Approche Batch, Temps réel ?
• Structurées ou non ?
• Volume ? Historique ?
• Sécurité ?
• Simple (meta) ?
• Complexe
(annotations,
corrélations) ?
• Recherche • Quelle représentation de
(taxonomie, la réalité (descriptif) ?
sémantique) ? • Quels algorithmes à
exécuter pour le prédictif
?
• Délai de restitution de la
valeur métier ? s/mn/h ?
• Outil de DataViz multi
dimensions
• Rapports dynamiques ?
• Outil de recherche « full text »
et sémantique ?
•
7 | 12-02-2015 | © Highly Confidential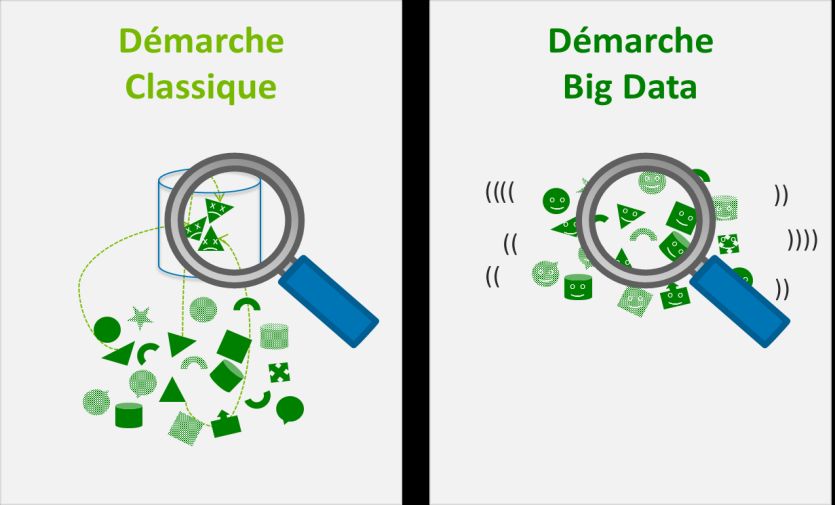
Sommaire
1 Introduction
2 Big Data Uses Cases
3 Les Technologies Big Data
Ingestion des données
Stockage des données
Traitement des données
8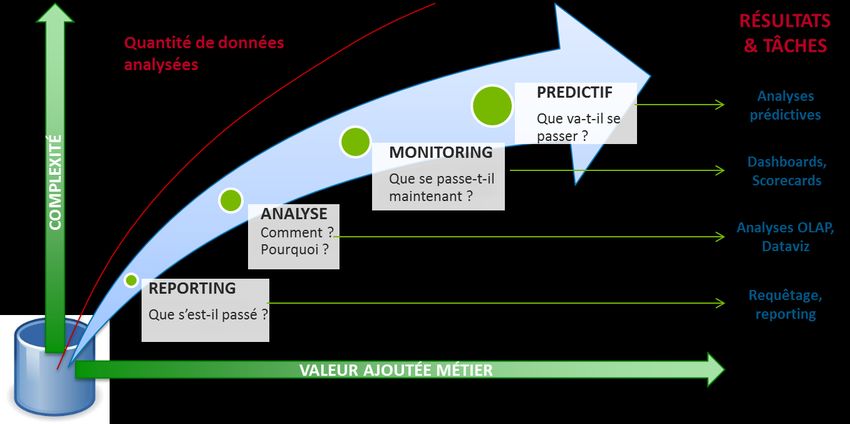
Big Data Uses Cases
Transformer les données en valeur métier
Advaced,
innovative
solutions
for SMART MACHINES DYNAMIC PRICING CUSTOMER 360° OFFRES PREDICTIVEs
ultimate
business
Insights
OPTIMISATION MAINTENANCE DETECTION DES SURVEILLANCE DU
FRAUDES RISQUE
9
Vision 360°
Utilisateur 1
Utilisateur 3 Utilisateur 1
Utilisateur 2 Utilisateur 3
Utilisateur 2
Data Lake
10Analyse prédictive d’incidents techniques
Source de Supervision
Plateforme
données &
Big Data
Capteurs Intervention
Flat files
11Détection de fraudes
▶ Objectif :
– Détecter les fraudes en temps de réel sur
un gros flux d’évènements
– Changer les patterns de fraude à chaud
– Identifier de nouveaux patterns sur un
large historique
– Déclencher des actions automatiques
suite à une fraude
▶ Solution In-Memory + Big Data:
– Architecture in-memory scalable avec un
CEP pour la détection en temps réel
– Hadoop et machine learning pour
identifier des patterns.
– Visualisation à l’aide de dashboard.
– Alimentation d’un outil de gestion de
fraude (BPM)
12Analyse de logs applicatifs
▶ Objectif :
– Centralisation d’un gros volume de logs
– Analyse du comportement des utilisateurs
– Analyse des performances de l’application Logs
– Aide au troubleshooting
– Détection des attaques et risques sur la sécurité
– Être plus proactif que réactif Hadoop
▶ Solution avec Hadoop ELK :
– Collecte des logs en temps réel avec Logstash
– Traitement et analyse avec Hadoop
– Indexation et recherche avec ElasticSearch
– Dashboard avec Kibana
– Scalabilité horizontale
13Sommaire
1 Introduction
2 Big Data Uses Cases
3 Les Technologies Big Data
Ingestion des données
Stockage des données
Traitement des données
Analyse & restitution des données
14Les étapes du projet
(2) Raffinement,
traitements
WWW
(1) Collecte d’une (3) Réalisation d’un
source de données rapport / Dashboard
Plateforme BigData
(0) Mise en place d’une
plateforme BigData
(4) Feedback
15 | 12-02-2015 | © Highly ConfidentialPlusieurs solutions pour différents besoins
Hadoop ecosystem
Data ingestion NoSQL
Batch analysis
Fast Data
Full Text Search Analytics
Real-Time
16C’est quoi Hadoop ?
▶ Solution Open Source Big Data fournissant un socle
– Distribué
– Scalable
– Pour du stockage et du traitement distribué
▶ Les origines d’Hadoop
– Basé sur les publications de Google concernant leur
système d’indexation
– Initié par Doug Cutting, auteur de Lucène
– Projet officiel Apache depuis 2009
▶ Distributeurs
– Fondation Apache
– Cloudera
– MapR
– HortonWorks
– …
17Architecture Hadoop
Streaming/ Traitements
Requêtage
Supervision et Management
Intégration au SI In-memory avancés
SQL
Framework de traitement distribué
Stockage distribué
18Architecture Hadoop
Pig
Spark Mahout
Hive
Sqoop Storm Giraph
Impala
Hue
Flume
SQL Zookeeper
Kafka MapReduce Oozie
YARN (v2)
Web- Ranger
HDSF
HBase …
CLI
HDFS
19Hadoop HDFS
Serveur Master /
Scheduler
Application
20Hadoop MapReduce
Serveur Master /
Scheduler
Application
21Requêtage
Meta-
(schéma à la demande)
data
SQL
HIVE / Pig / Impala / etc.
Extraction Extraction
Filtre etc. Filtre etc.
22Sqoop
▶ Sqoop est un outil d’import/export entre
– Bases de données relationelles et NoSQL et
Data warehouse
– HDFS, Hive, HBase
▶ Principes:
– Utilise JDBC pour se connecter aux bases de données
– Génère des jobs MapReduce
– Permet également d’importer des dumps MySQL et PostgreSQL
▶ Cas d’usage
– Alimenter le data warehouse Hive avec les données clients issues du CRM
– Exporter les résultats d’analyses dans une base Oracle
23Flume
▶ Flume est un outil permettant de collecter, agréger et déplacer de larges
volumes de logs dans HDFS
▶ Une architecture distribuée, basée sur des topologies d’agents et collecteurs
▶ Cas d’usage
– Collecter les logs des plateformes de production
– Collecter des données métiers au fil de l’eau
24Le NoSQL
▶ NoSQL = « Not only SQL »
▶ Des caractéristiques communes
– Stockage distribué, tolérant à la panne par réplication
– Relâchement de la contrainte de Cohérence
– Support d’un nombre de transactions/seconde très important (tps) en
conservant une latence faible (ms)
25Les types des bases NoSQL
26Search
Text
Data
(PDF, Email, Search
etc.) Web Portal
27Big Data in-memory
▶ Hadoop n’est pas adapté aux traitement avec plusieurs passes
– Chaque itération est un « Map-Reduce »
– Les données sont stockées sur disque à chaque itération
– Lenteur d’exécution
Distributed Memory
28Storm: traitement de streams Big Data
▶ Traitement au fil de l’eau de gros volume de données
issues de flux temps réél
▶ Storm est
– Scalable: plusieurs milliers de workers
– Tolérant aux pannes: ré-assignement des tâches suite à un échec
– Fiable: traitement de chaque message au moins une fois ou exactement une
fois
– Rapide: in-memory
▶ Concepts
– Spout
– Bolt
– Topology
29Analyse des données
▶ L’analyse des données fait appel à plusieurs disciplines
– Statistiques et mathématique
– Business Intelligence Chord diagram
– Data Science
– Visualisation
– …
Nuage de mots
30Différentes données, différentes solutions
31Merci
Pour plus d’information, merci de contacter:
Abdelkrim Hadjidj
+33 6 50 55 67 99
abdelkrim.hadjidj@fastconnect.fr
Atos, the Atos logo, Atos Consulting, Atos Worldline, Atos Sphere, Atos
Cloud and Atos WorldGrid are registered trademarks of Atos SA. 2015
© 2015 Atos. Confidential information owned by Atos, to be used by the
recipient only. This document, or any part of it, may not be reproduced,
copied, circulated and/or distributed nor quoted without prior written
approval from Atos.
32Vous pouvez aussi lire

















































