Cibler l'ADN : pour la compréhension du vivant
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Carine Giovannangeli Cibler l’ADN : pour la compréhension du vivant Cibler l’ADN : pour la compréhension du vivant Au sein de nos cellules se Si nous connaissons mainte- trouve l’ensemble de nos nant tout le génome humain gènes – le génome –, contenus depuis son séquençage en dans une grande molécule 2003 (Encart « Un peu d’histoire en forme de double hélice : sur l’ADN »), nous ne connais- l’ADN ou Acide DésoxyriboNu- sons néanmoins les fonctions cléique. L’ADN contient toutes que de 10 % de nos gènes… Il les informations permettant à reste à découvrir quelles infor- l’organisme de vivre et de se mations renferment les autres. développer ; il est le support Pour avancer dans la connais- de notre information géné- sance du génome, une méthode tique, mais également celui consiste à cibler et à agir sur de l’hérédité (Figure 1). Une ces gènes pour qu’ils ne s’ex- Figure 1 molécule a priori relativement priment plus normalement ; L’ADN, double hélice constitutive simple peut-elle commander c’est de cette manière que l’on de nos chromosomses, molécule à elle seule tout le fonctionne- peut parvenir à identifier leurs support de l’information génétique ment d’un organisme ? fonctions respectives. et de l’hérédité.
La chimie et la santé
UN PEU D’HISTOIRE SUR L’ADN
des gènes à l’ADN…
1865 : Johann Gregor Mendel établit les bases de l’hérédité en définissant
la manière dont les gènes se transmettent de génération en génération :
ce sont les lois de Mendel.
Johann Gregor Mendel (1822-1884),
le père fondateur de la génétique.
1869 : Johann Friedrich Miescher découvre dans le noyau des cellules vivantes une
substance riche en phosphate – la nucléine –, qui sera nommée au XXe siècle « ADN » ou
Acide DésoxyriboNucléique.
1882 : Walther Flemming met en évidence les chromosomes, constitués de molécules d’ADN,
qui regroupent plusieurs gènes. Il décrit pour la première fois la mitose, phénomène par
lequel les cellules se divisent et permettent la croissance et le renouvellement cellulaires.
Dessin de chromosomes
dans un noyau de cellule,
par J.F. Flemming.
1928 : Phoebus Levene puis Erwin Chargaff déterminent la structure chimique de l’ADN avec
sa composition en bases azotées : adénine A, thymine T, guanine G et cytosine C (Figure 2).
Figure 2
Formule chimique d’un fragment de brin d’ADN. L’ADN est une grande chaîne dont les maillons sont
des bases azotées (A, T, G ou C) qui s’enchaînent dans des ordres différents. L’ensemble {désoxyribose
+ groupement phosphate + base azotée} forme un nucléotide. L’ADN est donc un polymère de nucléotides.
42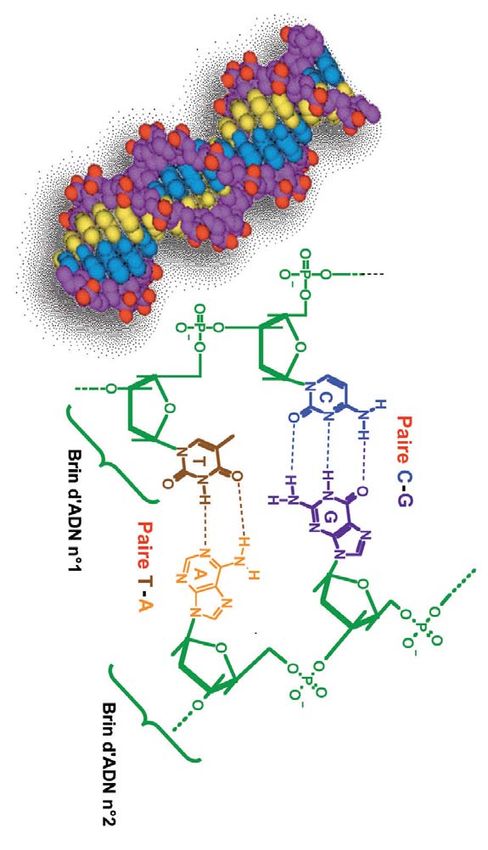
Cibler l’ADN : pour la compréhension du vivant
1944 : Oswald Avery établit que l’ADN est le transporteur de l’information génétique.
1952 : James Watson et Francis Crick établissent la structure en double hélice de l’ADN
(Figure 3), ce qui leur valut le prix Nobel de physiologie et de médecine en 1962.
Figure 3
L’ADN en double hélice, la figure
emblématique de la biologie
moléculaire.
La nouvelle ère :
en route pour l’épopée du séquençage du génome humain…
En 1995, les chercheurs ont pu « lire » pour la première fois tout l’ADN contenu dans le
génome d’un organisme unicellulaire. Depuis cette date, des pas de géant ont été franchis
en génétique, et les chercheurs ont ainsi séquencé des génomes de plus en plus longs,
aboutissant en avril 2003 au séquençage complet du génome humain.
C’est le résultat de nombreuses années de travail impliquant plusieurs pays à travers le monde,
associés dans ce « projet génome humain », parfois appelé « Apollo de la biologie » (Figure 4). Et
pour cause, ce fut un travail titanesque de plus de dix ans, à l’issue duquel les chercheurs ont
décrypté les quelque 3,5 milliards de bases de notre ADN. L’idée admise jusque-là était que le
génome humain contenait au moins 100 000 gènes… ! Puis l’équipe française du Génoscope,
dirigée par Jean Weissenbach* suggéra le nombre de 30 000 gènes, ce qui fut jugé un peu
iconoclaste. L’évaluation actuelle a encore réduit ce chiffre pour le ramener à environ 25 000…
Devant les 37 000 gènes du simple grain de riz, cela incite à la réflexion.
Figure 4
Le projet « Apollo de la biologie » : son ambition était
à l’image de celle de marcher sur la Lune. Centre
national du séquençage – Génoscope d’Evry.
43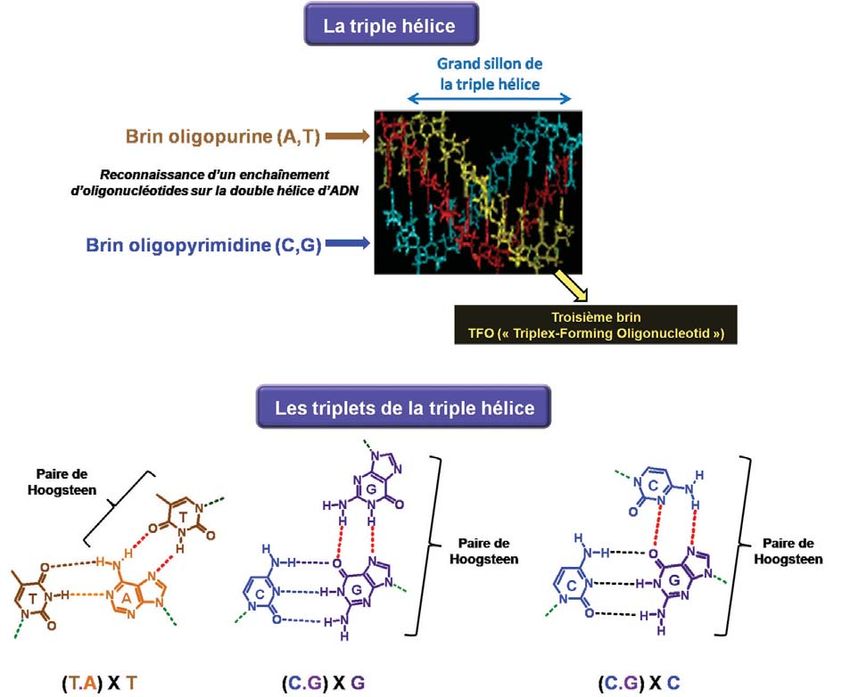
La chimie et la santé
Aujourd’hui, plus de 5 000 génomes ont été séquencés, ce qui aurait été impossible sans
les sauts technologiques énormes réalisés ces dernières années. Il faut citer l’invention
de la carte génétique de haute précision par Jean Weissenbach*, qui a été décisive pour le
diagnostic précoce de pathologies génétiques.
La recherche est maintenant armée pour séquencer les gènes plus rapidement et à un
moindre coût. Ce domaine de recherche, connu pour représenter un travail colossal et un
véritable « puzzle », évolue encore très vite et prévoit de plus en plus de gènes et de fonctions
à étudier, de plus en plus d’éléments à comprendre sur le fonctionnement du vivant.
* Jean Weisenbach, responsable du puissant génoscope au Centre national de séquençage d’Evry (centre
de séquençage français du « projet Apollo »), a reçu pour ses travaux pionnieers la prestigieuse médaille
d’or du CNRS en 2008.
Où en sommes-nous dans Faisons un zoom sur les pages
le développement de cette de notre hérédité, dont les mots
approche toute récente sont A, T, G et C…
qu’est le ciblage de l’ADN ?
L’ADN a une structure très
Comment peut-elle être appli-
simple et répétitive, qui
quée en thérapie génique et
repose sur un squelette phos-
de manière générale dans les
phodiester (groupements
manipulations génétiques ?
phosphates et désoxyriboses,
1
Figure 2). Sur ce squelette
Prise de connaissance
sont attachées des briques
avec la cible : l’ADN
élémentaires qui sont les
bases azotées, parmi les
1.1. L’ADN : découverte quatre possibles : adénine A,
de sa structure et de son thymine T, guanine G et cyto-
fonctionnement sine C (Figure 2). Squelette
Depuis le XIXe siècle, la nature phosphodiester et bases
et le rôle de cette grande molé- forment un brin. L’ADN est
cule en forme d’hélice se sont constitué de deux brins qui
révélés par étapes succes- s’enroulent l’un autour de
sives aux scientifiques puis au l’autre de manière très précise
grand public (Encart « Un peu en une double hélice. Ils sont
d’histoire sur l’ADN »). maintenus solidaires grâce
à la formation de paires de
C’est ainsi que dès le milieu
bases : l’adénine se lie avec
du XIXe siècle, nous avons déjà
la thymine – et seulement
compris les bases de notre
avec elle – en établissant des
fonctionnement.
liaisons de faible intensité
(liaisons hydrogène), et la
C’est le long de la chaîne cytosine se lie avec la guanine
d’ADN qu’est inscrit tout (Figure 5).
notre patrimoine géné-
C’est cette structure très
tique ; et c’est l’enchaîne-
simple dans son principe et
ment des bases azotées
à la fois très riche qui a été
A, T, G, et C – encore
à la base du « dogme de la
appelé séquence d’ADN –,
biologie moléculaire » : la
différent d’un individu à
molécule d’ADN est le support
l’autre, qui détermine nos
de l’information génétique et,
caractéristiques physio-
à travers plusieurs étapes,
logiques, et donc notre
elle conduit à la synthèse de
identité.
44 protéines, lesquelles sont
Cibler l’ADN : pour la compréhension du vivant
Figure 5
Les paires de bases qui permettent
aux deux brins d’ADN de s’associer.
associées à des fonctions de la division cellulaire (la L’adénine et la thymine se lient
bien précises dans la cellule. mitose), permettant ainsi entre elles par deux liaisons
Ces étapes sont les suivantes le transfert de l’information hydrogène, tandis que trois liaisons
hydrogène lient la cytosine et la
(Figure 6) : génétique de la cellule-mère
guanine.
1) la transcription : c’est la aux cellules-filles. C’est ainsi
production d’une copie de qu’est transmise l’informa-
l’ADN en ARN messager (ARN tion génétique d’une cellule
= Acide RiboNucléique), qui a à l’autre au cours du dévelop- Figure 6
une structure chimique très pement cellulaire et de son Le dogme de la biologie
proche ; renouvellement, et c’est ainsi moléculaire : une séquence d’ADN
que nous transmettons notre (un gène) est transcrite en un
2) la traduction : l’ARN est le ARN messager, lequel est traduit
messager de l’information en une protéine, qui exerce une
génétique, et son message fonction précise dans l’organisme
se traduit par la synthèse (structuration, transport,
d’une protéine. Les protéines catalyse, etc.) : c’est ce qui
ainsi produites par l’or- constitue l’information génétique.
On dit que l’ADN code pour cette
ganisme jouent des rôles
protéine ou encore qu’il s’exprime
physiologiques divers : rôle à travers la fonction protéique
structural (membranes des associée.
cellules, etc.), biosynthèse
de molécules indispensables
à la vie (glucides, lipides,
acides nucléiques), rôle de
messagers (hormones), etc.
Les protéines sont donc des
constituants majeurs et les
principaux bâtisseurs cellu-
laires.
Un corolaire découlant du
dogme de la biologie molécu-
laire est que l’ADN peut être
copié. Chaque brin d’ADN
pouvant servir de copie, une
molécule d’ADN peut donc
en donner deux au moment 45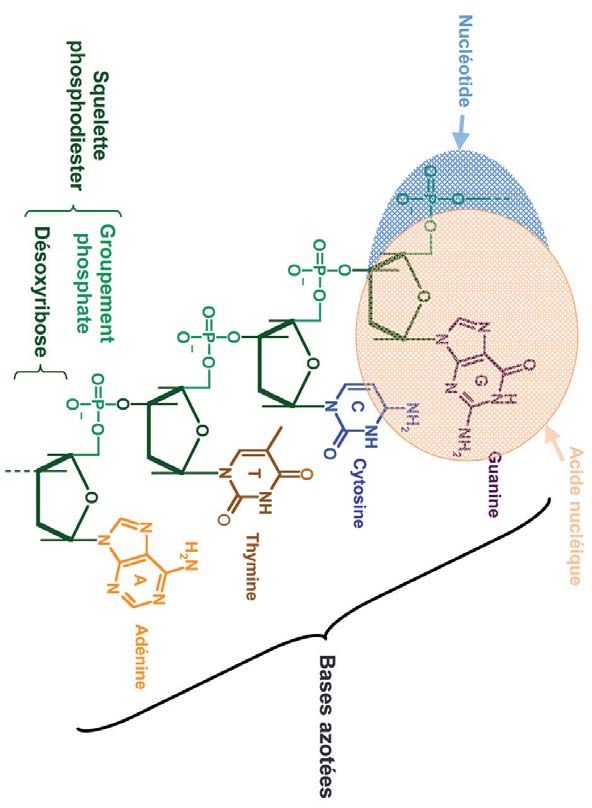
La chimie et la santé
information génétique à nos En fait, nous verrons que ces
descendants. 5 % ne résument pas à eux
seuls tout notre fonction-
1.2. Le génome est très nement, et que l’ADN n’est
complexe et les gènes ne pas un élément autonome. Il
sont pas seuls dans la partie existe en effet des protéines
dans l’organisme qui intera-
Comment une molécule rela-
gissent avec lui et jouent le
tivement simple comme l’ADN
rôle de facteurs régulateurs,
pourrait-elle contenir toute
c’est-à-dire qu’ils activent ou
l’information génétique qui
inhibent la fonction associée.
nous est nécessaire ? En fait,
Il a été prouvé récemment
le dogme de la biologie molé-
qu’au cours des divisions
culaire a été récemment revi-
cellulaires, certaines infor-
sité, et l’on sait maintenant que
mations sont transférées
pour les quelque 25 000 gènes
non pas directement par le
que nous avons, il existe
séquençage de l’ADN, comme
dix fois plus d’ARN, et trois
résumé par le dogme de la
mille fois plus de protéines
biologie moléculaire, mais par
(soit 10 000 000 protéines) ! On
des modifications de facteurs
voit donc qu’un gène peut être
régulateurs appelées modi-
associé à une multitude de
fications épigénétiques (déjà
fonctions différentes, ce qui
évoqués dans le chapitre de
rend très complexe l’étude du
J.-F. Bach). En particulier, les
génome.
nucléosomes sont des struc-
Quant aux ARN, on sait main- tures jouant un rôle important
tenant que 5 % d’entre eux ne dans ces régulations épigé-
donnent pas de protéines : nétiques (Encart « L’ADN, une
ce sont des ARN non codants pelote d’information génétique
appelés ARN régulateurs, dans nos cellules »).
à l’instar de nombreuses
protéines connues pour jouer
un rôle de régulation dans 1.3. Identifier les fonctions
l’organisme. Ils représentent des gènes
une quantité importante par Les scientifiques se sont
rapport à l’ensemble de l’in- donné l’objectif d’identi-
formation génétique. fier les fonctions de tous
Pour compliquer le tout, il se nos gènes, pour aboutir à
trouve que le génome n’est pas connaître toute l’information
constitué que de gènes. Les génétique renfermée dans
régions codantes n’en repré- notre génome. Pour cela, l’ap-
sentent que 5 % ! On a montré proche du ciblage de l’ADN a
qu’il existe des régions sans été envisagée pour modifier
gène, mais qui ont des fonc- son expression.
tions biologiques très particu- Par ailleurs, en ciblant l’ADN,
lières. Mais quelles sont donc on peut interférer avec les
ces fonctions ? facteurs régulateurs asso-
ciés, et donc identifier leur
Seuls 5 % de notre rôle dans la régulation de son
génome correspondent expression.
à des séquences
Quelles molécules peut-
codantes.
46 on donc utiliser pour cibler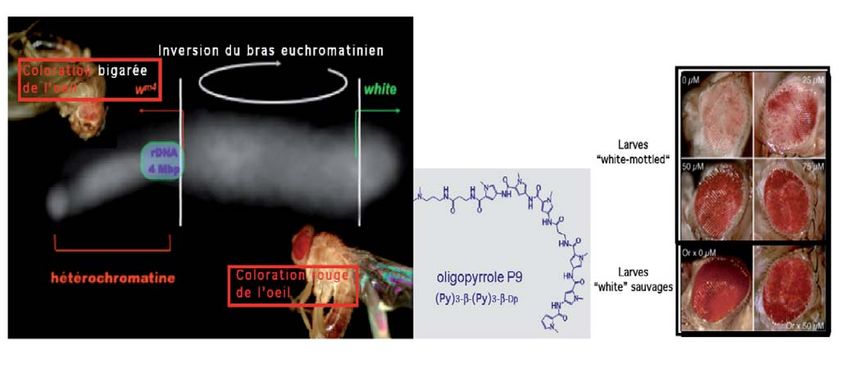
Cibler l’ADN : pour la compréhension du vivant
L’ADN, UNE PELOTE D’INFORMATION GÉNÉTIQUE DANS NOS CELLULES
Le génome humain comporte plus de trois milliards de paires de base et, selon J. Watson
et F. Crick, la distance entre deux paires de bases est de 3,4 Å, ce qui donne deux mètres
linéaires d’ADN dans nos cellules, mis bout à bout ! Un noyau cellulaire ayant un diamètre de
quelques microns, il faut donc compacter l’ADN pour le contenir dans ce noyau. La solution
trouvée par la nature est d’enrouler l’ADN autour de protéines appelées histones, pour former
des sortes de pelotes appelées nucléosomes (Figure 7). Ces pelotes de nucléosomes ne sont
pas anodines, car elles ont leur rôle à jouer dans les régulations épigénétiques !
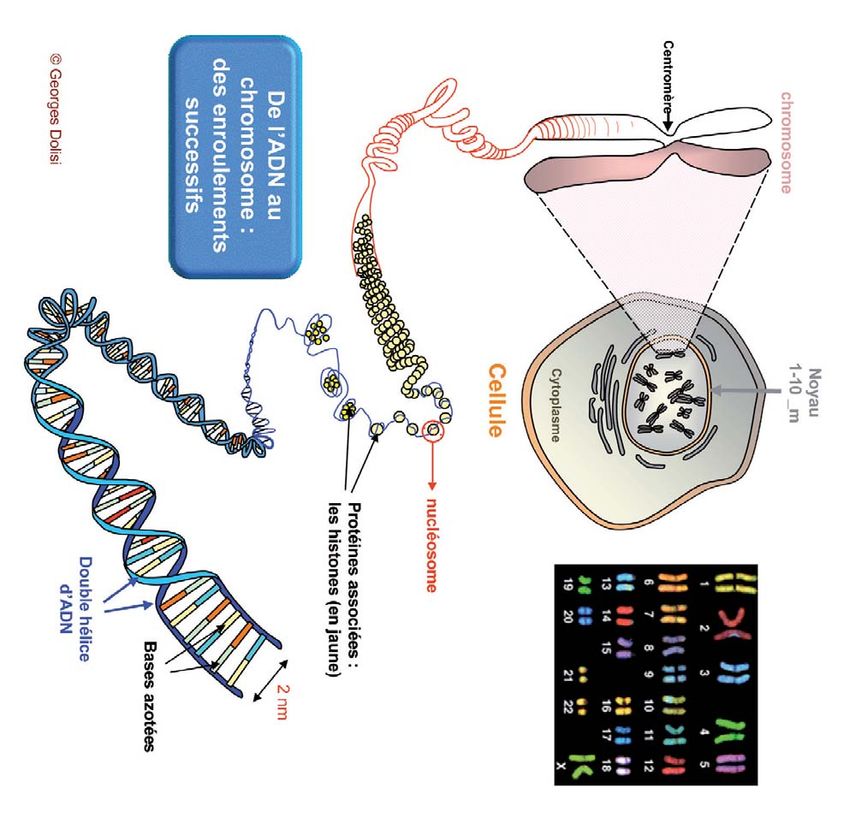
Figure 7
Les différentes échelles du transfert de l’information génétique : dans chacune de nos cellules se trouve
un noyau (1 à 10 microns) ; dans chaque noyau se trouve notre génome, c’est-à-dire l’ensemble de nos
chromosomes (22 paires de chromosomes et nos chromosomes sexuels) ; chaque chromosome possède
deux molécules d’ADN reliées au niveau du centromère. Chaque molécule d’ADN, dont les différents
fragments constituent des gènes, est enroulée en nucléosomes (autour de protéines appelées histones).
47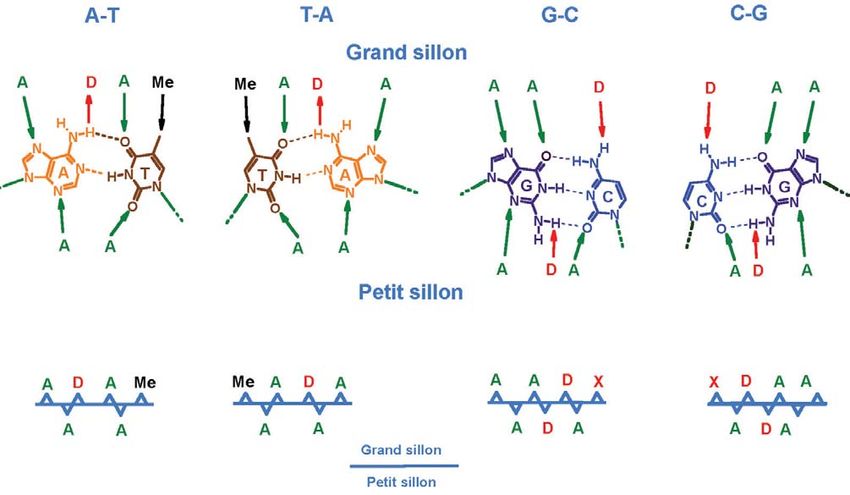
La chimie et la santé
LES ARN INTERFÉRENTS : UNE GRANDE INNOVATION
DANS LA BIOLOGIE MOLÉCULAIRE
L’approche antisens consiste en un ciblage de l’ARN
messager, ce qui revient en fait à moduler l’expression du biologistes appelée « anti-
gène qui l’engendre. Au début des années 2000, Tom Tuschl sens », qui cible l’ARN (Encart
a montré qu’une famille de molécules appelées ARN « Les ARN interférents :
interférents est capable de reconnaître des fragments une grande innovation dans
précis d’ARN et de s’y fixer en formant des mini-duplex. la biologie moléculaire »),
Cela a pour effet de bloquer l’étape de traduction et donc le ciblage de l’ADN est une
d’empêcher la production des protéines correspondantes. approche dite permanente car
la modification des séquences
Les oligonucléotides antisens et les ARN interférents sont de de bases qu’il vise a un impact
petits enchaînements de moins de vingt-cinq nucléotides, ce direct et permanent sur la
sont donc de petits bouts d’ADN ou d’ARN, respectivement. fonction associée.
Les chimistes savent en synthétiser rapidement et en
grande quantité (avec des robots synthétiseurs). Ce n’est Afin de cibler l’ADN, les
pas par hasard si cette découverte a été faite en 2001, au chimistes savent aujourd’hui
même moment que le séquençage du génome. En effet, synthétiser deux types de
c’est un outil largement utilisé pour inactiver des gènes et molécules capables de recon-
comprendre à quoi ils servent. Par ailleurs, ces molécules naître spécifiquement des
ont également un avenir prometteur en tant qu’agents fragments d’ADN, ce qui
thérapeutiques (anti-infectieux, anti-inflammatoires). permet ensuite d’en modifier
la séquence de bases avec
précision (Figure 8) :
l’ADN ? L’intervention et l’ima- – méthode 1 : on utilise des
gination des chimistes se oligonucléotides pouvant
révèlent indispensables dans reconnaître des séquences de
cette recherche. paires de bases et se fixant
dans le grand sillon pour
2 Cibler l’ADN : former des triplex (triples
comment ? Avec hélices) ;
quelles molécule ? – méthode 2 : on utilise des
molécules de la famille des
L’approche du ciblage de l’ADN pyrroles et imidazoles, qui se
consiste à concevoir des molé- fixent dans le petit sillon de
cules capables de reconnaître l’ADN.
certaines séquences bien
précises d’ADN et d’en modi-
2.1. Méthode 1 : des
fier la séquence en bases
oligonucléotides
azotées. En résumé, on touche
fonctionnalisés. Vers une
Figure 8 à un seul gène sans toucher
application dans la thérapie
L’ADN peut être ciblé par des aux autres. Une fois touché,
génique et la transgenèse
molécules de synthèse à deux ce gène ne pourra plus donner
niveaux possibles : au niveau la (ou les) protéine(s) dont il Étape 1 : reconnaître des
du grand sillon ou au niveau ` permet la synthèse habituel- fragments précis d’ADN
du petit sillon. lement. En étudiant les consé- Les deux brins d’ADN s’as-
quences de l’élimination de socient entre eux grâce à la
cette protéine, il sera ensuite formation de paires de bases
Petit possible de déterminer son selon quatre possibilités : T-A,
sillon rôle, et en particulier de voir A-T, C-G et G-C. Il est possible
Grand si elle est impliquée dans une de les distinguer en utilisant
sillon pathologie (maladie géné- des molécules qui vont inte-
tique ou développement d’une ragir de manière différente
tumeur). avec l’une ou l’autre, selon les
Contrairement à une autre liaisons qu’elles vont pouvoir
48 approche bien connue des établir avec certains sites
Cibler l’ADN : pour la compréhension du vivant
situés sur ces paires de bases de polymères une structure
(en particulier des liaisons à trois brins d’ADN, qu’il
hydrogène). Ces sites sont : interpréta comme une triple
« donneurs (D) », « accep- hélice ! Pendant trente ans,
teurs (A) » ou des méthyles, et cette découverte demeura
leur enchaînement est diffé- une curiosité de laboratoire.
rent selon la paire de bases, Il fallut attendre 1987 pour
mais aussi selon que l’on se que Peter Dervan et Claude
trouve au niveau du grand Hélène montrent simulta-
sillon ou du petit sillon. C’est nément qu’il est possible de
de cette manière que l’on peut former ce type de structure
différencier les quatre paires à trois brins avec de courts
de bases possibles (Figure 9). oligonucléotides (Encart « Le
En théorie, il est donc possible miracle de la triple hélice »).
d’arriver à reconnaître n’im- Cette démonstration a été le
porte quel enchaînement départ de ce qu’on a appelé
de paires de bases sur le la stratégie « anti-gène »
génome, et l’enjeu pour les pour « anti-ADN ». Et en tant
chimistes est alors de trouver que grands pionniers dans
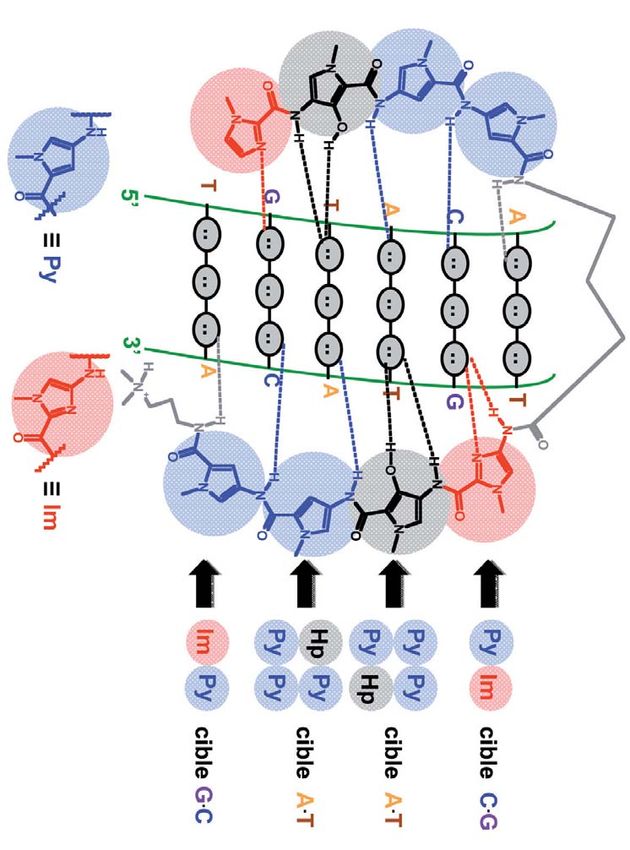
Figure 9
la molécule qui y parviendrait ! ce domaine, Peter Dervan et
Une famille de molécules peut Claude Hélène ont obtenu, Pour chaque paire de bases
en 1996, le grand prix de la possible, et selon que l’on se place
accomplir cet exploit : les
Fondation de la Maison de la au niveau du grand ou du petit
oligonucléotides. sillon de la double hélice d’ADN,
Chimie.
Revenons sur l’historique de on trouve des sites d’interaction
cette découverte : en 1957, Un travail considérable a été différents (accepteur A, donneur D
peu de temps après la décou- réalisé par les chimistes dans ou méthyle Me), avec des ordres
d’enchaînements bien définis.
verte de la structure en double la recherche d’oligonucléo- Cela permet de distinguer chacune
hélice de l’ADN, le chercheur tides qui soient capables de des quatre bases possibles et
Gary Felsenfeld découvrit reconnaître sélectivement au final donne accès à toutes les
sur une figure de diffraction des séquences en double séquences d’ADN possibles.
49
La chimie et la santé
LE MIRACLE DE LA TRIPLE HÉLICE
Comment une triple hélice peut-elle se former ? Dans le grand sillon de l’ADN, il est en
fait possible de fixer un troisième brin qui va interagir avec l’un des deux brins de la double
hélice. Il va reconnaître une purine (adénine ou guanine) de la double hélice, laquelle est
déjà engagée dans une paire, et va former deux liaisons hydrogène avec cette purine. De la
même manière, l’adénine d’une paire adénine/thymine est reconnue par une thymine, et la
guanine de la paire guanine/cytosine peut être reconnue soit par une cytosine soit par une
guanine. On forme donc des triplets de bases et le troisième brin va ainsi s’enrouler autour
de la double hélice (Figure 10).
Figure 10
Formation de la triple hélice : le troisième brin (oligopurine ou
oligopyrimidine) va reconnaître l’un des deux brins de l’ADN et
s’enrouler avec la double hélice.
50Cibler l’ADN : pour la compréhension du vivant
hélice de l’ADN, en formant souhaitées sur sa séquence Figure 11
une triple hélice stable. Et en bases ? Il suffit d’attacher
pour cause, il a fallu apporter à un court oligonucléotide une Les oligonucléotides avec des
acides nucléiques dits « locked »
plusieurs modifications molécule capable de couper
sont parmi les plus efficaces en
chimiques aux nucléotides l’ADN. Lorsque le brin court va cellules : le désoxyribose y est
pour que le ciblage d’ADN soit se fixer sélectivement sur une bloqué par un pont méthylène
efficace. En effet, un oligonu- région précise de l’ADN pour entre l’oxygène en 2’
cléotide standard mis dans former un triplex, la coupure et le carbone en 4’.
une cellule sera immédiate- de l’ADN s’effectuera à un
ment dégradé, car l’environ- endroit précis (Figure 12).
nement cellulaire regorge de On peut aller plus loin avec
nucléases, enzymes chargées la même méthode : on peut
de dégrader les oligonucléo- couper, mais on peut aussi
tides. D’autre part, les oligo- couper puis insérer un frag-
nucléotides standards ont ment contenant une séquence
généralement des affinités correcte qui peut alors
moyennes avec l’ADN que l’on corriger la séquence, comme
veut cibler. une sorte de pansement.
Ce n’est qu’après de
nombreuses études de modi- On dispose donc de
fications chimiques (squelette, deux stratégies de
désoxyribose, bases) que les modification de l’ADN :
oligonucléotides adéquats ont « couper » ou « couper, Figure 12
pu être mis au point pour cette coller ». Un oligonucléotide (en rouge)
application en milieu cellu- conjugué à un agent de coupure
laire (Figure 11). reconnaît une séquence précise
2.1.1. Modifier un gène selon la d’ADN et l’agent de coupure
méthode « couper » (en vert) coupe la chaîne en un
Étape 2 : modifier la séquence Des expériences ont été endroit précis. L’agent de coupure
d’ADN peut être l’orthophénanthroline
menées sur différents types
(OP), qui, en présence de métal
Une fois que l’on s’est posi- de conjugués (oligonucléo- et de réducteur, est capable de
tionné sur un fragment bien tide TFO + agent de coupure générer des espèces radicalaires
précis de l’ADN, comment y OP) ayant un nombre de sites et ainsi de casser le squelette
apporter les modifications de coupure différents. Les phosphodiester [1].
51La chimie et la santé
résultats montrent qu’avec un fragment de gène normal,
ces conjugués, il est possible le « pansement ».
de cibler des coupures en des
Pour procéder à cette opéra-
sites choisis du génome.
tion de « couper-coller »,
Une fois la coupure effectuée, les scientifiques utilisent
une cellule contenant des une machinerie cellulaire :
brins d’ADN coupés a natu- la « recombinaison homo-
rellement envie de réparer logue ». C’est une méthode
cette coupure. Mais de cette développée depuis longtemps
autoréparation il restera des et encore actuellement.
« séquelles » : des muta-
tions vont se produire dans la Si l’on utilise un fragment
région de la coupure, c’est- d’ADN extérieur, homo-
à-dire des changements logue à la séquence d’ADN
de paires de bases, et la que l’on veut réparer, mais
séquence de l’ADN s’en trou- sans les mutations indésira-
vera modifiée ; par consé- bles, il peut s’intégrer dans
quent, son évolution jusqu’à le génome. Le problème
la production d’une protéine rencontré est le manque d’ef-
sera également modifiée. ficacité de la méthode pour
Cette approche permet ainsi les cellules de mammifères
d’éteindre un gène et a été (mais elle s’avère très effi-
récemment utilisée in vivo cace dans des cellules de
avec succès pour obtenir des levures). Néanmoins, on a
organismes génétiquement trouvé depuis 1994 le moyen
modifiés, KO pour un gène d’augmenter l’efficacité de
d’intérêt [3]. l’intégration de l’ADN, et donc
Figure 13 l’efficacité de correction : il
L’approche « couper-coller », s’agit d’effectuer la coupure
ou réparation par recombinaison 2.1.2. Modifier un gène selon la à proximité du site que l’on
homologue. Sur un gène muté méthode « couper-coller » souhaite modifier, d’où l’im-
que l’on veut réparer, on effectue Prenons par exemple un gène portance de bien cibler les
une coupure au niveau du site
qui a subi une mutation et qui coupures (Figure 13) [2].
de mutation, on ajoute un ADN
correcteur (le fragment dit
est responsable d’une patho-
logie. On souhaite réparer Par rapport à la méthode
« homologue »), qui vient se coller
ce gène en coupant la partie précédente, où l’étape de recol-
à l’endroit que l’on veut réparer.
On récupère alors un gène réparé. mutée et en la remplaçant par lement n’était pas contrôlée,
on recolle dans ce cas exacte-
ment comme on le désire en
intégrant la séquence voulue
dans le milieu cellulaire.
Mais on peut aller encore plus
loin dans cette approche, en
intégrant un gène entier ; et
l’on s’est rendu compte qu’il
est possible de faire exprimer
dans une cellule des trans-
gènes, rien qu’en les intégrant
avec des fragments homolo-
gues… De là à envisager de
faire des organismes généti-
52 quement modifiés ?Cibler l’ADN : pour la compréhension du vivant Applications du « couper- des coupures avec une chimie coller » : des organismes donnée, bien contrôlée, ce génétiquement modifiés à la que ne font pas les nucléases thérapie génique de nature protéique (qui font Effectivement, cette méthode des réactions enzymatiques). de recombinaison homo- Cela permettrait de mimer logue a été utilisée dans des coupures qui se produi- le cas de cellules souches sent naturellement et d’en embryonnaires de souris. étudier les mécanismes de Le prix Nobel de médecine réparation. 2007 a été décerné à Mario À plus long terme, quand on Capecchi, Oliver Smithies et saura parfaitement corriger Martin Evans qui ont réalisé un gène, on pourra penser à l’exploit de générer des utiliser cette méthode pour souris transgéniques grâce la thérapie génique. En effet, à des recombinaisons homo- avec une maladie monogé- logues réalisées dans des nique (voir le chapitre de J.- cellules souches embryon- F. Bach, paragraphe 1) et un naires (Figure 14). La popu- gène à corriger, on peut non lation de cellules modifiées pas introduire un gène mais est enrichie, pour générer au simplement utiliser cette final l’animal génétiquement approche de modification de modifié, le mutant. séquence. Le problème est que, pour Beaucoup de questions ne l’instant, on sait faire des sont pas encore résolues. En cellules souches pour la souris effet, les résultats décrits sont mais pas encore pour beau- obtenus avec une première coup d’autres organismes, génération de nucléases, mais tels que la drosophile ou le la spécificité à l’échelle du poisson zèbre, qui sont pour- génome est encore à préciser tant des modèles importants car, pour des applications de Figure 14 en biologie. On n’est donc pas thérapie génique, il ne faut pas Les souris génétiquement encore capable de faire facile- se tromper dans la correction modifiées constituent un outil ment des mutants ciblés. du gène. Il faut aussi réussir précieux pour la recherche Mais il a été montré récem- à reconnaître de manière fine thérapeutique. ment qu’avec des ciseaux non synthétiques, des « nuclé- ases à doigts de zinc » [3], il est possible de cibler des coupures en utilisant ce type d’approche. En plein déve- loppement, cette méthode permet d’espérer faire de la transgenèse dans d’autres organismes. Par ailleurs, les chercheurs suspectent que la répara- tion de l’ADN change selon l’endroit où l’on se situe sur le génome. Ici, la chimie a un rôle important à jouer. En effet, il est possible de cibler 53
La chimie et la santé
n’importe quelle séquence À la découverte de régions
sur le génome. Il faut enfin non codantes du génome et de
savoir contrôler la chimie la régulation de l’expression
des coupures. Les chimistes des gènes
ont donc encore beaucoup de Pour étudier les régions non
travail en perspective ! codantes, les chercheurs ont
utilisé un type de molécules
composées de plusieurs
modules : pyrroles (Py) et
2.2. Méthode 2 : cibler des
imidazoles (Im). Elles se
gènes pour comprendre le
fixent dans le petit sillon de
fonctionnement des régions
l’ADN et des paires Im-Im et
non codantes du génome
Im-Py vont reconnaître les
Nous avons vu que seulement paires de bases de cet ADN.
5 % du génome correspon- Le code de reconnaissance a
dent à des régions codantes, été identifié par le chercheur
c’est-à-dire qui codent pour Peter Dervan : une paire Py-
la synthèse de protéines Im reconnaît un couple C-G,
nécessaires au fonction- une paire Py-Py reconnaît un
nement cellulaire. Qu’en couple A-T et une paire Im-
est-il du reste ? C’est l’objet Py reconnaît un couple G-C.
Figure 15 de toute une recherche qui On peut donc théoriquement
Reconnaissance des quatre paires utilise justement le ciblage reconnaître les quatre paires
de bases. de l’ADN. de bases (Figure 15).
54Cibler l’ADN : pour la compréhension du vivant
Ulrich Laemmli à Genève a une couleur rouge à l’œil de
étudié le rôle de certaines la drosophile. Mais chez des
séquences non codantes mutants naturels, l’œil est
appelées « séquences satel- blanc. Or on voit que pour ces
lites » chez la drosophile [4] ; derniers, ce gène « white » est
et Emmanuel Kas à Toulouse situé dans la région d’hétéro-
a essayé d’expliquer [5] les chromatine, près du satelli-
résultats observés, qui sont te III. Les régions satellites de
les suivants : près du centro- ces mutants perturberaient-
mère du chromosome X de elles ce gène censé donner
la drosophile, on trouve les l’œil rouge ?
régions satellites (appelées Après avoir traité des larves
hétérochromatine ou régions de drosophiles mutantes (œil
silencieuses), dont le « satel- blanc) avec un oligopyrrole
lite III » est une région très (P9), on a observé que leur
riche en paires A-T. Il pourra œil devenait rouge. Cette
donc être repéré par les paires molécule capable de se fixer
de molécules Py-Py. À côté de sur le satellite III a donc
ces séquences satellites, on une influence sur le gène
est surpris de découvrir des « white », qui se trouve juste
gènes codant pour des ARN à côté. Ce gène n’était donc
ribosomaux, que l’on sait être pas exprimé chez le mutant,
nécessaires à la prolifération mais le devient dès que le P9
cellulaire, et très exprimés s’est fixé sur le satellite III
(Figure 16). (Figure 17).
La question que se sont La réponse est donc trouvée :
posée les chercheurs était la les régions satellites régulent
suivante : quel est le rôle des l’expression des gènes avoisi-
régions satellites ? nants, lesquels contribuent à
Pour y répondre, l’expérience donner la couleur rouge aux
suivante a été réalisée : yeux. Figure 16
chez la drosophile sauvage, Cet exemple parmi d’autres Les séquences satellites dans le
il existe un gène (le gène montre bien que l’on dispose modèle drosophile. Emmanuel
« white ») qui est un transpor- de molécules chimiques capa- Kas (Toulouse) et Ulrich Laemmli
teur de pigment et qui donne bles de repérer les séquences (Genève).
55La chimie et la santé
Figure 17 non codantes de l’ADN pour
pouvoir les étudier, et avancer On découvre ici une
L’oligopyrrole (P9) a été injecté dans l’élucidation de leur rôle illustration du rôle
chez la lignée mutante « white- essentiel joué par des
à l’échelle du génome.
mottled » de la drosophile. régions non codantes
Étant capable de reconnaître
du génome, ou régions
des séquences A-T, il se fixe
sélectivement sur le satellite III de satellites : réguler
l’hétérochromatine, ce qui a pour l’expression des gènes.
effet de lever l’inhibition du gène
« white », et ce qui redonne à l’œil
sa couleur rouge.
Vers des ciblages plus spécifiques
pour la médecine du futur ?
La chimie peut donc concevoir et synthétiser
des molécules capables de reconnaître une
séquence choisie d’ADN. Néanmoins, il reste
encore du travail pour parvenir à reconnaître
n’importe quelle séquence d’ADN et réussir à
caractériser de manière très précise le niveau
de spécificité de ces molécules. En effet, seule
une attaque totalement spécifique du gène
ciblé fera la puissance de la méthode et de ses
applications, surtout si celles-ci sont d’ordre
thérapeutique.
Les nombreux exemples développés dans ce
chapitre ont néanmoins permis de montrer la
richesse potentielle des applications, notamment
en biologie mais aussi pour des applications
thérapeutiques qui seront à développer dans le
56 futur.Cibler l’ADN : pour la compréhension du vivant
Bibliographie disruption in zebrafish using
designed zinc-finger nucleases.
[1] Simon P., Cannata F., Nat. Biotechnol., 26: 702-708.
Perrouault L. , Halby L.,
Concordet J.-P., Boutorine A., [4] Janssen S., Cuvier O., Müller
Ryabinin V., Sinyakov A., M., Laemmli U.K. (2000). Specific
Giovannangeli C. (2008). gain- and loss-of-function
Sequence-specific targeted DNA phenotypes induced by satellite-
cleavage mediated by bipyridine specific DNA-binding drugs fed
polyamide conjugates . Nucleic to Drosophila melanogaster.
Acids Res., 36: 3531-3538. Mol. Cell., 6: 1013-1024.
[2] Pingoud A., Silva G.H. (2007). [5] Blattes R., Monod C.,
Precision genome surgery. Nat Susbielle G., Cuvier O., Wu J.H.,
Biotechnol., 25: 743-744. Hsieh T.S., Laemmli U.K., Käs
[3] Doyon Y., McCammon J.M., E. (2006). Displacement of D1,
Miller J.C., Faraji F., Ngo C., HP1 and topoisomerase II from
Katibah G.E., Amora R., Hocking satellite heterochromatin by a
T.D., Zhang L., Rebar E.J. et al. specific polyamide. EMBO J., 25:
(2008). Heritable targeted gene 2397-2408.
57La chimie et la santé
Crédits
photographiques
– Fig. 3 et 5 (gauche) : CNRS – Fig. 7 : Georges Dolisi.
Photothèque/Université de – Fig. 14 : CNRS Photothèque/
Montpellier 2, UPR 9080 Raguet Hubert, UMR 8612
– Laboratoire de Biochimie – Physico-Chimie, Pharma-
Théorique – Paris. cotechnie, Biopharmacie
– Fig. 4 : CNRS Photothèque/ – Châtenay-Malabry.
Lamoureux Richard, GIP- – Fig. 16 et 17 : E. Kas.
GENOSCOPE – Centre natio
nal de séquençage.Vous pouvez aussi lire