Data Warehouses für Bilder - Diplomarbeit Jean-Sébastien Vautrin
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Data Warehouses für
Bilder
Diplomarbeit
Jean-Sébastien Vautrin
September 2004
Prof. Dr. Jacques Calmet
Institut für Algorithmentechnik und Kognitive Systeme
Fakultät für Informatik
Universität Karlsruhe (TH)
Dr. Anne Tchounikine
Laboratoire d'Informatique en Images et Systèmes d'Information
Département Informatique
INSA de Lyon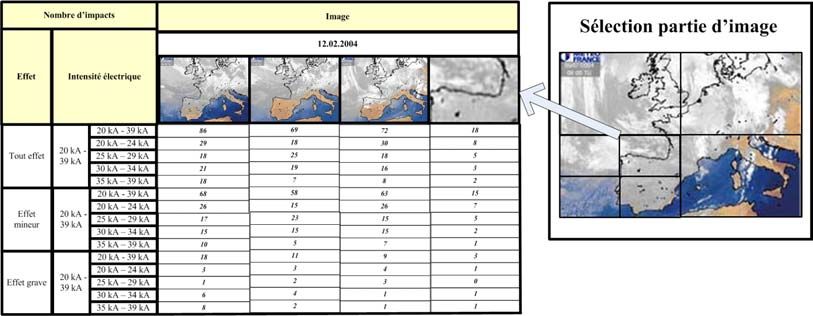
Erklärung
Hiermit erkläre ich, die vorliegende Arbeit selbständig erstellt und keine
anderen als die angegebenen Quellen und Hilfsmittel benutzt zu
haben.
Karlsruhe, den 29.09.2004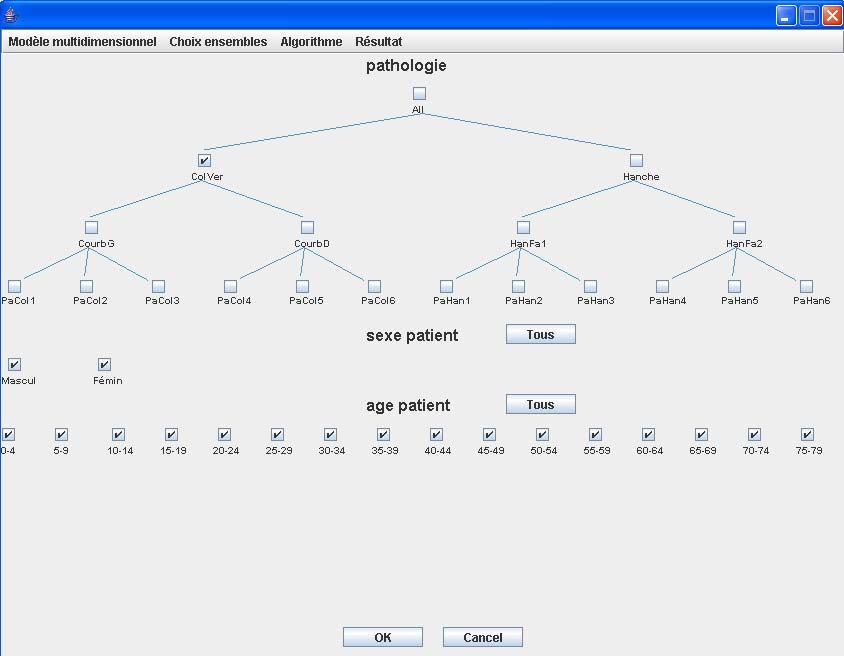
Dieses Dokument ist in zwei Teilen unterteilt:
1. Teil 1: Deutsche Zusammenfassung der Diplomarbeit
(Seiten 1-26).
2. Teil 2: Vollständige Version der in französischer
Sprache geschriebenen Diplomarbeit (Seiten 27-88).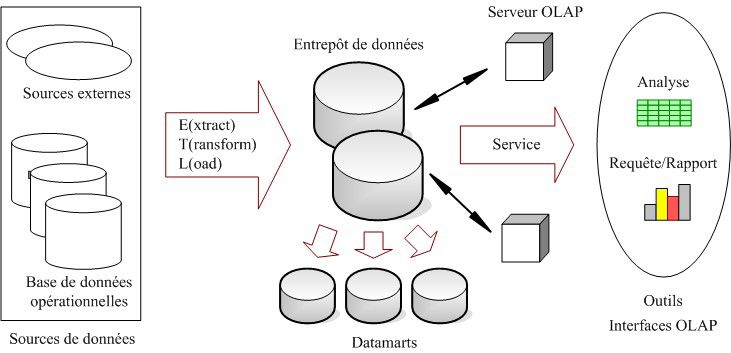
Teil 1
Deutsche Zusammenfassung der
Diplomarbeit
1
2
Zusammenfassung
Data Warehouses und OLAP-Systeme stellen Architekturen und Werkzeuge
bereit, welche zur Auswertung und zur Analyse von großen Datenmengen
angepasst sind und somit eine erhebliche Hilfe im
Entscheidungsfindungsprozess bieten. Klassische Data Warehouses
beschränken sich auf die Integration von alphanumerischen Daten, jedoch
beinhalten Bilder ebenfalls wichtige Informationen, die sich zur Datenanalyse
eignen. Im ersten Teil dieser Arbeit wird eine Typologie von Data Warehouses
für Bilder aufgestellt, in welcher zwischen zwei Fällen unterschieden wird. Im
ersten Fall bilden die Bilder eine Dimension. Im zweiten Fall sind die Bilder
die zu analysierenden Datenobjekte und sind somit die Fakten oder
Kenngrößen. Diesbezüglich wird vorgeschlagen, dass die Kenngröße ein Bild
ist, welches aus der Aggregation einer Menge von Bildern resultiert. In
diesem Fall führt die Materialisierung von Aggregaten zu
Datenspeicherproblemen. Es wird der Begriff der Relevanz einer Aggregation
von Bildern eingeführt und ein Model zur Materialisierung von Aggregaten
vorgeschlagen, welches entsprechend dieser Relevanz durchgeführt wird.
Anhand der vom Benutzer durchgeführten Selektionen, können Mengen von
Zellen von Kuboiden abgeleitet werden, deren Materialisierung
ausgeschlossen wird.
3
4
Inhaltsverzeichnis
1 Einführung ........................................................................................................7
2 Typologie von Data Warehouse Modellen für Bilder..................................11
2.1 Bilder als Dimension.................................................................................... 11
2.1.1 Kenngrößen ...........................................................................................................12
2.1.2 Dimensionen .........................................................................................................12
2.1.3 Hierarchische Gliederung der Bilderdimension ....................................................12
2.1.4 Anfragen................................................................................................................14
2.2 Bilder als Kenngrößen................................................................................. 14
2.2.1 Dimensionen .........................................................................................................14
2.2.2 Kenngrößen ...........................................................................................................15
2.2.3 Anfragen................................................................................................................15
3 Materialisierung von Sichten in einem Data Warehouse für Bilder..........17
3.1 Problematik .................................................................................................. 17
3.2 Auf der Relevanz einer Sicht basierender Ansatz .................................... 18
3.2.1 Definitionen...........................................................................................................19
3.2.2 Prototyp.................................................................................................................22
4 Zusammenfassung ..........................................................................................23
56
Kapitel 1
Einführung
Data Warehouses nehmen einen bedeutenden Platz ein, sowohl in der
Industrie, wo man oft von „Business Intelligence“ spricht, als auch in der
Forschung. Das Ziel ihres Einsatzes besteht darin, von großen Datenmengen
Profit zu ziehen, welche in verschiedenen Datenbänken gesammelt werden.
Diese Daten werden in Data Warehouses integriert, um sie effizient zu
analysieren und auszuwerten, und dienen somit als Hilfe zur
Entscheidungsfindung [CHA97]. Die Daten eines Data Warehouses werden
multidimensional modelliert [PED01]. Die sogenannten Fakten oder
Kenngrößen wie z.B. Erlöse, Gewinne oder Verluste, stehen im Zentrum der
Datenmodellierung. Diese Daten werden je nach Aggregationsebene mittels
Aggregatfunktionen berechnet. Die Kenngrößen sollen auf in verschiedener
Art unterteilten Bereichen betrachtet werden können, z.B. Zeit, Ort oder
Produkt. Jeden solchen Bereich modelliert man mit einer entsprechenden
Dimension. Letztere sind hierarchisch aufgebaut und besitzen mehrere
Dimensionsebenen, um Analysen verfeinern zu können. Solche Hierarchien
sind durch Klassifikationsschemata beschrieben (Bild 1). Die Entitäten einer
Dimension werden Dimensionselemente genannt und bilden mit den
hierarchischen Verbindungen die Klassifikationshierarchie (Bild 1). Jedes
dieser Dimensionselemente ist auf genau einer Dimensionsebene.
Bild 1: Klassifikationsschema und die dazugehörige Klassifikationshierarchie
7Kapitel 1. Einführung
Im klassischen Fall sind in Data Warehouses nur alphanumerische Daten
vorhanden. Jedoch werden immer mehr Bilder in Datenbanken integriert.
Bilder enthalten wichtige Informationen und eignen sich ebenfalls zur
Datenanalyse. Als Beispiel können die großen Bestände an medizinischen
Bildern erwähnt werden. Würden diese gleichermaßen in die Datenanalyse
bezüglich Krankheiten mit einbezogen werden, könnten die Analysen, in
manchen Fällen, effizienter durchgeführt werden.
Forschungsarbeiten wurden im Bereich der Data Warehouses für
Multimediadaten geleistet [ZAI98, YOU01, HAY02, WOO99]. In letzteren
spielen Bilder die Rolle von Dimensionen, indem Deskriptoren von den
Bildern extrahiert werden. Anhand dieser Deskriptoren werden die
Dimensionen gebildet. Deskriptoren sind zum Beispiel Farben, Texturen oder
Schlüsselwörter, welche die Bilder charakterisieren. Jedoch werden die Bilder
in alphanumerische Daten konvertiert und werden dabei selbst nicht
berücksichtigt. Deskriptoren können nicht alle in Bildern enthaltenen
Informationen widerspiegeln und dies kann die Analyse einschränken. Es
würde sich daher anbieten, eine auf den Bildern selbst aufgebaute Dimension
zu bilden, und nicht ausschließlich Deskriptoren zu verwenden.
Wenn die Kenngrößen Bilder sind, muss die Aggregatfunktion neu
definiert werden. Die klassischen Aggregatfunktionen der relationalen Algebra
wie z.B. MAX, MIN, SUM, COUN oder AVG, können hierfür nicht
verwendet werden.
In den bisher vorgeschlagenen Data Warehouses für Multimediadaten
wird dieses Problem umgangen, indem die Kenngrößen Zeiger auf Bilder sind.
In diesem Fall bestehen die Antworten auf Anfragen aus Listen von Bildern.
Jedes Bild, das die Kriterien der Anfrage erfüllt, ist ein Element einer solchen
Bilderliste. Jedoch kann die Liste aus hunderten oder tausenden Bildern
bestehen, was eine synthetische Sicht des Ergebnisses einer Anfrage kaum
ermöglicht. Ein aus der Aggregation einer Bildermenge resultierendes Bild
wäre daher vorteilhafter. In diesem Fall wären die Kenngrößen keine Zeiger
auf Bilder mehr, sondern die Bilder selbst. Dabei stellt sich ein Problem
bezüglich der Antwortzeiten auf Anfragen. Um die Antwortzeiten zu
verringern, wird eine häufig benutzte Methode angewandt, die darin besteht,
Aggregate von Sichten vorzuberechnen und bereitzuhalten, um Aggregationen
nicht „on-the-fly“ berechnen zu müssen. Man spricht hierbei von
Materialisierung von Sichten. Jedoch ist diese Methode sehr teuer, was den
benötigten Speicherplatz betrifft. Da das Datenvolumen von Bildern erheblich
größer ist als bei Zeigern, können bei gleichem Speicherplatz weniger Sichten
8Kapitel 1. Einführung
materialisiert werden. Dies spiegelt sich wiederum mit schlechteren
Antwortzeiten wider und gefährdet die Dienstqualität. Es ist daher notwendig,
Methoden zu entwickeln, die dem Kontext von Bildern als Kenngrößen
angepasst sind.
Ziel dieser Arbeit ist es die erwähnten Problematiken zu behandeln, um
die Integration von Bildern in Data Warehouses zu verbessern. Diese Arbeit
ist in zwei Teilen unterteilt:
1. Im ersten Teil wird eine Studie präsentiert, deren Ziel es ist, eine
Typologie von Data Warehouse Modellen für Bilder aufzustellen.
2. Im zweiten Teil wird die Problematik bezüglich der Materialisierung
von Sichten behandelt, wenn Kenngrößen Bilder sind.
9Kapitel 1. Einführung
10Kapitel 2
Typologie von Data Warehouse
Modellen für Bilder
Das multidimensionale Paradigma berücksichtigt drei Konzepte: Die
Eigenschaften, die Dimensionen und die Fakten bzw. Kenngrößen.
Dementsprechend wurden drei Klassen von Data Warehouse Modellen für
Bilder identifiziert:
1. Die erste Klasse beinhaltet die Modelle, welche Bilder als Eigenschaft
einer oder mehrerer Dimensionen integrieren. Die Bilder können somit
als zusätzliche Informationen zu alphanumerischen Daten dienen.
2. In der zweiten Klasse sind die Modelle vorhanden, in welchen die
Bilder selbst eine Dimension bilden. In diesem Fall ist es notwendig
eine Hierarchie auf den Bildern zu bilden, die es dem Benutzer
ermöglicht in den Daten zu navigieren, indem er unterschiedliche
Granularitäten von Daten wählt.
3. Die Data Warehouses der dritten Klasse integrieren die Bilder als
Kenngrößen. In diesem Fall müssen Aggregatfunktionen definiert
werden, sowie die diesem Datentyp angepassten Strategien zur
Materialisierung von Sichten entwickelt werden, wie dies für
alphanumerische oder geographische Daten gemacht wurde.
Es werden folgend nur die Modelle der zweiten und dritten Klasse
vorgestellt. Die Modelle der ersten Klasse stellen keine Problematik dar.
2.1 Bilder als Dimension
In diesem Modelltyp bilden die Bilder eine Dimension. Die Kenngrößen
sind alphanumerische Daten, die Zonen in den Bildern und
Dimensionselementen der anderen Dimensionen zugeordnet sind. Betrachten
wir zum Beispiel Satellitenbilder. Wenn Regenfälle oder
11Kapitel 2. Typologie von Data Warehouse Modellen für Bilder
Windgeschwindigkeiten die Daten sind, die den Bildern zugeordnet sind, so
können diese Daten bestimmten Zonen zugewiesen werden, z.B. Punkte auf
den Bildern, die den Ort der Wetterstation präzisieren, wo die Werte gemessen
wurden.
Die Data Warehouse Modelle dieser Klasse nähern sich sichtlich der Data
Warehouse Modelle des „Spatial OLAP“ (SOLAP) an, welche die OLAP
Systeme sind, die bei Data Warehouses für geographische Daten Verwendung
finden [PAP01, STE97]. Diese Ähnlichkeit erspart jedoch nicht die
Notwendigkeit von gewissen Anpassungen, um die vorhandenen Unterschiede
in Betracht zu ziehen. Dies ist z.B. der Fall bei der hierarchischen Gliederung
eines Bildes. Der Modelltyp wird in den folgenden Unterkapiteln beschrieben.
2.1.1 Kenngrößen
Die Kenngrößen können sichtbar sein, das bedeutet Objekte auf einem
Bild sein (z.B. Tumoren auf einem medizinischen Bild). Kenngrößen können
aber auch nicht sichtbar sein, z.B. die Windgeschwindigkeit. Bei letzteren
weist der Benutzer den Kenngrößen künstliche Koordinaten zu, welche die
Zonen in den Bildern bestimmen, die den Kenngrößen zugeordnet sind. Falls
es sich um eine sichtbare Kenngröße handelt, entsprechen die Koordinaten der
Zone im Bild den Konturen des jeweiligen Objektes.
2.1.2 Dimensionen
Es werden drei Dimensionstypen definiert:
1. Eine nicht Bilder Dimension ist eine Dimension, die auf allen
Dimensionsebenen alphanumerische Daten enthält.
2. Eine Bilder zu Bilder Dimension ist eine Dimension, die auf allen
Dimensionsebenen Bilder beinhaltet.
3. Eine Bilder zu nicht Bilder Dimension ist eine Dimension, die auf
unteren Dimensionsebenen aus Bildern und ab einer gewissen
Dimensionsebene aus alphanumerischen Daten besteht.
2.1.3 Hierarchische Gliederung der Bilderdimension
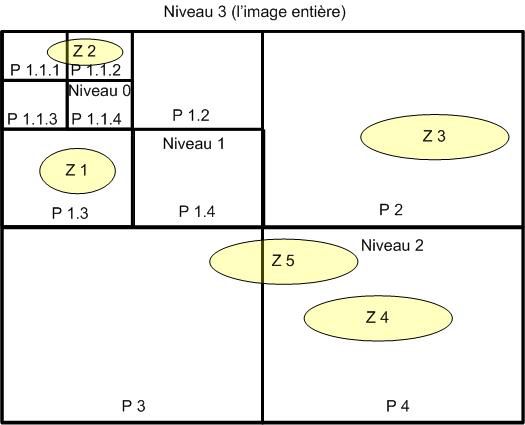
Ein „ganzes“ Bild ist auf der obersten Dimensionsebene. Um die unteren
Dimensionsebenen zu definieren, wird ein Bild in mehrere Teile zerteilt. Dazu
werden drei Zerteilungen definiert:
12Kapitel 2. Typologie von Data Warehouse Modellen für Bilder
1. Regelmäßige Zerteilung: Diese Methode besteht darin, ein Bild
rekursiv in n rechteckige Teile, bis zur gewünschten kleinsten
Granularität bzw. den kleinsten Bildteilen (Bild 2) zu zerteilen. Jedem
Bildteil der feinsten Granularität wird die Aggregation der Kenngrößen
zugeteilt, die den im Bildteil enthaltenen Zonen zugeordnet sind. Falls
eine Zone in mehreren Bildteilen enthalten ist, muss nur ein Teil der
Kenngröße dem jeweiligen Bildteil zugewiesen werden. Dieser Teil
sollte proportional zu der von dem Bildteil überlappenden Fläche sein.
2. Manuelle Zerteilung: Die Zerteilung wird von dem Benutzer selbst
durchgeführt, damit er die Datenanalyse mittels einer hierarchischen
Gliederung der Bilderdimension machen kann, die seinem Bedarf
entspricht.
3. Unregelmäßige Zerteilung: Die Zerteilung wird entsprechend den
Zonen, welchen Kenngrößen zugewiesen wurden, durchgeführt. Dies
ermöglicht dem Benutzer in der Bilderdimension, gemäß den Orten der
Kenngrößen zu navigieren. Nach der Zerteilung entsprechen die
kleinsten Bildteile den „minimal bounding rectangles“ der Zonen,
welchen die Kenngrößen zugewiesen wurden. Die Bildteile auf
höheren Dimensionsebenen werden mittels Gruppierungen der
Bildteile auf unteren Dimensionsebenen bestimmt (Bild 3). Hierfür
können Techniken benutzt werden, die im Bereich des SOLAP
Verwendung finden [PAP01]. Diese Techniken verwenden so genante
„R-Trees“, die zur Indexierung von geographischen Daten genutzt
werden.
Bild 2: Regelmäßige Zerteilung Bild 3: Unregelmäßige Zerteilung
13Kapitel 2. Typologie von Data Warehouse Modellen für Bilder
2.1.4 Anfragen
Es kann zwischen zwei Anfragetypen unterschieden werden:
1. Für jede Dimension wird ein Dimensionselement gewählt. Diese
Anfragen sind dementsprechend gleichermaßen wie bei den klassischen
Data Warehouses definiert.
2. Bei diesem Anfragetyp werden die Dimensionselemente jeder nicht
Bilder Dimension sowie die Dimensionselemente der Bilder zu nicht
Bilder Dimension gewählt, falls es sich um Deskriptoren handelt. Um
ein Teil eines Bildes zu wählen, wird hierbei nicht das jeweilige
Dimensionselement angegeben, sondern es wird ein „query window“
verwendet, wie es bei SOLAP-Systemen üblich ist. Der Einsatz eines
„query window“ ermöglicht es dem Benutzer einen beliebigen Teil
eines Bildes für die Datenanalyse zu selektieren. Er ist somit nicht an
die Wahl eines aus der Zerteilung hervorgehenden Bildteiles gebunden.
2.2 Bilder als Kenngrößen
In diesem Modelltyp werden die Dimensionen ausschließlich anhand von
Deskriptoren gebildet. Die Kenngrößen sind in diesem Fall Bilder. Bei den
bisher vorgeschlagenen Data Warehouses im „State of the Art“ beschränken
sich die Kenngrößen auf Zeiger auf Bilder. Es wird in dieser Arbeit ebenfalls
vorgeschlagen, ein Bild aus einer Aggregation einer Menge von Bildern zu
verwenden. In diesem Fall muss die Aggregatfunktion neu definiert werden,
da die klassischen Aggregatfunktionen der relationalen Algebra sich hierzu
nicht eignen.
2.2.1 Dimensionen
Zur Bildung der Dimensionen werden in diesem Data Warehouse
Modelltyp ausschließlich Deskriptoren verwendet. Da Deskriptoren
alphanumerische Daten sind, können die Dimensionen auf gleiche Art und
Weise hierarchisch gebildet werden, wie es bei klassischen Data Warehouses
üblich ist.
14Kapitel 2. Typologie von Data Warehouse Modellen für Bilder
2.2.2 Kenngrößen
Die Kenngrößen sind Bilder. Es kann sich hierbei um Zeiger auf Bilder,
wie es im State of the Art der Fall ist, oder um ein aus der Aggregation einer
Menge von Bildern resultierendes Bild handeln. Wenn der Benutzer die
„originalen“ bzw. die unveränderten Bilder als Antwort auf eine Anfrage
sehen will, ist der Gebrauch von Zeigern die einzig mögliche Lösung. Jedoch
ermöglicht dieser Ansatz keine synthetischen Antworten auf Anfragen, da
Antworten aus hunderten oder gar tausenden Bildern bestehen können.
Deshalb wurde der aus einem Bild bestehende Kenngößentyp bei dieser Arbeit
näher studiert.
Eine Aggregation einer Menge von Bildern besteht aus einer
Überlagerung von Bildern. Jede Aggregatfunktion, welche ein einziges Bild
aus einer Menge von Bildern erzeugt, ist denkbar. Um die Vergleichbarkeit
von Bildern zu gewährleisten, müssen die im Data Warehouse integrierten
Bilder die gleichen Maße besitzen, das heißt gleich lang und gleich breit sein.
2.2.3 Anfragen
Da die Dimensionen alle anhand von Deskriptoren gebildet sind,
unterscheidet sich der Anfragetyp nicht mit dem Anfragetyp der klassischen
Data Warehouses.
15Kapitel 2. Typologie von Data Warehouse Modellen für Bilder
16Kapitel 3
Materialisierung von Sichten in
einem Data Warehouse für Bilder
3.1 Problematik
Wenn Bilder zur Bildung einer Dimension oder als Eigenschaften benutzt
werden, sind die Probleme bezüglich des Speicherplatzes und der
Antwortzeiten auf Anfragen kaum verstärkt im Vergleich zu klassischen Data
Warehouses. Werden jedoch die Bilder als Kenngrößen verwendet, so sind
diese Probleme wesentlich komplizierter, da die Sichtenmaterialisierung auf
Redundanz basiert. Da Bilder sehr volumenreich sind, kann der benötigte
Speicherplatz durch diese Redundanz sehr groß werden und folglich können
nicht genug Sichten materialisiert werden. Zudem kommt noch hinzu, dass
Aggregatfunktionen, die auf Bildern operieren, üblicherweise komplexer sind,
und daher bei ihrer Anwendung mehr Zeit in Anspruch nehmen. Aus diesen
Gründen wird in diesem Kapitel eine Methode vorgeschlagen, die diese
Probleme behandelt.
Die Probleme bezüglich der Antwortzeiten auf Anfragen haben viele
Forschungsarbeiten zum Vorschein gebracht. Um diesen Problemen
entgegenzuwirken, wurden Methoden zur selektiven Materialisierung von
Sichten vorgeschlagen. Eine Sicht wird ebenfalls als Kuboid bezeichnet. Der
als HRU benannte Algorithmus [HAR96] ist der Refererenzalgorithmus zur
Selektion von zu materialisierenden Sichten. Der Datenwürfel wird als
Verband von Kuboiden dargestellt (Bild 4). Einige Sichten können von
anderen Sichten hergeleitet werden, die detailliertere Daten enthalten und
Nachfolger im Verband von Kuboiden sind. Die Daten aller Sichten können
von dem Basiskuboid hergeleitet werden. Letzterer enthält die detailliertesten
Daten. Der Algorithmus berücksichtigt die Tatsache, dass die
Materialisierung einer Sicht die Antwortzeiten für den Zugriff von Daten
17Kapitel 3. Materialisierung von Sichten in einem Data Warehouse für Bilder
Bild 4: Verband von Kuboiden (Sichten)
der jeweiligen Sicht und der Sichten, die Vorgänger der letzteren sind,
reduziert.
Der HRU-Algorithmus erzielt gute Ergebnisse und kann ausreichend sein
für alphanumerische Kenngrößen. Sind die Kenngrößen jedoch Bilder, würde
es oftmals nicht möglich sein, eine ausreichende Anzahl von Sichten zu
materialisieren, um schnelle Antwortzeiten zu gewährleisten, die für den
Benutzer akzeptabel sind. Dieses Problem wird in dieser Arbeit behandelt,
indem im folgenden Unterkapitel eine Methode vorgestellt wird, welche die
Verwendung des zur Verfügung stehenden Speicherplatzes optimiert.
3.2 Auf der Relevanz einer Sicht basierender
Ansatz
Wenn eine Kenngröße ein aus der Aggregation einer Menge von Bildern
resultierendes Bild ist, muss die Tatsache in Betracht gezogen werden, dass
eine Aggregation einer Menge von Bildern nicht immer relevant ist, das
bedeutet, dass das eine Menge von Bildern repräsentierende Bild nicht immer
nützlich für die Datenanalyse ist. Dies ist der Fall, wenn die zu aggregierende
Menge von Bildern zu heterogen ist. Betrachten wir zum Beispiel eine Menge
von Röntgenbildern von Lungen und von Wirbelsäulen. Da diese Bilder
verschiedene Objekte darstellen, wäre es widersinnig eine solche Menge von
Bildern zu aggregieren. Selbst wenn die Bilder gleiche Objekte darstellen,
kann eine Aggregation nicht relevant sein. Dieser Fall tritt ein, wenn die
Objekte verschiedene Bereiche in den Bildern abdecken. Es wäre z.B.
widersinnig eine Menge von Röntgenbildern, welche Wirbelsäulen mit stark
unterschiedlichen Krümmungen darstellen, oder Röntgenaufnahmen von sehr
jungen Kindern und Erwachsenen zu aggregieren.
18Kapitel 3. Materialisierung von Sichten in einem Data Warehouse für Bilder
Es wird vorgeschlagen, den Begriff der Relevanz einer Aggregation für
die Wahl der zu materialisierenden Zellen von Kuboiden zu integrieren. Ziel
ist es, die Materialisierung von gewissen Sichten zu verhindern, bei denen im
Vornherein sicher steht, dass sie für die Datenanalyse nicht nützlich sind.
Somit bleibt mehr Speicherplatz frei, um nützliche Sichten zu materialisieren.
Im folgenden Unterkapitel werden die Definitionen vorgestellt, welche
das Erreichen dieses Zieles ermöglichen.
3.2.1 Definitionen
Definition 1: Relevanz einer Aggregation einer Menge von Bildern
J
Sei ⊕ µ k i j eine Aggregatfunktion, ij ein Bild der Menge I, µk die Kenngröße k
j =1 J
und J die Kardinalität von I. Die Aggregation der Menge I mittels ⊕ µ k i j ist
j =1
relevant, wenn, und genau wenn das Ergebnis der Aggregation nicht
widersinnig ist.
Es sei darauf hingewiesen, dass der Begriff der Relevanz vom Auge des
Betrachters abhängt. Der Benutzer entscheidet also, ob eine Aggregation
relevant ist oder nicht. Die Kuboide, welche teilweise materialisiert werden
sollen, entsprechen jeweils einer Sicht, die jeweils durch folgende
Kombination entstehen: D1a, D2b,..., Dns , wobei Di x die Dimensionsebene x
der Dimension Di und n die Anzahl der Dimensionen des multidimensionalen
Modells ist. Jede Zelle eines Kuboides entspricht einer Kombination
( m 1 j a k b ,..., m n jl k m ), wobei m i j x k y das Dimensionselement ky auf der
Dimensionsebene jx der Dimension i ist.
Notierung 1:
Um Mengen von Bildern zu identifizieren, wird folgende Notierung
eingeführt: Images( m i j k ) ist die Menge von Bildern des Basiskuboides,
x y
welche unter ihren Koordinaten ein Dimensionselement m i j s k t der untersten
Dimensionsebene der Dimension i haben, mit:
• entweder m i j s k t = m i j xk y
,
• entweder m i js kt ist Nachfolger von m i jxk y in der
Klassifikationshierarchie der Dimension i.
19Kapitel 3. Materialisierung von Sichten in einem Data Warehouse für Bilder
Eigenschaft 1: Zu aggregierende Menge von Bildern
Sei ( m 1 j a k b ,..., m n j o k p ) eine Kombination von Dimensionselementen. Um das
in der Zelle ( m 1 ja k b ,..., m n jo k p ) enthaltene Bild zu erhalten, wird folgende
Menge von Bildern aggregiert: I=Images ( m1 ja kb ) ∩ ... ∩ Images (m n jo k p ) .
Definition 2: Relevanz einer Kombination von Dimensionselementen
Eine Kombination ( m 1 j a k b ,..., m n j o k p ) ist nicht relevant, wenn, entsprechend
der Definition 1, die Aggregation von Images( m 1 j a k b ,..., m n j o k p ) nicht
relevant ist.
Eigenschaft 2: Die Vererbung der Nicht-Relevanz für Mengen von
Bildern
J
Sei ⊕ µ k i j nicht relevant, wobei ij ein Bild der Menge Ix ist. Dann ist für Iy,
j =1 H
mit I x ⊆ I y , h⊕=1 µ k ih nicht relevant, wobei ih ein Bild der Menge Iy ist.
Eigenschaft 3: Die Vererbung der Nicht-Relevanz für Kombinationen von
Dimensionselementen
Sei ( m 1 ja k b ,..., m n jl k m ) nicht relevant. Dann sind alle Kombinationen von
Dimensionselementen ( m '1 jo k p ,..., m ' n j s k t ) mit :
i
z entweder m ' i j u k v = m jxk y , 1≤i≤n
i
z entweder m ' ju k v ist Vorgänger von m i jxk y in der
Klassifikationshierarchie der Dimension i, 1 ≤ i ≤ n
nicht relevant.
Definition 3: Ein zur Dimension i nicht relevantes Dimensionselement
Ein Dimensionselement m i j k ist nicht relevant zur Dimension i, wenn der
x y
Benutzer der Meinung ist, dass die Aggregation von Images( m i j k ) nicht x y
relevant ist.
Der Benutzer wählt alle zur Dimension i nicht relevanten
Dimensionselemente. Nachdem er diese Dimensionselemente selektiert hat,
gibt er die nicht relevanten Kombinationen dieser Dimensionselemente mit
Dimensionselementen anderer Dimensionen an. Ist m i j k ein nicht relevantes
x y
Dimensionselement, so kann, entsprechend der Eigenschaft 1, die Kuboidzelle
( m i j k All…All) von der Materialisierung ausgeschlossen werden. Jedoch
x y
bedeutet dies nicht, dass eine Untermenge von Images( m i j k ), die man durch
x y
die Kombination mit Dimensionselementen anderer Dimensionen erhält, nicht
relevant ist. Mengen von Kombinationen von Dimensionselementen werden
20Kapitel 3. Materialisierung von Sichten in einem Data Warehouse für Bilder
wie folgt beschrieben: {M 1 }× {M 2 }× ... × {M n } , wobei Mx eine Menge von
Dimensionselementen der Dimension x, n die Anzahl von Dimensionen und ×
der Operator des kartesischen Produktes ist.
Sei m 1 j k ein nicht relevantes Dimensionselement zur Dimension 1. Es wird
x y
zwischen zwei Fällen unterschieden:
1. Es gibt keine Untermenge von Images( m 1 j x k y ), bei welcher die
Aggregation relevant ist.
2. Es gibt mindestens eine Untermenge von Image( m 1 j x k y ), bei welcher
die Aggregation relevant ist.
Eigenschaft 4: Deduktion von Kombinationen von Dimensionselementen
Gemäß der Eigenschaft 3 kann abgeleitet werden, dass wenn
A= {M 1 }× {M 2 }× ... × {M n } eine Menge von Kombinationen von
Dimensionselementen ist, bei welcher jede Kombination nicht relevant ist, so
sind die Kombinationen der Menge
B= {M 1 ∪ M '1 }× {M 2 ∪ M ' 2 }× ... × {M n ∪ M ' n } nicht relevant, wobei M’i eine
Menge von Dimensionselementen ist, welche Vorgänger eines
Dimensionselementes von Mi, in der jeweiligen Klassifikationshierarchie sind.
Nachdem der Benutzer ein nicht relevantes Dimensionselement zur
Dimension i gewählt hat, gibt er die Kombinationen dieses
Dimensionselementes mit den Dimensionselementen der anderen
Dimensionen an. Er macht dies, indem er die Menge von Kombinationen
A= {m i j k }× {M k }× ... × {M z } angibt, so dass jede Kombination Element von A
x y
nicht relevant ist, wobei m i j k das nicht zur Dimension i relevante
x y
Dimensionselement ist. Gemäß Eigenschaft 4 reicht es für die Mengen Mi nur
die der jeweiligen untersten Dimensionsebene angehörenden
Dimensionselemente zu wählen, da die restlichen Kombinationen automatisch
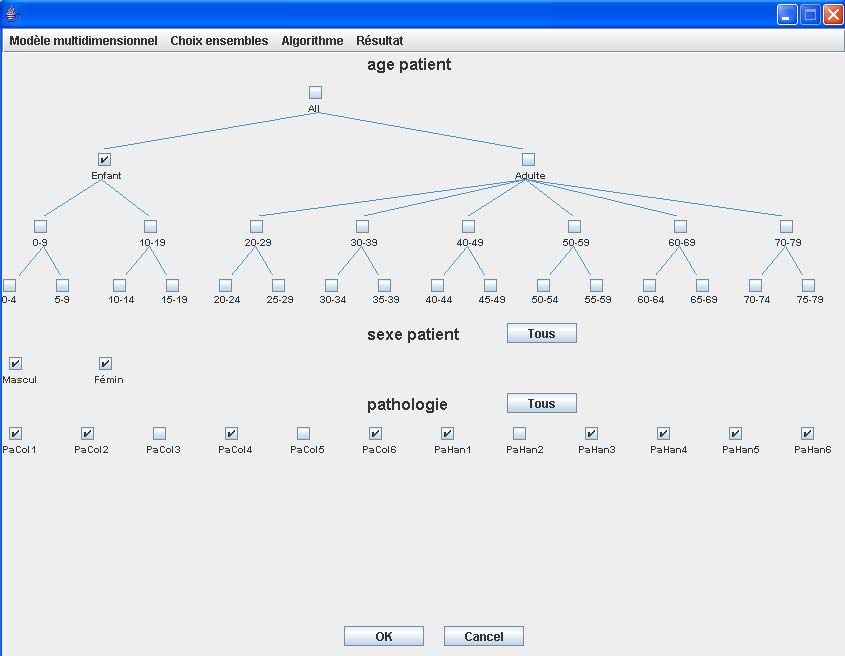
hergeleitet werden können. Bild 5 zeigt ein Beispiel einer Wahl einer Menge
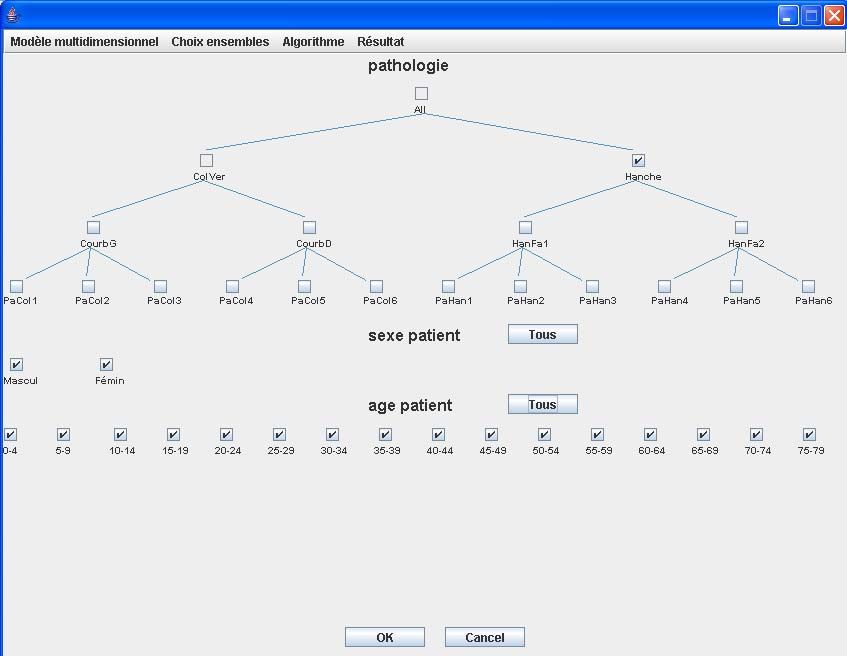
von nicht relevanten Kombinationen. Es wurde hierbei All als nicht relevantes
Dimensionselement zur Dimension Geschlecht gewählt. Die selektierten
Dimensionselemente sind umrahmt. Anhand einer vom Benutzer selektierten
Menge A kann automatisch eine größere Menge B hergeleitet werden mit
Hilfe eines dafür in dieser Arbeit entwickelten Algorithmus. Die Zellen von
Kuboiden, die jeweils einer Kombination von Dimensionselementen einer
Menge Bi entsprechen, werden von der Materialisierung ausgeschlossen.
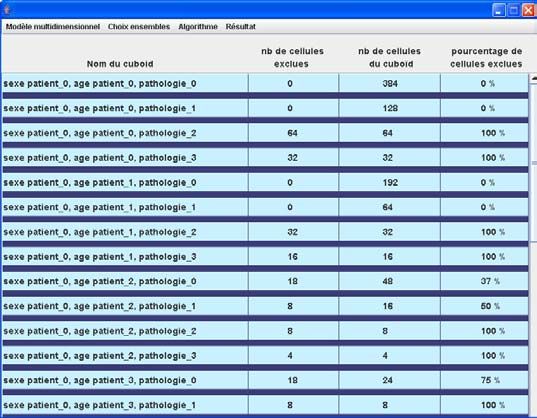
Der Algorithmus wurde in dem entwickelten Prototyp eingesetzt, der im
folgenden Unterkapitel beschrieben wird.
21Kapitel 3. Materialisierung von Sichten in einem Data Warehouse für Bilder
Bild 5: Selektion einer Menge von nicht relevanten Kombinationen
3.2.2 Prototyp
Der Prototyp wurde in JAVA entwickelt. Die Hauptfunktionalitäten sind
aufgelistet:
• Laden des multidimensionalen Modells anhand von XML Dokumenten.
Jede Klassifikationshierarchie einer Dimension wird durch ein XML
Dokument angegeben. Daraufhin wird die Datenstruktur des Verbandes
von Kuboiden aufgebaut.
• Wahl der nicht relevanten Kombinationen von Dimensionselementen
mit Hilfe einer dafür angepassten Benutzerschnittstelle.
• Berechnung der hergeleiteten, nicht relevanten Kombinationen durch
den entwickelten Algorithmus. Nach Anwendung des Algorithmus,
enthält die Datenstruktur des Verbandes von Kuboiden für jede
Kuboidzelle einen Wert, der angibt, ob die jeweilige Zelle materialisiert
werden soll oder nicht.
• Berechnung und Abbildung der Ergebnisse. Der prozentuale Anteil von
Kuboidzellen, die von der Materialisierung ausgeschlossen sind, wird
angegeben. Diese Information ermöglicht die Schätzung des Gewinnes
bezüglich des Speicherplatzbedarfs, der durch Anwendung dieser
Methode ermöglicht wurde.
22Kapitel 4
Zusammenfassung
Im ersten Teil der Arbeit wurde eine Typologie von Data Warehouses für
Bilder vorgestellt, in welcher zwischen zwei Fällen unterschieden wird. Im
ersten Fall werden Bilder verwendet, um eine Dimension zu bilden. Im
zweiten Fall sind die Kenngrößen Bilder. Hierfür wurde vorgeschlagen,
Kenngrößen zu verwenden, die jeweils ein aus einer Aggregation einer Menge
von Bildern resultierendes Bild sind. Somit sind die Ergebnisse von Anfragen
wesentlich synthetischer, als wenn es sich um Bilderlisten handeln würde.
Im zweiten Teil der Arbeit wurde die Problematik der Materialisierung
von Sichten behandelt, wenn die Kenngrößen Bilder sind. Es wurde hierfür der
Begriff der Relevanz einer Aggregation von Bildern eingeführt, die es dem
Benutzer ermöglicht, die Aggregate zu identifizieren, welche ihm für die
Datenanalyse nicht nützlich sind. Anhand von Mengen von nicht relevanten
Kombinationen von Dimensionselementen, die vom Benutzer angegeben
werden, werden mit Hilfe eines entwickelten Algorithmus größere Mengen
von Kombinationen hergeleitet. Diese Kombinationen entsprechen den Zellen
von Kuboiden, welche von der Materialisierung ausgeschlossen werden. Somit
werden nur die Zellen von Kuboiden materialisiert, die für die Datenanalyse
nützlich sind. Dadurch wird der verfügbare Speicherplatz effektiver genutzt.
Die in dieser Arbeit entwickelte Methode kann ergänzend zu Algorithmen zur
Selektion von zu materialisierenden Sichten angewendet werden. Wenn solche
Algorithmen nach Anwendung der in dieser Arbeit vorgestellten Methode
verwendet werden, so können mehr relevante Aggregate materialisiert werden,
indem nicht relevante Aggregate identifiziert und von der Materialisierung
ausgeschlossen werden.
2324
Literaturverzeichnis
[CHA97] S. Chaudhuri, U. Dayal. An Overview of Data Warehousing and
OLAP Technology. ACM SIGMOD Record, Volume 26, no. 1, pp. 65-74.
März 1997.
[HAR96] V. Harinarayan, A. Rajaraman, J. D.Ullman. Implementing Data
Cubes Efficiently. In Proceedings of the ACM SIGMOD Conference of
Management of Data, pp. 205-216, Montreal, Quebec. Juni 1996.
[HAY02] T. Hayashi, A. Sato, N. Berthouze. A hierarchical model to support
Kansei mining process. Intelligent Data Engineering and Automated Learning-
IDEAL 2002. Third International Conference, pp. 56-61, Manchester, UK. 12-
14. August 2002.
[PED01] T. B. Pedersen, C. S. Jensen. Multidimensional Database
Technology. IEEE Computer, Volume 34, no. 12, pp. 40-46. Dezember 2001.
[PAP01] D. Papadias, P. Kalnis, J. Zhang et al. Efficient Operations in Spatial
Data Warehouses. 7th International Symposium, SSTD 2001, pp. 443-459,
Redondo Beach, USA.12.-15. Juli 2001.
[STE97] N. Stefanovic. Design and Implementation of On-Line Analytical
Processing (OLAP) of Spatial Data. Doktorarbeit, Simon Fraser University.
1997.
[YOU01] J. You, T. Dillon, J. Liu, E. Pissaloux. On hierarchical information
retrieval. Proceedings 2001 International Conference on Image Processing, pp.
729-732, Thessaloniki, Greece. 7.-10. Oktober 2001.
[ZAI98] O.R. Zaïane, J.Han, Z.-N. Li, J. Hou. Mining Multimedia Data.
Proceeding CASCON'98: Meeting of Minds, pp. 83-96, Toronto, Canada.
November 1998.
[WOO99]L. Wookey, K. Yongkyu, L. Yunsun et al. Developing Multimedia
Data Warehouse of Education On-Demand Systems. Proceedings of IEEE.
IEEE Region 10 Conference. TENCON 99. `Multimedia Technology for Asia-
Pacific Information Infrastructure, pp. 942-945, Cheju Island, South Korea.
15.-17. September 1999.
2526
Teil 2
Vollständige Version der in
französischer Sprache geschriebenen
Diplomarbeit
2728
Résumé
Les entrepôts de données et les systèmes OLAP proposent des architectures et
des outils adaptés à l’exploitation et à l’analyse de grands volumes de données,
offrant ainsi une aide considérable au processus décisionnel. Les entrepôts de
données classiques se limitent à l’intégration de données alphanumériques, or
les images contiennent également des informations précieuses pouvant servir à
l’analyse de données. Dans un premier temps, nous établissons une typologie
d’entrepôts d’images dans laquelle nous distinguons deux cas. Dans le premier
cas, les images jouent le rôle d’axe d’analyse et forment une dimension. Dans
le deuxième cas, les images sont les sujets d’analyse ou faits. Nous proposons
pour cela que la mesure soit une image issue de l’agrégation d’un ensemble
d’images. Dans ce cas, la matérialisation d’agrégats pose des problèmes de
stockage et d’optimisation. Nous introduisons la notion de pertinence d’une
agrégation d’images et proposons un modèle de matérialisation d’agrégats
effectuée en fonction de cette pertinence. A partir des choix effectués par
l’utilisateur, nous en déduisons l’ensemble des cellules de cuboïdes ne devant
pas être matérialisées.
2930
Sommaire
1 Introduction.....................................................................................................33
2 Etude bibliographique et positionnement du problème.............................. 35
2.1 Les entrepôts de données.................................................................................... 35
2.1.1 Intégration des données dans l’entrepôt : les outils back-end.....................................36
2.1.2 Le modèle conceptuel : le modèle multidimensionnel d’hypercube...........................36
2.1.3 Le modèle physique....................................................................................................38
2.1.4 Interfaces: les outils front-end ....................................................................................39
2.2 La prise en compte de données complexes dans les entrepôts ........................ 39
2.2.1 Spatial OLAP..............................................................................................................40
2.2.1.1 Hiérarchie spatiale statique .................................................................................41
2.2.1.2 Hiérarchie spatiale dynamique............................................................................42
2.2.2 Entrepôts de données multimédia...............................................................................43
2.3 Conclusion et présentation des travaux effectués ............................................ 45
3 Typologie de modèles d’entrepôts d’images................................................. 47
3.1 Les images en dimension .................................................................................... 48
3.1.1 Type de modèle ..........................................................................................................48
3.1.1.1 Types de faits ......................................................................................................48
3.1.1.2 Types de dimension ............................................................................................49
3.1.1.3 Création d’une hiérarchie sur la dimension image..............................................49
3.1.2 Type de requête ..........................................................................................................52
3.1.2.1 Choix de membres de la dimension ....................................................................52
3.1.2.2 Utilisation d’une fenêtre de requête ....................................................................52
3.1.3 Exemple......................................................................................................................52
3.1.3.1 Modèle multidimensionnel .................................................................................52
3.1.3.2 Interface ..............................................................................................................53
3.2 Les images en faits .............................................................................................. 54
3.2.1 Type de modèle ..........................................................................................................54
313.2.1.1 Dimensions ......................................................................................................... 54
3.2.1.2 Faits et Mesures .................................................................................................. 54
3.2.2 Exemple...................................................................................................................... 55
3.2.2.1 Modèle multidimensionnel ................................................................................. 55
3.2.2.2 Interface.............................................................................................................. 56
3.3 Conclusion ........................................................................................................... 57
4 Matérialisation de vues dans un entrepôt d’images.................................... 59
4.1 Positionnement du problème ............................................................................. 59
4.1.1 Motivation .................................................................................................................. 59
4.1.2 Types de mesures ....................................................................................................... 60
4.1.3 La matérialisation de cuboïdes dans le cas classique ................................................. 60
4.1.4 Présentation générale de notre proposition................................................................. 63
4.2 Approche basée sur le calcul de pertinence des vues....................................... 63
4.2.1 Présentation générale de la méthode .......................................................................... 64
4.2.2 Définitions.................................................................................................................. 65
4.2.3 Mode de sélection de non-pertinence ......................................................................... 70
4.2.4 Algorithme ................................................................................................................. 72
5 Prototype ......................................................................................................... 77
6 Discussion & Conclusion ............................................................................... 79
6.1 Apports de notre approche ................................................................................ 79
6.2 Limites de notre approche ................................................................................. 79
6.3 Perspectives ......................................................................................................... 80
32Chapitre 1
Introduction
Les entrepôts de données occupent une place majeure, aussi bien dans le
monde de l’industrie, où l’on parle souvent de « Business Intelligence », que
dans celui de la recherche. L’intérêt principal consiste à tirer profit de grands
volumes de données collectées dans différentes bases de données
transactionnelles. Ces données sont intégrées dans les entrepôts de données
afin de pouvoir les analyser efficacement, servant ainsi de support d’aide à la
prise de décision. Ces analyses se font souvent à l’aide de systèmes OLAP
(On-Line Analytical Processing) qui s’opposent aux systèmes OLTP (On-Line
Transactional Processing) utilisés avec les bases de données transactionnelles.
Les systèmes OLTP garantissent la non-redondance, la fiabilité, la cohérence
et la performance. Contrairement à ces derniers, les systèmes OLAP sont plus
adaptés à l’exploitation de données et à l’analyse décisionnelle. Les données
dans les entrepôts sont modélisées sous forme de structure
multidimensionnelle, dans laquelle les données sont organisées en fonction de
plusieurs axes d’analyse, appelés dimensions. Les sujets d’analyse, appelés
faits ou mesures, sont calculés à l’aide de fonctions d’agrégations selon les
différentes granularités. Par exemple, les dimensions pourraient être les
produits, les localisations et les clients, et les faits pourraient être la quantité
vendue.
Dans le cas classique, les entrepôts de données sont constitués de données
alphanumériques. Or, de plus en plus d’images sont intégrées dans les bases de
données contenant des informations précieuses et se prêtant également à leur
exploitation et à l’analyse. Par exemple, dans le domaine de la santé, les
analyses visant à accroître les connaissances sur différentes pathologies
pourraient dans de nombreux cas être plus efficaces si des images médicales
étaient intégrées dans le processus décisionnel. Pour cette raison, les entrepôts
de données multimédia intégrant des images sont devenus un sujet de
recherche très prometteur qui soulève de nombreuses problématiques.
33Chapitre 1. Introduction
Une des premières problématiques consiste à déterminer et à étudier la
place et le rôle des images dans un entrepôt : les images peuvent-elles être
utilisées en tant que propriété d’une dimension, en tant que dimension et/ou en
tant que fait ? Les propositions faites jusqu’à présent sont basées sur
l’utilisation de descripteurs de contenu ou textuels extraits manuellement ou
automatiquement des images (mot-clé, couleur, texture,…). Or, cela revient à
ramener des images à des données alphanumériques, donc au cas classique, et
ne prend pas réellement en compte les images elles-mêmes. L’utilisation
d’images en tant que faits conduit à la redéfinition des fonctions d’agrégations.
En effet, les opérateurs d’agrégation relationnels classiques (COUNT,
SUM,…) ne sont pas appropriés à des données images. La solution proposée
jusqu’à présent qui consiste à remplacer ces opérateurs par un opérateur de
liste de pointeurs sur des images ne permet une analyse efficace que lorsque
les faits sont peu nombreux. Enfin le problème dit de la matérialisation de
vues, c’est-à-dire le précalcul et le stockage des différents agrégats en vue
d’accélérer les réponses aux requêtes, devient un problème critique dans le cas
de données aussi volumineuses que des images.
Le but de notre travail consiste à proposer des solutions aux
problématiques citées ci-dessus, afin de permettre l’intégration d’images au
sein de l’entrepôt.
Ce rapport est organisé comme suit : tout d’abord, nous présentons les
problématiques et les solutions existantes à la fois pour des entrepôts de
données classiques et multimédia. Ensuite, nous présentons les travaux que
nous avons effectué qui sont organisés en deux parties. Dans la première
partie, nous présentons une étude visant à établir une typologie d’entrepôts
d’images en abordant les deux premières problématiques présentées ci-dessus.
Dans la deuxième partie, nous présentons un modèle de matérialisation
d’agrégats permettant de pallier les problèmes de stockage et de performance.
Enfin, nous analysons les apports de nos travaux, leurs limites et les
perspectives possibles.
34Chapitre 2
Etude bibliographique et
positionnement du problème
2.1 Les entrepôts de données
Immon [INM96] définit un entrepôt de données comme « une collection
de données orientées sujet, intégrées, non volatiles, historisées et organisées
pour le support d’un processus d’aide à la décision». L’objectif est d’extraire
des informations pertinentes de grandes masses de données collectées de
diverses sources de données hétérogènes. Contrairement aux bases de données
opérationnelles (OLTP), les entrepôts de données ne subissent pas de mises à
jour continues. L’essentiel des opérations sont des opérations de lecture
déclenchées par des requêtes complexes. Pour permettre l’analyse des
données, celles-ci sont consolidées [WU97]. Les entrepôts de données sont
souvent utilisés en combinaison avec les systèmes OLAP (On-Line Analytical
Processing) qui ont été définis par E.F. Codd en 1993 [COD93]. « OLAP est
une catégorie de logiciels qui permet aux analystes et aux dirigeants
d’exploiter les données à l’aide d’un accès rapide et interactif à une variété de
vues possibles sur les informations issues de données brutes » [VAS99].
L’architecture typique d’un entrepôt de données est illustrée par figure 1.
35Chapitre 2. Etude bibliographique et positionnement du problème
Figure 1: une architecture d’entrepôts de données classiques
2.1.1 Intégration des données dans l’entrepôt : les
outils back-end
La première phase de la construction d’un entrepôt consiste à intégrer les
données provenant de sources multiples et hétérogènes dans l’entrepôt. Ce
processus, appelé ETL (Extract, Transform and Load) se fait à l’aide d’outils
« back-end » [CHA97]. Les données sont extraites des sources et ensuite
nettoyées, transformées (calculs, filtres, tris, agrégation) et homogénéisées
(réconciliation syntaxique et sémantique), car il est important que les données
soient correctes et comparables pour servir aux prises de décisions.
2.1.2 Le modèle conceptuel : le modèle
multidimensionnel d’hypercube
Le modèle conceptuel doit faciliter la compréhension, l’écriture de
requêtes et l’optimisation des temps d’exécution. Le modèle utilisé pour
permettre ceci est le modèle multidimensionnel appelé aussi cube ou
hypercube [PED01]. Dans ce dernier, les sujets d’analyse sont appelés
mesures ou faits. Ce sont généralement des données numériques comme, par
exemple, le montant des ventes, le budget ou les revenus. Les faits dépendent
d’un ensemble de dimensions qui décrivent le contexte des faits et qui
représentent les axes d’analyse. Par exemple, les dimensions associées aux
faits de ventes peuvent être la localisation, la date et le produit. Les
dimensions peuvent avoir plusieurs niveaux hiérarchiques selon les différents
degrés d’agrégation permettant d’affiner ou d’élargir l’analyse. Ces opérations
sont appelées roll-up et drill-down. Ainsi, la dimension Date peut être
36Chapitre 2. Etude bibliographique et positionnement du problème
hiérarchisée en Jour, Semaine, Mois, Trimestre et Année, la dimension
Localisation en Magasin, Ville, Département et Région. On obtient alors le
schéma de la dimension (figure 2). Les membres d’une dimension
représentant les entités de la dimension considérée forment, avec les liens
hiérarchiques, l’instance de la dimension (figure 3). Ainsi, les membres de la
dimension Date au niveau Mois pourraient être Janvier, Mars, Juin.
Figure 2 : schéma d’une dimension Date
Figure 3 : instance d’une dimension Date
La sélection des données à différents niveaux de détail implique
l’agrégation des faits. Les agrégats sont calculés à l’aide de fonctions
d’agrégation classiques de l’algèbre relationnel à savoir le calcul du nombre
de faits (COUNT), la détermination des valeurs maximales et minimales (MIN
et MAX), le calcul de la somme (SUM) et de la moyenne (AVG) des valeurs.
Les entrepôts de données étant conçus pour maintenir un volume de données
très important, l’application des fonctions d’agrégation peut nécessiter dans
certains cas des temps de calcul inacceptables pour l’utilisateur. Pour remédier
à ce problème de performance, une technique très utilisée consiste à
précalculer certaines agrégations et à stocker ces données pour qu’il ne soit
plus nécessaire de les calculer à la volée [HAR96]. On parle alors de
matérialisation de vues.
37Chapitre 2. Etude bibliographique et positionnement du problème
2.1.3 Le modèle physique
Pour les modèles physiques soutenant OLAP, il existe deux approches
principales : ROLAP (Relational OLAP) qui utilise les technologies des bases
de données relationnelles et MOLAP (Multidimensional OLAP) qui utilise des
technologies propriétaires [PED01].
MOLAP stocke les données dans des structures multidimensionnelles
comme des tableaux multidimensionnels, étant ainsi l’image fidèle d’un cube
OLAP (figure 5). Dans ROLAP, les données sont organisées en schémas en
étoile (figure 4) ou en schéma en flocon [VAS99]. Le schéma en étoile
consiste en une table de faits et plusieurs tables dénormalisées. Pour chaque
dimension il existe une table dans laquelle se trouvent tous les niveaux
d’agrégations d’une dimension. Le schéma en flocon représente une version
normalisée du schéma en étoile dans laquelle chaque niveau d’agrégation
d’une dimension possède sa propre table de dimension.
Figure 4 : schéma en étoile
Figure 5 : exemple d’un cube
L’avantage principal de MOLAP consiste en une meilleure performance
pour les temps de réponse aux requêtes. Par contre, ROLAP est plus adapté
lorsque le modèle comporte un grand nombre de faits et s’avère plus flexible
38Chapitre 2. Etude bibliographique et positionnement du problème
en cas de redéfinitions des cubes. Les avantages des deux approches sont
combinés dans HOLAP (Hybrid OLAP) qui utilise les technologies MOLAP
pour stocker les données agrégées et les technologies ROLAP pour stocker les
données détaillées.
2.1.4 Interfaces: les outils front-end
Les outils « front-end » représentent l’interface entre l’utilisateur et le
système OLAP. Ils permettent aux utilisateurs de naviguer facilement et d’une
manière intuitive à travers les données. Le mode de présentation le plus utilisé
est le tableau multidimensionnel. Les outils front-end mettent à disposition un
certain nombre d’opérations pour la navigation à travers les données. Par
exemple, le « Pivoting » permet de changer une ligne correspondant à une
dimension en une colonne ou vice versa, le « Slice&Dice » permet de réduire
la dimensionnalité des données en projetant les données sur un sous-ensemble
de dimensions sélectionnées et le « Roll-up » et « Drill-Down » permettent la
navigation à travers les données en changeant de niveau hiérarchique.
Dans la plupart des applications, les dimensions et les faits sont
uniquement des données alphanumériques et c’est le seul type de données
autorisé par les outils d’entrepôts de données et OLAP existants. Or, dans le
monde OLTP, de plus en plus de données plus complexes comme des images,
du son, des vidéos, des cartes et des documents sont intégrés grâce au
développement de formats, de SGBD et de systèmes d’interfaces dédiés (SIG,
PACS,…). Le monde décisionnel doit pouvoir intégrer ce type de données et
fournir des supports adaptés à ces changements dans le monde OLTP.
2.2 La prise en compte de données complexes
dans les entrepôts
La majorité des travaux sur les données complexes dans le domaine des
entrepôts de données a été faite dans le cadre de la gestion de données
spatiales. Les systèmes OLAP spécialisés pour l’analyse de données spatiales
sont appelés Spatial OLAP (SOLAP). Les travaux réalisés jusqu’à présent
portant sur la prise en compte de données multimédia comme le signal, les
images, les vidéos, le son, etc. restent peu nombreux.
Les entrepôts de données SOLAP et les entrepôts de données multimédia
ont un point commun important : les données qu’ils maintiennent sont
39Vous pouvez aussi lire

















































