Désambiguïsation et alignement d'entités géographiques dans les textes scientifiques - INIST-CNRS - IRIT
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Désambiguïsation et alignement
d'entités géographiques
dans les textes scientifiques
Pascal Cuxac pascal.cuxac@inist.fr
INIST-CNRS
Vandœuvre lès Nancy
Séminaire IRIT - Toulouse 06 Mars 2019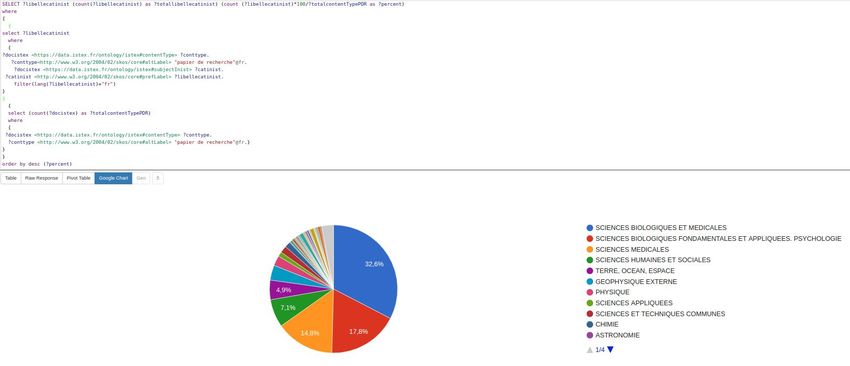
Paris ?
Athens ?
Séminaire IRIT - Toulouse 06 Mars 2019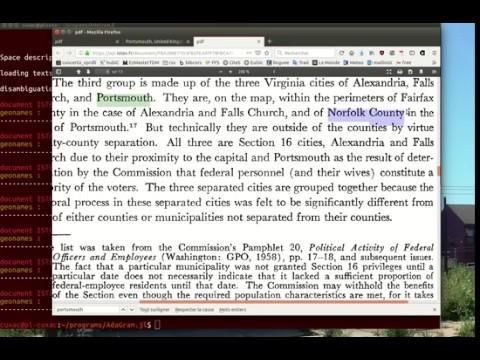
Contexte
ISTEX : Initiative d’Excellence en Information Scientifique et Technique
Offrir, à l’ensemble de la communauté de l’ESR, un accès en ligne aux collections rétrospectives
de la littérature scientifique dans toutes les disciplines (http://www.istex.fr).
➢ Un vaste programme d'acquisition de contenus électroniques pour les scientifiques
➢ 2 principaux objectifs:
○ Mettre en place un système permettant d'agréger toutes les données sous une forme
normalisée et enrichies en métadonnées
○ Pour des besoins documentaire et de fouille de textes.
Séminaire IRIT - Toulouse 06 Mars 2019
Contexte
ISTEX-RD : Intégrer dans les données ISTEX des enrichissements
complémentaires à partir du texte intégral et à l’aide d’outils ou méthodes issus de la
recherche pour les mettre à disposition d’autres projets.
4 axes de travail :
➢ identification des références citées et structuration,
➢ indexation automatique,
➢ reconnaissance d’entités nommées,
➢ catégorisation des documents.
Séminaire IRIT - Toulouse 06 Mars 2019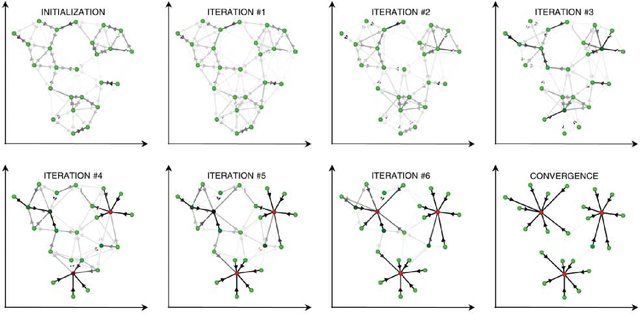
Contexte
ISTEX-RD :
➢ reconnaissance d’entités nommées :
○ en collaboration avec le LI de Tours
○ avec l’outil Unitex/CasSys
○ extraction de 8 types d’EN : nom de personnes / lieux / organisations / projets
financés / organismes hébergeur de ressources / url / dates / citations
placeName geogName
Séminaire IRIT - Toulouse 06 Mars 2019
Contexte
ISTEX-RD :
➢ reconnaissance d’entités nommées avec l’outil Unitex/CasSys
→ chaine de caractère isolée du contexte
Portsmouth
U.K. U.S.A.
Séminaire IRIT - Toulouse 06 Mars 2019
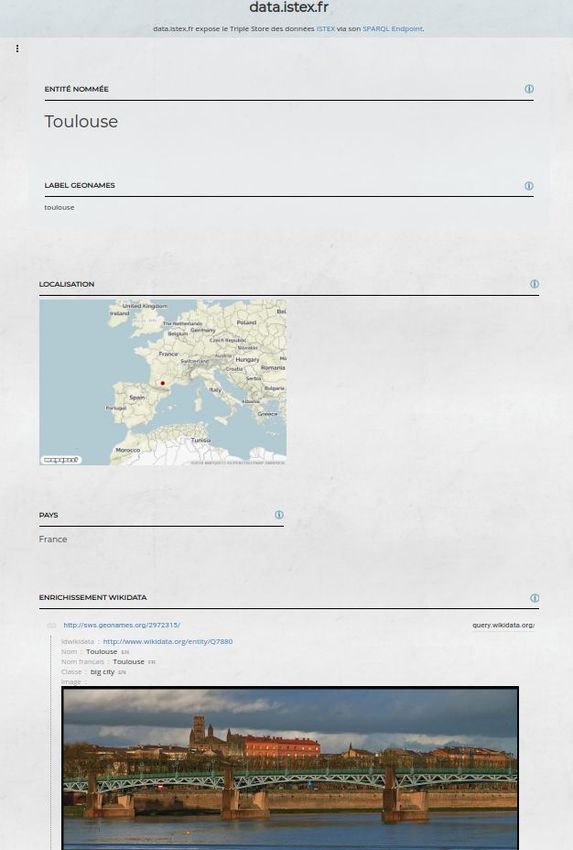
Projet ISTEX-LOD
DATA-ISTEX : exposition des données ISTEX produites et/ou transformées à
l'Inist selon les normes du web sémantique, modélisées via une ontologie dédiée.
data.istex.fr expose le Triple Store des données ISTEX données exportées en N-Quads et chargées dans un
via son SPARQL Endpoint triple store
https://data.istex.fr/ https://data.istex.fr/triplestore/sparql/
https://data.istex.fr/sparql/
Séminaire IRIT - Toulouse 06 Mars 2019
Projet ISTEX-LOD
DATA-ISTEX
- quelques chiffres : 10 263 903 documents
55 348 674 placeName
- alignement des placeName avec Geonames
- problèmes :
- une même entité peut avoir plusieurs orthographes
- une même entité peut correspondre à plusieurs
lieux différents (Paris, France / Paris, Texas)
→ désambiguïsation nécessaire
Séminaire IRIT - Toulouse 06 Mars 2019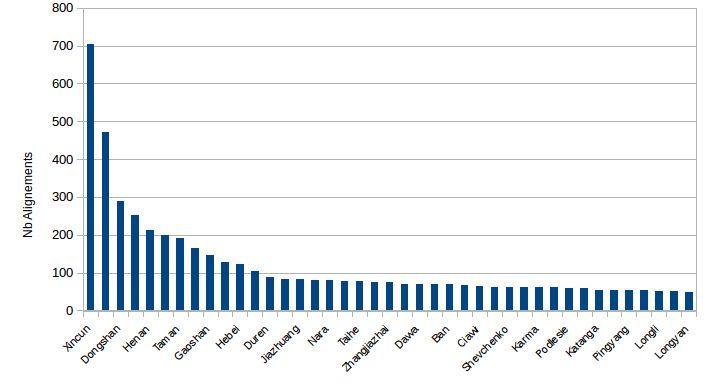
Graphies multiples
➢ Une même entité peut avoir plusieurs orthographes et/ou
peut comporter des erreurs (OCR/ fautes d’orthographe)
○ St Malo / Saint Malo
○ Vandoeuvre-Les-Nancy / Vandœuvre-Les-Nancy / Vandœuvre Lès Nancy
○ Maron / Marron
○ Cronenbourg / Kronenbourg
○ Lévignac sur Save / Lévignac
○ Colomiers / Colomier / Coloiniers
Séminaire IRIT - Toulouse 06 Mars 2019
Graphies multiples - Clustering
➢ Une méthode de clustering (classification non supervisée)
peut-elle résoudre ce problème ?
➢ Expérimentation :
■ Programme python :
● calcul de similarités entre entités
(Levenshtein / Jaccard / Hamming…)
● clustering par propagation d’affinité
Cabanes, Guénaël. (2010). Two-level Unsupervised
Clustering driven by neighborhood and density.
Séminaire IRIT - Toulouse 06 Mars 2019Graphies multiples - Clustering
➢ Un regroupement “d’écritures” à l’aide de clustering
○
○
nom du cluster
○
○ composition
○ du cluster
○
○
n° cluster ○
○
○
○
○
œ
○
○
○
○
○
Séminaire IRIT - Toulouse 06 Mars 2019Graphies multiples - Clustering
➢ Un regroupement “d’écritures” à l’aide de clustering
○ De bons résultats mais quelques problèmes :
■ tendance à la surestimation du nombre de classes
■ complexité de calcul quadratique
■ risque de regroupement de graphies proches correspondant à des lieux
différents
➢ Piste à suivre...
○ Utiliser une méthode “words embedding” ...
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation
➢ Une même entité peut correspondre à plusieurs lieux différents
(Paris, France / Paris, Texas)
➢ programme python utilisant la librairie “geopy”, permet d’interroger :
ArcGIS (USA) / Baidu Maps (Chine) / Bing Maps Locations (Microsoft) /
DataBC (Canada) / GeocodeFarm (Allemagne) / GeocoderDotUS (USA) /
GeoNames / Google Maps / IGN France GeoCoder OpenLS / LiveAddress de
SmartyStreets (USA) / NaviData (Canada) / OpenStreetMap / Open Cage
Data (UK) / OpenMapQuest / YahooPlaceFinder / Yandex (Russie) / …
MAIS...recherche d’une chaîne de caractères…!
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation
➢ Une même entité peut correspondre à plusieurs lieux différents
● Algeciras http://sws.geonames.org/3690160
● Algeciras http://sws.geonames.org/1731531
● Bordeaux http://sws.geonames.org/3031582
● Bordeaux http://sws.geonames.org/6420629
● Bordeaux http://sws.geonames.org/4795320
● Bordeaux City Of London None
● Cassio Bridge None
● Cassis http://sws.geonames.org/3028431
● Cassis http://sws.geonames.org/3728181
● Casson http://sws.geonames.org/3028428
● Chigaco http://sws.geonames.org/1049480
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
➢ La Représentation Continue des Données : les méthodes “Word2Vec”
○ Words embeddings (Word2Vec, Doc2Vec, FastText, Glove…) :
■ prendre en compte le contexte d’apparition des mots
■ utiliser de gros volumes de données
■ construire une représentation vectorielle “continue” (dense) des mots
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
➢ Word2Vec : == auto-encodeur
Efficient Implementation of Word Representations in Vector Space,
T. Mikolov, K. Chen, G. Corrado, and J. Dean, 2013. http://arxiv.org/pdf/1301.3781.pdf
Va permettre de passer de l’espace des mots à une représentation vectorielle continue. Nous
n'avons plus une matrice creuse mais bien une matrice pleine
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
➢ Fixer une fenêtre de prise en compte du contexte
➢ Fixer la dimension de la couche cachée (dimension des vecteurs de sortie)
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
➢ Words embeddings :
○ Réseau Neuronal avec 1 couche cachée,
○ En entrée : une description du contexte d’un mot,
○ En sortie : le mot qui apparaît dans ce contexte
(ou l’inverse),
○ Le système va "apprendre" (apprentissage non supervisé)
que certains mots sont prédits par les mêmes contextes,
○ C’est un réseau de neurones : on récupère à la fin
les pondérations de chaque mot avec la couche cachée,
○ On ne s’intéresse qu’à l’état du modèle prédictif, pas à sa capacité à prédire.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
➢ Words embeddings :
○ Avec cette représentation, les mots se regroupent par similarité de contexte qui
reflète à la fois une similarité syntaxique et une similarité sémantique,
○ On constate une forme d’additivité, par exemple la représentation la plus proche du
résultat du calcul [vMadrid−vSpain+vFrance ] est vParis,
○ Contrairement aux représentations BoW pondérées (TF-IDF), les représentations
Word2Vec sont d’assez faible dimension (par ex. 200 à 300) et denses,
○ Demande un apprentissage (non supervisé) sur la base de ressources textuelles très
volumineuses.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Words embeddings
Tout ceci permet donc de représenter des mots (ou des documents) dans un
espace et donc de calculer des distances entre eux (similarités) → les
mots/documents les plus similaires.
Mais quid de la désambiguïsation des mots ?
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
AdaGram :
Sergey Bartunov, Dmitry Kondrashkin, Anton Osokin, Dmitry Vetrov. Breaking Sticks
and Ambiguities with Adaptive Skip-gram. International Conference on Artificial
Intelligence and Statistics (AISTATS) 2016
Adaptation du modèle Skip-Gram : utilise une approche bayésienne non paramétrique
pour “apprendre” plusieurs prototypes associés à un terme.
Apprentissage non supervisé comme Word2Vec, avec en plus un paramètre fixant le
nombre de prototypes maximum.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
AdaGram : programme en Julia - Pourquoi Julia ?
- AdaGram - Programme en Julia : https://github.com/sbos/AdaGram.jl
“Julia has the performance of a statically compiled language while providing interactive
dynamic behavior and productivity like Python, LISP or Ruby.” in Bezanson, J., Karpinski,
S., Shah, V. B., & Edelman, A. (2012). Julia: A fast dynamic language for technical
computing.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
Alignement et Désambiguïsation :
➢ Alignement sur geonames et sélection de prototypes
➢ Désambiguïsation dans les documents
AdaGram EN Docs
(W2V + PlaceName
Inf.Bayes)
Istex
Prototypes
(Filtre proba) Alignements
automatiques
Corpus Modèle
Etiquetage
ISTEX AG
prototypes
+2eme filtrage
Désambiguïsation
Geonames
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
Exemple : Paris
➢ - Corpus d’apprentissage (full text ISTEX) → placeName Paris
➢ - AdaGram → 5 prototypes + seuil probabilités (dynamique) :
○ p1 île de france, tour eiffel, montmartre p=0.86
○ p2 dallas, désert, pétrole p=0.84
○ p3 blonde, mannequin, héritière p=0.78
○ p4 PMU, cheval, tiercé p=0.23
○ p5 psg, foot, quatar p=0.01
Seuil dynamique → rupture de pente
+ seuil fixe minimal
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
Exemple : Paris
➢ - AdaGram → 5 prototypes + seuil probabilités :
○ p1 île de france, saint denis, tour eiffel, montmartre p=0.86
○ p2 dallas, fort worth, houston, pétrole p=0.84
○ p3 blonde, mannequin, héritière p=0.78
➢ - Etiquetage “géo” avec geonames (à partir des 10 premiers termes contenus dans le
prototype) :
○ p1 France
○ p2 USA, Texas
○ p3 [ ]
➢ - Au final : 2 prototypes validés pour le corpus d’apprentissage utilisé et alignés avec
Geonames:
○ - Paris, France geonames.org/2988507
○ - Paris, USA geonames.org/4717560
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
Exemple : Paris
➢ - Désambiguïsation dans les textes :
○ 2 prototypes pour Paris dans le corpus d’apprentissage :
■ -p1 France
■ -p2 USA
➢ Pour une document donné Doc ISTEX12345678 (full text)
○ Probabilité de chaque prototype :
■ -p1 proba 0.90
■ -p2 proba 0.10
➢ => dans ce document Doc ISTEX12345678
○ Paris = Paris, France (prob =0.9) → geonames.org/2988507
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Démonstration
Exemple D’application :
➢ corpus de 400 000 documents (textes intégraux, format txt) issus d’ISTEX
➢ 5 prototypes demandés
➢ liste de 7 placeName (athens, carcassonne, montreal, annapolis, abbeville, lafayette, portsmouth)
➢ Apprentissage, sélection et labellisation des prototypes :
○ https://drive.google.com/open?id=1JzqZYlR4mKiCAAPRGn83RkMZeEl4ZLsE
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Démonstration
Exemple D’application :
➢ Désambiguïsation dans 7 documents (textes intégraux, format txt) issus d’ISTEX :
○ https://drive.google.com/open?id=1HwrHyG27-zPICuT174GOYX5Sa0l80usD
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Résultats
Exemple de Résultat :
➢ 41 PlaceNames nb alignements ⩾50 (max = 705 → XINCUN [Xincun == Nouveau village !])
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Résultats
Exemple de Résultat :
➢ Xincun
○ 705 alignements Geonames
○ 318 documents
○ 8 alignements dans le modèle appris
○ 1 alignement dans les documents ISTEX contenant Xincun comme EN-unitex
○ http://sws.geonames.org/1789159/
➢ un maximum de 4 alignements pour une même entité
➢ une désambiguïsation possible pour chaque document (en général 1 seul alignement par
document)
➢ Sur 6069 alignements à désambiguïser → il reste 152 alignements (550 placeNames)
➢ Suppression de termes qui ne sont pas des PN (francisco / highway / anne / velocity...)
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Évaluation
Campagne SemEval 2019 :
➢ SemEval (Évaluation sémantique)
est une série continue de campagnes d’évaluations
de systèmes d’analyse sémantique.
➢ Task 12 SemEval’19 :
Toponym Resolution in Scientific Papers
(https://competitions.codalab.org/competitions/19948)
○ Subtask 1: Toponym detection
○ Subtask 2: Toponym disambiguation
○ Subtask 3: end-to-end, toponym resolution
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Évaluation
Campagne SemEval 2019 Pourquoi ?
➢ Avoir un corpus étiqueté internationalement reconnu pour l’évaluation.
➢ Corriger et adapter l’approche proposée
➢ S’évaluer à partir de ce corpus
➢ Éventuellement se positionner par rapport aux participants
➢ remarque : notre approche étant non supervisée les corpus d’apprentissage peuvent être
utilisés pour évaluer/corriger la méthode.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Évaluation
Campagne SemEval 2019 -Premiers résultats :
Fmes
corpus test “échantillon” 0.85
corpus “training” 0.83
Gagnant de la task 2 : DM_NLP Fmes= 0.823
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Évaluation
Mais dans les non alignés problème de niveau administratif : exemple Nancy
http://www.geonames.org/2990999/→ PPLA2
http://www.geonames.org/6454307/→ ADM4
http://www.geonames.org/2990998/→ ADM3
…
Mais si on ne tient compte que de la géographie, càd des coordonnées géographiques
de l’entité ?
48.68, 6.18 / 48.69, 6.18 / 48.67, 6.17
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Évaluation
Si on ne tient compte que des coordonnées géographiques de l’entité ?
→ désambiguïsation/alignement/extraction des coordonnées géographiques
→ comparaison avec coordonnées géographiques de l’entité alignée par l’expert
Micro F
Alignement “Administratif” 0.83
Alignement “géographique” 0.946
Séminaire IRIT - Toulouse 06 Mars 2019Bilan
Quels sont les avantages ?
➢ Apprentissage non supervisé...pas de taggage,
➢ Application sur placeName mais potentiellement utilisable sur d’autres types de
données (ex : Apple / Rock…)
➢ Peut désambiguïser dans un texte global mais également dans un paragraphe
ou même une phrase,
Séminaire IRIT - Toulouse 06 Mars 2019Bilan
Désambiguïsation d’une EN dans une phrase, un (des) paragraphe(s), un
document...
disambiguate(vm,dict,"athens",split ("reflects a 70% budget allocation for the
Athens center consulting services"))
3-element Array{Float64,1}:
0.259825
0.702366 → “georgia”
0.0378085
Séminaire IRIT - Toulouse 06 Mars 2019Bilan
Quels sont les inconvénients ?
➢ Nécessité d’un corpus apprentissage volumineux (volume/représentativité),
mais non étiqueté
➢ Capacité de calcul (+ CPU ... + rapidité)
➢ Capacité de stockage (corpus d’apprentissage, modèle…)
À faire :
➢ Apprendre sur un corpus possédant TOUS les PN extraits
….ou….
➢ Apprendre sur TOUT ISTEX
Séminaire IRIT - Toulouse 06 Mars 2019Merci !
Merci de votre attention...
Quelques liens :
Data.istex :
https://data.istex.fr/ https://data.istex.fr/sparql/
https://data.istex.fr/triplestore/sparql
Julia
https://julialang.org/
AdaGram
https://github.com/sbos/AdaGram.jl
Word2vec
https://github.com/tmikolov/word2vec
Séminaire IRIT - Toulouse 06 Mars 2019Bibliographie sommaire (1)
Badieh Habib Morgan, M., & van Keulen, M. (2013). Named Entity Extraction and Disambiguation: The Missing Link. In Proceedings of
the Sixth International Workshop on Exploiting Semantic Annotations in Information Retrieval (p. 37–40). New York, NY, USA:
ACM. https://doi.org/10.1145/2513204.2513217
Bartunov, S., Kondrashkin, D., Osokin, A., & Vetrov, D. (2016). Breaking Sticks and Ambiguities with Adaptive Skip-gram. In
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS) (p. 130–138). Cadiz, Spain.
Consulté à l’adresse https://hal.archives-ouvertes.fr/hal-01404056
Bensalem, I., & Kholladi, M.-K. (2009). La désambiguïsation des toponymes par la densité géographique. In International Conference
on Applied Informatics (ICAI’09).
Bougriou, N., & Milat, S. (2016). Désambiguïsation des toponymes guidée par des ressources géographiques (thesis). Université
Abdelhamid Mehri Constantine 2, Constantine. Consulté à l’adresse http://agritrop.cirad.fr/581372/
Chen, X., Liu, Z., & Sun, M. (2014). A Unified Model for Word Sense Representation and Disambiguation. In Proceedings of the 2014
Conference on Empirical Methods in Natural Language Processing (EMNLP) (p. 1025–1035). Doha, Qatar: Association for
Computational Linguistics. https://doi.org/10.3115/v1/D14-1110
Chihaoui, A., Bouhafs, A., Roche, M., & Teisseire, M. (2018). Désambiguïsation des entités spatiales par apprentissage actif. Revue
Internationale de Géomatique, 28(2), 163‑189. https://doi.org/10.3166/rig.2018.00053
Habib, M. B., & van Keulen, M. (2011). Named entity extraction and disambiguation: The reinforcement effect. Proc. of MUD, 2011.
Séminaire IRIT - Toulouse 06 Mars 2019Bibliographie sommaire (2)
Heino, E., Tamper, M., Mäkelä, E., Leskinen, P., Ikkala, E., Tuominen, J., … Hyvönen, E. (2017). Named entity linking in a complex
domain: Case second world war history. In International Conference on Language, Data and Knowledge (p. 120–133). Springer.
Iacobacci, I., Pilehvar, M. T., & Navigli, R. (2016). Embeddings for Word Sense Disambiguation: An Evaluation Study. Proceedings of
the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1, 897‑907.
https://doi.org/10.18653/v1/P16-1085
Karl, J. W. (2018). Mining location information from life- and earth-sciences studies to facilitate knowledge discovery. Journal of
Librarianship and Information Science, 0961000618759413. https://doi.org/10.1177/0961000618759413
Kejriwal, M., & Szekely, P. (2017). Neural embeddings for populated geonames locations. In International Semantic Web Conference
(p. 139–146). Springer.
Martineau, C., Tolone, E., & Voyatzi, S. (2007). Les Entités Nommées : usage et degrés de précision et de désambiguïsation. In
26ème Colloque international sur le Lexique et la Grammaire (LGC’07) (p. pages 105-112). Bonifacio, France. Consulté à
l’adresse https://hal.archives-ouvertes.fr/hal-00461891
Neelakantan, A., Shankar, J., Passos, A., & McCallum, A. (2014). Efficient Non-parametric Estimation of Multiple Embeddings per
Word in Vector Space. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP)
(p. 1059–1069). Doha, Qatar: Association for Computational Linguistics. https://doi.org/10.3115/v1/D14-1113
Séminaire IRIT - Toulouse 06 Mars 2019Graphies multiples - Clustering
➢ Clustering par propagation d’affinité
Algorithme itératif reposant sur le partage des « affinités » :
➔ Chaque élément c repère dans son voisinage un élément qui lui ressemble suffisamment, et augmente son affinité pour
cet élément ;
Les étapes suivantes consistent à « propager » cette affinité :
➔ Chaque élément c repère celui pour qui il a la plus grand affinité, noté m ;
➔ Il ajoute à ses propres affinités celles de m ;
➔ Cette étape est répétée un certain nombre de fois, jusqu'à ce que le nombre d'éléments passe en dessous d'un certain
seuil (ou quand il n’y a plus aucun changement).
Il y a alors trois cas :
➔ L'élément considéré possède une affinité maximale pour un autre élément : il lui ressemble ;
➔ L'élément considéré possède une affinité maximale pour lui-même : il est « exemplaire » ;
➔ L'élément considéré possède une affinité nulle : il est « isolé ».
On obtient à l'issue de l'algorithme un graphe où tous les éléments identifiés comme semblables sont reliés.
Mezard, Marc. (2007). Computer science. Where are the exemplars?. Science (New York, N.Y.). 315. 949-51. 10.1126/science.1139678.
Séminaire IRIT - Toulouse 06 Mars 2019Désambiguïsation - Méthodologie
AdaGram - Programme en Julia : https://github.com/sbos/AdaGram.jl
Séminaire IRIT - Toulouse 06 Mars 2019Vous pouvez aussi lire

















































