DET4J D eveloppement Java d'un outil de visualisation de courbes de performance biom etriques
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
DET4J
Développement Java d’un outil de
visualisation de courbes de
performance biométriques
Christophe Gisler1
11 août 2006
Département d’Informatique
Rapport de Travail de Bachelor
Department of Informatics - Departement für Informatik • Université de Fribourg - University of
Fribourg - Universität Freiburg • Boulevard de Pérolles 90 • 1700 Fribourg • Switzerland
phone +41 (26) 300 84 65 fax +41 (26) 300 97 31 Diuf-secr-pe@unifr.ch http://diuf.unifr.ch
1
christophe.gisler@unifr.ch, Groupe DIVA, DIUF, Université de Fribourg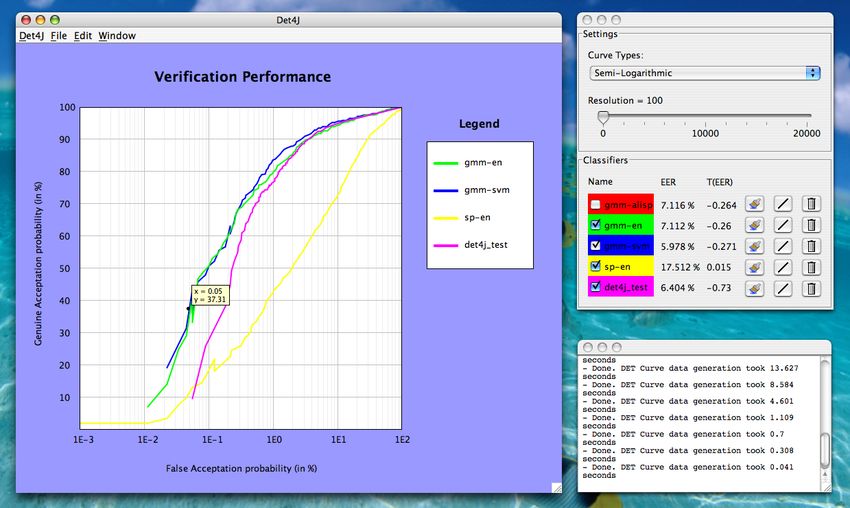
Table des matières
1 Introduction 1
2 But du projet 1
3 Bases théoriques 2
3.1 Définition de la biométrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
3.2 Evaluation des systèmes biométriques . . . . . . . . . . . . . . . . . . . . . . . . . 2
3.2.1 Qu’est-ce qu’un système biométrique ? . . . . . . . . . . . . . . . . . . . . . 2
3.2.2 Que mesure un système biométrique ? . . . . . . . . . . . . . . . . . . . . . 3
3.2.3 Les taux d’erreur et leur utilité . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.3 Différents types de courbes de performance . . . . . . . . . . . . . . . . . . . . . . 5
3.3.1 Courbe T-FA/T-FR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.3.2 Courbe ROC (Receiver Operating Characteristic) . . . . . . . . . . . . . . . 6
3.3.3 Courbe DET (Detection Error Tradeoff) . . . . . . . . . . . . . . . . . . . . 7
3.3.4 Courbe semi-logarithmique . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.3.5 Courbe de coût (Cost) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.4 Le format de fichier Ragga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.4.1 Définition du format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.4.2 Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.4.3 Description de quelques éléments importants . . . . . . . . . . . . . . . . . 9
4 Méthodologie et design 11
4.1 Management du projet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.1.1 Meetings et méthode de travail . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.1.2 Subversion (SVN) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.1.3 Présentations et rapport final . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.2 Choix technologiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.2.1 Langage de programmation . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.2.2 Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.2.3 GUI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.3 Architecture du programme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.3.1 biosecure.det4j . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.3.2 biosecure.det4j.model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.3.3 biosecure.det4j.parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.4 Description du GUI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 Travail effectué et résultat 16
5.1 Fonctionnalités du programme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5.2 Rédaction de la Javadoc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.3 Packages utilisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.3.1 Xerces et JDOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.3.2 VectorGraphics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.4 Evaluation du programme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4.1 Justesse et fiabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4.2 Robustesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4.3 Améliorations potentielles futures . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5 Résultat et courbes de performance . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
6 Apports personnels 24
6.1 Outils informatiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.2 Méthodologies informatiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.3 Contenu scientifique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.4 Gestion du projet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
7 Conclusion 24
i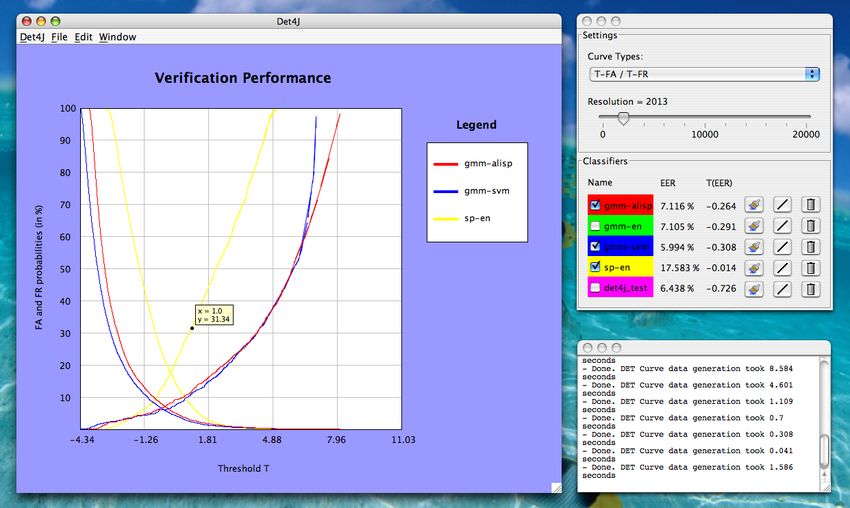
A Guide de l’utilisateur 26
A.1 La fenêtre principale “Det4J” et sa barre de menus . . . . . . . . . . . . . . . . . . 26
A.1.1 Le menu “Det4J” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
A.1.2 Le menu “File” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
A.1.3 Le menu “Edit” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
A.1.4 Le menu “Window” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
A.2 La fenêtre des réglages (Settings) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
A.2.1 Le compartiment “Settings” . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
A.2.2 Le compartiment “Cost” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
A.2.3 Le compartiment “Classifiers” . . . . . . . . . . . . . . . . . . . . . . . . . . 29
A.3 La fenêtre de la console . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
ii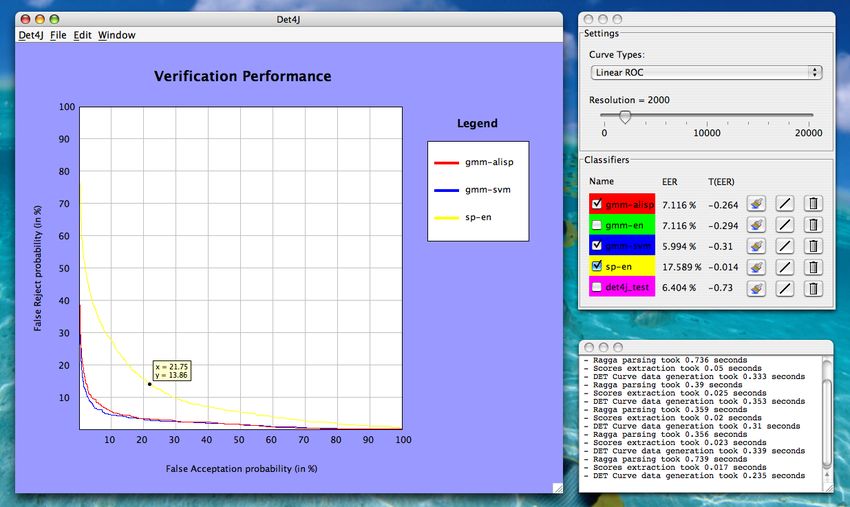
Table des figures
1 Composants d’un système biométrique . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Exemple de graphe T-FA/T-FR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 Exemple de courbe T-FA/T-FR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4 Exemple de courbe ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
5 Exemple de courbe DET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
6 Exemple de courbe semi-logarithmique . . . . . . . . . . . . . . . . . . . . . . . . . 8
7 Exemple de courbe de coût . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
8 Exemple de contenu d’un fichier Ragga . . . . . . . . . . . . . . . . . . . . . . . . . 10
9 Structure d’un classifier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
10 Déroulement d’un projet selon la méthode eXtreme Programming . . . . . . . . . . 12
11 Aperçu du GUI de l’application DET4J . . . . . . . . . . . . . . . . . . . . . . . . 15
12 Architecture du package VectorGraphics . . . . . . . . . . . . . . . . . . . . . . . . 19
13 Représentation de courbes T-FA/T-FR dans Det4J . . . . . . . . . . . . . . . . . . 21
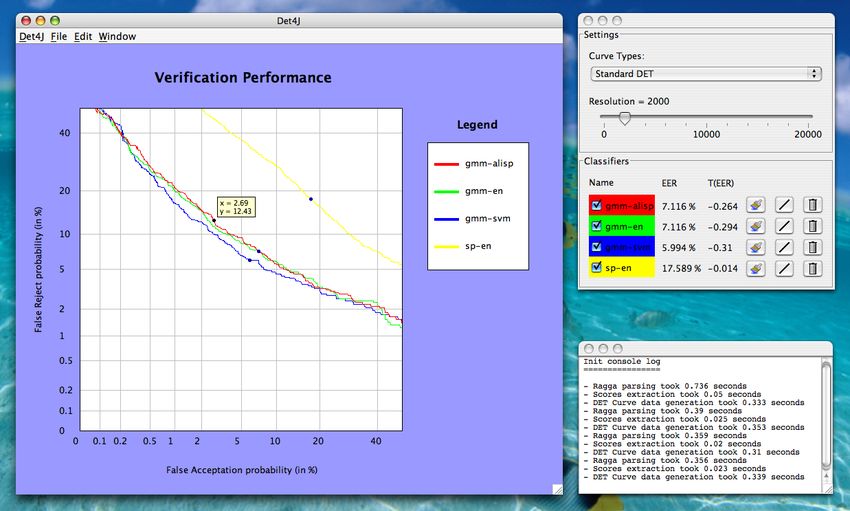
14 Représentation de courbes ROC dans Det4J . . . . . . . . . . . . . . . . . . . . . . 22
15 Représentation de courbes DET dans Det4J . . . . . . . . . . . . . . . . . . . . . . 22
16 Représentation de courbes semi-logarithmiques dans Det4J . . . . . . . . . . . . . 23
17 Représentation de courbes de coût dans Det4J . . . . . . . . . . . . . . . . . . . . 23
18 La fenêtre principale “Det4J” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
19 Le menu “Det4J” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
20 Les formats d’exportation disponibles . . . . . . . . . . . . . . . . . . . . . . . . . 27
21 Le menu “File” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
22 Le menu “Edit” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
23 Le menu “Window” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
24 La fenêtre des réglages (Settings) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
25 Les fenêtres permettant de changer la couleur, l’épaisseur et le type de trait d’une
courbe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
26 La fenêtre de la console . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
iii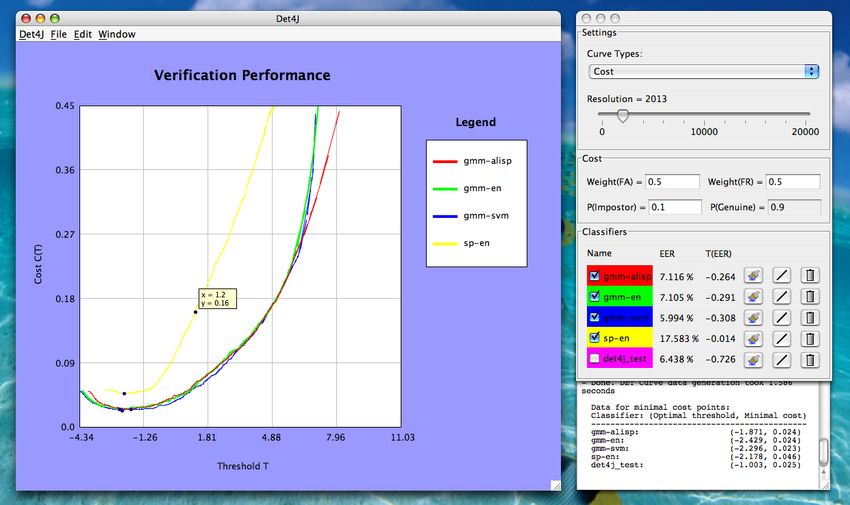
1 INTRODUCTION 1
1 Introduction
Depuis toujours, les humains se reconnaissent entre eux à leurs caractéristiques physiques et
comportementales. Nous reconnaissons nos semblables à leurs visages quand nous les rencontrons
ou à leurs voix quand nous leur parlons.
Jusqu’à présent, la vérification d’identité (authentification) dans les systèmes informatiques a
toujours été basée sur un objet que tout un chacun doit avoir sur lui (clé, carte à puce ou carte
magnétique). Malheureusement, ce genre d’objet à tendance à être perdu, voire volé.
Pour atteindre une vérification ou une identification plus fiable, l’être humain doit utiliser
un moyen qui caractérise réellement sa personne. La biométrie cherche à offrir des méthodes au-
tomatiques d’identification ou de vérification d’identité qui s’appuient sur les mesures des ca-
ractéristiques physiques ou comportementales, comme les empreintes digitales ou la signature vo-
cale. Ces caractéristiques devraient être uniques et non falsifiables. Hélas, il est souvent possible de
créer une copie qui sera acceptée par le système biométrique comme étant un échantillon véritable
[3].
Les systèmes biométriques qui vérifient automatiquement l’identité d’une personne peuvent
faire deux types d’erreurs. Il y a les erreurs de faux rejet (FR) lorsque le système refuse l’accès à
un vrai utilisateur (accès vrai) et les erreurs de fausse acceptation (FA) lorsque le système accorde
l’accès à un imposteur (accès imposteur). La décision d’accepter ou de rejeter un utilisateur se
prend en comparant les données d’un nouvel accès avec le template de l’utilisateur. La comparai-
son donne un score dit de vraisemblance. Lorsque le score est en dessous d’un seuil de sécurité (ou
seuil de rejet), le système décide de rejeter l’utilisateur. Lorsque le score est au-dessus de ce seuil,
l’utilisateur est accepté.
En fonction de la valeur du seuil de rejet, le système fait plus ou moins d’erreurs de faux
rejet ou de fausse acceptation. Si le seuil est très grand, il y aura beaucoup de faux rejets et peu
de fausses acceptations. Si le seuil est très petit, il y aura peu de faux rejets mais beaucoup de
fausses acceptations. A chaque valeur de seuil correspondent un taux de FR et un taux de FA, et
il est donc possible de dessiner une courbe de performance qui est paramétrée en fonction du seuil.
Généralement, ces courbes reprennent en abscisse le taux de FA et en ordonnée le taux de FR. Ces
courbes sont classiquement nommées les courbes de détection (DET curves) car une vérification
biométrique est en fait un problème classique de “détection” d’événements [1].
2 But du projet
Le but de ce projet de Bachelor était d’implémenter en JAVA un outil de visualisation de
courbes de performance biométriques de divers types (cf. §3.3). En entrée, l’outil devait prendre un
fichier XML contenant des scores de vraisemblance pour des accès vrais et des accès imposteurs.
En sortie, l’outil devait permettre une visualisation directe de la courbe de performance. Les prin-
cipales fonctionnalités à développer étaient les suivantes :
– Possibilité de visualiser jusqu’à 4 courbes de performance sur le même graphique ;
– Possibilité de visualiser jusqu’à 5 types de courbes différents ;
– Possibilité de charger ou de supprimer ces courbes ;
– Visualisation de divers points importants (equal error rate, minimal cost) ;
– Possibilité d’exporter les courbes sous différents formats graphiques ;
– Possibilité d’interagir avec le graphique, au moyen de la souris, pour effectuer diverses actions.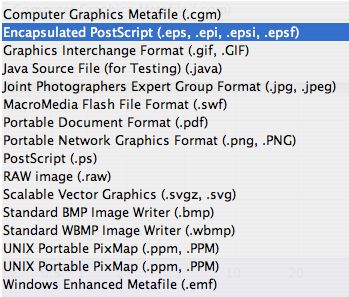
3 BASES THÉORIQUES 2
3 Bases théoriques
3.1 Définition de la biométrie
La biométrie vise l’élaboration de techniques d’identification automatique des humains. Cer-
taines biométries utilisent des caractéristiques physiques comme l’iris, les empreintes digitales ou
la forme du visage. D’autres biométries se basent sur des caractéristiques comportementales des
individus comme l’écriture ou le signal de la parole.
3.2 Evaluation des systèmes biométriques
3.2.1 Qu’est-ce qu’un système biométrique ?
Un système biométrique possède quatre composants principaux [2] :
1. Un module de senseurs (sensor module) qui acquiert les données biométriques d’un indi-
vidu. Par exemple, un senseur qui capture les empreintes digitales ;
2. Un module d’extraction des caractéristiques (feature extraction module) qui traite les
données acquises par le précédent module pour en extraire des valeurs caractéristiques, comme
la position et l’orientation de points précis de l’image de l’empreinte digitale ;
3. Un module de comparaison (matching module) dans lequel les valeurs caractéristiques
extraites par le précédent module sont comparées avec celles du profil de l’utilisateur (user’s
master template) dans la base de données pour générer un score S, dit score de concordance
(matching score). Par exemple, dans le cas des empreintes digitales, le nombre de points
concordants, entre l’image de l’empreinte de la requête et celle du template, va être calculé
pour retourner un score de concordance ;
4. Un module de décision (decision-making module) qui va décider d’accepter ou de rejeter
l’utilsateur en comparant le score de concordance généré par le module précédent avec un
seuil de sécurité T (security threshold ) donné. Dans le cas où S ≥ T , l’individu sera accepté,
et dans le cas contraire, si S < T , il sera rejeté.
ID Claim
Biometric
Database
Data
User's
Sensor master
template
Module Threshold T
Biometric
Sample
Biometric Matching
Feature Features Matching Score S Decision Accept if S ≥ T
Extraction Module Module Reject if S < T
Fig. 1 – Composants d’un système biométrique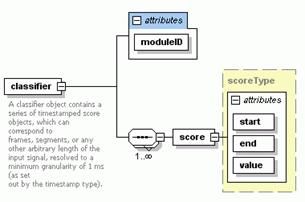
3 BASES THÉORIQUES 3
Le schéma de la figure 1 illustre bien les relations entre ces différents composants. La flèche
portant le label “ID Claim” n’apparaı̂t que dans le cas de vérification d’identité et pas dans celui
d’identification (voir ci-dessous), c’est la raison pour laquelle elle est en pointillé.
Les systèmes biométriques peuvent être utilisés dans deux modes différents :
– La vérification de personnes ;
– L’identification de personnes.
On parle de vérification d’identité lorsqu’une personne clame être déjà enrôlée dans le système
biométrique (et posséderait donc une ID-card ou un login name). Dans ce cas, les données biométriques
obtenues de cette personne sont comparées avec son template d’utilisateur qui est enregistré dans
la base de données.
On parle d’identification quand l’identité de l’utilisateur est à priori inconnue. Dans ce cas,
les données biométriques de l’utilisateur sont comparées aux templates de tous les utilisateurs en-
registrés dans la base de données du système biométrique, car l’utilisateur pourrait être n’importe
lequel (sinon aucun) d’entre eux.
Il est évident que l’identification de personnes est techniquement beaucoup plus compliquée et
beaucoup plus coûteuse, et le taux d’exactitude de l’identification diminue généralement quand la
grandeur de la base de données augmente.
Afin qu’une personne puisse être vérifiée ou identifiée avec succès par le système biométrique, elle
doit s’être fait préalablement enregistrer dans le système, c’est-à-dire que ses données biométriques
ont dû être enregistrées, traitées et stoquées. Comme la qualité de ces données biométriques
stoquées est cruciale pour les futures authentifications, il y a souvent plusieurs échantillons biométri-
ques (biometric samples) qui sont utilisés pour créer le profil maı̂tre de l’utilisateur (user’s
master template). Ce processus d’enregistrement d’un nouvel utilisateur est appelé l’enrôlement
(enrollment).
3.2.2 Que mesure un système biométrique ?
La différence la plus significative entre la biométrie et les technologies traditionnelles se situe
dans la réponse d’un système biométrique à une requête de vérification ou d’identification. De tels
systèmes ne peuvent pas répondre simplement par oui ou non, comme le ferait un système tradi-
tionnel en vérifiant que le code PIN d’une carte banquaire correspond bien à une séquence donnée
telle que “1234”. Aucun système biométrique ne peut vérifier l’identité ou identifier une personne
avec une certitude absolue. Par certitude absolue, on entend une probabilité de vérification stric-
tement égale à 1. La signature d’une personne n’est jamais deux fois identique, tout comme la
position du doigt sur un lecteur d’empreintes digitales n’est jamais deux fois la même. C’est la rai-
son pour laquelle on ne peut qu’essayer de mesurer les similitudes entre les données biométriques
du protagoniste et celles de son profil qui est stocké dans la bases de données. Ainsi, le système
biométrique retourne la probabilité que ces deux échantillons biométiques proviennent de la même
personne.
Les systèmes biométriques peuvent être divisés en deux catégories selon ce qu’ils mesurent :
– Les systèmes basés sur les caractéristiques physiques de l’individu (comme les empreintes
digitales , l’aspect de l’iris ou de la rétine, la morphologie de la main, du doigt ou du visage) ;
– Les systèmes basés sur les caractéristiques comportementales de l’individu (comme la
reconnaissance vocale ou la dynamique de la signature manuscrite ou des frappes au clavier).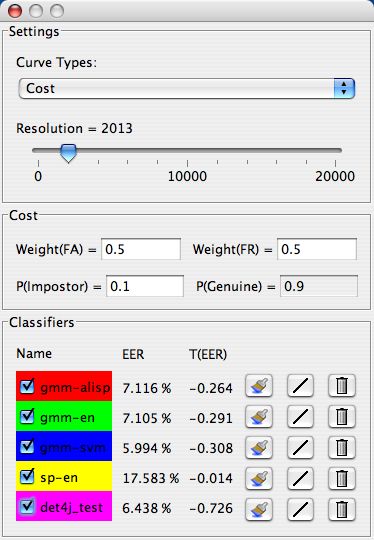
3 BASES THÉORIQUES 4
Les systèmes biométriques de la première catégorie sont généralement plus fiables et plus précis,
car les caractéristiques physiques sont plus facilement reproductibles et ne sont souvent pas affectées
par les conditions mentales de la personne au moment de l’enrôlement.
Si l’on construisait un système requérant 100% de concordance à chaque fois, alors évidemment
ce système serait pratiquement inutilisable, puisque seulement une petite minorité des utilisateurs
(et encore) pourrait l’utiliser. La plupart d’entre eux serait rejetée à chaque tentative, comme les
résultats des mesures ne seraient jamais les mêmes.
Ainsi, il faut tenir compte de la variabilité des données biométriques, car il n’est pas tolérable
qu’un système biométrique rejète trop souvent les véritables utilisateurs. Cependant, plus la varia-
bilité tolérée sera grande, plus la probabilité qu’un imposteur possédant des données biométriques
similaires soit accepté sera grande.
3.2.3 Les taux d’erreur et leur utilité
Un système biométrique peut faire deux types d’erreurs :
– Une erreur de faux rejet (ou erreur de type 1), qui survient lorsqu’un utilisateur légitime
est faussement rejeté, parce que le système trouve que ses données biométriques ne sont pas
suffisamment similaires à celles du profil maı̂tre (master template) de la base de données ;
– Une erreur de fausse acceptation (ou erreur de type 2), qui survient quand un imposteur
est malencontreusement accepté en tant qu’utilisateur légitime, parce que le système trouve
que ses données biométriques sont suffisamment similaires à celles du profil maı̂tre de la base
de données.
Dans un système idéal, il n’y a pas de faux rejet et de fausse acceptation. Dans un système
réel cependant, leur nombre n’est pas nul et peut prendre des valeurs non négligeables lorsque les
modalités et conditions d’utilisation augmentent la variabilité des données. Les taux de faux rejet
et de fausse acceptation dépendent du seuil de sécurité T . Plus la valeur du seuil sera grande, plus
il y aura de faux rejets et moins de fausses acceptations, et inversément, plus la valeur du seuil
sera petite, moins il y aura de faux rejets et plus de fausses acceptations. Le nombre de faux rejets
et celui de fausses acceptations sont inversément proportionnels. Le choix de la valeur de seuil
T (pour threshold ) à utiliser dépend principalement de la finalité du système biométrique. Cette
valeur est choisie de manière à faire un compromis adéquat entre la sécurité et l’utilisabilité du
système. Par exemple, un système biométrique aux portes d’un parc d’attraction comme Disney-
land appliquera typiquement un seuil beaucoup plus petit qu’un système biométrique aux portes
des quartiers généraux de la NSA.
Le nombre de faux rejets (resp. de fausses acceptations) est habituellement exprimé en un
pourcentage par rapport au nombre total de tentatives d’accès autorisés (resp. non autorisés). Ces
taux sont appelés taux de faux rejet (false reject rate, abrégé par FRR) et taux de fausse
acceptation (false acceptation rate, abrégé par FAR) et sont donc liés à une certaine valeur de
seuil T .
Certains appareils biométriques (ou les logiciels les accompagnant) prennent le seuil de sécurité
désiré comme paramètre du processus de décision. Les autres appareils biométriques retournent un
score S (borné) sur la base duquel la décision d’accepter ou de rejeter l’utilisateur va être prise
par l’application elle-même. En général, si le score S est plus grand ou égal au seuil T , l’utilisateur
va être accepté et, si le score est plus petit, il sera rejeté.
Dans le cas où le dispositif biométrique retourne un score, on peut générer un graphe indiquant
la dépendance des taux de fausse acceptation (FAR) et de faux rejets (FRR) au seuil (T ). La figure
2 montre un exemple d’un tel graphe, qu’on appelle graphe T-FA/T-FR.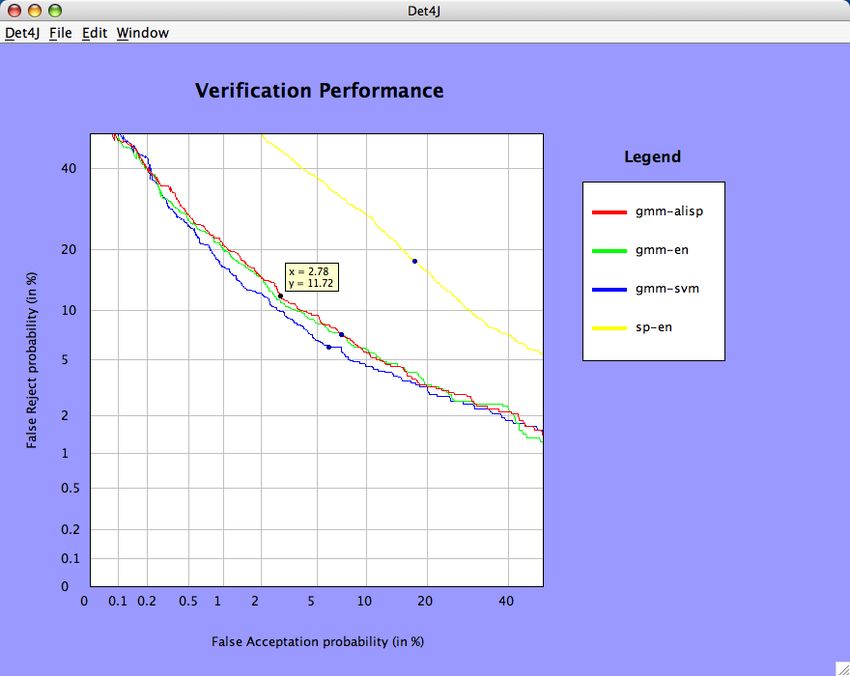
3 BASES THÉORIQUES 5
Fig. 2 – Exemple de graphe T-FA/T-FR
Les courbes des FAR et FRR se coupent en un point où les taux de fausse acceptation et de faux
rejet sont égaux ; la valeur en ce point est appélée equal error rate (EER) ou aussi crossover
accuracy. Cette valeur n’a presque pas d’utilité pratique car on ne souhaite généralement pas que
le FAR et le FRR soient les mêmes, mais elle constitue un bon indicateur de la précision du dispositif
biométrique. Par exemple, si l’on a deux appareils avec des equal error rates de 1% et 10%, on sait
alors que le premier est plus précis (i.e. qu’il fait moins d’erreurs) que le second. Pourtant, de telles
comparaisons ne sont pas aussi simples en réalité. D’une part, les valeurs fournies par les fabricants
sont incomparables parce que ces derniers ne publient habituellement pas les conditions exactes de
leurs tests, et d’autre part, même s’ils le font, les tests dépendent vraiment du comportement des
utilisateurs et d’autres influences extérieures, telles que la qualité des senseurs ou l’utilisation de
ceux-ci.
3.3 Différents types de courbes de performance
Il a été vu au paragraphe précédent que les performances d’un système biométrique peuvent
être mesurées en reportant ses taux de fausse acceptation (FAR) et de faux rejet (FRR) pour
différentes valeurs de seuil (threshold T ). A partir de ce triplet (T, F AR, F RR), diverses courbes
de performance peuvent être calculées et tracées. Celles qui sont décrites ci-dessous sont les plus
prépondérantes dans la recherche sur la biométrie et leurs modèles ont été implémentés dans le
projet DET4J.
3.3.1 Courbe T-FA/T-FR
La représentation de ce type de courbe est la plus simple à comprendre (voir figure 3). On fait
varier la valeur du seuil (threshold T ) sur l’axe des abscisses et les taux de fausse acceptation (FAR
in % ) et de faux rejet (FRR in % ) sur l’axe des ordonnées, ce qui donne au final deux courbes
qui se coupent au point de l’equal error rate (FRR et FRR égaux). Quand la valeur du seuil est
petite, les taux respectifs de faux rejet et de fausse acceptation sont l’un petit et l’autre grand, et
inversément quand la valeur du seuil est grande.
3 BASES THÉORIQUES 6
Fig. 3 – Exemple de courbe T-FA/T-FR
3.3.2 Courbe ROC (Receiver Operating Characteristic)
Pour obtenir ce type de courbe (représenté à la figure 4), on fait varier intrinsèquement la valeur
du seuil (threshold T ) et les points de l’unique courbe obtenue sont alors constitués des taux de
fausse acceptation (FAR in % ) et de faux rejet (FRR in % ) resp. en abscisses et en ordonnées.
L’échelle est linéaire. L’equal error rate (EER) est obtenu à l’intersection de la courbe et de la
diagonale partant de (0, 0) et arrivant en (100, 100). Les avantages de ce type de courbe sont que
l’on obtient une représentation compacte des performances d’un système biométrique au travers
d’une seule courbe, et que l’on peut ainsi comparer des systèmes biométriques différents (la courbe
la plus proche du coin inférieur gauche est la meilleure).
Fig. 4 – Exemple de courbe ROC3 BASES THÉORIQUES 7
3.3.3 Courbe DET (Detection Error Tradeoff )
Une courbe DET n’est par essence qu’une courbe ROC dont on a remplacé l’échelle linéaire par
une échelle basée sur une distribution normale1 [1] pour la rendre plus lisible et plus exploitable
(voir la figure 5). Comme les scores de vraisemblance se distribuent généralement selon une loi
normale, la courbe de performance s’aplatit et tend vers une droite. Les avantages des courbes
DET sont les mêmes que ceux des courbes ROC, mais elles permettent en plus de comparer des
systèmes biométriques qui ont des performances similaires.
Fig. 5 – Exemple de courbe DET
3.3.4 Courbe semi-logarithmique
À l’instar de la courbe DET, la courbe semi-logarithmique est une courbe ROC dont on a modifié
l’échelle (linéaire). L’échelle de l’axe des abscisses est simplement remplacée par une échelle semi-
logarithmique, tandis que celle de l’autre axe reste linéaire. De plus, on représente sur l’axe des
ordonnées le genuine acceptation rate (GAR), qui est égal à 1 − F RR. On obtient finalement une
courbe qui a l’allure de celle de la figure 6. Les courbes semi-logarithmiques, utilisées par certains
chercheurs en biométrie, permettent une lisibilité et une interprétation différente [2].
3.3.5 Courbe de coût (Cost)
La courbe de coût (cost) est une courbe particulière en ce sens qu’elle permet de donner des
poids variables (facteurs WF A et WF R ) aux taux de faux rejet et de fausse acceptation pour en
faire ressortir en quelque sorte un coût général du sytème biométrique pour un certain seuil. Les
points qui composent une telle courbe prennent en abscisse une valeur de seuil T et en ordonnée
la valeur Cost(T ) retournée par la fonction de coût pour ce seuil (voir la figure 7). L’expression
mathématique de cette fonction est donnée par :
Cost(T ) = WF A ∗ F AR(T ) ∗ P (Impostor) + WF R ∗ F RR(T ) ∗ P (Genuine)
WF A , W F R ≥ 0 ; P (Impostor), P (Genuine) ∈ [0,1] ; P (Genuine) = 1 − P (Impostor)
1 Pour plus d’informations sur les distributions normales : http://en.wikipedia.org/wiki/Normal distribution3 BASES THÉORIQUES 8
Fig. 6 – Exemple de courbe semi-logarithmique
Fig. 7 – Exemple de courbe de coût3 BASES THÉORIQUES 9
Dans une banque par exemple, un dispositif de reconnaissance vocal sur le système téléphonique
induira un coût de FRR élevé et un coût de FAR petit, car si les personnes qui veulent téléphoner se
font sans cesse rejeter, elles vont être frustrées et risquent de rompre leur relation avec la banque,
ce qui va coûter beaucoup plus cher à cette dernière que si quelques personnes non autorisées
se font un peu trop facilement accepter. Au contraire, un système biométrique sur un coffre fort
induira un coût de FRR petit et un coût de FAR élevé, car si une personne autorisée veut accéder
au coffre (ce qu’elle ne fait en général qu’à de rares occasions) et qu’elle se fait rejeter, ce ne sera
pas grave. Elle va recommencer le processus de vérification peut-être une fois ou deux jusqu’à ce
qu’elle soit acceptée. Elle sera même ravie de la réticence du système à accepter toute personne et
finira par avoir accès à ses biens, ce qui ne va pas coûter grand chose à la banque. Par contre, si
un imposteur se fait malencontreusement accepter, il pourra avoir accès au contenu du coffre et le
voler, ce qui va coûter cher à la banque qui va devoir dédommager son client.
3.4 Le format de fichier Ragga
3.4.1 Définition du format
Le format de fichier dénommé Ragga est un format de fichier de scores biométriques au format
XML (eXtended Markup Language) qui a été défini dans le cadre du projet européen BioSecure2 .
Ce format va être poussé et finalisé dans le consortium du projet afin qu’il devienne un standard
et que la plupart des laboratoires l’utilisent. Ce format de fichier contient aussi plus de méta-
informations que les autres formats de fichier employés par les outils de scoring actuels. On peut
donc potentiellement en faire plus de choses (par exemple, faire une analyse par client et non
plus une analyse globale, etc...). Ce format permet également d’inclure des informations de type
“observateur” sur les données de test. Ces observateurs peuvent par exemple donner un indice de
qualité sur les données (niveau de bruit ou autre).
3.4.2 Structure
La structure du contenu d’un fichier Ragga est rerésentée à la figure 8.
3.4.3 Description de quelques éléments importants
Dans un fichier Ragga, les éléments importants sont définis par des balises XML dont les prin-
cipales sont :
– eval : Un élément eval constitue une séquence de tests ;
...
– moduleInformation : Les éléments moduleInformation fournissent des informations supplé-
mentaires au sujet des systèmes utilisés pour produire les scores ou les meta-data. Ils sont
liés à un module spécifique qui est soit un classifier, soit un observer. Tous les sous-éléments
institution, version, features et notes sont optionnels ;
...
– test : Les éléments test définissent un accès unique qui peut être un accès vrai ou un accès
imposteur. Un test est défini par un nom de frichier (fileName), un modèle de test (testModel )
utilisé sur le nom de fichier, et éventuellement le modèle véritable (trueModel ) correspondant
au fichier testé. Un attribut facultatif est la longueur du fichier (fileLength) ;
...
2 Site web du projet BioSecure : http://www.biosecure.info3 BASES THÉORIQUES 10
Fig. 8 – Exemple de contenu d’un fichier Ragga4 MÉTHODOLOGIE ET DESIGN 11
– classifier : Les éléments classifier définissent les scores biométriques du fichier sous un test.
Le format Ragga permet de sortir des scores globaux du fichier sous un test ou une séquence
de scores individuels avec des timestamps spécifiant à partir de quel instant et jusqu’à quel
instant dans le temps un score individuel s’applique. Une finalité pourrait être par exemple
qu’un classifier retourne des scores individuels pour chaque trame de 10 ms dans le cas de la
biométrie sur le signal de parole ;
...
Fig. 9 – Structure d’un classifier
– score : Un élément de type score représente le score de vraisemblance issu du module de
comparaison. De façon générale, ce score est directement ou indirectement lié à la probabilité
que les données biométriques observées correspondent à l’identité prétendue. En pratique, ce
score est une valeur de type float qui peut être négative ou positive suivant son domaine de
représentation (logarithmique ou linéaire).
4 Méthodologie et design
4.1 Management du projet
4.1.1 Meetings et méthode de travail
Concernant le management du projet, il a été décidé avec le Dr Jean Hennebert et l’assistant
Bruno Dumas au début de l’année académique de faire des meetings environ toutes les deux se-
maines, ce qui en totalise une quinzaine durant l’année. Lors de ces réunions, Jean Hennebert
supervisait l’avancement du projet selon une méthode bien connue en entreprise qui s’appelle eX-
treme Programming 3 (abrégé XP ). Cette méthode de développement de programmes informatiques
(softwares) procède sommairement de la manière suivante :
1. Analyse de l’architecture et des fonctionnalités (features) du futur programme informatique.
Définition de priorités sur les fonctionnalités à implémenter ;
2. Elaboration d’un planning sur la durée totale estimée du projet et selon les priorités des
fonctionnalités à implémenter ;
3. Meetings (itérations) pendant lesquels le travail effectué est inspecté et les tâches suivantes
fixées. Pour chaque tâche, le temps de réalisation nécessaire est estimé, et s’il n’est pas
3 Site web de XP : http://www.extremeprogramming.org4 MÉTHODOLOGIE ET DESIGN 12
encore possible de le déterminer précisément, un travail de prospection appelé spike est
préalablement agendé ;
4. Tests d’acceptation et correction des bugs ;
5. Première sortie du programme (small release).
La figure 10 représente de manière plus précise ces différentes étapes :
Fig. 10 – Déroulement d’un projet selon la méthode eXtreme Programming
4.1.2 Subversion (SVN)
Il était demandé de faire régulièrement des sauvegardes des fichiers du projet en cours sur le
répertoire de sauvegardes (repository) du serveur du groupe DIVA du département d’informatique
en utilisant le logiciel de contrôle de versions appelé Subversion 4 (SVN ).
4.1.3 Présentations et rapport final
À la fin de chaque semestre, tous les étudiants accomplissant leur travail de Bachelor dans
le groupe DIVA devaient faire une présentation intermédiaire de leur projet et principalement de
son état d’avancement. A la fin de l’année académique (en l’occurence le 19 juillet 2006), une
présentation finale était exigée pour couronner l’aboutissement du projet et profiter des remarques
de dernière minute faites par le professeur et les assistants pour effectuer les dernières retouches
au programme et au rapport final (à rendre dans les deux semaines au plus tard).
4.2 Choix technologiques
4.2.1 Langage de programmation
Java5 (de Sun Microsystems) est le langage de programmation qui a été choisi pour le projet
DET4J. Les raisons de ce choix sont que Java est un langage multiplateforme, de haut niveau
(orienté objet), très répandu et apprécié des programmeurs pour sa convivialité (notamment sous
l’environnement de programmation Eclipse6 ).
4 Site web du projet Subversion : http://subversion.tigris.org
5 Site web du projet Java : http://java.sun.com
6 Site web du projet Eclipse : http://www.eclipse.org4 MÉTHODOLOGIE ET DESIGN 13
4.2.2 Parsing
Le choix du parseur de fichier XML a été porté sur SAX7 . JDOM8 constituait l’autre parseur
potentiel, mais SAX lui a été préféré car, contrairement à JDOM, c’est un modèle de parseur
événementiel qui est très peu gourmand en mémoire puisqu’il n’a pas besoin de charger tout le
fichier en mémoire, ce qui n’est pas du tout négligeable, sachant qu’un fichier Ragga possède une
taille moyenne d’une vingtaine de méga-octets environ. JDOM est très gourmand en mémoire car
il doit d’abord générer l’arbre du document entier pour pouvoir ensuite accéder aux éléments par
des opérations classiques de navigation dans les arbres, tandis que SAX accède aux éléments de
manière séquentielle, ce qui ne demande que peu de mémoire.
4.2.3 GUI
Une grande partie de la programmation de DET4J portait sur la réalisation de l’interface
graphique utilisateur (GUI), c’est la raison pour laquelle il était important d’utiliser une bonne
bibliothèque graphique telle que Swing pour le langage Java. Swing offre la possibilité de créer
des interfaces graphiques identiques quel que soit le système d’exploitation sous-jacent, au prix de
performances moindres qu’en utilisant Abstract Window Toolkit (AWT). En effet, AWT fournit une
API indépendante du système d’exploitation pour mettre en oeuvre des composants graphiques.
Dans AWT, chaque composant est dessiné et contrôlé par un composant tiers natif spécifique au
système d’exploitation. C’est pourquoi les composants d’AWT sont appelés composants lourds. Au
contraire, les composants Swing sont décrits comme légers, car ils ne requièrent pas d’allocation
de ressources natives de la part du gestionnaire de fenêtres sous-jacent, mais “empruntent” les
resources de leurs ancètres. Une grande partie de l’API Swing est une extension complémentaire à
AWT plutôt qu’un remplaçant direct. L’affichage est fourni par Java2D. Finalement, Swing utilise
le principe Modèle-Vue-Contrôleur9 (MVC) et dispose de plusieurs choix d’apparence (de vue)
pour chacun des composants standard.
4.3 Architecture du programme
Le programme DET4J se décompose en trois différents paquetages (packages) Java dont voici
les descriptions :
4.3.1 biosecure.det4j
biosecure.det4j est le package principal. Il est constitué de toutes les classes qui sont l’essence
même de l’application DET4J. Ce package comprend :
– Det4J.java, qui est la classe principale du programme DET4J. Elle lance le programme et
instancie les différentes classes pour, entre autres, créer les trois fenêtres du GUI et le menu,
lancer le parseur SAX et extraire les différentes données utiles pour l’affichage et la manipu-
lation des courbes de performance ;
– SettingsWindow.java, qui contient les méthodes pour créer une fenêtre permettant d’effectuer
divers réglages ainsi que de manipuler les classifiers et leurs courbes ;
– ConsoleWindow.java, qui contient les méthodes pour créer une fenêtre de console qui affiche
des informations sur les actions et événements importants qui se produisent durant l’utilisa-
tion du logiciel ;
– JCanvas.java, qui contient les méthodes pour créer dans la fenêtre principale de DET4J le
graphique (canvas) contenant les courbes, la grille, les labels, le titre, la légende, etc... C’est
ce canvas qui constitue la finalité de l’utilitaire et qui va pouvoir être imprimé ou exporté ;
7 Siteweb du projet SAX : http://www.saxproject.org
8 Siteweb du projet JDOM : http://www.jdom.org
9 Pour plus d’informations sur la démarche MVC : http://fr.wikipedia.org/wiki/Modèle-Vue-Contr^
oleur4 MÉTHODOLOGIE ET DESIGN 14
– CanvasObject.java, qui décrit un objet représentant une certaine zone du graphique (canvas)
et mémorisant les caractéristiques de cette dernière pour pouvoir détecter les événements de
la souris (clics et glissements) et permettre de réagir en conséquence ;
– ActiveZoneDescriptors.java, qui crée un objet contenant la liste de tous les CanvasObjects
qui vont réagir aux actions de la souris ;
– CDF Normal.java, qui contient les routines nécessaires au calcul de la fonction de distribu-
tion normale cumulative (CDF) et de sa fonction inverse. Ces routines sont utilisées dans la
représentation de courbes de performance de type DET (cf. §3.3) ;
– ClassifierDETCurveData.java, qui décrit une structure de données pour contenir les ca-
ractéristiques de la courbe d’un classifier. Ces caractéristiques sont le nom du classifier, le
nom de la courbe dans la légende, le vecteur contenant les coordonnées de tous ses points, sa
couleur, son type et son épaisseur, la valeur de son equal error rate (EER) et celle du seuil
associé (T (EER)). Cette classe contient aussi les méthodes qui calculent le vecteur des points
de la courbe (la dimension de ce vecteur est donnée constitue la résolution de la courbe, i.e.
le nombre de points qui la compose), son EER et le seuil associé T (EER) ;
– ClassifierScores.java, qui a pour fonction de créer la liste des scores bruts d’un classifier ;
– Coordinate.java, qui crée une structure de données pour contenir les coordonnées d’un point
d’une courbe de performance et du seuil associé ;
– PrintUtilities.java, qui est une classe utilitaire permettant d’imprimer un composant (com-
ponent) quelconque, tel que le graphique (canvas) dans notre cas ;
– RaggaException.java, qui retourne une exception spécifique lorsqu’une erreur survient lors du
parsing d’un fichier Ragga.
4.3.2 biosecure.det4j.model
Ce package a comme fonction de représenter le modèle interne d’un fichier Ragga et contient
une classe pour chaque élément structurel du format (cf. 3.4). Ces classes sont bien évidemment
employées par le parseur SAX et sont AuxiliarySignal.java, Classifier.java, Eval.java, Generic.java,
MetaData.java, ModuleInformation.java, Observer.java, Score.java et Test.java.
4.3.3 biosecure.det4j.parser
Ce package est celui du parseur de fichiers Ragga (XML) et contient l’unique classe RaggaSax-
Parser.java qui est utilisée pour lire et parser un fichier (XML) au format Ragga au moyen de
SAX.
4.4 Description du GUI
Lors de la réflexion sur le layout final de l’utilitaire DET4J, il a été décidé que l’interface gra-
phique utilisateur (GUI) serait composé de trois fenêtres indépendantes (voir la figure 11) :
1. Une première fenêtre, la principale, pour contenir et interagir avec le graphique. Elle contient
aussi l’unique barre de menus ;
2. Une deuxième fenêtre pour effectuer les réglages les plus importants et qui s’appliquent
directement aux courbes des classifiers ;
3. Une troisième fenêtre pour la console permettant d’afficher les informations à propos des
actions et erreurs pouvant survenir durant l’utilisation.4 MÉTHODOLOGIE ET DESIGN 15
Fig. 11 – Aperçu du GUI de l’application DET4J
Dans la fenêtre principale “Det4J”, il a été souhaité que le plus grand nombre possible de
manipulations soient réalisables intuitivement et directement sur le graphique au moyen de la sou-
ris (par clics et glissements). Cela comprend la majorité des manipulations d’édition des titres,
des labels et de la légende. Les opérations restantes et les options typiques des menus (comme
l’ouverture de fichiers, l’impression, l’exportation, etc...) sont accessibles via la barre de menus.
Les menus disponibles sont : “Det4J”, “File”, “Edit” et “Window”. Le menu “Det4J” contient les
options relatives au programme lui-même (About, Quit), le menu “File” les options relatives au
fichier (Open, Export, Print), le menu “Edit” les options relatives à l’édition du graphique, et le
menu “Window” les options relatives aux fenêtres annexes (Show, Hide).
Dans la deuxième fenêtre, il a été décidé de placer deux compartiments principaux. Le pre-
mier, “Settings”, permet de faire les deux réglages principaux relatifs à toutes les courbes de
performance, c’est-à-dire de changer par un menu déroulant le type de courbes à visualiser, et
d’augmenter/réduire avec un “slider” la résolution des courbes (i.e. le nombre de points calculés
pour chacune d’entre elles). Le second compartiment, “Classifiers”, permet d’effectuer des réglages
et de voir des informations propres à chaque classifier. Un troisième compartiment s’intercale entre
les deux premiers quand le type de courbe sélectionné dans le menu déroulant est la courbe de
coût (cf. §3.3). Ce dernier compartiment offre à l’utilisateur la possibilité de modifier directement
les paramètres de la fonction de coût.
L’éventualité de créer une application DET4J réunissant ces trois fenêtres en une unique fenêtre
principale a longuement été discutée, mais finalement abandonnée, et ceci pour les raisons suivantes.
La programmation de la création, de la séparation, de la hiérarchisation, de l’affichage et de l’exploi-
tation de plusieurs zones de fonctionnalités diverses au sein d’une même fenêtre est extrêmement
fastidieuse avec Swing et donc plus sujette aux bugs et aux pertes de temps. Finalement, la création
d’un GUI avec fenêtres séparées — comme c’est le cas dans DET4J — permet à l’utilisateur de
masquer à souhait celles dont il n’a pas l’utilité ou qu’il ne veut simplement pas voir s’afficher.5 TRAVAIL EFFECTUÉ ET RÉSULTAT 16
5 Travail effectué et résultat
5.1 Fonctionnalités du programme
Dans sa version actuelle, l’utilitaire DET4J est doté de multiples fonctionnalités. Voici les des-
criptions de celles qui paraissent essentielles :
Support du nouveau format de score Ragga : Il était primordial que DET4J supporte ce fu-
tur standard de format de fichier de scores biométriques élaboré récemment par le consortium
du projet européen BioSecure ;
Chargement et fermeture de plusieurs fichiers Ragga : Il est possible d’ouvrir plusieurs fi-
chiers Ragga l’un après l’autre. Chaque fichier peut contenir un ou plusieurs classifiers. Les
courbes de performance respectives seront alors affichées sur le même graphique dans DET4J.
Ce dernier permet de désactiver à la volée l’affichage des courbes des classifiers chargés en
décochant la case prévue à cet effet à côté de leur nom dans la fenêtre des réglages. No-
tons que DET4J gère les fichiers Ragga d’après les classifiers qu’ils contiennent. Ainsi, il est
possible de se débarasser de tout classifier (qui a été chargé) indépendamment des autres
classifiers pouvant appartenir au même fichier Ragga. En réouvrant le même fichier Ragga,
le classifier perdu va être rechargé sans que les autres classifiers, déjà chargés, ne le soient à
leur tour (un message d’avertissement va alors nous en informer) ;
Création du GUI : L’interface graphique utilisateur (GUI), dont les principes sous-jacents ont
été discutés au paragraphe 4.4, a été réalisé avec Swing et a représenté une partie considérable
du projet (création des fenêtres, des menus, boutons, sliders, etc..). Il est à noter que divers
“tool-tips” ont été implémentés pour afficher des messages d’aide quand l’utilisateur déplace
le pointeur de la souris sur certains éléments du GUI ;
Calcul et affichage des courbes ROC, DET, Semi-Log, T-FA/T-FR et Cost : Le calcul
et l’affichage de ces divers types de courbes, dont les modèles ont été discutés au para-
graphe 3.3, se font entièrement dans la classe JCanvas.java. Le mode d’affichage désiré est
sélectionnable au moyen le menu déroulant “Curve types” dans la fenêtre des réglages ;
Optimisation de l’affichage des courbes : Lors du calcul des coordonnées F AR et F RR des
points de chaque courbe, on a remarqué que la répartition de ces points n’était pas uniforme
(bien que le seuil de sécurité T varie linéairement). En effet, la majeure partie des points se
situaient aux extrémités du graphe, si bien que beaucoup d’entre eux étaient dessinés sur le
même pixel. L’affichage des courbes devenait donc lourd et lent. C’est la raison pour laquelle,
lors du calcul et de l’affichage des points d’une courbe, on supprime ceux qui sont inutilement
trop proches. De plus, une fonction d’anti-aliasing (i.e. de lissage des pixels) applicable aux
courbes a été implémentée. L’anti-aliasing est désactivé par défaut, mais peut être activé par
une commande du menu “Edit” ;
Exportation dans un grand nombre de formats : Grâce au package VectorGraphics (cf. §
5.3.2), il est possible d’exporter le graphique dans un grand nombre de formats, tels png,
jpg, gif, bmp, pdf, ps, eps, svg (la liste exhaustive est donnée à la figure 20 du Guide de
l’Utilisateur en annexe). L’exportation se fait via la commande “Export” du menu “File” ;
Impression : Il est possible d’imprimer le graphique via la commande “Print” du menu “File”.
C’est la classe PrintUtilities.java qui en est responsable (cf. §4.3) ;
Calcul et affichage de l’equal error rate : Les valeurs de l’equal error rate (EER) de tous
les classifiers chargés s’affichent à côté de leurs noms respectifs dans la fenêtre des réglages.
En outre, dans quatre des cinq visualisations implémentées (toutes sauf celle de la courbe de5 TRAVAIL EFFECTUÉ ET RÉSULTAT 17
coût), il est possible d’afficher, via le menu “Edit”, les points des equal error rates sur les
différentes courbes de performance activées ;
Calcul du seuil de l’equal error rate : De manière analogue, les seuils associés aux equal error
rates respectifs des classifiers (T (EER)) sont affichés à côté des noms dans la fenêtre des
réglages ;
Calcul et affichage des points de coût minimal, seuil optimal : Si la visualisation en mode
“Courbe de coût” est sélectionnée, le troisième compartiment permettant de modifier à la
volée les paramètres de la fonction de coût apparaı̂t dans la fenêtre des réglages. De plus,
on peut afficher le point de coût minimal (le seuil associé est par conséquent optimal) sur
la courbe de chaque classifier, et un tableau contenant les coordonnées de ces points (Topt ,
Cmin = C(Topt )) pour chaque classifier est imprimé dans la console. Ce tableau est réimprimé
après tout changement de résolution ou de paramètre de la fonction C(T ). Notons que ce
tableau n’est pas mis à jour, mais réimprimé, ce qui permet de faire des comparaisons entre
tableaux de configurations différentes ;
Gestion des événements de la souris : La gestion des événements de la souris sur le graphique
(canvas) de la fenêtre principale de DET4J permet de repérer et d’identifier les actions po-
tentielles de la souris (clics et glissements) aux endroits spécifiques du canvas pour pouvoir
réagir en conséquence. Comme il l’a été vu au paragraphe 4.3, ce sont les classes CanvasOb-
ject.java et ActiveZoneDescriptors.java qui en sont responsables ;
Déplacement de la légende par “drag and drop” : La légende est déplaçable par un glisser-
déposer (drag and drop) de la souris au sein-même du graphique. Notons qu’il est possible
de masquer la légende si on le souhaite ;
Affichage des coordonnées d’un point en fonction d’un clic dans la grille : Lorsqu’un clic
de la souris est effectué à l’intérieur du cadran contenant les courbes, un point muni d’un
cadre contenant ses coordonnées est dessiné à l’endroit du clic. La couleur du fond de ce cadre
est modifiable au moyen d’un “color-chooser” accessible par une commande du menu “Edit” ;
Edition des labels des axes, titre, légende et noms des classifiers : Les labels des axes, le
titre, la légende et les noms des classifiers sont éditables soit via le menu “Edit”, soit en
cliquant directement sur l’élément concerné dans le graphique. Les valeurs par défaut de tous
les éléments sont restaurables par l’intermédiaire des commandes appropriées dans le menu
“Edit” ;
Gestion du redimensionnement de la fenêtre (canvas) : La gestion du redimensionnement
de la fenêtre principale de DET4J, et par conséquent du canvas, constituait une lourde tâche.
En effet, il n’a pas été aisé de faire que le graphique reste consistant, utilisable et présentable,
et que les événements de la souris continuent de fonctionner lors des redimensionnements de
la fenêtre. DET4J impose une taille minimale de la fenêtre au-delà de laquelle il n’est pas
possible d’aller. Notons aussi que le redimensionnement constitue une sorte de zoom qui peut
être utile ;
Edition de la couleur, de l’épaisseur et du type de trait des courbes : Il est possible de
changer la couleur de chaque courbe de performance par l’intermédiaire d’un “color-chooser”
qui apparaı̂t lorsqu’on clique sur le bouton adéquat à droite du nom du classifier dans la
fenêtre des réglages. L’épaisseur (de 1 à 10 pixels) et le type de trait (continu, pointillé, petit
ou grand traitillé) est modifiable d’une façon analogue. Ces changements sont aussi pris en
considération par les symboles dans la légende.5 TRAVAIL EFFECTUÉ ET RÉSULTAT 18
5.2 Rédaction de la Javadoc
Pendant la durée du projet DET4J, une partie non négligeable du temps de travail a été
consacrée à la rédaction de la documentation de l’API au format HTML (Javadoc). L’environne-
ment de programmation Eclipse dispose d’un outil de création de Javadoc à partir du code source
(dans lequel on insère certaines commandes spécifiques). Le code de l’application DET4J est donc
entièrement commenté et prêt à être consulté. C’est la raison pour laquelle l’auteur de ce rapport
ne va pas s’attarder sur le code et l’implémentation.
5.3 Packages utilisés
5.3.1 Xerces et JDOM
Il a été vu au paragraphe 4.2 que SAX a été choisi pour effectuer le parsing des fichiers XML au
format Ragga. SAX, dont l’acronyme veut dire “Simple API for XML”, a été le premier API pour
XML à être largement adopté par la communité des programmeurs Java, et constitue “de facto”
un standard à l’heure actuelle. La dernière version stable de SAX est la 2.0.1 (SAX2). SAX2 est
gratuit et il n’est pas possible d’en posséder une license car il fait partie du domaine public.
Pour utiliser SAX2, il est nécessaire d’installer un parseur XML pour Java qui supporte les in-
terfaces de SAX2, comme Xerces-J10 . Xerces fait partie du projet XML d’Apache. Le programme
DET4J requiert aussi l’installation de JDOM11 dont le parseur SAX utilise certaines classes (no-
tamment pour représenter les modèles des éléments XML dans Java). Par conséquent les fichiers
xerces.jar et jdom.jar doivent être ajoutés au CLASSPATH de Java.
5.3.2 VectorGraphics
Description du package
Le package VectorGraphics de la bibliothèque Java FreeHEP12 est mis à dispostion et utilisable
sous les termes de license LGPL. Il permet à tout programme Java d’exporter dans une variété de
formats graphiques vectoriels et bitmap. La gamme des formats vectoriels recense entre autres les
formats PostScript, PDF, EMF, SWF et CGM, tandis que celle des formats bitmap les formats
GFI, PNG, JPG and PPM. Ce package utilise la classe standard java.awt.Graphics2D comme
interface pour le programme utilisateur, ce qui rend plutôt facile son couplage à un quelconque
programme Java. En outre, il met à disposition une boı̂te de dialogue qui permet à l’utilisateur
de choisir entre les différents formats mentionnés ci-dessus et de fixer les paramètres propres à
chaque format. Finalement, VectorGraphics contient un ensemble de classe basiques pouvant être
étendues pour gérer des nouveaux formats de sortie qui viendraient à faire leur apparition. La
figure 12 montre un schéma de l’architecture du package et ce qui suit est extrait du manuel13 .
Comment utiliser le package ?
En Java, c’est la méthode paint(Graphics g) d’un component qui permet de dessiner un gra-
phique. Dans le corps de cette méthode, l’utilisateur appelle séquentiellement plusieurs méthodes
d’un contexte java.awt.Graphics ou de java.awt.Graphics2D pour réaliser le dessin. Le package
VectorGraphics étend la classe Graphics2D pour permettre aux utilisateurs de continuer de des-
siner vers le même ancien contexte Graphics2D qui leur est familier. Cependant, cette exten-
sion ajoute la gestion des nouveaux formats de sortie. Le code de l’utilisateur pour dessiner
un graphique reste donc le même, autant pour ce qui concerne l’affichage à l’écran que pour
ce qui est de l’écriture dans un format quelconque. Pour utiliser le package VectorGraphics, le
programmeur doit ajouter le code pour afficher la boı̂te de dialogue d’exportation (ExportDia-
log) afin que l’utilisateur puisse sélectionner un format. Cet ajout peut se faire dans un Me-
nuItem (voir l’exemple du manuel en ligne). Pour lancer le programme dont le code employe
ce package, il est impératif d’ajouter au CLASSPATH les fichiers jar suivants : freehep-base.jar,
10 Siteweb du projet Xerces : http://xerces.apache.org/xerces-j
11 Siteweb du projet JDOM : http://www.jdom.org/
12 The FreeHEP Java library : http://java.freehep.org
13 Manuel en ligne de VectorGraphics : http://java.freehep.org/freehep1.x/vectorgraphics/Manual.html5 TRAVAIL EFFECTUÉ ET RÉSULTAT 19
Fig. 12 – Architecture du package VectorGraphics
freehep-graphics2d.jar, freehep-graphicsio.jar, qui incluent les formats bitmap de base JPG, PNG
et PPM. Pour inclure en plus le format GIF ainsi qu’un ou plusieurs formats vectoriels, les fi-
chiers jar suivants doivent aussi être ajoutés : freehep-graphicsio-gif.jar, freehep-graphicsio-cgm.jar,
freehep-graphicsio-emf.jar, freehep-graphicsio-pdf.jar, freehep-graphicsio.ps.jar, freehep-graphicsio-
svg.jar et freehep-graphicsio-swf.jar. Le cas échéant, la boı̂te de dialogue d’exportation va auto-
matiquement détecter tous les formats dont les fichiers jar ont été ajoutés au CLASSPATH et
permettre à l’utilisateur de les sélectionner.
Comment dessiner dans un contexte VectorGraphics ?
Afin d’utiliser les méthodes du package pour dessiner, l’utilisateur a besoin de convertir le
contexte standard java.awt.Graphics en un contexte VectorGraphics. Pour ce faire, on dispose
de la méthode VectorGraphics.create(Graphics g), qui va retourner g si ce dernier est déjà une ins-
tance de VectorGraphics ou alors encapsuler g dans une instance de VectorGraphics (un exemple
de code est disponible dans le manuel en ligne). On pourra ainsi faire appel à toutes les méthodes
de Graphics2D et aux méthodes additionnelles de VectorGraphics.
Fonctionnalités additionnelles du package ?
La classe VectorGraphics étend Graphics2D avec un certain nombre de fonctionnalités permet-
tant d’écrire de meilleurs formats de sortie. Ces fonctionnalités sont :
– Les méthodes Draw, Fill, Clear, Clip,... : Ces méthodes (drawLine(), fillOval(), clear-
Rect(), clipRect(),...) qui prennent normalement en paramètres des nombres entiers ont été
surchargées avec des méthodes dont les noms sont les mêmes mais qui prennent en paramètres
des double. Ceci permet de dessiner avec une plus grande précision en continuant d’utiliser
ces méthodes simples. Une telle précision est requise par les formats vectoriels, souvent des-
tinés à être exploités par des périphériques demandant une résolution plus haute que celle
d’un écran (une imprimante par exemple). Les méthodes setLineWidth() et getLineWidth()
permettent de changer la largeur du trait sans créer explicitement un objet de type Stroke.
– Les objets PrintColors : La classe PrintColor étend java.awt.Color pour tenir compte desVous pouvez aussi lire

















































