IMN430 Introduction Olivier Godin 8 janvier 2019 - Université de Sherbrooke
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

IMN430
Chapitre 1
Introduction
Olivier Godin
Université de Sherbrooke
8 janvier 2019
Introduction 1 / 76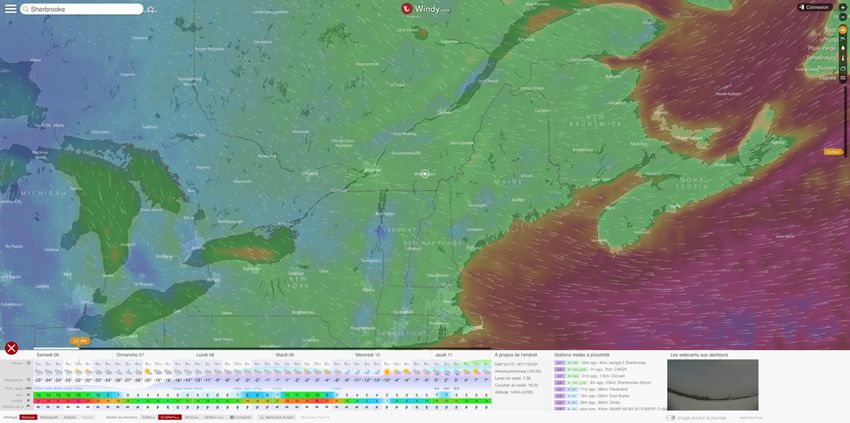
Plan du chapitre
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 2 / 76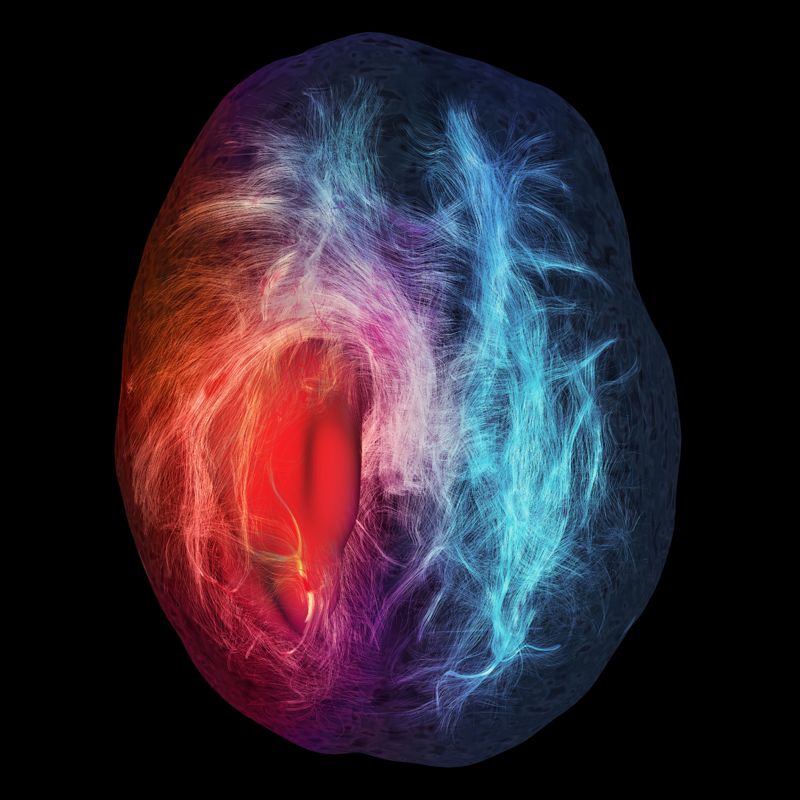
Présentation du plan de cours
Présentation du plan de cours
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 3 / 76
Présentation du plan de cours
Présentation du plan de cours
Enseignant
Olivier Godin
Courriel : Olivier.Godin2@USherbrooke.ca
Local : D6-0047
Téléphone : (819) 821-8000 poste 65565
Site web : http://info.usherbrooke.ca/ogodin/
Horaire
Mardi 15 h 30 à 17 h 20 (D4-2021)
Jeudi 15 h 30 à 17 h 20 (D4-2021)
(+ Quelques reprises durant la session)
Introduction 4 / 76
Présentation du plan de cours
Présentation du plan de cours
Description officielle de l’activité pédagogique [6]
Cibles de formation : Connaître et approfondir les concepts utilisés en visualisation ;
réaliser une application de visualisation dans le domaine de l’imagerie médicale.
Contenu : Techniques de visualisation des données : analyse de données (analyse
en composantes principales et analyse géométrique), sélection des données par
sous-espace ou par pondération, regroupement des données (maillage,
triangulation, tenseur, glyphe). Techniques de visualisation des phénomènes
complexes : représentations continues (équations différentielles partielles) et
discrètes (processus aléatoires). Contextes d’application : imagerie médicale,
sciences du vivant.
Introduction 5 / 76
Présentation du plan de cours
Présentation du plan de cours
Mise en contexte
La visualisation scientifique regroupe tous les aspects associés à la production d’une
représentation visuelle d’un ensemble de données obtenu par expérimentation ou
simulation. L’objectif de la visualisation scientifique est double : améliorer notre
compréhension d’un phénomène, de même qu’obtenir une représentation plus simple
d’un ensemble de données complexe.
Les outils de visualisation sont rapidement devenus indispensables dans plusieurs
domaines de l’ingénierie, des sciences, de l’économie et de la médecine. Ce faisant, la
visualisation scientifique est devenue un champ de recherche des plus actifs.
Introduction 6 / 76
Présentation du plan de cours
Présentation du plan de cours
Cibles de formation spécifiques
À la fin de cette activité pédagogique, l’étudiante ou l’étudiant sera capable de
1 Manipuler et interpréter un ensemble de données de haute dimension ;
2 Représenter visuellement des ensembles de données scalaires, vectorielles et
tensorielles ;
3 Déterminer une bonne forme de représentation visuelle à utiliser pour un ensemble
de données ;
4 Appliquer des principes d’infographie à la visualisation des données ;
5 Appliquer des principes de traitement d’images à la visualisation des données ;
6 Comprendre les étapes principales du processus menant à la visualisation d’un
ensemble de données ;
7 Saisir les enjeux passés, présents et futurs associés à la visualisation des données.
Introduction 7 / 76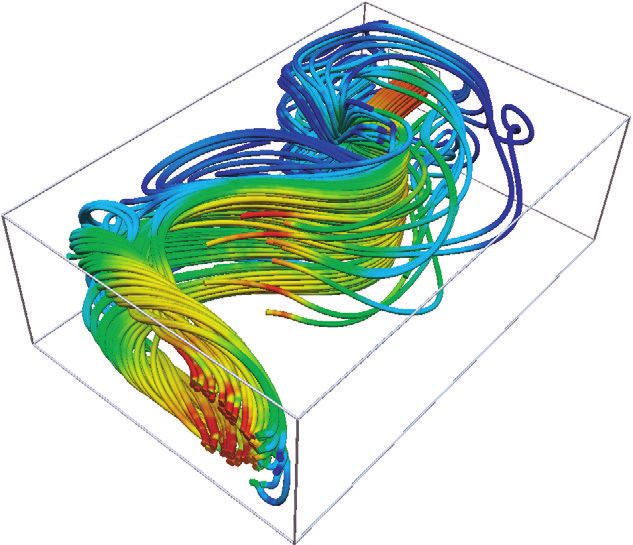
Présentation du plan de cours
Présentation du plan de cours
Contenu détaillé
1 Introduction
Mise en contexte
Infographie et visualisation
Représentation des données
Pipeline de visualisation
2 Réduction de la dimension des données
Méthodes linéaires
Méthodes non linéaires
3 Techniques de base en visualisation
Visualisation de données scalaires
Visualisation de données vectorielles
Visualisation de données tensorielles
Introduction 8 / 76
Présentation du plan de cours
Présentation du plan de cours
Contenu détaillé (suite)
4 Visualisation basée sur le domaine
Manipulation du domaine
Traitement d’image et visualisation
Visualisation de volumes
5 Conclusion
Visualisation d’informations vs. visualisation scientifique
Logiciels de visualisation
Recherche en visualisation scientifique
Méthode pédagogique
Une semaine comprend trois heures de cours magistraux et une heure d’exercices. La
plupart des présentations en classe se feront à l’aide de diapositives disponibles sur le
site du cours au format pdf.
Introduction 9 / 76
Présentation du plan de cours
Présentation du plan de cours
Évaluation
Travaux (3) : 3 × 15% (en équipe de deux ou trois étudiants)
1 Réduction de la dimension d’un ensemble de données
2 Visualisation de données scalaires et vectorielles
3 Visualisation de données tensorielles et de volumes
Examen périodique : 25%
Examen final : 30%
Bonus : cinq fautes de français = une tablette de chocolat pour le groupe 1
1. Aucun achat requis. Certaines conditions s’appliquent.
Introduction 10 / 76Présentation du plan de cours
Présentation du plan de cours
Introduction 11 / 76Mise en contexte
Mise en contexte
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 12 / 76Mise en contexte
Qu’est-ce que la visualisation ?
L’objectif de la visualisation est de produire une représentation graphique en lien avec
un certain phénomène d’intérêt (simulation scientifique, données observées, etc.) qui
permet à l’utilisateur d’obtenir un aperçu de ce phénomène. Terrace
Whitehorse Fort St. John
Grande Prairie
Yellowknife
Ft. McMurray
Prince George
Edmonton
Comox Kamloops
Nanaimo Vancouver Calgary/Banff
Abbotsford Kelowna Saskatoon Deer Lake
Victoria
Penticton
CANADA St. John’s, NL
Seattle-Tacoma
Spokane
Pasco/Richland Regina
ALASKA Portland /Kennewick Kalispell Winnipeg
Sydney
Fairbanks Great Falls Charlottetown
Lewiston Missoula
International Falls Moncton
Eugene Redmond/Bend Helena Williston Minot
Butte Grand Thunder Bay Québec
Forks Fredericton
Bozeman Chisholm/
Hibbing Halifax
Bemidji
Anchorage Billings Bismarck
Medford Boise Fargo Duluth Marquette Sault Ste. Montreal
West Yellowstone Brainerd Marie Bangor
Cody Ottawa
Juneau Sun Valley Idaho Falls Rhinelander Iron Mountain
Twin Aberdeen Escanaba Pellston/Mackinac Island Portland
Falls Gillette Minneapolis- Alpena Burlington
Sitka Jackson Hole
Rapid City St. Paul Wausau Green Bay Traverse City
Pocatello Toronto Manchester
Appleton/ Albany Boston
Ketchikan Elko Fox Cities Midland/ Syracuse
Rochester La Crosse Grand Saginaw Rochester
Reno/Tahoe Casper Rapids London Hartford/
Sioux Falls Milwaukee Ithaca Springfield Martha’s Vineyard
San Sacramento Flint Buffalo/ Elmira/
Madison Kalamazoo/ Niagara FallsCorning Binghamton Nantucket
Francisco Oakland Lansing Newburgh Providence
Salt Lake City Cedar Rapids/ Battle Creek Wilkes-Barre/ White Plains
San Jose Iowa City Detroit Erie Scranton
Hayden/Steamboat Springs Omaha Chicago South Bend Cleveland New York (JFK, LGA)
State
Des Moines
(ORD, MDW) Akron/Canton College Allentown Newark
Eagle/Vail/Beaver Creek Peoria Philadelphia
Fresno/Yosemite Moline/
Cedar City Grand Junction Bloomington Ft. Wayne Pittsburgh Harrisburg
Aspen/ Denver Lincoln Quad
Snowmass Cities Columbus Baltimore
St. George Dayton
Montrose/ Colorado Springs
Telluride Kansas City Indianapolis Washington, D.C. (DCA, IAD)
Las Vegas Cincinnati Charlottesville
Charleston
Burbank Ontario St. Louis Richmond
Louisville Lexington
Los Angeles Palm Springs Newport News/Williamsburg
Wichita Evansville
Long Beach Springfield/ Norfolk/Virginia Beach
Orange County Branson Roanoke
Tri-Cities Greensboro/High Point/Winston-Salem
San Diego Albuquerque Fayetteville/ Nashville Raleigh-Durham
Tulsa Northwest Arkansas Knoxville
Phoenix/Scottsdale New Bern
Asheville
Charlotte Jacksonville/Camp Lejeune
Oklahoma City Ft. Smith Greenville/
Memphis Fayetteville/Ft. Bragg
Chattanooga Spartanburg
Tucson Huntsville/ Wilmington
Little Rock Decatur Columbia Myrtle Beach
Columbus/ Atlanta
Dallas/ Starkville/ Birmingham
Ft. Worth West Point Augusta Charleston
El Paso/
Kauai Ciudad Juárez (DFW) Dallas Love Columbus/Ft. Benning
Monroe
Field (DAL) Montgomery
Jackson Savannah
Oahu
Shreveport
Lihue Killeen/Ft. Hood Dothan Albany Brunswick
Kahului Mobile Valdosta
Honolulu Maui Delta Air Lines/Delta Connection/ Alexandria Baton Pensacola Jacksonville
Delta Joint Venture Route Austin Rouge Tallahassee
New Route Starting this Month Lafayette Gulfport/Biloxi Panama City
Houston New Orleans Daytona Beach
H AWA I I Hilo Future Route Service San Antonio (IAH, HOU) Destin/
Ft. Walton Beach
Gainesville
Orlando
Kona Hawaii Destination served by Delta/
Delta Connection Tampa/St. Petersburg Melbourne
Destination served by one of Delta’s
Worldwide Codeshare Partners Sarasota/Bradenton West Palm Beach
Ft. Myers/Naples Ft. Lauderdale/
MEXICO
Effective July 2017. Select routes are seasonal. Some future
services subject to government approval. Service may be Harlingen/ Hollywood
operated by one of Delta’s codeshare partner airlines or one South Padre Island
Miami
BAHAMAS
[2]
of Delta’s Connection Carriers. Flights are subject to change
without notice.
Key West
Dans le cadre de ce cours, on s’intéressera particulièrement au processus permettant
d’obtenir la représentation visuelle à partir des données initiales.
Introduction 13 / 76Mise en contexte
Qu’est-ce que la visualisation ?
La visualisation est un domaine très vaste qui repose autant sur les mathématiques et
l’informatique que sur les sciences cognitives. L’objectif du cours n’est pas
d’approfondir chacun de ces champs de compétence, mais plutôt d’apprendre à utiliser
les notions qui sont nécessaires à la production de représentations visuelles adéquates.
[4]
Introduction 14 / 76Mise en contexte
Qu’est-ce que la visualisation ?
[7]
Au cours de la session, on s’intéressera à des techniques de visualisation très répandues
qui ont de multiples applications. On étudiera aussi plusieurs méthodes moins comunes,
mais qui tissent des liens avec des sujets abordés dans d’autres cours du programme.
Introduction 15 / 76Mise en contexte
Aperçu d’un phénomène
Le terme « aperçu » (insight) est fréquemment utilisé en visualisation, mais il demeure
plutôt vague. On l’utilisera pour décrire deux types d’information que l’on pourra obtenir à
l’aide des techniques de visualisation :
des réponses à des questions prédéterminées ;
4 1. Introduction
des faits inconnus concernant un phénomène.
visualization targets
specific questions discovering the unknown
What is in this dataset?
quantitative qualitative
What is the data's Does the data
mimimum/average/ answer some
distribution? problem X? [5]
Figure 1.1. Types of questions targeted by the visualization process.
Introduction
that should be able to convey insight into the considered process. In the words 16 / 76Mise en contexte
Aperçu d’un phénomène
Dans le premier cas, nous avons des questions concrètes à propos d’un certain
phénomène ou ensemble de données. L’objectif de la visualisation est alors de répondre
à ces questions aussi précisément et aussi rapidement que possible.
Exemple : À quel endroit se situe le point le plus élevé du parcours ?
[3]
Introduction 17 / 76Mise en contexte
Aperçu d’un phénomène
L’exemple précédent en est un basé sur des données quantitatives. La visualisation peut
aussi servir à représenter des données qualitatives.
Exemple : À partir des données d’un examen du cerveau, peut-on déterminer les régions
affectées par une tumeur ?
[1]
Introduction 18 / 76Mise en contexte
Aperçu d’un phénomène
Les questions auxquelles on cherche à répondre peuvent être autant très précises que
très vagues. De plus, l’utilisation d’un support visuel peut fournir à l’utilisateur de
l’information qui n’était pas explicitement recherchée et peut mener à une meilleure
interprétation des données.
[3]
Introduction 19 / 76Mise en contexte
Aperçu d’un phénomène
Le deuxième cas où la visualisation est utile concerne la découverte de faits inconnus
pour un certain phénomène. On peut par exemple croire qu’en observant les données
associées à une situation, on pourra comprendre sa cause ou encore découvrir des
signes avant-coureurs.
Introduction 20 / 76Mise en contexte
Aperçu d’un phénomène
Dans la pratique, les deux cas ne sont souvent pas séparés.
Une question concrète peut très bien mener à la découverte de nouvelle information dans
un ensemble de données. De la même manière, une exploration sans but précis peut être
à la source de8 questionnements plus pointus. 1. Introduction
inlet = seed area
highest rainfall, mild temperature
outlet
a) b)
2003 2004 2005 2006
N
W E
S
c) d) [5]
Figure 1.2. Visualization examples targeting different types of questions.
Introduction 21 / 76Mise en contexte
Qu’est-ce que la visualisation ?
La visualisation est souvent séparée en deux sous-domaines principaux : la
visualisation scientifique et la visualisation d’information :
Visualisation scientifique : cette branche est apparue suite à la démocratisation
des simulations par ordinateur qui produisent de très grandes quantités de données.
Habituellement, les données à représenter possèdent une composante spatiale
intrinsèque.
Visualisation d’information : le défi pour cette branche de la visualisation est de
créer une représentation visuelle pour des données qui n’en ont pas naturellement
ou qui n’ont pas de notion de position dans l’espace (graphes, arbres, listes, etc.)
On assiste de plus en plus à un mélange de ces deux sous-domaines en raison de la
démocratisation des représentations visuelles de données qui, à la base, n’en
possédaient pas.
Introduction 22 / 76Mise en contexte
Qu’est-ce que la visualisation ?
Finalement, un aspect fondamental de la visualisation est la possibilité pour l’utilisateur
d’intéragir avec la représentation visuelle, ce qui rend l’information encore plus
1.1. How Visualization Works
tangible.
raw data final image
f(x,y) ∈ R3 input output
visualization application
{0,2,-5,...}
observed
by
interact
measuring
device or end user
simulation insight into the original phenomenon
[5]
Figure 1.3. Conceptual view of the visualization process.
Introduction 23 / 76Infographie et visualisation
Infographie et visualisation
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
Un premier exemple
Rappels d’infographie
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 24 / 76Infographie et visualisation Un premier exemple
Un premier exemple
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
Un premier exemple
Rappels d’infographie
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 25 / 76Infographie et visualisation Un premier exemple
Un premier exemple
Tant en infographie qu’en visualisation, un cherche à produire une représentation visuelle
qui reflète un ensemble de données fourni en entrée. Quel rôle occupe donc
l’infographie en visualisation ?
Pour répondre à cette question, on introduit le problème très simple d’effectuer le rendu
du graphique associé à une fonction à deux variables f (x, y ) = z. En visualisation, un
tel graphique porte le nom de carte de hauteur.
Avec cet exemple, on introduira plusieurs concepts centraux eu processus de
visualisation tels que les ensemble de données, l’échantillonnage, le rendu, etc.
Introduction 26 / 76Infographie et visualisation Un premier exemple
Un premier exemple
Soit une fonction f : D → R, où D ⊂ R2 . Le graphique associé à f (x, y ) = z est une
surface 3D S ⊂ R3 définie par les points (x, y , z).
Aussi simple ce problème soit-il, il soulève plusieurs questions importantes :
Comment représenter informatiquement la fonction f et le domaine D ?
Comment représenter visuellement la surface S ?
Toutes ces questions ramènent à la notion de représentation numérique de données
continues. La solution tient en un mot : échantillonnage.
Introduction 27 / 76Infographie et visualisation Un premier exemple
Un premier exemple
Aux fins de l’exemple, supposons que le domaine D est échantillonné à l’aide de Nx × Ny
points positionnés à égale distance les unes des autres. Il est alors question
d’échantillonnage uniforme.
2 2
Posons Nx = Ny = 30 et f (x, y ) = e−(x +y ) définie sur D = [−1, 1]2 . On aura alors la
2.1. A Simple Example 23
représentation graphique intuitive suivante :
[5]
2
+y 2 )
Figure 2.1. Elevation plot for the function f (x, y) = e−(x drawn using 30 × 30
sample points.
Introduction 28 / 76Infographie et visualisation Un premier exemple
Un premier exemple
Le nombre d’échantillons Nx × Ny à utiliser aura un impact important sur la performance
de notre algorithme de visualisation de la carte de hauteur.
Un grand nombre d’échantillons produira un rendu plus représentatif de la fonction
f (x, y ), mais sera plus gourmand en puissance de calcul et en espace mémoire.
Un petit nombre d’échantillons permettra d’obtenir un résultat plus rapidement en
26 2. From Graphics to Visualization
sacrifiant de la précision.
[5]
2
+y 2 )
Figure 2.2. Elevation plot for the function f (x, y) = e−(x . A coarse grid of 10 × 10
samples is used.
Introduction 29 / 76Infographie et visualisation Un premier exemple
Un premier exemple
Une (bonne) solution à ce problème consiste à utiliser un échantillonnage adaptatif
plutôt qu’un échantillonnage uniforme. La théorie du traitement du signal nous a appris
que la densité locale des échantillons doit être proportionnelle à la fréquence
locale de la fonction continue.
1
Pour illustrer ce principe, posons g(x, y ) = sin définie sur le même domaine D
x2 + y2
que précédemment. La figure suivante illustre un rendu construit à partir de 100 × 100
2.1. A Simple Example 27
échantillons uniformément distribués.
[5]
(a) (b)
Figure 2.3. Elevation plot for the function f (x, y) = sin 1
x2 +y 2
, rendered using (a) a
Introduction 30 / 76Infographie et visualisation Un premier exemple
Un premier exemple
À l’opposé, la figure suivante présente un résultat où la densité des échantillons est
inversement proportionnelle à la distance à l’origine, mais où le nombre
2.1. A Simple Example 27
d’échantillons est le même que dans la figure précédente.
[5]
(a) (b)
Figure 2.3. Elevation plot for the function f (x, y) = sin x2 +y
1
2 , rendered using (a) a
la représentation
Le sujet deuniform des données sera approfondi à la section suivante.
grid of 100 × 100 samples and (b) an adaptively sampled grid.
approach the origin x = y = 0.1 Figure 2.3(a) shows the elevation plot of this
function constructed from a grid of 100 by 100 samples. Even though this plot
has roughly 10 times more sample points than the one shown in Figure 2.1 for
the Gaussian Introduction
function, the resulting quality is clearly poor close to the origin. 31 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
Un premier exemple
Rappels d’infographie
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 32 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
L’objectif de l’infographie est la production d’images d’une scène 3D. Pour atteindre cet
objectif, il faut avoir des objets 3D, un ensemble de lumières et une caméra virtuelle.
La production de l’image se fera en appliquant l’équation du rendu à chaque point de la
surface de chaque objet.
Z
Équation du rendu : I(p, v ) = Le (p, v ) + f (p, v , ωi )Li (p, ωi ) |cos θi | dωi
S2
En pratique, on se contentera d’évaluer une approximation de l’équation du rendu. En
particulier, on se limitera au calcul de l’illumination locale.
Introduction 33 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
Pour approximer l’équation du rendu, on fera appel au modèle d’illumination de Phong
qui est décrit par l’équation suivante :
I(p, v , L) = camb + Il (cdiff max(−L · n, 0) + cspec max(r · v , 0)α ) .
2.2. Graphics-Rendering Basics 29
observer light
r n L
l
v
p-l
p
object surface
[5]
Figure 2.4. The Phong local lighting model.
Introduction 34 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
En théorie, l’équation du rendu doit être appliquée pour chaque point de la surface de
chaque objet afin d’en déterminer la couleur. Toutefois, il peut être beaucoup plus
efficace de faire appel à des techniques de lissage dont le but est de limiter le nombre
de points où l’équation du rendu doit réellement être évaluée.
Le modèle de lissage le plus simple proposé par les moteurs graphiques est le lissage
plat (flat shading) où l’équation du rendu n’est calculée qu’une seule fois par polygone, et
la couleur obtenue est supposée constante sur toute la surface.
Introduction 35 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
Les résultats de la section précédente étaient obtenus avec du lissage plat.
26 2. From Graphics to Visualization
2.1. A Simple Example 23
[5]
2
2
+y 2 ) +y 2 )
Figure 2.2. Elevation plot for the function f (x, y) = e−(x . A coarse Figure
grid of2.1.
10 ×Elevation
10 plot for the function f (x, y) = e−(x drawn using 30 × 30
samples is used. sample points.
Comparing this image with the previous one (Figure 2.1), we see number of pixels on a computer screen to draw. Hence, the natural way to
that reduc-
ing the sample density yields a worse approximation of the surface generate
S. Thisan iselevation plot is to draw the surface points (xi , yi , f (xi , yi )) that
correspond
especially visible close to the center point x = y = 0. Basically, our renderedto a given finite set of sample points {xi , yi } in the variable domain
D. Figure 2.1 shows the pseudocode of what is probably the most-used method
surface approximates the continuous one with a set of quadrilaterals determined
to draw an elevation plot. We sample the function definition domain X × Y with
Introduction
by the sample point locations and function values. The quality of this approx- 36 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
Bien que simple et efficace, cette approche du lissage ne produira pas des résultat de
qualité suffisante pour nos besoins.
On lui préférera souvent le lissage de Gouraud (smooth shading) qui consiste à évaluer
l’équation du rendu à chaque sommet de chaque polygone pour ensuite estimer la
34 2. From Graphics to Visualization
couleur des autres points par interpolation.
[5]
2
+y 2 )
Figure 2.5. Elevation plot for the function f (x, y) = e−(x (Gouraud shaded).
Introduction 37 / 76Infographie et visualisation Rappels d’infographie
Rappels d’infographie
Un élément important dans le calcul de l’équation du rendu pour un point est le vecteur
normal à la surface de l’objet pour cepoint. Pour une
fonction f (x, y ), la normale à un
∂f ∂f
point sera donnée par le vecteur n = − , − , 1 .
∂x ∂y
Dans le cas où on ne dispose pas d’une fonction analytique, mais plutôt d’un ensemble
de données pour décrire notre objet, on évaluera la normale en un point en trouvant la
normale moyenne de tous les polygones partageant ce point.
Introduction 38 / 76Infographie et visualisation or transforms,
Rappels which are described next.
d’infographie
Virtual camera. The first step in specifying how to view a 3D scene is t
Caméra virtuelle where from, and in which direction, we want to look at the scene. Th
way to picture this is to imagine that we have a virtual photo camera
want to point at the scene in a specific way. In OpenGL, such a cam
be specified by indicating its location (also called the eye position e), a
Toutes les images de la carte de hauteur présentent celle-ci selon le même point de vue.
towards which the camera is pointing (also called the center position
Pour obtenir le rendu d’une scène, il importe devector
définir
u indicating caméra
une how virtuelle
the camera à partir
is rotated around desdirect
the viewing
(also called the “up” vector). Figure 2.9 illustrates this. The plane or
paramètres extrinsèques suivants : to the viewing direction, on which the final image will appear, is also c
view plane.
u
z
une position dans l’espace 3D ; (c-e)×u
e
une direction vers laquelle pointe la caméra ; c-e view pla
ne
c
une orientation autour de la direction de regard.
x
y
[5]
Figure 2.9. Extrinsic parameters of the OpenGL camera.
Introduction 39 / 76Infographie et visualisation Rappels d’infographie
Caméra virtuelle
Il sera aussi nécessaire de spécifier des paramètres intrinsèques à la caméra fin de
pouvoir modéliser le processus de projection.
2.6. Viewing 45
far c
lippin
g pla
ne
u
view
plan
e
view
area
tum
view frus
fov c-e
e
znear
zfar (c-e)×u
[5]
Figure 2.10. Intrinsic parameters of the OpenGL camera.
view plane beyond which the camera “sees” no objects. This plane is also called
Introduction 40 / 76Infographie et visualisation Rappels d’infographie
Caméra virtuelle
46 2. From Graphics to Visualization
screen window
u
view viewport
plan
e
view
area
viewport
height
transform
H
e x
(c-e) y width
×u
W [5]
Figure 2.11. OpenGL viewport transform from view area on the view plane to a screen
area.
Ce bref rappel d’infographie ne se
make objects further away from the ni
voulait viewexhaustif, ni rigoureux.
plane appear smaller (an effect also Si certaines notions
called foreshortening), are also supported by OpenGL, by using the
vous semblaient lointaines, il pourra être judicieux de réviser, en temps et lieux, la matière
gluOrtho2D
function
du cours d’infographie.
gluOrtho2D ( xlef t , xright , ybottom , ytop )
The values xlef t , xright , ybottom , and ytop define the positions of the four edges of
the view area rectangle on the view plane, with respect to the intersection point
Introduction
of the view direction with this plane. This effectively creates a parallelepiped- 41 / 76Représentation des données
Représentation des données
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 42 / 76Représentation des données
Continuité
Mathématiquement, un ensemble de données continues peut être modélisé par une
fonction f : D → C, où D ⊂ Rd est le domaine et où C ⊂ Rc est l’image de la fonction f .
Cette dernière sera continue si, pour chaque point p ∈ D, on a que ∀ > 0, ∃ δ > 0 tel
que si ||x − p|| < δ et x ∈ C, alors ||f (x) − f (p)|| < .
y
f(x)
x x
En d’autres mots, une fonction sera continue si sa représentation graphique ne présente
aucun trou ou saut...
Introduction 43 / 76∀ > 0, ∃δ > 0 such that if x − p < δ, x ∈ C then f (x) − f (p) < . (3.1)
Représentation des données
This continuity criterion is known as the Cauchy criterion, after the French
Continuité eighteenth-century mathematician who proposed it, or the − δ criterion, a
name that follows from its formulation.
What does continuity mean in the intuitive sense? In plain terms, a function
is continuous if the graph of the function is a connected surface without “holes”
or “jumps.” Furthermore, we say that a function f is continuous of order k if
La continuité the
desfunction itself and
dérivées all its
d’une derivatives
fonction up to and également
présente including orderunk are also en
intérêt
continuous in this sense. This is denoted as f ∈ C k . Figure 3.1 illustrates
k
visualisation. On dira qu’une fonction f est continue d’ordre k (f ∈ C ) si la fonction
the continuity concept for the case of a one-dimensional function f : R → R,
elle-même, de whose
même queis ses
graph k premières
displayed in green. Thedérivées sont
first image continues.
(Figure 3.1(a)) shows a
function having a discontinuity at the points x0 . Clearly, if we evaluate the
a
f(x) f(x) f(x)
b
f '(x) f '(x) f '(x)
x0 x x1 x2 x x0 x [5]
(a) (b) (c)
Figure 3.1. Function continuity. (a) Discontinuous function. (b) First-order C 0 contin-
uous function. (c) High-order C k continuous function.
Introduction 44 / 76Représentation des données
Continuité
Soit d la dimension de l’espace Rd contenant le domaine D de la fonction f . On dira que
d est la dimension géométrique de l’ensemble de données. Soit s, la dimension réelle
du domaine D. On appellera s la dimension topologique de l’ensemble de données.
Introduction 45 / 76Représentation des données
Continuité
Exemple : le rouleau Suisse.
Quelle est la dimension géométrique ?
Quelle est la dimension topologique ?
Introduction 46 / 76Représentation des données
Continuité
De manière générale, toutes les applications de visualisation fixeront la dimension
géométrique à d = 3. Cela signifie que la dimension topologique d’un ensemble de
données à visualiser pourra être s ≤ 3.
Il importe aussi de mentionner le cas particulier de la dimension temporelle.
Habituellement, on ne considérera pas le temps comme une dimension en tant que tel.
On préférera grandement produire une séquence de représentations visuelles pour
illustrer l’évolution temporelle des données que de représenter le temps comme une
dimension de l’ensemble.
Introduction 47 / 76Représentation des données
Échantillonnage
Lorsqu’il est question d’échantillonnage, deux opérations de base doivent pouvoir être
exécutées sur les données :
à partir d’un ensemble de données continues, on doit pouvoir produire un ensemble
de données discrètes par échantillonnage ;
à partir d’un ensemble de données discrètes ayant une signification continue, on doit
pouvoir produire une approximation des données continues originales par
reconstruction.
Introduction 48 / 76Représentation des données
Échantillonnage
L’échantillonnage d’un ensemble de données continues est un sujet qui a été
brièvement abordé dans la section précédente, mais qui a été largement approfondi dans
d’autres cours du programme.
On se limitera donc à dire que pour être valide, un ensemble de données discrètes
obtenues par échantillonnage doit être précis, minimal, générique, efficace et simple.
64 3. Data Representation
fi
sampling
xi
[5]
(a) continuous f (b) sample points xi and values fi
Introduction reconstruction 49 / 76Représentation des données
Échantillonnage
64 3. Data Representation
fi
La reconstruction des données continues est un sujet moins populaire et la place qui lui
est réservée est minime... et ce cours nesampling
fera pas exception. On se contentera de
mentionner l’importance de disposer, pour un échantillonnage donné, de fonctions de
base permettant d’assurer une bonne reconstruction. xi
(a) continuous f (b) sample points xi and values fi
reconstruction
~
[5]
(d) reconstructed f
transform T 1 1
1 1 2
Introduction 50 / 76Pipeline de visualisation
Pipeline de visualisation
1 Présentation du plan de cours
2 Mise en contexte
3 Infographie et visualisation
4 Représentation des données
5 Pipeline de visualisation
6 Références
Introduction 51 / 76Pipeline de visualisation
Pipeline de visualisation
L’objectif de la visualisation est de représenter visuellement des données qui ne
possèdent pas nécessairement d’interprétation géométrique naturelle.
On s’intéresse ici à la structure complète d’un logiciel de visualisation. Ce processus
porte le nom de pipeline de visualisation et est composé de quatre grandes étapes :
1 l’acquisition des données
2 le filtrage
3 le mappage
4 le rendu
Introduction 52 / 76Pipeline de visualisation
Pipeline de visualisation
imported enriched 2D/3D final
raw data dataset dataset shape image
f(x,y)→R3
import filter map render
{0,2,-5,...}
data acquisition data enriching, map abstract draw visual
transformation, data to visual representations
resampling... representations
measuring
device or end user
simulation insight into the original phenomenon
[5]
Introduction 53 / 76Pipeline de visualisation
Pipeline de visualisation
Base de
Simulation Capteurs
données
Acquisition des données
Données brutes
Filtrage
Données à
visualiser
Primitives graphiques :
- Points
Mappage
- Lignes
- Surfaces Représentation
- Volumes
Attributs : affichable
- Couleur
- Texture
- Transparence
Rendu
Affichage
Introduction 54 / 76Pipeline de visualisation
Acquisition
Base de
Simulation Capteurs
données
Acquisition des données
Données brutes
L’acquisition des données brutes peut être faite de différentes façons : par des
simulations (calculs informatiques), des enquêtes statistiques, des bases de données
historiques, des capteurs de mesures réelles, etc.
Introduction 55 / 76Pipeline de visualisation
Acquisition
En pratique, l’acquisition peut inclure différentes modifications aux données originales :
Modification de l’étendue ([min, max] −→ [0, 1])
Échantillonnage (Continu −→ Discret)
Rééchantillonnage (Discret −→ Discret)
Il faut garder à l’esprit que les choix faits lors de l’acquisition détermineront la qualité de
la représentation graphique que l’on sera en mesure d’obtenir.
Introduction 56 / 76Pipeline de visualisation
Filtrage
Données brutes
Filtrage
Données à
visualiser
Le filtrage prépare les données brutes pour la suite du traitement. On peut par exemple
éliminer des données inutiles, faire du débruitage ou faire de la segmentation.
Introduction 57 / 76Pipeline de visualisation
Filtrage
Attardons-nous à la pertinence de cette étape en s’intéressant à deux exemples,
provenant de deux domaines différents :
l’imagerie médicale
la finance
Introduction 58 / 76Pipeline de visualisation
Filtrage
Introduction 59 / 76Pipeline de visualisation
Filtrage
En imagerie médicale, un scanneur IRM ou CT fournit énormément d’information...
souvent beaucoup plus qu’il n’en faut.
À la suite d’un AVC, par exemple, les médecins s’intéresseront avant tout au système
sanguin, tandis que suite à une fracture, c’est l’information sur la structure osseuse qui
sera considérée comme pertinente.
Introduction 60 / 76Pipeline de visualisation
Filtrage
Introduction 61 / 76Pipeline de visualisation
Filtrage
En finances, une analyste reçoit de l’information sur le cours de l’ensemble des
actions à la bourse.
Il peut toutefois n’être qu’intéressé par la valeur de celles d’une seule compagnie, de
toutes les entreprises dans un domaine particulier, ou encore par les titres que détient
un client.
Introduction 62 / 76Pipeline de visualisation
Mappage
Données à
visualiser
Mappage
Représentation
affichable
Le mappage est l’étape centrale du processus de visualisation. On cherche à mettre en
correspondance les données avec des primitives graphiques connues.
On cherche ici à répondre au quoi et comment qu’on veut visualiser.
Introduction 63 / 76Pipeline de visualisation
Mappage
Le mappage est différent du rendu ; celui-ci a pour but de simuler une représentation
graphique (scène) afin de faciliter l’examination des données.
[5]
Introduction 64 / 76Pipeline de visualisation
Mappage
En plus des propriétés géométriques qui dépendent de la nature des données, on peut
faire correspondre des attributs visuels comme la couleur et la texture aux données.
mapping rendering
}
0 1 3
1 2 4
3 4 6
4 5.8 11
abstract visual features rendered
dataset dataset [5] image
Introduction map height to recognize height 65 / 76
}Pipeline de visualisation
Mappage
Données à
visualiser
Mappage
Représentation
affichable
Données Primitive graphique
Scalaires 2D Isocontour
Scalaires 2D Carte de hauteurs
Scalaires 3D Isosurface
Vecteurs 2D/3D Champ vectoriel
Tenseurs 2D/3D Champ de glyphes
Introduction 66 / 76Pipeline de visualisation
Mappage
Tel que mentionné précédemment, le mappage est l’étape centrale du processus de
visualisation. Les autres opérations du pipeline font essentiellement appel à des
techniques provenant d’autres disciplines telles que les statistiques, le traitement de
signal et l’infographie. Ce n’est donc pas un hasard si les chapitres suivants porteront
essentiellement sur cette portion du processus.
Parmi les propriétés que doit avoir le mappage, on retrouve l’injectivité. C’est donc dire
que deux données différentes x1 6= x2 doivent correspondre à des valeurs d’attributs
visuels différents MAP(x1 ) 6= MAP(x2 ).
Introduction 67 / 76Pipeline de visualisation
Mappage
À titre d’exemple, considérons la carte de hauteur d’une fonction z = f (x, y ).
On doit être en mesure d’inverser mentalement la représentation graphique pour
estimer les valeurs relatives de z. Si le mappage n’est pas injectif, deux valeurs de z
différentes pourraient avoir la même hauteur dans la carte.
Introduction 68 / 76Pipeline de visualisation
Mappage
Une autre propriété fort utile pour le mappage est celle de conservation des distances.
Si deux points sont séparés par une distance d dans l’espace des données, alors leur
distance d 0 dans l’espace de visualisation devrait refléter la distance originale.
La façon la plus simple d’y arriver est de maintenir une relation de proportionnalité
directe entre les distances.
Introduction 69 / 76Pipeline de visualisation
Mappage
Soient quatre points x1 , x2 , x3 et x4 tels que
d(x1 , x2 ) = di
d(x3 , x4 ) = dj
dans l’espace des données. Si dans l’espace de visualisation ces distances deviennent di0
et dj0 , respectivement, on devra avoir que
di d0
= i0 .
dj dj
Introduction 70 / 76Pipeline de visualisation
Rendu
Représentation
affichable
Rendu
Affichage
Dans l’étape de rendu, les données géométriques sont converties en information
visuelle. Pour atteindre un bon niveau de détails, on applique des techniques appartenant
au domaine de l’infographie (illumination, textures, projection, etc.)
Introduction 71 / 76Pipeline de visualisation
Sources d’erreur
Chaque étape du pipeline peut être la source de plusieurs erreurs. Celles-ci peuvent
grandement altérer les résultats jusqu’à les rendre complètement faux. Il est donc crucial
de savoir comment minimiser les erreurs en évitant certains pièges.
1 Acquisition des données
L’échantillonnage est-il assez précis pour qu’on soit en mesure d’obtenir l’information
souhaitée ? Inversement, est-il trop fin ? Il ne faut pas considérer des données inutiles
qui ne feraient qu’alourdir les calculs.
Est-ce que la quantification se fait avec assez de précision pour être en mesure de faire
ressortir les caractéristiques souhaitées ?
Introduction 72 / 76Pipeline de visualisation
Sources d’erreur
2 Filtrage
Conserve-t-on les données importantes et significatives ? Au contraire, élimine-t-on les
données non pertinentes à l’extraction des caractéristiques souhaitées ?
S’il est nécessaire d’ajouter des données par interpolation, quelle forme doivent prendre
celles-ci ? À partir de quels points doit-on faire l’interpolation ? Les données ajoutées
sont elles représentatives du reste ?
3 Mappage
Le choix de la primitive graphique est il approprié pour représenter le type d’information
que l’on souhaite obtenir des données ?
Introduction 73 / 76Pipeline de visualisation
Sources d’erreur
4 Rendu
Cherche-t-on à avoir un rendu interactif ? Si oui, des compromis devront être faits sur les
techniques utilisées pour permettre une navigation rapide à travers les données.
Il est important de savoir où seront affichées les images et de considérer les limitations
techniques pour ne pas inutilement faire de rendus complexes.
L’ajout de réalisme (illumination, transparence, etc.) n’ajoute pas nécessairement de
valeur informative à vos images. Plus beau ne rime pas toujours avec plus significatif.
Introduction 74 / 76Pipeline de visualisation
Pipeline de visualisation
imported enriched 2D/3D final
raw data dataset dataset shape image
f(x,y)→R3
import filter map render
{0,2,-5,...}
data acquisition data enriching, map abstract draw visual
transformation, data to visual representations
resampling... representations
measuring
device or end user
simulation insight into the original phenomenon
[5]
Introduction 75 / 76Références
Références
M. Chamberland, D. Fortin, and M. Descoteaux.
Cerebral infiltration http://www.neurobureau.org/galleries/brain-art-competition-2012/.
Delta Air Lines.
North America Route Maps - https://www.delta.com/content/dam/delta-www/pdfs/route-maps/us-route-map.pdf.
Ride with GPS.
07/23/17 - A bike ride in Gaspé, Québec - https://ridewithgps.com/trips/16306584.
Strava.
Afternoon Activity | Snowboard - https://www.strava.com/activities/1342321609.
A. C. Telea.
Data Visualization Principles and Practice Second Edition.
CRC Press, 2015.
Université de Sherbrooke.
IMN430 - Visualisation - https://www.usherbrooke.ca/admission/fiches-cours/imn430/.
Windy.com.
Windy : Wind map & weather forecast - https://www.windy.com/.
Introduction 76 / 76Vous pouvez aussi lire

















































