JFPDA PFIA 2021 Journées Francophones sur la Planification, la Décision et l'Apprentissage pour la conduite de systèmes
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
JFPDA
Journées Francophones sur
la Planification, la Décision et l’Apprentissage
pour la conduite de systèmes
PFIA 2021
Crédit photo : Flicr/xlibber

Table des matières François Schwarzentruber Éditorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 Comité de programme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5 Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud Grounding Language to Autonomously-Acquired Skills via Goal Generation. . . . . . . . . . . . . . . . . . . . . .6 Aurélien Delage, Olivier, Jilles Dibangoye HSVI pour zs-POSG usant de propriétés de convexité, concavité, et Lipschitz-continuité . . . . . . 21 Sergej Scheck, Alexandre Niveau, Bruno Zanuttini Explicit Representations of Persistency for Propositional Action Theories . . . . . . . . . . . . . . . . . . . . . . . 35 Yang You, Vincent Thomas, Francis Colas, Olivier Buffet Résolution de Dec-POMDP à horizon infini à l’aide de contrôleurs à états finis dans JESP . . . . 43 Sébastien Gamblin, Alexandre Niveau, Maroua Bouzid Vérification symbolique de modèles pour la logique épistémique dynamique probabiliste. . . . . . .59 Arthur Queffelec, Ocan Sankur, François Schwarzentruber Planning for Connected Agents in a Partially Known Environment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .71
Éditorial
Journées Francophones sur
la Planification, la Décision et l’Apprentissage
pour la conduite de systèmes
Les Journées Francophones Planification, Décision et Apprentissage (JFPDA) ont pour but de rassembler la
communauté de chercheurs francophones travaillant sur les problèmes d’apprentissage par renforcement, de la
théorie du contrôle, de programmation dynamique et plus généralement dans les domaines liés à la prise de
décision séquentielle sous incertitude et à la planification. La conférence JFPDA est soutenue par le Collège
Représentation et Raisonnement de l’AFIA.
Nous remercions tous les membres du comité de programme pour leur travail de relecture.
François Schwarzentruber
JFPDA@PFIA 2021 4
Comité de programme
Président
— François Schwarzentruber (ENS Rennes, IRISA)
Membres
— Olivier Buffet (LORIA, INRIA)
— Alain Dutech (LORIA, INRIA)
— Humbert Fiorino (LIG, Grenoble)
— Andreas Herzig (CNRS, IRIT, Université de Toulouse)
— Jérôme Lang (CNRS LAMSADE, Université Paris-Dauphine)
— Frédéric Maris (Université Toulouse 3 Paul Sabatier, IRIT)
— Laetitia Matignon (LIRIS CNRS)
— Alexandre Niveau (GREYC, Université de Normandie)
— Damien Pellier (LIG, Grenoble)
— Sophie Pinchinat (IRISA, Rennes)
— Cédric Pralet (ONERA, Toulouse)
— Philippe Preux (Université de Lille)
— Emmanuel Rachelson (ISAE-SUPAERO)
— Régis Sabbadin (INRA)
— Abdallah Saffidine (The University of New South Wales)
— Olivier Sigaud (ISIR, UPMC)
— Florent Teichteil-Königsbuch (Airbus Central Resaerch & Technology)
— Vincent Thomas (LORIA, Nancy)
— Paul Weng (UM-SJTU Joint Institute)
— Bruno Zanuttini (GREYC, Normandie Univ. ; UNICAEN, CNRS, ENSICAEN)
5 JFPDA@PFIA 2021
Grounding Language to Autonomously-Acquired Skills via Goal Generation
Grounding Language to Autonomously-Acquired Skills via Goal Generation
Ahmed Akakzia*1 Cédric Colas∗2 Pierre-Yves Oudeyer2 Mohamed Chetouani1 Olivier Sigaud1
1
Sorbonne Université
2
INRIA
ahmed.akakzia@isir.upmc.fr
Résumé havioral diversity for a given language input. To resolve
L’objectif principal de cet article est de construire des these issues, we propose a new conceptual approach to
agents artificiels capables d’apprendre aussi bien en au- language-conditioned RL: the Language-Goal-Behavior
tonomie que sous l’assistance d’un tuteur humain. Pour architecture (LGB). LGB decouples skill learning and lan-
apprendre en autonomie, ces agents doivent être capa- guage grounding via an intermediate semantic representa-
bles de générer et poursuivre leurs propres buts ainsi tion of the world. To showcase the properties of LGB, we
que d’apprendre à partir de leurs propres signaux de ré- present a specific implementation called DECSTR. DEC -
STR is an intrinsically motivated learning agent endowed
compense. Pour apprendre sous assistance externe, ils
doivent interagir avec un tuteur et apprendre à suivre des with an innate semantic representation describing spatial
instructions basées sur du langage naturel. Nous pro- relations between physical objects. In a first stage (G→B),
posons une nouvelle architecture d’apprentissage par ren- it freely explores its environment and targets self-generated
forcement conditionné sur du langage : Language-Goal- semantic configurations. In a second stage (L→G), it trains
Behavior (LGB). Contrairement aux approches classiques, a language-conditioned goal generator to generate seman-
LGB découple l’apprentissage sensorimoteur et l’ancrage
tic goals that match the constraints expressed in language-
du langage grâce à une couche sémantique intermédi- based inputs. We showcase the additional properties of
LGB w.r.t. both an end-to-end LC - RL approach and a sim-
aire. Nous présentons DECSTR, une instance particulière
de LGB. DECSTR est intrinsèquement motivé et doté ilar approach leveraging non-semantic, continuous inter-
d’une représentation spatiale basée sur des prédicats que mediate representations. Intermediate semantic represen-
les enfants préverbaux maîtrisent. Nous comparons LGB tations help satisfy language commands in a diversity of
à l’approche bout-à-bout où la politique est directement ways, enable strategy switching after a failure and facili-
basée sur le langage (LC - RL) et à l’approche non séman- tate language grounding.
tique où la politique est conditionnée sur des buts représen- Keywords
tant des positions 3D. Nous montrons que LGB permet
de satisfaire les instructions langagières, d’apprendre des Artificial Intelligence, Deep Reinforcement Learning, Lan-
comportements plus diversifiés, de changer de stratégie en guage Grounding
cas d’échec et de faciliter l’ancrage du langage.
1 Introduction
Mots Clef
Developmental psychology investigates the interactions
Intelligence Artificielle, Apprentissage par Renforcement,
between learning and developmental processes that sup-
Ancrage du Langage.
port the slow but extraordinary transition from the behav-
Abstract ior of infants to the sophisticated intelligence of human
adults (Piaget, 1977; Smith & Gasser, 2005). Inspired by
We are interested in the autonomous acquisition of reper-
this line of thought, the central endeavour of developmen-
toires of skills. Language-conditioned reinforcement learn-
tal robotics consists in shaping a set of machine learning
ing (LC - RL) approaches are great tools in this quest,
processes able to generate a similar growth of capabili-
as they allow to express abstract goals as sets of con-
ties in robots (Weng et al., 2001; Lungarella et al., 2003).
straints on the states. However, most LC - RL agents are
In this broad context, we are more specifically interested
not autonomous and cannot learn without external instruc-
in designing learning agents able to: 1) explore open-
tions and feedback. Besides, their direct language con-
ended environments and grow repertoires of skills in a self-
dition cannot account for the goal-directed behavior of
supervised way and 2) learn from a tutor via language com-
pre-verbal infants and strongly limits the expression of be-
mands.
* Equal contribution. The design of intrinsically motivated agents marked a ma-
JFPDA@PFIA 2021 6Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud
jor step towards these goals. The Intrinsically Motivated Language - Behavior (LB) Language - Goal - Behavior (LGB) Known
or language-conditioned RL Semantic
Goal Exploration Processes family (IMGEPs), for exam- Langage language embedding
Goals
Encoder
ple, describes embodied agents that interact with their en- Langage inst.
Encoder language Semantic Goal
inst. OR
vironment at the sensorimotor level and are endowed with
embedding initial state Generator semantic goal
goal
the ability to represent and set their own goals, rewarding Policy state
Policy
action
themselves over completion (Forestier et al., 2017). Re-
state action
LG phase: language grounding GB phase: skill learning
cently, goal-conditioned reinforcement learning (GC - RL)
(language semantic goals) (semantic goals behavior)
LB phase: instruction following LGB phase: instruction-following
appeared like a viable way to implement IMGEPs and tar- (language behavior) (language semantic goals behavior)
get the open-ended and self-supervised acquisition of di-
verse skills. Figure 1: A standard language-conditioned RL architecture (left)
and our proposed LGB architecture (right).
Goal-conditioned RL approaches train goal-conditioned
policies to target multiple goals (Kaelbling, 1993; Schaul
et al., 2015). While most GC - RL approaches express goals
• It can exhibit a diversity of behaviors for any given
as target features (e.g. target block positions (Andrychow-
instruction,
icz et al., 2017), agent positions in a maze (Schaul et al.,
• It can switch strategy in case of failures.
2015) or target images (Nair et al., 2018)), recent ap-
Besides, we introduce an instance of LGB, named DEC -
proaches started to use language to express goals, as lan-
STR for DEep sets and Curriculum with SemanTic goal
guage can express sets of constraints on the state space (e.g.
Representations. Using DECSTR, we showcase the ad-
open the red door) in a more abstract and interpretable way
vantages of the conceptual decoupling idea. In the skill
(Luketina et al., 2019).
learning phase, the DECSTR agent evolves in a manipu-
However, most GC - RL approaches – and language-based
lation environment and leverages semantic representations
ones (LC - RL) in particular – are not intrinsically motivated
based on predicates describing spatial relations between
and receive external instructions and rewards. The IMAG -
physical objects. These predicates are known to be used
INE approach is one of the rare examples of intrinsically
by infants from a very young age (Mandler, 2012). DEC -
motivated LC - RL approaches (Colas et al., 2020). In any
STR autonomously learns to discover and master all reach-
case, the language condition suffers from three drawbacks.
able configurations in its semantic representation space.
1) It couples skill learning and language grounding. Thus,
In the language grounding phase, we train a Conditional
it cannot account for goal-directed behaviors in pre-verbal
Variational Auto-Encoder (C - VAE) to generate semantic
infants (Mandler, 1999). 2) Direct conditioning limits the
goals from language instructions. Finally, we can eval-
behavioral diversity associated to language input: a single
uate the agent in an instruction-following phase by com-
instruction leads to a low diversity of behaviors only result-
posing the first two phases. The experimental section in-
ing from the stochasticity of the policy or the environment.
vestigates three questions: how does DECSTR perform in
3) This lack of behavioral diversity prevents agents from
the three phases? How does it compare to end-to-end
switching strategy after a failure.
LC - RL approaches? Do we need intermediate representa-
To circumvent these three limitations, one can decouple
tions to be semantic? Code and videos can be found at
skill learning and language grounding via an intermediate
https://sites.google.com/view/decstr/.
innate semantic representation. On one hand, agents can
learn skills by targeting configurations from the semantic
representation space. On the other hand, they can learn to
2 Related Work
generate valid semantic configurations matching the con- Standard language-conditioned RL. Most approaches
straints expressed by language instructions. This genera- from the LC - RL literature define instruction following
tion can be the backbone of behavioral diversity: a given agents that receive external instructions and rewards (Her-
sentence might correspond to a whole set of matching con- mann et al., 2017; Chan et al., 2019; Bahdanau et al., 2018;
figurations. This is what we propose in this work. Cideron et al., 2019; Jiang et al., 2019; Fu et al., 2019), ex-
cept the IMAGINE approach which introduced intrinsically
Contributions. We propose a novel conceptual RL archi-
motivated agents able to set their own goals and to imagine
tecture, named LGB for Language-Goal-Behavior and pic-
new ones (Colas et al., 2020). In both cases, the language-
tured in Figure 1 (right). This LGB architecture enables an
condition prevents the decoupling of language acquisition
agent to decouple the intrinsically motivated acquisition of
and skill learning, true behavioral diversity and efficient
a repertoire of skills (Goals → Behavior) from language
strategy switching behaviors. Our approach is different, as
grounding (Language → Goals), via the use of semantic
we can decouple language acquisition from skill learning.
goal representation. To our knowledge, the LGB architec-
The language-conditioned goal generation allows behav-
ture is the only one to combine the following four features:
ioral diversity and strategy switching behaviors.
• It is intrinsically motivated: it selects its own (se-
mantic) goals and generates its own rewards, Goal-conditioned RL with target coordinates for block
• It decouples skill learning from language grounding, manipulation. Our proposed implementation of LGB,
accounting for infants learning, called DECSTR, evolves in a block manipulation domain.
7 JFPDA@PFIA 2021Grounding Language to Autonomously-Acquired Skills via Goal Generation
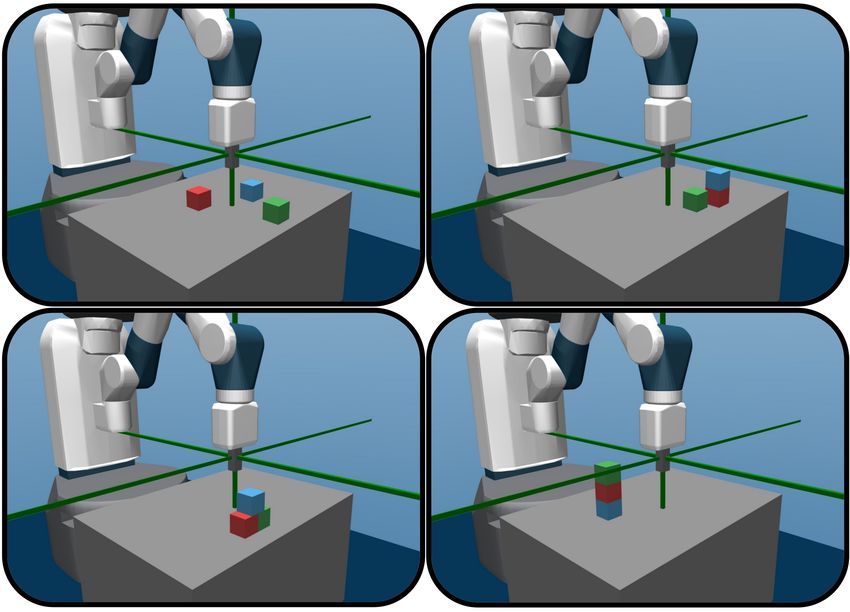
Stacking blocks is one of the earliest benchmarks in arti- Goal → Behavior, see Figure 1 and Appendix 6. Instances
ficial intelligence (e.g. Sussman (1973); Tate (1975)) and of the LGB architecture should demonstrate the four prop-
has led to many simulation and robotics studies (Deisen- erties listed in the introduction: 1) be intrinsically moti-
roth et al., 2011; Xu et al., 2018; Colas et al., 2019a). Re- vated; 2) decouple skill learning and language grounding
cently, Lanier et al. (2019) and Li et al. (2019) demon- (by design); 3) favor behavioral diversity; 4) allow strategy
strated impressive results by stacking up to 4 and 6 blocks switching. We argue that any LGB algorithm should ful-
respectively. However, these approaches are not intrinsi- fill the following constraints. For LGB to be intrinsically
cally motivated, involve hand-defined curriculum strategies motivated (1), the algorithm needs to integrate the gener-
and express goals as specific target block positions. In con- ation and selection of semantic goals and to generate its
trast, the DECSTR agent is intrinsically motivated, builds own rewards. For LGB to demonstrate behavioral diver-
its own curriculum and uses semantic goal representations sity and strategy switching (3, 4), the language-conditioned
(symbolic or language-based) based on spatial relations be- goal generator must efficiently model the distribution of se-
tween blocks. mantic goals satisfying the constraints expressed by any
Decoupling language acquisition and skill learning. language input.
Several works investigate the use of semantic representa- 3.2 Environment
tions to associate meanings and skills (Alomari et al., 2017;
Tellex et al., 2011; Kulick et al., 2013). While the two first
use semantic representations as an intermediate layer be-
tween language and skills, the third one does not use lan-
guage. While DECSTR acquires skills autonomously, previ-
ous approaches all use skills that are either manually gener-
ated (Alomari et al., 2017), hand-engineered (Tellex et al.,
2011) or obtained via optimal control methods (Kulick
et al., 2013). Closer to us, Lynch & Sermanet (2020) also
decouple skill learning from language acquisition in a goal-
conditioned imitation learning paradigm by mapping both
language goals and images goals to a shared representation
space. However, this approach is not intrinsically moti-
vated as it relies on a dataset of human tele-operated strate-
gies. The deterministic merging of representations also
limits the emergence of behavioral diversity and efficient
strategy-switching behaviors. Figure 2: Example configurations. Top-right: (111000100).
3 Methods The DECSTR agent evolves in the Fetch Manipulate en-
This section presents our proposed Language-Goal- vironment: a robotic manipulation domain based on MU -
Behavior architecture (LGB) represented in Figure 1 (Sec- JOCO (Todorov et al., 2012) and derived from the Fetch
tion 3.1) and a particular instance of the LGB architec- tasks (Plappert et al., 2018), see Figure 2. Actions are 4-
ture called DECSTR. We first present the environment it dimensional: 3D gripper velocities and grasping velocity.
is set in [3.2], then describe the implementations of the Observations include the Cartesian and angular positions
three modules composing any LGB architecture: 1) the se- and velocities of the gripper and the three blocks. Inspired
mantic representation [3.3]; 2) the intrinsically motivated by the framework of Zone of Proximal Development that
goal-conditioned algorithm [3.4] and 3) the language- describes how parents organize the learning environment of
conditioned goal generator [3.5]. We finally present how their children (Vygotsky, 1978), we let a social partner fa-
the three phases described in Figure 1 are evaluated [3.6]. cilitate DECSTR’s exploration by providing non-trivial ini-
3.1 The Language-Goal-Behavior Architec- tial configurations. After a first period of autonomous ex-
ploration, the social partner initializes the scene with stacks
ture of 2 blocks 21% of times, stacks of 3 blocks 9% of times,
The LGB architecture is composed of three main modules. and a block is initially put in the agent’s gripper 50% of
First, the semantic representation defines the behavioral times. This help is not provided during offline evaluations.
and goal spaces of the agent. Second, the intrinsically mo-
tivated GC - RL algorithm is in charge of the skill learning 3.3 Semantic Representation
phase. Third, the language-conditioned goal generator is in Semantic predicates define the behavioral space.
charge of the language grounding phase. Both phases can Defining the list of semantic predicates is defining the di-
be combined in the instruction following phase. The three mensions of the behavioral space explored by the agent. It
phases are respectively called G→B for Goal → Behavior, replaces the traditional definition of goal spaces and their
L → G for Language → Goal and L → G → B for Language → associated reward functions. We believe it is for the best, as
JFPDA@PFIA 2021 8Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud
it does not require the engineer to fully predict all possible defined goal buckets, we cluster goals based on their time
behaviors within that space, to know which behaviors can of discovery, as the time of discovery is a good proxy for
be achieved and which ones cannot, nor to define reward goal difficulty: easier goals are discovered earlier. Buck-
functions for each of them. ets are initially empty (no known configurations). When an
Semantic predicates in DECSTR. We assume the DEC - episode ends in a new configuration, the Nb = 5 buckets
STR agent to have access to innate semantic representations
are updated. Buckets are filled equally and the first buckets
based on a list of predicates describing spatial relations be- contain the configurations discovered earlier. Thus goals
tween pairs of objects in the scene. We consider two of the change buckets as new goals are discovered.
spatial predicates infants demonstrate early in their devel- Tracking competence, learning progress and sampling
opment (Mandler, 2012): the close and the above binary probabilities. Regularly, the DECSTR agent evaluates itself
predicates. These predicates are applied to all permuta- on goal configurations sampled uniformly from the set of
tions of object pairs for the 3 objects we consider: 6 per- known ones. For each bucket, it tracks the recent history of
mutations for the above predicate and 3 combinations for past successes and failures when targeting the correspond-
the close predicate due to its order-invariance. A seman- ing goals (last W = 1800 self-evaluations). C is estimated
tic configuration is the concatenation of the evaluations of as the success rate over the most recent half of that his-
these 9 predicates and represents spatial relations between tory C = Crecent . LP is estimated as the difference between
C recent and the one evaluated over the first half of the his-
objects in the scene. In the resulting semantic configura-
tion space {0, 1}9 , the agent can reach 35 physically valid tory (Cearlier ). This is a crude estimation of the derivative of
configurations, including stacks of 2 or 3 blocks and pyra- the C curve w.r.t. time: LP = Crecent - Cearlier . The sampling
mids, see examples in Figure 2. The binary reward function probability Pi for bucket i is:
directly derives from the semantic mapping: the agent re- (1 − Ci ) ∗ |LPi |
wards itself when its current configuration cp matches the Pi = P .
j ((1 − Cj ) ∗ |LPj |)
goal configuration cp = g. Appendix 7 provides formal
definitions and properties of predicates and semantic con- In addition to the usual LP bias (Colas et al., 2019a), this
figurations. formula favors lower C when LP is similar. The absolute
3.4 Intrinsically Motivated Goal- value ensures resampling buckets whose performance de-
creased (e.g. forgetting).
Conditioned Reinforcement Learning
Object-centered architecture. Instead of fully-
This section describes the implementation of the intrinsi-
connected or recurrent networks, DECSTR uses for the
cally motivated goal-conditioned RL module in DECSTR.
policy and critic an object-centered architecture similar
It is powered by the Soft-Actor Critic algorithm (SAC)
to the ones used in Colas et al. (2020); Karch et al.
(Haarnoja et al., 2018) that takes as input the current state,
(2020), adapted from Deep-Sets (Zaheer et al., 2017).
the current semantic configuration and the goal configu-
For each pair of objects, a shared network independently
ration, for both the critic and the policy. We use Hind-
encodes the concatenation of body and objects features and
sight Experience Replay (HER) to facilitate transfer be-
current and target semantic configurations, see Appendix
tween goals (Andrychowicz et al., 2017). DECSTR samples
Figure 6. This shared network ensures efficient transfer
goals via its curriculum strategy, collects experience in the
of skills between pairs of objects. A second inductive
environment, then performs policy updates via SAC. This
bias leverages the symmetry of the behavior required
section describes two particularities of our RL implemen-
to achieve above(oi , oj ) and above(oj , oi ). To ensure
tation: the self-generated goal selection curriculum and the
automatic transfer between the two, we present half of
object-centered network architectures. Implementation de-
the features (e.g. those based on pairs (oi , oj ) where
tails and hyperparameters can be found in Appendix 8.
i < j) with goals containing one side of the symmetry (all
Goal selection and curriculum learning. The DECSTR above(oi , oj ) for i < j) and the other half with the goals
agent can only select goals among the set of semantic con- containing the other side (all above(oj , oi ) for i < j). As
figurations it already experienced. We use an automatic a result, the above(oi , oj ) predicates fall into the same
curriculum strategy (Portelas et al., 2020) inspired from slot of the shared network inputs as their symmetric coun-
the CURIOUS algorithm (Colas et al., 2019a). The DEC - terparts above(oj , oi ), only with different permutations
STR agent tracks aggregated estimations of its competence of object pairs. Goals are now of size 6: 3 close and 3
(C) and learning progress (LP). Its selection of goals to tar- above predicates, corresponding to one side of the above
get during data collection and goals to learn about during symmetry. Skill transfer between symmetric predicates
policy updates (via HER) is biased towards goals associated are automatically ensured. Appendix 8.1 further describes
with high absolute LP and low C. these inductive biases and our modular architecture.
Automatic bucket generation. To facilitate robust estima-
tion, LP is usually estimated on sets of goals with similar 3.5 Language-Conditioned Goal Generation
difficulty or similar dynamics (Forestier et al., 2017; Co- The language-conditioned goal generation module (LGG)
las et al., 2019a). While previous works leveraged expert- is a generative model of semantic representations condi-
9 JFPDA@PFIA 2021Grounding Language to Autonomously-Acquired Skills via Goal Generation
tioned by language inputs. It is trained to generate seman- in Appendix 8.2):
tic configurations matching the agent’s initial configuration 1. Pairs found in D, except pairs removed to form the
and the description of a change in one object-pair relation. following test sets. This calls for the extrapolation of
A training dataset is collected via interactions between a known initialization-effect pairs (ci , d) to new final
DECSTR agent trained in phase G → B and a social part- configurations cf (D contains only 20% of Cf on aver-
ner. DECSTR generates semantic goals and pursues them. age).
For each trajectory, the social partner provides a descrip- 2. Pairs that were removed from D, calling for a recom-
tion d of one change in objects relations from the initial bination of known effects d on known ci .
configuration ci to the final one cf . The set of possi- 3. Pairs for which the ci was entirely removed from D.
ble descriptions contains 102 sentences, each describing, This calls for the transfer of known effects d on un-
in a simplified language, a positive or negative shift for known ci .
one of the 9 predicates (e.g. get red above green). This 4. Pairs for which the d was entirely removed from D.
leads to a dataset D of 5000 triplets: (ci , d, cf ). From This calls for generalization in the language space, to
this dataset, the LGG is learned using a conditional Varia- generalize unknown effects d from related descriptions
tional Auto-Encoder (C - VAE) (Sohn et al., 2015). Inspired and transpose this to known ci .
by the context-conditioned goal generator from Nair et al. 5. Pairs for which both the ci and the d were entirely re-
(2019), we add an extra condition on language instruction moved from D. This calls for the generalizations 3 and
to improve control on goal generation. The conditioning 4 combined.
instruction is encoded by a recurrent network that is jointly
Instruction following phase L→G→B: DECSTR is in-
trained with the VAE via a mixture of Kullback-Leibler and
structed to modify an object relation by one of the 102
cross-entropy losses. Appendix 8.2 provides the list of sen-
sentences. Conditioned on its current configuration and in-
tences and implementation details. By repeatedly sampling
struction, it samples a compatible goal from the LGG, then
the LGG, a set of goals is built for any language input. This
pursues it with its goal-conditioned policy. We consider
enables skill diversity and strategy switching: if the agent
three evaluation settings: 1) performing a single instruc-
fails, it can sample another valid goal to fulfill the instruc-
tion; 2) performing a sequence of instructions without fail-
tion, effectively switching strategy. This also enables goal
ure; 3) performing a logical combination of instructions.
combination using logical functions of instructions: and is
The transition setup measures the success rate of the agent
an intersection, or is an union and not is the complement
when asked to perform the 102 instructions 5 times each,
within the known set of goals.
resetting the environment each time. In the expression
3.6 Evaluation of the three LGB phases setup, the agent is evaluated on 500 randomly generated
logical functions of sentences, see the generation mecha-
Skill learning phase G→B: DECSTR explores its seman- nism in Appendix 8.2. In both setups, we evaluate the per-
tic representation space, discovers achievable configura- formance in 1-shot (SR1 ) and 5-shot (SR5 ) settings. In the
tions and learns to reach them. Goal-specific performance 5-shot setting, the agent can perform strategy switching, to
is evaluated offline across learning as the success rate sample new goals when previous attempts failed (without
(SR) over 20 repetitions for each goal. The global perfor- reset). In the sequence setup, the agent must execute 20 se-
mance SR is measured across either the set of 35 goals or quences of random instructions without reset (5-shot). We
discovery-organized buckets of goals, see Section 3.4. also test behavioral diversity. We ask DECSTR to follow
Language grounding phase L→G: DECSTR trains the each of the 102 instructions 50 times each and report the
LGG to generate goals matching constraints expressed via number of different achieved configurations.
language inputs. From a given initial configuration and
a given instruction, the LGG should generate all compati- 4 Experiments
ble final configurations (goals) and just these. This is the Our experimental section investigates three questions:
source of behavioral diversity and strategy switching be- [4.1]: How does DECSTR perform in the three phases?
haviors. To evaluate LGG, we construct a synthetic, oracle [4.2]: How does it compare to end-to-end language-
dataset O of triplets (ci , d, Cf (ci , d)), where Cf (ci , d) is conditioned approaches? [4.3]: Do we need intermediate
the set of all final configurations compatible with (ci , d). representations to be semantic?
On average, Cf in O contains 16.7 configurations, while
the training dataset D only contains 3.4 (20%). We are in- 4.1 How does DECSTR perform in the three
terested in two metrics: 1) The Precision is the probability phases?
that a goal sampled from the LGG belongs to Cf (true posi-
This section presents the performance of the DECSTR agent
tive / all positive); 2) The Recall is percentage of elements
in the skill learning, language grounding, and instruction
from Cf that were found by sampling the LGG 100 times
following phases.
(true positive / all true). These metrics are computed on
5 different subsets of the oracle dataset, each calling for a Skill learning phase G→B: Figures 3, 4, 5 show that
different type of generalization (see full lists of instructions DECSTR successfully masters all reachable configurations
JFPDA@PFIA 2021 10Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud
in its semantic representation space. Figure 3 shows the DECSTR Exp. Buckets Flat
evolution of SR computed per bucket. Buckets are learned w/o Curr. w/o Asym. w/o ZPD
in increasing order, which confirms that the time of dis-
covery is a good proxy for difficulty. Figure 4 reports 1.00
C , LP and sampling probabilities P computed online us-
Success Rate
ing self-evaluations for an example agent. The agent lever- 0.75
ages these estimations to select its goals: first focusing on
the easy goals from bucket 1, it moves on towards harder 0.50
and harder buckets as easier ones are mastered (low LP,
high C). Figure 5 presents the results of ablation studies. 0.25
Each condition removes one component of DECSTR: 1)
Flat replaces our object-centered modular architectures by 0.00
0 250 500 750 1000 1250
flat ones; 2) w/o Curr. replaces our automatic curriculum Episodes (x103)
strategy by a uniform goal selection; 3) w/o Sym. does not
use the symmetry inductive bias; 4) In w/o SP, the social Figure 5: Ablation study. Medians and interquartile ranges over
partner does not provide non-trivial initial configurations. 10 seeds for DECSTR and 5 seeds for others in (a) and (c). Stars
In the Expert buckets condition, the curriculum strategy is indicate significant differences to DECSTR as reported by Welch’s
applied on expert-defined buckets, see Appendix 9.1. The t-tests with α = 0.05 (Colas et al., 2019b).
full version of LGB performs on par with the Expert buck-
ets oracle and outperforms significantly all its ablations.
Appendix 10.3 presents more examples of learning trajec- Language grounding phase L→G: The LGG demon-
tories, and dissects the evolution of bucket compositions strates the 5 types of generalization from Table 1. From
along training. known configurations, agents can generate more goals than
they observed in training data (1, 2). They can do so
Bucket 1 Bucket 3 Bucket 5 from new initial configurations (3). They can generalize
1.00
Bucket 2 Bucket 4 Global to new sentences (4) and even to combinations of new sen-
tences and initial configurations (5). These results assert
that DECSTR generalizes well in a variety of contexts and
0.75
shows good behavioral diversity.
Success Rate
0.50 Table 1: L→G phase. Metrics are averaged over 10 seeds, stdev
< 0.06 and 0.07 respectively.
Metrics Test 1 Test 2 Test 3 Test 4 Test 5
0.25
Precision 0.97 0.93 0.98 0.99 0.98
Recall 0.93 0.94 0.95 0.90 0.92
0.00
0 200 400 600 800 1000 1200 1400
Episodes (x103)
Figure 3: Skill Learning: SR per bucket. Instruction following phase L→G→B: Table 2 presents
the 1-shot and 5-shot results in the transition and expres-
sion setups. In the sequence setups, DECSTR succeeds in
B1 B2 B3 B4 B5 L = 14.9 ± 5.7 successive instructions (mean±stdev
1.0 over 10 seeds). These results confirm efficient language
0.5 grounding. DECSTR can follow instructions or sequences
C
of instructions and generalize to their logical combina-
0.0 tions. Strategy switching improves performance (SR5 -
0.10 SR 1 ). DECSTR also demonstrates strong behavioral diver-
LP
0.05 sity: when asked over 10 seeds to repeat 50 times the same
0.00
instruction, it achieves at least 7.8 different configurations,
1.0 15.6 on average and up to 23 depending on the instruction.
0.5
P
Table 2: L→G→B phase. Mean ± stdev over 10 seeds.
0.00 Metr. Transition Expression
200 400 600 800 1000 1200 1400
SR 1 0.89 ± 0.05 0.74 ± 0.08
Episodes (x103)
SR 5 0.99 ± 0.01 0.94 ± 0.06
Figure 4: C, LP and P estimated by a DECSTR agent.
11 JFPDA@PFIA 2021Grounding Language to Autonomously-Acquired Skills via Goal Generation
4.2 Do we need an intermediate representa- The LGB - C baseline. The LGB - C baseline uses contin-
tion? uous goals expressing target block coordinates in place of
semantic goals. The skill learning phase is thus equiva-
This section investigates the need for an intermediate se-
lent to traditional goal-conditioned RL setups in block ma-
mantic representation. To this end, we introduce an end-
nipulation tasks (Andrychowicz et al., 2017; Colas et al.,
to-end LC - RL baseline directly mapping Language to Be-
2019a; Li et al., 2019; Lanier et al., 2019). Starting from
havior (L→B) and compare its performance with DECSTR
the DECSTR algorithm, LGB - C adds a translation module
in the instruction following phase (L→G→B).
that samples a set of target block coordinates matching the
The LB baseline. To limit the introduction of confound- targeted semantic configuration which is then used as the
ing factors and under-tuning concerns, we base this im- goal input to the policy. In addition, we integrate defining
plementation on the DECSTR code and incorporate defin- features of the state-of-the-art approach from Lanier et al.
ing features of IMAGINE, a state-of-the-art language con- (2019): non-binary rewards (+1 for each well placed block)
ditioned RL agent (Colas et al., 2020). We keep the same and multi-criteria HER, see details in Appendix 9.2.
HER mechanism, object-centered architectures and RL al-
gorithm as DECSTR. We just replace the semantic goal Comparison in skill learning phase G→B: The LGB -
C baseline successfully learns to discover and master all
space by the 102 language instructions. This baseline can
be seen as an oracle version of the IMAGINE algorithm 35 semantic configurations by placing the three blocks
where the reward function is assumed perfect, but without to randomly-sampled target coordinates corresponding to
the imagination mechanism. these configurations. It does so faster than DECSTR: 708 ·
103 episodes to reach SR= 95%, against 1238 · 103 for
Comparison in the instruction following phase L→B DECSTR , see Appendix Figure 8. This can be explained by
vs L→G→B: After training the LB baseline for 14K the denser learning signals it gets from using HER on con-
episodes, we compare its performance to DECSTR’s in the tinuous targets instead of discrete ones. In this phase, how-
instruction-following setup. In the transition evaluation ever, the agent only learns one parameterized skill: to place
setup, LB achieves SR1 = 0.76 ± 0.001: it always manages blocks at their target position. It cannot build a repertoire
to move blocks close to or far from each other, but consis- of semantic skills because it cannot discriminate between
tently fails to stack them. Adding more attempts does not different block configurations. Looking at the sum of the
help: SR5 = 0.76 ± 0.001. The LB baseline cannot be eval- distances travelled by the blocks or the completion time,
uated in the expression setup because it does not manipu- we find that DECSTR performs opportunistic goal reach-
late goal sets. Because it cannot stack blocks, LB only suc- ing: it finds simpler configurations of the blocks which sat-
ceeds in 3.01 ± 0.43 random instructions in a row, against isfy its semantic goals compared to LGB - C. Blocks move
14.9 for DECSTR (sequence setup). We then evaluate LB’s less (∆dist = 26 ± 5 cm), and goals are reached faster
diversity on the set of instructions it succeeds in. When (∆steps = 13 ± 4, mean±std across goals with p-values
asked to repeat 50 times the same instruction, it achieves > 1.3 · 10−5 and 3.2 · 10−19 respectively).
at least 3.0 different configurations, 4.2 on average and up
to 5.2 depending on the instruction against 7.8, 17.1, 23 on Table 3: LGB - C performance in the L→G phase. Mean over 10
the same set of instructions for DECSTR. We did not ob- seeds. Stdev < 0.003 and 0.008 respectively.
serve strategy-switching behaviors in LB, because it either
always succeeds (close/far instructions) or fails (stacks). Metrics Test 1 Test 2 Test 3 Test 4 Test 5
Conclusion. The introduction of an intermediate se- Precision 0.66 0.78 0.39 0.0 0.0
mantic representation helps DECSTR decouple skill learn- Recall 0.05 0.02 0.06 0.0 0.0
ing from language grounding which, in turns, facilitates
instruction-following when compared to the end-to-end
Comparison in language grounding phase L→G: We
language-conditioned learning of LB. This leads to im-
train the LGG to generate continuous target coordinates
proved scores in the transition and sequence setups. The
conditioned on language inputs with a mean-squared loss
direct language-conditioning of LB prevents the generaliza-
and evaluate it in the same setup as DECSTR’s LGG, see
tion to logical combination and leads to a reduced diversity
Table 3. Although it maintains reasonable precision in the
in the set of mastered instructions. Decoupling thus brings
first two testing sets, the LGG achieves low recall – i.e. di-
significant benefits to LGB architectures.
versity – on all sets. The lack of semantic representations
4.3 Do we need a semantic intermediate rep- of skills might explain the difficulty of training a language-
resentation? conditioned goal generator.
This section investigates the need for the intermediate rep- Conclusion. The skill learning phase of the LGB - C base-
resentation to be semantic. To this end, we introduce the line is competitive with the one of DECSTR. However, the
LGB - C baseline that leverages continuous goal representa- poor performance in the language grounding phase pre-
tions in place of semantic ones. We compare them on the vents this baseline to perform instruction following. For
two first phases. this reason, and because semantic representations enable
JFPDA@PFIA 2021 12Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud
agents to perform opportunistic goal reaching and to ac- goal sets. It would be of interest to simultaneously perform
quire repertoires for semantic skills, we believe the seman- language grounding and skill learning, which would result
tic representation is an essential part of the LGB architec- in “overlapping waves" of sensorimotor and linguistic de-
ture. velopment (Siegler, 1998).
Semantic configurations of variable size. Considering
5 Discussion and Conclusion a constant number of blocks and, thus, fixed-size configura-
This paper contributes LGB, a new conceptual RL archi- tion spaces is a current limit of DECSTR. Future implemen-
tecture which introduces an intermediate semantic repre- tations of LGB may handle inputs of variable sizes by lever-
sentation to decouple sensorimotor learning from language aging Graph Neural Networks as in Li et al. (2019). Corre-
grounding. To demonstrate its benefits, we present DEC - sponding semantic configurations could be represented as a
STR , a learning agent that discovers and masters all reach- set of vectors, each encoding information about a predicate
able configurations in a manipulation domain from a set and the objects it applies to. These representations could
of relational spatial primitives, before undertaking an effi- be handled by Deep Sets (Zaheer et al., 2017). This would
cient language grounding phase. This was made possible allow to target partial sets of predicates that would not need
by the use of object-centered inductive biases, a new form to characterize all relations between all objects, facilitating
of automatic curriculum learning and a novel language- scalability.
conditioned goal generation module. Note that our main
Conclusion In this work, we have shown that introduc-
contribution is in the conceptual approach, DECSTR being
ing abstract goals based on relational predicates that are
only an instance to showcase its benefits. We believe that
well understood by humans can serve as a pivotal repre-
this approach could benefit from any improvement in GC -
sentation between skill learning and interaction with a user
RL (for skill learning) or generative models (for language
through language. Here, the role of the social partner was
grounding).
limited to: 1) helping the agent to experience non-trivial
Semantic representations. Results have shown that us- configurations and 2) describing the agent’s behavior in a
ing predicate-based representations was sufficient for DEC - simplified language. In the future, we intend to study more
STR to efficiently learn abstract goals in an opportunis- intertwined skill learning and language grounding phases,
tic manner. The proposed semantic configurations show- making it possible to the social partner to teach the agent
case promising properties: 1) they reduce the complexity during skill acquisition.
of block manipulation where most effective works rely on
a heavy hand-crafted curriculum (Li et al., 2019; Lanier Acknowledgments
et al., 2019) and a specific curiosity mechanism (Li et al., This work was performed using HPC resources from
2019); 2) they facilitate the grounding of language into GENCI-IDRIS (Grant 20XX-AP010611667), the MeSU
skills and 3) they enable decoupling skill learning from platform at Sorbonne-Université and the PlaFRIM experi-
language grounding, as observed in infants (Piaget, 1977). mental testbed. Cédric Colas is partly funded by the French
The set of semantic predicates is, of course, domain- Ministère des Armées - Direction Générale de l’Armement.
dependent as it characterizes the space of behaviors that
the agent can explore. However, we believe it is easier and References
requires less domain knowledge to define the set of pred- Muhannad Alomari, Paul Duckworth, David C Hogg, and
icates, i.e. the dimensions of the space of potential goals, Anthony G Cohn. Natural language acquisition and
than it is to craft a list of goals and their associated reward grounding for embodied robotic systems. In Thirty-First
functions. AAAI Conference on Artificial Intelligence, 2017.
A new approach to language grounding. The approach
proposed here is the first simultaneously enabling to decou- Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas
ple skill learning from language grounding and fostering a Schneider, Rachel Fong, Peter Welinder, Bob Mc-
diversity of possible behaviors for given instructions. In- Grew, Josh Tobin, Pieter Abbeel, and Wojciech
deed, while an instruction following agent trained on goals Zaremba. Hindsight Experience Replay. arXiv preprint
like put red close_to green would just push the red block arXiv:1707.01495, 2017.
towards the green one, our agent can generate many match- Dzmitry Bahdanau, Felix Hill, Jan Leike, Edward Hughes,
ing goal configurations. It could build a pyramid, make a Arian Hosseini, Pushmeet Kohli, and Edward Grefen-
blue-green-red pile or target a dozen other compatible con- stette. Learning to understand goal specifications by
figurations. This enables it to switch strategy, to find alter- modelling reward. arXiv preprint arXiv:1806.01946,
native approaches to satisfy a same instruction when first 2018.
attempts failed. Our goal generation module can also gen-
eralize to new sentences or transpose instructed transfor- Harris Chan, Yuhuai Wu, Jamie Kiros, Sanja Fidler, and
mations to unknown initial configurations. Finally, with the Jimmy Ba. Actrce: Augmenting experience via teacher’s
goal generation module, the agent can deal with any logical advice for multi-goal reinforcement learning. arXiv
expression made of instructions by combining generated preprint arXiv:1902.04546, 2019.
13 JFPDA@PFIA 2021Grounding Language to Autonomously-Acquired Skills via Goal Generation
Geoffrey Cideron, Mathieu Seurin, Florian Strub, and generalization in RL. arXiv preprint arXiv:2003.09443,
Olivier Pietquin. Self-educated language agent with 2020.
hindsight experience replay for instruction following.
arXiv preprint arXiv:1910.09451, 2019. Johannes Kulick, Marc Toussaint, Tobias Lang, and
Manuel Lopes. Active learning for teaching a robot
Cédric Colas, Pierre-Yves Oudeyer, Olivier Sigaud, Pierre grounded relational symbols. In Twenty-Third Interna-
Fournier, and Mohamed Chetouani. CURIOUS: In- tional Joint Conference on Artificial Intelligence, 2013.
trinsically motivated multi-task, multi-goal reinforce-
ment learning. In International Conference on Machine John B. Lanier, Stephen McAleer, and Pierre Baldi.
Learning (ICML), pp. 1331–1340, 2019a. Curiosity-driven multi-criteria hindsight experience re-
play. CoRR, abs/1906.03710, 2019. URL http://
Cédric Colas, Olivier Sigaud, and Pierre-Yves Oudeyer. arxiv.org/abs/1906.03710.
A hitchhiker’s guide to statistical comparisons of
reinforcement learning algorithms. arXiv preprint Richard Li, Allan Jabri, Trevor Darrell, and Pulkit
arXiv:1904.06979, 2019b. Agrawal. Towards practical multi-object manipulation
using relational reinforcement learning. arXiv preprint
Cédric Colas, Tristan Karch, Nicolas Lair, Jean-Michel
arXiv:1912.11032, 2019.
Dussoux, Clément Moulin-Frier, Peter Ford Dominey,
and Pierre-Yves Oudeyer. Language as a cognitive tool
Jelena Luketina, Nantas Nardelli, Gregory Farquhar, Jakob
to imagine goals in curiosity-driven exploration. arXiv
Foerster, Jacob Andreas, Edward Grefenstette, Shimon
preprint arXiv:2002.09253, 2020.
Whiteson, and Tim Rocktäschel. A survey of rein-
Marc Peter Deisenroth, Carl Edward Rasmussen, and Di- forcement learning informed by natural language. arXiv
eter Fox. Learning to control a low-cost manipulator preprint arXiv:1906.03926, 2019.
using data-efficient reinforcement learning. Robotics:
Science and Systems VII, pp. 57–64, 2011. Max Lungarella, Giorgio Metta, Rolf Pfeifer, and Giulio
Sandini. Developmental robotics: a survey. Connection
Sébastien Forestier, Yoan Mollard, and Pierre-Yves Science, 15(4):151–190, 2003.
Oudeyer. Intrinsically motivated goal exploration pro-
cesses with automatic curriculum learning. arXiv Corey Lynch and Pierre Sermanet. Grounding language in
preprint arXiv:1708.02190, 2017. play. arXiv preprint arXiv:2005.07648, 2020.
Justin Fu, Anoop Korattikara, Sergey Levine, and Sergio Jean M. Mandler. Preverbal representation and language.
Guadarrama. From language to goals: Inverse rein- Language and space, pp. 365, 1999.
forcement learning for vision-based instruction follow-
ing. arXiv preprint arXiv:1902.07742, 2019. Jean M Mandler. On the spatial foundations of the concep-
tual system and its enrichment. Cognitive science, 36
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey (3):421–451, 2012.
Levine. Soft actor-critic: Off-policy maximum en-
tropy deep reinforcement learning with a stochastic ac- Ashvin Nair, Shikhar Bahl, Alexander Khazatsky, Vitchyr
tor. arXiv preprint arXiv:1801.01290, 2018. Pong, Glen Berseth, and Sergey Levine. Contex-
tual imagined goals for self-supervised robotic learning.
Karl Moritz Hermann, Felix Hill, Simon Green, Fumin
arXiv preprint arXiv:1910.11670, 2019.
Wang, Ryan Faulkner, Hubert Soyer, David Szepes-
vari, Wojciech Marian Czarnecki, Max Jaderberg, De- Ashvin V Nair, Vitchyr Pong, Murtaza Dalal, Shikhar
nis Teplyashin, et al. Grounded language learning in a Bahl, Steven Lin, and Sergey Levine. Visual reinforce-
simulated 3D world. arXiv preprint arXiv:1706.06551, ment learning with imagined goals. In Advances in
2017. Neural Information Processing Systems, pp. 9191–9200,
Yiding Jiang, Shixiang Shane Gu, Kevin P Murphy, and 2018.
Chelsea Finn. Language as an abstraction for hierarchi-
Jean Piaget. The development of thought: Equilibration of
cal deep reinforcement learning. In Advances in Neural
cognitive structures. Viking, 1977. (Trans A. Rosin).
Information Processing Systems, pp. 9414–9426, 2019.
Leslie Pack Kaelbling. Learning to achieve goals. In Inter- Matthias Plappert, Marcin Andrychowicz, Alex Ray, Bob
national Joint Conference on Artificial Intelligence, pp. McGrew, Bowen Baker, Glenn Powell, Jonas Schnei-
1094–1099, 1993. der, Josh Tobin, Maciek Chociej, Peter Welinder, et al.
Multi-goal reinforcement learning: Challenging robotics
Tristan Karch, Cédric Colas, Laetitia Teodorescu, Clément environments and request for research. arXiv preprint
Moulin-Frier, and Pierre-Yves Oudeyer. Deep sets for arXiv:1802.09464, 2018.
JFPDA@PFIA 2021 14Ahmed Akakzia, Cédric Colas, Pierre-Yves Oudeyer, Mohamed Chetouani, Olivier Sigaud
Rémy Portelas, Cédric Colas, Lilian Weng, Katja Hof- Supplementary Material
mann, and Pierre-Yves Oudeyer. Automatic curriculum
learning for deep RL: A short survey. arXiv preprint 6 LGB pseudo-code
arXiv:2003.04664, 2020.
Algorithm 1 and 2 present the high-level pseudo-code of
Tom Schaul, Daniel Horgan, Karol Gregor, and David Sil- any algorithm following the LGB architecture for each of
ver. Universal value function approximators. In Inter- the three phases.
national Conference on Machine Learning, pp. 1312–
1320, 2015. Algorithm 1 LGB architecture
G → B phase
Robert S Siegler. Emerging minds: The process of change
in children’s thinking. Oxford University Press, 1998. . Goal → Behavior phase
1: Require Env E
Linda Smith and Michael Gasser. The development of em- 2: Initialize policy Π, goal sampler Gs , buffer B
bodied cognition: Six lessons from babies. Artificial life, 3: loop
11(1-2):13–29, 2005. 4: g ← Gs .sample()
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning 5: (s, a, s0 , g, cp , c0p )traj ← E.rollout(g)
structured output representation using deep conditional 6: Gs .update(cTp )
generative models. In Advances in neural information 7: B.update((s, a, s0 , g, cp , c0p )traj )
processing systems, pp. 3483–3491, 2015. 8: Π.update(B)
9: return Π, Gs
Gerald J. Sussman. A computational model of skill acquisi-
10:
tion. Technical report, HIT Technical Report AI TR-297,
11:
1973.
12:
Austin Tate. Interacting goals and their use. In Interna-
tional Joint Conference on Artificial Intelligence, vol- Algorithm 2 LGB architecture
ume 10, pp. 215–218, 1975. L → G and L → G → B phases
Stefanie Tellex, Thomas Kollar, Steven Dickerson, . Language → Goal phase
Matthew R Walter, Ashis Gopal Banerjee, Seth Teller, 1: Require Π, E, Gs , social partner SP
and Nicholas Roy. Approaching the symbol grounding 2: Initialize language goal generator LGG
problem with probabilistic graphical models. AI maga- 3: dataset ← SP .interact(E, Π, Gs )
zine, 32(4):64–76, 2011. 4: LGG.update(dataset)
5: return LGG
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mu- . Language → Behavior phase
joco: A physics engine for model-based control. In 6: Require E, Π, LGG, SP
2012 IEEE/RSJ International Conference on Intelligent 7: loop
Robots and Systems, pp. 5026–5033. IEEE, 2012. 8: instr. ← SP .listen()
L. S. Vygotsky. Tool and Symbol in Child Development. In 9: loop . Strategy switching loop
Mind in Society, chapter Tool and Symbol in Child De- 10: g ← LGG.sample(instr., c0 )
velopment, pp. 19–30. Harvard University Press, 1978. 11: cTp ← E.rollout(g)
ISBN 0674576292. doi: 10.2307/j.ctvjf9vz4.6. 12: if g == cTp then break
J. Weng, J. McClelland, A. Pentland, O. Sporns, I. Stock-
man, M. Sur, and E. Thelen. Autonomous mental de-
7 Semantic predicates and applica-
velopment by robots and animals. Science, 291(5504): tion to fetch manipulate
599–600, 2001.
In this paper, we restrict the semantic representations to
Danfei Xu, Suraj Nair, Yuke Zhu, Julian Gao, Animesh the use of the close and above binary predicates applied to
Garg, Li Fei-Fei, and Silvio Savarese. Neural task M = 3 objects. The resulting semantic configurations are
programming: Learning to generalize across hierarchi- formed by:
cal tasks. In 2018 IEEE International Conference on
Robotics and Automation (ICRA), pp. 1–8. IEEE, 2018. F =[c(o1 , o2 ), c(o1 , o3 ), c(o2 , o3 ), a(o1 , o2 ),
a(o2 , o1 ), a(o1 , o3 ), a(o3 , o1 ), a(o2 , o3 ), a(o3 , o2 )],
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh,
Barnabas Poczos, Russ R Salakhutdinov, and Alexan-
der J Smola. Deep sets. In Advances in neural informa- where c() and a() refer to the close and above predicates
tion processing systems, pp. 3391–3401, 2017. respectively and (o1 , o2 , o3 ) are the red, green and blue
blocks respectively.
15 JFPDA@PFIA 2021Grounding Language to Autonomously-Acquired Skills via Goal Generation
Symmetry and asymmetry of close and above predi- Algorithm 3 DECSTR: sensorimotor phase G→B.
cates. We consider objects o1 and o2 . 1: Require: env E, # buckets Nb , # episodes before
• close is symmetric: “o1 is close to o2 " ⇔ “o2 is biased init. nunb , self-evaluation probability pself_eval ,
close to o1 ". The corresponding semantic mapping noise function σ()
function is based on the Euclidean distance, which is 2: Initialize: policy Π, buffer B, goal sampler Gs , bucket
symmetric. sampling probabilities pb , language module LGG.
• above is asymmetric: “o1 is above o2 " ⇒ not “o2 3: loop
is above o1 ". The corresponding semantic mapping 4: self_eval ← random() < pself_eval . If T rue then
function evaluates the sign of the difference of the evaluate competence
object Z-axis coordinates. 5: g ← Gs .sample(self_eval, pb )
6: biased_init ← epoch < nunb . Bias initialization
8 The DECSTR algorithm only after nunb epochs
8.1 Intrinsically Motivated Goal- 7: s0 , c0p ← E.reset(biased_init) . c0 : Initial
semantic configuration
Conditioned RL 8: for t = 1 : T do
Overview. Algorithm 3 presents the pseudo-code of the 9: at ← policy(st , ct , g)
sensorimotor learning phase (G→B) of DECSTR. It alter- 10: if not self_eval then
nates between two steps: 11: at ← at + σ()
• Data acquisition. A DECSTR agent has no prior on 12: s , cp ← E.step(at )
t+1 t+1
the set of reachable semantic configurations. Its first
13: episode ← (s, c, a, s0 , c0 )
goal is sampled uniformly from the semantic config-
14: Gs .update(cT )
uration space. Using this goal, it starts interacting
15: B.update(episode)
with its environment, generating trajectories of sen-
16: g ← Gs .sample(pb )
sory states s, actions a and configurations cp . The
17: batch ← B.sample(g)
last configuration cTp achieved in the episode after T
18: Π.update(batch)
time steps is considered stable and is added to the
19: if self_eval then
set of reachable configurations. As it interacts with
20: pb ← Gs .update_LP()
the environment, the agent explores the configura-
tion space, discovers reachable configurations and
selects new targets.
• Internal models updates. A DECSTR agent updates originally targeted. HER was designed for continuous goal
two models: its curriculum strategy and its policy. spaces, but can be directly transposed to discrete goals (Co-
The curriculum strategy can be seen as an active goal las et al., 2019a). In our setting, we simply replace the orig-
sampler. It biases the selection of goals to target and inally targeted goal configuration by the currently achieved
goals to learn about. The policy is the module con- configuration in the transitions fed to SAC. We also use
trolling the agent’s behavior and is updated via RL. our automatic curriculum strategy: the LP-C-based prob-
abilities are used to sample goals to learn about. When
Policy updates with a goal-conditioned Soft Actor- a goal g is sampled, we search the experience buffer for
Critic. Readers familiar with Markov Decision Process the collection of episodes that ended in the configuration
and the use of SAC and HER algorithms can skip this para- cp = g. From these episodes, we sample a transition uni-
graph. formly. The HER mechanism substitutes the original goal
We want the DECSTR agent to explore a semantic con- with one of the configurations achieved later in the trajec-
figuration space and master reachable configurations in it. tory. This substitute g has high chances of being the sam-
We frame this problem as a goal-conditioned MDP (Schaul pled one. At least, it is a configuration on the path towards
et al., 2015): M = (S, Gp , A, T , R, γ), where the state this goal, as it is sampled from a trajectory leading to it.
space S is the usual sensory space augmented with the The HER mechanism is thus biased towards goals sampled
configuration space Cp , the goal space Gp is equal to the by the agent.
configuration space Gp = Cp , A is the action space,
T : S × A × S → [0, 1] is the unknown transition proba- Object-Centered Inductive Biases. In the proposed
bility, R : S × A → {0, 1} is a sparse reward function and Fetch Manipulate environment, the three blocks share the
γ ∈ [0, 1] is the discount factor. same set of attributes (position, velocity, color identifier).
Policy updates are performed with Soft Actor-Critic (SAC) Thus, it is natural to encode a relational inductive bias in
(Haarnoja et al., 2018), a state-of-the-art off-policy actor- our architecture. The behavior with respect to a pair of
critic algorithm. We also use Hindsight Experience Replay objects should be independent from the position of the ob-
(HER) (Andrychowicz et al., 2017). This mechanism en- jects in the inputs. The architecture used for the policy is
ables agents to learn from failures by reinterpreting past depicted in Figure 6.
trajectories in the light of goals different from the ones A shared network (N Nshared ) encodes the concatenation of:
JFPDA@PFIA 2021 16Vous pouvez aussi lire

















































