LinkedIn rend Open Source Pinot, son outil d'analyse en temps réel - Silicon.fr
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

LinkedIn rend Open Source Pinot, son outil d’analyse en temps réel LinkedIn multiplie les initiatives dans le Big Data. Huit mois après avoir dévoilé son framework d’analyse de données en temps réel Pinot (en réference au cépage du même nom), le réseau social professionnel américain a annoncé, mercredi 10 juin, rendre sa solution Open Source. Le but : ouvrir Pinot aux contributions de développeurs tiers et élargir son adoption. Pour collecter des évènements en temps réel et réagir à l’activité de l’utilisateur en quelques secondes, LinkedIn s’est détourné de solutions propriétaires et d’alternatives comme Druid, le data store Open Source qui se rapproche le plus de Pinot. Cet outil maison a été conçu pour traiter « des milliards d’évènements en temps réel par jour ». Hautement évolutif et tolérant aux pannes, selon ses promoteurs, Pinot offre un faible temps de latence et dispose d’une interface de type SQL. Pinot en téléchargement sur Github En interne, LinkedIn utilise Pinot depuis plus de deux ans avec 30 de ses produits, dont XLNT, plateforme de test A/B, indique dans un billet de blog Kishore Gopalakrishna, responsable technique logiciels chez LinkedIn. Parallèlement, Pinot sert de backend à plus de 25 produits d’analyse destinés aux clients et aux membres du réseau (Qui a consulté votre profil ou vos nouvelles ? Quel est l’impact des offres d’emploi et des annonces publicitaires diffusées via LinkedIn…). Le code source de Pinot est disponible sous licence Apache 2.0 sur Github. En plus de Pinot, LinkedIn a « ouvert » d’autres solutions d’infrastructure data, parmi lesquelles : Azkaban, Kafka, Samza et Voldemort. Il n’est pas le seul. D’autres grands noms du numérique ont rendu Open Source leurs propres outils d’analyse et traitement de flux, dont eBay avec Pulsar et Twitter avec Storm. Lire aussi : Emploi et Big Data : LinkedIn ouvre ses données aux chercheurs Linkedin s’empare de l’expertise Big Data de Carreerify Crédit : McIek Shutterstock
BI : Qlik veut convertir les métiers au mélange des données Dans la foulée des annonces de Qlik Sense, de ses offres cloud, et de son service Datamarket (issu du rachat du service Data as a Service ou DaaS éponyme –données professionnelles accessibles en mode cloud), l’éditeur suédois a organisé une journée dédiée à ses clients et partenaires à Paris. Une occasion pour Silicon.fr de rencontrer Anthony Deighton, son directeur technique (CTO), et James Richardson, son Managing Director (ex-analyste du cabinet d’études Gartner). Dès la création de la société, le leader de la visualisation et de l’exploration analytiques choisit de stocker tous les détails des données en mémoire, et pas uniquement les résultats. Un défi risqué dans les années 1990, lorsque la mémoire coutait beaucoup plus cher… L’évolution informatique semble lui avoir donné raison, comme le prouve la généralisation du In-Memory ou encore SAP avec Hana. Libérer l’utilisateur de la technologie « En 30 ans, la Business Intelligence a fortement évolué. Devenue stratégique, elle s’impose désormais à tous les niveaux de l’entreprise,» assure James Richardson. «C’est pourquoi les utilisateurs peuvent à présent faire beaucoup plus avec une solution comme Qlik. Grâce à la plateforme Sense, les métiers peuvent explorer intelligemment leurs données en mode Click&Look sans dépendre sans cesse des informaticiens afin de découvrir des informations ou de prendre de meilleures décisions. Nous visons trois objectifs essentiels. Avant tout : libérer l’utilisateur métier des barrières technologiques grâce à la visualisation. Second objectif : intégrer et donner accès à tous les types de données internes ou externes à l’entreprise. Traditionnellement, la BI se contentait d’analyser les informations transactionnelles des ERP et autres applications centrales. D’ailleurs, les volumes ne sont pas forcément importants. Enfin, il s’agit de mettre fin à l’utilisateur final passif se contentant de visualiser le résultat d’une chaîne de traitements: SGBD, ETL, front-office… Aujourd’hui, l’utilisateur plus impliqué veut être actif et explorer des données de façon interactive, collaborative, afin d’exprimer des idées, des opinions, etc.» Le mélange de données à la portée des métiers La variété des données à considérer et leurs différents formats –bases de données, tableurs, etc.) apportent un niveau de complexité pour l’utilisateur final, non-initié aux liaisons de données et autres référentiels informatiques. Les opérations dites « de data blending » (mélange de données) nécessitent une connaissance de la structure des données et de la mise en relation entre elles. Peut-on alors s’affranchir des informaticiens ? « Dans Sense, notre moteur d’associations détecte les relations a priori possibles entre des colonnes Excel et des champs de bases de données, ou en analysant la forme des informations… Il propose donc automatiquement à l’utilisateur des liens qu’il peut refuser, soit parce qu’il constate que cela n’a aucun sens, soit parce que le résultat final n’apporte rien. Mais bien souvent, la proposition est pertinente,» explique Anthony Deighton. « Effectivement, parfois l’opération s’avère inefficace. Néanmoins, cela présente l’avantage de mettre à jour des problèmes d’incohérence ou de qualité des données, avec charge à l’utilisateur et aux informaticiens d les résoudre. Toutefois, l’utilisateur connait ses informations généralement locales et

est à même de trouver rapidement une solution.» Pourtant le problème des données non structurées ne devrait-il pas s’accentuer? « Pour ma part, je ne connais pas de données non structurées. Toute information a une structure, non seulement les bases de données, mais aussi les documents bureautiques ou les objets connectés. Le défi consiste surtout à détecter cette structure,» rétorque le directeur technique. Cette question de qualité des données est épineuse, car essentielle à la pertinence des analyses. D’où l’importance croissante des solutions de gouvernance des données. « Cependant, avec les grands volumes, la pertinence a fortement tendance à augmenter,» relativise James Richardson. « La question à se poser touche aux seuils de tolérance acceptable par l’entreprise pour telle ou telle analyse. Ainsi, sur des informations locales, elle pourrait envisager 90 à 95% de fiabilité, contre 99,99% pour des données professionnelles achetées auprès de spécialistes. Par ailleurs, le phénomène culturel reste l’un des freins majeurs à la démocratisation de l’accès aux outils de BI. Certaines personnes pensent que leur pouvoir tient dans ces informations. Mais cela évolue finalement assez vite dans le bon sens. Et ces solutions visuelles y contribuent.» La concurrence, quelle concurrence ? Dans le sillon d’entreprises pionnières comme Qlik et Tableau, et face aux succès remportés, tous les acteurs de la BI ont fortement investi sur la visualisation et l‘exploration des données. La concurrence s’accentue donc, non seulement pour Qlik, mais aussi pour des acteurs comme Tableau. « Souvent, ces acteurs ont imité l’interface de Qlik, mais leur moteur reste le même, et ne propose ni le même spectre fonctionnel ni la même agilité,» affirme Anthony Deighton. «Contrairement à Qlik, ces plates formes n’ont pas été originellement conçues avec cette préoccupation visuelle intégrée dans leur socle. Ni avec la mobilité. Résultat la combinaison des deux devient généralement laborieuse et complexe, et non naturelle,» renchérit James Richardson. La guerre des trois n’aura pas lieu Longtemps, les éditeurs de BI ont proposé leurs solutions comme exclusivement à destination des informaticiens. Puis, depuis quelques années, certains responsables d’entreprise (marketing, financiers…) ont décidé de passer outre l’informatique. Alors, une grande partie des éditeurs ont court-circuité les DSI en s’adressant directement aux métiers. Résultat : des solutions souvent hétérogènes et complexes à intégrer, des conflits plus tendus encore, et un remplacement de l’éditeur quand il faut quelqu’un porte le chapeau… « Chacun doit trouver sa place dans la décision, avec pour objectif une solution qui réponde aux attentes de l’utilisateur final. Car, finalement, tout le monde ressort perdant de la bataille entre DSI et directions métier, et surtout l’entreprise. La solution doit être simple à utiliser, ergonomique et pouvoir apporter la bonne information dans le bon contexte et au bon moment à l’utilisateur. Avec la possibilité pour l’informaticien d’intervenir. Sinon, comment l’utilisateur peut-il avoir confiance dans les résultats de données ? Comment pourrait-il utiliser un outil qui ne convient pas?… Le dénouement passe par un partenariat en bonne intelligence autour d’un outil collaboratif,» conclut James Richardson. A lire aussi :
Avec Sense 2.0, Qlik pousse la dataviz vers les métiers et le Cloud Qlik Branch, une plateforme ouverte au partage d’API entre développeurs Crédit Photo : Syda production-Shutterstock Le gouvernement britannique s’associe avec IBM sur le Big Data Le ministre des Sciences du gouvernement britannique, Jo Johnson, a levé le voile sur un partenariat signé avec IBM, d’une durée de cinq ans et d’un montant de 313 millions de livres (environ 453 millions d’euros). L’objectif est de booster la recherche sur le Big Data au sein du Royaume-Uni. Le gouvernement va mettre 113 millions de livres sur la table, et IBM 200 millions, sous la forme d’un ensemble de technologies et d’une expertise sur site. L’accès aux datacenters d’IBM et à la plate-forme Watson sera ouvert aux chercheurs. Un minimum de 24 chercheurs de la firme américaine seront également détachés auprès du Hartree Centre, piloté par le STFC (Science and Technology Facilities Council). Les résultats des travaux menés par les universitaires britanniques et les équipes d’IBM seront commercialisés conjointement par les deux acteurs. Des serveurs OpenPower Ce partenariat est d’importance pour IBM, mais également pour la Fondation OpenPower. Cette technologie sera en effet un des éléments clés des infrastructures qui seront mises en place dans le cadre de ces travaux de recherche, aux côtés de Watson, lui aussi basé sur la technologie Power. Les machines OpenPower se positionnent ainsi comme les fantassins des infrastructures massives dédiées à des traitements Big Data, la tête pensante de ces clusters restant Watson. À lire aussi : Quiz Silicon.fr – 10 questions pour tout savoir sur l’initiative OpenPower SoftLayer va intégrer des serveurs OpenPower à ses offres bare metal Tyan et Cirrascale lancent les premiers serveurs OpenPower non IBM Crédit photo : © Feature Photo Service
Discover 2015 : les 4 commandements de Hewlett Packard Entreprise La séparation en deux activités arrive à grand pas pour HP, car elle sera effective au 1er novembre prochain, a annoncé Meg Whitman, CEO du groupe. Elle a profité de l’évènement annuel de la firme à Las Vegas pour reparler de la création de ces deux entités et surtout de dresser une feuille de route pour l’activité entreprise qu’elle va diriger. En premier lieu, elle justifie inlassablement cette scission pour mieux rassurer les clients. « Nous avons besoin de plus d’agilité, d’apporter plus vite des solutions à vos besoins notamment dans la transformation numérique », rappelle la dirigeante. Elle constate en outre que les stratégies métiers et IT ne sont pas si éloignées au point d’en faire un nouveau credo, le « new style of business ». Les choses ont bien avancé depuis l’annonce de cette séparation. Hewlett Packard Entreprise a vu son périmètre se cantonner des serveurs et du stockage au Cloud en passant par la sécurité et le réseau, tout en gardant au passage les services. L’organigramme des différents responsables de ces divisions a aussi été arrêté en janvier dernier. Pour mémoire, il comprend Mike Nefkens, en charge des services, et Robert Youngjohns, à la tête de la division Software. Antiono Neri, responsable de l’activité serveur et réseau, prend part à l’aventure pour s’occuper de la gestion courante. Ils étaient tous présents sur scène, mais on aura noter l’absence de Bill Veghte, en charge de la stratégie de HP et homme fort de HP Entreprise. Cette entité s’est dotée d’un nouveau logo avec un rectangle vert qui avait été présenté en avril dernier. Bascule sur l’hybride Puis est venu le temps pour Meg Whitman de décliner sa stratégie pour HP Entreprise. Elle se décline en 4 orientations : transformation, protection, accompagnement et renforcement. A chaque orientation, les dirigeants de HP Entreprise cités précédemment sont venus apporter la bonne parole de manière un peu docte, parfois, et commerciale, souvent. La première pierre de la stratégie de Meg Whitman est la transformation des sociétés vers des infrastructures hybrides. « Avec le développement des applications (1 trillion en 2020), des devices (100 milliards), les entreprises ont besoin de se reposer sur des infrastructures plus agiles, plus rapides. Il est donc nécessaire de les accompagner vers des solutions d’automatisation, d’orchestration et de convergence », souligne Mike Nefkens. HP Entreprise propose plusieurs éléments pour cette transformation comme l’a rappelé Antonio Neri. Sur le Cloud par exemple, la firme de Palo Alto a dévoilé la 9ème itération de Helion Cloud System comprenant la plateforme Helion Openstack ainsi qu’une version de Cloud Foundry et la dernière mouture de CSA (Cloud Service Automation). Elle sera disponible en septembre prochain. On peut ajouter l’amélioration du reporting et du monitoring avec View 2.0 et Ops Analytics pour permettre à la DSI de « devenir un broker d’applications et de services ».
La sécurité, un problème de Big Data La seconde orientation est la sécurité avec comme objectif de protéger les données, les applications contre différentes menaces (cyberattaques, erreurs humaines, incidents systèmes). Pour Robert Yougjohns, « la sécurité est un problème de Big Data. Pour détecter les menaces, il faut analyser des énormes volumes de données ». L’analytique est donc la clé pour réduire le temps de détection des attaques. Le responsable n’a pas fait d’annonces produits. Il faudra attendre septembre pour en savoir un peu plus notamment sur les évolutions du produit ArcSight. Troisième étage de la stratégie de HP Entreprise, valoriser les données de l’entreprise. Car le constat est sans appel : « actuellement 80 à 90 % des personnes considèrent que les promesses du Big Data ne sont pas effectives ou surévaluées », constate Mike Nefkens. Pour les porte-parole, le salut passera par les solutions de HP en matière de Big Data comme Haven ou la mise en place d’une plateforme Hadoop en collaboration avec Hortonworks. Aruba au cœur de la mobilité Enfin, dernière brique du ‘quadrant magique’ de HP Entreprise : la mutation de la productivité. Sous ce concept, on retrouve notamment la transition vers la mobilité. Dans ce cadre, l’acquisition d’Aruba Networks va prendre tout son sens. Son CEO, Dominic Orr, a fait sensation sur scène avec un dynamisme rafraîchissant pour expliquer les besoins des différentes générations en entreprises et leur implication sur les réseaux. Pour Antonio Neri, il ne fait aucun doute qu’Aruba va redéfinir le paysage du réseau. Toutefois, il faudra là encore attendre quelques mois avant d’en savoir un peu plus. Au final, Meg Whitman a donné sa feuille de route : « nous nous sommes demandés comment positionner HP non pas pour seulement survivre, mais aussi prospérer ». Cela passera par des acquisitions probablement, comme le montrent les derniers mouvements autour d’Aruba ou de Contextream. La dirigeante sait qu’elle joue une partie de poker importante, car les derniers résultats financiers de HP n’étaient pas au beau fixe. A lire aussi : Discover 2015 : HP enfonce le coût sur le stockage flash HP s’ancre dans le SDN/NFV avec Contextream Antemeta et HP, une histoire commune sur
le stockage et l’innovation « Ce ne sont pas nos amis, ils sont des partenaires de raison où les clients recherchent des experts et des compétences », explique Gérald Karsenti, PDG de HP France en parlant d’Antemeta. L’intégrateur français de solutions de stockage assume ce rôle de partenaire depuis 20 ans, précise Stéphane Blanc, président d’Antemeta. L’histoire des deux acteurs a commencé en février 1995 avec le développement des services Storageworks de HP. Puis, « il y a eu quelques infidélités » glisse discrètement Stéphane Blanc. Déçu par Storageworks, il a écumé la Silicon Valley pour trouver une technologie plus performante et importera dans l’hexagone les produits 3Par, dont le CEO, David Scott est un ancien de HP. Cette infidélité ne durera pas, car au mois de septembre2010, après une bataille homérique entre HP et Dell, 3Par tombe dans l’escarcelle de la firme de Palo Alto. Depuis ce rachat, les relations sont de plus en plus étroites entre les deux partenaires. « Nous disposons de la troisième base installée de baies 3Par dans le monde », constate Stéphane Blanc. Une connaissance des produits qui lui permet de disposer d’une R&D en étroite collaboration avec les laboratoires de HP pour développer des fonctionnalités ou des outils de gestion des solutions de stockage. Le directeur technique d’Antemeta, Samuel Berthollier, est venu présenter les dernières évolutions des solutions 3Par Vision et Peer Persitent pour AIX. Des solutions de gestion du stockage Sur le premier, il s’agit d’un service de reporting sur l’utilisation des baies. La troisième version vient de sortir et comprend quelques innovations, comme le traitement en quasi temps réel avec des points de mesure remontés chaque seconde. Un avantage et un inconvénient constate le CTO d’Antemeta. « Les clients sont très demandeurs de ces informations en temps réel. Par contre il est difficile de leur fournir des données sur mobiles ou tablettes, car certains vont jusqu’à 150 000 points retranscrits. Nous avons essayé, mais les écrans ne sont pas adaptés et les navigateurs crashent. » L’application qui tourne sous Windows s’essaye à la BI et au machine learning pour prévoir le comportement des baies et l’évolution des besoins de stockage du client (consommation IOPS, niveau d’utilisation de la baie, etc.). Autre service, Peer Persistent pour AIX. « Il s’agit d’un outil pour s’assurer la migration d’une baie à une autre à chaud dans des datacenters distants. HP a eu la bonne idée d’intégrer cette fonctionnalité dans les contrôleurs. Mais sur d’autres environnements comme AIX d’IBM très implantés dans certains secteurs comme la banque, il a été nécessaire de développer des solutions ad hoc », indique Samuel Berthollier. Des solutions qui sont homologuées par les laboratoires de HP et qui sont ensuite proposées aux clients HP/3Par. 10% de passage en full flash Mais la prochaine grande rupture, c’est la flash. Pour Gerald Karsenti, « l’année 2015 sera celle de la flash avec un marché en forte croissance avec une orientation vers les services et les usages ». Les prix et les capacités commencent à devenir intéressants sur la mémoire flash au point de devenir une vraie alternative aux disques traditionnels. Stéphane Blanc est plus direct. « Les constructeurs de disques se
sont reposés sur leurs lauriers, il n’y avait plus de réelle innovation. La flash a redistribué les cartes. » Un engouement pour la flash qui commence à percer selon le dirigeant : « Nous avons migré aujourd’hui 10% de notre base installée en full-flash. » Et les ambitions sont grandes dans ce domaine, sans pour autant tout confier à HP. En effet, Antemeta a noué un partenariat avec Pure Storage depuis plusieurs mois pour développer son activité autour du flash. L’intégrateur pousse également ses services managés avec des bons retours notamment sur sa dernière offre Arcabox, un service de stockage Cloud pour les entreprises. A lire aussi : Avec ArcAbox, Antemeta à l’assaut du stockage Cloud pour entreprise Antemeta : « Nous avons développé une solution de gestion unifiée de stockage NAS » Analytique Big Data : R sera intégré en standard au sein de SQL Server 2016 Fin janvier, Microsoft annonçait l’acquisition de Revolution Analytics, spécialiste du langage de programmation R. Voir à ce propos notre précédent article « Microsoft gobe Revolution Analytics sur un R de Big Data ». Les annonces autour de cette technologie ne se seront pas fait attendre. « SQL Server 2016 (qui sera accessible en version publique de test cet été) comprendra de nouvelles fonctions d’analyse en temps réel, le chiffrement automatique des données et la possibilité d’exécuter R au sein de la base de données elle-même », explique ainsi David Smith sur le blog de Revolution Analytics. « Les data scientists n’auront plus besoin d’extraire les données d’un serveur SQL via ODBC pour les analyser avec R. Au lieu de cela, Ils seront en mesure d’amener le code R au cœur des données, où il sera exécuté dans un processus de SQL Server lui-même. Ceci élimine le temps et le stockage nécessaire pour déplacer les données, et offre toute la puissance de R et des packages CRAN dans la base de données. » R, la nouvelle star des data scientists R est un outil Open Source de traitement des données, spécialisé dans les analyses statistiques. Des caractéristiques qui lui valent une popularité croissante au sein de la communauté des data scientists. L’acquisition de Revolution Analytics et l’inclusion de R au sein de SQL Server 2016 sont donc des avancées clés pour Microsoft sur le terrain du Big Data analytique. La firme n’est toutefois pas seule dans ce secteur. Elle a en effet été précédée par Oracle, qui a déployé très tôt R dans ses offres (voir l’article de février 2012 « Oracle place le langage R au cœur de son offre analytique big data »).
À lire aussi : Rust 1.0 : le langage de programmation des projets critiques Programmation : Xojo pourra créer des applications Raspberry Pi La NASA et IBM lancent un concours de programmation basé sur Bluemix Crédit photo : © McIek – Shutterstock Avec Sense 2.0, Qlik pousse la dataviz vers les métiers et le Cloud Outre Analytics Platform, destinée aux développeurs pour concevoir des applications analytiques avec exploration visuelle des données, l’éditeur suédois fait évoluer sa plateforme Sense destinée à l’utilisateur non informaticien, et annonce ses nouveaux services cloud. Les rachats des sociétés DataMarket et Vizubi (et sa ligne de produits Nprinting) donnent naissance à des offres intégrées à forte valeur ajoutée. Quelles sont les particularités et les différences entre Analytics Platform et Sense ? Stéphane Briffod : La business intelligence traditionnelle est assez rigide et très orientée informatique. En outre, au sein des départements de l’entreprise les utilisateurs nécessitent non seulement les données centrales, mais aussi celle provenant de tableurs comme Excel ou d’autres sources d’information, ou encore du cloud. On constate aussi un écart important entre l’anarchie des données de l’utilisateur et l’indispensable gouvernance informatique. C’est pourquoi Qlik se positionne en tant que plate-forme d’entreprise permettant une collaboration entre l’informatique et les métiers, avec du self-service discovery, des tableaux de bord, du reporting, des analyses guidées, des applications analytiques embarquées dans d’autres logiciels, de la collaboration et du partage… Le travail des informaticiens reste indispensable, mais l’entreprise a besoin de plus d’agilité pour permettre aux métiers de prendre des décisions dans l’heure ou dans la journée. Ce qui amène à repenser l’organisation des données dans l’entreprise afin de réconcilier ces deux mondes. Analytics Platform apporte au développeur une solution simple pour concevoir rapidement des applications analytiques en quelques jours ou semaines et non plus en plusieurs mois ou années. Elle repose sur le moteur associatif de données en mémoire QIX in-memory Associative Indexing Engine, proposant aussi des APIs de mash-up et d’extension. Analytics Platform permet d’étendre la Business Intelligence aux clients et partenaires via l’extranet et Internet, favorisant la collaboration et l’interaction autour des données. Quant aux utilisateurs métier, Sense Enterprise 2.0 leur apporte le self-service, la collaboration et du partage, la possibilité de créer très simplement des visualisations différentes, en modifiant des axes, filtrant les résultats, etc. Qlik Sense Enterprise 2.0 (disponible dès juin 2015) leur apporte une
utilisation ergonomique et intuitive pour la visualisation de données en libre-service, le reporting, les tableaux de bord, et les analyses guidées et intégrées. Et suite à l’acquisition récente de NPrinting, Sense permet désormais d’imprimer et d’exporter des analyses au format PDF ou sous PowerPoint (ou Word), et de produire ces rapports pour les partager. Analytics Platform est intégré dans Sense. Ce qui répond au besoin d’agilité. En effet, dans les rapports interactifs ou applications analytiques conçues par les informaticiens, certaines choses non prévues s’avèrent parfois indispensables pour l’utilisateur final, qui peut via Qlik Sense en réaliser en grande partie de façon autonome. Pouvez-vous nous expliquer la nouvelle fonction Smart Data Load ? Avec Sense, l’utilisateur métier peut combiner des informations issues de diverses sources et les relier automatiquement, afin de révéler des relations invisibles entre ces informations. Le profiling Visuel de la nouvelle fonction Smart Data Load permet à l’utilisateur métier d’associer visuellement et en quelques clics des sources de données via une interface graphique intuitive. Par exemple, s’il utilise une feuille Excel avec une colonne « Client » et des données venant d’une base de données ou application avec une colonne « Customer », Smart Data Load lui suggérera automatiquement de relier ces deux colonnes. Et le tout, sans script ni code d’aucune sorte. Un script étant généré automatiquement, l’informaticien pourra éventuellement s’en servir pour d’autres cas d’usage. Qu’offrez-vous aujourd’hui (et demain) sur le Cloud ? Sous Qlik Cloud, via le service Sense Cloud, l’utilisateur peut partager gratuitement des applications Sense avec d’autres personnes (jusqu’à 5, et plus au cours du second semestre 2015) qui nécessitent juste un terminal équipé d’un navigateur Internet. Au cours du second semestre, il sera également possible directement dans Sense Cloud de créer des applications analytiques, du Story Telling, de la visualisation, etc. Suite à l’acquisition de Datamarket, nous proposerons dès le mois de juin (et dans QlikView au second semestre 2015) notre offre de Data as a service Qlik DataMarket permettant aux utilisateurs de Sense d’accéder à une multitude de données externes payantes ou gratuites afin d’enrichir leurs informations (avec des bases de données Entreprises, météorologie, finances, démographie…). Des opérations qui permettent d’apporter plus de valeur et donc de prendre de meilleures décisions aussi bien pour de de l’analyse que pour du prédictif. Ces sources de données sont préfigurées et accessibles via un modèle d’abonnement. Au second semestre 2015, Sense Charts offrira aux utilisateurs métier techniques d’intégrer des visualisations interactives Sense au sein d’une page Web ou d’un blog ou de les partager gratuitement sur les réseaux sociaux. Et chacun pourra consulter ces graphiques interactifs depuis n’importe quel support et même –par exemple- filtrer ces données pour découvrir davantage d’informations avancées. Le tout à partir d’un simple navigateur. A lire aussi : Qlik Branch, une plateforme ouverte au partage d’API entre développeurs
René Bergniard : « Qlikview ne se limite pas à la dataviz » Crédit Photo : Syda production-Shutterstock Le Machine Learning améliore la productivité de la PME Conexance Mise à jour à 14h22 Remplacer un long processus manuel par des algorithmes qui découvrent seuls les relations les plus significatives entre différentes variables. Cette approche, qui est au cœur du Machine Learning, ne pouvait pas laisser la PME lilloise Conexance indifférente. Regroupant une quarantaine de personnes, ce prestataire spécialiste de statistiques propose à des sociétés d’un même secteur de partager, au sein de clubs fermés (distribution, presse et caritatif), des données anonymisées afin d’effectuer des analyses sur de larges volumes d’information. « Nous gérons des données historisées sur de longues périodes, renfermant de multiples informations sur les comportements des clients. Notre travail consiste à fournir des informations prédictives à nos clients : modélisation du churn (déperdition au sein de la base clients, NDLR), définition du potentiel de clients, stratégie d’acquisition de nouveaux clients… », précise René Lefébure, le directeur de la R&D de Conexance. Au total, la PME a agrégé, dans ses bases, 24 millions de foyers et gère pas moins de 1 700 variables essentiellement transactionnelles (2 500 prévues fin 2016. Autant d’éléments potentiellement significatifs des comportements clients. « C’est cette largeur qui pose problème. Nous avions besoin de nouveaux algorithmes », reprend René Lefébure. Un modèle prêt en moins d’une heure Avant tout pour des questions de productivité. Chez Conexance, une équipe de 9 personnes doit réaliser plus de 5 000 scorings par an. « Or, chacun d’entre eux nécessite en moyenne 6 passages (choix des dimensions et algorithmes pertinents, NDLR). Ces étapes statistiques demandent entre 3 heures – pour les scorings les plus simples – et jusqu’à 7 ou 8 heures de travail », détaille le directeur de la R&D. D’où l’intérêt de la PME pour les services de Machine Learning. Après étude (et évaluation de plusieurs alternative dont l’offre de Sas Institute et des solutions Open Source bâties autour de R), Conexance opte pour l’offre Microsoft : Azure Machine Learning. « Aujourd’hui, avec plus de 1 000 variables et environ 1 million d’enregistrements, construire un modèle sur ce service prend environ 50 minutes. Et le faire tourner demande 11 à 12 minutes de plus », assure René Lefébure. A condition évidemment de dimensionner l’infrastructure Azure en conséquence, ce qui a un impact sur les coûts. Le gain de productivité pour les équipes de statisticiens n’en reste pas moins important. Un élément intéressant pour Conexance, qui, pour gagner l’adhésion de nouveaux clients à ses clubs, propose des tests gratuits sur de premiers scoring. Etre en mesure de les produire rapidement et
de façon très automatisée s’avère donc crucial pour la société nordiste. Prédictions plus fiables Par ailleurs, le passage au Machine Learning masque également un enjeu de performances. « Dans l’univers mouvant de la donnée, où il faut faire progresser les rendements des campagnes, multiplier les types de scoring, intégrer des démarches de segmentation ou encore raccourcir les délais de livraison, miser sur une analyse statistique qui, elle, n’évolue pas ne me paraît pas être le bon modèle », résumé René Lefébure. Le Machine Learning permet de faire tourner en parallèle 8 modèles différents. « Selon les problématiques il est possible soit de sélectionner le meilleur modèle (selon un ou plusieurs critères), soit de combiner les différents modèles et/ou leurs résultats », précise le statisticien dans un billet de blog. Là où la méthode classique ne permet de bâtir – en 3 heures au mieux – qu’un modèle reposant sur un seul algorithme. Conexance avance des gains dans la qualité de prédiction allant de 20 % – « ce qui ne change rien pour un client sur le plan opérationnel »- à 300 %. Un bond qui, là, se révèle très significatif et qui résulte de « l’intégration de davantage de variables et de l’utilisation d’une combinaison de modèles », selon René Lefébure Si la PME utilise pour l’instant Azure for Machine Learning en doublon de son outillage traditionnel (basé sur les solutions de Sas Institute), essentiellement pour benchmarker les modèles traditionnels de Conexance, René Lefébure envisage un avenir où le Machine Learning prendra le pas sur les démarches manuelles. « A terme, j’espère que ces dernières ne représenteront plus que 10 % de nos opérations de scoring », dit-il. D’ici la fin 2015, la PME envisage également la construction d’un portail sur lequel ses clients pourront faire fonctionner eux-mêmes les modèles les plus performants. Signalons que Conexance s’est également appuyé sur Azure pour son architecture Hadoop. Celle-ci héberge des données non structurées (essentiellement des données de navigation), tandis que les bases SQL plus classiques (Oracle pour les données très confidentielles et SQL Server) prennent en charge les données transactionnelles. A lire aussi : Machine Learning contre statistiques « classiques » : qui remportera le match ? (tribune) Ciblage marketing : la Fnac fait confiance au Machine Learning Bernard Ourghanlian, Microsoft : « Pourquoi le Machine Learning va gagner l’entreprise » Crédit photo : agsandrew / Shutterstock Emploi et Big Data : LinkedIn ouvre ses
données aux chercheurs Après avoir acquis Careerify, spécialiste du Big Data appliqué au recrutement et à la détection de talents, LinkedIn va mettre des jeux de données à disposition de 11 équipes de chercheurs sélectionnées dans le cadre de son programme Economic Graph Challenge. Les chercheurs ont 6 mois pour analyser ces données préalablement anonymisées et présenter leurs conclusions, indique LinkedIn dans un billet de blog. L’objectif : identifier les opportunités économiques du marché. Les équipes de chercheurs, doctorants et professeurs, axent leurs travaux sur des thématiques différentes, de la réduction des inégalités sur le marché du travail à la montée en compétences IT des collaborateurs. L’équipe du Massachusetts Institute of Technology (MIT), par exemple, veut mesurer la « santé économique » des villes en examinant les données d’individus qui y travaillent et celles d’organisations qui les emploient. Un autre groupe étudie la façon dont les hommes et les femmes assurent leur auto-promotion via leur profil professionnel. LinkedIn tire profit du Big Data Les chercheurs peuvent donc analyser de nouveaux jeux de données et apporter plus de visibilité à leurs travaux. Pour Linkedin, c’est l’occasion de bénéficier des lumières de datascientists à moindre frais. Le réseau social américain va en effet verser une enveloppe de 25 000 dollars à chaque équipe (soit 275 000 dollars au total). Une somme bien inférieure aux rémunérations de spécialistes de la donnée et au retour sur investissement attendu. Les solutions issues des travaux de recherche pourraient, selon LinkedIn, impacter positivement « des millions de personnes ». Les travaux engagés au printemps doivent se conclure en fin d’année 2015 et les résultats être présentés dans la foulée à des collaborateurs de LinkedIn triés sur le volet. Le réseau social américain assure, par ailleurs, que les résultats de recherche seront rendus publics début 2016, mais LinkedIn, qui a un droit de propriété intellectuelle sur ces travaux, gardera la main sur les informations publiées à cette occasion. La plateforme disposera ainsi d’une marge de manoeuvre pour créer des produits et services issus de ces recherches et s’adapter aux attentes du marché. D’autres acteurs actifs dans la gestion de carrière tirent profit d’investissements réalisés dans le Big Data, dont Workday. L’éditeur a récemment complété ses applications RH de fonctionnalités de recommandation. Les employeurs ont ainsi la possibilité de déterminer quels talents seraient prêts à les quitter dans les prochains mois et quelles actions mettre en oeuvre pour les retenir. Lire aussi : LinkedIn lorgne sur la collaboration intra-entreprise LinkedIn géolocalise les compétences IT
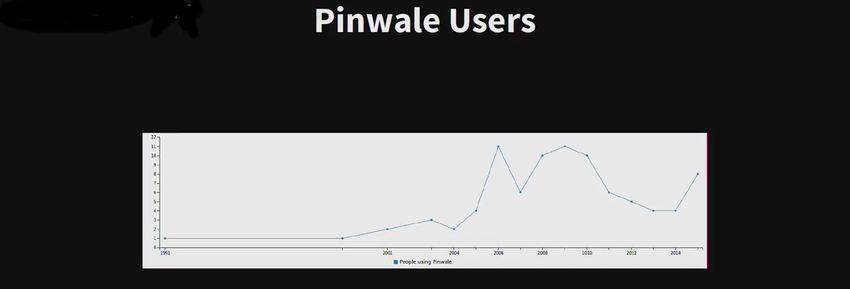
Un outil pour débusquer les espions sur Linkedin Et si vous surveilliez les surveillants ? C’est le credo défendu par trois passionnés d’informatiques. Brennan Novack (co-fondateur du service de mail chiffré Mailpile), Kevin Gallagher et M.C.Mc Grath ont créé ensemble un outil, baptisé Transparency Toolkit qui a pour vocation de recenser à travers les réseaux sociaux, les personnes travaillant directement et étroitement avec les agences de renseignements, via notamment leurs compétences. Ce service, dont le code est disponible sur Git Hub, utilise l’analyse de données publiques que les personnes mettent sur les médias sociaux. Une première vague d’études vient de se conclure par le recensement de plus de 27 000 personnes grâce à leur profil public sur Linkedin. Dans une intervention à la conférence Re:Publica 15, M.C.Mc Grath a démontré que les agents laissent beaucoup de traces visibles et publiques sur les médias sociaux. Dans leur outil d’analyse, les chercheurs ont travaillé sur des mots clés, notamment sur les noms des programmes de surveillance dévoilés dans les documents transmis par Edward Snowden. Dans sa communication, le jeune universitaire du MIT donne l’exemple d’une femme de la Navy qui marque ses compétences en analytique dans son CV sur Linkedin en inscrivant les noms XKeyScore, Pinwale, Marina, etc. Il cite d’autres exemples de CV qui contiennent les fameux programmes de la NSA.
Avoir une autre vue des programmes de surveillance Au final, cet outil a permis la création d’un moteur de recherche ICwatch qui permet de trouver des gens à partir d’un nom, d’un lieu ou d’une société qui ont un lien avec des programmes de surveillance. Mais la finalité n’est pas seulement d’être un annuaire « d’espions » assure M.C.Mc Grath, cette recherche peut corréler les métadonnées pour mettre en perspective le travail des agences de surveillance. Par exemple, il est possible de connaître le nombre de personnes travaillant sur un programme, de savoir quand il a commencé, le pic d’activité, sa fin ou d’éventuelles reprises après une mise en berne. Par recoupement, il est possible aussi de détecter les prémisses de nouveaux projets.
Interrogé sur le caractère moral de cette recherche avec des noms, des photos, des adresses personnelles, M.C.Mc Grath se retranche derrière le fait que ces informations sont publiques et ne sont donc pas classées. Les travaux des chercheurs ont pour objectif de mieux faire comprendre aux citoyens les enjeux des programmes de surveillance massive et des orientations des agences de renseignements. Ils auront aussi le mérite de montrer les limites de l’exposition des « agents » sur les réseaux sociaux. A lire aussi : Les acteurs de l’IT mobilisés contre la surveillance massive de la NSA Les CNIL européennes encadrent la surveillance « Made in NSA » crédit photo © kurhan- shutterstock Accord autour du marketing entre IBM et Facebook Facebook et IBM Commerce se rapprochent dans le but de fournir aux entreprises des solutions marketing leur permettant de mener des campagnes mieux ciblées, avec comme objectif de toucher « la bonne personne, avec le bon message, au bon moment ». Une problématique classique du monde la publicité. Nous retrouverons d’un côté la solution Custom Audiences de Facebook, qui permet de cibler des clients, dont les données seront affinées par l’offre Journey Analytics d’IBM, qui va se charger de faire un tri encore plus précis parmi les 1,44 milliard d’utilisateurs du réseau social. IBM Journey Designer sera ensuite employé afin de délivrer des messages sur mesure sur le site Facebook. Les réactions des clients seront remontées au sein de Journey Analytics pour analyse. Un workflow complet est donc proposé ici aux enseignes souhaitant cibler les utilisateurs du réseau social Facebook, avec à la clé des campagnes qui se veulent plus efficaces.
Facebook rejoint le Commerce ThinkLab Dans le même temps, Facebook rejoint l’IBM Commerce ThinkLab, unité de recherche et de collaboration qui permettra aux entreprises de travailler avec les marques, avec pour objectif la mise au point de solutions permettant de mieux personnaliser l’expérience client. Facebook est la première société à rejoindre cette nouvelle entité. Un candidat et partenaire de choix pour Big Blue dans le secteur du marketing digital. À lire aussi : Résultats : Facebook dépense toujours plus en R&D Résultats IBM : bénéfices en hausse, chiffre d’affaires en baisse Le spécialiste du marketing mobile ZipDial rejoint Twitter Crédit photo : © Jirsak – Shutterstock Avec les Xeon E7 v3, Intel met le cap sur l’analytique temps réel En septembre dernier, Intel avait levé le voile sur les puces Xeon E5 2600 v3 qui accueillaient la microarchitecture Haswell. A la mi 2015, c’est au tour du haut de gamme des puces pour serveurs de profiter du passage à cette microarchitecture. Le fondeur a annoncé le lancement des Xeon E7 v3. Il s’agit de processeurs comprenant 5,7 milliards de transistors, un die de 3,1 cm sur 2. Gravée en 22 nanomètres, la puce accueille 18 cœurs (144 cœurs sur 8 sockets) soit une progression de 20% par rapport à la génération précédente. Stanislas Odinot, responsable avant-vente datacenter en France et pivot de la collaboration avec les OEM explique que « ces processeurs sont historiquement dédiés pour les bases de données principalement Oracle et DB2 pour du datawarehouse. Aujourd’hui compte tenu de la performance et des fonctionnalités, le transactionnel reste toujours le cœur de cible avec de nouveaux usages comme le in-memory promu par HANA de SAP ». Car la cible de ces dernières puces d’Intel est d’entrer dans le monde de l’analytique en temps réel et pour cela, la firme de Santa Clara a mis les bouchées doubles, notamment sur la mémoire. Une gestion optimisée de la mémoire En matière de performance, beaucoup de travail a été réalisé sur la mémoire. Comme sur les E5 v3, les Xeon E7 v3 supportent la DDR3, mais aussi la DDR4 qui affichent une bande passante deux fois plus véloce que celles en DDR3 (1 066 MT/s (megatransfert par seconde) et 8,5 Go/s pour la DDR3 contre 2 133 MT/s et 17 Go/s pour la DDR4). Stanislas Odinot souligne que « d’ici la fin de l’année, la
parité du prix entre la DDR4 et la DDR3 devrait être acquise ». Cette mémoire DDR4 comporte plusieurs avantages dont la hausse de la fréquence et une amélioration de l’efficacité énergétique. Et les processeurs peuvent gérer jusqu’à 1,5 To de mémoire à travers 24 bancs, précise le responsable. La performance est une chose, mais les Xeon E7 v3 affichent certaines fonctionnalités pour accompagner ce voyage vers l’analytique en temps réel. On peut citer le cas du TSX (Transactional Synchronization Extension) qui apporte de la puissance supplémentaire et ouvre aux éditeurs la possibilité d’exécuter des threads de manière opportuniste plus rapidement. « Les gains peuvent atteindre 40 à 42% », souligne Stanislas Odinot. Les bugs sur cette fonctionnalité sont corrigés assure-t-on du côté d’Intel. Elle reste néanmoins désactivée par défaut sur les différentes configurations. Le cache monitoring est une autre fonction intéressante qui se niche dans la mémoire de niveau 3 et permet aux applications de voir s’il y a un engorgement de mémoire. Une vision pratique dans le cadre de la virtualisation pour constater si, dans un groupe de VM, une des machines est plus gourmande et donc nécessite un déplacement. Rafraîchissement de gammes chez les constructeurs La gamme des Xeon E7 v3 a été simplifiée pour comprendre 3 catégories : Basic, Standard et Advanced. Il faut compter également une famille de processeurs supplémentaires réalisés sur mesure pour des constructeurs sur certaines applications. Pour le lancement, pas moins de 38 fabricants ( dont Bull, Cisco, Dell, Fujitsu, Hitachi, Hewlett-Packard, Huawei, Inspur, Lenovo, NEC, Oracle, PowerLeader, Quanta, SGI, Sugon, Supermicro, et ZTE) ont prévu d’intégrer les derniers processeurs Intel dans leurs configurations. Ainsi, HP vient de rafraîchir sa gamme Apollo 2000 et 4000, mais également les systèmes critiques Superdome X et la génération 9 des serveurs ProLiant DL580, DL560 et BL660c. De son côté, Lenovo toilette son offre Flex System par deux serveurs orientés vers le Big Data et notamment pour l’offre SAP HANA. Les tarifs de ces processeurs s’échelonneront de 1200 à plus de 7100 dollars. A lire aussi : Microserveurs : Intel livre les Xeon D, des SoC Broadwell en 14 nm Ribambelle d’annonces chez les fabricants de serveurs autour du Xeon E5 v3 Stockage : HDS mise sur l’agilité et la verticalisation Hitachi Data Systems a réuni partenaires et clients à Las Vegas à la fin du mois dernier pour dévoiler ses ambitions et ses propositions. Michel Alliel, directeur marketing chez HDS France, est
revenu sur les tendances de cette grand-messe. « Les annonces se sont focalisées sur deux thèmes : le software defined infrastructure et la social innovation », souligne le responsable. Derrière le premier thème se cache la montée en puissance de la programmation du hardware et de la virtualisation du stockage. « Il faut donner à l’infrastructure plus d’agilité, plus de performance », précise Michel Alliel. Et cela passe par une unification des gammes comme par exemple les VSP (Virtual Storage Platform) qui voient l’arrivée des modèles G200, G400, G600 et prochainement le G800. « Il s’agit des déclinaisons de l’offre high end existante G1000 en gardant les mêmes microcodes. La plus petite déclinaison comme le G200 dispose de fonctionnalités comme la virtualistation, la réplication, du provisionning et du tiering dynamique, ainsi que du stockage multisite en mode actif/actif . Il y a la même connectivité sur le back et front end. » Sur les caractéristiques techniques (cf schéma ci-dessous), les baies VSP accueillent aussi bien des disques classiques, des SSD, ou un mix des deux. L’hyperconvergence, terme en vogue, n’est pas oubliée avec l’arrivée de deux évolutions de l’UCP (Unified Compute Platform) en version 1000 et 2000. Il s’agit de la déclinaison des solutions hyperconvergées poussées par VMware à travers son programme Evo : Rail qui peut aller de 4 nœuds jusqu’à 16 nœuds. HDS ajoute des couches logicielles maisons pour l’automatisation des workflows, la sauvegarde, le déploiement, etc. Une orientation métier assumée L’autre axe de développement est ce que HDS nomme la social innovation, ce qui peut se traduire par un renforcement de la segmentation métier de HDS. « Nous avons pour ambitions de combiner différentes technologies pour adresser des métiers différents. C’est notamment le cas avec l’analytique et nos différentes acquisitions dans ce domaine, Avrio, OxYa, Pantascene et de Pentaho », affirme Michel Alliel. D’où l’idée d’enrichir le portefeuille de solutions autour de l’analytique. Ainsi pour les responsables informatiques, Hitachi lance Insight for IT Operations, une solution de big data pour le datacenter, nous confie son porte-parole. Elle analyse les interactions entre les machines (M2M) et offre aux utilisateurs la capacité d’optimiser les performances et la disponibilité de leur IT. Autre service annoncé, Clinical Repositery for Connected Health qui s’adresse au monde de la santé avec des outils d’analyses sur les données médicales, le partage et la découverte de dossier patient, etc. Enfin, le constructeur annonce le lancement de Live Insight Center of Excellence, qui s’adresse à de multiples secteurs énergies, finances, etc. Il s’agit d’une plateforme mettant à disposition différentes solutions de HDS pour mener à bien des projets et de bénéficier des bonnes pratiques. A lire aussi : HDS met la main sur le Français Oxya, spécialiste de l’infogérance SAP Michel Alliel, HDS: « les objets connectés nécessitent un stockage en mode Scale Out»
Vous pouvez aussi lire

















































