STAT-D-103/104 : exemple transversal Statistique descriptive uni- et bivariée
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

STAT-D-103/104 : exemple transversal
Statistique descriptive uni- et bivariée
Exemple rédigé par Morgane GILADI et Catherine VERMANDELE
1. DESCRIPTION DU THEME DE L’ETUDE
1.1 Le thème de recherche
Les performances en mathématiques dans l’enseignement secondaire des élèves en
Communauté française de Belgique et l’impact éventuel sur ces performances de facteurs
socioculturels et socioéconomiques.
1.2 La population d’intérêt
L’ensemble des élèves de 4e année du secondaire général en Communauté française, inscrits
dans l’option « sciences humaines ».
1.3 L’objectif de la recherche
Décrire et expliquer les performances en maths des jeunes de la population d’intérêt.
1.4 Les questions de recherche
Quels facteurs socioculturels et socioéconomiques peuvent expliquer les performances en
maths des jeunes de la population d’intérêt ? Plus précisément, l’origine culturelle des élèves
(belge ou étrangère), la langue parlée à la maison (le français ou une autre langue), le niveau
d’études des parents, le revenu des parents ont-ils un impact sur la performance en maths des
élèves ?
1.5 Le dispositif de collecte des données
L’étude est réalisée sur la base d’un questionnaire rempli par 60 jeunes sélectionnés dans la
population d’intérêt, parmi lesquels 30 jeunes ont un père provenant d’un pays étranger (nous
dirons que ces jeunes sont d’origine culturelle étrangère) et les 30 autres sont d’origine belge.1
Ces 60 jeunes ont tous été soumis préalablement à un même test en mathématiques
susceptible d’évaluer leurs performances et compétences dans cette discipline.
Le questionnaire comporte les questions suivantes :
• Quel score avez-vous obtenu au test en mathématiques que vous avez passé ? (Ce
score est un nombre entier compris entre 0 et 10 ; il est donc de la forme 0/10, ou 1/10,
ou 2/10, etc.)
• Quel est le niveau du diplôme le plus élevé obtenu par votre père ?
o Aucun diplôme ou diplôme de niveau primaire
o Secondaire inférieur
1
Dans la réalité, l’échantillon étudié aurait intérêt à être de plus grande taille. Nous nous limitons ici à un
échantillon de taille 60 de manière à pouvoir vérifier aisément « à la main » les différents résultats présentés.
Par ailleurs, dans l’espoir d’obtenir un échantillon représentant correctement les diverses caractéristiques de la
population d’intérêt, il est conseillé de le sélectionner en faisant appel à l’une ou l’autre méthode
d’échantillonnage aléatoire appropriée (cf. Théorie des sondages).
1 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée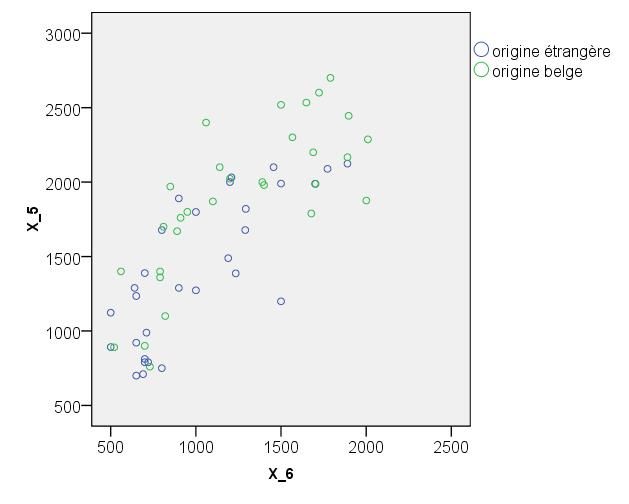
o Secondaire supérieur
o Supérieur non universitaire
o Universitaire
• Quel est le niveau du diplôme le plus élevé obtenu par votre mère ?
o Aucun diplôme ou diplôme de niveau primaire
o Secondaire inférieur
o Secondaire supérieur
o Supérieur non universitaire
o Universitaire
• Quel est le revenu mensuel de votre père ? ……..…. €
• Quel est le revenu mensuel de votre mère ? …….…. €
• Quel est le pays d’origine de votre père ?
o Belgique
o Autre (à préciser) : ……..……………
• Quelle langue parlez-vous le plus souvent à la maison ?
o Français
o Autre
L’étude entreprise ici se situe dans le registre de l’enquête. Les variables que l’on désire
analyser ne sont pas directement observables sur l’ensemble de la population d’intérêt (il
n’existe pas de fichiers administratifs contenant ce type de données pour l’ensemble des
élèves de la population et interroger l’ensemble de la population d’intérêt coûterait bien trop
de temps et d’argent) ; l’unique solution consiste donc à récolter les données (via un
questionnaire) auprès d’un échantillon sélectionné dans la population. Si l’échantillon est
prélevé par une méthode d’échantillonnage aléatoire adéquate, on peut espérer qu’il reflètera
adéquatement les principales caractéristiques de la population ; les analyses réalisées sur ce
sous-ensemble de la population fourniront alors des résultats qui pourront être, dans une
certaine mesure, généralisés à l’ensemble de la population d’intérêt (via les techniques
d’inférence statistique que nous n’aborderons pas dans cet exemple).
2. PREPARATION DE L’ANALYSE
2.1 Analyse préliminaire des variables utilisées
Avant de débuter l’analyse proprement dite, il est important de savoir avec quelles variables
nous allons devoir travailler et quelles en sont les caractéristiques.
Sept variables ont été observées sur les 60 élèves de l’échantillon :
(i) la performance (ou score) de l’élève au test en maths auquel il a été soumis : cette
variable peut prendre les valeurs 0, 1, 2, …, 10 (note sur 10).
(ii) le niveau d’études du père : cette variable peut prendre les modalités « ≤ primaire »,
« secondaire inférieur », « secondaire supérieur », « supérieur non universitaire » et
« universitaire ».
(iii) le niveau d’études de la mère : cette variable peut prendre les mêmes modalités que
la variable précédente.
(iv) le revenu mensuel du père : cette variable peut prendre n’importe quelle valeur entre
0 € et 5000 €.
2 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée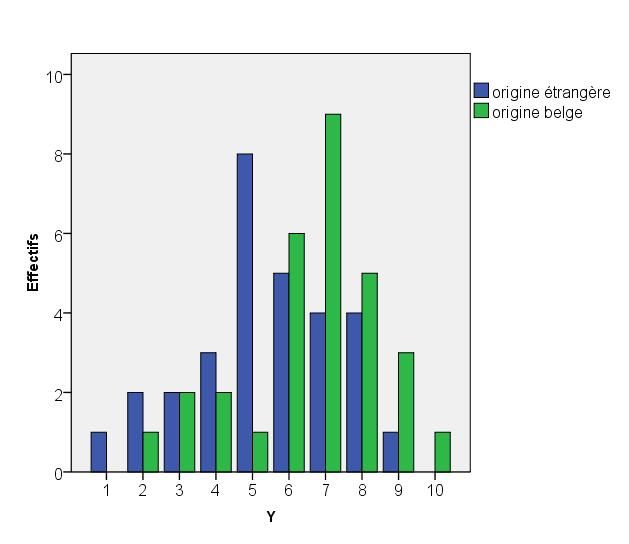
(v) le revenu mensuel de la mère : cette variable peut prendre n’importe quelle valeur
entre 0 € et 5000 €.
(vi) l’origine culturelle de l’élève (via le pays d’origine du père) : pour la facilité de
l’analyse, il a été décidé de considérer les modalités « origine belge », « origine
marocaine », « origine espagnole », « origine italienne », « origine congolaise »,
« origine polonaise » et « autre origine » pour cette variable.
(vii) la langue parlée le plus souvent à la maison : cette variable ne peut prendre que les
deux modalités « français » et « autre ». On dira que cette variable est dichotomique
(ou binaire).
a) Variables dépendante (à expliquer) et indépendantes (explicatives)
Etant donné nos questions de recherche, il est clair que la variable « score en maths » joue un
rôle particulier. Nous allons non seulement décrire avec soin la distribution observée de cette
variable, mais aussi tenter d’expliquer cette variable à partir des 6 autres variables observées.
La variable « score en maths » va dès lors jouer le rôle de variable dite dépendante (nous la
désignerons dès lors par Y) alors que les 6 autres variables seront dites explicatives ou
indépendantes (et seront désignées par X1, X2,…,X6) :
X1 : origine culturelle de l’élève ;
X2 : langue parlée le plus souvent à la maison ;
X3 : niveau d’études du père ;
X4 : niveau d’études de la mère ;
X5 : revenu mensuel du père ;
X6 : revenu mensuel de la mère.
b) Variables qualitatives et quantitatives
Les variables Y (score en maths), X5 (revenu mensuel du père) et X6 (revenu mensuel de la
mère) sont des variables quantitatives : elles prennent des valeurs numériques qui quantifient
une caractéristique d’un élève ou de ses parents.
Les 4 autres variables (X1, X2, X3 et X4) sont qualitatives (ou encore catégorielles) : leurs
« valeurs » correspondent à des modalités ou des catégories dans lesquelles nous pouvons
classer les élèves interrogés. Insistons sur le fait que ces 4 variables restent qualitatives même
si nous décidons de coder numériquement leurs modalités ; les valeurs numériques utilisées
pour ce codage ne sont en réalité que des « étiquettes » attribuées aux différentes modalités
pour la facilité de l’analyse.
c) Variables discrètes et continues
Une variable qualitative ne pouvant pas être continue, les 4 variables qualitatives (X1, X2, X3
et X4) sont nécessairement discrètes : elles prennent un nombre fini de modalités distinctes.
Etant donné que la variable quantitative Y (score en maths) ne peut prendre que les 11 valeurs
distinctes 0, 1, 2, …, 10, elle est discrète. En revanche, les variables quantitatives X5 (revenu
3 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée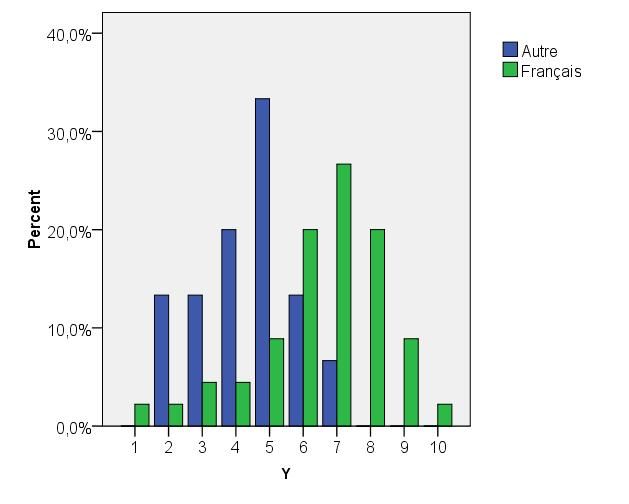
mensuel du père) et X6 (revenu mensuel de la mère) peuvent a priori prendre n’importe quelle
valeur dans un intervalle défini de la droite réelle : elles sont dès lors des variables continues.
d) Echelles de mesure des variables
Les modalités des variables X1 (origine culturelle de l’élève) et X2 (langue parlée le plus
souvent à la maison) ne peuvent pas être « rangées » selon un ordre naturel (une origine
donnée n’est pas « meilleure » qu’une autre ; une langue particulière n’est pas « meilleure »
qu’une autre) : ces variables qualitatives sont dès lors nominales.
Par contre, les modalités des variables X3 (niveau d’études du père) et X4 (niveau d’études de
la mère) peuvent être « rangées » selon un ordre naturel, du plus faible niveau d’études (≤
primaire) au niveau d’études le plus élevé (universitaire) : ces deux variables qualitatives sont
donc ordinales.
Les 3 variables quantitatives (Y, X5 et X6) sont mesurées sur des échelles de rapports
(puisque, pour ces variables, la valeur « zéro » correspond bien à une caractéristique nulle :
performance nulle en maths ou absence de revenu).2
2.2 Préparation des données
a) Codification des données
Il est habituel de coder numériquement les modalités des variables qualitatives observées,
c’est-à-dire d’associer une valeur numérique (une étiquette numérique) à chaque modalité.
Ceci facilite à la fois l’enregistrement et l’analyse des données.
Si la variable qualitative est nominale, le choix des valeurs numériques utilisées pour coder
les différentes modalités est parfaitement arbitraire. En revanche, si la variable qualitative est
ordinale, il faut veiller à ce que les valeurs numériques attribuées aux différentes modalités
respectent l’ordre naturel existant entre ces modalités (en dehors de cette condition d’ordre, le
choix des valeurs utilisées reste arbitraire).
Les codes utilisés pour la suite de l’analyse sont les suivants :
- variable X1 (origine culturelle de l’élève) :
o origine belge →1
o origine marocaine →2
o origine espagnole →3
o origine italienne →4
o origine congolaise → 5
o origine polonaise →6
o autre origine →7
2
On pourrait raisonnablement penser que la variable « score en maths » est une variable quantitative ordinale
plutôt que de rapports, d’autant plus si l’on considère qu’une différence donnée de scores n’a pas la même
signification en terme de différence de performance au début ou à la fin de l’échelle : il peut être justifié de
penser, par exemple, que l’écart de performance en maths entre un élève qui a obtenu 2 (sur 10) et un élève qui a
obtenu 3 (sur 10) n’est pas similaire à l’écart de performance existant entre un élève qui a obtenu 7 (sur 10) et un
autre qui a obtenu 8 (sur 10)). Toutefois, en sciences humaines, une telle variable sera plus généralement
considérée comme étant mesurée sur une échelle de rapports, notamment afin de pouvoir bénéficier de
techniques d’analyse statistique plus nombreuses et plus riches.
4 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée
- variable X2 (langue parlée le plus souvent à la maison) :
o français →1
o autre →0
- variables X3 (niveau d’études du père) et X4 (niveau d’études de la mère) :
o ≤ primaire →1
o secondaire inférieur →2
o secondaire supérieur →3
o supérieur non universitaire → 4
o universitaire →5
b) Construction de nouvelles variables
Etant donné que nous chercherons notamment à comparer les scores en maths des élèves
d’origine culturelle belge et des élèves d’origine culturelle étrangère (sans prise en
considération du pays étranger particulier dont est originaire le père de l’élève), il sera
pratique de construire, à partir de la variable X1, une nouvelle variable qualitative nominale –
nous la désignerons par Z1 – ne possédant plus que les deux modalités suivantes : « origine
belge » (1) et « origine étrangère » (0).
La catégorisation des variables X3 et X4 s’avèrera trop fine pour toute une série d’analyses,
d’autant plus que notre échantillon est de taille relativement petite. Il peut dès lors être
judicieux de regrouper certaines catégories. C’est ainsi que l’on peut définir, par exemple, les
nouvelles variables qualitatives ordinales Z3 et Z4, correspondant elles aussi aux niveaux
d’études du père et de la mère, mais ne possédant que les 2 modalités suivantes : « pas de
diplôme du supérieur » (1) et « diplôme de l’enseignement supérieur (universitaire ou non) »
(2).
Enfin, il peut être intéressant de considérer conjointement les niveaux d’études du père et de
la mère au travers d’une unique variable qualitative ordinale – le « niveau d’études des
parents » – construite à partir de X3 et X4. On peut ainsi proposer, par exemple, que cette
nouvelle variable, que nous désignerons par W, prenne les 3 modalités suivantes : « aucun
parent diplômé du supérieur » (1), « au moins un parent diplômé du supérieur mais aucun
parent universitaire » (2) et « au moins un parent universitaire » (3).
Bien évidemment, la définition des modalités des nouvelles variables Z3, Z4 et W ne se fait
pas au hasard. Elle doit se faire en réalité après une première analyse du lien existant entre la
variable Y (score en maths) et les variables X3 et X4, avec pour objectif de mettre en avant le
plus clairement possible les principales caractéristiques ou tendances de ce lien éventuel.
c) Matrice de données ou tableau Individus x Caractères
Il est usuel de présenter les données dans un tableau Individus x Caractères (on peut aussi
parler de matrice de données) : chaque ligne de ce tableau correspond à un élève interrogé et
chaque colonne à une variable observée ou construite (voir le tableau 1).
5 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée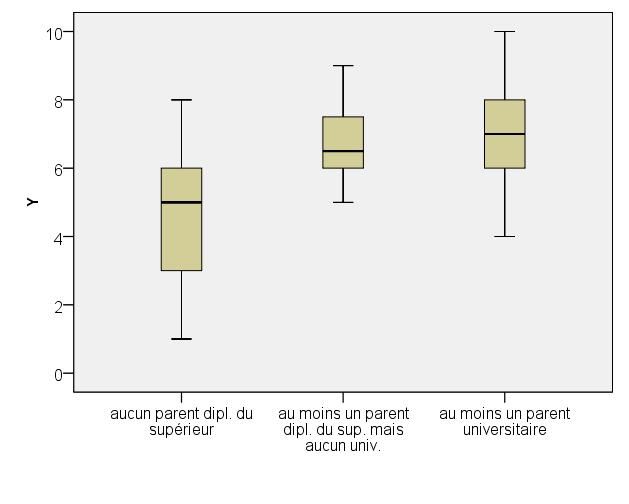
Tableau 1 : Tableau Individus x Caractères
Elève Y X1 Z1 X2 X3 Z3 X4 Z4 W X5 X6
1 3 1 1 1 3 1 3 1 1 900 700
2 3 1 1 1 3 1 1 1 1 890 520
3 2 1 1 1 2 1 1 1 1 760 730
4 4 1 1 1 1 1 3 1 1 1100 820
5 4 1 1 1 3 1 5 2 3 1400 560
6 5 1 1 1 3 1 4 2 2 1360 790
7 6 1 1 1 2 1 1 1 1 1700 810
8 6 1 1 1 4 2 2 1 2 1670 890
9 6 1 1 1 3 1 2 1 1 1400 790
10 6 1 1 1 5 2 5 2 3 1970 850
11 6 1 1 1 4 2 4 2 2 1760 910
12 6 1 1 1 3 1 3 1 1 1800 950
13 7 1 1 1 5 2 3 1 3 1980 1400
14 7 1 1 1 3 1 2 1 1 1870 1100
15 7 1 1 1 4 2 5 2 3 2400 1060
16 7 1 1 1 4 2 5 2 3 2000 1390
17 7 1 1 1 4 2 3 1 2 1988 1703
18 7 1 1 1 3 1 3 1 1 2023 1200
19 7 1 1 1 3 1 4 2 2 2100 1140
20 7 1 1 1 5 2 3 1 3 1789 1678
21 7 1 1 1 1 1 2 1 1 1876 2001
22 8 1 1 1 5 2 5 2 3 2700 1790
23 8 1 1 1 4 2 4 2 2 2200 1689
24 8 1 1 1 4 2 5 2 3 2167 1890
25 8 1 1 1 5 2 4 2 3 2287 2010
26 8 1 1 1 3 1 3 1 1 2301 1567
27 9 1 1 1 5 2 4 2 3 2601 1723
28 9 1 1 1 5 2 3 1 3 2534 1649
29 9 1 1 1 4 2 2 1 2 2445 1897
30 10 1 1 1 5 2 2 1 3 2519 1500
31 1 2 0 1 1 1 3 1 1 700 650
32 2 4 0 0 1 1 2 1 1 750 800
33 2 6 0 0 2 1 1 1 1 710 690
34 3 3 0 0 2 1 2 1 1 812 700
35 3 2 0 0 2 1 3 1 1 790 700
36 4 4 0 0 3 1 5 2 3 892 500
37 4 5 0 0 2 1 2 1 1 790 720
38 4 6 0 0 3 1 2 1 1 921 650
39 5 4 0 1 4 2 3 1 2 989 710
40 5 7 0 1 1 1 3 1 1 1289 640
41 5 5 0 0 3 1 3 1 1 1123 500
42 5 3 0 0 3 1 2 1 1 1235 650
43 5 2 0 1 2 1 1 1 1 1389 700
44 5 7 0 0 2 1 3 1 1 1273 1000
45 5 3 0 0 2 1 2 1 1 1289 900
46 5 3 0 0 3 1 5 2 3 1199 1500
47 6 4 0 0 3 1 4 2 2 1387 1234
48 6 7 0 1 4 2 5 2 3 1678 800
49 6 2 0 1 4 2 4 2 2 1489 1190
6 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée50 6 3 0 0 5 2 3 1 3 1678 1290
51 6 2 0 1 3 1 2 1 1 1890 900
52 7 5 0 1 3 1 3 1 1 1820 1293
53 7 3 0 1 4 2 4 2 2 1799 1000
54 7 5 0 1 4 2 5 2 3 1989 1700
55 7 6 0 0 5 2 3 1 3 2032 1209
56 8 5 0 1 4 2 5 2 3 2000 1200
57 8 4 0 1 4 2 3 1 2 2124 1890
58 8 4 0 1 3 1 3 1 1 1990 1500
59 8 6 0 1 5 2 4 2 3 2089 1773
60 9 5 0 1 5 2 5 2 3 2100 1456
3. ANALYSE DESCRIPTIVE DE LA VARIABLE Y
Notre analyse descriptive de la variable Y (score en maths) se fera en plusieurs étapes. Nous
commencerons par étudier la distribution observée des effectifs et des fréquences, puis des
effectifs cumulés et des fréquences cumulées. Nous déterminerons ensuite différentes mesures
de position, de dispersion et d’asymétrie, afin de mettre en évidence les principales
caractéristiques des scores en maths observés.
3.1 D.O.1 des effectifs et des fréquences
La distribution observée (D.O.1) des effectifs et des fréquences est présentée dans le tableau 2
ci-dessous.
Tableau 2 : D.O.1 des effectifs et des fréquences
Scores en maths Effectifs Fréquences
1 1 1,67 %
2 3 5,00 %
3 4 6,67 %
4 5 8,33 %
5 9 15,00 %
6 11 18,33 %
7 13 21,67 %
8 9 15,0 %
9 4 6,67 %
10 1 1,67 %
Total 60 100 %
Cette D.O.1 met en évidence les caractéristiques suivantes :
- Le moins bon score en maths est égal à 1 (sur 10) ; un seul des 60 élèves (soit
1/60=1,67% des élèves) a obtenu ce score catastrophique.
- Le score maximal de 10 (sur 10) a été atteint par un élève (soit 1,67% des élèves de
l’échantillon).
7 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariée- Les deux scores les plus fréquemment atteints sont 6 (score obtenu par 11 des 60
élèves, soit 18,33% des élèves) et 7 (score obtenu par 13 des 60 élèves, soit 21,67%
des élèves).
Nous pouvons représenter la D.O.1 à l’aide d’un diagramme en bâtons (des effectifs, par
exemple).
14 nj 13
13
12
11
11
10
9 9
9
8
7
6
5
5
4 4
4
3
3
2
1 1
1 xoj
0
0 1 2 3 4 5 6 7 8 9 10 11
Figure 1 : Diagramme en bâtons des effectifs
3.2 D.O.1 des effectifs cumulés et des fréquences cumulées
La distribution observée (D.O.1) des effectifs cumulés et des fréquences cumulées est
présentée dans le tableau 3.
Tableau 3 : D.O.1 des effectifs cumulés et des fréquences cumulées
Scores en maths Effectifs Fréquences Eff. cumulés Fréq. cumulées
1 1 1,67 % 1 1,67 %
2 3 5,00 % 4 6,67 %
3 4 6,67 % 8 13,33 %
4 5 8,33 % 13 21,67 %
5 9 15,00 % 22 36,67 %
6 11 18,33 % 33 55,00 %
7 13 21,67 % 46 76,67 %
8 9 15,0 % 55 91,67 %
9 4 6,67 % 59 98,33 %
10 1 1,67 % 60 100 %
Total 60 100 %
On peut observer qu’un peu plus d’un élève sur 5 (21,67% des élèves) a obtenu un score
inférieur ou égal à 4 ; un peu plus de la moitié des élèves (55% des élèves) ont réalisé un
8 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéescore en maths inférieur ou égal à 6 ; un peu plus du ¾ des élèves (76,67%) ont obtenu un
score inférieur ou égal à 7.
La distribution observée des effectifs (fréquences) cumulé(e)s peut être représentée
graphiquement à l’aide de la courbe cumulative des effectifs (fréquences).
70 Nj
59 60
60
55
50 46
40
33
30
22
20
13
10 8
4
1 xoj
0
0 1 2 3 4 5 6 7 8 9 10 11
Figure 2 : Courbe cumulative des effectifs
3.3 Mesures de position
Afin de faciliter le calcul des différentes mesures de position et de dispersion (plus
spécifiquement de la moyenne et de la variance), nous pouvons d’ores et déjà compléter le
tableau 2 par deux colonnes contenant les quantités (les scores distincts observés,
multipliés par leurs effectifs) et (les scores distincts observés au carré, multipliés par
leurs effectifs).
Tableau 4 : D.O.1 des effectifs et des fréquences, avec calculs intermédiaires
1 1 1,67 % 1 1
2 3 5,00 % 6 12
3 4 6,67 % 12 36
4 5 8,33 % 20 80
5 9 15,00 % 45 225
6 11 18,33 % 66 396
7 13 21,67 % 91 637
8 9 15,0 % 72 576
9 4 6,67 % 36 324
10 1 1,67 % 10 100
Total 60 100 % 359 2387
9 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéea) Le mode ( )
Le score en maths le plus fréquemment observé dans l’échantillon est le score de 7 (sur 10) ;
il a été obtenu par 13 des 60 élèves (soit un peu plus d’un élève sur cinq).
b) La moyenne ( )
La moyenne des scores en maths obtenus par les élèves de l’échantillon est égale à
359
5,983.
60
Notons que ce score moyen n’est que légèrement supérieur à la note de 5/10 sous laquelle un
élève est considéré comme étant en échec au test en mathématiques.
c) La médiane ( / )
La médiane se détermine aisément à partir du tableau 3 ou de la figure 2. Elle est égale au
plus petit score observé auquel est associé un effectif cumulé supérieur ou égal à 60/2=30 (ou
encore, de manière équivalente, au plus petit score observé auquel est associée une fréquence
cumulée supérieure ou égale à 50%) ; la médiane est donc égale au score de 6 (sur 10).
On a en fait un petit peu plus de la moitié des élèves (exactement 33 élèves sur 60, soit 55%
des élèves) qui ont obtenu un score en maths inférieur ou égal à 6 sur 10. En d’autres termes,
les 55% d’élèves les plus faibles en maths dans l’échantillon ont au mieux atteint le score de 6
sur 10 ; l’autre petite moitié des élèves les plus forts en maths ont tous au moins obtenu 7 sur
10.
Observons ici que la moyenne et la médiane des scores en maths ont des valeurs très proches
l’une de l’autre ; ceci est une conséquence du caractère relativement symétrique de la
distribution observée des scores (cette relative symétrie s’observe aisément sur la figure 1).
d) Premier et troisième quartiles ( / et y / ), premier et neuvième déciles ( / et
y/ )
Le calcul de la médiane peut être complété par la détermination d’autres quantiles. Ceux-ci
permettent de mettre en avant certaines caractéristiques importantes de la distribution des
scores en maths dans l’échantillon. Ainsi, par exemple, les trois quartiles (parmi lesquels se
retrouve la médiane) vont nous permettre de voir la note maximale obtenue par les (environ)
25%, 50% et 75% d’élèves les moins performants.
Ces différents quantiles sont déterminés, tout comme la médiane, à partir du tableau 3 ou de la
figure 2.
Le plus petit score auquel est associé un effectif cumulé
- supérieur ou égal à 60/4=15 est le score de 5 (l’effectif cumulé qui lui correspond est
égal à 22 et la fréquence cumulée est égale 36,67%) : / 5;
- supérieur ou égal à (3*60)/4=45 est le score de 7 (l’effectif cumulé qui lui correspond
est égal à 46 et la fréquence cumulée est égale à 76,67%) : / 7;
- supérieur ou égal à 60/10=6 est le score de 3 (l’effectif cumulé qui lui correspond est
égal à 8 et la fréquence cumulée est égale à 13,33%) : / 3;
- supérieur ou égal à (9*60)/10=54 est le score de 8 (l’effectif cumulé qui lui correspond
est égal à 55 et la fréquence cumulée est égale à 91,67%) : / 8.
10 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeLes 13,33% d’élèves les plus faibles ont au mieux obtenu 3 sur 10 en maths et les 36,67%
d’élèves les plus faibles ont obtenu des scores inférieurs ou égaux à 5 sur 10.
Un peu plus des trois quarts des élèves ont obtenu un score en maths inférieur ou égal à 7 sur
10 et un peu plus de 9 élèves sur 10 ont obtenu un score inférieur ou égal à 8 sur 10. En
d’autres termes, un peu moins d’un quart des élèves de l’échantillon ont obtenu un score en
maths supérieur ou égal à 8 sur 10 ; un peu moins de 10% des élèves de l’échantillon ont
obtenu un excellent score de 9 ou 10.
3.4 Mesures de dispersion
a) L’étendue ( )
L’étendue est l’écart entre le score le plus élevé et le score le plus faible observés dans
l’échantillon ; elle est donc égale à 10-1=9.
b) Les écarts interquartile ( ; ) et interdécile ( ; )
L’intervalle interquartile est l’intervalle allant du premier quartile / au troisième quartile
/ ; il s’agit donc de l’intervalle 5; 7 . Environ 50% des élèves de l’échantillon (exactement
15% + 18,33% + 21,67% = 55% des élèves ; voir le tableau 3) ont obtenu un score en maths
appartenant à cet intervalle. L’écart interquartile est égal à la longueur de cet intervalle :
; / / 7 5 2.
Selon la même logique, l’intervalle interdécile est l’intervalle allant du premier décile /
au neuvième décile / ; il s’agit donc de l’intervalle 3; 8 . Environ 80% des élèves de
l’échantillon (exactement 6,67% + 8,33% + 15% + 18,33% + 21,67% + 15% = 85% des
élèves ; voir le tableau 3) ont obtenu un score en maths appartenant à cet intervalle. L’écart
interdécile est égal à la longueur de cet intervalle : ; / / 8 3 5.
c) La boîte à moustaches
Nous avons déjà vu que la médiane des scores en maths était égale à 6 et que le premier et le
troisième quartiles valaient respectivement 5 et 7.
Les valeurs pivots gauche et droite sont dès lors égales à
/ 1,5 ⁄ ⁄ 5 1,5 2 5 3 2
et
/ 1,5 ⁄ ⁄ 7 1,5 2 7 3 10 .
Le pivot droit est égal au score observé le plus élevé ; dès lors, la valeur adjacente droite,
extrémité de la moustache droite, est égale à ce pivot droit : 10.
En revanche, on a observé un score de 1, strictement inférieur au pivot gauche. Il s’ensuit que
la valeur adjacente gauche ( ), extrémité de la moustache gauche, est égale au pivot gauche
et que le score de 1 correspond à une valeur extérieure (il s’agit du score obtenu par l’élève
n° 31).
11 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeFigure 3 : Boîte à moustaches
d) La variance ( ), l’écart-type ( ) et le coefficient de variation (CV)
La dernière colonne du tableau 4 nous permet d’obtenir aisément la variance des scores en
maths observés dans l’échantillon :
5,983 39,783 35,796 3,987.
L’écart-type n’est autre que la racine carrée de cette variance :
√3,987 1,997.
Le coefficient de variation est égal à
⁄ 1,997⁄5,983 0,334 33,4% ;
il nous indique que l’écart-type correspond à un peu plus de 33% de la moyenne.
Observons encore que l’intervalle remarquable ; = 3,986; 7,980 contient
63,33% (= 8,33% + 15% + 18,33% + 21,67% ; voir le tableau 3) des élèves ; l’intervalle
2 ; 2 = 1,989; 9,977 contient 96,67% (voir le tableau 3) des élèves.
3.5 Mesures d’asymétrie
Les deux coefficients empiriques d’asymétrie s’obtiennent aisément.
Le coefficient de Pearson est égal à
5,983 7
0,51;
1,997
le coefficient empirique de Yule et Kendall est égal à
/ / / / 7 6 6 5 1 1
0.
/ / 7 5 2
Le signe négatif du premier coefficient empirique objective l’existence d’une très légère
asymétrie à droite (la moyenne étant légèrement plus petite que le mode). Le second
coefficient empirique est nul (puisque la médiane se trouve exactement au centre de
12 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéel’intervalle interquartile), objectivant ainsi l’absence d’une asymétrie marquée de la
distribution des scores en maths.
4. STATISTIQUE DESCRIPTIVE BIVARIEE
Après cette première analyse descriptive des performances en maths dans notre échantillon,
intéressons-nous au lien éventuel existant entre la variable Y et les autres variables observées.
Nous allons ainsi réaliser diverses analyses descriptives bivariées dans le but de vérifier les 4
hypothèses de recherche suivantes :
- H1 : les élèves d’origine culturelle étrangère ont tendance à obtenir des scores en
maths plus faibles que les élèves d’origine culturelle belge ;
- H2 : les élèves qui parlent à la maison la même langue que celle utilisée à l’école ont
tendance à présenter de meilleures performances en maths que ceux parlant une autre
langue à la maison ;
- H3 : plus le statut socio-économique des parents d’un élève est élevé, plus celui-ci a
tendance à obtenir un bon score en maths ;
- H4 : plus le niveau de diplôme des parents d’un élève est élevé, plus la performance en
maths de celui-ci est élevée.
4.1 Vérification de l’hypothèse de recherche H1 – Etude du lien entre les
variables Y et Z1
Pour étudier le lien existant entre la performance en mathématiques et l’origine culturelle de
l’élève, il nous faut comparer la distribution de la variable Y dans le sous-échantillon
constitué des élèves d’origine culturelle étrangère et dans celui constitué des élèves d’origine
culturelle belge. En d’autres termes, nous devons comparer la distribution conditionnelle de Y
étant donné que Z1 vaut 0 et la distribution conditionnelle de Y étant donné que Z1 vaut 1.
L’analyse de chacune des deux distributions conditionnelles de Y se fera suivant la même
démarche que celle suivie dans la section 3.
Tableau 5 : Distribution des scores en maths selon l’origine culturelle des élèves
Origine culturelle étrangère Origine étrangère belge
Scores Eff. Fréq. Eff. cum. Fréq. cum. Eff. Fréq. Eff. cum. Fréq. cum.
1 1 3,3 % 1 3,3 % 0 0,0 % 0 0,0 %
2 2 6,7 % 3 10,0 % 1 3,3 % 1 3,3 %
3 2 6,7 % 5 16,7 % 2 6,7 % 3 10,0 %
4 3 10,0 % 8 26,7 % 2 6,7 % 5 16,7 %
5 8 26,7 % 16 53,4 % 1 3,3 % 6 20,0 %
6 5 16,7 % 21 70,1 % 6 20,0 % 12 40,0 %
7 4 13,3 % 25 83,4 % 9 30,0 % 21 70,0 %
8 4 13,3 % 29 96,7 % 5 16,7 % 26 86,7 %
9 1 3,3 % 30 100 % 3 10,0 % 29 96,7 %
10 0 0,0 % 30 100 % 1 3,3 % 30 100 %
Total 30 100 % 30 100 %
Parmi les élèves d’origine culturelle étrangère, le moins bon score obtenu est 1 et le meilleur
score atteint est 9 ; parmi les élèves d’origine culturelle belge, le plus petit score observé est 2
et le plus grand score est 10.
13 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeLe score le plus fréquemment observé est égal à 5 chez les élèves d’origine culturelle
étrangère (ce score a été atteint par 8 des 30 élèves d’origine culturelle étrangère), à 7 chez les
élèves d’origine culturelle belge (ce score a été obtenu par 9 des 30 élèves d’origine culturelle
belge).
Un peu plus de la moitié (53,4%) des élèves d’origine culturelle étrangère ont obtenu une note
inférieure ou égale à 5 ; ce n’est le cas que pour 20% des élèves d’origine culturelle belge.
Une très large part (80%) des élèves d’origine culturelle étrangère ont obtenu une note entre 4
et 8 ; parmi les élèves d’origine culturelle belge, 76,7% des jeunes ont atteint un score entre 6
et 9.
Les diagrammes en bâtons de la figure 4 illustrent clairement les remarques que nous avons
faites sur la base du tableau 5. Le diagramme en bâtons pour les élèves d’origine belge
apparaît légèrement décalé vers la droite par rapport à celui pour les élèves d’origine
étrangère.
Figure 4 : Diagramme en bâtons des effectifs pour la variable « score en maths »
selon l’origine culturelle des élèves
Il semble donc que les scores en maths atteints par les élèves d’origine culturelle étrangère
soient globalement plus faibles que ceux obtenus par les élèves d’origine belge. Ceci se
confirme lorsqu’on compare les mesures de position et de dispersion des deux sous-
échantillons.
Toutes les mesures de position calculées pour les élèves d’origine culturelle belge (mode,
moyenne, médiane, 1er et 3e quartiles, 1er et 9e déciles) ont des valeurs supérieures à celles
obtenues pour les élèves d’origine culturelle étrangère (voir le tableau 6). Ainsi, par exemple,
le score moyen des élèves d’origine culturelle belge s’élève à 6,57, alors que celui des élèves
d’origine culturelle étrangère est égal à 5,40.
14 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeTableau 6 : Mesures de position, de dispersion et d’asymétrie pour la variable « score en
maths » selon l’origine culturelle des élèves
Origine culturelle
étrangère belge
Mode 5 7
Moyenne 5,40 6,57
Médiane 5 7
1er quartile 4 6
3e quartile 7 8
1er décile 2 3
9e décile 8 9
Étendue 8 8
Ecart interquartile 3 2
Ecart interdécile 6 6
Variance 4,04 3,76
Ecart-type 2,01 1,94
Coeff. de variation 37,2 % 29,5 %
Coeff. d’asym de Pearson 0,20 -0,22
Coeff. d’asym. de Yule
0,33 0
et Kendall
La dispersion des scores en maths apparaît légèrement plus faible parmi les élèves d’origine
culturelle belge. On a ainsi, par exemple, un coefficient de variation de moins de 30% parmi
les élèves d’origine culturelle belge (l’écart-type des scores qu’ils ont obtenus au test en
mathématiques représente 29,5% de la moyenne de ces scores), mais de plus de 37% parmi
les élèves d’origine culturelle étrangère.
Le fait que les élèves d’origine culturelle étrangère aient obtenu des scores en maths
globalement plus faibles et un peu plus hétérogènes que les élèves d’origine culturelle belge
est également mis en évidence par les boîtes à moustaches de la figure 5, d’autant plus que le
score de 2 (obtenu par l’élève portant le numéro 3 dans l’échantillon) ressort comme valeur
extérieure dans la boîte à moustaches obtenue pour les élèves d’origine culturelle belge.
Figure 5 : Boîte à moustaches des scores en maths selon l’origine culturelle des élèves
15 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéePour ce qui est de l’asymétrie des distributions observées dans les deux sous-échantillons, elle
n’est que très faiblement présente et n’apparaît dès lors pas comme une caractéristique
marquante. Pour les élèves d’origine culturelle belge, la moyenne est (très) légèrement
inférieure au mode et la médiane se trouve exactement au centre de l’intervalle interquartile,
ce qui explique que le coefficient empirique de Pearson soit légèrement négatif alors que le
coefficient empirique de Yule et Kendall est nul ; pour les élèves d’origine culturelle
étrangère, la moyenne est (très) légèrement supérieure au mode et la médiane est un peu plus
éloignée du 3e quartile que du 1er quartile, ce qui conduit à un coefficient empirique de
Pearson et un coefficient empirique de Yule et Kendall tous deux positifs (mais relativement
petits).
4.2 Vérification de l’hypothèse de recherche H2 – Etude du lien entre les
variables Y et X2
Parmi les 60 élèves de l’échantillon, 45 parlent habituellement le français à la maison (donc la
même langue qu’à l’école) et 15 parlent le plus souvent une autre langue (ces 15 élèves sont
tous d’origine culturelle étrangère).
Tableau 7 : Distribution des scores en maths selon la langue parlée à la maison
Français Autre
Scores Eff. Eff. cum. Eff. Eff. cum.
1 1 1 0 0
2 1 2 2 2
3 2 4 2 4
4 2 6 3 7
5 4 10 5 12
6 9 19 2 14
7 12 31 1 15
8 9 40 0 15
9 4 44 0 15
10 1 45 0 15
Total 45 15
Le diagramme en bâtons représentant la distribution des scores en maths des élèves parlant le
français chez eux apparaît clairement décalé vers la droite par rapport à celui associé à la
distribution des scores des élèves parlant habituellement une autre langue. Il semble donc que
notre hypothèse de recherche H2 se vérifie dans notre échantillon : les élèves qui parlent à la
maison la même langue que celle utilisée à l’école ont tendance à présenter de meilleures
performances en maths que ceux parlant une autre langue à la maison.
16 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeFigure 6 : Diagramme en bâtons des fréquences pour la variable « score en maths »
selon la langue parlée à la maison
Les mesures de position présentées dans le tableau 8 ne font que conforter cette constatation :
elles sont toutes plus élevées dans le sous-échantillon des élèves parlant le français à la
maison que dans celui des élèves parlant habituellement une autre langue.
Tableau 8 : Mesures de position, de dispersion et d’asymétrie pour la variable « score en
maths » selon la langue parlée à la maison
Langue
Français Autre
Mode 7 5
Moyenne 6,51 4,40
Médiane 7 5
1er quartile 6 3
3e quartile 8 5
1er décile 4 2
9e décile 9 6
Étendue 9 5
Ecart interquartile 2 2
Ecart interdécile 5 4
Variance 3,54 1,97
Ecart-type 1,88 1,40
Coeff. de variation 28,9 % 31,8 %
Coeff. d’asym de Pearson -0,26 -0,43
Coeff. d’asym. de Yule
0 -1
et Kendall
La comparaison des boîtes à moustaches va bien évidemment aussi dans le sens de
l’hypothèse H2, mais il est intéressant de noter que deux élèves parlant habituellement le
français ont obtenu des scores en maths particulièrement faibles.
La comparaison des boîtes à moustaches et des mesures de dispersion reprises dans le tableau
8 nous indique par ailleurs que la dispersion des scores en maths est légèrement plus
17 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeimportante parmi les élèves parlant le français que parmi ceux parlant habituellement une
autre langue.
Figure 7 : Boîte à moustaches des scores en maths selon la langue parlée à la maison
Enfin, l’allure des diagrammes en bâtons et les coefficients d’asymétrie empiriques (voir le
tableau 8) objectivent l’existence d’une légère asymétrie droite de la distribution des scores en
maths dans les deux sous-échantillons.
4.3 Vérification de l’hypothèse de recherche H3 – Etude du lien entre les
variables Y, X5 et X6
Etudions à présent le lien existant entre les variables Y (score en maths), X5 (revenu mensuel
du père) et X6 (revenu mensuel de la mère).
Les pères ont, en moyenne, un revenu mensuel plus élevé que les mères (voir le tableau 9).
Par ailleurs, les revenus mensuels des mères sont légèrement plus dispersés autour du revenu
moyen que ceux des pères : en effet, le coefficient de variation est égal à 39,1%
(443,682/1 135,87) pour les revenus des mères contre 33,6% (552,187/1 645,10) pour les
revenus des pères.
Tableau 9 : Moyennes et écarts-types pour les variables Y, X5 et X6
Variable Moyenne Ecart-type
Y 5,98 1,997
X5 1 645,10 552,187
X6 1 135,87 443,682
Le coefficient de corrélation (de Pearson) entre les variables X5 et X6 est égal à 0,783 (voir le
tableau 10). Il existe donc une association linéaire et positive assez marquée entre les revenus
des pères et ceux des mères. Comme le montre clairement le troisième nuage de points de la
figure 8, les élèves dont le père a un revenu mensuel plutôt élevé (plus élevé que la moyenne)
18 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeont généralement aussi une mère disposant d’un revenu mensuel relativement élevé, alors que
les élèves dont le père a un revenu mensuel plutôt faible (plus faible que la moyenne) ont le
plus souvent une mère ayant un revenu mensuel faible.
Tableau 10 : Matrice de corrélation entre les variables Y, X5 et X6
Y X5 X6
Y 1 0,941 0,789
X5 0,941 1 0,783
X6 0,789 0,783 1
Si la variable « score en maths » est fortement corrélée positivement avec la variable « revenu
mensuel de la mère » (coeff. de corrélation égal à 0,789 ; voir aussi le deuxième nuage de
points de la figure 8), elle l’est encore plus fortement avec la variable « revenu mensuel du
père » (coeff. de corrélation égal à 0,941 ; voir aussi le premier nuage de points de la figure
8). Il apparaît donc que les élèves vivant dans un milieu économiquement favorisé aient
tendance à atteindre de meilleurs scores en maths que les élèves ayant des parents aux revenus
plus faibles. Cette constatation confirme ce que d’autres études ont déjà pu montrer ; le fait de
vivre dans un milieu de niveau socio-économique élevé semble être un facteur favorisant la
réussite scolaire d’un jeune, et notamment en mathématiques.
Figure 8 : Graphiques de dispersion entre les variables Y, X5 et X6
19 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeInsistons toutefois sur le fait qu’il ne s’agit que d’une tendance et non d’un lien déterministe :
une augmentation du revenu mensuel du père et/ou de la mère n’implique pas nécessairement
une augmentation du score en maths ; d’autres facteurs que le revenu des parents peuvent
influencer les performances scolaires des élèves et il est donc tout à fait possible pour un
élève dont les parents ont des revenus faibles d’obtenir un meilleur score en maths qu’un
condisciple dont les parents auraient des revenus supérieurs.
Nous avons, sur les nuages de points de la figure 8, différencié les élèves d’origine culturelle
belge (points verts) et ceux d’origine culturelle étrangère (points bleus). Ceci nous permet de
constater que les élèves qui ont des parents (surtout un père) aux revenus élevés sont pour la
plupart d’origine culturelle belge, alors que les élèves dont les parents ne bénéficient que de
revenus plus faibles sont souvent aussi d’origine culturelle étrangère. La variable « origine
culturelle » est donc étroitement liée à la variable « revenu mensuel du père » et, dans une
moindre mesure, à la variable « revenu mensuel de la mère ».
Tentons à présent de modéliser le lien linéaire et positif unissant la variable Y (score en
maths) à la variable X5 (revenu mensuel du père) à l’aide de la droite de régression de Y en
X5. Cette droite a pour équation , où la pente b est égale à
0,941 1,997
0,0034
552,187
et l’ordonnée à l’origine a est égale à
5,98 0,0034 1 645,10 0,3867
(voir la figure 9).
Figure 9 : Droite de régression de Y en X5
Le coefficient de détermination associé à cette régression est égal à 0,941
0,886 ; plus de 88% de la variance des scores en maths observés peuvent être expliqués par le
lien unissant ces scores au revenu mensuel du père (la dispersion des revenus induit une
dispersion des scores prédits par la droite de régression ; le coeff. de détermination correspond
à la part de la variance des scores observés captée par la variance reg des scores prédits).
20 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeLe revenu mensuel du père apparaît donc comme un facteur ayant un pouvoir prédictif
(explicatif) élevé sur la performance en mathématiques.
On a précisément 1,997 3,988 et reg 0,886 3,988 3,533 ; il
s’ensuit que la variance résiduelle est égale à . reg 3,988 3,533 0,455.
Cette variance résiduelle est faible, objectivant une faible dispersion des résidus de la
régression, donc une forte concentration du nuage de points de Y en fonction de X5 autour de
la droite de régression (voir la figure 9).
La qualité de l’ajustement du nuage de points par la droite de régression n’est cependant pas
parfaite. En effet, le graphique des résidus de la régression en fonction des revenus des pères
(figure 10) ne montre pas de structure particulière – ce qui nous confirme le fait que la
structure du nuage de points croisant Y et X5 est bien linéaire, pouvant donc être modélisée
par une droite – mais la boîte à moustaches des résidus (figure 11) n’est pas parfaitement
symétrique et, surtout, met en évidence trois résidus extérieurs (nettement plus petits que les
autres résidus). Il s’agit des résidus associés aux élèves portant les numéros 15, 22 et 31, trois
élèves qui ont obtenu des scores en maths « anormalement » faibles pour le niveau de revenu
mensuel de leur père3.
Figure 10 : Graphique de dispersion entre les résidus de la régression de Y en X5
et la variable Y
3
Considérons par exemple l’élève n°22. Etant donné que le revenu mensuel de son père s’élève à 2 700 euros (il
s’agit du revenu le plus élevé parmi tous les revenus paternels observés), la droite de régression prédit pour cet
élève un score en maths de 0,3867 0,0034 2 700 9,5667. Or, cet élève a en réalité obtenu un score égal
à 8. L’erreur de prédiction (résidu) est donc égale à 8 9,5667 1,5667 ; elle est considérée comme valeur
extérieure dans la boîte à moustaches des résidus de la régression.
21 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeFigure 11 : Boîte à moustaches pour les résidus de la régression de Y en X5
4.4 Vérification de l’hypothèse de recherche H4 – Etude du lien entre les
variables Y, X3 (ou Z3), X4 (ou Z4) et W
La situation socio-économique-culturelle d’un jeune est aussi déterminée par le niveau
d’études de ses parents. Vérifions à présent s’il existe un lien entre la performance en
mathématiques d’un élève et le niveau d’études de ses parents. Dans un premier temps, nous
prendrons en compte les niveaux d’études du père et de la mère au travers des variables X3 et
X4.
4.4.1 Etude du lien entre les variables X3 et X4
Considérons tout d’abord le tableau de contingence des effectifs et des fréquences croisant les
variables X3 (niveau d’études du père) et X4 (niveau d’études de la mère).
Tableau 11.a : Tableau de contingence (effectifs) croisant les variables X3 et X4
Niveau d’études de la mère (X4)Tableau 11.b : Tableau de contingence (fréquences) croisant les variables X3 et X4
Niveau d’études de la mère (X4)Nous pouvons plus clairement synthétiser la situation en considérant plutôt les niveaux
d’études du père et de la mère au travers des variables dichotomiques Z3 et Z4 (2 modalités :
« pas de diplôme du supérieur » et « diplôme de l’enseignement supérieur (universitaire ou
non) »). Comme nous l’indique le tableau 13, 36,7% des élèves ont leur mère diplômée de
l’enseignement supérieur ; ce n’est cependant le cas que pour un peu plus de 18% des élèves
dont le père n’a pas dépassé le niveau secondaire, mais pour presque 60% des élèves dont le
père est lui aussi porteur d’un diplôme du supérieur.
Tableau 13 : Distributions conditionnelles de Z4 sachant Z3 – Profils-lignes associés aux
deux modalités de Z3
Niveau d’études de la mère (Z4)
Pas de dipl. du Diplôme
Total
supérieur du supérieur
Pas de dipl. Eff. 27 6 33
Niveau
du supérieur Fréq. 81,8 % 18,2 % 100 %
d’études
Diplôme Eff. 11 16 27
du père (Z3)
du supérieur Fréq. 40,7 % 59,3 % 100 %
Eff. 38 22 60
Total
Fréq. 63,3 % 36,7 % 100 %
4.4.2 Etude du lien entre les variables Y et Z3
De quelle manière les scores en maths des élèves sont-ils liés aux niveaux d’études des
pères ?
Comme le montrent très clairement les diagrammes en bâtons de la figure 12, les mesures de
position présentées dans le tableau 14 et les boîtes à moustaches de la figure 13, les élèves
dont le père est diplômé de l’enseignement supérieur ont obtenu des scores en maths
globalement plus élevés que ceux atteints par les autres élèves. Notons encore que la
dispersion des scores en maths est légèrement plus faible chez les élèves dont le père est
diplômé de l’enseignement supérieur (voir les mesures de dispersion reprises dans le tableau
14 et les boîtes à moustaches de la figure 13).
Tableau 13 : Distribution des scores en maths selon le niveau d’études du père
Pas diplômé Diplômé
du supérieur du supérieur
Scores Eff. Eff. cum. Eff. Eff. cum.
1 1 1 0 0
2 3 4 0 0
3 4 8 0 0
4 5 13 0 0
5 8 21 1 1
6 5 26 6 7
7 5 31 8 15
8 2 33 7 22
9 0 33 4 26
10 0 33 1 27
Total 33 27
24 STAT‐D‐103/104 – Exemple transversal – Stat. descriptive uni‐ et bivariéeVous pouvez aussi lire