Statistiques descriptives d'un couple de variables
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Statistiques descriptives d’un couple de variables
Benoit Gaüzère, Stéphane Canu
benoit.gauzere@insa-rouen.fr
INSA Rouen Normandie - ITI
February 8, 2021
Exemples de couples de variables
Low–income countries Middle–income countries High–income countries
85
Japan France
Gapminder World Map 2010
Sweden
Germany Hong Kong
Andorra
Italy Iceland
Switzerland
Spain Australia Singa-
Israel Canada pore Norway
1
New Zealand Finland Liechten-
80 Puerto Malta Netherlands stein
Healthy 3 2
Cuba Costa Rico South Bel- Ireland Lux-
Rica Chile Korea GreeceUK gium Austria embourg
USA
China
Portugal Slovenia Denmark
Albania
Mexico Barbados Taiwan
UAE
Kuwait
Belize Uruguay Croatia Czech Rep. Brunei
Grenada Panama Argen- Oman
Vietnam Bosnia & H. Dominica tina Poland Bahrain Qatar
75 Poor Rich Kosovo Syria Venezuela
Ecuador Macedonia4 Serbia
Slovakia
Malaysia Antigua & Barbuda
Sri Lanka Tunisia Colo-5 Libya Bahamas
Armenia Bulgaria Hungary
Nicaragua Palestine Algeria Peru mbia St Kitts & N. Estonia
Saudi Arabia
Micronesia
Honduras
Paraguay
Jordan
DR
Brazil
Romania Latvia Seychelles
Philippines Cape Tonga Leba- 1. San Marino
El Jamaica Mauritiusnon Lithuania
Maldives 6
Verde Georgia Samoa
Sick Marshall Isl. Morocco Salvador Palau
Iran Turkey
2. Monaco
Indonesia Guate-
Vanuatu 3. Cyprus
70 mala
Egypt
Azerbaijan Trinidad & 4. Montenegro
Tuvalu
Fiji Suriname Belarus Tobago
5. Saint Lucia
Moldova
Kyrgyzstan Ukraine 6. St Vincent &
Uzbe- Iraq Thailand
Nepal North kistan Grenadines
Korea Guyana
Health Life expectancy at birth (years)
Paki- Solo- Mongolia
Russia
Comoros
Tajikistan
Laos
stan mon Isl. Bolivia
Bhutan
Bangladesh
India
São Tomé
65 & P. Turkmenistan Kazakhstan
Nauru
Yemen Kiribati
Togo Colour by region:
Myanmar Benin Cambodia
Namibia
Timor-
Madagascar Haiti Papua Leste Gabon
60 Eritrea New
Guinea
Liberia Sudan
Guinea
Côte d'Ivoire
Ghana Mauritania
Tanzania Gam- Size by population:
Ethiopia bia Senegal Djibouti
55 Kenya Botswana
Malawi
Uganda
Burkina Faso
Congo, Rep.
3
100 1000
or less
10
millions
Gapminder World Chart 2010 Version May 2010b
Niger South Africa
Burundi Rwanda Cameroon
Equatorial Guinea
50 Somalia Data are for 2009 for all 192 UN member states and the other
5 countries and territories with more than 1 million people
Mozambique Mali Chad (Hong Kong, Taiwan, Palestine, Puerto Rico and Kosovo).
Congo, DR Sierra Leone Guinea-Bissau
Nigeria Angola
Free to copy, share and remix but attribute Gapminder.
For sources see:
Central African Rep. www.gapminder.org
Zambia Swaziland http://www.gapminder.org/worldmap
Zimbabwe Afghanistan Lesotho
45
500 1 000 2 000 5 000 10 000 20 000 50 000
Money GDP per person in US dollars (purchasing power adjusted) (log scale) Les distances de freinage et les
consommations d’alcool
Pourquoi étudier un couple de variables ?
I Il y a t’il des couples aberrants ?
I Ces deux variables sont elles liées ou sont elles
indépendantes ?
I Quelle est la nature de cette dépendance ?
2 / 35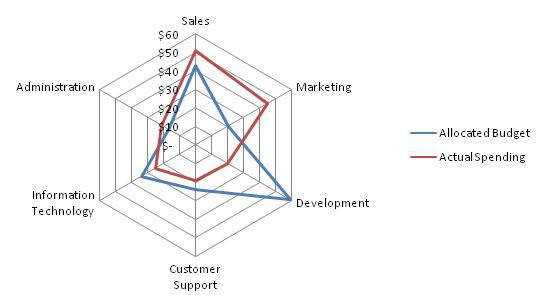
Deux variables discrètes : tableau de contingence
Considérons un échantillon où chaque observation est une vente,
décrite par deux variables qualitatives : le vendeur et le produit.
Vendeur Produit
Bob un pc
Percy un aspirateur
Percy une télé
Bob une télé ⇒
Percy une télé
Bob un mac
John un mac
Bob un lave vaisselle
3 / 35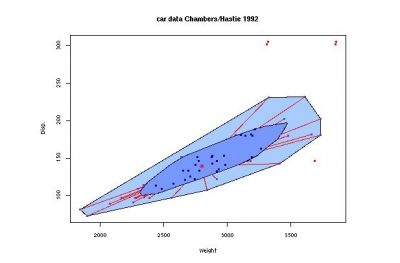
Deux variables discrètes : tableau de contingence
Considérons un échantillon où chaque observation est une vente,
décrite par deux variables qualitatives : le vendeur et le produit.
Vendeur Produit
Bob un pc Bob Percy John
Percy un aspirateur
télévision 1 2 0
Percy une télé ordinateurs 2 0 1
Bob une télé ⇒
aspirateurs 0 1 0
Percy une télé lave vaisselle 0 1 0
Bob un mac
John un mac Tableau de Contingence
Bob un lave vaisselle
3 / 35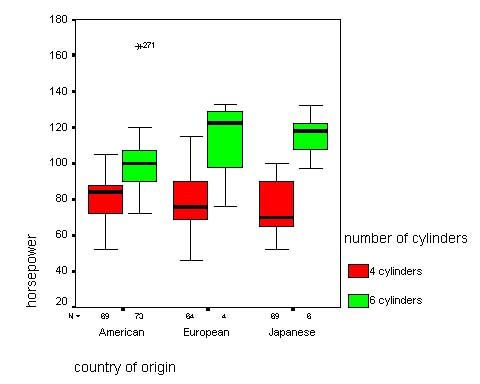
Deux variables discrètes : Tableau de contingence
Définition : Tableau de contingence
Soit X une variable discrète à ` modalités et Y une variable
discrète à k modalités. Soit
Sn = {(x1 , y1 ), (x2 , y2 ), ..., (xi , yi ), ..., (xn , yn )}
un échantillon de n observations.
On appelle Tableau de contingence de l’échantillon Sn le tableau
N de ` lignes et k colonnes dont le terme général Nij désigne
le nombre d’individus présentant conjointement les modalités
ai pour X et bj pour Y .
4 / 35Effectifs marginaux d’un tableau de contingence
Définition : Effectif marginal
L’effectif marginal ni• (n•j ) d’une modalité d’un tableau de
contingence de taille n est le nombre d’individus dans l’échantillon
pour lesquels on a observé la modalité ai (bj )
/
X Y b1 b2 ··· bj ··· bk marge
k
X a1 n11 n12 ··· n1j ··· n1k n1•
Ligne n i• = nij
.. .. .. ..
j=1 . . . .
X`
Colonne n •j = nij ai ni1 ni2 ··· nij ··· nik ni•
i=1
` X
X k .. .. ..
Total n= nij . . .
i=1 j=1
a` n`1 n`2 ··· n`j ··· n`k n`•
marge n•1 n•2 ··· n•j ··· n•k n•• = n
5 / 35Fréquences
Définition : Fréquence
nij
La fréquence fij = n , c’est un estimateur du probabilité
jointe IP(ai et bj ).
` X
X k
Par construction, nous avons fij = 1 et 0 ≤ fij ≤ 1.
i=1 j=1
6 / 35Profils
Définition : Profil Ligne et Profil Colonne
nij
On appelle Profil Ligne les nombres lij = ni• et Profil Colonne
nij
les nombres cij = n•j .
Remarques
I Les fij définissent une distribution de probabilité empirique
suivant la loi jointe IP(X = ai , Y = bj ) = fij
I Les profils ligne définissent des probabilités empiriques de la
loi conditionnelle IP(Y = bj |X = ai )
I Les profils colonne les probabilités empiriques de la loi
conditionnelle IP(X = ai |Y = bj )
7 / 35Exemple de tableau de contingence
Marges, fréquences et profils
Bob Percy John
TV 12 21 12
PC 21 12 14
VC 22 31 14
LV 4 17 5
8 / 35Exemple de tableau de contingence
Marges, fréquences et profils
Bob Percy John Marge
TV 12 21 12 45
PC 21 12 14 47
VC 22 31 14 67
LV 4 17 5 26
Marge 59 81 45 185
8 / 35Exemple de tableau de contingence
Marges, fréquences et profils
Bob Percy John Fréquences
12 21 12 45
TV 185 185 185 185
21 12 14 47
PC 185 185 185 185
22 31 14 67
VC 185 185 185 185
4 17 5 26
LV 185 185 185 185
59 81 45 185
Fréquences 185 185 185 185 = 1
Tableau de contingence avec Fréquences
9 / 35Exemple de tableau de contingence
Marges, fréquences et profils
Bob Percy John
12 21 12
TV 59 81 45
I Profils colonnes: PC 21 12 14
59 81 45
22 31 14
VC 59 81 45
4 17 5
LV 59 81 45
Bob Percy John
12 21 12
TV 45 45 45
I Profils lignes: PC 21 12 14
47 47 47
22 31 14
VC 67 67 67
4 17 5
LV 26 26 26
10 / 35Cas mixte : une variable discrète et l’autre continue
Performances de conduite pour trois groupes de personnes
Mesure de la distance de freinage pour 3 groupes de personnes : à
jeun, a bu une bière (G1) et a bu trois verres de vin (G2).
Sujet À jeun G. 1 G. 2
1 22 m 21 m 27 m
2 20 m 24 m 24 m
.. .. .. ..
. . . .
n 19 m 22 m 31 m
moyenne 20,9 22,5 28,3
variance 4,32 5,18 5,87
I Effet de la variable qualitative ?
I Le codage des variables a un effet.
11 / 35Tendance centrale
Moyenne
Couple des moyennes (x̄, ȳ):
n n
X X zi = (xi , yi )
min (xi −c1 )2 +(yi −c2 )2 = kzi −ck2 avec :
c1 ,c2 c = (c1 , c2 )
i=1 i=1
Médiane
Couple des médianes (Mx , My ) :
n n
X X zi = (xi , yi )
min |xi −c1 |+|yi −c2 | = kzi −ck1 avec :
c1 ,c2 c = (c1 , c2 )
i=1 i=1
12 / 35Tendance centrale : illustration 2d
13 / 35Mesure de dépendance : motivation
Moyennes et variances égales:
Comment mesurer la dépendance ?
https://moodle.insa-rouen.fr/mod/resource/view.php?id=57129
14 / 35Mesure de dépendance : cas des variables quantitatives
Variance empirique
n n
1X 1X
s2x = (xi − x̄)2 s2y = (yi − ȳ)2
n n
i=1 i=1
Covariance empirique
n n
1X 1X
sxy = (xi − x̄)(yi − ȳ) sxy = xi yi − x̄ȳ
n n
i=1 i=1
I Mesure comment les variables évoluent de manière conjointe
15 / 35Mesure de dépendance : cas des variables quantitatives
Coefficient de corrélation
n
X
1
n (xi − x̄)(yi − ȳ) Pn
sxy i=1 i − nx̄ȳ
i=1 xi yp
r= = = pPn Pn
sx sy sx sy i=1 (xi − x̄)
2
i=1 (yi − ȳ)2
I r ∈ [−1, 1]
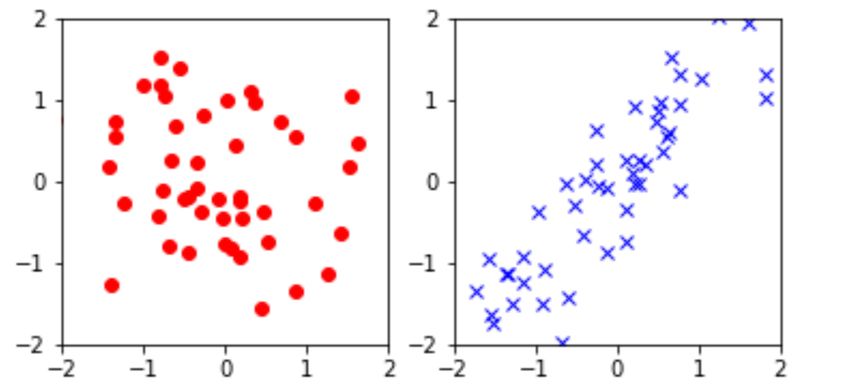
16 / 35Corrélations
17 / 35Corrélations
18 / 35Cas des variables qualitatives
Variables indépendantes
IP(x, y) = IP(x)IP(y)
Mesure du degré d’indépendance entre deux variables
Distance du χ2 entre la distribution empirique observé et celle
théorique calculée en faisant l’hypothèse d’indépendance sur le
tableau de contingence.
Bob Percy John
TV 12 21 12
PC 21 12 14
VC 22 31 14
LV 4 17 5
19 / 35Cas des variables qualitatives
Variables indépendantes
IP(x, y) = IP(x)IP(y)
Mesure du degré d’indépendance entre deux variables
Distance du χ2 entre la distribution empirique observé et celle
théorique calculée en faisant l’hypothèse d’indépendance sur le
tableau de contingence.
Bob Percy John
TV 12 21 12 45
PC 21 12 14 47
VC 22 31 14 67
LV 4 17 5 26
59 81 45 185
19 / 35Cas des variables qualitatives
Variables indépendantes
IP(x, y) = IP(x)IP(y)
Mesure du degré d’indépendance entre deux variables
Distance du χ2 entre la distribution empirique observé et celle
théorique calculée en faisant l’hypothèse d’indépendance sur le
tableau de contingence.
Bob Percy John
Bob Percy John
TV 12 21 12 45
PC 21 12 14 47 TV 14.35 19.70 10.94
VC 22 31 14 67 PC 14.98 20.57 11.43
LV 4 17 5 26 VC 21.36 29.33 16.29
LV 8.29 11.38 6.32
59 81 45 185
59 45
IP(T V, Bob) = ∗ = 14.35
185 185
19 / 35Variables qualitatives : distance du χ2
Définition : Distance du χ2
On appelle distance du χ2 du tableau de contingence n:
2
X X (nij − ni. n.j /n)2 X X b ij − IP
IP b i IP
bj
Dχ2 (X, Y ) = =n
i∈Ω j∈Ω
ni. n.j /n i∈Ω j∈Ω IP
b i IP
bj
x y x y
I Ib
Pij = nij /n : fréquence empirique de la loi jointe
I Ib
Pi = ni. /n, Ib
Pj = n.j /n: Distributions marginales empiriques
(12−14.35)2
I Dχ2 (X, Y ) = 14.35 + ...
I À comparer avec des distances de réference
20 / 35Cas mixte : l’analyse de la variance
Découpage de la variance
I X variable qualitative, Y la variable quantitative
I yij le i-ème de la modalité j.
I Variance totale:
n nj
X X X
2 2
s = (yi − ȳ) = (yij − ȳ)2 = s2inter + s2intra
i=1 j∈Ωx i=1
I Variance intra-classe
nj
X X
s2intra = (yij − y¯j )2
j∈Ωx i=1
I Variance inter-classe
nj
X X X
s2inter = (y¯j − ȳ)2 = nj (y¯j − ȳ)2
j∈Ωx i=1 j∈Ωx 21 / 35Cas mixte : l’analyse de la variance
Le rapport de corrélation
La dépendance est évaluée par le rapport des variances :
2
P
2 s2inter j∈Ω nj (y¯j − ȳ)
ηY /X = 2 = Pnx 2
s i=1 (yi − ȳ)
I Carré du rapport de corrélation ηY2 /X
I ηY2 /X ∈ [0, 1]
I ηY2 /X = 1: la variance entre les classes expliquent toute la
variance : les variables sont liées
I ηY2 /X = 0 : Pas de variance inter classe. Toute la variance est
“à l’intérieur” des classes.
I Il augmente avec p = card(Ωx )
22 / 35Mesure de ressemblance : Résumé
X Y Exemple étude de la dépendance ?
continue continue poids/taille corrélation
continue discrète poids/variété analyse de la variance
discrète discrète nombre d’enfants / PCS distance du χ2
sxy 1 Pn
i=1 (xi −x̄)(yi −ȳ)
I Corrélation : r= = n
sx sy
sx sy
2
P
j∈Ωx nj (y¯j −ȳ)
I Analyse de la variance : s2Y /X = P n
(y i −ȳ)2
i=1
(nij −ni. n.j /n)2
I Distance du χ2 :
P P
Dχ2 (X, Y ) = i∈Ωx j∈Ωy ni. n.j /n
23 / 35Résumé graphique de deux variables qualitatives
Histogrammes 2d, diagramme de Kiviat (radar, star, ou spider
charts)
et boites à moustaches
24 / 35Résumé graphique de deux variables quantitatives
25 / 35Résumé graphique : Sac à moustache
1. Centre (médiane 2d)
2. Boite (sac médian)
3. Épure
4. Moustaches
5. Points aberrant
L’analogue en deux dimensions des boites à moustaches.
26 / 35Les étapes du calcul du sac à moustaches
.
Calcul de la médiane de Tukey Calcul du sac médian .
.
Calcul de l’épure aaaa Sac à moustaches .
27 / 35Calcul du sac à moustaches
1. Calculer la médiane 2d (le barycentre des points de
profondeur maximale)
2. Sélectionner les enveloppes convexes #Dk ≤ n/2 ≤ #Dk−1
points les plus proches de la médiane, en dessiner l’enveloppe
interpolante. Le résultat est ce qu’on appelle le sac médian
(bag plot en anglais).
3. Calculer l’épure : l’enveloppe du sac médian ”gonflé” trois fois
4. Dessiner l’enveloppe convexe des points contenus dans
l’épure. Il s’agit des points situés à moins de trois fois la
distance entre le sac médian et la médiane. Une moustache
est associée à chacun des points de cette enveloppe convexe.
5. Les points en dehors de cette dernière enveloppe son marqués
comme étant hors épure.
P. J. Rousseeuw, I. Ruts & J. W. Tukey (1999): The Bagplot: A Bivariate Boxplot, The American Statistician, 53:4, 382-387
https://www.tandfonline.com/doi/abs/10.1080/00031305.1999.10474494
28 / 35Exemple d’utilisation du sac à moustaches
P. J. Rousseeuw, I. Ruts & J. W. Tukey (1999): The Bagplot: A Bivariate Boxplot, The American Statistician, 53:4, 382-387
29 / 35Conclusion
Tableau
I Qualitative et quantitative discrète : Tableau de contingence
I Quantitative (continue) : pseudo variables
Résumé quantitatif
I ordre 1 : centre (calcul)
I ordre 2 : corrélation, Anavar (anova) et χ2
I 2D est différent de 1D
Résumé qualitatif (graphique)
I Qualitative et quantitative discrète : histogramme
I Quantitative qualitative : diagramme de Kiviat
I Quantitative (continue) : nuage de points et bag plot.Bonus
Médiane de Tukey
Définition : Médiane de Tukey
C’est le centre de gravité des points de profondeur maximale
encore appelé le sous espace médian.
La définition originale est de nature géométrique, elle est complexe
mais il existe des algorithmes de calcul rapide.
La méthode des pelures d’oignon
Dk l’ensemble des points de profondeurs k
32 / 35La notion d’enveloppe convexe
Définition : Enveloppe convexe (Convex hull)
L’enveloppe convexe d’un ensemble de points est le plus pe-
tit ensemble convexe qui le contienne. Cette enveloppe con-
vexe est un polyèdre convexe dont les sommets sont les points
extérieurs.
33 / 35Calcul de la médianne de Tukey
Algorithme du calcul de la Médiane de Tukey
Pour construire la médiane de Tukey on utilise un algorithme de
type épluchage:
1. Tant qu’il reste des points non étiquetés
I Considérons l’enveloppe convexe des points non étiquetés
I on étiquette les points de cette enveloppe convexe
2. La médiane de Tukey est alors le centre de gravité (la
moyenne) du dernier ensemble de points
2
1.8
1.6
1.4
1.2
1
0.8
0.6
0.4
0.2
0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
34 / 35Corrélation : interprétation géométrique
y y−y Sans perte de généralité
supposons que x = y = c
θ 1I
r ∈ [−1, 1] analogue à cos(θ),
x−x c
ou θ c’est l’angle formé par
x
x − (x̄ × ~1) et y − (ȳ × ~1)
0
n
X
1
n (xi − x̄)(yi − ȳ) Pn
sxy i=1 i − nx̄ȳ
i=1 xi yp
r= = = pPn Pn
sx sy sx sy i=1 (xi − x̄)
2
i=1 (yi − ȳ)2
35 / 35Vous pouvez aussi lire

















































