Big Data L'émergence d'un nouveau métier de Data Scientist - Haytham Elghazel
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

UMR 5205 CNRS
Big Data
L’émergence d’un nouveau métier de Data Scientist
Haytham Elghazel
Laboratoire d’InfoRmatique en Image et S ystèmes d’information
Le Business Intelligence
2
Pour résumer
But du BI : fournir la bonne information au bon
moment, dans le bon format et à la bonne
personne
Que s’est-il passé (constat)
Que se passe t’il
Pourquoi est ce arrivé
Que va t’il se passé Data Mining
Que désirons nous qu’il se passe
3
L'omniprésence des données
Les 20 dernières années : des grands investissements
dans les infrastructures des entreprises, augmentant
leurs moyens de collecte de données
Chaque service est maintenant ouvert à la collecte
des données mais aussi instrumentalisé pour la
collecte des données: production, logistique,
propriétés ou profils des consommateurs, compagnes
de marketing, etc..
En même temps, l’information est maintenant
largement disponible sur des évenements en dehors
des entreprises : les tendances du marché, les
nouveautés de l'industrie, et les comportement des
concurrents.
4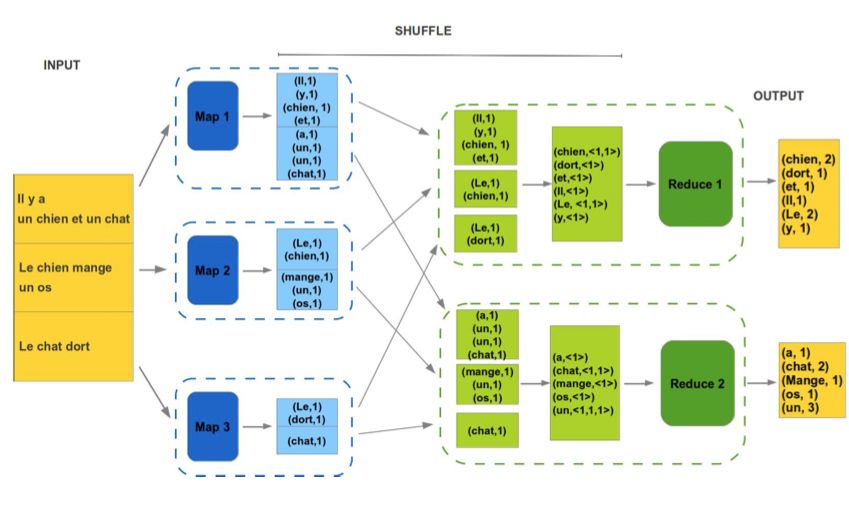
L'omniprésence des données : Linky
Le nouveau compteur intelligent Linky
Un projet Smart Grid : Linky est l’objet
connecté qui sera déployé dans 35
millions de foyers français d’ici 2020.
Un suivi de la consommation toutes les
10 minutes : Big Data par excellence
C’est aussi pour prévoir le pics de consommation, éviter le
lancement de centrales électriques, détecter les fraudes
5
L'omniprésence des données : Linky
Linky peut-il aussi savoir quel appareil ménager j’utilise ?
combien de téléviseurs je possède ? A quelle heure je prends
ma douche ? mes habitudes et donc mon profil de
consommateur : Une publicité adaptée
6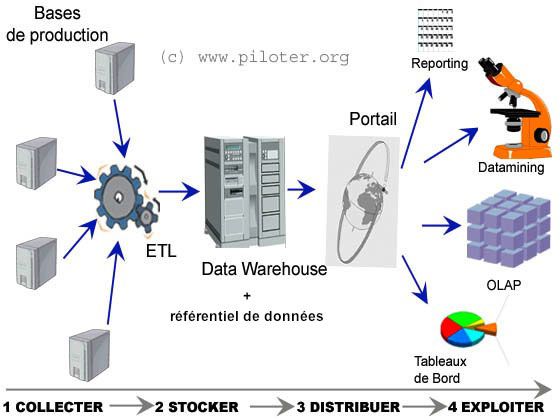
L'omniprésence des données : Freebox
La Freebox Révolution
Peu de données à la signature
d’un contrat
Et après …
Plein de nouvelles données : à quel heure vous rentrez chez
vous, à quel heure vous couchez, vos préférences télé, etc.
Une bonne analyse de vos habitudes conduira à vous
recommander la bonne chaine au bon moment (le client est
satisfait mais le FAI aussi)
7
L'omniprésence des données : les applis mobile
Nouvelles applications Web/mobiles :
La recommandation ou la publicité
n’est plus fonction du profil d’un client
ou de sa manière de naviguer
Mais plutôt de sa ressemblance aux
autres clients
Quant ces nouvelles applications
deviennent des plateformes
collaboratives (Collaborative filtering)
8
L'omniprésence des données : les applis mobile
9
Un enjeu : l’entreprise étendue
10Quelles données ?
Prolifération des données
90% des données dans le monde ont été créées au cours des deux
dernières années seulement
données produites principalement par le Web, les grands acteurs
d’Internet, les réseaux sociaux
Type de données
données structurées (données relationnelles), peu structurées (XML) ou non
structurées (textes, images, etc.)
Volumétrie des données
grandes quantités de données, données continues (datastreams)
Avènement du Big data
11Avènement du Big data
Le big data (données massives), désigne des données
tellement volumineuses qu'elles en deviennent difficiles à
travailler avec des outils classiques de gestion de base de
données ou de traitement de l'information.
Dans ces nouveaux ordres de grandeur, la collecte, le
stockage, la recherche, l’administration, le partage,
l'analyse et la visualisation des données doivent être
redéfinis au sein de notre activité.
Selon les experts et les grandes institutions, le phénomène
du big data s’annonce comme l'un des grands défis
informatiques de cette décennie et en ont fait une de leurs
nouvelles priorités de recherche et de développement.
12Certains disent que Big Data s’écrit avec
1, 2, 3 «V»
13Pour d’autres, le Big Data est avant tout
une force..
Cette large disponibilité des données rend leur
exploitation indispensable aux entreprises en vue
d’améliorer la compétitivité.
Au même moment, les ordinateurs sont de plus en
plus performants, les réseaux informatiques de
plus en plus omniprésents, et les algorithmes sont
de plus en plus développés de manière à pouvoir
travailler sur différents fragments des données
La convergence de tous ces phenomènes a
donné lieu à la forte demande des entreprises
pour l’application des outils de data mining : On
parle ici du Big Data Analytics
14Quelles perspectives pour le Big Data Analytics ?
Des outils de Datamining qui offrent une analyse
plus poussée des données permettant de
découvrir de nouvelles connaissances et donc de
nouveaux besoins :
la détection de tendances pour la recommandation
l’établissement de typologies et de segmentations
ou encore des prédictions ou des prévisions
Les perspectives du traitement des big data sont
énormes et pour partie encore insoupçonnées. Il
peut aider les entreprises à réduire les risques et
faciliter la prise de décision
15L’Analytics s’est étendu, des simples
données d’entreprise au Big Data
Volume Vitesse Varieté
12 terabytes
de Tweets créés quotidiennement
5 millions
de transactions commerciales
par seconde
100’s
en provenance de caméras
de surveillance
de flux
vidéo
Analyse de sentiment et d’opinions Identification de fraudes potentielles Surveillance / Analyse comportements
180 Millions
de dossiers de prêts par jour
500 millions
d’enregistrement d’appels
80% des données
créées
sont des images, des vidéos, des
chaque jour documents, courriers, e-mail, …
Découvrir les risques cachés Prévention de l’attrition client Amélioration de la satisfaction client
16Et quelles solutions ?
Un problème : les données deviennent de plus en
plus volumineuses. Les algorithmes de Data Mining
classiques se trouvent donc impuissants devant une
telle situation.
La solution : parallélisation massive du processus
d’analyse.
Paradigme MapReduce patron de développement
informatique popularisé par Google et utilisé dans le
framework Hadoop (High-availability distributed object-
oriented platform)
Hadoop offre une solution idéale et facile à
implémenter au problème.
17La solution : Apache Hadoop
Projet de la fondation Apache
Plate-forme Open Source, composants complètement ouverts,
tout le monde peut participer.
Un système de fichier distribué : Hadoop Distributed File System
(HDFS)
Modèle simple pour les développeurs: il suffit de développer des
tâches MapReduce, depuis des interfaces simples accessibles
via des librairies (API) dans des langages multiples (Java, Python,
etc.).
Déployable très facilement (paquets Linux pré-configurés),
configuration très simple elle aussi.
S'occupe de toutes les problématiques liées au calcul distribué,
comme l’accès et le partage des données, la tolérance aux
pannes, ou encore la répartition des tâches aux machines
membres du cluster : le programmeur a simplement à s'occuper
du développement logiciel pour l'exécution de la tâche.
18Utilisateurs d’Hadoop
19Utilisateurs d’Hadoop par taille du cluster
20Une technologie en plein essort
Pour exécuter un problème large de manière distribué, il
faut pouvoir découper le problème en plusieurs
problèmes de taille réduite à exécuter sur chaque
machine du cluster.
De multiples approches existent et ont existé pour cette
division d'un problème en plusieurs « sous-tâches ».
MapReduce est un paradigme (un modèle) visant à
généraliser les approches existantes pour produire une
approche unique applicable à tous les problèmes.
MapReduce existait déjà depuis longtemps mais la
présentation du paradigme sous une forme rigoureuse,
généralisable à tous les problèmes et orientée calcul
distribué a été popularisé par google en 2004.
21Le modèle MapReduce
Une transparence pour le programmeur :
une parallélisation automatique sur l’ensemble
d’unités de calcul en terme de :
distribution des traitements
distribution des données
équilibrage de charge
stockage et transfert de données
tolérance aux pannes
éviter les goulots d’étranglement
22MapReduce: les différentes étapes
On distingue donc 4 étapes distinctes dans un traitement
MapReduce:
Découper (split) les données d'entrée en plusieurs fragments.
Mapper chacun de ces fragments pour obtenir des couples
(clef ; valeur).
Grouper (shuffle) ces couples (clef ; valeur) par clef.
Réduire (reduce) les groupes indexés par clef en une forme
finale, avec une valeur pour chacune des clefs distinctes.
En modélisant le problème à résoudre de la sorte, on le rend
parallélisable
23Flux de données MapReduce
24Au dela du MapReduce
Pour le Big Data analytics : de nouvelles alternatives
et des nouveaux outils de la fondation apache
développés autour d’Hadoop (Spark, Flume, Pig,
Mahoot, Zeppelin.)
25L’émergence du métier de Data Scientist
Un métier avec une démarche empirique qui se
base sur des données pour apporter une
réponse à des problèmes
Imaginons un problème ou une question
Collecter les données
Préparer les données
Concevoir un modèle de Data Mining adapté
Optimiser le modèle
Visualiser et comprendre les résultats
Déploiement, industrialisation
26Data Scientist
Data scientist: A person who is better at statistics than
any software engineer and better at software
engineering than any statistician
27Data Scientist
Faire parler les données
Donner du sens aux données
brutes, trouver leur logique sous-
jacente et en déduire des faits
importants sur l’environnement de
l’entreprise
Partager ces découvertes avec les
responsables métier pour leur
permettre de prendre des décisions
pertinentes.
28Data Scientist
“Data scientist : The sexiest Job of the 21th
Century”
T.H. Davenport, DJ. Patil, Harvard Business Review, oct. 2012.
Le rôle du data scientist gagne en importance
dans les entreprises
Dans les 10 prochaines années, le profil data
scientist sera très recherché
29Vous pouvez aussi lire

















































