Google Tag Manager, la nouvelle arme anti adblock
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Google Tag Manager, la nouvelle arme
anti adblock
La version "Server-Side Tagging" de l'outil de Google permet
de contourner les protections navigateurs et autres
adblockers
Publié par Pixel de Tracking le 15 nov. 2020
EDIT 25 mai 2021 : le "Server-Side Tagging" de Google Tag Manager évolue,
et contourner les adblockers devient de plus en plus simple. J'ai ajouté la
section "Un temps d'avance sur les adblockers" à l'article.
Google Tag Manager, le cheval de Troie des
équipes marketing
Google Tag Manager
(https://marketingplatform.google.com/intl/fr/about/tag-manager/) est
un TMS (https://fr.wikipedia.org/wiki/Système_de_gestion_de_balises)
(Tag Management System) : il permet aux équipes marketing d'ajouter des
traceurs sur un site web ou une application, sans devoir passer par des
développeurs. Via une interface web, ces équipes peuvent décider :
Des traceurs à déclencher (analytics, A/B testing, attribution, etc).
Des conditions de déclenchement (catégories de pages,
caractéristiques utilisateur, etc).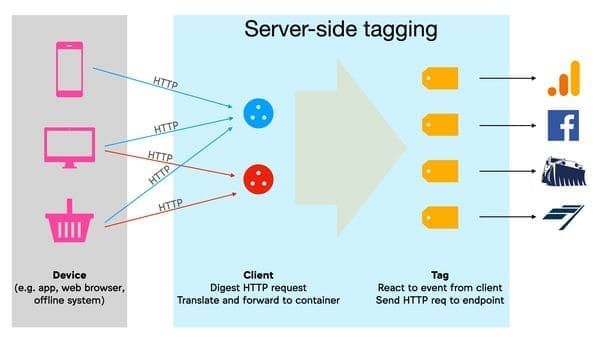
Des données à transmettre à ces outils tiers (caractéristiques
utilisateur, données de navigation, variables présentes sur la page, etc).
Ce n'est pas le seul (on peut par exemple citer Segment
(https://segment.com), le français TagCommander
(https://www.commandersact.com/fr/solutions/tagcommander/) ou
Matomo Tag Manager (https://fr.matomo.org/docs/tag-manager/)) mais
Google Tag Manager est ultra dominant :
Google Tag Manager est présent sur 31,9% du top 10 millions des sites web
Alexa, d'après W3Techs (https://frama.link/6sE8rTVq), mais surtout Google
Tag Manager a une part de marché de 99,4% sur les TMS (!)
Comment Google a-t-il pu de nouveau s'imposer ? Tout comme avec Google
Analytics, la version standard de Google Tag Manager est gratuite (les
solutions du marché sont en général payantes), elle est très bien intégrée
aux autres solutions Google et elle est bien faite.
Des traceurs qui ne sont plus appelés depuis
votre navigateur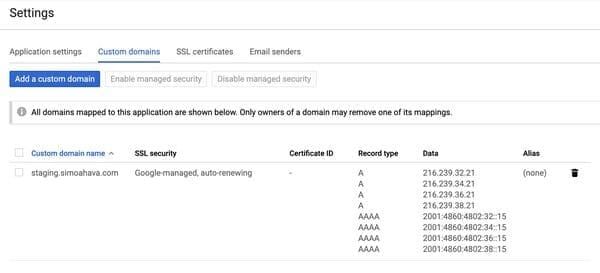
En août dernier, Google annonce une nouvelle version de Google Tag Manager (https://blog.google/products/marketingplatform/360/improve- performance-and-security-server-side-tagging/), appelée Server-Side Tagging. Voici un schéma de Google (https://developers.google.com/tag- manager/serverside/intro) pour expliquer comment fonctionne Google Tag Manager en version Client-Side Tagging (la version "historique") : Google Tag Manager va permettre le déclenchement des différents traceurs tiers (sur le schéma : Google Analytics, Google Ads, et un outil d'analytics), directement sur votre navigateur. Dans la nouvelle version Server-Side (https://developers.google.com/tag- manager/serverside/intro), les traceurs tiers ne sont plus exécutés depuis votre navigateur mais depuis un serveur "Proxy (https://fr.wikipedia.org/wiki/Proxy)" appelé "Server container" sur le schéma ci-dessous (et hébergé chez Google) :
La librairie javascript (appelée sur le schéma "Tag Manager web container") s'exécute toujours sur votre navigateur afin de récolter vos interactions et vos données personnelles, mais l'exécution des différents traceurs tiers a lieu côté serveur. Notez que cette nouvelle version s'applique aussi aux applications et à la collecte des données "offline" (pour transmettre les achats en magasin par exemple) :
Schéma du blog de Simo Ahava (https://frama.link/CgwLQt6F) : côté serveur, les "Clients" sont là pour traduire les requêtes HTTP reçues en "events", les "Tags" réagissent à ces évènements pour envoyer des "hits" aux sociétés de marketing tierces. Cette logique de déclenchement des traceurs tiers côté serveur change la donne. Simo Ahava a détaillé les différents impacts dans un excellent article (https://www.simoahava.com/analytics/server-side-tagging-google-tag- manager/), je vais pour ma part résumer les avantages et m'attarder sur les problèmes pour votre vie privée (opérer côté serveur peut permettre de contourner vos choix et de fuiter vos données personnelles, sans être démasqué). Une meilleure expérience utilisateur Sur la plupart des sites web, le nombre de librairies javascript chargées par des tiers (pour de l'analytics, de la publicité, de l'A/B testing, etc) est impressionnant. Le chargement et l'exécution de ces librairies est souvent la cause principale d'une mauvaise expérience utilisateur : lenteur du site et manque d'interactivité. Conséquences pour les sites web proposant une mauvaise expérience utilisateur : des internautes moins satisfaits, qui abandonneront directement la navigation ou ne reviendront pas. Voici un exemple avec Le Bon Coin, celui-ci appelle un nombre incalculable de librairies javascript (https://www.pixeldetracking.com/fr/le-bon-coin- donnees-personnelles-rgpd) :
Une petite partie des scripts javascript appelés sur la page accueil de Le Bon Coin, celui-ci fuite vos données personnelles à de nombreux tiers (https://frama.link/RSFS9ZYh). Dans le meilleur des scénarios, le site web n'installera qu'une seule librairie javascript (les événements pouvant être très différents entre des outils n'ayant pas les mêmes buts, le site web utilisera parfois plus qu'une seule librairie). Celle-ci pourra être celle de Google Tag Manager mais pas obligatoirement : il est possible de créer sa propre librairie ou d'utiliser d'autres librairies du marché telles que Snowplow (https://docs.snowplowanalytics.com/docs/collecting-data/collecting- from-own-applications/javascript-tracker/web-quick-start-guide/), Matomo (https://developer.matomo.org/guides/tracking-javascript-guide), AT Internet, etc.
Charge ensuite à cette librairie d'envoyer les "hits" avec les paramètres
requis lors des interactions clés. Puis le "client" du containeur serveur devra
traduire ces "hits" en évènements, ceux-ci seront lus par les "Tags" qui
enverront des "hits" aux sociétés marketing tierces. À noter que si la
librairie javascript installée sur le site est fournie par Google, le "client" est
déjà pré-configuré dans Google Tag Manager. Si le site web utilise une autre
librairie, il lui faudra créer son propre "client" dans Google Tag Manager
(exemple avec AT Internet (https://levelup.gitconnected.com/google-tag-
manager-server-side-how-to-manage-custom-vendor-tags-
21bef51bc89e)), en attendant d'avoir des "clients" pré-configurés pour les
principales librairies de tracking javascript.
Avantage donc : une seule librairie de tracking javascript est installée sur le
site web et un seul "flux" de données en provenance du navigateur,
l'utilisateur devrait voir la différence.
Un meilleur contrôle sur les données
transmises aux tiers
Avoir un "proxy" côté serveur permet de contrôler les données transmises
aux tiers (ce qui est beaucoup plus difficile lorsque les traceurs sont
directement exécutés par le navigateur de l'utilisateur) :
Par défaut et à la différence de la version "client-side", l'adresse IP et le
User-Agent (https://fr.wikipedia.org/wiki/User_agent) (nom du
navigateur, version, système d'exploitation, langue, etc) de l'utilisateur
ne fuitent pas (ce qui évite l'identification de l'utilisateur via
"fingerprinting (https://www.cnil.fr/fr/definition/fingerprinting)").
L'éditeur utilisant la version Server-Side Tagging de Google Tag
Manager peut décider de transmettre ces informations aux tiers, mais
ce n'est pas automatique.Il arrive souvent que des informations personnelles fuitent vers des
tiers via des paramètres d'URLs (lisez par exemple l'article "Google Tag
Manager Server-Side — How To Manage Custom Vendor Tags
(https://medium.com/@thezedwards/the-2020-url-querystring-data-
leaks-millions-of-user-emails-leaking-from-popular-websites-to-
39a09d2303d2)"), le Server-Side Tagging permet d'éviter cela.
De manière générale, l'éditeur a la main sur les données personnelles et
cookies envoyés par son "proxy" aux tiers (lisez la documentation
technique de Google (https://developers.google.com/tag-
manager/serverside/permissions), notez par exemple les méthodes
get_cookies et set_cookies). Il peut donc "nettoyer" les informations et
n'envoyer aux tiers que le strict nécessaire.
Exemple avec un hit AT Internet "vu" par le "proxy" serveur, le site web peut
décider de ne pas transmettre l'adresse IP et le User-Agent de l'utilisateur à AT
Internet.
Un site web mieux sécuriséMettre en place une Content-Security Policy
(https://developer.mozilla.org/fr/docs/Web/HTTP/CSP) (CSP) permet à
un éditeur de mieux se prémunir contre différents types de menaces dont
les attaques XSS (https://developer.mozilla.org/fr/docs/Glossaire/Cross-
site_scripting) (Cross-Site Scripting) et les injections de contenus. En
ajoutant un en-tête aux réponses du serveur web, le site peut indiquer aux
navigateurs quelles ressources (scripts, css, etc) sont autorisées.
Voici un exemple de CSP documenté par Google
(https://developers.google.com/web/fundamentals/security/csp) :
Content-Security-Policy: script-src 'self' https://apis.google.com.
Ce qui signifie : le navigateur n'a le droit d'exécuter que les scripts qui
viennent directement du site consulté ('self') ou de apis.google.com. Et voici
comment votre navigateur réagira si un script malicieux tente alors de
s'exécuter à partir du site consulté :
Le script evil.js n'est pas hébergé sur le site consulté, ni sur apis.google.com :
son exécution est bloquée par le navigateur.
En réduisant fortement les domaines tiers autorisés à exécuter du code
javascript, la CSP devient plus robuste.Si le Server-Side Tagging a des avantages pour les utilisateurs consentants à la surveillance marketing (rapidité, sécurité), il met en péril les protections des utilisateurs non consentants. Un contournement des protections navigateurs Le serveur "proxy" est hébergé dans le cloud de Google (instance App Engine (https://cloud.google.com/appengine?hl=fr)) mais Google conseille (https://developers.google.com/tag-manager/serverside/custom-domain) de lier le domaine App Engine à un sous-domaine du site de ses clients (sans expliquer les raisons) : The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead. La liaison entre le domaine App Engine et le sous-domaine du client, documentée par Google (https://frama.link/DKtyuDee).
Google ne conseille pas d'enregistrement DNS de type CNAME (alias), mais
un enregistrement DNS de type A ou AAAA
(https://fr.wikipedia.org/wiki/Liste_des_enregistrements_DNS),
directement lié aux adresses IPs de Google App Engine, qui fait office
d'hébergeur. Le serveur "proxy" est donc bien considéré par les navigateurs
comme 1st party, et les conséquences sont donc importantes.
En particulier, les cookies déposés par le serveur "proxy" ne sont pas des
cookies tiers, ni des cookies créés via du javascript, ni des cookies déposés
par un domaine CNAME. Ils sont donc autorisés, sans restriction :
Safari via Intelligent Tracking Prevention
(https://webkit.org/blog/9521/intelligent-tracking-prevention-2-3/)
(ITP) restreint la durée de vie des cookies créés en javascript à 7 jours
(exemple : les cookies 1st-party créés par Google Analytics). Grâce au
serveur "proxy", les traceurs tiers passent maintenant outre cette
limitation.
Toujours Safari via ITP restreint maintenant les cookies déposés via un
domaine CNAME à 7 jours (https://webkit.org/blog/11338/cname-
cloaking-and-bounce-tracking-defense/). Grâce au serveur "proxy", les
traceurs tiers ne sont pas concernés par cette limitation.
Brave de son côté bloque les requêtes CNAME vers des traceurs connus
(https://brave.com/privacy-updates-6/). Toujours grâce au serveur
"proxy", les traceurs tiers évitent ce blocage.
Un contournement des adblockers
Votre adblocker (uBlock Origin sur Firefox
(https://addons.mozilla.org/fr/firefox/addon/ublock-origin/) par
exemple), votre bloqueur de contenu (Firefox Focus
(https://apps.apple.com/fr/app/firefox-focus/id1055677337) ou Adguard
(https://apps.apple.com/us/app/adguard-adblock-privacy/id1047223162)
sur iOS par exemple) ou votre bloqueur DNS (NextDNS(https://www.pixeldetracking.com/fr/nextdns-mon-nouveau-bloqueur- de-publicites-prefere) par exemple) fonctionne sur votre appareil. Il peut ainsi détecter les traceurs tiers et les bloquer avant que vos données personnelles ne fuitent. Rien de tout cela avec la version Server-Side Tagging de Google Tag Manager : les fuites de données personnelles se déroulent depuis le serveur proxy du client (hébergé dans le cloud Google) vers les tiers. Vous n'avez donc plus la main pour éviter ces fuites. Vous pourriez vous dire : il suffit de bloquer le premier appel, celui de votre navigateur vers la librairie javascript en charge de récolter les données et de communiquer vers le serveur "proxy". Sauf que cette librairie javascript peut très bien être accessible sur le domaine du site web (et non sur un domaine Google par exemple). Aussi, Google conseille déjà (https://developers.google.com/tag-manager/serverside/send- data#update_the_gtagjs_source_domain) à ses clients de changer leurs scripts gtag.js afin de renseigner le domaine du serveur proxy. Cette manipulation rend déjà le blocage via nom de domaine inopérant. Toutes les librairies de tracking Google (gtag.js, analytics.js mais aussi gtm.js, la librairie "avancée" de Google, en charge de Google Tag Manager) peuvent être hébergées sur son propre domaine.
Via le blog de Simo Amaha (https://www.simoahava.com/analytics/google- tag-manager-web-container-client-server-side-tagging/).
Si gtag.js ou gtm.js sont des librairies javascript dont les noms sont connus des principaux adblockers, ceux-ci devront trouver d'autres méthodes lorsque le nom de la librairie javascript aura été modifié ou que des sites auront créés leurs propres librairies. uBlock Origin, efficace contre le CNAME cloaking sur Firefox (https://frama.link/VR9XsofE), impuissant contre le Server-Side Tagging ? Un temps d'avance sur les adblockers La librairie javascript de Google Tag Manager s'appelle gtm.js, elle est appelée avec l'identifiant du containeur : GTM-.... Un adblocker peut donc facilement cibler ces noms et bloquer le chargement de cette librairie. Un site web pourrait décider de créer sa propre librairie javascript, mais ce n'est pas si facile.
Mais toujours grâce à Simo Ahava
(https://www.simoahava.com/analytics/custom-gtm-loader-server-side-
tagging/), il est maintenant facile de choisir un autre nom pour la librairie
javascript gtm.js et de cacher l'identifiant du containeur (plus besoin de
créer sa propre librairie javascript) :
Via le blog de Simo Ahava (https://www.simoahava.com/analytics/custom-
gtm-loader-server-side-tagging/) : avec la template "GTM Loader" de Simo, le
site web peut renommer la librairie javascript ("Request Path") et cacher
l'identifiant du containeur ("Override Container ID" coché, "Container ID"
vide).
Également, s'il était possible côté adblockers de cibler le proxy Google
(https://github.com/gorhill/uBlock/wiki/Static-filter-syntax#header), un
site web peut maintenant héberger le container serveur ailleurs (sur
Amazon AWS, Microsoft Azure, OVH... ou sur sa propre infrastructure). Cen'est pas si facile, mais Google fournit l'image Docker ainsi que les étapes à
suivre (https://developers.google.com/tag-manager/serverside/manual-
setup-guide).
Simo Ahava indique ainsi la marche à suivre pour déployer le containeur
serveur sur Amazon AWS (https://www.simoahava.com/analytics/deploy-
server-side-google-tag-manager-aws/) tandis que Mark Edmondson
détaille comment déployer le containeur serveur sur Google Cloud Run
(https://code.markedmondson.me/gtm-serverside-cloudrun/) (autre
service de Google Cloud Platform, différent de Google App Engine).
Comment les adblockers peuvent-ils réagir ?
Le sujet n'est pas évident, voici des idées mais je ne suis pas certain qu'elles
soient réalisables :
Automatiquement détecter ces appels "1st party" au serveur "proxy" via
les paramètres d'URLs envoyés. Sauf que ces paramètres d'URLs
changeront d'un site à l'autre, en fonction de la librairie utilisée, de la
page consultée, etc.
Détecter la librairie javascript responsable des appels au serveur "proxy"
pour bloquer son exécution. Comme nous avons pu le voir, cette
méthode ne fonctionnera pas si le site web renomme la librairie de
Google Tag Manager (https://www.simoahava.com/analytics/custom-
gtm-loader-server-side-tagging/) ou développe sa propre librairie
javascript.
Bloquer les proxy (https://developer.mozilla.org/en-
US/docs/Web/HTTP/Headers/Via), au risque de bloquer des
fonctionnalités essentielles de sites web ? Aussi, cette méthode ne
fonctionne pas si le site web décide d'héberger le containeur serveur
sur sa propre infrastructure (https://developers.google.com/tag-
manager/serverside/manual-setup-guide).Ne jamais exécuter de javascript sur son navigateur, avec par exemple
l'extension NoScript
(https://addons.mozilla.org/fr/firefox/addon/noscript/), paramétrée
de manière radicale. Option efficace, sauf que de nombreux sites web
ne fonctionneront plus.
Fuiter vos données personnelles dans
l'opacité la plus totale
Si beaucoup de sites web fuitent aujourd'hui vos données personnelles,
souvent sans votre consentement, il est néanmoins possible d'auditer les
sites, de prouver la violation de consentement et de documenter les fuites.
La CNIL pourrait par exemple faire son travail et sanctionner les fautes. Rien
de tout cela avec le Server-Side Tagging, un site peut maintenant très
facilement :
Donner une apparence de consentement en vous laissant répondre à un
bandeau de consentement.
Tout en fuitant vos données personnelles à de multiples tiers, sans qu'un
auditeur extérieur ne puisse s'en rendre compte (il verra simplement
l'appel "1st-party" au serveur "proxy", sans savoir si les données
personnelles sont utilisées, partagées ou revendues derrière).
Vos données sur le cloud de Google
Par défaut, le serveur "proxy" logue toutes les requêtes qu'il reçoit
(https://developers.google.com/tag-manager/serverside/script-user-
guide) :
By default, App Engine logs information about every single request (e.g. request path,
query parameters, etc) that it receives.Mais les données personnelles contenues dans ces requêtes ne sont pas les
seules informations qui fuitent vers Google. Tout comme pour le CNAME
cloaking (https://www.laquadrature.net/2020/10/05/le-deguisement-
des-trackers-par-cname/), les cookies associés au domaine du site consulté
sont envoyés au sous-domaine du serveur "proxy". Ainsi, si vos cookies de
session sont associés au domaine du site (et non à un sous-domaine
distinct), ils seront bien envoyés au cloud de Google.
Celui-ci déclare (https://cloud.google.com/security/privacy) que les
données hébergées sur son cloud appartiennent au client, et non à Google. Il
vous faut néanmoins faire confiance à Google.
Le Server-Side Tagging, probablement bientôt
largement adopté
Si des solutions Server-Side existaient sur le marché depuis bien longtemps,
et s'il était déjà possible de développer son propre "proxy", le lancement de
la solution de Google aura probablement un impact énorme sur l'adoption
du Server-Side Tagging :
Google Tag Manager est présent sur un nombre considérable de sites
web, il est ultra-dominant.
Google présente cette version comme une évolution
(https://blog.google/products/marketingplatform/360/improve-
performance-and-security-server-side-tagging/) des outils TMS,
améliorant la performance et la sécurité des sites web.
Gros argument pour les marketeurs, fuiter vos données personnelles
vers Facebook
(https://www.facebook.com/business/m/HSBSeries/signals).Un tag Google Analytics peut cacher la fuite de vos données personnelles vers Facebook (https://www.simoahava.com/analytics/facebook-conversions-api- gtm-server-side-tagging/), combo ! Même si un client Google Tag Manager peut continuer d'utiliser la version Client-Side, même si la version Server-Side a encore des limites (peu de librairies tierces, certaines solutions auront du mal à être supportés, etc), même si l'apprentissage de la solution est complexe et même si c'est souvent payant (facture Google App Engine du serveur "proxy"), on peut donc parier que les clients Google Tag Manager vont progressivement migrer vers cette version. Contourner les adblockers et autres protections navigateurs, un argument de vente Comme nous l'avons vu, Google n'explique pas (https://developers.google.com/tag-manager/serverside/custom-domain) le pourquoi de la création d'un sous-domaine du site web pour son serveur "proxy" :
The default server-side tagging deployment is hosted on an App Engine domain. We
recommend that you modify the deployment to use a subdomain of your website
instead.
Il n'en a pas besoin, les contournements des protections navigateurs et
adblockers ont déjà été listés comme "bénéfices" par de nombreuses
publications :
"Server-side Tagging In Google Tag Manager
(https://www.simoahava.com/privacy/intelligent-tracking-
prevention-ios-14-ipados-14-safari-14/) " de Simo Ahava, l'article
indique comme bénéfice de pouvoir contourner les limitations de Safari
concernant la durée de vie des cookies javascript. Tout à son honneur,
l'auteur ne veut pas donner de détail sur le fait que le Server-Side
Tagging permet de contourner les adblockers et indique que la collecte
de données doit se faire après recueil du consentement.
"GTM Server Side – L’évolution naturelle pour votre tagging ?
(https://converteo.com/blog/gtm-server-side-levolution-naturelle-
pour-votre-tagging/)" de Converteo. L'article liste en avantages le fait
de pouvoir contourner les limitations navigateurs telles que celles de
Safari et Firefox, ainsi que le contournement des adblockers.
"Introduction to Google Tag Manager Server-side Tagging
(https://www.analyticsmania.com/post/introduction-to-google-tag-
manager-server-side-tagging/)", du blog Analytics mania. Là aussi, les
contournements des limitations navigateurs et adblockers sont listés en
bénéfice.
"Google introduit le tagging côté serveur, une bonne nouvelle ?
(https://www.journaldunet.com/ebusiness/publicite/1494723-google-
introduit-le-tagging-cote-serveur-une-bonne-nouvelle/)" de Nicolas
Jaimes sur le JDN. L'angle de l'article est la publicité, et donc le
contournement des protections navigateurs est listé en bénéfice (mêmesi pour l'instant, le manque de librairies tierces fait que le Server-Side
Tagging reste complexe à implémenter).
Malheureusement, il y a fort à parier que beaucoup de sites seront
également séduits par ces "bénéfices", en plus des gains de performance, de
sécurité et de contrôle. L'impossibilité d'auditer les sites web sera
également une grosse perte pour les défenseurs de la vie privée. En espérant
que les navigateurs et adblockers trouvent des parades afin que les
internautes soucieux de leur vie privée puissent continuer de se défendre.
(https://twitter.com/pixeldetracking)
Copyright © Pixel de Tracking 2020Vous pouvez aussi lire

















































