STATISTIQUE BAYÉSIENNE : UTILISATION D'OPENBUGS (+WINBUGS, JAGS + UTILISATION AVEC R) - LPSM
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Statistique bayésienne : utilisation d’OpenBUGS
(+WinBUGS, JAGS + utilisation avec R)
1/59 1/
Étapes 1 Rappels : principe de la statistique bayésienne 2 Principe de l’outil OpenBUGS 3 Contenu de l’outil OpenBUGS 4 Utilisation d’OpenBUGS avec R 5 Exemple de l’ANOVA à deux facteurs 6 Autres outils et compléments 7 Un cas "jouet" : gaussien conjugué 8 Un cas réel en fiabilité industrielle : DCC 2/59 2/
Rappels : principe de la statistique bayésienne Rappels : principe de la statistique bayésienne 3/59 3/

Rappels : principe de la statistique bayésienne
Aspects descriptifs - le cadre statistique paramétrique
On s’intéresse au comportement d’une variable aléatoire X évoluant dans un espace mesuré et
probabilisé (Ω, A, µ, P) où
1 Ω est l’espace d’échantillonnage des X = x , càd l’ensemble de toutes les valeurs possibles
prises par X
on travaillera avec Ω = IR n et des échantillons observés xn = (x1 , . . . , xn )
2 la tribu (ou σ−algèbre) A = collection des événements (sous-ensembles de Ω) mesurables
par µ
on travaillera avec A = B(IR n ) = σ ⊗ni=1 ]ai , bi ]; ai < bi ∈ IR
3 µ est une mesure positive dominante sur (Ω, A) (Lebesgue ou Dirac dans ce cours)
4 P est une famille de distributions de probabilité dominée par µ, que suit X ,
supposé paramétrique : P = {Pθ ; θ ∈ Θ ⊂ IR p }
de mesure de densité f (.|θ), ie.
dPθ
= f (X |θ)
dµ
4/59 4/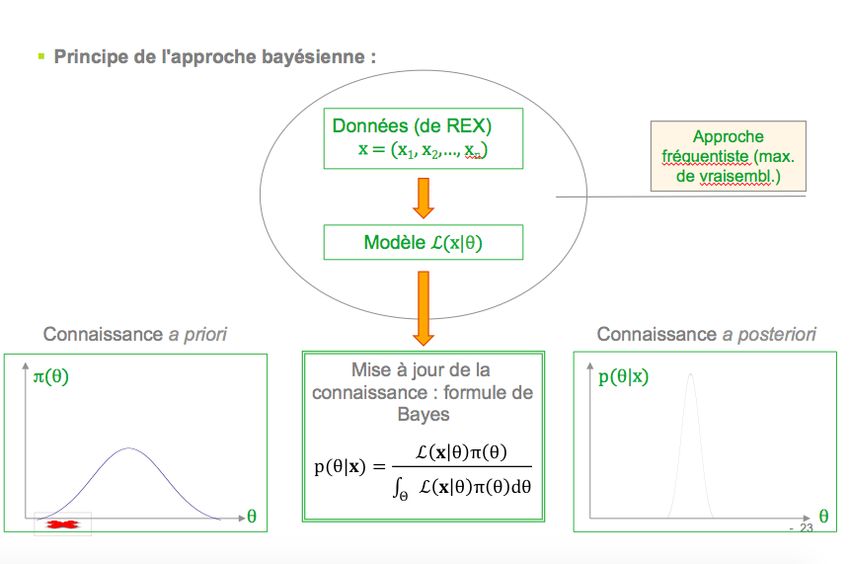
Rappels : principe de la statistique bayésienne
Aspects descriptifs - simplifions-nous la vie
Dans la suite, on parlera indifféremment de la variable aléatoire
X ∼ f (x |θ)
ou de son observation x ∼ f (x |θ), et on parlera plus généralement de loi en confondant Pθ et
f (.|θ)
On n’utilisera plus la notation µ qui sera induite :
Z
Pθ (X < t) = f (x )1{x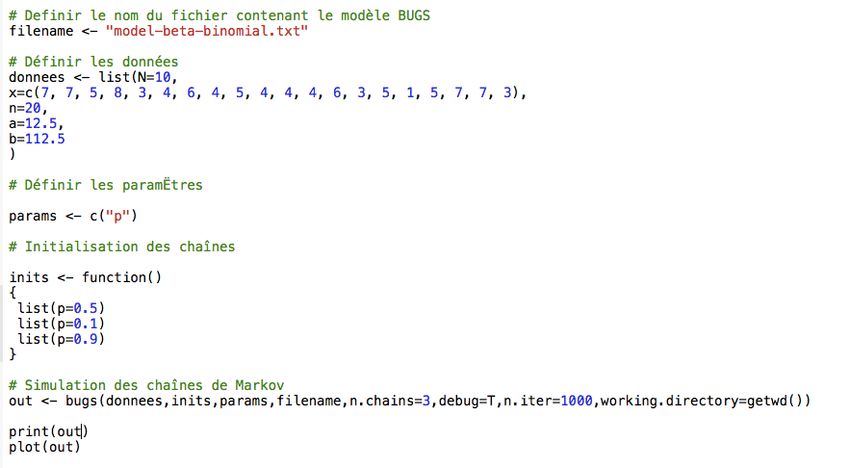
Rappels : principe de la statistique bayésienne
Aspects inférentiels - l’inversion
L’inférence statistique est une inversion car elle cherche à déterminer
1 les causes
réduites au paramètre θ du mécanisme probabiliste générateur
à partir
2 des effets
résumés par les observations xn = (x1 , . . . , xn )
alors que la modélisation caractérise le comportement des observations futures
conditionnellement à θ
L’écriture usuelle (fiduciaire) de la vraisemblance témoigne de cette inversion ; on l’écrit plutôt
`(θ|xn ) = f (xn |θ)
6/59 6/
Rappels : principe de la statistique bayésienne
Aspects inférentiels - le théorème de Bayes
Une description générale de l’inversion des probabilités est donnée par le théorème de Bayes
Si C (cause) et E (effet) sont des évènements tels que P(E ) 6= 0, alors
P(E |C )P(C )
P(C |E ) =
P(E |C )P(C ) + P(E |C c )P(C c )
P(E |C )P(C )
=
P(E )
Il s’agit d’un principe d’actualisation, décrivant la mise à jour de la vraisemblance de la cause C
de P(C ) vers P(C |E )
Une version en densité de ce théorème a été proposée par Bayes (1763)
soit X et Y deux v.a. de lois conditionnelle f (x |y ) et marginale g(y )
la loi conditionnelle de Y sachant X = x est
g(y |x ) = R f (x |y )g(y )
f (x |y )g(y ) dy
7/59 7/Rappels : principe de la statistique bayésienne
Aspects inférentiels - modélisation bayésienne
Bayes (1763) puis Laplace (1795) ont supposé que l’incertitude sur θ pouvait être décrite par
une distribution de probabilité de densité π(θ) sur Θ, appelée loi a priori
Sachant des données xn , la mise à jour de cette loi a priori s’opère par le conditionnement de θ à
xn ; on obtient la loi a posteriori
π(θ|xn ) = R f (xn |θ)π(θ)
f (xn |θ)π(θ) dθ
Θ
Un modèle statistique bayésien
est constitué d’un modèle statistique paramétrique f (x |θ) et
d’une distribution a priori π(θ) pour les paramètres
8/59 8/Rappels : principe de la statistique bayésienne En résumé ... 9/59 9/
Rappels : principe de la statistique bayésienne Un exemple pour comprendre : modèle bêta-binomial 10/59 10
Rappels : principe de la statistique bayésienne Graphe acyclique orienté 11/59 11
Rappels : principe de la statistique bayésienne Modélisation bayésienne : élicitation a priori 12/59 12
Rappels : principe de la statistique bayésienne Calcul a posteriori par conjugaison Avec alors 13/59 13
Principe de l’outil OpenBUGS
Principe de l’outil OpenBUGS
WinBUGS et son successeur OpenBUGS font partie du projet BUGS (Bayesian inference Using
Gibbs Sampler) qui vise à rendre simple la pratique des méthodes MCMC aux statisticiens. Il a
été développé par l’université de Cambridge. Seul OpenBUGS est actuellement maintenu
WinBUGS et OpenBUGS peuvent être utilisé de différentes manières :
Via une interface « clique-bouton » qui permet de contrôler l’analyse,
En utilisant des modèles définis par des interfaces graphiques, appelés DoddleBUGS,
Via d ?autres logiciels tels que R (en particulier via le package R2WinBUGS).
WinBUGS et OpenBUGS sont des logiciels libres et gratuits, Cependant, afin d’accéder à la
version non restreinte de WinBUGS, il est nécessaire d’obtenir la clé d’utilisation.
Le site internet pour WinBUGS et OpenBUGS, The BUGS Project présente les deux logiciels et
fournit de la documentation.
Site spécialisé pour OpenBUGS : http ://www.openbugs.net/
14/59 14Principe de l’outil OpenBUGS
Comment ça marche ?
1 Ouverture de la fenêtre OpenBUGS
2 Création d’un fichier "modele.txt" contenant l’écriture formelle de la
vraisemblance et de la distribution a priori
nécessité d’utiliser une boucle sur les données pour la vraisemblance
langage BUGS différent de R (mais plutôt compréhensible)
3 Création d’un fichier "data.txt" avec des données entrées en vectoriel
(possibilité de tableaux)
les "données" regroupent aussi les constantes du problème : taille des
données n, etc.
4 Éventuellement création d’un fichier d’initialisation pour les paramètres
(chaînes MCMC)
15/59 15Principe de l’outil OpenBUGS Exemple du modèle bêta-binomial (1/5) Fichier model-beta-binomial.txt (à ouvrir comme "Text") 1 - Vérification du modèle via "Model/Model Specification" puis "Check Model" ⇒ model is syntactically correct 16/59 16
Principe de l’outil OpenBUGS
Exemple du modèle bêta-binomial (2/5)
2 - Enregistrement des données via :
1 sélection du fichier data-beta-binomial.txt
2 "Load data"
⇒ data loaded
17/59 17Principe de l’outil OpenBUGS
Exemple du modèle bêta-binomial (3/5)
3 - Sélection du nombre de chaînes MCMC puis compilation du modèle via "compile"
⇒ model compiled
4 - Initialisation des chaînes MCMC : 2 façons possibles
1 Sélection dans le fichier init-beta-binomial.txt puis "load inits", chaîne par chaîne
2 Génération automatique via "gen inits" pour toutes les chaînes
⇒ model initialized
18/59 18Principe de l’outil OpenBUGS
Exemple du modèle bêta-binomial (4/5)
5 - Ouverture de la fenêtre de monitoring des chaînes via "Inference/Sample Monitor Tool"
Écrire "p" dans la fenêtre "node", valider avec "set"
6 - Ouverture de la fenêtre de lancement des chaînes via "Model/Update"
cliquer sur "update" pour lancer une première fois les chaînes
⇒ model is updating
7 - Monitorer les chaînes via la fenêtre consacrée :
Aller chercher "p" dans la fenêtre "node", puis cliquer sur :
"trace" pour tracer l’évolution des chaînes associées à p
"trace" pour tracer la densité a posteriori courante (approximative)
"coda" pour récupérer les chaînes
"stats" pour obtenir un résumé statistique de la loi a posteriori courante
etc.
19/59 19Principe de l’outil OpenBUGS
Exemple du modèle bêta-binomial (5/5)
Manipulez !
Injectez des erreurs et retester l’ensemble pour comprendre les messages d’erreur
faites une erreur de nom dans la définition du modèle
"oubliez" une des données
etc.
20/59 20Principe de l’outil OpenBUGS
Exemple du modèle bêta-binomial (6/5)
Augmentation de dimension : on suppose que a est aléatoire et décrit a priori par
a ∼ G(1, 0.5)
et on pose b = 9 · a
Modifier le code pour cela
Décrire les résultats a posteriori bivariés sur p et a
21/59 21Contenu de l’outil OpenBUGS
Quelques détails supplémentaires dans Sample Monitor Tool
Commande "jump" : trace la Mean Square Euclidian Jumping Distance pour chaque chaîne
MCMC
n−1
1 X
S2 = łx (i+1) − x (i) k22
n−1
i=1
permettant de donner une vision plus lisible du parcours des chaînes (atteinte stationnarité)
Commande "bgr" : trace la statistique de Brooks-Gelman-Rubin pour la dimension sélectionnée ;
la stationnarité est postulée lorsque celle-ci adhère à la valeur 1
Commande "accept" : trace le taux moyen d’acceptation dans les chaînes MCMC pour la
dimension sélectionnée
Commande "auto cor" : trace l’autocorrélation estimée pour la dimension sélectionnée
22/59 22Contenu de l’outil OpenBUGS
Quelques détails supplémentaires dans le menu Inference
Sous-menu "Correlation"
"Correlation Tool"
scatter ⇒ trace un "scatterplot" entre 2 dimensions
matrix ⇒ dessine la matrice de corrélation (par niveaux de gris)
print ⇒ calcule le coefficient de corrélation linéaire
Sous-menu "Compare"
"Comparison Tool"
boxplot ⇒ trace une "boîte à moustaches" d’une dimension sélectionnée
23/59 23Contenu de l’outil OpenBUGS
Quelques détails supplémentaires
Menu Model
Commande "latex" : fournit le code latex du fichier sélectionné (utile pour le fichier de
modèle !)
24/59 24Contenu de l’outil OpenBUGS
Un rappel : le critère de déviance (Spiegelhalter et al.) pour la comparaison de modèle
Défini par
D = −2 log L(X |θ) ( +C une constante inutile pour la comparaison)
avec L la vraisemblance
Permet en outre de calculer les critères BIC et AIC lorsque ceux-ci sont pertinents (quand la loi
a posteriori est approximativement gaussienne)
25/59 25Contenu de l’outil OpenBUGS Où trouver une aide lisible et rapide ? Ici : http://www.openbugs.net/Manuals/Contents.html 26/59 26
Contenu de l’outil OpenBUGS Liste des distributions de probabilité (par défaut) 27/59 27
Contenu de l’outil OpenBUGS Noeuds logiques et indexation (1/2) Les noeuds logiques sont définis par une flèche et sont toujours indexés On peut utiliser une fonction de lien (log, logit, probit) On peut définir des tableaux Toute variable (noeud logique ou stochastique ~) ne peut apparaître qu’une fois dans la partie gauche d’une expression (sauf dans le cas d’une transformation de données) du type 28/59 28
Contenu de l’outil OpenBUGS Noeuds logiques et indexation (2/2) On peut créer des noeuds multiparités : soient µ et τ deux vecteurs de taille K On peut alors définir la boucle suivante : 29/59 29
Contenu de l’outil OpenBUGS Fonctions utiles Aller voir dans l’aide consacrée ici : http://www.openbugs.net/Manuals/ModelSpecification.html 30/59 30
Contenu de l’outil OpenBUGS Un piège à éviter 1. Toujours aller vérifier de quelle façon les distributions de probabilité sont définies ! Piégeant en particulier pour les lois normale et log-normale : 31/59 31
Contenu de l’outil OpenBUGS Comment gérer la censure ou la troncature ? La censure est possible en utilisant la notation suivante Il s’agit d’une censure par intervalle. On laisse un blanc à gauche (resp. à droite) si la donnée est censurante à droite (resp. à gauche) La troncation est possible en utilisant la notation suivante 32/59 32
Contenu de l’outil OpenBUGS
Les priors non informatifs
Les priors impropres (non intégrables) ne sont pas utilisables en BUGS. Il faut les approcher avec
des distributions propres mais de variance très large (dangereux hélas)
Une "règle du pouce" pour les paramètres de variance inverse :
τ ∼ dgamma(0.001, 0.001)
D’où la nécessité de toujours faire des études de sensibilité a posteriori
33/59 33Contenu de l’outil OpenBUGS Implémenter une nouvelle distribution ? Passer par des subterfuges : typiquement une transformation de variables latentes (ex : Box-Müller) 34/59 34
Utilisation d’OpenBUGS avec R Utilisation d’OpenBUGS avec R Pour se faciliter la vie, on peut appeler OpenBUGS depuis R et mener des calculs bayésiens "en aveugle" Utile aussi pour traiter les échantillons a posteriori (et notamment les décorréler) Plusieurs packages utiles : BRugs, R2WinBUGS et R2OpenBUGS R2OpenBUGS plus récent et plus utilisé (aller voir l’aide, très bien faite) 35/59 35
Utilisation d’OpenBUGS avec R Procédure avec R2OpenBUGS (1/3) 1. Installer le package R2OpenBUGS (nécessite CODA) 2. Le charger dans un programme R avec library(R2OpenBUGS) 3. Définir le répertoire où se trouve les fichiers BUGS comme répertoire de travail courant, par exemple : 36/59 36
Utilisation d’OpenBUGS avec R Procédure avec R2OpenBUGS (2/3) : spécification du modèle 37/59 37
Utilisation d’OpenBUGS avec R Procédure avec R2OpenBUGS (3/3) : obtention des résultats Avec debug=T, fermer la fenêtre OpenBUGS qui s’est ouverte pour achever le traitement numérique Le répertoire courant doit se présenter ainsi : 38/59 38
Exemple de l’ANOVA à deux facteurs Exemple de l’ANOVA à deux facteurs : rendements de maïs On dispose de mesure de rendement de 3 variétés de maïs, cultivées sur 6 parcelles (blocs), durant 10 années. Pour cet exemple on ne travaillera que sur la dernière année. 39/59 39
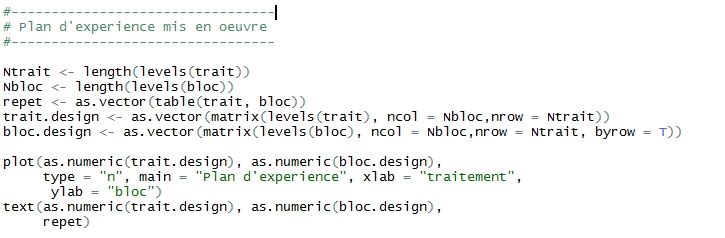
Exemple de l’ANOVA à deux facteurs Schéma du plan d’expérience 40/59 40
Exemple de l’ANOVA à deux facteurs Représentation des données en fonction de leur appartenance (bloc/variété) Pour avoir une idée de la variabilité... 41/59 41
Exemple de l’ANOVA à deux facteurs Analyse classique de la variance à 2 facteurs 42/59 42
Exemple de l’ANOVA à deux facteurs DAG du modèle d’ANOVA à 2 facteurs 43/59 43
Exemple de l’ANOVA à deux facteurs ANOVA bayésienne (1/3) 44/59 44
Exemple de l’ANOVA à deux facteurs ANOVA bayésienne (2/3) Exercice : construire le modèle BUGS permettant de réaliser cette inférence et donner un résumé des distributions a posteriori des paramètres 45/59 45
Exemple de l’ANOVA à deux facteurs ANOVA bayésienne (3/3) Un résumé des distributions a posteriori (pour comparer avec votre solution) calculé à partir d’une taille 10000 46/59 46
Autres outils et compléments JAGS Version "rapide" de BUGS développée par Martyn Plummer Repose sur le même language, à quelques différences subtiles près Pas d’interface graphique pour la gestion des chaînes (mais pouvant aussi être appelé par R) Moins de distributions de probabilité que sous OpenBUGS Démonstration en cours (si possible) 47/59 47
Autres outils et compléments JAGS : exemple de script 48/59 48
Autres outils et compléments Ce qu’on n’a pas fait dans ce cours... Le Doodle Editor : permet de définir un modèle de façon graphique, par DAG (Graphes Acycliques Orientés) Un lien utile : http://http://www.openbugs.net/Manuals/DoodleBUGS.html 49/59 49
Autres outils et compléments
Compléments utiles à OpenBUGS
GeoBUGS : modèles spatiaux
ReliaBUGS : modèles de fiabilité
50/59 50Autres outils et compléments
Les références indispensables..
Pensez à les citer lorsque vous utilisez OpenBUGS et R2OpenBUGS dans un rapport !
Spiegelhalter et al. (2014). OpenBUGS User Manual.
Sturz et al. (2005). R2OpenBUGS : A Package for Running OpenBUGS from R. Journal
of Statistical Software, 12(3), 1 ?16.
51/59 51Un cas réel en fiabilité industrielle : DCC
Un cas d’étude en fiabilité industrielle : Défaillances de
Cause Commune
Considérons un matériel composé de K = 4 composants
Chacun peut tomber en panne indépendamment des autres, mais plusieurs peuvent tomber en
panne simultanément à cause d’un évènement extérieur
On dispose d’un vecteur de données n = (n1 , . . . , nK ) où nk = nombre observé de défaillances
simultanées de k composants
n1 = 69
n2 = 6
n3 = 0
n4 = 1
52/59 52Un cas réel en fiabilité industrielle : DCC
Que veut-on faire ?
On veut estimer chaque probabilité pi qu’un groupe de i composants tombe en panne
simultanément
Ce vecteur de probabilités p est lié au vecteur d’observations n par une distribution multinomiale
n ∼ M(M; p).
P
avec M = i
ni
Par ailleurs, vous disposez de l’information a priori suivante :
valeurs ponctuelles “moyennes” p̃1 , . . . , p̃K resultant d’anciennes études,
non-accompagnées de mesures d’incertitude (comme des écart-types, par ex.)
p̃1 = 0.921
p̃2 = 0.0658
p̃3 = 0.011
p̃4 = 0.00274
un estimé λ̃ de la probabilité totale de défaillance λ du matériel (incluant toutes les
sources de défaillance interne)
53/59 λ̃ = 0.016 53Un cas réel en fiabilité industrielle : DCC
Choix de la distribution a priori (1)
Vous voulez construire un a priori sur p
Supposons que nous n’ayons pas du tout d’information. Un bon choix est la mesure de Jeffreys
p ∼ Dir (1/2, . . . , 1/2)
où Dir (α1 , . . . , αK ) est la distribution de Dirichlet définie par sa densité
PK K
Γ( αi ) Y α −1
π(p|α) = QK i=1 pi i 1{SK (p)}
i=1
Γ(αi ) i=1
P
dont le support est le simplexe Sk (p) = p = (p1 , . . . , pK ); i=1
pi = 1, pi > 0
La distribution de Dirichlet est la généralisation multivariée de la loi bêta
Quand αi = 1, la loi de Dirichlet est la loi uniforme sur Sk (p)
54/59 54Un cas réel en fiabilité industrielle : DCC
Choix de la distribution a priori (2)
Cet a priori est conjugué pour la loi multinomiale
Supposons alors que l’information a priori est similaire à celle donnée par un échantillon virtuel
de taille
K
X
P = ñi
i=1
Alors une vision idéale de la distribution a priori est celle du posterior de Jeffreys, qui est
p ∼ Dir (α)
avec
1
αi = + ñi
2
55/59 55Un cas réel en fiabilité industrielle : DCC
Choix de la distribution a priori (3) : une construction par conditionnement hiérarchique
Supposons
αi
p̃i = E[pi ] =
K
P
αk
k=1
αi
⇒ = K
P+ 2
Il faut placer de l’information sur P pour avoir une distribution a priori complète sur p
Remarquons que P = nombre d’expériences virtuelles ayant mené à au moins une défaillance
En appelant Q le nombre de tous les stress virtuels (ayant mené ou non à une défaillance
virtuelle), alors
P ∼ Bin (Q, λ)
Dans une première étude on peut assimiler λ à son estimateur a priori λ̃
56/59 56Un cas réel en fiabilité industrielle : DCC
Choix de la distribution a priori (4) : une construction par conditionnement hiérarchique
Comment placer un a priori hiérarchique sur le nombre de stress virtuels Q ?
Voici un raisonnement cohérent (mais heuristique) :
Disposer d’un estimateur a priori (prior guess) λ̃ requiert d’avoir “observé"’ au moins 1/λ̃
exemple : observer 1 défaillance sur 100 expériences répétées fournit un estimateur
λ̃ = 1/100
Il est désiré que l’a priori (subjectif) apporte moins d’information que les données (objectives)
⇒ 1/λ̃ ≤ Q ≤ M
La distribution a priori Q ∼ U [1/λ̃, M] uniforme discrète semble raisonnable
57/59 57Vous pouvez aussi lire

















































