Système neuronal pour réponses à des questions de compréhension de scène auditives
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
UNIVERSITÉ DE SHERBROOKE
Faculté de génie
Département de génie électrique et de génie informatique
Système neuronal pour réponses à des
questions de compréhension de scène auditives
Mémoire de maitrise
Spécialité : génie électrique
Jérôme Abdelnour
Sherbrooke (Québec) Canada
Mai 2021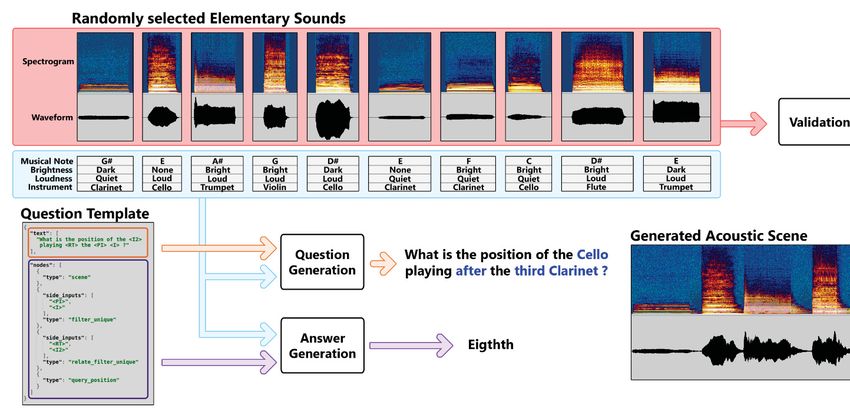
MEMBRES DU JURY
Jean Rouat
Directeur
Giampiero Salvi
Évaluateur
Éric Plourde
Évaluateur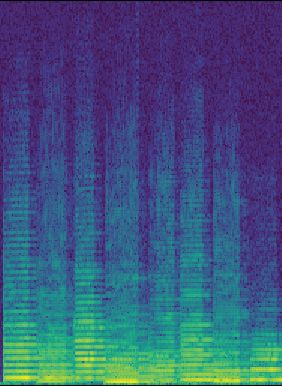
RÉSUMÉ Le présent projet introduit la tâche "réponse à des questions à contenu auditif" (Acoustic Question Answering-AQA) dans laquelle un agent intelligent doit répondre à une ques- tion sur le contenu d’une scène auditive. Dans un premier temps, une base de données (CLEAR) comprenant des scènes auditives ainsi que des paires question-réponse pour chacune d’elles est mise sur pied afin de permettre l’entraînement de systèmes à base de neurones. Cette tâche étant analogue à la tâche "réponse à des questions à contenu visuel" (Visual Question Answering-VQA), une étude préliminaire est réalisé en utilisant un ré- seau de neurones (FiLM) initialement développé pour la tâche VQA. Les scènes auditives sont d’abord transformées en représentation spectro-temporelle afin d’être traitées comme des images par le réseau FiLM. Cette étude a pour but de quantifier la performance d’un système initialement conçu pour des scènes visuelles dans un contexte acoustique. Dans la même lignée, une étude de l’efficacité de la technique visuelle de cartes de coordonnées convolutives (CoordConv ) lorsqu’appliquée dans un contexte acoustique est réalisée. Fi- nalement, un nouveau réseau de neurones adapté au contexte acoustique (NAAQA) est introduit. NAAQA obtient de meilleures performances que FiLM sur la base de données CLEAR tout en étant environ 7 fois moins complexe. Mots-clés : Réseau neurones, AQA, VQA, Question réponse, Convolution, Coordconv, FiLM, Acoustique
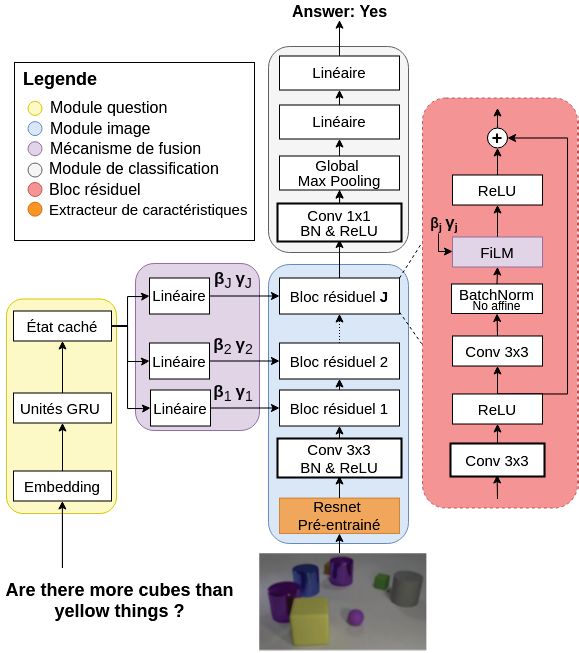

TABLE DES MATIÈRES
1 INTRODUCTION 1
2 REVUE DE LA LITTÉRATURE 3
2.1 Réseaux de neurones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 Perceptron multi-couches . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.3 Apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.4 Réseaux convolutifs . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.5 Pooling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.6 Resnets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Visual Question answering et Feature-wise Linear Modulation (FiLM) . . . 9
2.3 Cartes de coordonnées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Réseaux convolutifs appliqués à l’audio . . . . . . . . . . . . . . . . . . . . 15
2.4.1 Filtres convolutifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.2 Représentation spectro-temporelle . . . . . . . . . . . . . . . . . . . 15
2.4.3 Réseaux audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 BASE DE DONNÉES ET RÉSULTATS PRÉLIMINAIRES 19
3.1 CLEAR : A Dataset for Compositional Language and Elementary Acoustic
Reasoning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Introduction and Related Work . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3.1 Scenes and Elementary Sounds . . . . . . . . . . . . . . . . . . . . 22
3.3.2 Questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.4 Preliminary Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.5.1 Limitations and Future Directions . . . . . . . . . . . . . . . . . . . 26
3.6 Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.7 APPENDIX : Statistics on the Data Set . . . . . . . . . . . . . . . . . . . 28
4 RÉSEAU DE NEURONES ACOUSTIQUE 33
4.1 NAAQA : A Neural Architecture for Acoustic
Question Answering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.4.1 Text-Based Question Answering . . . . . . . . . . . . . . . . . . . . 38
4.4.2 Visual Question Answering (VQA) . . . . . . . . . . . . . . . . . . 38
4.4.3 Acoustic Question Answering (AQA) . . . . . . . . . . . . . . . . . 38
vvi TABLE DES MATIÈRES
4.4.4 Convolutional neural network on Audio . . . . . . . . . . . . . . . . 39
4.5 Variable scene duration dataset . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6 Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.6.1 Baseline model : Visual FiLM . . . . . . . . . . . . . . . . . . . . . 42
4.6.2 NAAQA : Adapting feature extractors to acoustic inputs . . . . . . 43
4.6.3 Coordinate maps with acoustic inputs . . . . . . . . . . . . . . . . . 46
4.7 Experiments & Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7.1 Acoustic Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7.2 Experimental conditions . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7.3 Initial configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.7.4 Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.7.5 Coordinate Maps . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.7.6 Complexity reduction . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.7.7 Impact of dataset composition . . . . . . . . . . . . . . . . . . . . . 52
4.8 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.8.1 NAAQA detailed analysis . . . . . . . . . . . . . . . . . . . . . . . 54
4.8.2 Importance of text versus audio modality . . . . . . . . . . . . . . . 55
4.8.3 Variability of the input size . . . . . . . . . . . . . . . . . . . . . . 56
4.9 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.10 APPENDIX : Network Optimization . . . . . . . . . . . . . . . . . . . . . 58
5 CONCLUSION 61
5.1 Sommaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.2 Retour sur les contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.3 Travaux futurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
LISTE DES RÉFÉRENCES 65LISTE DES FIGURES
2.1 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Perceptron multi couche . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 Réseau convolutif. L’opération de pooling est définie dans la section 2.1.5 . 5
2.4 Champs récepteurs de filtres convolutif. Inspirée de [61]. . . . . . . . . . . 6
2.5 Example de Pooling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.6 Comparaison entre blocs convolutifs . . . . . . . . . . . . . . . . . . . . . . 8
2.7 Schéma du système VQA FiLM . . . . . . . . . . . . . . . . . . . . . . . . 10
2.8 Exemple de tâche de régression de coordonnée. Inspirée de [63]. . . . . . . 13
2.9 Cartes de coordonnées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.10 Différentes formes de filtres convolutifs. Inspirée de [78]. . . . . . . . . . . . 16
2.11 Exemple de spectrogramme. . . . . . . . . . . . . . . . . . . . . . . . . . . 17
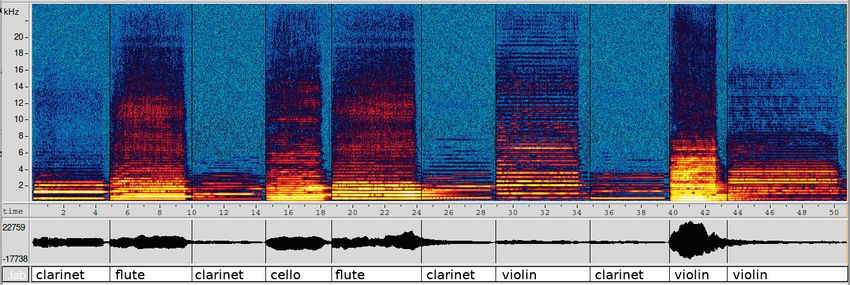
3.1 Example of an acoustic scene . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2 Distribution of answers in the dataset by set type. The color represent the
answer category. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3 Distribution of question types. The color represent the set type. . . . . . . 30
3.4 Distribution of template types. The same templates are used to generate
the questions and answers for the training, validation and test set. . . . . . 31
3.5 Distribution of sound attributes in the scenes . . . . . . . . . . . . . . . . 32
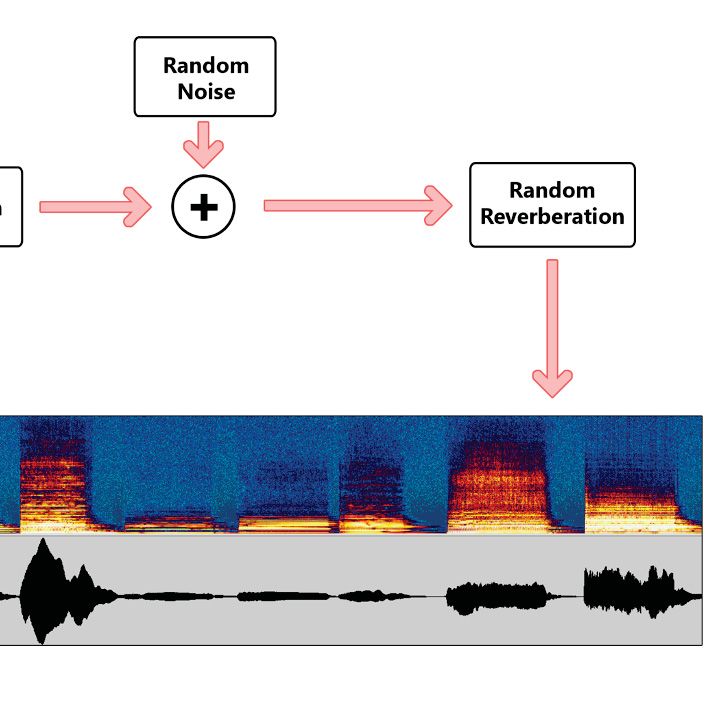
4.1 Overview of the CLEAR dataset generation process . . . . . . . . . . . . . 37
4.2 Common Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3 Acoustic feature extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4 Test accuracy for NAAQA trained on different dataset sizes . . . . . . . . 53
4.5 Test accuracy of NAAQA final configuration by question type and the num-
ber of relation in the question . . . . . . . . . . . . . . . . . . . . . . . . . 54
viiviii LISTE DES FIGURES
LISTE DES TABLEAUX
2.1 Architecture de la première étape de traitement du module image du sys-
tème FiLM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Architecture de chaque bloc résiduel . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Type de questions dans base de donnée CLEVR [48] . . . . . . . . . . . . . 12
3.1 Types of questions with examples and possible answers. . . . . . . . . . . . 23
4.1 Types of questions with examples and possible answers . . . . . . . . . . . 40
4.2 Dataset statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3 Impact of different feature extractors . . . . . . . . . . . . . . . . . . . . . 48
4.4 Impact of the placement of Time and Frequency coordinate maps . . . . . 50
4.5 Comparison of Time and Frequency coordinate maps . . . . . . . . . . . . 51
4.6 Impact of the number of GRU text-processing units G . . . . . . . . . . . 58
4.7 Impact of the number of filters C and hidden units H in the classifier . . . 58
4.8 Impact of reducing the number of Resblock J and the number of filters M
in each Resblocks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.9 Impact of the number of blocks K in the parallel feature extractor and its
projection size P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
ixx LISTE DES TABLEAUX
LISTE DES ACRONYMES
Acronyme Définition
AQA Acoustic Question Answering
BN Batch Normalisation
CLEAR Dataset for Compositional Language and Elementary Acoustic Reasoning
CLEVR Dataset for Compositional Language and Elementary Visual Reasoning
CNN Convolutional Neural Network
Conv Convolution
CQT Constant-Q transform
dB Decibel
FiLM Feature-wise Linear Modulation
GRU Gated Recurrent Unit
LUFS Loudness Unit Full Scale
MFCC Mel-frequency cepstral coefficients
MLP Multi-Layer Perceptron
NAAQA Neural Architecture for Acoustic Question Answering
QA Question Answering
ReLU Rectified Linear Unit
STFT Short-Time Fourier transform
t-SNE t-distributed Stochastic Neighbor Embedding
VQA Visual Question Answering
xixii LISTE DES ACRONYMES
CHAPITRE 1
INTRODUCTION
Le groupe de recherche NECOTIS [85] de la faculté de génie de l’université de Sherbrooke
est le laboratoire coordonnateur du projet Interactive Grounded Language Understanding
(IGLU [86]) financé par CHIST-ERA [99]. Dans le cadre de ce projet, un “jeu” nommé
GuessWhat ? ! [25] a été développé. Il s’agit d’un jeu comportant 2 joueurs. Ceux-ci ont des
rôles bien spécifiques. Le premier joueur assume le rôle de “l’oracle”. Il doit choisir un objet
dans la scène et le garder secret. Le deuxième joueur doit deviner quel est l’objet choisi
par l’oracle. Pour ce faire, les 2 joueurs doivent avoir une conversation orientée autour de
l’objet choisi par l’oracle. Le “devineur” pose une série de questions se répondant par oui
ou par non à l’oracle afin de déduire quel est l’objet choisi. Exemple de question :
– Est-ce une personne ?
– Est-ce que l’objet est de couleur rouge ?
– Etc.
La tâche de l’oracle est de répondre à une question en lien avec le contenu d’une image.
Cette tâche est appelée "réponse à des questions à contenu visuel" (Visual Question Ans-
wering - VQA) [7]. Il existe plusieurs types de solutions dans la littérature pour ce pro-
blème. Perez et al. [76] (membres du consortium IGLU) ont utilisé des réseaux de neurones
convolutifs [58] et des réseaux de neurones récurrents [34] afin de proposer une solution à
la tâche de VQA. Ceux-ci ont développé un mécanisme permettant de moduler les cartes
d’activations d’un réseau convolutif en fonction d’une entrée textuelle (question).
Dans ce mémoire, nous proposons une nouvelle tâche comparable au VQA : réponse à
des questions à contenu auditif (Acoustic Question Answering-AQA). Dans cette tâche,
un agent intelligent doit répondre à une question sur le contenu d’une scène auditive.
Nous nous interrogeons sur la performance de techniques à base de réseau de neurones
initialement développées afin de s’attaquer à des tâches visuelles lorsqu’appliquées dans
un contexte acoustique. Plus précisément, nous nous intéressons à la performance de l’ar-
chitecture FiLM [76] sur la tâche d’Acoustic Question Answering.
Cette problématique peut être formulée sous la forme d’une question :
12 CHAPITRE 1. INTRODUCTION
Est-ce qu’une architecture à base de réseau de neurones développée dans le
but de répondre à des questions sur des scènes visuelles peut être utilisée pour
répondre à des questions sur des scènes auditives ?
Pour répondre à cette question, j’ai conçu une base de données pour la tâche d’AQA. Un
réseau de neurones de type FiLM a été par la suite entraîné sur cette base de données. Une
nouvelle architecture, adaptée au contexte auditif de la tâche a été élaborée et évaluée.
En résumé, voici les contributions scientifiques originales de ce travail de recherche :
– Une base de données composée de 50 000 scènes acoustiques et de 4 paires de ques-
tions et réponses par scène pour un total de 200 000 exemples.
– Une analyse de la performance du système original FiLM sur la tâche d’Acoustic
Question answering.
– Une architecture à base de réseaux de neurones développée spécifiquement pour la
tâche d’Acoustic Question answering.
– Une analyse de la pertinence de l’utilisation de cartes de coordonnées dans un
contexte acoustique.
Le présent document est structuré de la façon suivante : Le chapitre 2 fait une revue de la
littérature en lien avec les objectifs du projet. Le chapitre 3 définit une première version de
la base de données CLEAR accompagnée de résultats préliminaires avec le système FiLM.
Le contenu de ce chapitre a été publié à la conférence NeurIPS 2018 sous le nom CLEAR :
A Dataset for Compositional Language and Elementary Acoustic Reasoning. Finalement, le
chapitre 4 définit la version finale de la base de données CLEAR, une nouvelle architecture
à base de réseaux de neurones adaptée au contexte acoustique de la tâche d’AQA ainsi
qu’une analyse approfondie des résultats. Ce chapitre fait aussi l’analyse de l’utilisation
de cartes de coordonnées dans un contexte acoustique. Le contenu de ce chapitre a été
soumis à la revue IEEE Pattern Analysis and Machine Intelligence sous le nom NAAQA :
A Neural Architecture for Acoustic Question Answering.CHAPITRE 2
REVUE DE LA LITTÉRATURE
Dans ce chapitre, nous introduisons les concepts élémentaires nécessaires à la compréhen-
sion des articles présentés aux chapitres 3 et 4 de ce mémoire. Une revue de la littérature
plus spécialisée est effectuée dans l’article de journal présenté au Chapitre 4.
2.1 Réseaux de neurones
2.1.1 Perceptron
w1
X1
w2
X2
w3 Fonction
X3 activation
wn Biais
Xn
Figure 2.1 Perceptron
Le perceptron [84] est l’unité de base des réseaux de neurones artificiels. Le perceptron
prend un certain nombre d’entré Xn et effectue une somme pondérée via une série de
poids wn . Une transformation non-linéaire, appelée fonction d’activation, est par la suite
appliquée au résultat afin de mieux séparer l’espace. L’équation suivante définie l’opération
effectuée par le perceptron :
N
z = f( w n · xn ) (2.1)
n=1
Où z est la sortie du perceptron, xn représente une entrée, wn représente le poids associée
à cette entrée et f représente la fonction d’activation.
Lors de l’élaboration du perceptron, la fonction d’activation utilisée était la fonction hea-
viside. Cette fonction est discontinue et est définit par l’équation suivante :
⎧
⎨0 si x < 0
f (x) = (2.2)
⎩1 si x ≥ 1
34 CHAPITRE 2. REVUE DE LA LITTÉRATURE
Il existe plusieurs autres types de fonction d’activation tel que la fonction Sigmoide [35],
la fonction tangente hyperbolique [50], la fonction ReLU [46], etc. La fonction d’activation
la plus communément utilisée de nos jours est la ReLU. Elle est définie par l’équation
suivante :
f (x) = max(0, x) (2.3)
2.1.2 Perceptron multi-couches
Couche Couches
d'entrée Cachées
X1 Couche de
Sortie
X2
X3
XN
Figure 2.2 Perceptron multi couche
Un certain nombre de perceptrons peut être assemblé tel qu’illustré à la Figure 2.2 afin de
modéliser des expressions complexes. Ils sont organisés en couches : la couche d’entrée, les
couches cachées (en jaune) et la couche de sortie (en vert). Chaque neurone est connecté
à tous les neurones de la couche précédente. Chaque connexion est modulée par un poids
wij où i correspond à l’indice du neurone et j correspond à l’indice de la couche. Les biais
ainsi que les fonctions d’activations ne sont pas inclus à la Figure 2.2 afin de simplifier
l’illustration. Le nombre de couches cachées ainsi que le nombre de neurones par couche
sont des hyper-paramètres qui doivent être ajusté lors de l’élaboration du réseau. Le nombre
de neurones dans la couche de sortie dépend de la tâche pour laquelle est entraîné le
réseau. Le réseau illustré à la Figure 2.2 pourrait, par exemple, être utilisé pour une tâche
d’approximation ou une tâche de classification binaire puisqu’il ne contient qu’un seul
neurone de sortie. Pour une classification où il y a plus de 2 classes, le réseau pourrait
contenir C neurones de sortie où C est le nombre de classes.
2.1.3 Apprentissage
Un réseau de neurones peut être entraîné de façon supervisée ou non-supervisée. L’en-
traînement supervisé est la stratégie la plus répandue et celle qui sera utilisée dans ce
mémoire. Un jeu de données annoté est nécessaire pour ce type d’entraînement. Il s’agit2.1. RÉSEAUX DE NEURONES 5
Convolution Pooling Convolution Pooling
Figure 2.3 Réseau convolutif. L’opération de pooling est définie dans la section
2.1.5
d’un processus itératif où la sortie du réseau est comparée à la valeur attendue pour en
calculer la différence (erreur) et appliquer un correctif aux poids du réseau (W ) en fonc-
tion de cette erreur. Il existe plusieurs façons de calculer cette erreur. Par exemple il est
possible d’utiliser le critère de l’erreur moyenne carrée (MSE) ou encore le critère Cross-
Entropy. Les poids du réseau (W ) sont optimisé de façon itérative afin de minimiser le
critère d’erreur (L) choisi. L’algorithme utilisé est la descente de gradient [87] et est défini
de la façon suivante :
e+1 e ∂L(X, W )
W =W −μ (2.4)
∂W
Où e est le numéro de l’itération, X est la matrice d’entrée, W est la matrice de poids du
réseau, L est le critère d’erreur et μ est le taux d’apprentissage régissant la mise a jour
des poids. Sa valeur est définie lors de la phase d’apprentissage.
Le gradient est propagé à travers le réseau en partant de la sortie vers l’entrée. La dérivée
partielle est calculée en utilisant la règle de dérivation en chaine [82]. Les gradients locaux
pour chaque couches sont multipliés ensemble ce qui fait en sorte que plus le nombre de
couche est élevé, plus le gradient tend vers zéro. Un gradient qui tend vers zéro pour les
couches inférieures implique que les valeurs des poids ne changent presque pas lors de la
mise à jour itérative (Équation 2.4). L’apprentissage devient alors très lent voir impossible.
Ce problème est communément appelé disparition du gradient (vanishing gradient.)
2.1.4 Réseaux convolutifs
Les réseaux convolutifs dominent les applications en reconnaissance d’image depuis que le
réseau AlexNet [54] a remporté la compétition ImageNet Large Scale Visual Recognition
Challenge [47] en 2012. Ceux-ci ont néanmoins été introduits bien avant, en 1998, par Lecun
et al. [56]. Les réseaux convolutifs sont construits de façon hiérarchique [58] : les couches
inférieures capturent des composantes primitives et les couches supérieures combinent
les composantes de la couche précédente afin d’apprendre des concepts de plus en plus
complexes. Par exemple, pour un réseau faisant la reconnaissance de chaises, la première
couche pourrait capturer des lignes avec différentes orientations, puis la deuxième couche6 CHAPITRE 2. REVUE DE LA LITTÉRATURE
Figure 2.4 Champs récepteurs de filtres convolutif. Inspirée de [61].
assemble ces lignes afin de reconnaître les pattes, le siège et le dossier. Finalement, la couche
supérieure assemble les composantes des pattes, du siège et du dossier pour reconnaître
la chaise. La sortie d’une couche convolutive est appelée carte d’activation. Le nombre de
cartes d’activation dépend du nombre de filtres convolutifs dans une couche convolutive.
Les couches convolutives sont généralement entrelacées avec des couches de pooling afin de
réduire la taille des cartes d’activations (contribuant ainsi au processus de hiérarchisation).
La Figure 2.4 illustre le champs réceptif d’un neurone dans différentes couches. L’opération
de pooling est détaillée à la Section 2.1.5. La dernière couche d’un réseau convolutif est
plus souvent qu’autrement un perceptron multi-couche. Dans le cas d’un réseau faisant de
la classification, cette couche permet l’apprentissage des relations entre les composantes
complexes et les différentes classes à reconnaître.2.1. RÉSEAUX DE NEURONES 7
2.1.5 Pooling
58 24 45
12 38 8 6 33 5 Max-Pooling 92 67 91
58 2 24 11 9 45 93 74 93
86 55 38 22 91 32
92 7 18 67 85 39
23 85 74 4 15 93 27.5 12.3 23.0
17 93 49 62 46 34 60.0 36.3 61.8
Average-Pooling
54.5 47.3 47.0
Figure 2.5 Example de Pooling
L’opération de pooling est utilisée afin de sous-échantillonner une carte d’activation. Pour
ce faire, la carte d’activation est séparée en une série de rectangles de N ×M . Une seule va-
leur est retenue par rectangle ce qui a pour effet de réduire la taille de la carte d’activation.
Cette opération contribue à la propriété d’insensibilité spatiale des réseaux convolutifs.
Plus les cartes d’activations sont réduites, plus les activations représentent des concepts
abstraits et moins elles ont de lien avec la position sur l’image d’entrée tel qu’illustré à la
Figure 2.4. Il existe plusieurs stratégies de pooling. Une première stratégie est de faire la
moyenne des valeurs dans chaque rectangle. Une autre stratégie est de garder la valeur la
plus grande dans chaque rectangle. On garde ainsi la valeur la plus représentative de la
caractéristique extraite par le filte convolutif. La figure 2.5 montre un example pour les
deux types de Pooling avec un filtre de taille 2 × 2.8 CHAPITRE 2. REVUE DE LA LITTÉRATURE
2.1.6 Resnets
Block 2 Resblock 2
Entrée
+
Convolution
Convolution
Convolution
Convolution
Block 1 Resblock 1
Entrée
+
Convolution
Convolution
Convolution
Convolution
(a) Bloc convolutif (b) Bloc convolutif rédisuel
Figure 2.6 Comparaison entre blocs convolutifs
Les réseaux convolutifs de type VGG[91] souffrent du problème de disparition du gradient
décrit à la Section 2.1.3. Plus on ajoute de couches convolutives, plus le gradient diminue
et donc la capacité de convergence du réseau. He et al. [37] ont introduit le concept de
bloc résiduel avec le réseau ResNet afin de pallier à ce problème. Pour ce faire, la sortie du
bloc convolutif est additionnée avec l’entrée tel qu’illustré à la Figure 2.6b. Cette addition
est appelée Skip Connection. La sortie d’un bloc résiduel est définie par :
H(x) = x + F (x) (2.5)
Où x est l’entrée et F (x) est une série d’opérations de convolution.
Le gradient de la fonction de coût (L) par rapport à l’entrée peut être écrit de la façon
suivante :
∂L ∂L ∂H
=
∂x ∂H
∂x
∂L ∂F
= 1+ (2.6)
∂H ∂x
∂L ∂L ∂F
= +
∂H ∂H ∂x2.2. VISUAL QUESTION ANSWERING ET FEATURE-WISE LINEAR
MODULATION (FILM) 9
Le gradient de l’entrée par rapport à elle même est égale à 1. En additionnant l’entrée à la
sortie du bloc résiduel, le gradient peut se propager plus facilement limitant ainsi l’impact
du problème de disparition du gradient. En utilisant cette technique, il est possible de
développer des réseaux convolutifs beaucoup plus profonds.
2.2 Visual Question answering et Feature-wise Linear
Modulation (FiLM)
Le VQA [7] est un type de problème pour lequel un agent intelligent doit répondre à des
questions liées au contenu d’une image qui a été choisie au préalable. Ces questions sont
habituellement formulées sous forme de mots. Chaque scène visuelle peut être composée
d’une seule ou plusieurs images (vidéo). Perez et al. [75, 76] ont proposé une approche à
base de réseaux de neurones afin de résoudre ce problème. La solution peut être séparée
en 2 modules principaux : un module qui analyse la question textuelle et un module qui
analyse l’image.
Le module question textuelle, désigné par les boites GRU sur la figure 2.7, prend en entrée
une séquence de mots (certaines questions font plus de 40 mots). Puisque l’ordre de la
séquence contient des informations importantes quant au sens de la question [34], le module
est composé d’un réseau de neurones récurrent. Il s’agit d’un réseau récurrent de type
GRU [23] formé de 4096 unités cachées. La dernière unité cachée produit un nombre N de
couples de 2 paramètres (γ,β) paramétrant les N couches FiLM utilisées dans le module
image. Ces paramètres permettent de “focaliser l’attention” du module d’analyse d’image
en modulant les cartes d’activations du réseau.
Le module image, désigné par les boites CNN et ResBlock sur la figure 2.7, est composé d’un
réseau convolutif qui analyse la scène visuelle. Plutôt que de faire l’apprentissage à partir
de valeurs de poids aléatoires, Perez et al. ont choisi d’utiliser les premières couches d’un
réseau classificateur ResNet-101 [37] pré-entraîné sur la base de données ImageNet [47].
Ceci permet d’accélérer grandement la vitesse de convergence de l’apprentissage du réseau
convolutif puisque les couches se chargeant de l’apprentissage des structures primaires [58]
(les premières couches du réseau) n’ont pas besoin d’être apprises. Cet apprentissage prend
un temps considérable car les variations appliquées aux poids des couches deviennent de
plus en plus petites plus on descend dans l’architecture du réseau (la sortie du réseau est
ici considérée comme étant la couche la plus haute alors que la première couche est la
couche la plus basse) à cause du problème de dégénérescence du gradient [11]. Perez et al.
ont utilisé la couche conv4_6 du réseau Resnet ainsi que les couches inférieures comme
première étape de traitement de l’image. La sortie de la couche conv4_6 passe ensuite10 CHAPITRE 2. REVUE DE LA LITTÉRATURE
Figure 2.7 Schéma du système VQA FiLM inspirée de [76]. À gauche, le module
question composé d’un réseau récurrent de type GRU. Ce dernier prend en
entrée une question sous forme d’une séquence de mots et calcule les valeurs
β et γ qui seront utilisées par le module image présenté au centre du schéma.
Celui-ci prend en entrée l’image représentant la scène d’intérêt. Cette image
est traitée par un premier réseau convolutif pré entrainé (CNN) puis par une
série de blocs résiduels. L’architecture d’un bloc résiduel est détaillée à droite
du schéma. On y retrouve une série de couches convolutives (Conv ), une couche
de normalisation par lot (batch normalisation-BN ) ainsi qu’une couche FiLM.
Cette couche prend en paramètre β et γ calculés par le module question afin
d’appliquer une transformation linéaire sur l’activation de la couche précédente.
Cette transformation permet de focaliser l’attention du réseau convolutif sur
différentes caractéristiques de l’image en fonction de la question posée. La couche
FiLM est suivie par la fonction d’activation ReLU définie à la section 2.1.3. La
sortie du dernier bloc résiduel est finalement envoyée dans un classificateur qui
choisira la réponse la plus probable à la question en fonction de la liste de
réponses possibles.2.2. VISUAL QUESTION ANSWERING ET FEATURE-WISE LINEAR
MODULATION (FILM) 11
Couche Dimension
Image d’entrée 3 x 224 x 224
ResNet-101 jusqu’à conv4_6 1024 x 14 x 14
Conv(3 x 3, 1024 → 128) 128 x 14 x 14
ReLU 128 x 14 x 14
Conv(3 x 3, 128 → 128) 128 x 14 x 14
ReLU 128 x 14 x 14
Tableau 2.1 Architecture de la première étape de traitement du module image
du système FiLM [49, 76]. La colonne dimension A x B x C exprime la dimension
de la sortie de chaque couche. A est le nombre de cartes d’activation de dimension
B par C. ResNet-101 fait référence au réseau ResNet [37] pré-entraîné sur la base
de données ImageNet [47]. À la colonne Couche, Conv(E x F, G → H) représente
une couche convolutive composée de H filtres de dimension E par F. La relation
G → H montre le nombre de cartes de caractéristique en entrée G versus le
nombre en sortie H. ReLU représente la fonction d’activation “Rectified Linear
Unit” [108].
par 2 couches convolutives avec fonction d’activation ReLU [108]. Le tableau 2.1 donne
les détails de ces couches.
Un nombre N de blocs résiduels est placé après cette première étape de traitement. Le
nombre de blocs résiduel est un choix d’implémentation. Perez et al. ont choisi d’utiliser
un N de 4. Ce choix a été déterminé de façon empirique. Chaque bloc résiduel est défini
tel que présenté dans le tableau 2.2.
La principale contribution du travail de Perez et al. [76] se trouve au niveau de la couche
FiLM. Cette couche effectue une transformation linéaire de la sortie de la couche précédente
en fonction de 2 paramètres qui sont appris par le module question. L’équation 2.7 démontre
la transformation appliquée :
F iLM (Fj,c |γj,c , βj,c ) = γj,c Fj,c + βj,c (2.7)
Dans cette équation, F représente la carte d’activation (sortie) de la couche précédente.
Les index i et c correspondent respectivement à l’index de l’entrée et l’index de la carte
d’activation. Les paramètres γ et β sont appris lors de la phase d’entrainement du sys-
tème. Dépendamment de la valeur de ceux-ci, la carte d’activation F sera modulée d’une
façon différente. Par exemple, la modulation appliquée peut effectuer une négation, une
amplification ou encore le seuillage de certaines parties des cartes d’activation. Ces modu-
lations permettent de focaliser l’attention du réseau convolutif vers des parties spécifiques
de l’image en fonction de la question présentée en entrée. Les auteurs ont effectué une12 CHAPITRE 2. REVUE DE LA LITTÉRATURE
Indice Couche Dimension
(1) Sortie du module précédent 128 x 14 x 14
(2) Conv(1 x 1, 128 → 128) 128 x 14 x 14
(3) ReLU 128 x 14 x 14
(4) Conv(3 x 3, 128 → 128) 128 x 14 x 14
(5) Batch Normalisation 128 x 14 x 14
(6) Couche FiLM 128 x 14 x 14
(7) ReLU 128 x 14 x 14
(8) Ajout des résidus (3) et (7) 128 x 14 x 14
Tableau 2.2 Architecture de chaque bloc résiduel [49, 76]. La colonne dimension
A x B x C exprime la dimension de la sortie de chaque couche. A est le nombre
de cartes d’activation de dimension B par C. La couche Batch Normalisation est
détaillé dans [44]. La couche FiLM est définie par l’équation 3.1. Conv(E x F,
G → H) représente une couche convolutive composée de H filtres de dimension
E par F. La relation G → H montre le nombre de cartes de caractéristique en
entrée G versus le nombre en sortie H. ReLU représente la fonction d’activation
“Rectified Linear Unit” [108].
Type de question Example de question
Existe (Exist) Is there a white cube ?
Moins de (Less than) Is there less red cylinder than big sphere ?
Plus que (Greater than) Is there more sphere than cube ?
Compte (Count) How many cubes are metallic ?
Requête du matériel (Query material) What is the material of the red cylinder in the right corner ?
Requête de la taille (Query size) What is the size of the yellow sphere ?
Requête de la couleur (Query color) What is the color of the brown thing that is left of the big sphere ?
Requête de la forme (Query shape) What is the shape of the green metallic thing ?
Équivalence de couleur (Equal color) Are the big cube and the small sphere of the same color ?
Équivalence de forme (Equal shape) Are the red metallic thing and the brown thing of the same shape ?
Équivalence de taille (Equal size) Are the brown cube and the yellow sphere of the same size ?
Équivalence de matériel (Equal material) Are the sphere and the red cube of the same material ?
Équivalence de quantité (Equal integer) Are there an equal number of large things and metal spheres ?
Tableau 2.3 Type de questions dans base de donnée CLEVR [48]
analyse des paramètres γ et β après entraînement pour chaque bloc résiduel. Ceux-ci ont
observé des regroupements en lien avec les différents types de questions dans les blocs
résiduels de haut niveau via une projection t-SNE [76]. Les auteurs soutiennent que ces
regroupements témoignent d’un certain "raisonnement" basé sur les questions.
La sortie du dernier bloc résiduel passe ensuite à travers un classificateur qui permettra
d’attribuer une probabilité à chaque réponse possible. La réponse prédite correspond alors
à la “classe” ayant la plus grande probabilité. L’ensemble des réponses possibles est défini
par les exemples de réponse présentés lors de la phase d’entrainement. Le réseau ne sera
donc pas en mesure de produire des réponses qu’il n’a pas vues à l’apprentissage. Le2.3. CARTES DE COORDONNÉES 13
(x,y) Conv
Figure 2.8 Exemple de tâche de régression de coordonnée. Inspirée de [63].
classificateur est composé d’une couche convolutive 1 x 1 et de 2 couches perceptron (512
et 1024 neurones).
Afin de réaliser l’entrainement du système, les auteurs ont utilisé la base de données
CLEVR [49]. Celle-ci est composée de 70 000 images d’entrainement, 15 000 images de
validation et 15 000 images de test. Ces images sont des scènes contenant des formes
géométriques 3D de différentes couleurs, différentes tailles, placées à différents endroits
et avec différents paramètres d’occlusion. Chacune de ces scènes est générée de façon
artificielle. Pour chaque scène, une panoplie d’ensembles question-réponse est générée. On
en compte 699 989 pour l’entrainement, 149 991 pour la validation et 14 988 pour les tests.
Les différentes catégories de question sont celles présentées dans le Tableau 2.3. En plus du
triplet question-image-réponse, la base de données offre aussi une notion de contexte quant
au type de question. Cette information à priori n’est pas utilisée pour faire l’apprentissage
dans ce cas-ci. Ce système atteint une précision moyenne de 97.7% sur l’ensemble de test
de CLEVR en faisant ainsi la meilleure technique dans l’état de l’art pour cette base de
données à l’époque de la publication.
2.3 Cartes de coordonnées
Liu et al. [63] ont développé une tâche où un réseau de neurones doit déterminer la position
d’un carré blanc dans une image avec un fond noir à partir de ses coordonnées cartésiennes.
Un exemple est illustré à la Figure 2.8. L’opération inverse, c’est à dire déterminer les
coordonnées cartésiennes d’un carré à partir d’une image, est aussi exploré. Cette tâche
(et son opposée) semble très simple mais Liu et al. ont observé que les réseaux de neurones
convolutifs ont de la difficulté à effectuer cette transformation de l’espace cartésien vers
l’espace des pixels. Selon eux, cette difficulté s’explique par le fait que chaque filtre d’une
couche convolutive est déplacé sur l’image d’entrée. Ce déplacement permet au filtre de
s’activer lorsqu’il détecte un objet ou une caractéristique quelle que soit sa position dans
l’image (invariance spatiale). Il s’agit là d’une des forces des réseaux convolutifs, surtout
dans le cadre d’une tâche de classification d’image où l’objectif est d’identifier une image
à partir de ses composantes. Cette propriété est par contre problématique pour une tâche14 CHAPITRE 2. REVUE DE LA LITTÉRATURE
Carte Coordonnées axe Y Carte Coordonnées axe X Cartes activations
-1 -1 -1 -1 -1 -1 -1 -1 -1 -0.9 -0.8 0.8 0.9 1
-0.9 -0.9 -0.9 -0.9 -0.9 -0.9 -0.9 -0.9 -1 -0.9 -0.8 0.8 0.9 1
-0.8 -0.8 -0.8 -0.8 -0.8 -0.8 -0.8 -0.8 -1 -0.9 -0.8 0.8 0.9 1
-1 -0.9 -0.8 0.8 0.9 1 Convolution
-1 -0.9 -0.8 0.8 0.9 1
0.8 0.8 0.8 0.8 0.8 0.8 0.8 0.8 -1 -0.9 -0.8 0.8 0.9 1
0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.9 -1 -0.9 -0.8 0.8 0.9 1
1 1 1 1 1 1 1 1 -1 -0.9 -0.8 0.8 0.9 1
Figure 2.9 Cartes de coordonnées
où la position dans l’espace est importante tel que le traçage de cadre autour d’objets dans
une scène visuelle ou encore la régression de coordonnée cartésiennes.
Liu et al. [63] proposent le concept de carte de coordonnées afin de permettre a une couche
convolutive de conserver des informations sur la position d’un objet. L’objectif est d’offrir
une série de points de référence au réseau afin de faciliter son orientation spatiale. Pour ce
faire, 2 matrices composées de valeurs fixes sont concaténées avec les cartes d’activations à
l’entrée d’une couche convolutive tel qu’illustré à la Figure 2.9. Les dimensions des matrices
sont les mêmes que celles des cartes d’activations avec lesquelles elles sont concaténées.
La première matrice sert de référence pour l’axe des ordonnées (Y). Toutes les colonnes
de cette matrice sont identiques. La valeur à la première ligne est -1 et augmente de
façon linéaire jusqu’à la dernière ligne qui comporte la valeur 1. Ceci donne un point de
repère quant au début et à la fin de l’axe des ordonnées. Cette référence est constante
pour chaque couche convolutive quelle que soit la dimension des cartes d’activations. La
deuxième matrice sert de référence pour l’axe abscisse (X) et est similaire à la première.
Les axes sont inversés : les valeurs des colonnes varient linéairement de -1 à 1 et les lignes
sont identiques.
Un réseau convolutif faisant usage de cartes de coordonnées atteint une précision de 100%
sur la tâche illustrée à la Figure 2.8 alors que le meilleur réseau sans carte de coordon-
nées évalué dans [63] obtient 86%. Liu et al. ont aussi testé les cartes de coordonnées sur
des tâches plus complexes et ont observé une augmentation considérable de la précision2.4. RÉSEAUX CONVOLUTIFS APPLIQUÉS À L’AUDIO 15 lorsqu’utilisé dans le cadre d’une tâche de traçage de cadre autour d’objet visuel. La per- formance reste sensiblement la même lorsqu’appliqué à la tâche de classification ImageNet [47]. Ceci démontre qu’il est possible pour le réseau d’apprendre à ignorer les informations de coordonnées et ainsi maintenir la propriété d’invariance spatiale des réseaux convolutifs lorsque nécessaire. 2.4 Réseaux convolutifs appliqués à l’audio 2.4.1 Filtres convolutifs Tel que mentionné à la section 2.1.4, les réseaux convolutifs sont réputés être capables d’apprendre une certaine hiérarchie liée à l’organisation de la scène représentée dans une image. Afin d’utiliser ce type de réseau avec des trames sonores, plusieurs travaux [21, 26, 72, 73, 79] utilisent des représentations temps-fréquence des dites trames. Ce type de représentation organise les fréquences sur l’axe des ordonnées et le temps sur l’axe des abscisses. Dans une image classique, les 2 axes représentent une position spatiale. Il s’agit là d’une différence majeure qui a un grand impact sur la façon d’interpréter ces 2 types d’images. Lorsqu’on effectue une opération de convolution sur une image classique, on déplace habituellement un filtre selon les 2 axes de façon similaire. Ce déplacement n’a pas la même signification dans le cas d’une représentation temps-fréquence que dans une image classique. La plupart du temps, lorsqu’on travaille avec des images classiques, les filtres sont de forme carrée. Pons et al. [78, 80] font l’analyse de différentes formes de filtres. Ils expliquent qu’un filtre de forme m × 1 (Fig. 2.10a) est un filtre permettant de capturer les caractéristiques fréquentielles du signal. Un filtre de forme 1 × n (Fig. 2.10b), quant à lui, capture les caractéristiques temporelles du signal. Pons et al. [80] expérimentent avec plusieurs longueurs de filtre temporel. Un filtre court (moins de 950 ms) permet de modéliser les onsets alors qu’un filtre long (plus de 1500 ms) capture le rythme du signal. Un filtre de forme carrée/rectangulaire m × n (Fig. 2.10c) permet donc de modéliser à la fois des composantes fréquentielles et temporelles. Cette configuration est d’ailleurs la plus utilisée dans la littérature. 2.4.2 Représentation spectro-temporelle Il existe plusieurs types de représentation temps-fréquence. Une des plus populaires dans la littérature est le spectrogramme [105] (Illustré dans la Figure 2.11). Celui-ci est obtenu en faisant une transformée de Fourier à temps court (STFT) [27] du signal. Rui et al. [16] proposent d’effectuer une décomposition en composantes principales (PCA [3]) sur un spectrogramme. Il existe d’autres représentations temps-fréquence telles que le Constant- Q Transform (CQT) [90], le Perceptual Linear Predictive (PLP) [39], le Mel frequency
16 CHAPITRE 2. REVUE DE LA LITTÉRATURE
n=1
M m M M n
n
m
m=1
N N N
(a) Filtre fréquenciel (b) Filtre temporel (c) Filtre fréquentiel et tem-
porel
Figure 2.10 Différentes formes de filtres convolutifs. Inspirée de [78].
Cepstrum coefficients (MFCC) [64, 68] et le spikegramme [28]. Chaque représentation
permet de faire ressortir des caractéristiques du son différentes. Par exemple, la représen-
tation MFCC et la CQT utilisent une échelle fréquentielle non linéaire similaire à celle
de la perception humaine [64]. Cette échelle permet de mieux distinguer les composantes
vocales d’un signal et offre une meilleure résolution en basse fréquence que la STFT. Cela
permet d’identifier plus facilement la fréquence fondamentale. Ces représentations ont été
et sont encore beaucoup utilisées dans le domaine de la reconnaissance vocale. L’utilisation
d’une représentation plutôt qu’une autre dépend de la nature des sons avec lesquels on
travaille.
2.4.3 Réseaux audio
Les réseaux convolutifs ont été utilisés sur des signaux sonores en transformant d’abord
le signal en représentation temps-fréquence pour effectuer plusieurs types de tâches. Pour
n’en citer que quelques unes, ceux-ci ont été utilisés pour faire la classification de son [72,
78, 79, 93], la reconnaissance vocale [1, 26, 59], l’annotation de musique [21] et le dé-
bruitage [73]. Comme dans tout système à base de réseau de neurones, il n’existe pas de
configuration optimale pour tous les types de tâches. Pons et al. [79] proposent d’utiliser
une architecture peu profonde avec seulement une couche convolutive et une couche de
max-pooling [89] pour faire la modélisation de caractéristiques temporelles à court-terme
de signaux musicaux. Ils proposent aussi d’ajouter un réseau récurrent à la sortie du ré-
seau convolutif. Puisque le réseau convolutif modélise les caractéristiques à court-terme
des signaux, l’ajout d’un réseau récurrent pourrait permettre la modélisation de caracté-
ristiques plus long-terme. Cette piste de solution sera explorée dans un travail futur des
auteurs. Park et al. [73] proposent quant à eux d’utiliser 3 couches convolutives avec le
même nombre de couches max-pooling pour faire la classification de segments de bruit
dans un signal. Tel que mentionné précédemment, la forme du filtre ainsi que la direc-
tion de son mouvement permettent de capturer différents aspects du son. Choi et al. [21]2.4. RÉSEAUX CONVOLUTIFS APPLIQUÉS À L’AUDIO 17
Fréquence
Temps
.
Figure 2.11 Exemple de spectrogramme.
utilisent des filtres qui se déplacent selon l’axe X (temps) dans le but d’apprendre la dis-
tribution temporelle des différentes bandes de fréquences d’un signal musical pour en faire
l’annotation. Pons et al. [80] mentionnent que l’utilisation de différents filtres pour chaque
couche convolutive permet d’améliorer les performances du système. Le travail de Sprengel
et al. [93] quant à lui n’a réussi à obtenir des résultats qu’avec des filtres carrés. La forme
des filtres dépend, encore une fois, du type de signaux analysés.
Finalement, il existe d’autres approches permettant d’intégrer des représentations sonores
dans un réseau de neurones. Par exemple, la combinaison d’un réseau à réservoir avec une
représentation par cochléogramme pour faire la reconnaissance de séquences temporelles
acoustiques [9, 13] et l’utilisation d’une représentation évènementielle pour faire la détec-
tion et la localisation d’évènement acoustique [28]. Ces dernières approches ont l’avantage
de ne pas avoir besoin de travailler avec des trames fixes (contrairement aux approches
conventionnelles) placées sur le signal et sont développées au sein du groupe de recherche
NECOTIS[85].18 CHAPITRE 2. REVUE DE LA LITTÉRATURE
CHAPITRE 3
BASE DE DONNÉES ET RÉSULTATS PRÉ-
LIMINAIRES
Auteurs et affiliation :
Jerome Abdelnour : étudiant à la maitrise, Université de Sherbrooke,
Faculté de génie, Département de génie électrique et de génie informatique.
Giampiero Salvi : professeur, Université Norvégienne de sciences et
technologies (NTNU), Département de systèmes électroniques.
Jean Rouat : professeur, Université de Sherbrooke, Faculté de génie,
Département de génie électrique et de génie informatique.
Date de l’acceptation : 10 novembre 2018
État de l’acceptation : version finale publiée
Revue : NeurIPS 2018 - Visually Grounded Interaction and Language workshop
Référence : [J. Abdelnour, J. Rouat and G. Salvi, “CLEAR : A Dataset for Com-
positional Language and Elementary Acoustic Reasoning,” in Workshop on Visually
Grounded Interaction and Language in Advances in Neural Information Processing
Systems 31, 2018, https ://arxiv.org/abs/1811.10561]
Titre français : CLEAR : Une base de données pour raisonnement acoustique.
Code : https://github.com/IGLU-CHISTERA/CLEAR-dataset-generation
Contribution au document :
Cet article contribue au présent mémoire en introduisant la tâche Acoustic Question
Answering ainsi qu’une première version de la base de données CLEAR. La base
de données est la première étape de ce travail puisque sans elle, aucun réseau de
neurones ne peut être entraîné. L’article décrit les diverses caractéristiques de la
base de données ainsi que les techniques utilisées pour la générer. L’article introduit
aussi des résultats préliminaires avec le système FiLM.
Résumé français :
La tâche d’Acoustic Question Answering est introduite pour la première fois dans cet
article afin de promouvoir la recherche en raisonnement acoustique. Dans cette tâche,
un agent intelligent apprend à répondre à une question sur le contenu d’une scène
1920 CHAPITRE 3. BASE DE DONNÉES ET RÉSULTATS PRÉLIMINAIRES
auditive. Nous proposons un paradigme de génération de données pour la tâche AQA
inspiré par CLEVR [48]. Les scènes acoustiques sont de durée fixe et sont générées
en assemblant 10 sons provenant d’une banque de son élémentaire. Les questions et
réponses pour chaque scène acoustique sont générées via des programmes fonctionnels
définis manuellement. Le code pour générer la base de données est rendu publique
pour la communauté sur GitHub. Une analyse préliminaire de la performance du
modèle FiLM, initialement développé pour la tâche VQA, est rapporté pour cette
tâche acoustique.
Modifications apportées à l’article :
La mise en page a été ajusté afin d’uniformiser la mise en page de ce document. La
bibliographie de l’article à été intégrée dans la bibliographie à la fin de ce mémoire.3.1. CLEAR : A DATASET FOR COMPOSITIONAL LANGUAGE AND
ELEMENTARY ACOUSTIC REASONING 21
3.1 CLEAR : A Dataset for Compositional Language
and Elementary Acoustic Reasoning
3.1.1 Abstract
We introduce the task of acoustic question answering (AQA) in the area of acoustic rea-
soning. In this task an agent learns to answer questions on the basis of acoustic context.
In order to promote research in this area, we propose a data generation paradigm adapted
from CLEVR [48]. We generate acoustic scenes by leveraging a bank of elementary sounds.
We also provide a number of functional programs that can be used to compose questions
and answers that exploit the relationships between the attributes of the elementary sounds
in each scene. We provide AQA datasets of various sizes as well as the data generation
code. As a preliminary experiment to validate our data, we report the accuracy of current
state of the art visual question answering models when they are applied to the AQA task
without modifications. Although there is a plethora of question answering tasks based on
text, image or video data, to our knowledge, we are the first to propose answering ques-
tions directly on audio streams. We hope this contribution will facilitate the development
of research in the area.
3.2 Introduction and Related Work
Question answering (QA) problems have attracted increasing interest in the machine lear-
ning and artificial intelligence communities. These tasks usually involve interpreting and
answering text based questions in the view of some contextual information, often expressed
in a different modality. Text-based QA, use text corpora as context ([40, 45, 81, 92, 101,
102]) ; in visual question answering (VQA), instead, the questions are related to a scene
depicted in still images (e.g. [5, 7, 30, 31, 45, 48, 81, 111, 114]. Finally, video question
answering attempts to use both the visual and acoustic information in video material as
context (e.g. [17, 22, 51, 97, 104, 106]). In the last case, however, the acoustic information
is usually expressed in text form, either with manual transcriptions (e.g. subtitles) or by
automatic speech recognition, and is limited to linguistic information [112].
The task presented in this paper differs from the above by answering questions directly
on audio streams. We argue that the audio modality contains important information that
has not been exploited in the question answering domain. This information may allow QA
systems to answer relevant questions more accurately, or even to answer questions that
are not approachable from the visual domain alone. Examples of potential applications are
the detection of anomalies in machinery where the moving parts are hidden, the detection
of threatening or hazardous events, industrial and social robotics.Vous pouvez aussi lire