TAL: traitement automatique de la langue Manipulation des s equences - Lip6
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous

Intro HMM CRF RNN
TAL: traitement automatique de la langue
Manipulation des séquences
Vincent Guigue
UPMC - LIP6
Vincent Guigue TAL – Séquences 1/54
Intro HMM CRF RNN
Fonctionnement de l’UE
I TAL = mélange de plusieurs disciplines
1/2 Traitement de la Langue (=métier): Brigitte Grau & Anne-Laure
Ligozat
1/2 Apprentissage Automatique (=outils): Vincent Guigue
I Evaluation:
◦ 60% Projet = biblio + analyse d’une problématique TAL +
manipulation des outils
◦ 40% Examen = fonctionnement des méthodes d’apprentissage
I Positionnement:
◦ Un peu de MAPSI/ARF...
◦ Mais surtout de l’utilisation de modèles + campagne d’expériences
(+professionalisante)
Vincent Guigue TAL – Séquences 2/54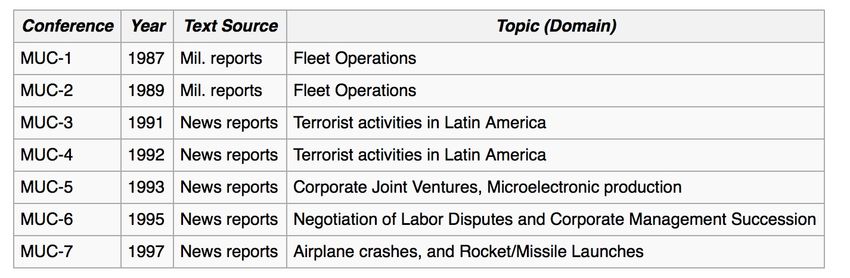
Intro HMM CRF RNN
C’est quoi du texte?
I Une suite de lettres
l e c h a t e s t ...
I Une suite de mots
le chat est ...
I Un ensemble de mots
chat
est
Dans l’ordre alphabétique
le
...
Vincent Guigue TAL – Séquences 3/54
Intro HMM CRF RNN
Différentes tâches
I Classification de textes
◦ Classification thématique
e.g. football, article scientifique, analyse politique
◦ Classification de sentiments positif, négatif, neutre, agressif, . . .
I Classification de mots
◦ Grammaire = Part-Of-Speech (POS)
Nom, Nom propre, Déterminant, Verbe...
◦ NER = Named Entity Recognition
détection des noms propres, travail sur les co-références
◦ SRL = Semantic Role Labeling sujet, verbe, compléments...
I Question Answering, Extraction d’information
Vincent Guigue TAL – Séquences 4/54
Intro HMM CRF RNN
Applications
Part-of-Speech (POS) Tagging
I tags: ADJECTIVE, NOUN, PREPOSITION, VERB, ADVERB,
ARTICLE...
Exemple: Bob drank coffee at Starbucks
⇒ Bob (NOUN) drank (VERB) coffee (NOUN) at (PREPOSITION) Starbucks
(NOUN).
Named Entity Recognition (NER)
Vincent Guigue TAL – Séquences 5/54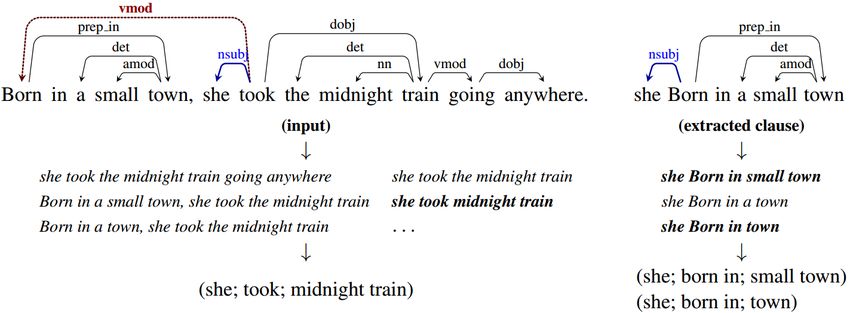
Intro HMM CRF RNN
Applications (suite)
I Temporal tagger : reco + normalisation
I Parsing
crédit : CoreNLP
I Information ExtractionVincent
/ Semantic
Guigue
Role Labeling :
TAL – Séquences 6/54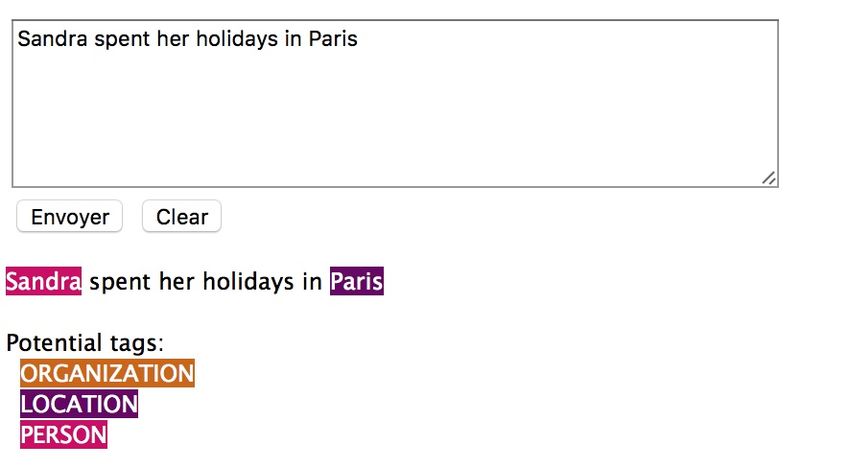
Intro HMM CRF RNN
Applications (suite)
I Temporal tagger : reco + normalisation
I Parsing
I Information Extraction / Semantic Role Labeling :
Crédit: Stanford NLP
I Question answering (QA)
Vincent Guigue TAL – Séquences 6/54Intro HMM CRF RNN
Applications (suite)
I Temporal tagger : reco + normalisation
I Parsing
I Information Extraction / Semantic Role Labeling :
I Question answering (QA)
Who is the daughter of Bill Clinton married to? Entity Relation Class
Paraphrases
Question Legend
married Who daughter Bill Clinton married
dep nsubjpass
dbo:Person dbo:child res:Bill Clinton dbp:spouse
Who daughter
res:The Who dbp:daughter dbp:clinton dbo:partner
prep of
Bill Clinton res:Marriage
(b) Simplified syntactic graph (a) Mapping
Knowledge
base
res:Bill Clinton res:Bill Clinton
Who Bill Clinton
Triplet dbo:child dbo:child
married daughter x x
Triplet dbp:spouse dbo:partner
Implicit entity
dbo:Person:? dbo:Person:?
(c) Syntactico-semantic
(d) Semantic graph GS
Q
graph GSS
Q
Marc Mezvinsky
Answer
Fig. 1. System overview
Vincent Guigue TAL – Séquences 6/54Intro HMM CRF RNN
Applications (suite)
I Traduction automatique
◦ Aligner des mots
◦ Générer une phrase intelligible / vraisemblable
I Historique (en évolution rapide)
◦ traduction de mots
◦ traduction de séquences
◦ traduction de connaissances / signification
Vincent Guigue TAL – Séquences 7/54Intro HMM CRF RNN
Modélisations du texte
Approche classique:
I Sac de mots (bag-of-words, BoW)
+ Avantages BoW
◦ plutôt simple, plutôt léger
◦ rapide (systèmes temps-réel, RI, indexation naturelle...)
◦ nb possibilités d’enrichissement
(POS, codage du contexte, N-gram...)
◦ bien adapté pour la classification de documents
◦ Implémentations existantes efficaces nltk, sklearn
− Inconvénient(s) BoW
◦ perte de la structure des phrases/documents
⇒ Plusieurs tâches difficiles à attaquer
· NER, POS tagging, SRL
· Génération de textes
Vincent Guigue TAL – Séquences 8/54Intro HMM CRF RNN
Mieux gérer les séquences
1 Enrichissement de la description vectorielle
◦ N-grams,
◦ Description du contexte des mots...
◦ Usage type : amélioration des tâches de classification au niveau
document
Vincent Guigue TAL – Séquences 9/54Intro HMM CRF RNN
Mieux gérer les séquences
1 Enrichissement de la description vectorielle
◦ N-grams,
◦ Description du contexte des mots...
◦ Usage type : amélioration des tâches de classification au niveau
document
2 Approche par fenêtre glissante : prendre une décision à l’échelle
intra-documentaire
◦ Taille fixe ⇒ possibilité de description vectorielle
· Classifieur sur une représentation locale du texte
◦ Traitement du signal (AR, ARMA...)
◦ Détection de pattern (frequent itemsets, règles d’association)
Vincent Guigue TAL – Séquences 9/54Intro HMM CRF RNN
Mieux gérer les séquences
1 Enrichissement de la description vectorielle
◦ N-grams,
◦ Description du contexte des mots...
◦ Usage type : amélioration des tâches de classification au niveau
document
2 Approche par fenêtre glissante : prendre une décision à l’échelle
intra-documentaire
◦ Taille fixe ⇒ possibilité de description vectorielle
Les dépendances dans un MMC
· Classifieur sur une représentation locale du texte
◦ Traitement du signal (AR, ARMA...)
◦ Détection de pattern (frequent itemsets, règles d’association)
3 Modèles séquentiels
◦ Hidden Markov Model (=Modèles de Markov Cachés)
UPMC - M1 - MQIA - T. Artières
◦ CRF (Conditional Random Fields) : approche discriminante
8
Vincent Guigue TAL – Séquences 9/54Intro HMM CRF RNN
Historique des approches POS, SRL, NER
I Modélisation par règle d’association 80’s
◦ Quelles sont les cooccurrences fréquentes entre un POS et un item
dans son contexte?
◦ ⇒ Règles
I Modélisation bayésienne
◦ Pour un POS i, modélisation de la distribution du contexte
p(contexte|θi )
◦ Décision en MV: arg maxi p(contexte|θi )
I Extension structurée (Hidden Markov Model) > 1985/90
◦ HMM taggers are fast and achieve precision/recall scores of about
93-95%
I Vers une modélisation discriminante (CRF) > 2001
I Recurrent Neural Network (cf cours ARF, AS) > 2010
Vincent Guigue TAL – Séquences 10/54Intro HMM CRF RNN
TAL / ML : beaucoup de choses en commun
I Des financements liés (et pas toujours glorieux) :
◦ Conférences MUC / TREC (...)
· RI, extraction d’info, classification de doc, sentiments, QA
· Multiples domaines: général, médecine, brevet, judiciaire...
· ⇒ Construction de bases, centralisation des résultats, échanges
◦ NSA,
◦ Boites noires (loi sur le renseignement 2015)
I Avancée ML tirée par le TAL : HMM, CRF
I De nombreux projets ambitieux:
◦ Google Knowledge Graph,
◦ NELL: Never-Ending Language Learning (Tom Mitchell, CMU)
Vincent Guigue TAL – Séquences 11/54Intro HMM CRF RNN
Formalisation séquentielle
Observations : Le chat est dans le salon
Etiquettes : DET NN VBZ ...
Le HMM est pertinent: il est basé sur
I les enchainements d’étiquettes,
I les probabilités d’observation
Vincent Guigue TAL – Séquences 12/54Intro HMM CRF RNN
Notations
I La chaine de Markov est toujours composée de:
◦ d’une séquence d’états S = (s1 , . . . , sT )
◦ dont les valeurs sont tirées dans un ensemble fini Q = (q1 , ..., qN )
◦ Le modèle est toujours défini par {Π, A}
· πi = P(s1 = qi )
· aij = p(st+1 = qj |st = qi )
I Les observations sont modélisées à partir des st
◦ séquence d’observation: X = (x1 , . . . , xT )
◦ loi de probabilité: bj (t) = p(xt |st = qj )
◦ B peut être discrète ou continue
I MMC: λ = {Π, A, B}
Vincent Guigue TAL – Séquences 13/54Intro HMM CRF RNN
Ce que l’on manipule
I Séquence d’observations
◦ X = (x1 , . . . , xT )
I Séquence d’états (cachée = manquante)
◦ S = (s1 , . . . , sT )
Vincent Guigue TAL – Séquences 14/54Intro HMM CRF RNN
Rappels sur la structure d’un MMC
Constitution d’un MMC:
S1 S2 S3 S4 ST
1 ...
2 ...
Etats
...
...
...
...
...
N ...
X1 X2 X3 X4 XT
Observations
I Les états sont inconnus...
Vincent Guigue TAL – Séquences 15/54Intro HMM CRF RNN
Rappels sur la structure d’un MMC
Constitution d’un MMC:
S1 S2 S3 S4 ST
1 ...
2 ...
Etats
Pi
...
...
...
...
...
N ...
X1 X2 X3 X4 XT
Observations
I Les états sont inconnus...
Vincent Guigue TAL – Séquences 15/54Intro HMM CRF RNN
Rappels sur la structure d’un MMC
Constitution d’un MMC:
S1 S2 S3 S4 ST
A
1 ...
2 ...
Etats
Hyp. Ordre 1:
chaque état ne
...
...
...
...
...
dépend que du
précédent
N ...
X1 X2 X3 X4 XT
Observations
I Les états sont inconnus...
La combinatoire à envisager est problématique!
Vincent Guigue TAL – Séquences 15/54Intro HMM CRF RNN
Rappels sur la structure d’un MMC
Constitution d’un MMC:
S1 S2 S3 S4 ST
1 ...
Hyp. Ordre 1:
... chaque état ne
2
Etats
dépend que du
B précédent
...
...
...
...
...
Chaque obs. ne
N ... dépend que de
l’état courant
X1 X2 X3 X4 XT
Observations
I Les états sont inconnus...
Vincent Guigue TAL – Séquences 15/54Intro HMM CRF RNN
Les trois problèmes des MMC (Fergusson - Rabiner)
I Evaluation: λ donné, calcul de p(x1T |λ)
I Décodage: λ donné, quelle séquence d’états a généré les
observations?
s1T ? = arg max p(x1T , s1T |λ)
s1T
I Apprentissage: à partir d’une série d’observations, trouver λ?
λ? = {Π? , A? , B ? } = arg max p(x1T , s1T |λ)
s1T ,λ
Vincent Guigue TAL – Séquences 16/54Intro HMM CRF RNN
PB1: Algorithme forward (prog dynamique)
αt (i) = p(x1t , st = i|λ)
I Initialisation:
S1 S2 S3
αt=1 (i) = p(x11 , s1 = i|λ) = πi bi (x1 ) A
1
I Itération: " #
N
X 2 j
Etats
αt (j) = αt−1 (i)aij bj (xt )
...
...
...
i=1
I Terminaison: N
N
X
p(x1T |λ) = αT (i)
X1 X2 X3
i=1
Observations
I Complexité linéaire en T
◦ Usuellement: T >> N
Vincent Guigue TAL – Séquences 17/54Intro HMM CRF RNN
PB2: Viterbi (récapitulatif)
δt (i) = max
t−1
p(s1t−1 , st = i, x1t |λ)
s1
S1 S2 S3
1 Initialisation A
δ1 (i) = πi bi (x1 ) 1
Ψ1 (i) = 0
2 j
Etats
2 Récursion h i
δt (j) = max δt−1 (i)aij bj (xt )
...
...
...
i
Ψt (j) = arg max δt−1 (i)aij N
i∈[1, N]
3 Terminaison S ? = maxi δT (i)
4 Chemin qT? = arg max δT (i) X1 X2 X3
i
?
qt? = Ψt+1 (qt+1 ) Observations
Vincent Guigue TAL – Séquences 18/54Intro HMM CRF RNN
PB3: Apprentissage des MMC
I Version simplifiée (hard assignment): type k-means
I Nous disposons de :
◦ Evaluation: p(x1T |λ)
◦ Décodage: s1T ? = arg maxs T p(x1T |λ)
1
I Proposition:
Data: Observations : X , Structure= N, K
Result: Π̃? , Ã? , B̃ ?
Initialiser λ0 = Π0 , A0 , B 0 ;
→ finement si possible;
t = 0;
while convergence non atteinte do
St+1 = decodage(X , λt );
λ?t+1 = Πt+1 , At+1 , B t+1 obtenus par comptage des transitions ;
t = t + 1;
end
Algorithm 1: Baum-Welch simplifié pour l’apprentissage d’un MMC
Vous avez déjà tous les éléments pour faire ça!
Vincent Guigue TAL – Séquences 19/54Intro HMM CRF RNN
Apprentissage en contexte supervisé
Observations : Le chat est dans le salon
Etiquettes : DET NN VBZ ...
I Beaucoup plus simple (après la couteuse tâche d’étiquetage) :
I Matrices A, B, Π obtenues par comptage...
I Inférence = viterbi
Philosophie & limites:
Trouver l’étiquetage qui maximise la vraisemblance de la séquence
états–observations...
... sous les hypothèses des HMM – indépendance des
observations étant donnés les états, ordre 1 –
Vincent Guigue TAL – Séquences 20/54Intro HMM CRF RNN
Intro
HMM
CRF
RNN
Vincent Guigue TAL – Séquences 21/54Intro HMM CRF RNN
Modélisation discriminante vs générative
I Modélisation bayesienne = modèle génératif
◦ Pour un POS i, modélisation de la distribution du contexte
p(contexte|θi )
◦ Décision en MV: arg maxi p(contexte|θi )
◦ Génératif car on peut générer des contextes (même si ça n’a pas de
sens dans cette application)
◦ Très apprécié en TAL depuis les approches Naive Bayes (directement
calculable en BD)
Vincent Guigue TAL – Séquences 22/54Intro HMM CRF RNN
Modélisation discriminante vs générative
I Modélisation bayesienne = modèle génératif
◦ Pour un POS i, modélisation de la distribution du contexte
p(contexte|θi )
◦ Décision en MV: arg maxi p(contexte|θi )
◦ Génératif car on peut générer des contextes (même si ça n’a pas de
sens dans cette application)
◦ Très apprécié en TAL depuis les approches Naive Bayes (directement
calculable en BD)
◦ Bayesien + Séquence = HMM
Vincent Guigue TAL – Séquences 22/54Intro HMM CRF RNN
Modélisation discriminante vs générative
I Modélisation bayesienne = modèle génératif
◦ Pour un POS i, modélisation de la distribution du contexte
p(contexte|θi )
◦ Décision en MV: arg maxi p(contexte|θi )
◦ Génératif car on peut générer des contextes (même si ça n’a pas de
sens dans cette application)
◦ Très apprécié en TAL depuis les approches Naive Bayes (directement
calculable en BD)
◦ Bayesien + Séquence = HMM
I Modélisation discriminante
◦ Qu’est ce que distingue une classe d’une autre classe?
◦ p(yi |contexte): regression logistique
◦ proba ⇒ scoring: fonction linéaire, minimisation d’un coût...
Vincent Guigue TAL – Séquences 22/54Intro HMM CRF RNN
Modélisation discriminante vs générative
I Modélisation bayesienne = modèle génératif
◦ Pour un POS i, modélisation de la distribution du contexte
p(contexte|θi )
◦ Décision en MV: arg maxi p(contexte|θi )
◦ Génératif car on peut générer des contextes (même si ça n’a pas de
sens dans cette application)
◦ Très apprécié en TAL depuis les approches Naive Bayes (directement
calculable en BD)
◦ Bayesien + Séquence = HMM
I Modélisation discriminante
◦ Qu’est ce que distingue une classe d’une autre classe?
◦ p(yi |contexte): regression logistique
◦ proba ⇒ scoring: fonction linéaire, minimisation d’un coût...
◦ Discriminant + séquence = CRF
Vincent Guigue TAL – Séquences 22/54Intro HMM CRF RNN
Retour sur la regression logistique
Le problème de reconnaissance des chiffres (USPS)
Vincent Guigue TAL – Séquences 23/54Intro HMM CRF RNN
Retour sur la regression logistique
Le problème de reconnaissance des chiffres (USPS)
1 Approche bayesienne générative :
◦ modélisation de chaque classe (e.g. en gaussiennes (µ, σ))
Modélisation (µ, σ)de la classe 0 par MV = trouver ce qui
caractérise un 0
◦ critère de décision MV :
y ? = arg max p(x|y )
y
Quel modèle ressemble le plus à x?
Vincent Guigue TAL – Séquences 23/54Intro HMM CRF RNN
Retour sur la regression logistique
Le problème de reconnaissance des chiffres (USPS)
1 Approche bayesienne générative :
◦ modélisation de chaque classe (e.g. en gaussiennes (µ, σ))
◦ critère de décision MV :
y ? = arg max p(x|y )
y
Quel modèle ressemble le plus à x?
2 Approche discriminante: modéliser directement p(y |x)
◦ Construction d’un modèle minimisant les a priori:
1
p(Y = 1|x) =
1 + exp(−(xθ + θ0 ))
Qu’est ce qui distingue un 0 des autres chiffres?
Vincent Guigue TAL – Séquences 23/54Intro HMM CRF RNN
RegLog (2)
Processus bi-classe:
1
1 p(Y = 1|x) = 1+exp(−(xθ+θ0 ))
2 p(y|x) = P(Y = 1|x) × [1 − P(Y = 1|x)]1−y , y ∈ {0, 1}
y
(Bernoulli)
PN
3 (log) Vraisemblance : L = i=1 log P(xi , yi )
4 Optimisation :
∂
Llog = N 1
P
◦ gradient : ∂θ j i=1 xij (yi − 1+exp(xθ+θ0 ) )
◦ ... résolution analytique impossible...
∂
◦ montée de gradient θj ← θj + ε ∂θ j
Llog ou BFGS
I Extension un-contre-tous
Vincent Guigue TAL – Séquences 24/54Intro HMM CRF RNN
1.2
HMMGraphical
⇒ CRF Models
Introduction to CRF, Sutton & McCallum
SEQUENCE Ge
Naive Bayes HMMs G
CONDITIONAL CONDITIONAL
SEQUENCE Ge
Logistic Regression Linear-chain CRFs G
Vincent Guigue TAL – Séquences 25/54Intro HMM CRF RNN
Modélisation CRF
I Séquence de mots x = {x1 , . . . , xT }
I Sequence d’étiquettes y (=POS tag)
Estimation paramétrique des probabilités basées sur la famille
exponentielle:
1 Y
p(y, x) = Ψt (yt , yt−1 , xt ),
Z t
P
Ψt (yt , yt−1 , xt ) = exp ( k θk fk (yt , yt−1 , xt ))
I Dépendances de Ψt ⇒ forme du modèle HMM
I θk : paramètres à estimer (cf regression logistique)
I fk (yt , yt−1 , xt ) : expression générique des caractéristiques
(détails plus loin)
Vincent Guigue TAL – Séquences 26/54Intro HMM CRF RNN
CRF = généralisation des HMM
Cas général (slide précédent): !
1 Y X
p(y, x) = exp θk fk (yt , yt−1 , xt )
Z t
k
Cas particulier :fk =existence de (yt , yt−1 ) ou (yt , xt )
1 Y X X
p(y, x) = exp θi,j 1yt =i&yt−1 =j + µo,i 1yt =i&xt =o
Z t
i,j∈S i∈S,o∈O
Avec :
I θi,j = log p(yt = i|yt−1 = j)
I µo,i = log p(x = o|yt = i)
I Z =1
⇒ Dans ce cas, les caractéristiques sont binaires (1/0)
Vincent Guigue TAL – Séquences 27/54Intro HMM CRF RNN
CRF : passage aux probas conditionnelles
!
1 Y X
p(y, x) = exp θk fk (yt , yt−1 , xt )
Z t
k
⇒ Q P
t exp ( k θk fk (yt , yt−1 , xt ))
p(y|x) = P Q P 0 0
y0 t exp k θk fk (yt , yt−1 , xt )
!
1 Y X
= exp θk fk (yt , yt−1 , xt )
Z (x) t
k
Vincent Guigue TAL – Séquences 28/54Intro HMM CRF RNN
Apprentissage CRF
!
1 Y X
p(y|x) = exp θk fk (yt , yt−1 , xt )
Z (x) t
k
Comme pour
X la regression logistique:
Lcond = log p(yn |xn ) =
n XXX X
θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))
n t k n
Comment optimiser?
Vincent Guigue TAL – Séquences 29/54Intro HMM CRF RNN
Apprentissage CRF
!
1 Y X
p(y|x) = exp θk fk (yt , yt−1 , xt )
Z (x) t
k
Comme pour
X la regression logistique:
Lcond = log p(yn |xn ) =
n XXX X
θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))
n t k n
Comment optimiser?
∂L
Montée de gradient ∂θ
X k X X
θk ← θk + fk (xn , ytn , yt−1
n
)− fk (xn , yt0 , yt−1
0
)p(yt0 , yt−1
0
|xn )
n,t n,t yt0 ,yt−1
0
2
Calcul exact possible O(TM N), solutions approchées plus rapides
I M : nb labels, T : lg chaine, N : nb chaines
Vincent Guigue TAL – Séquences 29/54Intro HMM CRF RNN
Apprentissage CRF
!
1 Y X
p(y|x) = exp θk fk (yt , yt−1 , xt )
Z (x) t
k
Comme pour
X la regression logistique:
Lcond = log p(yn |xn ) =
n XXX X
θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))
n t k n
Comment optimiser?
I La difficulté réside essentiellement dans le facteur de normalisation
Vincent Guigue TAL – Séquences 29/54Intro HMM CRF RNN
Régularisation
I Que pensez-vous de la complexité du modèle?
I Comment la limiter?
X X
Lcond = θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))
n,k,t n
⇒
X X 1
Lcond = θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))+ kθk2
n
2σ 2
n,k,t
X X X
Lcond = θk fk (xn , ytn , yt−1
n
)− log(Z (xn ))+α |θk |
n,k,t n k
Vincent Guigue TAL – Séquences 30/54Intro HMM CRF RNN
Et les fj alors???
( T
)
1 XX
p(y|x) = exp θk fk (x, yt , yt−1 )
Z (x) t=1 k
I Par défaut, les fk sont des features et ne sont pas apprises
I Exemples:
◦ f1 (x, yt , yt−1 ) = 1 if yt = ADVERB and the word ends in ”-ly”; 0
otherwise.
· If the weight θ1 associated with this feature is large and positive,
then this feature is essentially saying that we prefer labelings where
words ending in -ly get labeled as ADVERB.
◦ f2 (x, yt , yt−1 ) = 1 si t=1, yt = VERB, and the sentence ends in a
question mark; 0 otherwise.
◦ f3 (x, yt , yt−1 ) = 1 if yt−1 = ADJECTIVE and yt = NOUN; 0
otherwise.
I Il est possible d’apprendre des features sur des données
Vincent Guigue TAL – Séquences 31/54Intro HMM CRF RNN
Et les fj alors???
( T
)
1 XX
p(y|x) = exp θk fk (x, yt , yt−1 )
Z (x) t=1 k
I Par défaut, les fk sont des features et ne sont pas apprises
I Exemples:
◦ f1 (x, yt , yt−1 ) = 1 if yt = ADVERB and the word ends in ”-ly”; 0
otherwise.
◦ f2 (x, yt , yt−1 ) = 1 si t=1, yt = VERB, and the sentence ends in a
question mark; 0 otherwise.
· Again, if the weight θ2 associated with this feature is large and
positive, then labelings that assign VERB to the first word in a
question (e.g., Is this a sentence beginning with a verb??) are
preferred.
◦ f3 (x, yt , yt−1 ) = 1 if yt−1 = ADJECTIVE and yt = NOUN; 0
otherwise.
I Il est possible d’apprendre des features sur des données
Vincent Guigue TAL – Séquences 31/54Intro HMM CRF RNN
Et les fj alors???
( T
)
1 XX
p(y|x) = exp θk fk (x, yt , yt−1 )
Z (x) t=1 k
I Par défaut, les fk sont des features et ne sont pas apprises
I Exemples:
◦ f1 (x, yt , yt−1 ) = 1 if yt = ADVERB and the word ends in ”-ly”; 0
otherwise.
◦ f2 (x, yt , yt−1 ) = 1 si t=1, yt = VERB, and the sentence ends in a
question mark; 0 otherwise.
◦ f3 (x, yt , yt−1 ) = 1 if yt−1 = ADJECTIVE and yt = NOUN; 0
otherwise.
· Again, a positive weight for this feature means that adjectives tend
to be followed by nouns.
I Il est possible d’apprendre des features sur des données
Vincent Guigue TAL – Séquences 31/54Intro HMM CRF RNN
Feature engineering
I Label-observation features : les fk qui s’expriment
fk (x, yt ) = 1yt =c qk (x) sont plus facile à calculer (ils sont calculés
une fois pour toutes)
◦ e.g. : si x = moti , x termine par -ing, x a une majuscule... alors 1
sinon 0
I Node-obs feature : même si c’est moins précis, essayer de ne pas
mélanger les références sur les observations et sur les transitions.
◦ fk (x, yt , yt−1 ) = qk (x)1yt =c 1yt−1 =c 0 ⇒
fk (xt , yt ) = qk (x)1yt =c , & fk+1 (yt , yt−1 ) = 1yt =c 1yt−1 =c 0
I Boundary labels
Vincent Guigue TAL – Séquences 32/54Intro HMM CRF RNN
Feature engineering (2)
I Unsupported features : générée automatiquement à partir des
observations (e.g. with n’est pas un nom de ville)... Mais pas très
pertinente.
◦ Utiliser ces features pour désambiguiser les erreurs dans la base
d’apprentissage
I Feature induction
I Features from different time steps
I Redundant features
I Complexe features = model ouputs
Vincent Guigue TAL – Séquences 33/54Intro HMM CRF RNN
Inférence
Processus:
1 Définir des caractéristiques,
2 Apprendre les paramètres du modèles (θ)
3 Classer les nouvelles phrases (=inférence)
y? = arg max p(y|x)
y
⇒ Solution très proche de l’algorithme de Viterbi
Vincent Guigue TAL – Séquences 34/54Intro HMM CRF RNN
Inférence (2)
1 Y
p(y|x) = Ψt (yt , yt−1 , xt ),
Z (x) t
!
X
Ψt (yt , yt−1 , xt ) = exp θk fk (yt , yt−1 , xt )
k
1 Passerelle avec les HMM:
Ψt (i, j, x) = p(yt = j|yt−1 = i)p(xt = x|yt = j)
X X
αt (j) = Ψt (i, j, x)αt−1 (i), βt (i) = Ψt (i, j, x)βt+1 (j)
i j
δt (j) = max Ψt (i, j, x)δt−1 (i)
i
Vincent Guigue TAL – Séquences 35/54Intro HMM CRF RNN
Inférence (2)
1 Y
p(y|x) = Ψt (yt , yt−1 , xt ),
Z (x) t
!
X
Ψt (yt , yt−1 , xt ) = exp θk fk (yt , yt−1 , xt )
k
1 Passerelle avec les HMM:
Ψt (i, j, x) = p(yt = j|yt−1 = i)p(xt = x|yt = j)
X X
αt (j) = Ψt (i, j, x)αt−1 (i), βt (i) = Ψt (i, j, x)βt+1 (j)
i j
δt (j) = max Ψt (i, j, x)δt−1 (i)
i
2 Les définitions restent valables avec les CRF (cf Sutton, McCallum),
avec:
X
Z (x) = αT (i) = β0 (y0 )
i
Vincent Guigue TAL – Séquences 35/54Intro HMM CRF RNN
Applications
I Analyse des phrases: analyse morpho-syntaxique
I NER: named entity recognition
... Mister George W. Bush arrived in Rome together with ...
... O name name name O O city O O ...
I Passage en 2D... Analyse des images
Vincent Guigue TAL – Séquences 36/54Intro HMM CRF RNN
Applications
I Analyse des phrases: analyse morpho-syntaxique
I NER: named entity recognition
... Mister George W. Bush arrived in Rome together with ...
... O name name name O O city O O ...
I Passage en 2D... Analyse des images
◦ Détection des contours
◦ Classification d’objets
features =
◦ cohésion de l’espace
◦ enchainements usuels/impossibles
crédit: DGM lib
Vincent Guigue TAL – Séquences 36/54Intro HMM CRF RNN
Intro
HMM
CRF
RNN
Vincent Guigue TAL – Séquences 37/54Intro HMM CRF RNN
Réseaux de neurones
Architecture non linéaire pour la classification ou la régression
Vincent Guigue TAL – Séquences 38/54Intro HMM CRF RNN
Réseaux de neurones
I Codage BoW, application en classification...
I Variante avec auto-encodeurs
Vincent Guigue TAL – Séquences 39/54Intro HMM CRF RNN
Réseaux de neurones récurrents
t t+1 Temps
Un réseau pour suivre le texte: y y
I Apprentissage de dépendances
h h
longues...
I Différentes architectures pour
A A
différentes applications
x x
Vincent Guigue TAL – Séquences 40/54Intro HMM CRF RNN
RNN génératifs
Encodeur Décodeur
z Prédiction de : v e $
Alignement avec les
représentations Word2Vec Représentation 0
0.1
latente du mot 0.
0.
0.4
B 0
0
h h h h h h A A A A A ... A
unité unité
GRU GRU
A A A A A ... A z z z z z
Concaténation
des + + + + +
0 0 0 0 1
représentations 1 0 0 1
0 0 1 0 0 0 1 0 0
1-hot 0
0
0
0
0
0
1
0
0
0
0
0
0
0
1
0
0
0
encoding 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0
^ v e n d eur$$ ^ v e n d eur$$
Vincent Guigue TAL – Séquences 41/54Intro HMM CRF RNN
Karpathy’s blog
Exemples de générations (Shakespeare)
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain’d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
Vincent Guigue TAL – Séquences 42/54Intro HMM CRF RNN
Karpathy’s blog
Exemples de générations (wikipedia)
Naturalism and decision for the majority of Arab countries’ cap
by the Irish language by [[John Clair]], [[An Imperial Japanese
with Guangzham’s sovereignty. His generals were the powerful rul
in the [[Protestant Immineners]], which could be said to be dire
Communication, which followed a ceremony and set inspired prison
emperor travelled back to [[Antioch, Perth, October 25|21]] to n
of Costa Rica, unsuccessful fashioned the [[Thrales]]
Vincent Guigue TAL – Séquences 43/54Intro HMM CRF RNN
Karpathy’s blog
Exemples de générations (wikipedia)
Vincent Guigue TAL – Séquences 44/54Intro HMM CRF RNN
Karpathy’s blog
Exemples de générations (linux code)
*
* Increment the size file of the new incorrect UI_FILTER group
* of the size generatively.
*/
static int indicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
Vincent Guigue TAL – Séquences 45/54Intro HMM CRF RNN
Approches par RNN
Karpathy ⇒ Générer du texte = Utiliser des RNN
t t+1 Temps
Neurones exotiques / gestion de la
y y mémoire:
I GRU
h h I LSTM
http://colah.github.io/posts/2015- 08- Understanding- LSTMs/
A A
Inférence beam search: maximiser la
probabilité de la séquence.
x x
Andrej Karpathy blog, 2015
The Unreasonable Effectiveness of Recurrent Neural Networks
Lipton, Vikram, McAuley, arXiv, 2016
Generative Concatenative Nets Jointly Learn to Write and Classify Reviews
Vincent Guigue TAL – Séquences 46/54Intro HMM CRF RNN
Approches par RNN
Andrej Karpathy blog, 2015
The Unreasonable Effectiveness of Recurrent Neural Networks
Lipton, Vikram, McAuley, arXiv, 2016
Generative Concatenative Nets Jointly Learn to Write and Classify Reviews
Vincent Guigue TAL – Séquences 46/54Intro HMM CRF RNN
3.3 Weight Tra
Models with eve
RNN & modélisation du contexte
(b) tations are consi
supervised chara
first train a charac
plant these weigh
izing the extra we
hidden layer) to
atic here because
broken. Thus we
strictly lower los
(c) repeated training
the pre-training
Figure 3: (a) Standard generative RNN; (b) encoder-
nity (Yosinski et
I decoderinput
Concatenation: RNN; +
(c) concatenated input RNN.
weights, we train
contexte
3.2 Generative Concatenative RNNs
I Inférence = test (combinatoire) 3.4 Running th
des contextes + max
Our goal de
is to generate text in a supervised fashion, condi-
vraisemblance
tioned on an auxiliary input xaux . This has been done at Many common d
the word-level with encoder-decoder models (Figure 3b), in
Démo: http://deepx.ucsd.edu/ logistic regressio
which the auxiliary input is encoded and passed as the ini- ing labels given
Lipton, Vikram, McAuley, arXiv, 2016
tial state
Gen. Concatenative toJointly
Nets a decoder,
Learn which
to then must preserve this input we can produce
signalReviews
Write and Classify across many sequence steps (Sutskever et al., 2014; ference, that is,
Karpathy and Fei-Fei, 2014). Such models have success- given a classific
fully produced (short) image captions,
Vincent Guigue but seem impracti-
TAL – Séquences two tasks (P 47/54
(xauIntro HMM CRF RNN
3.3 Weight Tra
Models with eve
RNN & modélisation du contexte
(b) tations are consi
supervised chara
first train a charac
plant these weigh
izing the extra we
hidden layer) to
atic here because
broken. Thus we
strictly lower los
(c) repeated training
the pre-training
Figure 3: (a) Standard generative RNN; (b) encoder-
nity (Yosinski et
I decoderinput
Concatenation: RNN; +
(c) concatenated input RNN.
weights, we train
contexte
3.2 Generative Concatenative RNNs
I Inférence = test (combinatoire) 3.4 Running th
des contextes + max
Our goal de
is to generate text in a supervised fashion, condi-
vraisemblance
tioned on an auxiliary input xaux . This has been done at Many common d
the word-level with encoder-decoder models (Figure 3b), in
Démo: http://deepx.ucsd.edu/ logistic regressio
which the auxiliary input is encoded and passed as the ini- ing labels given
Lipton, Vikram, McAuley, arXiv, 2016
tial state
Gen. Concatenative toJointly
Nets a decoder,
Learn which
to then must preserve this input we can produce
signalReviews
Write and Classify across many sequence steps (Sutskever et al., 2014; ference, that is,
Karpathy and Fei-Fei, 2014). Such models have success- given a classific
fully produced (short) Figure
image
Vincent Guigue 5: – Most
captions,
TAL butlikely
Séquences seem star rating
impracti- as two
eachtasks (P is
letter (xenau
47/54Intro HMM CRF RNN
3.3 Weight Tra
Models with eve
RNN & modélisation du contexte
(b) tations are consi
supervised chara
first train a charac
plant these weigh
izing the extra we
hidden layer) to
atic here because
broken. Thus we
strictly lower los
(c) repeated training
Test Set Perplexity the pre-training
Figure 3: (a) Standard generative RNN; (b) encoder-
Mean Median nity (Yosinski et
decoder
Concatenation:
I RNN; +
input (c) concatenated input RNN.
anguage Model 4.23 2.22 weights, we train
contexte
2.94 2.07
3.2 Generative Concatenative RNNs
I Inférence = test 2.17
4.48 (combinatoire) 3.4 Running th
des contextes
2.26
Our + max
2.03
goal de
is to generate text in a supervised fashion, condi-
tioned on
2.25
vraisemblance an auxiliary input xaux . This has been done at
1.98 Many common d
the word-level with encoder-decoder models (Figure 3b), in
Démo: http://deepx.ucsd.edu/ logistic regressio
which the auxiliary input is encoded and passed as the ini- ing labels given
on test setLipton,
data for unsupervised
Vikram, McAuley, RNN2016
arXiv,
tial state toJointly Learn which
a decoder, then must preserve this input we can produce
well as GCNs with rating,
Gen. Concatenative category,
Nets to
signal
Write and Classify across
Reviews many sequence steps (Sutskever et al., 2014; ference, that is,
item info. given a classific
Karpathy and Fei-Fei, 2014). Such models have success-
fully produced (short) image captions,
Vincent Guigue but seem impracti-
TAL – Séquences two tasks (P 47/54
(xauTest Set Perplexity
Intro HMM CRF RNN
3.3 Weight Tra
Mean Median Models with eve
RNN
Language Model& modélisation
4.23 2.22 du contexte
(b) tations are consi
2.94 2.07 supervised chara
4.48 2.17 first train a charac
2.26 2.03 plant these weigh
2.25 1.98 izing the extra we
hidden layer) to
on test set data for unsupervised RNN atic here because
well as GCNs with rating, category, broken. Thus we
item info. strictly lower los
(c) repeated training
the pre-training
Figure 3: (a) Standard generative RNN; (b) encoder-
Concatenation: nity (Yosinski et
decoderinput
RNN; +
I
(c) concatenated input RNN.
mation conferred little additional power
contexte weights, we train
w. In fact, item information
I Inférence 3.2
= test ID provedConcatenative RNNs
Generative
(combinatoire)
ing information for explaining the con- 3.4 Running th
des contextes + max de
his struck us as surprising,
Our goal because in-
is to generate text in a supervised fashion, condi-
vraisemblance Many common d
gives a decent indicationtionedofonthe an rating
auxiliary input xaux . This has been done at
Démo: http://deepx.ucsd.edu/ logistic regressio
he beer category. It alsothe suggests
word-level which
with encoder-decoder models (Figure 3b), in
kely to occur in the
Lipton, review.
which
Vikram, In contrast,
the
McAuley, auxiliary input is encoded and passed as the ini-
arXiv, 2016 ing labels given
Gen. Concatenative Nets Jointly Learn to
user information tial state to a decoder,
diffi- which then must preserve this input we can produce
Write andwould
Classifybe more
Reviews
surprised that our modelsignalcould
across many sequence steps (Sutskever et al., 2014;
capture ference, that is,
Karpathy andnearly
Fei-Fei, 2014). Such models have success- given a classific
erns extremely accurately. For
fully produced (short) image captions,
Vincent Guigue but seem impracti-
TAL – Séquences two tasks (P 47/54
(xauIntro HMM CRF RNN
3.3 Weight Tra
RNN & modélisation du contexte Models with eve
(b) tations are consi
supervised chara
first train a charac
plant these weigh
izing the extra we
hidden layer) to
atic here because
broken. Thus we
strictly lower los
(c) repeated training
Concatenation: the pre-training
Figure input
3: (a)+Standard generative RNN; (b) encoder-
I
contexte decoder RNN; (c) concatenated input RNN. nity (Yosinski et
Perspective: weights, we train
I Inférence = test (combinatoire)
I Authorship
des contextes3.2 Generative
+ max de Concatenative RNNs
3.4 Running th
I ⇒ Réduire la combinatoire...
vraisemblance
Our goal is to generate text in a supervised fashion, condi-
Démo: http://deepx.ucsd.edu/ I ... Ou traiter des contextes
Many common d
tioned on an auxiliary input xaux . This has been done at
the McAuley,
Lipton, Vikram, word-level with
arXiv, continus
encoder-decoder models
2016 (Figure 3b), in logistic regressio
which Nets
Gen. Concatenative the auxiliary input
Jointly Learn is encoded and passed as the ini-
to ing labels given
Write and Classify Reviews
tial state to a decoder, which then must preserve this input we can produce
signal across many sequence steps (Sutskever et al., 2014; ference, that is,
Vincent Guigue TAL – Séquences given a classific
47/54Intro HMM CRF RNN
Apprentissage de représentations:
1 objet brut ⇒ 1 représentation vectorielle dont les variables latentes
correspondent à des concepts de haut niveau
Vision 1990-2000 : extraction de caractéristiques / thématiques
Vincent Guigue TAL – Séquences 48/54Intro HMM CRF RNN
Apprentissage de représentations:
1 objet brut ⇒ 1 représentation vectorielle dont les variables latentes
correspondent à des concepts de haut niveau
Vision 2000-2010 : apprentissage de profils (utilisateurs)
Produit
Factorisation matricielle Bibliothèque
/ compression
d’information
nt ur
te te
La crip
s
De
Compression d’une
matrice de notes
I Completion :
qui aime quoi ? Individu
I Explication : Score d’affinité
qui possède quel facteur?
I Communautés
Population
Vincent Guigue TAL – Séquences 48/54Intro HMM CRF RNN
Apprentissage de représentations:
1 objet brut ⇒ 1 représentation vectorielle dont les variables latentes
correspondent à des concepts de haut niveau
Vision 2010- : apprentissage de profils généralisés
Traitement de données hétérogènes
Unified vector space:
1 Initialisation aléatoire
User 2 Intégration de nombreuses contraintes
Words
Inférences entre tous les concepts
Item
Rating + sentences, documents...
e.g. bière :
Vincent Guigue TAL – Séquences 48/54Intro HMM CRF RNN
Les enjeux de l’apprentissage de représentations
Apprendre une représentation numérique pour les mots, les phrases, les
documents...
I Encoder une signification / une connaissance sur un point de l’espace
◦ Nouvelle manière de penser l’extraction d’information
◦ Nouvelle approche de la traduction automatique
· Supervision plus légère / plus de ressources disponibles
· Traductions plus intelligibles
⇒ Les tâches de POS-tagging / SRL ont-elles encore une utilité?
I Systèmes end-to-end
◦ chatbot
Vincent Guigue TAL – Séquences 49/54Intro HMM CRF RNN
Nouvelles propriétés des espaces de mots : Word2Vec
a est à b ce que c est à ??? ⇔ zb − za + zc
Propriété syntaxique (1):
Requête:
zwoman − zman ≈ zqueen − zking zwoman − zman + zking = zreq
zkings − zking ≈ zqueens − zkings Plus proche voisin:
arg mini kzreq − zi k = queen
⇒ Mise en place d’un test quantitatif de référence.
Vincent Guigue TAL – Séquences 50/54Intro HMM CRF RNN
Nouvelles propriétés des espaces de mots : Word2Vec
a est à b ce que c est à ??? ⇔ zb − za + zc
Propriété syntaxique (2):
Requête:
zeasy − zeasiest + zluckiest = zreq
Plus proche voisin:
arg mini kzreq − zi k = lucky
Vincent Guigue TAL – Séquences 50/54Intro HMM CRF RNN
Nouvelles propriétés des espaces de mots : Word2Vec
a est à b ce que c est à ??? ⇔ zb − za + zc
Propriété sémantique (1)
Vincent Guigue TAL – Séquences 50/54Intro HMM CRF RNN
Nouvelles propriétés des espaces de mots : Word2Vec
NEG-15 with 10−5 subsampling HS with 10−5 subsampling
Vasco de Gama Lingsugur Italian explorer
a est àLake
b ce que c
Baikal Great⇔
est à ??? RiftzbValley
− za + zc Aral Sea
Alan Bean Rebbeca Naomi moonwalker
Ionian Sea Ruegen Ionian Islands
chess master chess grandmaster Garry Kasparov
Propriété sémantique (2)
Table 4: Examples of the closest entities to the given short phrases, using two different models.
Czech + currency Vietnam + capital German + airlines Russian + river French + actress
koruna Hanoi airline Lufthansa Moscow Juliette Binoche
Check crown Ho Chi Minh City carrier Lufthansa Volga River Vanessa Paradis
Polish zolty Viet Nam flag carrier Lufthansa upriver Charlotte Gainsbourg
CTK Vietnamese Lufthansa Russia Cecile De
Table 5: Vector compositionality using element-wise addition. Four closest tokens to the sum of two
vectors are shown, using the best Skip-gram model.
To maximize the accuracy on the phrase analogy task, we increased the amount of the training data
by using a dataset with about 33 billion words. We used the hierarchical softmax, dimensionality
of 1000, and the entire sentence for the context. This resulted in a model that reached an accuracy
Vincent Guigue TAL – Séquences 50/54Overview
Intro HMM CRF RNN
•Raisonnement automatique
Each relation is described by a neural network and pairs of entities are giv
input to the model. Each entity has a vector representation, which can be
< 2008
structed by itslogiques
I Systèmes word vectors.
(prolog)
Application
• TheI model de règles
returns a high score if they are in that relationship and a low
I Analyse morpho-syntaxique des phrases
otherwise. This allows any fact, whether implicitly or explicitly mentioned
I Classifieurs locaux & caractéristiques manuelles
database to be answered with a certainty score.
> 2008
Knowledge Base Word Vector Space Reasoning about Relations
tail
Relation: has part
Confidence for Triplet
cat tail eye
dog leg leg
…. …. cat
dog Neural
Relation: type of
Tensor
tiger cat tiger R Network
leg limb
…. ….
e1 e2
India
Relation: instance of
Bengal
tiger ( Bengal tiger, has part, tail)
Bengal tiger
…. … Does a Bengal tiger have a tail?
Vincent Guigue TAL – Séquences 51/54Intro HMM CRF RNN
Traduction automatique
Ancien paradigme Paradigme RNN
Under review as a conference paper at ICLR 2018
De moins en moins de ressources requises:
Figure 1: Toy illustration of the method. (A) There are two distributions of word embeddings, English words
in red denoted by X and Italian words in blue denoted by Y , which we want to align/translate. Each dot
represents a word in that space. The size of the dot is proportional to the frequency of the words in the training
corpus of that language. (B) Using adversarial learning, we learn a rotation matrix W which roughly aligns the
two distributions. The green stars are randomly selected words that are fed to the discriminator to determine
whether the two word embeddings come from the same distribution. (C) The mapping W is further refined via
Procrustes. This method uses frequent words aligned by the previous step as anchor points, and minimizes an
energy function that corresponds to a spring system between anchor points. The refined mapping is then used
to map all words in the dictionary. Vincent Guigue
(D) Finally, we translateTAL – Séquences
by using the mapping W and a distance metric, 52/54Intro HMM CRF RNN
Vision & texte : description image
Couplage de la détection d’objet et de la
génération de texte
Microsoft
Vincent Guigue TAL – Séquences 53/54Intro HMM CRF RNN
Accès à l’information :
des moteurs de recherche aux chatbots
Système d’accès à l’information personnalisé avec 2 particularités:
Dynamique Le profil de l’utilisateur évolue au fil du dialogue
Dialog State Tracking
End to end Requête = langage naturel, Réponse = langage naturel
Base de connaissances
Représentation d’un
utilisateur
U: Question 1 : kqsjdhflqjkfllkfdg
Représentation d’une
question Encodeur
CB: Réponse 1: qlksjdhflqkjsdlf
Représentation d’une
réponse
Décodeur
Nouvelle représentation
utilisateur
Vincent Guigue TAL – Séquences 54/54Vous pouvez aussi lire

















































