Ce que peut faire votre à - Framablog
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Ce que peut faire votre Fournisseur d’Accès à l’Internet Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part. L’actualité de M. Bortzmeyer est son ouvrage à paraître intitulé Cyberstructure, L’Internet : un espace politique. Vous pouvez en lire un extrait et le commander en souscription jusqu’au 10 décembre, où vous pourrez rencontrer l’auteur à la librairie À Livr’ouvert. Introduction Photo par Ophelia Noor, CC BY-SA 2.0,

Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ? Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée. Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI. La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.

Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à
l’Internet), il faut se rappeler de quelques propriétés
essentielles du monde numérique :
Modifier des données numériques ne laisse aucune trace.
Contrairement à un message physique, dont l’altération,
même faite avec soin, laisse toujours une trace, les
messages envoyés sur l’Internet peuvent être changés
sans que ce changement ne se voit.
Copier des données numériques, par exemple à des fins de
surveillance des communications, ne change pas ces
données, et est indécelable. Elle est très lointaine,
l’époque où (en tout cas dans les films policiers), on
détectait une écoute à un « clic » entendu dans la
communication ! Les promesses du genre « nous
n’enregistrons pas vos données » sont donc impossibles à
vérifier.
Modifier les données ou bien les copier est très bon
marché, avec les matériels et logiciels modernes. Le FAI
qui voudrait le faire n’a même pas besoin de compétences
pointues : les fournisseurs de matériel et de logiciel
pour FAI ont travaillé pour lui et leur catalogue est
rempli de solutions permettant modification et écoute
des données, solutions qui ne sont jamais accompagnées
d’avertissements légaux ou éthiques.
Une publicité pour un logiciel d’interception des
communications, même chiffrées. Aucun avertissement légal ou
éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des
données numériques. On a vu qu’elle était non seulement
faisable, mais en outre facile. Citons quelques exemples où
l’internaute ne recevait pas les données qui avaient été
réellement envoyées, mais une version modifiée :
de 2011 à 2013 (et peut-être davantage), en France, le
FAI SFR modifiait les images envoyées via son réseau,
pour en diminuer la taille. Une image perdait donc ainsi
en qualité. Si la motivation (diminuer le débit) était
compréhensible, le fait que les utilisateurs n’étaient
pas informés indique bien que SFR était conscient du
caractère répréhensible de cette pratique.
en 2018 (et peut-être avant), Orange Tunisie modifiait
les pages Web pour y insérer des publicités. La
modification avait un intérêt financier évident pour le
FAI, et aucun intérêt pour l’utilisateur. On lit parfois
que la publicité sur les pages Web est une conséquence
inévitable de la gratuité de l’accès à cette page mais,
ici, bien qu’il soit client payant, l’utilisateur voit
des publicités qui ne rapportent qu’au FAI. Comme
d’habitude, l’utilisateur n’avait pas été notifié, et le
responsable du compte Twitter d’Orange, sans aller
jusqu’à nier la modification (qui est interdite par la
loi tunisienne), la présentait comme un simple problème
technique.
en 2015 (et peut-être avant), Verizon Afrique du Sud
modifiait les échanges effectués entre le téléphone et
un site Web pour ajouter aux demandes du téléphone des
informations comme l’IMEI (un identificateur unique du
téléphone) ou bien le numéro de téléphone de
l’utilisateur. Cela donnait aux gérants des sites Web
des informations que l’utilisateur n’aurait pas donné
volontairement. On peut supposer que le FAI se faisait
payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où
des experts ont décortiqué ce qui se passait et l’ont
documenté. Il y a certainement de nombreux autres cas qui
passent inaperçus. Ce n’est pas par hasard si la majorité de
ces manipulations se déroulent dans les pays du Sud, où il y a
moins d’experts disponibles pour l’analyse, et où l’absence de
démocratie politique n’encourage pas les citoyens à regarder
de près ce qui se passe. Il n’est pas étonnant que ces
modifications du trafic qui passe dans le réseau soient la
règle en Chine. Ces changements du trafic en cours de route
sont plus fréquents sur les réseaux de mobiles (téléphone
mobile) car c’est depuis longtemps un monde plus fermé et
davantage contrôlé, où les FAI ont pris de mauvaises
habitudes. Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données). Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer ! Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses. Surveiller le trafic réseau De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux. Grâce au courage du lanceur d’alerte Edward Snowden, la
surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie. L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI. Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel. La solution du chiffrement Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont

illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données. Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques. Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités. Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur

ce blog que vous êtes en train de lire. Tous les sites Web sérieux ont aujourd’hui HTTPS Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques. Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées. Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC
(Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 » 1 décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté. Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux ! Conclusion Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site. J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable. Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans
certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité. Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés. Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week- end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro- alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile. Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des
utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle. Les données que récolte Google – Ch.3 Voici déjà la traduction du troisième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit aujourd’hui de mesurer ce que les plateformes les plus populaires recueillent de nos smartphones Traduction Framalang : Côme, goofy, Khrys, Mika, Piup. Remerciements particuliers à badumtss qui a contribué à la traduction de l’infographie. La collecte des données par les plateformes Android et Chrome 11. Android et Chrome sont les plateformes clés de Google qui facilitent la collecte massive de données des utilisateurs en raison de leur grande portée et fréquence d’utilisation. En janvier 2018, Android détenait 53 % du marché américain des systèmes d’exploitation mobiles (iOS d’Apple en détenait 45 %)2 et, en mai 2017, il y avait plus de 2 milliards d’appareils Android actifs par mois dans le monde.3
12. Le navigateur Chrome de Google représentait plus de 60 % de l’utilisation mondiale de navigateurs Internet avec plus d’un milliard d’utilisateurs actifs par mois, comme l’indiquait le rapport Q4 10K de 20174. Les deux plateformes facilitent l’usage de contenus de Google et de tiers (p.ex. applications et sites tiers) et fournissent donc à Google un accès à un large éventail d’informations personnelles, d’activité web, et de localisation. A. Collecte d’informations personnelles et de données d’activité 13. Pour télécharger et utiliser des applications depuis le Google Play Store sur un appareil Android, un utilisateur doit posséder (ou créer) un compte Google, qui devient une passerelle clé par laquelle Google collecte ses informations personnelles, ce qui comporte son nom d’utilisateur, son adresse de messagerie et son numéro de téléphone. Si un utilisateur s’inscrit à des services comme Google Pay5, Android collecte également les données de la carte bancaire, le code postal et la date de naissance de l’utilisateur. Toutes ces données font alors partie des informations personnelles de l’utilisateur associées à son compte Google. 14. Alors que Chrome n’oblige pas le partage d’informations personnelles supplémentaires recueillies auprès des utilisateurs, il a la possibilité de récupérer de telles informations. Par exemple, Chrome collecte toute une gamme d’informations personnelles avec la fonctionnalité de remplissage automatique des formulaires, qui incluent typiquement le nom d’utilisateur, l’adresse, le numéro de téléphone, l’identifiant de connexion et les mots de passe.6 Chrome stocke les informations saisies dans les formulaires sur le disque dur de l’utilisateur. Cependant, si l’utilisateur se connecte à Chrome avec un compte Google et active la fonctionnalité de synchronisation, ces informations
sont envoyées et stockées sur les serveurs de Google. Chrome
pourrait également apprendre la ou les langues que parle la
personne avec sa fonctionnalité de traduction, activée par
défaut.7
15. En plus des données personnelles, Chrome et Android
envoient tous deux à Google des informations concernant les
activités de navigation et l’emploi d’applications mobiles,
respectivement. Chaque visite de page internet est
automatiquement traquée et collectée par Google si
l’utilisateur a un compte Chrome. Chrome collecte également
son historique de navigation, ses mots de passe, les
permissions particulières selon les sites web, les cookies,
l’historique de téléchargement et les données relatives aux
8
extensions.
16. Android envoie des mises à jour régulières aux serveurs de
Google, ce qui comprend le type d’appareil, le nom de
l’opérateur, les rapports de bug et des informations sur les
applications installées9. Il avertit également Google chaque
fois qu’une application est ouverte sur le téléphone (ex.
Google sait quand un utilisateur d’Android ouvre son
application Uber).
B. Collecte des données de localisation
de l’utilisateur
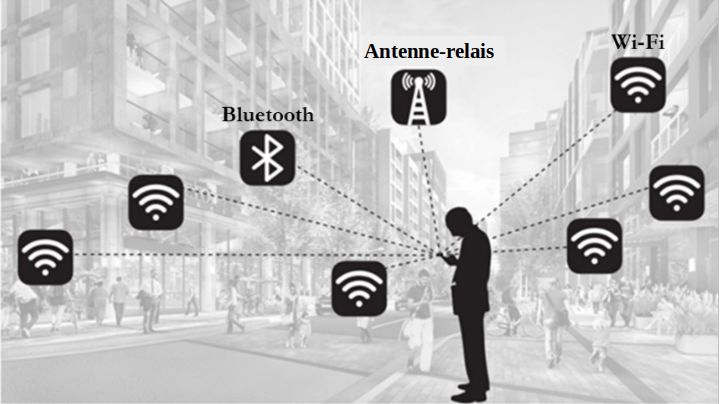
17. Android et Chrome collectent méticuleusement la
localisation et les mouvements de l’utilisateur en utilisant
une variété de sources, représentées sur la figure 3. Par
exemple, un accès à la « localisation approximative » peut
être réalisé en utilisant les coordonnées GPS sur un téléphone
Android ou avec l’adresse IP sur un ordinateur. La précision
de la localisation peut être améliorée (« localisation
précise ») avec l’usage des identifiants des antennes
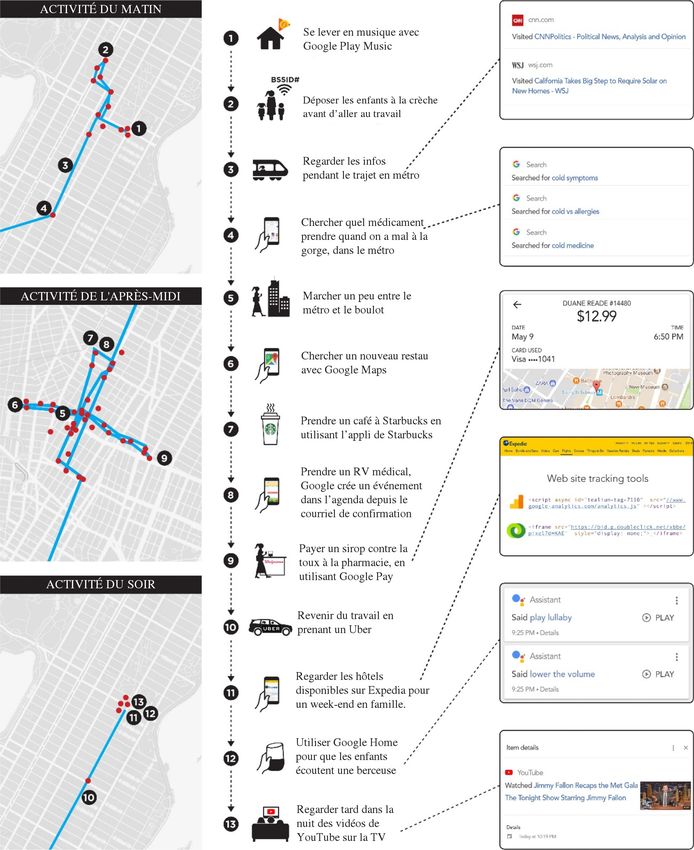
cellulaires environnantes ou en scannant les BSSID (’’BasicService Set IDentifiers’’), identifiants assignés de manière unique aux puces radio des points d’accès Wi-Fi présents aux alentours10. Les téléphones Android peuvent aussi utiliser les informations des balises Bluetooth enregistrées dans l’API Proximity Beacon de Google 1 1 . Ces balises non seulement fournissent les coordonnées de géolocalisation de l’utilisateur, mais pourraient aussi indiquer à quel étage exact il se trouve dans un immeuble.12 Figure 3 : Android et Chrome utilisent diverses manières de localiser l’utilisateur d’un téléphone. 18. Il est difficile pour un utilisateur de téléphone Android de refuser le traçage de sa localisation. Par exemple, sur un appareil Android, même si un utilisateur désactive le Wi-Fi, la localisation est toujours suivie par son signal Wi-Fi. Pour éviter un tel traçage, le scan Wi-Fi doit être explicitement désactivé par une autre action de l’utilisateur, comme montré sur la figure 4.
Figure 4 : Android collecte des données même si le Wi-
Fi est éteint par l’utilisateur
19. L’omniprésence de points d’accès Wi-Fi a rendu le traçage
de localisation assez fréquent. Par exemple, durant une courte
promenade de 15 minutes autour d’une résidence, un appareil
Android a envoyé neuf requêtes de localisation à Google. Les
requêtes contenaient au total environ 100 BSSID de points
d’accès Wi-Fi publics et privés.
20. Google peut vérifier avec un haut degré de confiance si un
utilisateur est immobile, s’il marche, court, fait du vélo, ou
voyage en train ou en car. Il y parvient grâce au traçage à
intervalles de temps réguliers de la localisation d’un
utilisateur Android, combiné avec les données des capteurs
embarqués (comme l’accéléromètre) sur les téléphones mobiles.
La figure 5 montre un exemple de telles données communiquéesaux serveurs de Google pendant que l’utilisateur marchait.
Figure 5 : capture d’écran d’un
envoi de localisation d’utilisateur
à Google.
C. Une évaluation de la collecte passive
de données par Google via Android et
Chrome
21. Les données actives que les plateformes Android ou Chrome
collectent et envoient à Google à la suite des activités des
utilisateurs sur ces plateformes peuvent être évaluées à
l’aide des outils MyActivity et Takeout. Les données passives
recueillies par ces plateformes, qui vont au-delà des données
de localisation et qui restent relativement méconnues des
utilisateurs, présentent cependant un intérêt potentiellement
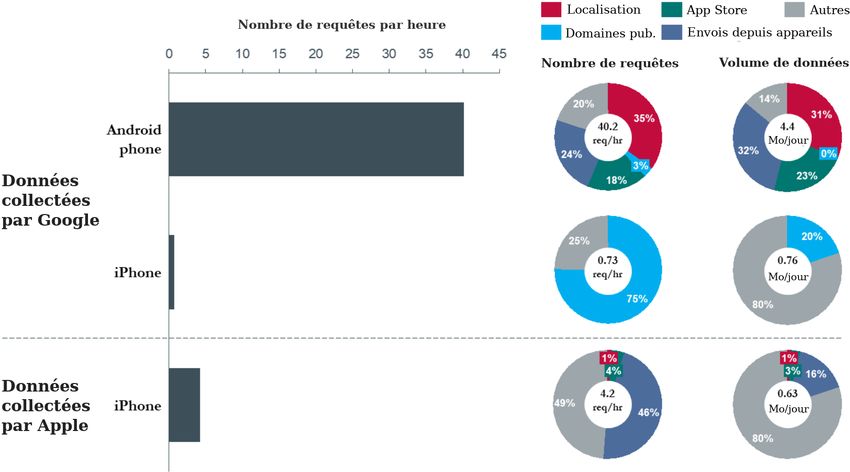
plus grand. Afin d’évaluer plus en détail le type et lafréquence de cette collecte, une expérience a été menée pour surveiller les données relatives au trafic envoyées à Google par les téléphones mobiles (Android et iPhone) en utilisant la méthode décrite dans la section IX.D de l’annexe. À titre de comparaison, cette expérience comprenait également l’analyse des données envoyées à Apple via un appareil iPhone. 22. Pour des raisons de simplicité, les téléphones sont restés stationnaires, sans aucune interaction avec l’utilisateur. Sur le téléphone Android, une seule session de navigateur Chrome restait active en arrière-plan, tandis que sur l’iPhone, le navigateur Safari était utilisé. Cette configuration a permis une analyse systématique de la collecte de fond que Google effectue uniquement via Android et Chrome, ainsi que de la collecte qui se produit en l’absence de ceux-ci (c’est-à-dire à partir d’un appareil iPhone), sans aucune demande de collecte supplémentaire générée par d’autres produits et applications (par exemple YouTube, Gmail ou utilisation d’applications). 23. La figure 6 présente un résumé des résultats obtenus dans le cadre de cette expérience. L’axe des abscisses indique le nombre de fois où les téléphones ont communiqué avec les serveurs Google (ou Apple), tandis que l’axe des ordonnées indique le type de téléphone (Android ou iPhone) et le type de domaine de serveur (Google ou Apple) avec lequel les paquets de données ont été échangés par les téléphones. La légende en couleur décrit la catégorisation générale du type de demandes de données identifiées par l’adresse de domaine du serveur. Une liste complète des adresses de domaine appartenant à chaque catégorie figure dans le tableau 5 de la section IX.D de l’annexe. 24. Au cours d’une période de 24 heures, l’appareil Android a communiqué environ 900 échantillons de données à une série de terminaux de serveur Google. Parmi ceux-ci, environ 35 % (soit environ 14 par heure) étaient liés à la localisation. Les domaines publicitaires de Google n’ont reçu que 3 % du trafic,
ce qui est principalement dû au fait que le navigateur mobile n’a pas été utilisé activement pendant la période de collecte. Le reste (62 %) des communications avec les domaines de serveurs Google se répartissaient grosso modo entre les demandes adressées au magasin d’applications Google Play, les téléchargements par Android de données relatives aux périphériques (tels que les rapports de crash et les autorisations de périphériques), et d’autres données — principalement de la catégorie des appels et actualisations de fond des services Google. Figure 6 : Données sur le trafic envoyées par les appareils Andoid et les iPhones en veille. 25. La figure 6 montre que l’appareil iPhone communiquait avec les domaines Google à une fréquence inférieure de plus d’un ordre de grandeur (50 fois) à celle de l’appareil Android, et que Google n’a recueilli aucun donnée de localisation utilisateur pendant la période d’expérience de 24 heures via iPhone. Ce résultat souligne le fait que les plateformes Android et Chrome jouent un rôle important dans la collecte de
données de Google. 26. De plus, les communications de l’appareil iPhone avec les serveurs d’Apple étaient 10 fois moins fréquentes que les communications de l’appareil Android avec Google. Les données de localisation ne représentaient qu’une très faible fraction (1 %) des données nettes envoyées aux serveurs Apple à partir de l’iPhone, Apple recevant en moyenne une fois par jour des communications liées à la localisation. 27. En termes d’amplitude, les téléphones Android communiquaient 4,4 Mo de données par jour (130 Mo par mois) avec les serveurs Google, soit 6 fois plus que ce que les serveurs Google communiquaient à travers l’appareil iPhone. 28. Pour rappel, cette expérience a été réalisée à l’aide d’un téléphone stationnaire, sans interaction avec l’utilisateur. Lorsqu’un utilisateur commence à bouger et à interagir avec son téléphone, la fréquence des communications avec les serveurs de Google augmente considérablement. La section V du présent rapport résume les résultats d’une telle expérience. Khrys’presso du lundi 26 novembre Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Brave New World
Comment la Chine a réussi à devenir une superpuissance
tout en se cloisonnant d’Internet (nytimes.com – en
anglais)
Aujourd’hui, la Chine possède les seules entreprises
sur Internet au monde qui peuvent égaler les US en
ambition et en rayonnement. […] Et tout cela, sur un
espace cybernétique cloisonné, protégé de Facebook et
Google, surveillé par des dizaines de milliers de
censeurs et soumis à des contrôles stricts sur la façon
dont les données sont collectées, stockées et
partagées.
Colonisation d’Internet par la censure : la Chine
dégaine en Afrique (theconversation.com)
Beijing va implémenter définitivement son système de
notation des citoyens d’ici deux ans (numerama.com)
Votre cote de solvabilité n’est pas le reflet de votre
caractère moral. Mais le Département de la Sécurité
Intérieure semble penser qu’il l’est (slate.com – en
anglais)
Le département de la Sécurité intérieure des États-Unis
veut utiliser les cotes de solvabilité à des fins
entièrement différentes, pour lesquelles elles n’ont
jamais été conçues et pour lesquelles elles ne sont pas
adaptées. L’agence chargée de la protection de la
nation aimerait obliger les immigrants à présenter leur
cote de solvabilité lorsqu’ils demandent le statut
légal de résident.
L’OCCRP s’oppose fermement au détournement du RGPD par
la Roumanie pour museler les médias (occrp.org – en
anglais)
Le système allemand de carte d’identité électronique
vulnérable à l’usurpation d’identité en ligne (zdnet.fr)Vote électronique : en Suisse, le débat relancé par le Chaos Computer Club (numerama.com) You Snooze, You Lose : les assureurs rendent le vieil adage littéralement vrai (propublica.org – en anglais) “Vous le considériez comme un appareil qui est le vôtre et conçu pour vous servir, et tout à coup, vous vous rendez compte qu’il s’agit d’un appareil de surveillance utilisé par votre compagnie d’assurance maladie pour limiter votre accès aux soins de santé.”[…] “J’aimerais qu’ils consacrent autant de temps à me prodiguer des soins qu’à vérifier si je suis « en règle ».” Un test génétique pour détecter l’intelligence de son futur bébé ? (rtl.fr) La startup Nebula Genomics propose de séquencer gratuitement l’ensemble de votre génome, si vous acceptez que vos données soient stockées sur la Blockchain. (usbeketrica.com – en anglais) Un des pères de l’IA s’inquiète de son avenir (technologyreview.com – en anglais) Des jeunes au bord de l’illettrisme numérique (liberation.fr) Les mensonges de Trump sont un virus et les organismes de presse en sont l’hôte (theatlantic.com – en anglais) Julian Assange : Il a dit la vérité, Il doit être exécuté (mediapart.fr)
Julian se meurt à petit feu dans l’indifférence générale des principaux canaux d’information des « démocraties » occidentales. Personne n’en parle. Il est impératif de faire passer ce message. […] Au cours des six dernières années, le gouvernement britannique a refusé ses demandes d’accès aux soins de santé de base : air frais, exercice, soleil pour la vitamine D et accès à des soins médicaux et dentaires appropriés. En conséquence, sa santé s’est sérieusement détériorée et les médecins qui l’examinent mettent en garde contre ces conditions de détention qui mettent sa vie en danger. Un assassinat lent et cruel se déroule sous nos yeux à l’ambassade de Londres. En 2016, après une enquête approfondie, les Nations Unies ont statué que les droits de Julian avaient été violés à plusieurs reprises, qu’il était détenu illégalement depuis 2010, et ont ordonné sa libération immédiate, un sauf-conduit et son indemnisation. Le gouvernement britannique a refusé de se conformer à la décision de l’ONU.[…] Je vous demande de faire du bruit, beaucoup de bruit, et de continuer à en faire jusqu’à ce que mon fils soit libéré. Nous devons protester contre cette brutalité assourdissante. Les sociétés spécialisées dans l’analyse de données engagées par l’ICE (Immigration and Customs Enforcement) pour traquer les gens sont symptomatiques d’une industrie secrète de la surveillance (fastcompany.com – en anglais) Le PDG de Ford admet franchement que la voiture du futur est un appareil de surveillance que vous payez pour vous espionner. (boingboing.net – en anglais) Une enceinte connectée a-t-elle été « témoin » d’un meurtre aux Etats-Unis ? (lemonde.fr) LinkedIn a violé la protection des données en utilisant
18 millions d’adresses e-mail de non-membres pour acheter des publicités ciblées sur Facebook (techcrunch.com – en anglais) Au sein de la guerre des prix pour influencer votre flux Instagram (wired.com – en anglais) Haut score, bas salaires : pourquoi l’économie adore les jeux vidéo (theguardian.com – en anglais) Il est temps de briser l’emprise de l’édition universitaire sur la recherche (newscientist.com – en anglais) Quelle est l’entreprise la plus rentable au monde ? Vous pensez peut-être au pétrole, ou peut-être à la banque. Vous auriez tort. La réponse est l’édition universitaire, dont les marges bénéficiaires sont énormes, de l’ordre de 40 % selon les rapports. La raison pour laquelle c’est si lucratif, c’est parce que la plupart des coûts de contenu sont assumés par les contribuables : des chercheurs financés par des fonds publics font le travail, le rédigent et jugent son bien-fondé. Et pourtant, la propriété intellectuelle qui en résulte se retrouve entre les mains des
éditeurs. Pour remuer le couteau dans la plaie, ils la
vendent ensuite par le biais d’abonnements exorbitants
et de « pay walls », souvent également financés par les
contribuables.
Spécial France
Tout va rentrer dans l’ordre sur le cuivre en 2019,
promet Orange (zdnet.fr)
À la recherche des RIP FTTH : accéder aux documents
administratifs, c’est plus long que prévu (ffdn.org)
La Ville de Paris va passer de Google à Qwant (zdnet.fr)
fr/enfants/youtube-ou-le-bescherelle-les-profs-pourront-
choisir-%28ou-non%29,n5896337.php »>YouTube ou le
Bescherelle : les profs pourront choisir (ou non)
(telerama.fr)
Biométrie : le FNAEG en passe de devenir le nouveau
fichier des « gens honnêtes » (nextinpact.com) – voir
aussi : (OLN) Fichage génétique : dérapage incontrôlé
(lececil.org)
L’amendement proposant de ne plus restreindre l’extrait
d’ADN prélevé aux seuls segments non codants est
présenté comme une évidence scientifique et une
nécessité pour s’adapter aux évolutions futures. Or
cette exclusion était centrale lors de la création du
fichier : ces segments « non codants » devaient
permettre, sur la base des connaissances scientifiques
de l’époque, d’identifier la personne concernée de
manière unique sans révéler ses caractéristiques
héréditaires ou acquises et c’est sur la base de cedit
garde-fou, scientifiquement contesté depuis, que ce
fichier a pu prospérer sans véritable débat
démocratique sur l’éthique du fichage génétique. Le
balayer d’un revers de main, en prétendant qu’il
suffirait désormais de préciser que les informationsrelatives aux caractéristiques de la personne ne
pourront apparaitre dans le fichier vise à endormir la
vigilance des citoyens. La Commission nationale
informatique et libertés (CNIL) ne s’y est pas trompée,
en dénonçant cette évolution lourde, intervenue sans
son avis préalable.
Mais bientôt, il suffira qu’un parent, cousin, oncle,
tante ait déjà été fiché, même pour une infraction
mineure, pour devenir un suspect potentiel.
« Le fonctionnement des administrations est incompatible
avec l’ouverture des données publiques »
(rue89strasbourg.com)
État d’urgence : l’un des premiers arrêtés interdisant
les manifestations fin 2015 jugé illégal (europe1.fr)
Droit de manifester : que dit la loi ? (liberation.fr)
La marche #NousToutes à Paris a rassemblé plus de monde
que la manif des gilets jaunes (huffingtonpost.fr)
Caméras-piétons : un outil contre les violences
policières, ou au service des forces de l’ordre ?
(bastamag.net)
Spécial GAFAM
Les GAFAM ont perdu près de 1 000 milliards de dollars
de valeur depuis cet été (lemonde.fr) – voir aussi :
Pourquoi les GAFAM s’effondrent en bourse (letemps.ch)
Directive sur le droit d’auteur : Google contre-attaque
(usbeketrica.com) – voir aussi : Article 13 : comment
YouTube enrôle ses utilisateurs contre la directive sur
le droit d’auteur (telerama.fr) et : Article 13: si vous
voulez forcer Google à plus payer les artistes, forcez
Google à plus payer les artistes (eff.org – en anglais)
Au lieu de détruire Internet, réparons le droit
d’auteur : trouvons des règles qui réduisent le pouvoir
monopolistique, augmentent la concurrence et mettent del’argent dans les poches des artistes. Si nous voulons que Google paie davantage les créateurs, faisons simplement en sorte que Google paie davantage les créateurs et oublions le logiciel de censure. Google investit 600 millions d’euros dans son premier datacenter au Danemark (zdnet.fr) Les données que récolte Google – Ch. 2 (framablog.org) La France abandonne Google pour regagner son indépendance en ligne (wired.co.uk – en anglais) Amazon n’a pas choisi votre ville pour son deuxième QG, mais elle a recueilli beaucoup de données à son sujet. (popsci.com – en anglais) “Cela n’a jamais été vraiment à propos du second QG”. Chaque ville qui a fait sa promotion auprès d’Amazon a remis des dizaines, voire des centaines de pages d’informations organisées dans le cadre du processus de séduction. “C’était vraiment une façon unique d’obtenir de l’information sur des dizaines de villes.”
Amazon avertit ses clients qu’il a divulgué leurs noms et adresses e-mail (grahamcluley.com – en anglais) The Guardian : Notre nouvelle rubrique au sein d’Amazon:’Ils nous traitent comme des objets jetables’ (theguardian.com – en anglais) Pour le Black Friday, des employés d’Amazon font grève en Europe (mais pas en France) (numerama.com) – voir aussi : Les travailleurs d’Amazon à travers l’Europe protestent contre le vendredi noir, citant des conditions de travail pénibles (gizmodo.com – en anglais) À présent, huit parlements exigent des réponses de M. Zuckerberg pour les scandales concernant Facebook (techcrunch.com – en anglais) Désolé Mark Zuckerberg, Facebook n’est pas une force positive (arstechnica.com – en anglais) Facebook ne pourra jamais faire les choses correctement (edri.org – en anglais) « Facebook, broyeur destiné à ruiner tout l’édifice de la culture » (franceculture.fr) Facebook accepte de payer 100 millions d’euros d’arriérés d’impôts en Italie (nextinpact.com) Après avoir initialement qualifié le dossier du New York Times de faux, Facebook confirme la plupart des assertions de l’article (nytimes.com – en anglais) Apple n’a pas l’intention de se passer de Google comme moteur de recherche par défaut (numerama.com) Le patron d’Apple, Tim Cook, considère que Google est tout à fait pertinent comme moteur de recherche par défaut. Parce qu’il offre d’excellents résultats, parce qu’Apple a mis des protections pour la vie privée… et parce que l’accord rapporte des milliards de dollars. La mise à jour iOS de Google Assistant vous permet désormais de dire : ’Salut Siri, OK Google’ (techcrunch.com – en anglais)
Pourquoi quitter iOS pour Android est un cauchemar
(01net.com)
Paradoxalement, pour retenir un utilisateur dans son
écosystème, Apple le pousse à tout transférer chez la
concurrence. C’est le constat que je dresse de cette
expérience de migration vers Android. J’aurais aimé
profiter du Pixel en conservant mes services Apple mais
la marque fait tout pour que l’utilisateur qui
l’abandonne n’ait pas d’autres choix que de tirer un
trait sur tout le reste de son écosystème. Pas besoin
de vous dire qu’un HomePod, une Apple Watch, un Mac ou
un iPad se montrent bien moins collaboratifs avec un
Pixel qu’un iPhone, histoire de rappeler à
l’utilisateur qu’il est désormais sorti d’un monde
intégré, passé dans une autre dimension, celle des
smartphones Android.
Microsoft menacé par de très grosses amendes liées au
RGPD en Europe pour une collecte « secrète et à grande
échelle » d’informations sur les gens via Office
(theregister.co.uk – en anglais)
Les auteurs du dossier ont constaté que le goliath
Windows recueillait des données télémétriques et
d’autres contenus à partir de ses applications Office,
y compris des titres et des phrases de courriels où la
traduction ou le correcteur orthographique était
utilisé, et stockait secrètement les données sur des
systèmes situés aux États-Unis.
Microsoft teste de la publicité dans l’app Courrier de
Windows 10, puis se rétracte (numerama.com)
Et cette semaine, on soutient…
L’association #OpenStreetMap France, qui lance un appel
aux dons pour le renouvellement de ses serveurs, et ilssont nombreux 10 ans au compteur mais la Quadrature a toujours besoin de vos dons (zdnet.fr) Framasoft, encore et toujours ! Voir aussi Impôts et dons à Framasoft : le prélèvement à la source en 2019 Software Freedom Conservancy : un objectif de fin d’année de $90K de dons pour financer une année ambitieuse (sfconservancy.org – en anglais) Celles et ceux qui, dans les coulisses le plus souvent, créent, développent et maintiennent les logiciels et services qu’on utilise : C’est facile de leur dire merci… Et on continue à contribuer… Mozilla a mis en route un site web pour construire une voix de synthèse en alternative à celles des GAFAM. Il y a une base de donnée libre (licence CC-0) en cours de construction. Les contributions peuvent être rapides ! Plein de façons différentes de contribuer à / aider εxodus privacy, qui fête son premier anniversaire !
Les plus ou moins gros pavés de la
semaine
Décentraliser Internet par la fédération : l’exemple
d’ActivityPub (framasoft.org)
Recevoir une avalanche de messages menaçants sur
WhatsApp. Être pistée par un logiciel espion installé
sur son téléphone. Devoir fournir le mot de passe de sa
boîte e-mail… Voilà quelques-unes des épreuves que
doivent régulièrement traverser les victimes de
violences conjugales et qu’a identifiées le centre
Hubertine-Auclert, (centre francilien pour l’égalité
femmes-hommes), dans un rapport publié mardi 20
novembre.
Violences conjugales : enquête sur un meurtre de masse
(liberation.fr)
Les lectures de la semaine
Le Fax n’est pas encore obsolete (theatlantic.com – en
anglais)
« Le respect de la vie privée est l’arbre qui cache la
forêt » (usbeketrica.com)
Quand le droit d’auteur devient plus vigoureux que la
lutte contre les contenus terroristes (nextinpact.com)
« Logiciel libre » et « Open Source », c’est pareil ou
pas ? (bortzmeyer.org)
Pourquoi les écoles devraient utiliser exclusivement des
logiciels libres (gnu.org – en anglais)
À qui faisons-nous confiance pour le bien commun ?
(edri.org – en anglais)
Il est troublant de penser que Google dispose de plus
de données sur le développement urbain d’Amsterdam que
la ville d’Amsterdam elle-même. Non seulement les
autres entreprises ont de plus en plus de mal à
concurrencer Google, mais le secteur public estégalement distancé. Nous nous dirigeons vers une situation où de plus en plus de nos données publiques appartiendront à des intérêts privés et nous seront louées sous conditions commerciales. Une situation intenable, une fois que vous réalisez que Google sera celui qui décidera quelles données doivent être collectées et quelle partie de celles-ci doit être divulguée à qui et sous quelles conditions. Si Google n’est pas satisfait de l’orientation d’un certain projet de recherche ou des produits et services élaborés sur la base de « ses » données, il pourra simplement fermer l’accès à ces données. Négocier les horaires du ramassage scolaire : l’impact du calcul sur la société ne s’imposera pas par ses qualités ! (internetactu.net) « Il n’y a qu’une solution : décroître très fortement » (usbeketrica.com) « La Silicon Valley nous montre à quoi ressemble le capitalisme déchaîné » (usbeketrica.com) La couleur des gilets jaunes (laviedesidees.fr) Comment la musique peut doper notre cerveau (usbeketrica.com)
Vous pouvez aussi lire

















































